文章目錄
- 摘要
- 1. 引言
- 2. 相關工作
- 2.1 自動駕駛中的語言模型
- 2.2 自動駕駛中的視覺問答
- 3. 方法
- 3.1 數據生成流水線
- 3.2 兩階段訓練流程
- 3.2.1 基于 SFT 的推理預熱
- 3.2.2 基于 RLFT 的推理增強
- 3.3 推理與評估
- 4. 實驗
- 4.1 主要實驗結果
- 4.2 工具使用分析
- 4.3 消融實驗
- 4.4 泛化性評估
- 5. 結論
- 局限性
- 倫理聲明
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
1 清華大學 2 麥吉爾大學 3 小米公司 4 威斯康星大學麥迪遜分校
arxiv’25’05
這篇論文的創新點是 首次將動態的工具調用與鏈式推理統一到自動駕駛視覺語言模型中,通過結構化數據(構建微調數據)、兩階段訓練(SFT+GRPO)和專門的工具使用評估顯著提升了推理一致性、可解釋性和決策準確性。
摘要
視覺-語言模型(Vision-Language Models,VLMs)在自動駕駛中展現出潛力,但其在幻覺(hallucinations)、低效推理以及有限的真實場景驗證方面的困境,阻礙了其實現準確感知與穩健的逐步推理。為了解決這一問題,我們提出 AgentThink,這是首個將鏈式思維(Chain-of-Thought, CoT)推理與動態的、類代理(agent-style)工具調用相結合的統一框架,專為自動駕駛任務設計。AgentThink 的核心創新包括:
(i) 結構化數據生成,通過建立自動駕駛工具庫,自動構建結構化、可自驗證的推理數據,顯式地將工具使用融入到多樣化的駕駛場景中;
(ii) 兩階段訓練流程,采用監督微調(Supervised Fine-Tuning, SFT)結合群組相對策略優化(Group Relative Policy Optimization, GRPO),賦予 VLMs 自動工具調用的能力;
(iii) 類代理的工具使用評估,提出一種新穎的多工具評估協議,用于嚴格評估模型的工具調用與使用情況。
在 DriveLMM-o1 基準上的實驗表明,AgentThink 將整體推理得分顯著提升了 53.91%,答案準確率提高了 33.54%,同時大幅改善了推理質量和一致性。此外,消融實驗與跨多個基準的零樣本/少樣本泛化實驗進一步驗證了其強大能力。這些結果表明,發展值得信賴、具備工具感知能力的自動駕駛模型具有廣闊前景。
250904:整體推理得分從 51.77 提升到 79.68(+53.91%)明顯寫錯了,應該是+27.91
1. 引言
“君子性非異也,善假于物也。” —— 荀子
近年來,基礎模型的進步為自動駕駛開辟了新的機遇,預訓練的大型語言模型(Large Language Models, LLMs)[2, 10] 和視覺-語言模型(Vision-Language Models, VLMs)[28, 35, 47] 越來越多地被用于實現高層次的場景理解、常識推理和決策。這些模型旨在超越傳統的感知管線——后者依賴于手工設計的組件,如目標檢測 [20, 32]、運動預測 [29, 40] 和基于規則的規劃 [5]——通過提供更豐富的語義表征和更廣泛的泛化能力,并以互聯網規模的知識為基礎。
許多最新的方法將自動駕駛任務重新表述為視覺問答(Visual Question Answering, VQA)問題,利用監督微調(Supervised Fine-Tuning, SFT)在基礎 VLMs 上結合特定任務提示,用于目標識別、風險預測或運動規劃 [8, 25, 33, 36, 44]。然而,如圖 2(a) 所示,這些模型通常將推理視為靜態的輸入-輸出映射,忽略了真實世界決策所必需的不確定性、復雜性和可驗證性。因此,它們往往表現出較差的泛化能力、幻覺式輸出以及有限的可解釋性 [42]。

為了提升魯棒性和透明性,近期研究探索了將鏈式思維(Chain-of-Thought, CoT)推理引入 VLMs,如圖 2(b) 所示。一些方法采用固定的 CoT 模板 [14, 35],在促進結構化邏輯的同時犧牲了靈活性。另一些方法使用開放式推理格式 [15, 26],但可能過度擬合于符號模式,表現出淺層或冗余的推理。此外,大多數現有方法僅依賴于來自人工構建軌跡的模仿學習,缺乏檢測知識不確定性或調用工具進行中間驗證的能力 [46]。
這些挑戰引出了一個關鍵問題:VLM 是否能夠真正作為一個決策代理發揮作用——意識到其知識邊界,具備驗證能力,并能夠從工具引導的反饋中學習? 靈感來自有經驗的人類駕駛員,他們在不確定時會借助后視鏡或 GPS 來修正判斷。同樣,一個有能力的自動駕駛代理不僅需要進行顯式推理,還必須識別其局限性,并能夠動態調用工具,如目標檢測器或運動預測器,以引導其推理和決策過程。
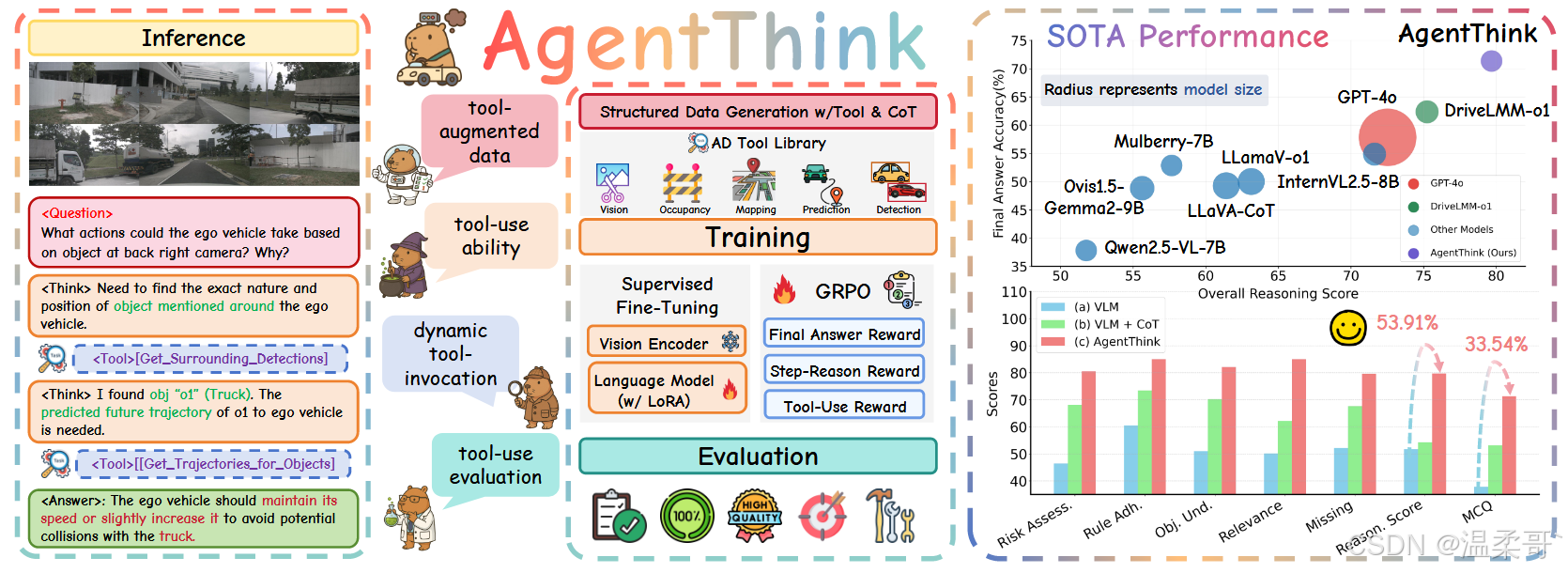
因此,我們提出 AgentThink,這是一個面向自動駕駛 VLMs 的統一框架,其建模推理的方式不再是靜態輸出,而是作為一種 類代理(agent-style)的過程——模型在其中學會利用工具生成工具增強(Tool-Augmented)的推理鏈,驗證中間步驟,并不斷優化結論。如圖 2(c) 所示,AgentThink 不再盲目地將輸入映射為輸出,而是動態決定在推理過程中何時以及如何使用工具,以支持或修正推理路徑。為實現這一行為,我們構建了一個數據-訓練-評估流水線。首先,我們構建了一個包含工具增強推理軌跡的結構化數據集。隨后,我們引入兩階段訓練流程:(i) 使用 SFT 對推理能力進行預熱;(ii) 采用 GRPO [31],一種基于強化學習(RL)的策略,通過結構化獎勵優化推理深度和工具使用行為。最后,我們提出一個超越答案正確性的綜合評估協議,用于評估工具選擇、集成質量以及推理-工具對齊。
如圖 1 所示,在先進的 DriveLMM-o1 基準 [15] 上的實驗表明,AgentThink 在答案準確率和推理得分方面都達到了新的最先進性能,超越了現有模型。我們方法在培養動態、具備工具感知的推理方面的有效性,還通過全面的消融研究和跨多個基準的穩健泛化能力得到了進一步驗證。這些結果強有力地表明,使視覺-語言代理具備學習到的、動態調用的工具使用能力,是構建更加魯棒、可解釋和可泛化的自動駕駛系統的關鍵。

總體而言,我們的貢獻如下:
- 我們提出了 AgentThink,這是首個將動態的、類代理的工具調用(agent-style tool invocation) 引入到自動駕駛任務的視覺-語言推理中的框架。
- 我們開發了一條可擴展的數據生成流水線,能夠產生 結構化、自驗證的數據,其中顯式地集成了工具使用和推理鏈。
- 我們引入了一個兩階段訓練流程,將 SFT 與 GRPO 相結合,使模型能夠學習在何時以及如何調用工具以增強推理性能。
- 我們設計了新的評估指標,專門針對 自動駕駛工具調用,以衡量工具選擇、集成質量和推理-工具對齊情況。
2. 相關工作
2.1 自動駕駛中的語言模型
語言建模的最新進展為自動駕駛開辟了新的機遇,尤其是在支持可解釋推理、常識理解和決策制定方面 [6]。早期的嘗試整合了 LLMs(如 GPT 系列 [27]),通過將駕駛任務(例如場景描述 [23, 44]、決策制定 [9, 41] 和風險預測 [3, 22])重新表述為文本提示,從而支持零樣本或小樣本推理。盡管這些方法展示了 LLMs 的推理潛力,但它們往往缺乏逐步的可解釋性,并且在分布外場景中的泛化能力較弱 [39]。
近期的研究通過提示策略、基于記憶的上下文構建或視覺輸入擴展了 LLMs [12]。例如,DriveVLM [28, 35] 引入了一種 CoT 方法和雙系統,包含用于場景描述、分析和分層規劃的模塊;而 DriveLM [33] 則聚焦于圖結構的視覺問答。EMMA [13] 展示了多模態模型如何直接將原始攝像頭輸入映射為駕駛輸出,包括軌跡和感知目標。盡管有這些進展,基于 LLM 和 VLM 的方法通常仍將推理視為靜態的輸入-輸出映射,缺乏檢測不確定性、執行中間驗證或引入物理約束的能力 [15]。其挑戰包括幻覺、過度依賴固定模板以及缺乏特定領域獎勵反饋。為解決這些局限性,我們的工作引入了一種工具增強的、基于 RL 的推理框架,使動態且可驗證的決策在自動駕駛中成為可能。
2.2 自動駕駛中的視覺問答
視覺問答(Visual Question Answering, VQA)已成為評估自動駕駛感知、預測和規劃能力的重要范式。BDD-X [18]、DriveBench [42]、DriveMLLM [11]、Nuscenes-QA [30] 和 DriveLMM-o1 [15] 等基準提供了結構化的 QA 任務,涵蓋了城市與高速場景中的復雜推理。針對 VQA 任務,近期方法如 Reason2Drive [26]、Alphadrive [17]、OmniDrive [37] 和 DriveCoT [38] 都引入了 CoT 推理,以提升模型的可解釋性。
然而,許多方法采用僵化的推理模板或僅依賴模仿學習,使其容易出現過擬合和幻覺。這些方法往往忽視動態推理過程,并未利用外部工具驗證中間步驟。相比之下,我們的框架結合了結構化數據生成、逐步獎勵和推理過程中的工具驗證。通過在推理中引入基于 RL 的 GRPO,我們優化了模型的推理軌跡,使其在正確性、效率和真實應用性上保持一致性,為自動駕駛 VQA 開辟了一條新的方向。
3. 方法
圖 3 展示了 AgentThink 的三個關鍵組成部分:(i) 一個可擴展的流水線,用于生成結構化的、工具增強的推理數據;(ii) 一個兩階段訓練流程,結合 SFT 與 GRPO 以提升推理和工具使用能力;(iii) 一種新的評估方法,重點在于評估模型對工具的有效利用及其對推理的影響。

3.1 數據生成流水線
盡管已有研究 [26, 36] 探索了 VLMs 中的推理,但持續存在的幻覺問題仍是挑戰。我們認為,可靠的自動駕駛推理(類似于人類決策)不僅需要內部知識,還需要在必要時調用外部工具的能力。為此,我們引入了一個工具增強的數據生成流水線。不同于僅關注推理步驟和最終答案的現有數據集 [15, 39],我們的流水線獨特地將顯式的工具使用融入推理過程。
工具庫。 我們開發了一個專門的工具庫,靈感來自 Agent-Driver [24],其中包含五個面向駕駛的核心模塊——視覺信息(visual info)、檢測(detection)、預測(prediction)、占據(occupancy)和地圖(mapping)——以及單視角視覺工具(開放詞匯檢測、深度、裁剪、縮放)。這還結合了基礎的單視角視覺工具,如開放詞匯目標檢測器和深度估計器。它們共同支持對環境信息的全面提取,以服務于多樣的感知與預測任務。具體細節見附錄 A.1。
提示設計。 初始的工具集成推理步驟和答案由 GPT-4o 自動生成,受提示模板(如圖 3 所示)引導,該模板旨在引出針對任務指令 L\mathcal{L}L 的工具增強推理鏈,而非直接給出答案。
具體來說,對于一個預訓練 VLM πθ\pi_\thetaπθ?,輸入圖像 VVV 和任務指令 L\mathcal{L}L,在時刻 ttt 的推理步驟生成方式為:
Rt=πθ(V,L,[R1,…,Rt?1])(1)R_t = \pi_\theta(V, \mathcal{L}, [R_1, \ldots, R_{t-1}]) \tag{1} Rt?=πθ?(V,L,[R1?,…,Rt?1?])(1)
其中,RtR_tRt? 表示第 ttt 個推理步驟,[R1,…,Rt?1][R_1, \ldots, R_{t-1}][R1?,…,Rt?1?] 表示之前生成的步驟。完整的推理軌跡記為 TR=(R1,…,RM)T_R = (R_1, \ldots, R_M)TR?=(R1?,…,RM?),其中 MMM 是最大推理步數。
每個推理步驟 RtR_tRt? 包含五個關鍵要素:所選工具(TooliTool_iTooli?)、生成的子問題(SubiSub_iSubi?)、不確定性標記(UFiUF_iUFi?)、猜測的答案(AiA_iAi?),以及下一步的動作選擇(ACiAC_iACi?),如繼續推理或結束。如果內部知識足以回答 SubiSub_iSubi?,則輸出 AiA_iAi? 并令 UFi=FalseUF_i = FalseUFi?=False;否則 UFi=TrueUF_i = TrueUFi?=True 且 AiA_iAi? 為空。
這一過程將重復進行,以在每個 QA 對上采樣 NNN 條結構化推理軌跡。
數據評估。 一個單獨的 LLM 會對每條數據進行事實準確性和邏輯一致性的審查,剔除存在步驟不匹配或結論不支持的樣本。最終得到的高質量語料庫結合了顯式工具使用與連貫、可驗證的推理。
3.2 兩階段訓練流程
在構建好結構化數據集后,我們設計了一個兩階段的訓練流程,以逐步增強模型的推理能力和工具使用熟練度。
3.2.1 基于 SFT 的推理預熱
在第一階段,我們在工具增強的 CoT 數據集上進行 SFT,以預熱模型生成推理鏈和適當工具調用的能力。每個訓練樣本表示為:
τ=(V,L,TR,A),\tau = (\mathcal{V}, \mathcal{L}, T_R, A), τ=(V,L,TR?,A),
其中 V\mathcal{V}V 是視覺輸入,L\mathcal{L}L 是語言指令,TRT_RTR? 是逐步推理過程,AAA 是最終答案。訓練目標是最大化生成 TRT_RTR? 和 AAA 的似然:
LSFT=?Eτ~D∑t=1Tlog?πθ(Rt∣V,L,R<t),(2)\mathcal{L}_{\text{SFT}} = -\mathbb{E}_{\tau \sim \mathcal{D}} \sum_{t=1}^{T} \log \pi_\theta(R_t \mid \mathcal{V}, \mathcal{L}, R_{<t}), \tag{2} LSFT?=?Eτ~D?t=1∑T?logπθ?(Rt?∣V,L,R<t?),(2)
其中 D\mathcal{D}D 是訓練數據集,RtR_tRt? 表示第 ttt 個推理步驟或答案 token。
3.2.2 基于 RLFT 的推理增強
為了在模仿學習之外進一步優化模型,我們采用基于強化學習微調(Reinforcement Learning Fine-Tuning, RLFT)的方法,引入 GRPO,它能夠在無需學習價值函數的情況下,有效利用結構化獎勵。
GRPO 概述。 GRPO 通過計算組內樣本的相對優勢來避免對價值函數的需求。給定一個問題 qqq 和 GGG 個由舊策略 πθold\pi_{\theta_{\text{old}}}πθold?? 采樣的響應 {oi}i=1G\{o_i\}_{i=1}^G{oi?}i=1G?,其目標函數為 [31]:
JGRPO(θ)=Eq,{oi}~πold[1G∑i=1GLi?βDKL(πθ∥πref)](3)J_{\text{GRPO}}(\theta) = \mathbb{E}_{q, \{o_i\} \sim \pi_{\text{old}}} \left[ \frac{1}{G} \sum_{i=1}^G L_i - \beta D_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}}) \right] \tag{3} JGRPO?(θ)=Eq,{oi?}~πold??[G1?i=1∑G?Li??βDKL?(πθ?∥πref?)](3)
其中,組內裁剪損失(clipped loss)定義為:
Li=min?(wiAi,clip(wi,1??,1+?)Ai)(4)L_i = \min \big(w_i A_i,\; \text{clip}(w_i,\; 1-\epsilon,\; 1+\epsilon) A_i \big) \tag{4} Li?=min(wi?Ai?,clip(wi?,1??,1+?)Ai?)(4)
重要性權重 wiw_iwi? 與歸一化優勢 AiA_iAi? 分別為:
wi=πθ(oi∣q)πθold(oi∣q)(5)w_i = \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)} \tag{5} wi?=πθold??(oi?∣q)πθ?(oi?∣q)?(5)
Ai=ri?mean(r)std(r)(6)A_i = \frac{r_i - \text{mean}(r)}{\text{std}(r)} \tag{6} Ai?=std(r)ri??mean(r)?(6)
其中 rir_iri? 表示分配給輸出 oio_ioi? 的獎勵,β\betaβ 和 ?\epsilon? 為可調超參數。
250904:πθ\pi_\thetaπθ? 是 當前策略模型(更新后的模型),πθold\pi_{\theta_\text{old}}πθold?? 是 舊策略模型(上一次迭代的模型)。
如果某個輸出在新模型里概率更大(wi>1w_i > 1wi?>1),說明新模型更傾向于生成它;
獎勵設計。 為了引導模型實現準確、可解釋且具備工具感知的推理,我們設計了一個結構化獎勵函數,包含三個主要部分:
- 最終答案獎勵(Final Answer Reward): 驗證最終答案是否與真實值一致,鼓勵任務級別的正確性。
- 步驟推理獎勵(Step Reasoning Reward): 評估中間推理步驟的邏輯與結構,包括:
- 步驟匹配: 與參考步驟對齊,并懲罰錯誤的順序;
- 連貫性: 步驟之間的邏輯過渡是否自然。
- 工具使用獎勵(Tool-Use Reward): 鼓勵適當且有意義的工具使用,包括:
- 格式合規性: 是否遵循預期輸出結構(如 “Tool”、“Step Reasoning”);
- 集成質量: 工具輸出是否被有效且連貫地整合進推理中。
250904:獎勵這里寫的太籠統了,附錄里也沒有詳細的。

這種結構化的獎勵設計比通用的相似性度量提供了更有針對性和更可解釋的監督。它使 GRPO 能夠同時優化推理過程的質量,以及模型在需要時調用工具的能力。
3.3 推理與評估
在推理過程中,如圖 4 所示,VLM 會從預定義的工具庫中動態調用工具以獲取信息,從而支持逐步推理。這種動態工具調用機制提高了準確性,并且反映了我們工具增強訓練數據的結構。然而,現有的基準 [11, 15] 往往忽視了對工具使用的評估。為此,我們在表 2 中引入了三項指標,用于評估模型在推理過程中對工具的利用情況。


4. 實驗
在本節中,我們進行了大量實驗來驗證 AgentThink 的有效性。實驗旨在回答以下核心問題:
Q1. 動態的工具增強推理是否能夠在最終答案準確率和推理一致性上超越現有的 VLM 基線?
Q2. 我們的結構化獎勵設計(最終答案、逐步推理、工具使用)是否對推理行為有意義的貢獻?
Q3. AgentThink 在零樣本和單樣本設定下對未見數據集的泛化能力如何?
評估指標。 我們采用 DriveLMM-o1 的評估指標,具體包括利用整體推理得分來衡量 VLMs 的推理水平,并使用多選題質量(Multiple Choice Quality, MCQ)來評估最終答案的準確性,更多細節見附錄 C。此外,我們引入了新的指標來評估工具使用能力,詳見表 2。
模型與實現。 我們使用 Qwen2.5-VL-7B 作為基礎模型,并凍結視覺編碼器。SFT 通過 LoRA 實現,隨后進行 GRPO 微調。訓練批大小設為每設備 1。所有實驗均在 16× NVIDIA A800 GPUs 上進行。在 GRPO 微調階段,我們對每個問題執行 2 次 rollout。其他設置見附錄 B。
4.1 主要實驗結果
與開源 VLMs 的比較。 表 3 展示了在 DriveLMM-o1 基準上的主要結果,將 AgentThink 與一系列強大的開源 VLM 模型進行對比,包括 DriveLMM-o1 [15]、InternVL2.5 [4]、LLaVA-CoT [43] 以及 Qwen2.5-VL 系列。

我們的完整模型 AgentThink 在所有類別中都達到了最新的最優性能。與基線模型 Qwen2.5-VL-7B 相比,其整體推理得分從 51.77 提升到 79.68(+53.91%),最終答案準確率從 37.81% 提升到 71.35%(+33.54%)。與此前最強的系統 DriveLMM-o1 相比,AgentThink 進一步提升了 +5.9% 的推理得分和 +9.0% 的最終答案準確率——這表明學習到的工具使用相較于靜態 CoT 或基于模仿的方法具有明顯優勢。
250904:整體推理得分從 51.77 提升到 79.68(+53.91%)明顯寫錯了,應該是+27.91
性能細分。 除了推理和準確率之外,AgentThink 在駕駛相關的特定指標(如風險評估、交通規則遵循和場景理解)以及感知相關的類別(如相關性和缺失細節檢測)方面也始終優于其他模型。這些提升體現了其能夠利用動態工具調用和反饋,更有效地將推理錨定在視覺上下文中。
關鍵洞察。 不同于傳統的 CoT 或基于提示的方法,AgentThink 學會了 何時以及為何調用外部工具,從而實現了更具適應性和上下文感知的推理。這帶來了更高質量的決策、更少的幻覺,以及在安全關鍵的駕駛場景中更高的可信度。相關案例見附錄 D。
4.2 工具使用分析
如前所述,我們分析了不同訓練策略在推理過程中對工具使用行為的影響。表 5 報告了三個維度的結果:(1) 工具使用的適當性,(2) 工具鏈的連貫性,(3) 感知引導的對齊性。
DirectTool 基線通過提示強制調用工具,但不具備推理結構,其表現為中等的鏈路連貫性,但在適當性和對齊性上較差——這表明強制工具使用往往缺乏目的性。加入 SFT 后,適當性和對齊性均有所改善,但由于缺乏對工具質量的反饋,進一步提升受到限制。結合結構化獎勵的 GRPO 帶來了顯著提升,教會模型有選擇性地調用工具,并將輸出連貫地整合。我們的完整模型結合了 SFT 與 GRPO,并引入全面獎勵,在所有指標上取得最佳表現。這表明監督和獎勵塑造對于學習有效的、具備上下文感知的工具使用至關重要。我們還評估了訓練數據規模的影響,詳見附錄 E。

4.3 消融實驗
在表 4 中,我們進行了全面的消融實驗,以檢驗不同獎勵信號和訓練階段在 AgentThink 中的作用。單獨使用 SFT 或 GRPO(配合最終答案獎勵或逐步推理獎勵)相較基線模型帶來了適度提升,分別在任務準確率和推理連貫性上有所改善。然而,當它們單獨應用時,效果有限。
我們發現,將 SFT 與 GRPO 結合(即便沒有工具使用獎勵)也能取得更好的性能,這表明在強化學習微調之前進行推理預熱至關重要。我們的完整模型 AgentThink 融合了三種獎勵組件,達到了最優結果。它顯著提升了推理質量和答案準確率,從而強調了工具使用和將推理錨定在視覺上下文中的重要性。

4.4 泛化性評估
我們在新的 DriveMLLM 基準上評估了 AgentThink 的泛化能力,分別在零樣本(zero-shot)和單樣本(one-shot)設定下與一系列強大的基線方法進行對比,這些基線包括主流 VLMs 和任務特定的變體(詳細結果見表 6)。評估指標詳見附錄 F。

AgentThink 在零樣本(26.52)和單樣本(47.24)得分上均達到了最新最優,超越了 GPT-4o 和 LLaVA-72B。盡管基線方法(如 DirectTool)通過硬編碼的工具提示在感知任務上表現出較強結果(例如 RHD 89.2 vs. 86.1,BBox 精度 92.4% vs. 91.7%),但它們在上下文剛性和推理-感知對齊方面存在不足。我們的模型通過有效協調顯式推理與學習到的自適應工具使用,在感知上下文中展現了更優的平衡。這凸顯了學習型工具使用機制相較于靜態提示或單純依賴大規模模型在穩健泛化上的優勢。
從定性結果來看,如圖 5 所示,AgentThink 能夠在多樣化基準(BDD-X [18]、Navsim [7]、DriveBench [42]、DriveMLLM [11])上的零樣本困難案例中成功導航。在這些場景下,基礎 Qwen 模型往往無法獲取足夠信息,或在推理過程中產生幻覺,從而導致錯誤輸出。相比之下,AgentThink 能夠熟練調用工具獲取關鍵決策信息,從而正確回答這些困難問題。這進一步強調了其動態工具增強推理在陌生環境下的實用價值。

5. 結論
我們提出了 AgentThink,這是首個緊密結合鏈式思維(Chain-of-Thought, CoT)推理與類代理工具調用的統一框架,專為自動駕駛而設計。通過利用可擴展的工具增強數據集,以及結合逐步推理與規劃優化(GRPO)的兩階段監督微調(SFT)流程,AgentThink 在推理和準確性指標上取得了顯著提升。具體而言,其在 DriveLMM-o1 上的推理得分從 51.77 提升至 79.68,答案準確率從 37.81% 提升至 71.35%,分別超越此前最強模型 +5.9% 和 +9.0%。
除了性能提升之外,AgentThink 還在可解釋性方面表現更優,因為其將推理過程中的每一步都錨定在具體的工具輸出上。這強有力地證明了顯式推理與學習到的工具使用相結合是一種行之有效的策略,有助于推動更安全、更穩健的駕駛任務。這類智能體更好地應對現實駕駛環境中的復雜性,在動態場景下展現出更強的泛化性和適應性。
局限性
數據規模。 我們的工具增強語料庫僅包含 18k 個標注實例,限制了對長尾或稀有駕駛事件的覆蓋。未來需要顯著更大且更具多樣性的數據集,以幫助模型學習更廣泛的真實世界場景。
模型規模。 我們的方法依賴于 Qwen2.5-VL-7B,其 70 億參數規模在嵌入式車載硬件上帶來非平凡的內存和延遲開銷。未來工作應探索更輕量的骨干網絡(如 ~30 億參數),在減輕資源壓力的同時保持推理能力。
缺乏時間上下文。 當前模型僅處理單幀、多視角圖像作為輸入。在缺乏序列信息的情況下,模型可能會誤解依賴時間線索的場景(例如變化的交通信號燈)。為解決此問題,可以引入視頻 token 或采用循環記憶機制。
缺少三維模態。 缺乏 LiDAR 或點云數據會使模型喪失精確的空間幾何信息,從而在與距離相關的推理中引入不確定性。未來通過引入更多模態進行融合有望提升模型的魯棒性。
倫理聲明
所有數據均來自公開發布的駕駛數據集,這些數據已匿名化以去除個人可識別信息;我們未采集任何私人或眾包數據。本研究不涉及人類受試者,所有實驗均在離線或仿真環境中完成。模型檢查點在非商業許可下發布,禁止在未經額外驗證的情況下部署于安全關鍵車輛中。本研究遵循 ACL 倫理準則,并未依賴任何敏感數據或模型。





)



的證明)




![NSSCTF每日一題_Web_[SWPUCTF 2022 新生賽]奇妙的MD5](http://pic.xiahunao.cn/NSSCTF每日一題_Web_[SWPUCTF 2022 新生賽]奇妙的MD5)




