目錄
散點圖1
散點圖2
添加線性回歸線的散點圖
自定義點形狀的散點圖
不同樣式的散點圖
抖動散點圖
邊際圖
邊緣為直方圖的邊際圖
邊緣為箱線圖的邊際圖
曼哈頓圖


?【聲明】:未經版權人書面許可,任何單位或個人不得以任何形式復制、發行、出租、改編、匯編、傳播、展示或利用本博客的全部或部分內容,也不得在未經版權人授權的情況下將本博客用于任何商業目的。但版權人允許個人學習、研究、欣賞等非商業性用途的復制和傳播。非常推薦大家學習《Python數據可視化科技圖表繪制》這本書籍。
散點圖1
import seaborn as sns # 導入seaborn庫并簡寫為sns
import matplotlib.pyplot as plt
df = sns.load_dataset('iris',data_home='seaborn',cache=True) # 加載 iris 數據集
# 繪制散點圖
sns.regplot(x=df["sepal_length"], y=df["sepal_width"])
# 繪制散點圖(默認進行線性擬合),如圖所示sns.regplot(x=df["sepal_length"], y=df["sepal_width"], fit_reg=False)# 保存圖片
plt.savefig("P142散點圖1.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()
散點圖2
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltmidwest = pd.read_csv(r'E:\PythonProjects\experiments_figures\繪圖案例數據\midwest_filter.csv') # 導入數據集
categories = np.unique(midwest['category']) # 獲取數據集中的唯一類別
# 生成與唯一類別數量相同的顏色
# 使用 matplotlib 的顏色映射函數來生成顏色
colors = [plt.cm.tab10(i / float(len(categories) - 1)) for i inrange(len(categories))]# 繪制每個類別的圖形
# 設置圖形的大小、分辨率和背景色
plt.figure(figsize=(10, 6), dpi=600, facecolor='w', edgecolor='k')# 遍歷每個類別,并使用 scatter 函數繪制散點圖
for i, category in enumerate(categories):# 使用 loc 方法篩選出特定類別的數據,并繪制散點圖plt.scatter('area', 'poptotal',data=midwest.loc[midwest.category == category, :],s=20, color=colors[i], label=str(category)) # 使用 color 參數# 圖形修飾
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),xlabel='Area', ylabel='Population') # 設置 x 軸和 y 軸的范圍、標簽# 設置 x 軸和 y 軸的刻度字體大小
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)plt.title("Scatterplot ", fontsize=22) # 設置圖形標題
plt.legend(fontsize=12) # 添加圖例# 保存圖片
plt.savefig("P143散點圖2.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()
添加線性回歸線的散點圖
import pandas as pd # 導入pandas庫并簡寫為pd
import matplotlib.pyplot as plt # 導入matplotlib.pyplot模塊并簡寫為plt
import seaborn as sns # 導入seaborn庫并簡寫為snsdf = sns.load_dataset('iris') # 加載iris數據集
# 繪制散點圖,并添加紅色線性回歸線
fig, ax = plt.subplots(figsize=(8, 6)) # 創建圖形和子圖對象,并設置圖形大小
sns.regplot(x=df["sepal_length"], y=df["sepal_width"],# 繪制散點圖,指定橫縱軸數據line_kws={"color": "r"}, ax=ax) # 設置線性回歸線顏色為紅色
# 保存圖片
plt.savefig("P144添加線性回歸線的散點圖_添加紅色線性回歸線.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()# 繪制散點圖,并添加半透明的紅色線性回歸線
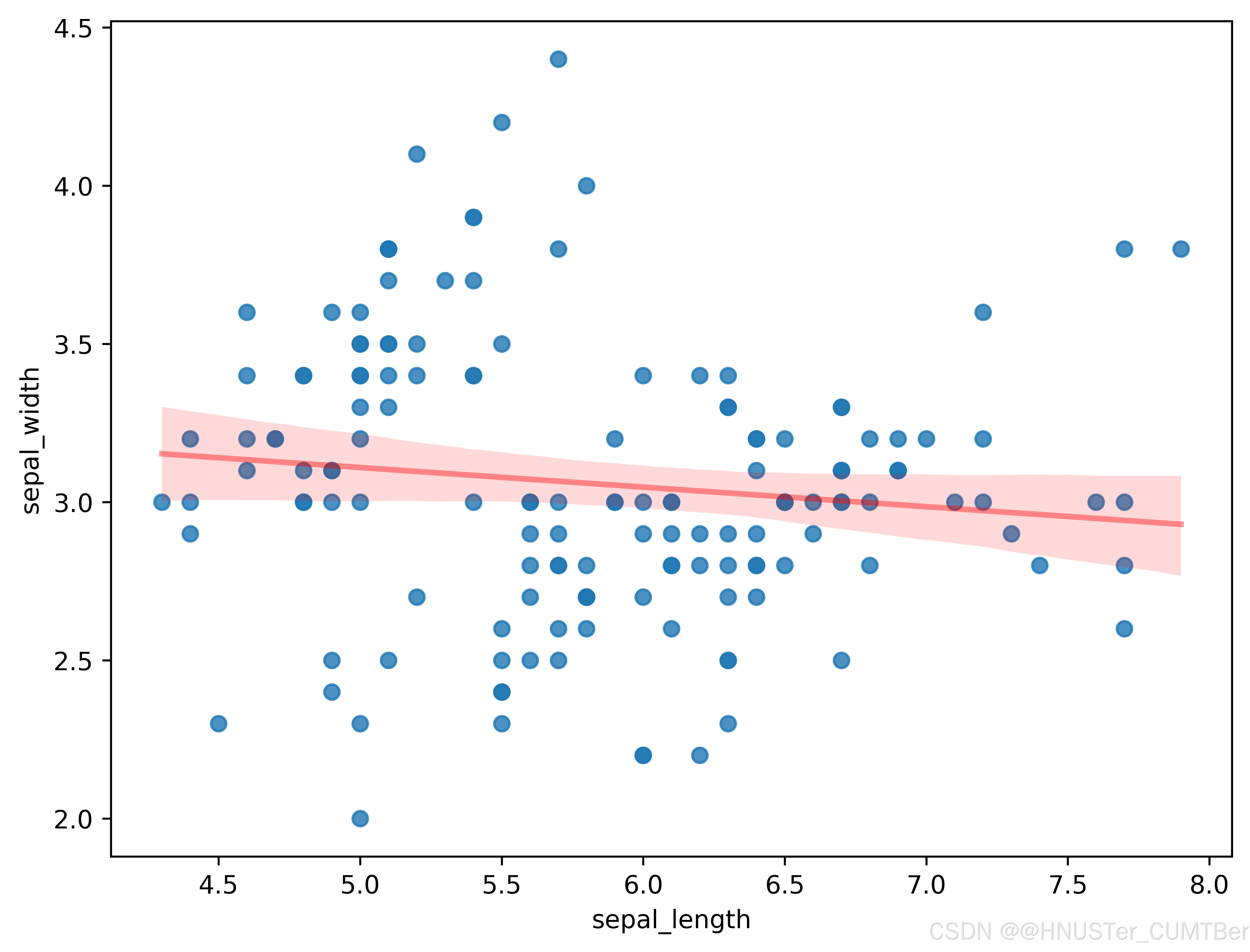
fig, ax = plt.subplots(figsize=(8, 6)) # 創建圖形和子圖對象,并設置圖形大小
sns.regplot(x=df["sepal_length"], y=df["sepal_width"],# 繪制散點圖,指定橫縱軸數據line_kws={"color": "r", "alpha": 0.4}, ax=ax)
# 設置線性回歸線顏色為紅色,透明度為0.4
# 保存圖片
plt.savefig("P144添加線性回歸線的散點圖_添加半透明的紅色線性回歸線.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()# 繪制散點圖,并自定義線性回歸線的線寬、線型和顏色
fig, ax = plt.subplots(figsize=(8, 6)) # 創建圖形和子圖對象,并設置圖形大小
sns.regplot(x=df["sepal_length"], y=df["sepal_width"],# 繪制散點圖,指定橫縱軸數據line_kws={"color": "r", "alpha": 0.4, "lw": 5, "ls": "--"}, ax=ax)
# 設置線性回歸線的顏色、透明度、線寬和線型
# 保存圖片
plt.savefig("P144添加線性回歸線的散點圖_自定義線性回歸線的線寬、線型和顏色.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()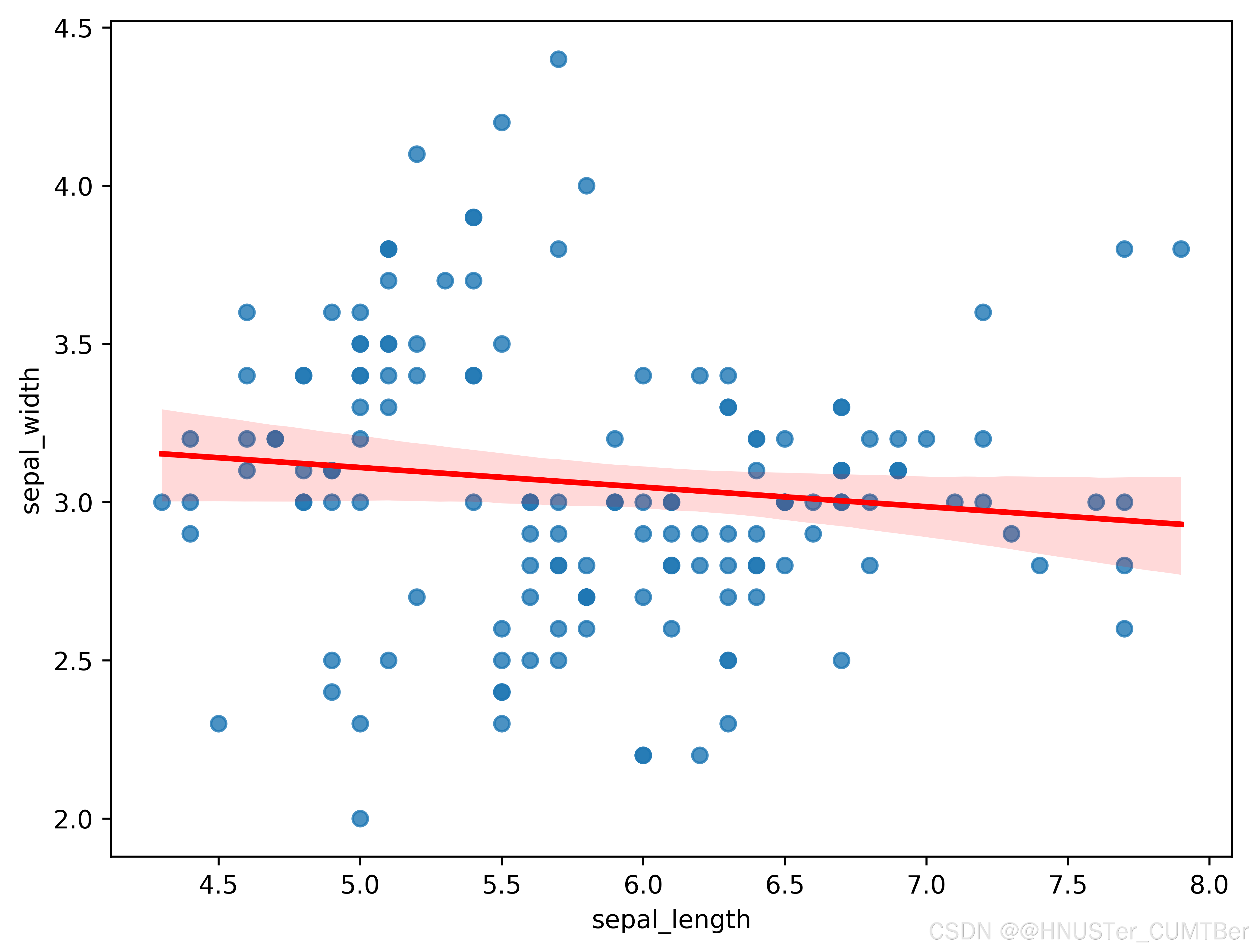

自定義點形狀的散點圖
import pandas as pd # 導入pandas庫并簡寫為pd
import matplotlib.pyplot as plt # 導入matplotlib.pyplot模塊并簡寫為plt
import seaborn as sns # 導入seaborn庫并簡寫為snsdf = sns.load_dataset('iris') # 加載iris數據集
fig, ax = plt.subplots(figsize=(8, 6)) # 創建圖形和子圖對象,并設置圖形大小
# 繪制散點圖,不添加回歸線,標記形狀為"+"
sns.regplot(x=df["sepal_length"], y=df["sepal_width"],marker="+", fit_reg=False, ax=ax)# 保存圖片
plt.savefig("P146使用標記形狀“+”.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()fig, ax = plt.subplots(figsize=(8, 6)) # 創建圖形和子圖對象,并設置圖形大小
# 繪制散點圖,不添加回歸線,設置散點標記顏色為暗紅色,透明度為0.3,標記大小為200
sns.regplot(x=df["sepal_length"], y=df["sepal_width"], fit_reg=False,scatter_kws={"color": "darkred", "alpha": 0.3, "s": 200}, ax=ax)# 保存圖片
plt.savefig("P146定義顏色、透明度和大小.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()

不同樣式的散點圖
import seaborn as sns # 導入seaborn庫
import matplotlib.pyplot as plt # 導入matplotlib.pyplot庫df = sns.load_dataset('iris') # 加載iris數據集
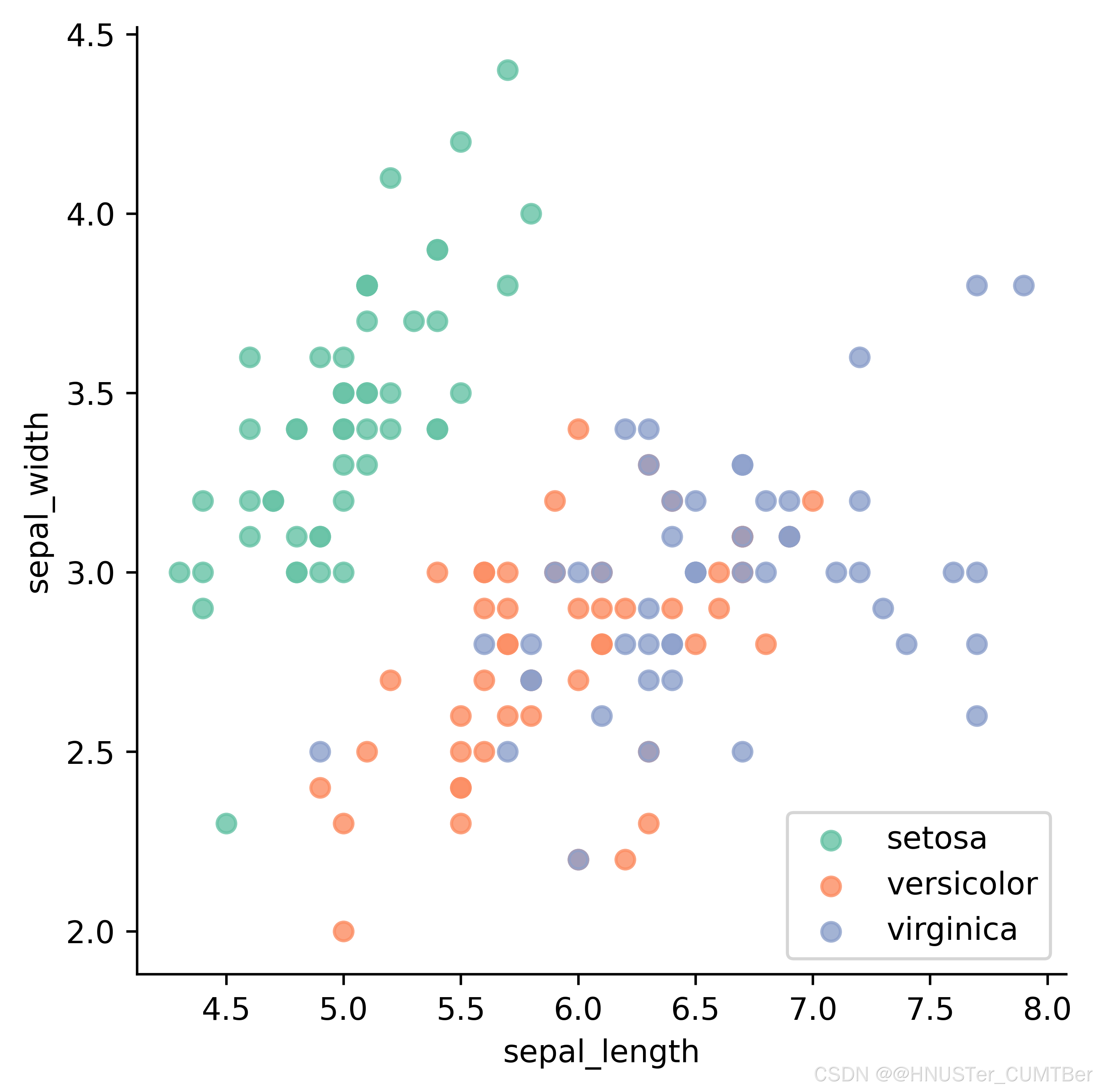
# 使用'hue'參數提供一個因子變量,并繪制散點圖
sns.lmplot(x="sepal_length", y="sepal_width",data=df, fit_reg=False, hue='species', legend=False)
# 將圖例移動到圖形中的一個空白部分
plt.legend(loc='lower right')
# 保存圖片
plt.savefig("P147散點圖_著色不同的數據子集.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()# 繪制散點圖,并指定每個數據子集的標記形狀
sns.lmplot(x="sepal_length", y="sepal_width", data=df,fit_reg=False, hue='species', legend=False, markers=["o", "x", "1"])
# 將圖例移動到圖形中的一個空白部分
plt.legend(loc='lower right')
# 保存圖片
plt.savefig("P147散點圖_指定標記形狀.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()# 使用調色板來著色不同的數據子集
sns.lmplot(x="sepal_length", y="sepal_width",data=df, fit_reg=False, hue='species',legend=False, palette="Set2")
# 將圖例移動到圖形中的一個空白部分
plt.legend(loc='lower right')
# 保存圖片
plt.savefig("P147散點圖_使用了調色板.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()# 控制每個數據子集的顏色
sns.lmplot(x="sepal_length", y="sepal_width",data=df, fit_reg=False, hue='species', legend=False,palette=dict(setosa="blue", virginica="red",versicolor="green"))
# 將圖例移動到圖形中的一個空白部分
plt.legend(loc='lower right')
# 保存圖片
plt.savefig("P147散點圖_自定義的調色板.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()


抖動散點圖
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as pltdf = pd.read_csv(r"E:\PythonProjects\experiments_figures\繪圖案例數據\mpg_ggplot2.csv") # 導入數據# 繪制Stripplot
fig, ax = plt.subplots(figsize=(12, 6), dpi=80)
sns.stripplot(x='cty', y='hwy', hue='class', data=df, jitter=0.25, size=6,ax=ax, linewidth=.5)
# 修飾
plt.title('Use jittered plots to avoid overlapping of points', fontsize=22)
# 保存圖片
plt.savefig("P149抖動散點圖.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()
邊際圖
import seaborn as sns # 導入Seaborn庫并簡寫為sns
import matplotlib.pyplot as plt # 導入Matplotlib.pyplot庫并簡寫為pltdf = sns.load_dataset('iris') # 從Seaborn中加載iris數據集# 創建帶有散點圖的邊際圖
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='scatter')
plt.savefig("P150邊際圖1.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 創建帶有六邊形圖的邊際圖
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='hex')
plt.savefig("P150邊際圖2.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 創建帶有核密度估計圖的邊際圖
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='kde')
plt.savefig("P150邊際圖3.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 自定義聯合圖中的散點圖
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"],kind='scatter', s=200, color='m',edgecolor="skyblue", linewidth=2)
plt.savefig("P150邊際圖4.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 自定義顏色
sns.set_theme(style="white", color_codes=True)
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='kde',color="skyblue")
plt.savefig("P150邊際圖5.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 自定義直方圖
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='hex',marginal_kws=dict(bins=30, fill=True))
plt.savefig("P150邊際圖6.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 無間隔
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='kde',color="blue", space=0)
plt.savefig("P150邊際圖7.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 大間隔
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='kde',color="blue", space=3)
plt.savefig("P150邊際圖8.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖# 調整邊際圖比例
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"],kind='kde', ratio=2)
plt.savefig("P150邊際圖9.png", dpi=600, bbox_inches='tight', transparent=True)
plt.close() # 關閉當前圖,避免影響后續繪圖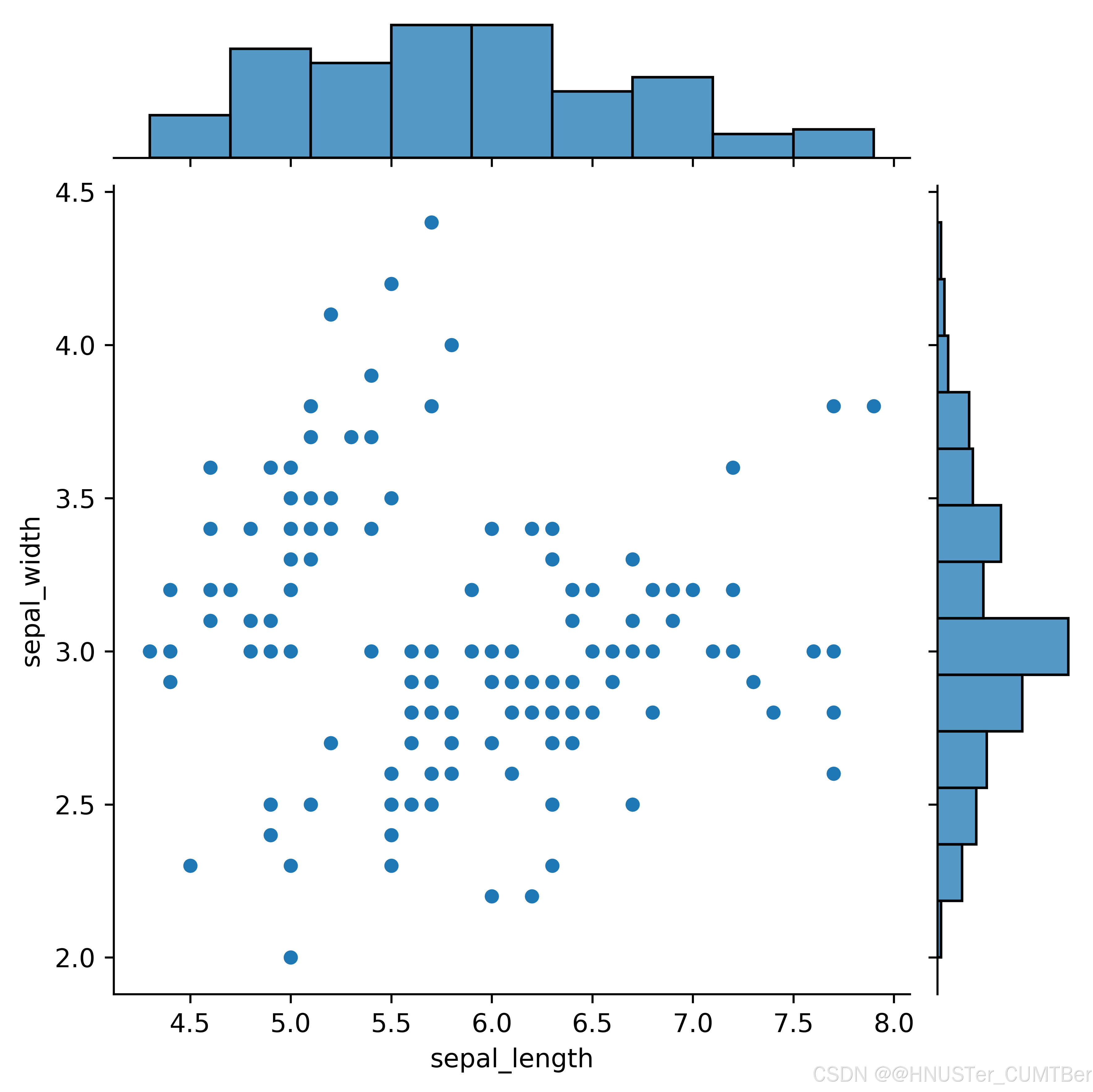


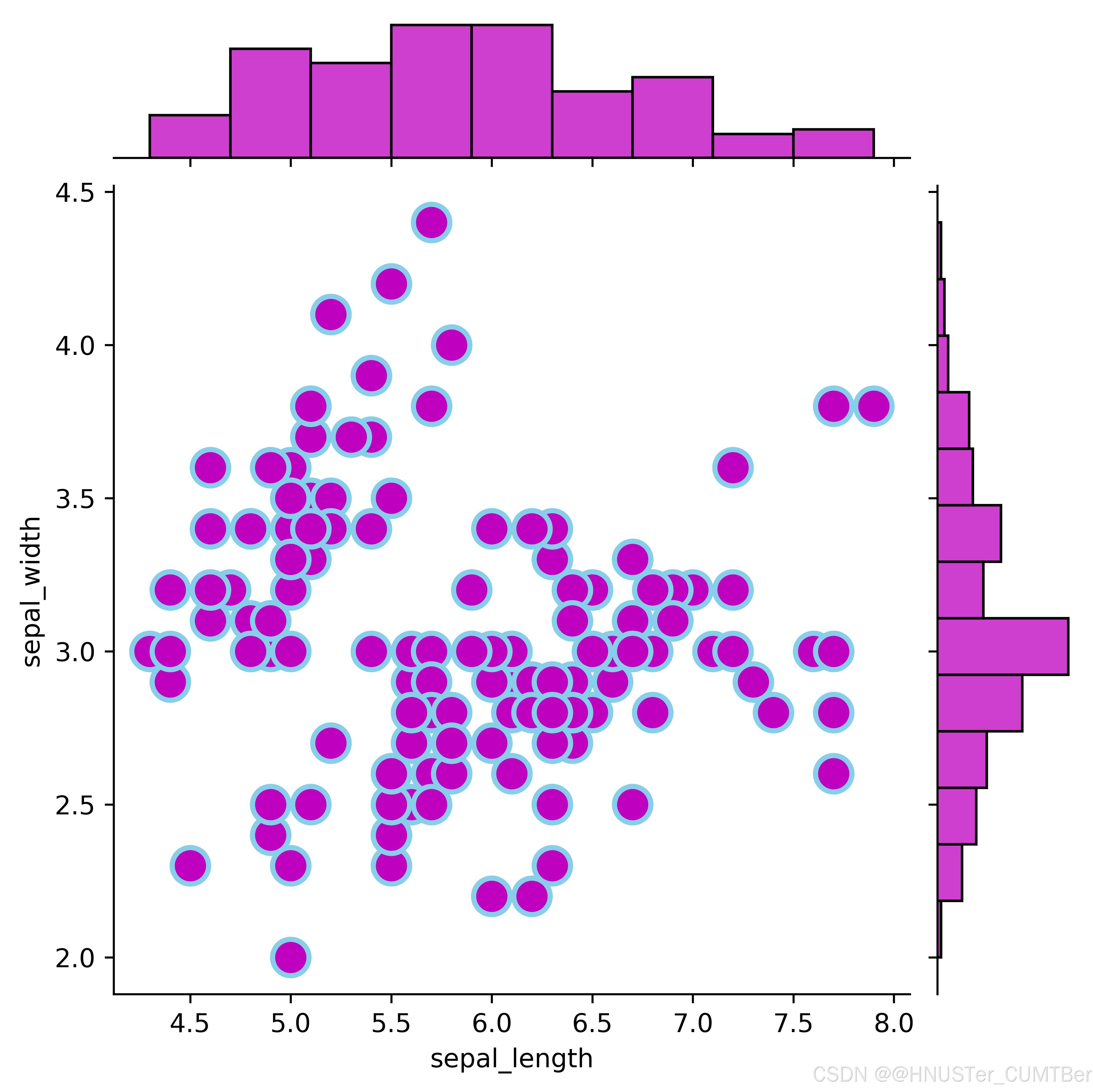



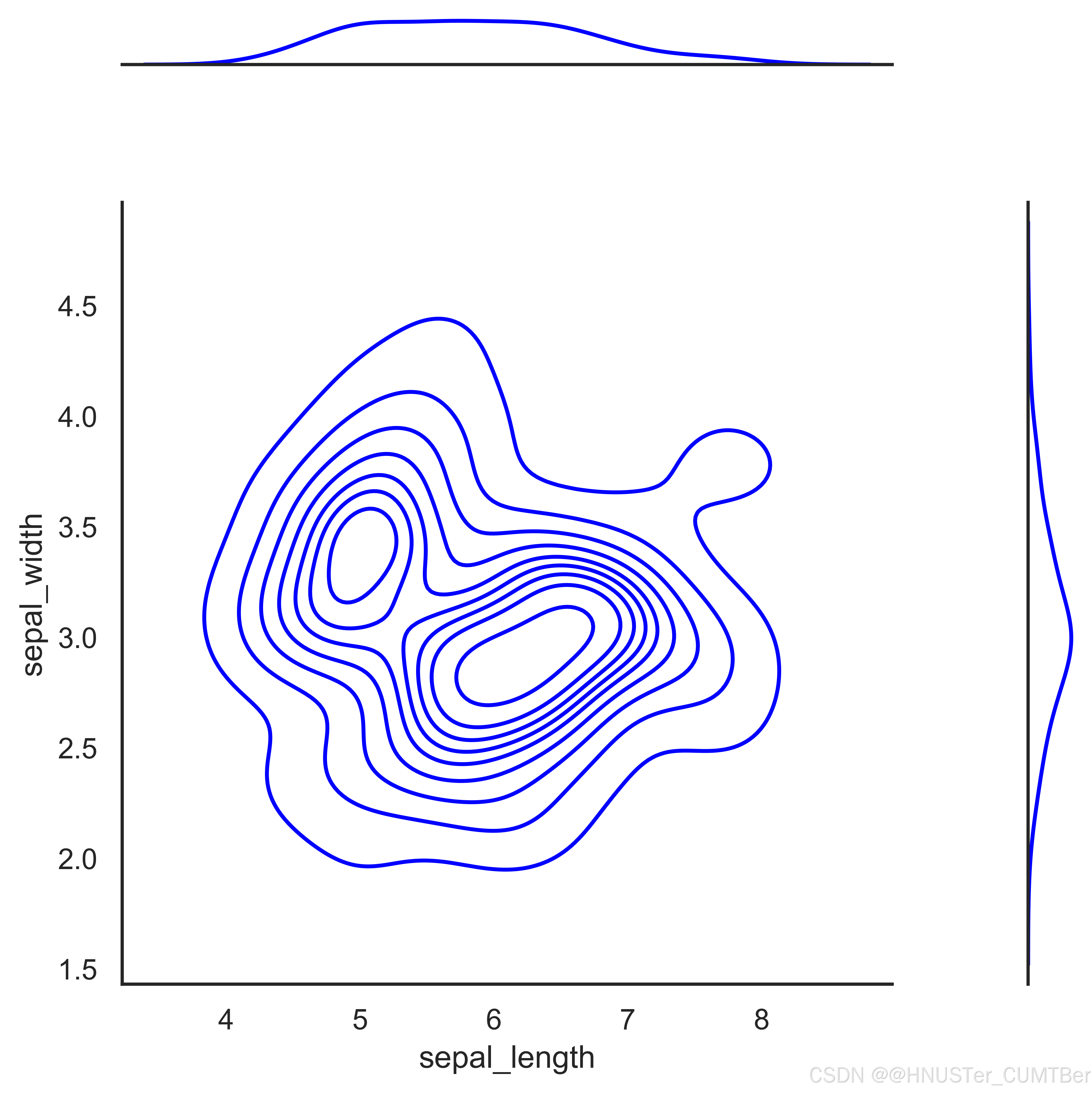

邊緣為直方圖的邊際圖
import pandas as pd
import matplotlib.pyplot as pltdf = pd.read_csv(r"E:\PythonProjects\experiments_figures\繪圖案例數據\mpg_ggplot2.csv") # 導入數據# 創建圖形和網格布局
fig = plt.figure(figsize=(12, 8), dpi=80)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)# 定義坐標軸
ax_main = fig.add_subplot(grid[:-1, :-1])
ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])# 主圖上的散點圖
ax_main.scatter('displ', 'hwy', s=df.cty * 4,c=df.manufacturer.astype('category').cat.codes,alpha=.9, data=df, cmap="tab10", edgecolors='gray', linewidths=.5)# 右側的直方圖
ax_bottom.hist(df.displ, 40, histtype='stepfilled', orientation='vertical',color='blue', alpha=0.8)
ax_bottom.invert_yaxis()# 底部的直方圖
ax_right.hist(df.hwy, 40, histtype='stepfilled', orientation='horizontal',color='blue', alpha=0.8)# 圖形修飾
ax_main.set(title='Scatterplot with Histograms \n displ vs hwy',xlabel='displ', ylabel='hwy')
ax_main.title.set_fontsize(20)
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] +ax_main.get_xticklabels() + ax_main.get_yticklabels()):item.set_fontsize(14)# 獲取當前的刻度位置并設置
xlabels = ax_main.get_xticks().tolist()
ax_main.set_xticks(xlabels)
ax_main.set_xticklabels(xlabels)# 保存圖片
plt.savefig("P152邊緣為直方圖的邊際圖.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()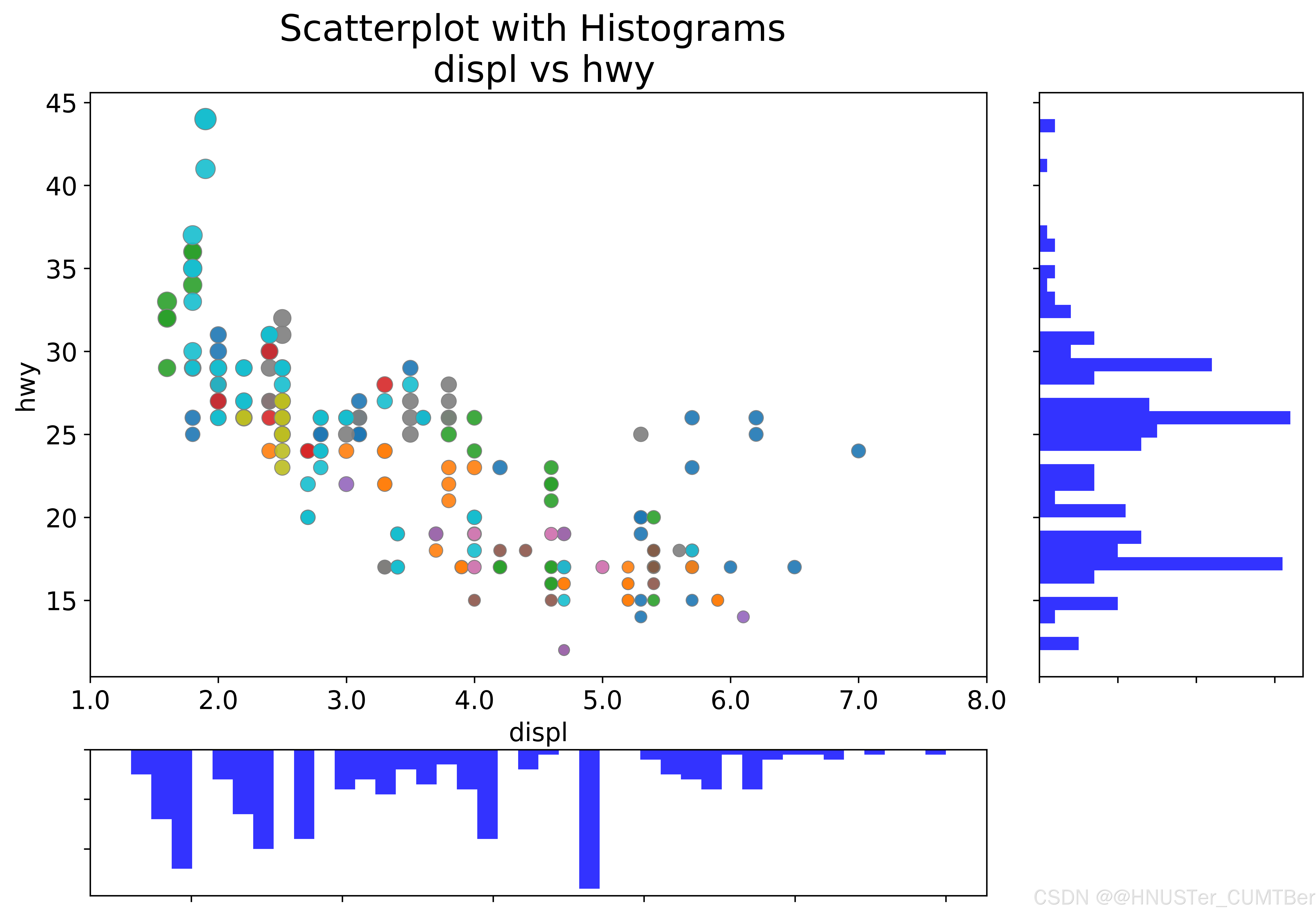
邊緣為箱線圖的邊際圖
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as pltdf = pd.read_csv(r"E:\PythonProjects\experiments_figures\繪圖案例數據\mpg_ggplot2.csv") # 導入數據# 創建圖形和網格布局
fig = plt.figure(figsize=(12, 8), dpi=80)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)# 定義坐標軸
ax_main = fig.add_subplot(grid[:-1, :-1]) # 主圖的位置
ax_right = fig.add_subplot(grid[:-1, -1],xticklabels=[], yticklabels=[]) # 右側箱線圖的位置
ax_bottom = fig.add_subplot(grid[-1, 0:-1],xticklabels=[], yticklabels=[]) # 底部箱線圖的位置# 主圖上的散點圖
ax_main.scatter('displ', 'hwy', s=df.cty * 5,c=df.manufacturer.astype('category').cat.codes, # 根據制造商進行著色alpha=.8, data=df, cmap="Set1", edgecolors='black', linewidths=.5)
sns.boxplot(df.hwy, ax=ax_right, orient="v") # 在右側添加箱線圖
sns.boxplot(df.displ, ax=ax_bottom, orient="h") # 在底部添加箱線圖# 圖形修飾
ax_bottom.set(xlabel='') # 移除箱線圖的x軸名稱
ax_right.set(ylabel='') # 移除箱線圖的y軸名稱# 主標題、X軸和Y軸標簽
ax_main.set(title='Scatterplot with Histograms \n displ vs hwy',xlabel='displ', ylabel='hwy')# 設置字體大小
ax_main.title.set_fontsize(20) # 設置主標題的字體大小
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] +ax_main.get_xticklabels() + ax_main.get_yticklabels()):item.set_fontsize(14) # 設置其他組件的字體大小# 保存圖片
plt.savefig("P154邊緣為箱線圖的邊際圖.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()
曼哈頓圖
from pandas import DataFrame # 導入DataFrame模塊
from scipy.stats import uniform # 從scipy.stats模塊導入uniform分布
from scipy.stats import randint # 從scipy.stats模塊導入randint分布
import numpy as np # 導入numpy庫,并簡稱為np
import matplotlib.pyplot as plt # 導入matplotlib.pyplot模塊,并簡稱為plt# 生成樣本數據
df = DataFrame({'gene': ['gene-%i' % i for i in np.arange(10000)],# 創建基因名字的序列'pvalue': uniform.rvs(size=10000), # 生成服從均勻分布的p值數據'chromosome': ['ch-%i' % i for i in randint.rvs(0, 12, size=10000)]})
# 生成隨機的染色體編號# 計算-log10(pvalue)
df['minuslog10pvalue'] = -np.log10(df.pvalue)
# 計算-p值的負對數,用于曼哈頓圖的縱軸
df.chromosome = df.chromosome.astype('category') # 將染色體列轉換為分類類型
df.chromosome = df.chromosome.cat.set_categories(['ch-%i' % i for i in range(12)], ordered=True) # 對染色體進行排序
df = df.sort_values('chromosome') # 根據染色體排序# 準備繪制曼哈頓圖
df['ind'] = range(len(df)) # 為數據集添加索引列
df_grouped = df.groupby(('chromosome'), observed=False) # 按染色體分組# 繪制曼哈頓圖
fig = plt.figure(figsize=(14, 8)) # 設置圖形大小
ax = fig.add_subplot(111) # 添加子圖
colors = ['darkred', 'darkgreen', 'darkblue', 'gold'] # 定義顏色列表
x_labels = [] # 初始化x軸標簽列表
x_labels_pos = [] # 初始化x軸標簽位置列表
for num, (name, group) in enumerate(df_grouped): # 遍歷分組后的數據group.plot(kind='scatter', x='ind', y='minuslog10pvalue',color=colors[num % len(colors)], ax=ax) # 繪制散點圖,并按染色體著色x_labels.append(name) # 添加染色體名到標簽列表x_labels_pos.append((group['ind'].iloc[-1] -(group['ind'].iloc[-1] - group['ind'].iloc[0]) / 2)) # 添加染色體標簽的位置
ax.set_xticks(x_labels_pos) # 設置x軸刻度位置
ax.set_xticklabels(x_labels) # 設置x軸刻度標簽ax.set_xlim([0, len(df)]) # 設置x軸范圍
ax.set_ylim([0, 3.5]) # 設置y軸范圍
ax.set_xlabel('Chromosome') # 設置x軸標簽# 保存圖片
plt.savefig("P159曼哈頓圖.png", dpi=600, bbox_inches='tight', transparent=True)
plt.show()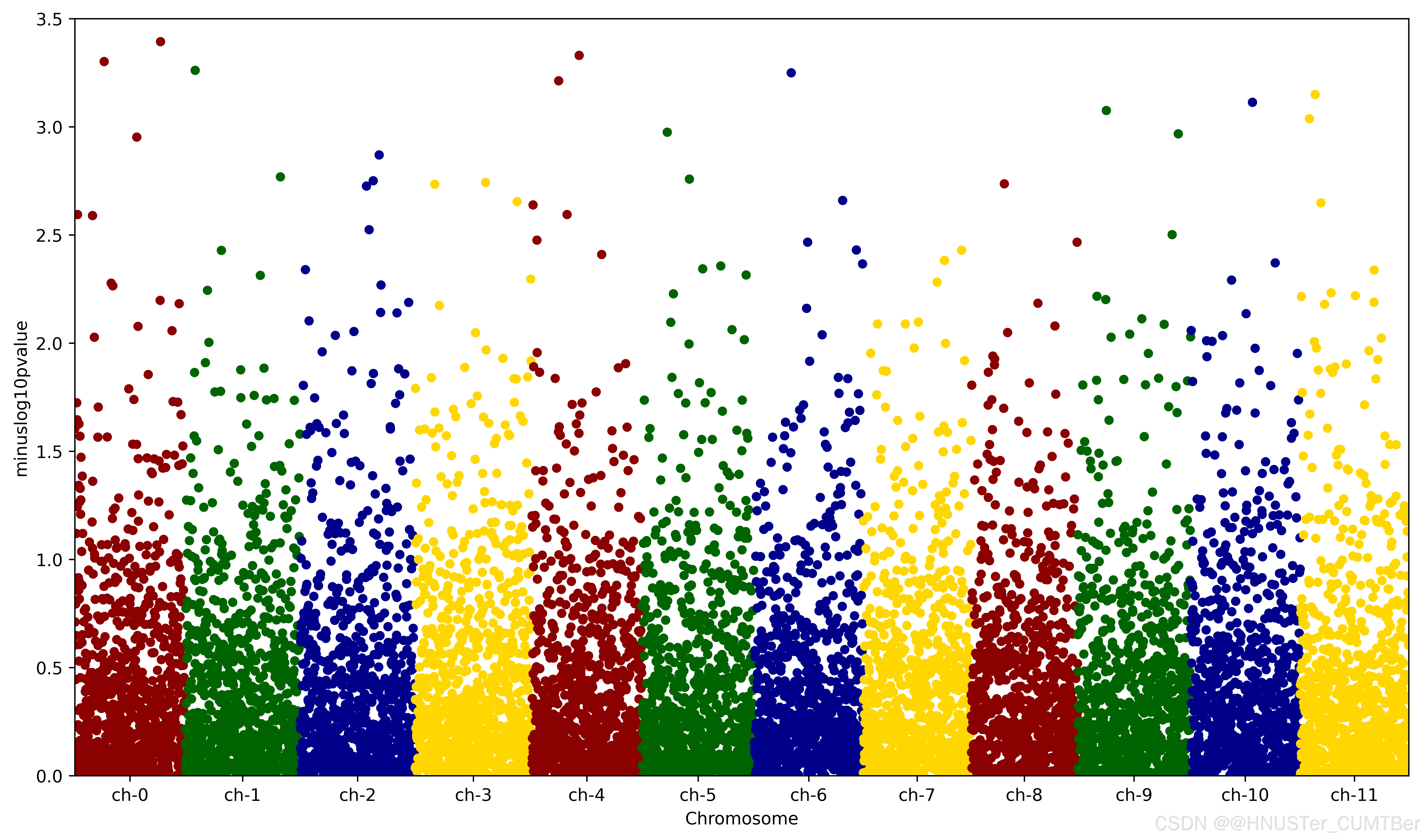




)














