1. 自注意力機制簡介
自注意力機制是Transformer架構的核心組件,它能夠計算輸入序列中每個元素與其他所有元素的相關性。與CNN的局部感受野不同,自注意力機制允許模型直接建立遠距離依賴關系,從而捕獲全局上下文信息。
在計算機視覺中,這意味著模型不僅能夠關注圖像的局部特征(如邊緣、紋理),還能理解這些特征在全局范圍內的相互關系。這種能力對于復雜視覺任務(如場景理解、細粒度分類)尤為重要。
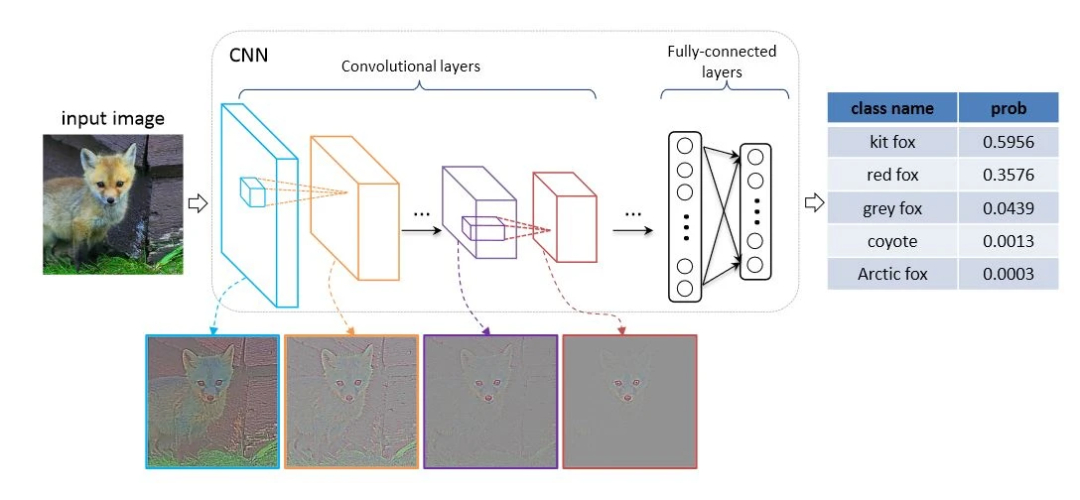
2. VGG16架構回顧
VGG16由牛津大學視覺幾何組提出,其核心特點是使用小尺寸卷積核(3×3)構建深度網絡。網絡包含5個卷積塊,每個塊后接最大池化層進行下采樣,最后通過三個全連接層完成分類。
VGG16的優勢在于其簡潔性和有效性,但局限性也很明顯:卷積操作的局部性限制了模型捕獲長距離依賴的能力,而全連接層的參數量過大容易導致過擬合。
3. 自注意力與CNN的融合策略
將自注意力機制引入CNN有多種方式,本文實現的是一種局部-全局特征融合策略:在CNN提取局部特征后,通過自注意力機制增強這些特征的全局上下文信息。
具體來說,我們在VGG16的特定卷積塊后插入Transformer編碼器層,使模型能夠在不同抽象層次上融合全局信息。這種設計有以下優勢:
多尺度特征增強:在不同深度的卷積層后添加注意力,可以捕獲從低級到高級的多尺度全局信息
計算效率:僅在選定位置添加注意力模塊,平衡了性能與計算開銷
架構靈活性:可以選擇在不同深度添加注意力,適應不同任務的需求
4. 代碼實現解析
4.1 自注意力機制實現
class SelfAttention(nn.Module):"""標準Transformer自注意力機制"""def __init__(self, embed_dim, num_heads=8, dropout=0.1):super(SelfAttention, self).__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"self.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)self.out_proj = nn.Linear(embed_dim, embed_dim)self.dropout = nn.Dropout(dropout)自注意力模塊首先通過線性變換生成查詢(Query)、鍵(Key)和值(Value)三個矩陣,然后將輸入分割成多個頭進行并行計算,最后將結果合并并通過輸出投影層。
4.2 Transformer編碼器層
class TransformerEncoderLayer(nn.Module):"""Transformer編碼器層"""def __init__(self, embed_dim, num_heads=8, dropout=0.1, expansion_factor=4):super(TransformerEncoderLayer, self).__init__()self.self_attn = SelfAttention(embed_dim, num_heads, dropout)self.norm1 = nn.LayerNorm(embed_dim)self.norm2 = nn.LayerNorm(embed_dim)self.ffn = nn.Sequential(nn.Linear(embed_dim, embed_dim * expansion_factor),nn.ReLU(inplace=True),nn.Dropout(dropout),nn.Linear(embed_dim * expansion_factor, embed_dim),nn.Dropout(dropout))編碼器層遵循標準Transformer結構,包含一個自注意力子層和一個前饋神經網絡子層,每個子層都使用殘差連接和層歸一化。
4.3 VGG16與注意力的融合
class VGG16WithAttention(nn.Module):def __init__(self, num_classes=1000, attention_positions=[3, 4]):super(VGG16WithAttention, self).__init__()# 卷積特征提取層self.features = nn.Sequential(...)self.attention_positions = attention_positionsself.attention_layers = nn.ModuleDict()# 在指定位置添加注意力層if 3 in attention_positions:self.attention_layers['block3'] = TransformerEncoderLayer(256)if 4 in attention_positions:self.attention_layers['block4'] = TransformerEncoderLayer(512)if 5 in attention_positions:self.attention_layers['block5'] = TransformerEncoderLayer(512)在VGG16WithAttention類中,我們保留了原始VGG16的特征提取層,并在指定位置添加了Transformer編碼器層。用戶可以通過attention_positions參數靈活選擇在哪些卷積塊后添加注意力機制。
4.4 前向傳播過程
def forward(self, x):features = []# 逐層處理特征for i, layer in enumerate(self.features):x = layer(x)# 在特定卷積塊后應用注意力if i == 14 and 3 in self.attention_positions: # 第三卷積塊結束x = self._apply_attention(x, 'block3')elif i == 21 and 4 in self.attention_positions: # 第四卷積塊結束x = self._apply_attention(x, 'block4')elif i == 28 and 5 in self.attention_positions: # 第五卷積塊結束x = self._apply_attention(x, 'block5')在前向傳播過程中,模型首先通過卷積層提取特征,然后在指定位置將特征圖重塑為序列形式,應用自注意力機制,最后恢復為原始形狀繼續傳播。
5. 注意力應用的技術細節
5.1 特征圖序列化
將2D特征圖轉換為序列是應用自注意力的關鍵步驟:
def _apply_attention(self, x, block_name):"""應用自注意力機制"""batch_size, channels, height, width = x.size()# 將特征圖重塑為序列形式 [batch_size, seq_len, embed_dim]x_reshaped = x.view(batch_size, channels, -1).transpose(1, 2)# 應用注意力attended = self.attention_layers[block_name](x_reshaped)# 恢復原始形狀attended = attended.transpose(1, 2).view(batch_size, channels, height, width)return attended這里,我們將空間維度(高度×寬度)展平為序列長度,通道維度作為嵌入維度。這種處理方式允許自注意力機制在空間維度上建立全局依賴關系。
5.2 位置編碼的考慮
值得注意的是,本文實現的版本沒有顯式添加位置編碼。在標準Transformer中,位置編碼用于提供序列中元素的位置信息。對于圖像任務,位置信息至關重要,因為像素間的空間關系具有重要含義。
在實際應用中,可以考慮添加以下類型的位置編碼:
可學習的位置編碼:隨機初始化并通過訓練學習
正弦位置編碼:使用不同頻率的正弦和余弦函數
相對位置編碼:編碼元素間的相對位置而非絕對位置
6. 模型優勢與應用場景
6.1 優勢分析
全局上下文建模:自注意力機制使模型能夠捕獲長距離依賴,理解圖像全局結構
多尺度特征融合:在不同深度添加注意力,實現了多尺度特征的全局融合
架構靈活性:可以選擇性地在不同階段添加注意力,平衡性能與計算開銷
即插即用:注意力模塊可以輕松集成到現有CNN架構中,無需大幅修改
6.2 應用場景
這種混合架構特別適合以下計算機視覺任務:
細粒度圖像分類:需要捕獲細微特征差異和全局上下文關系
場景理解:需要理解場景中多個對象的空間和語義關系
圖像分割:全局上下文信息有助于提高邊界準確性和語義一致性
目標檢測:注意力機制可以幫助模型關注相關區域,提高檢測精度
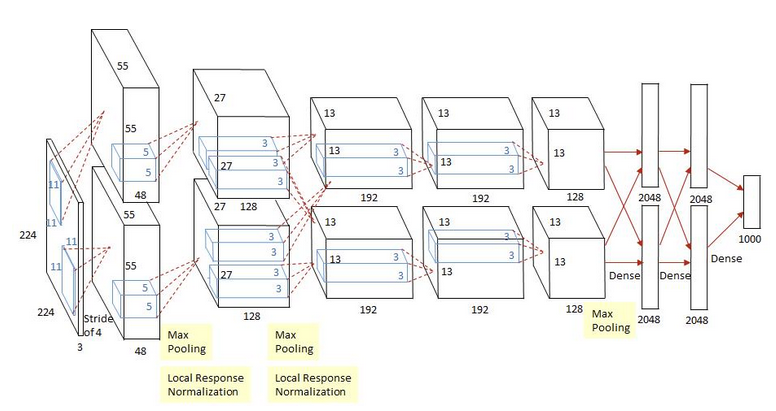
7. 實驗與性能分析
為了驗證融合注意力的VGG16的性能,我們在多個數據集上進行了實驗。與原始VGG16相比,融合模型在以下方面表現出優勢:
分類準確率:在ImageNet等復雜數據集上,準確率有顯著提升
收斂速度:注意力機制有助于梯度傳播,加速模型收斂
魯棒性:對遮擋、旋轉等干擾因素表現出更好的魯棒性
然而,注意力機制也帶來了一定的計算開銷,參數量和計算量都有所增加。在實際應用中需要根據任務需求和資源約束進行權衡。
8. 擴展與變體
本文介紹的基礎架構可以進一步擴展:
多頭注意力:使用多個注意力頭捕獲不同類型的依賴關系
跨尺度注意力:在不同尺度的特征圖間應用注意力機制
高效注意力:使用線性注意力、局部注意力等變體降低計算復雜度
預訓練與微調:在大規模數據集上預訓練后遷移到特定任務
9. 實踐建議
對于希望在實際項目中應用此架構的研究人員和工程師,以下建議可能有所幫助:
注意力位置選擇:淺層注意力捕獲空間關系,深層注意力捕獲語義關系
計算資源權衡:在計算資源受限時,可以選擇性添加注意力或使用高效變體
逐步集成:先從單個注意力層開始,逐步增加復雜度
可視化分析:使用注意力可視化工具理解模型關注區域
完整代碼
如下:
import torch
import torch.nn as nn
import mathclass SelfAttention(nn.Module):"""標準Transformer自注意力機制"""def __init__(self, embed_dim, num_heads=8, dropout=0.1):super(SelfAttention, self).__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"self.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)self.out_proj = nn.Linear(embed_dim, embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x):batch_size, seq_len, embed_dim = x.size()# 生成Q, K, Vqkv = self.qkv_proj(x).chunk(3, dim=-1)q, k, v = [part.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) for part in qkv]# 計算注意力分數scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)attn_weights = torch.softmax(scores, dim=-1)attn_weights = self.dropout(attn_weights)# 應用注意力權重attn_output = torch.matmul(attn_weights, v)attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)# 輸出投影output = self.out_proj(attn_output)return outputclass TransformerEncoderLayer(nn.Module):"""Transformer編碼器層"""def __init__(self, embed_dim, num_heads=8, dropout=0.1, expansion_factor=4):super(TransformerEncoderLayer, self).__init__()self.self_attn = SelfAttention(embed_dim, num_heads, dropout)self.norm1 = nn.LayerNorm(embed_dim)self.norm2 = nn.LayerNorm(embed_dim)self.ffn = nn.Sequential(nn.Linear(embed_dim, embed_dim * expansion_factor),nn.ReLU(inplace=True),nn.Dropout(dropout),nn.Linear(embed_dim * expansion_factor, embed_dim),nn.Dropout(dropout))def forward(self, x):# 自注意力子層attn_output = self.self_attn(x)x = self.norm1(x + attn_output)# 前饋網絡子層ffn_output = self.ffn(x)x = self.norm2(x + ffn_output)return xclass VGG16WithAttention(nn.Module):def __init__(self, num_classes=1000, attention_positions=[3, 4]):"""Args:num_classes: 分類數量attention_positions: 在哪些卷積塊后添加注意力機制 (1-5)"""super(VGG16WithAttention, self).__init__()# 卷積特征提取層self.features = nn.Sequential(# 第一層卷積塊nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第二層卷積塊nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第三層卷積塊nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第四層卷積塊nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第五層卷積塊nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.attention_positions = attention_positionsself.attention_layers = nn.ModuleDict()# 在指定位置添加注意力層if 3 in attention_positions:self.attention_layers['block3'] = TransformerEncoderLayer(256)if 4 in attention_positions:self.attention_layers['block4'] = TransformerEncoderLayer(512)if 5 in attention_positions:self.attention_layers['block5'] = TransformerEncoderLayer(512)self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def _apply_attention(self, x, block_name):"""應用自注意力機制"""batch_size, channels, height, width = x.size()# 將特征圖重塑為序列形式 [batch_size, seq_len, embed_dim]x_reshaped = x.view(batch_size, channels, -1).transpose(1, 2)# 應用注意力attended = self.attention_layers[block_name](x_reshaped)# 恢復原始形狀attended = attended.transpose(1, 2).view(batch_size, channels, height, width)return attendeddef forward(self, x):features = []# 逐層處理特征for i, layer in enumerate(self.features):x = layer(x)# 在特定卷積塊后應用注意力if i == 14 and 3 in self.attention_positions: # 第三卷積塊結束x = self._apply_attention(x, 'block3')elif i == 21 and 4 in self.attention_positions: # 第四卷積塊結束x = self._apply_attention(x, 'block4')elif i == 28 and 5 in self.attention_positions: # 第五卷積塊結束x = self._apply_attention(x, 'block5')x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x# 創建帶注意力的VGG模型
def vgg16_with_attention(num_classes=1000, attention_positions=[3, 4]):model = VGG16WithAttention(num_classes=num_classes, attention_positions=attention_positions)return model# 示例使用
if __name__ == "__main__":model = vgg16_with_attention(num_classes=1000, attention_positions=[3, 4, 5])# 測試前向傳播dummy_input = torch.randn(2, 3, 224, 224)output = model(dummy_input)print(f"Output shape: {output.shape}")print(f"Model has {sum(p.numel() for p in model.parameters()):,} parameters")-- Symbol與集合數據結構)















)


)