F012 百度地圖+vue+flask+爬蟲 推薦算法旅游大數據可視化系統Echarts mysql數據庫 帶沙箱支付+圖像識別技術
📚編號: F012
文章結尾部分有CSDN官方提供的學長 聯系方式名片
博主開發經驗15年,全棧工程師,專業搞定大模型、知識圖譜、算法和可視化項目和比賽
視頻介紹
百度地圖+vue+flask+爬蟲 推薦算法旅游大數據可視化系統Echarts mysql數據庫 帶沙箱支付+圖像識別技術
簡介:vue+flask+爬蟲 旅游景點推薦算法與可視化大數據系統源碼-包含基于用戶和基于物品的協同過濾算法、多種百度地圖API集成(熱力圖、地圖)、Echarts分析圖、WordCloud詞云、支付寶沙箱支付、百度AI圖像識別(OCR識別身份證-實名認證) 👉 👈
1 系統功能
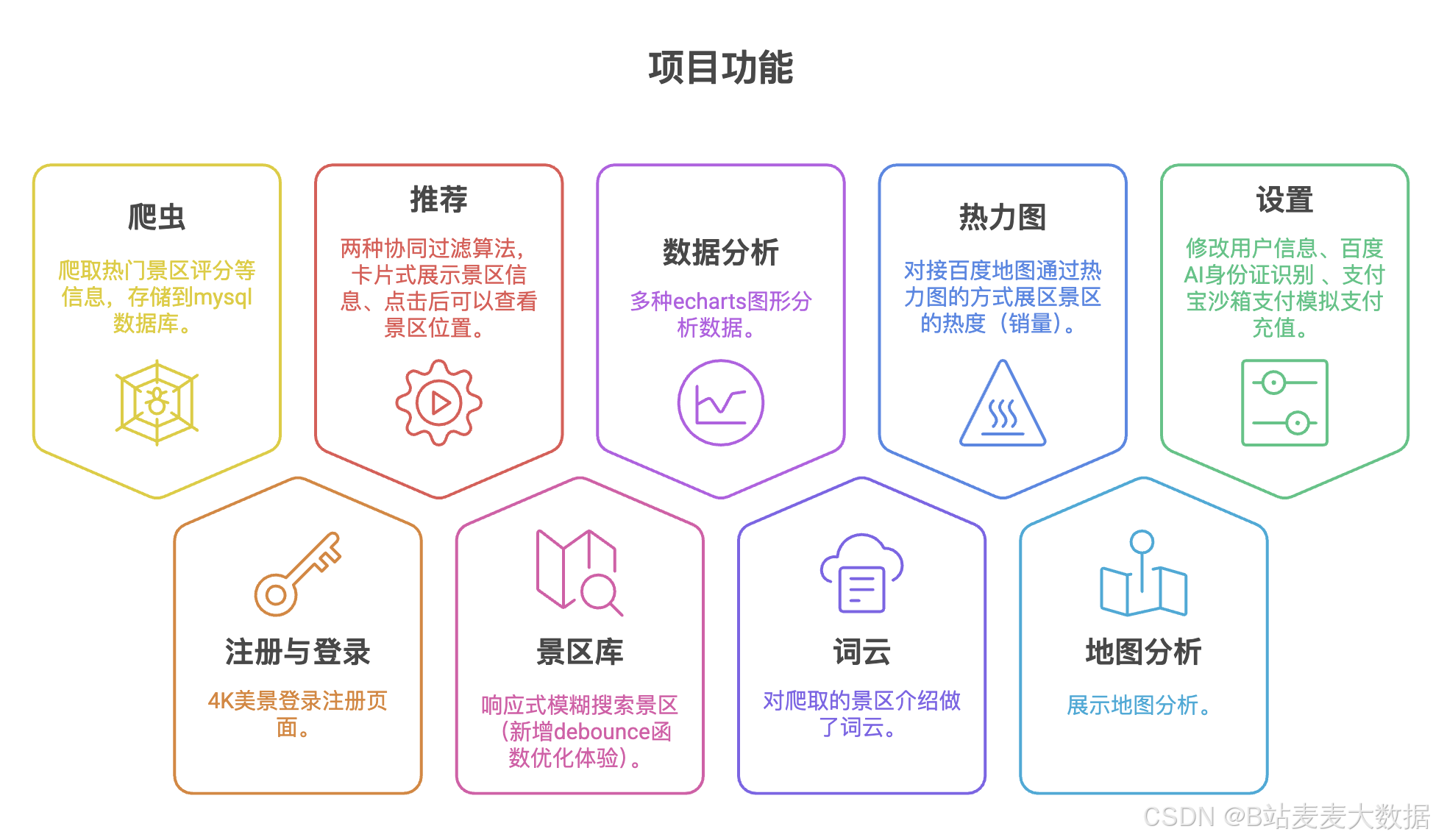
- 爬蟲:爬取熱門景區評分等信息,存儲到mysql數據庫;
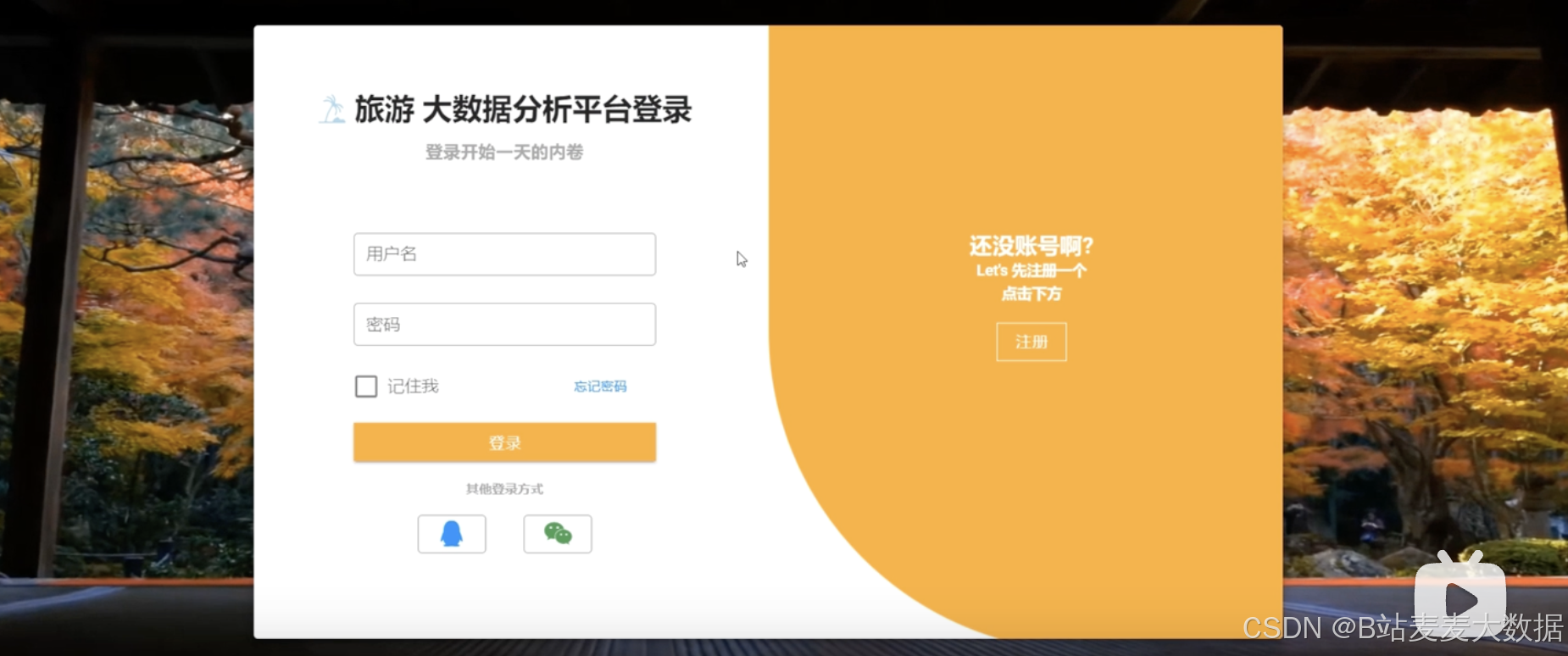
- 注冊與登錄 : 4K美景登錄注冊頁面;
- 推薦:兩種協同過濾算法,卡片式展示景區信息、點擊后可以查看景區位置;
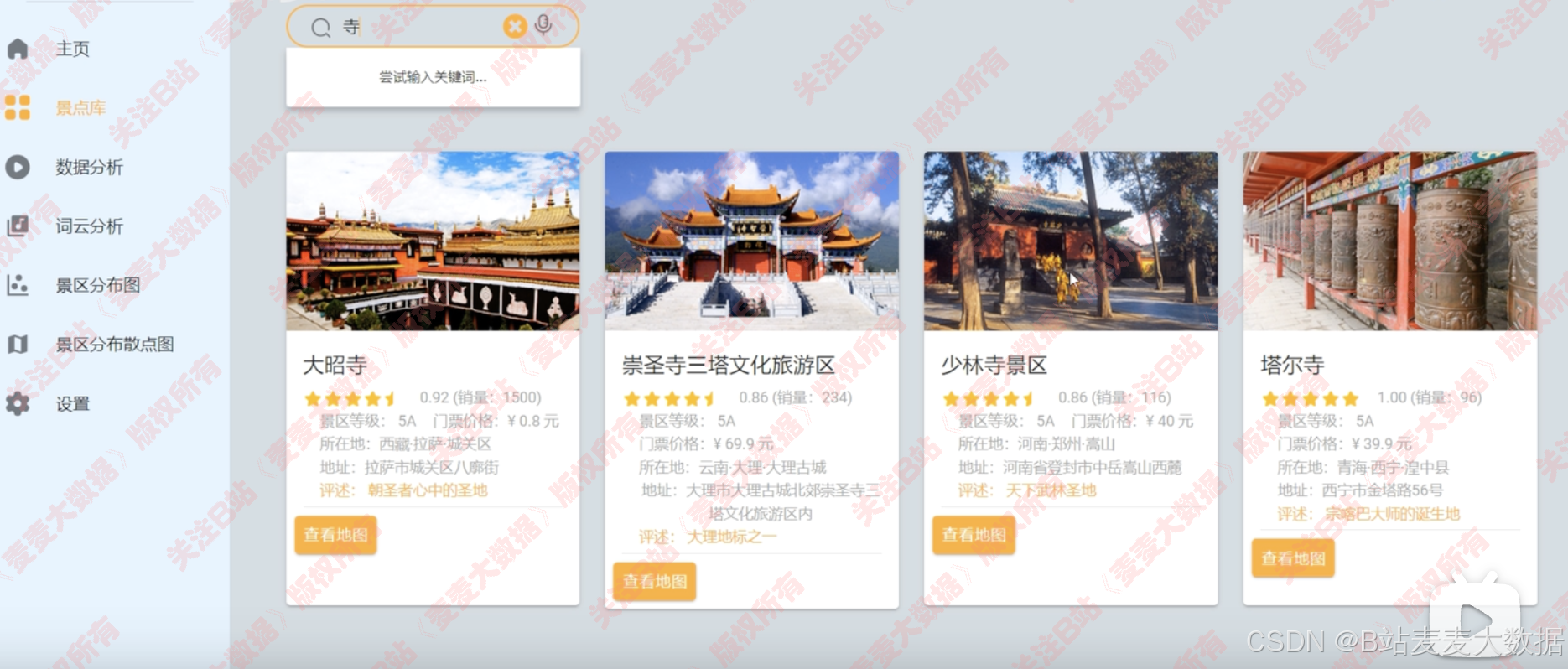
- 景區庫: 響應式模糊搜索景區(新增debounce函數優化體驗);
- 數據分析: 多種echarts圖形分析數據;
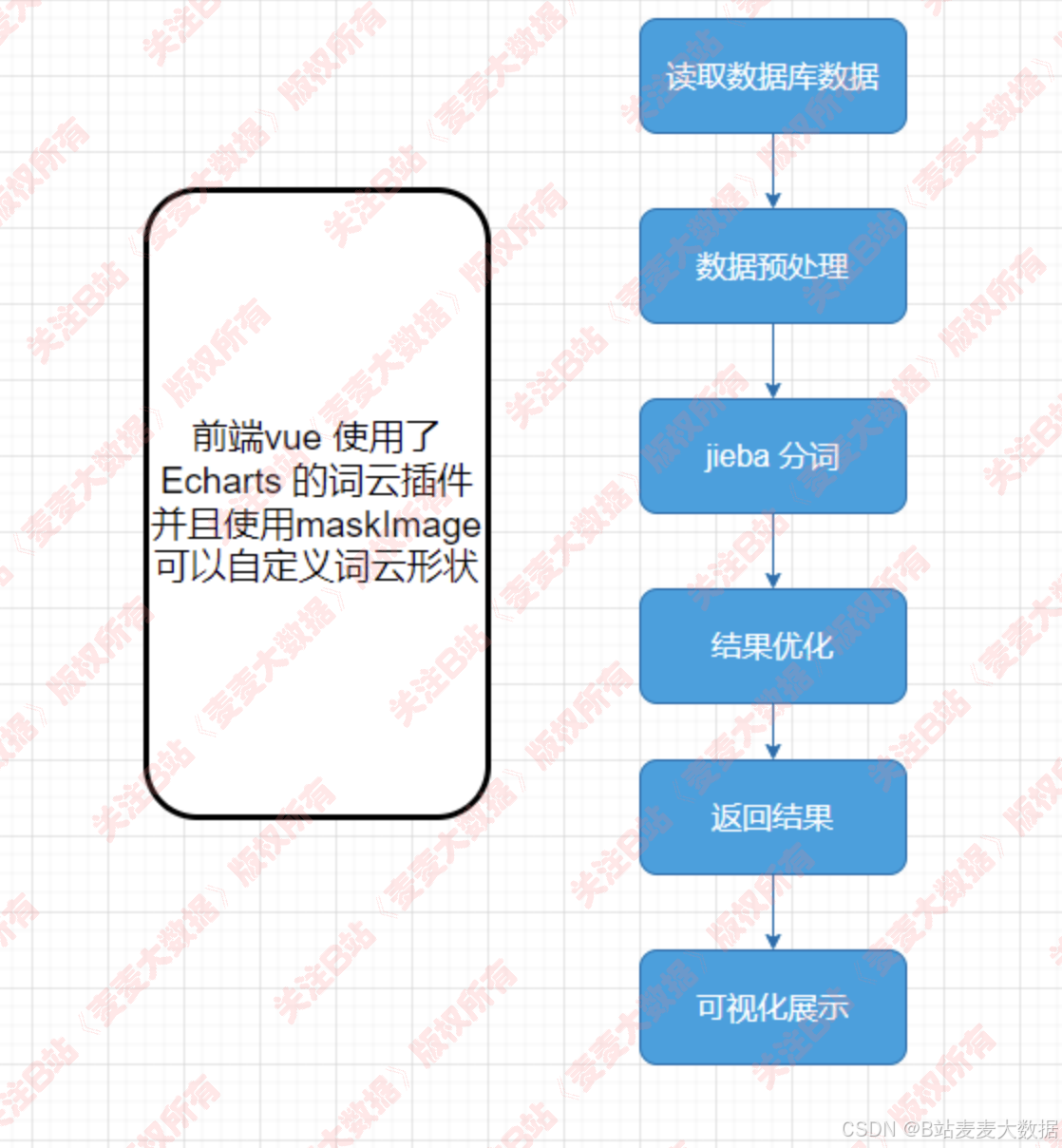
- 詞云: 對爬取的景區介紹做了詞云;
- 熱力圖:對接百度地圖通過熱力圖的方式展區景區的熱度(銷量)
- 地圖分析: 展示地圖分析;
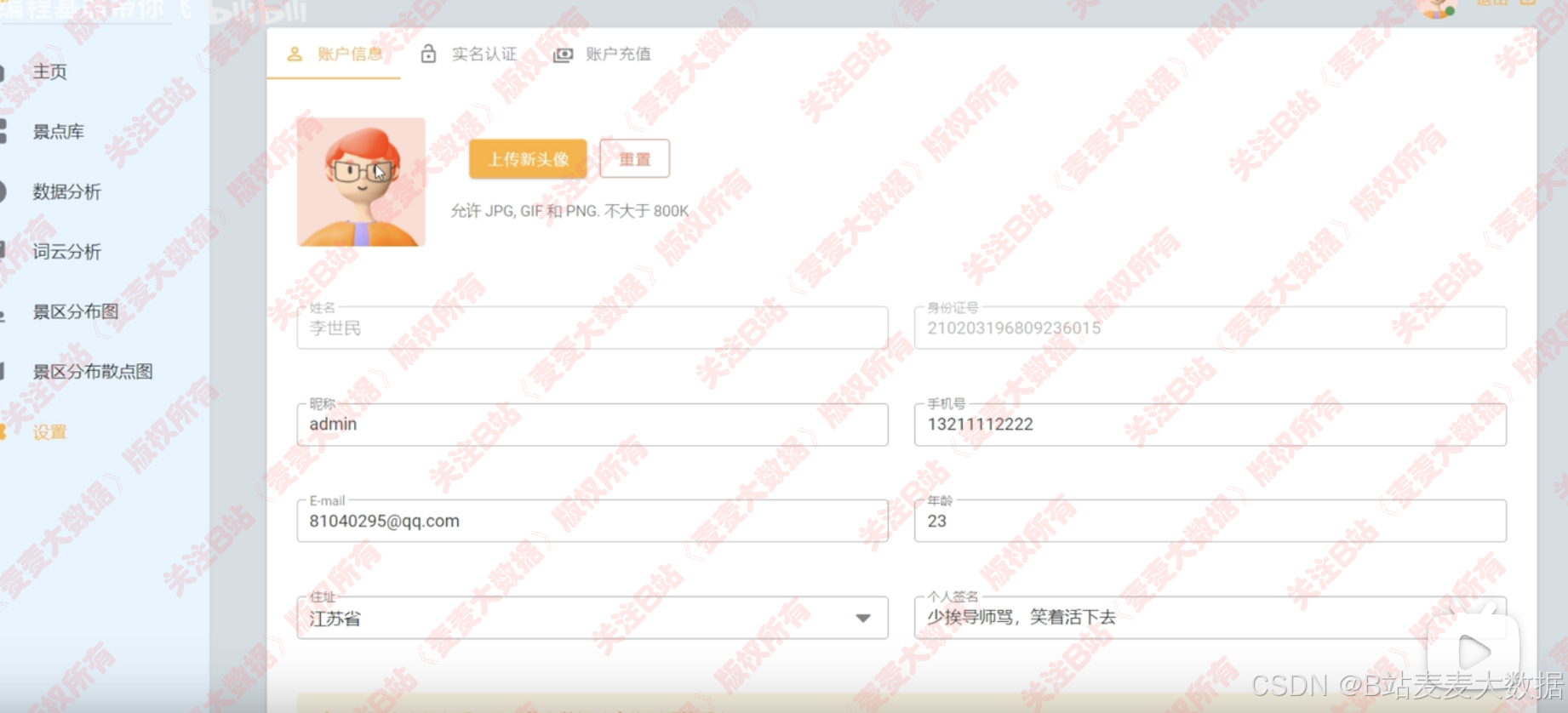
- 設置:修改用戶信息、百度AI身份證識別 、支付寶沙箱支付模擬支付充值;
2 系統亮點 ?
- 實現的分析圖:數據大屏、景區熱力圖、景區分布地圖、景區交互地圖、詞云、多種折線圖、餅圖、環圖等;
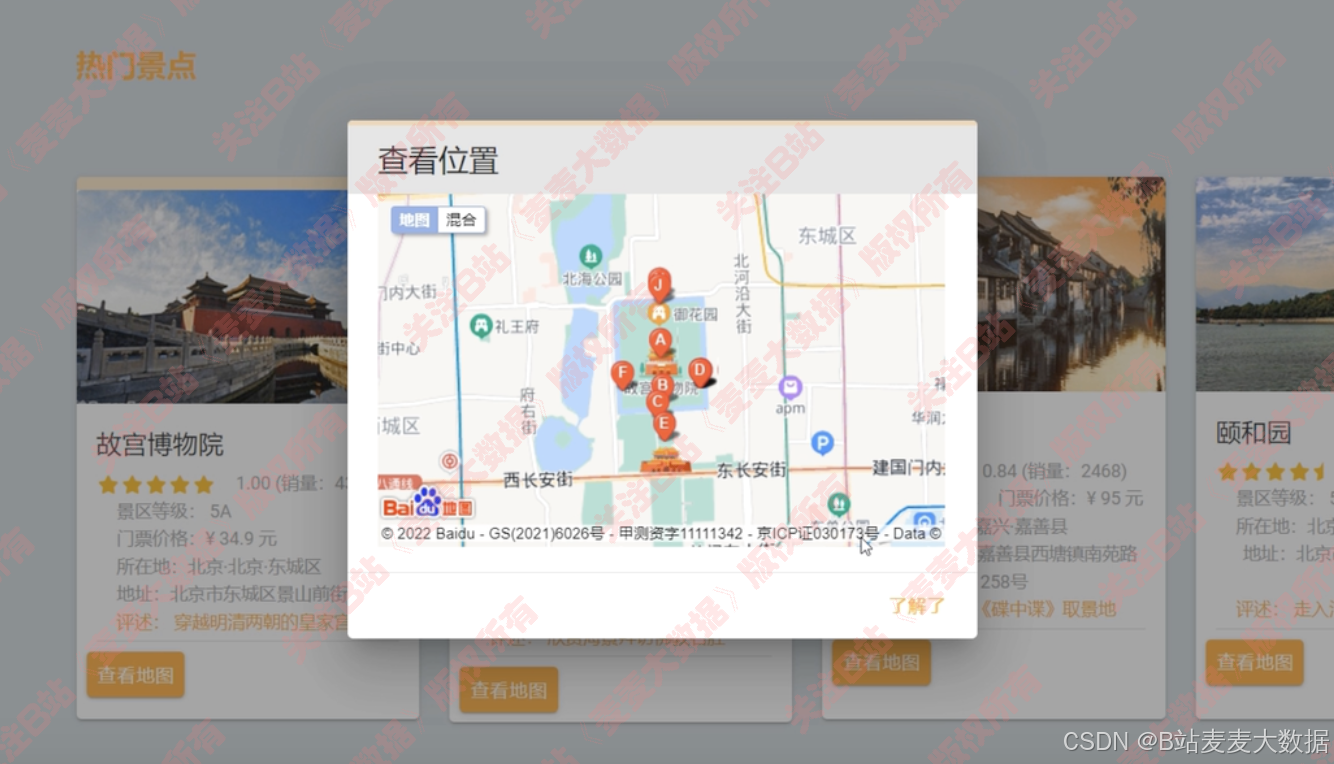
- 景區地圖展示:可以直接在百度地圖中給出景區位置;
- 推薦算法: 兩種協同過濾推薦算法使用。 【User Based & Item Based】;
- 實名認證功能:通過使用百度AI-ORC識別身份證實現 【python實現】;
- 充值功能:完美集成支付寶沙箱支付;
- 自適應移動端;
- 界面主題可修改,配置化批量修改配色;
3 架構功能圖
3.1 功能圖
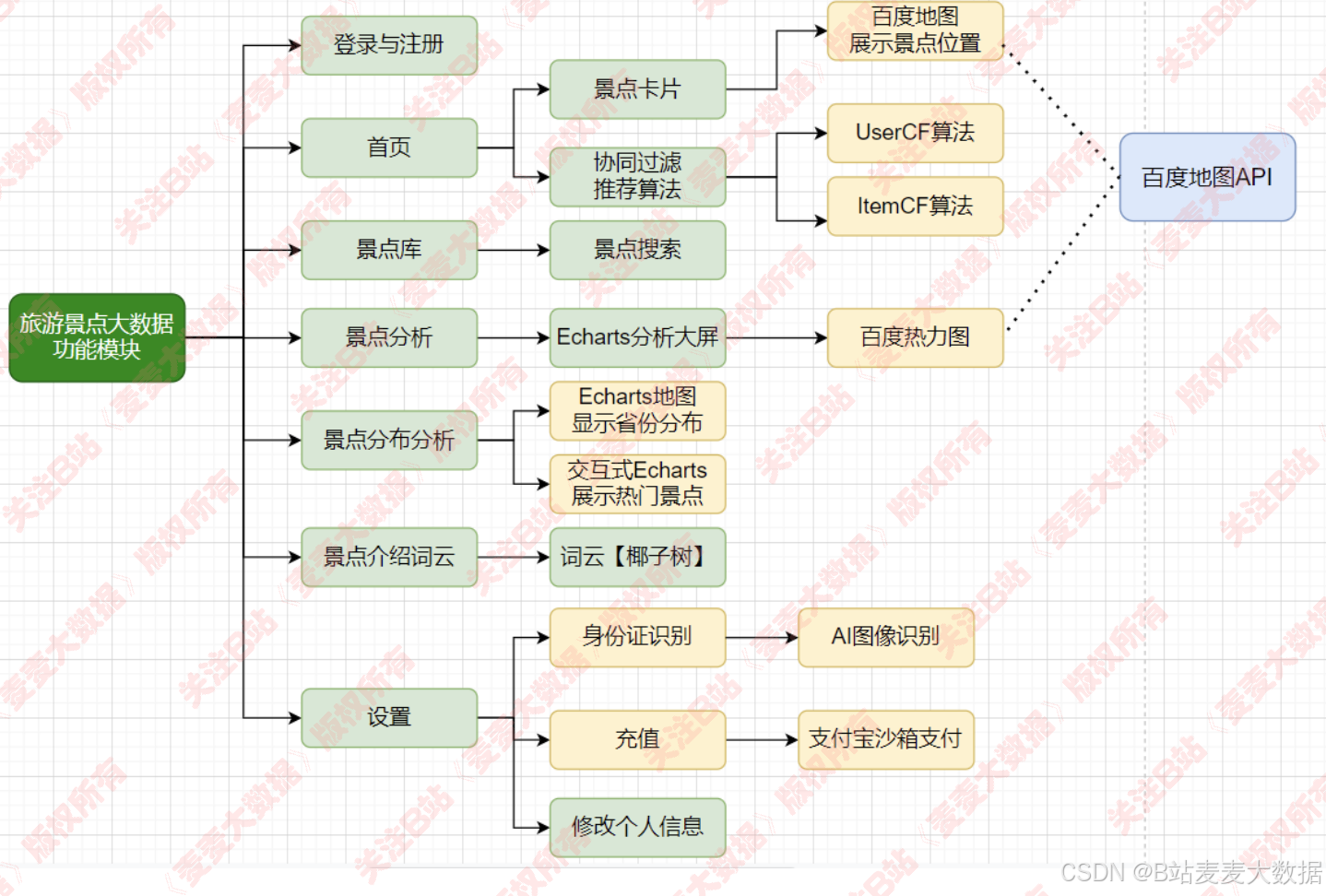
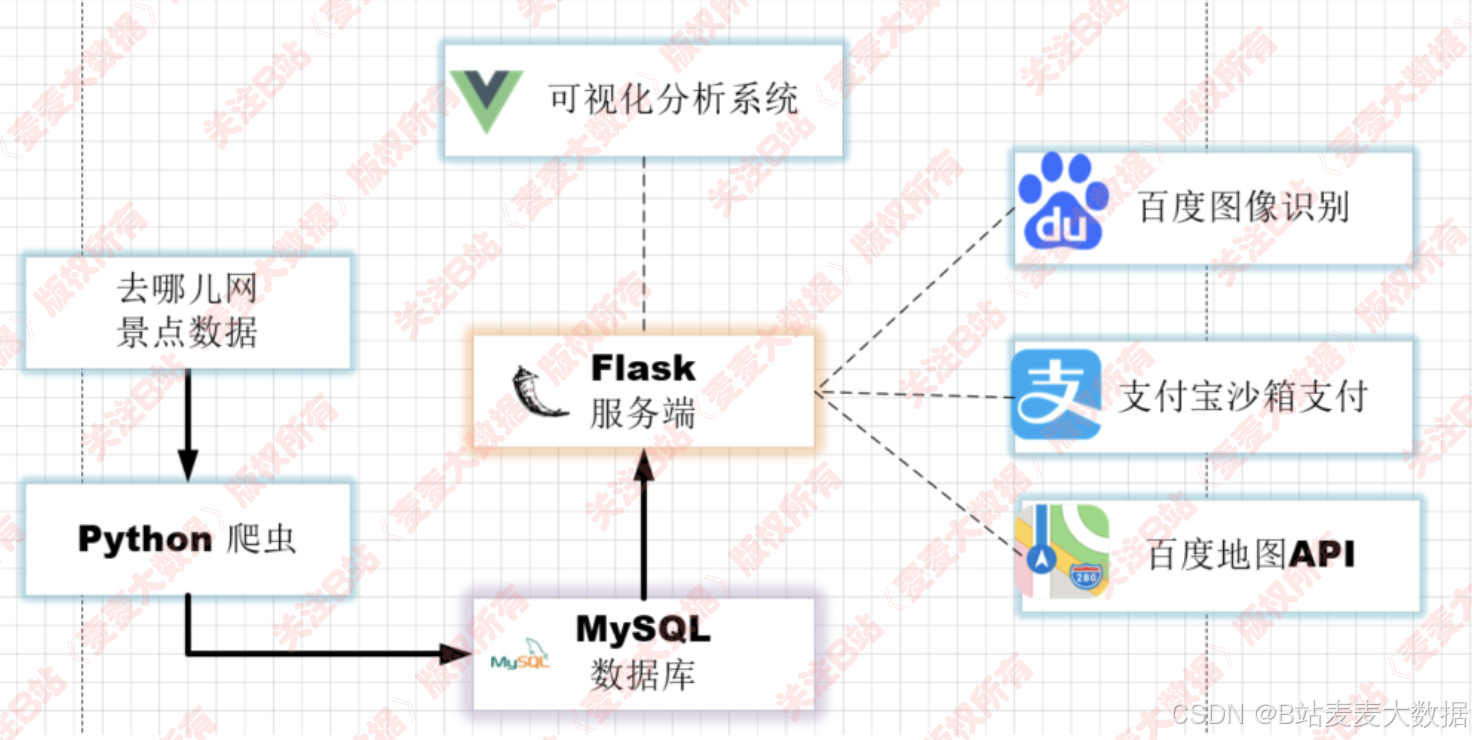
3.2 架構圖
3.3 詞云處理邏輯
4 功能介紹
4.1 登錄 (動態效果背景)
4.2 推薦算法
主頁展示景點卡片 【展示圖片、名稱等信息】
基于usercf+itemcf 雙協同過濾推薦算法的景點推薦
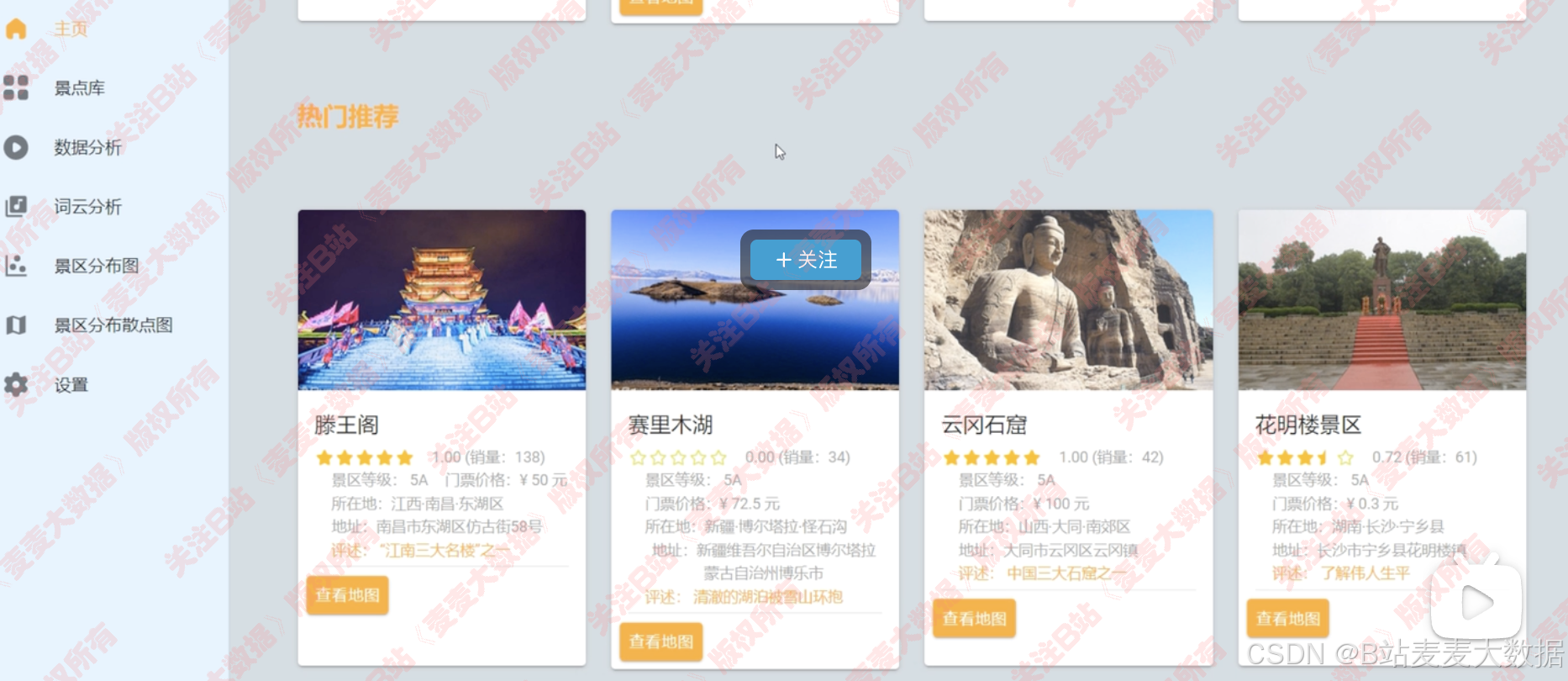
熱門景點展示

景點庫可以進行模糊搜索
景點卡片可以點擊查看具體的位置,對接百度地圖方式
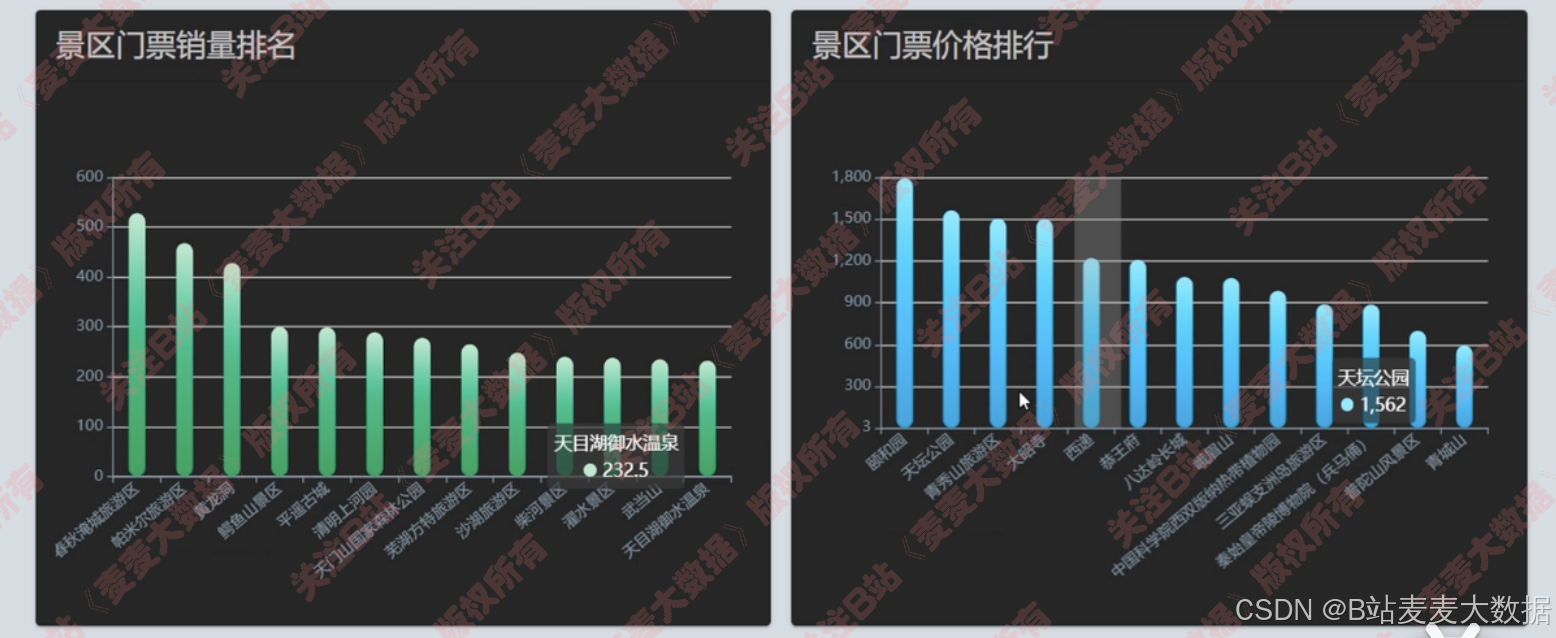
4.3 數據可視化
可視化大屏、 景點熱力圖、 下方是可以滾動的柱狀圖
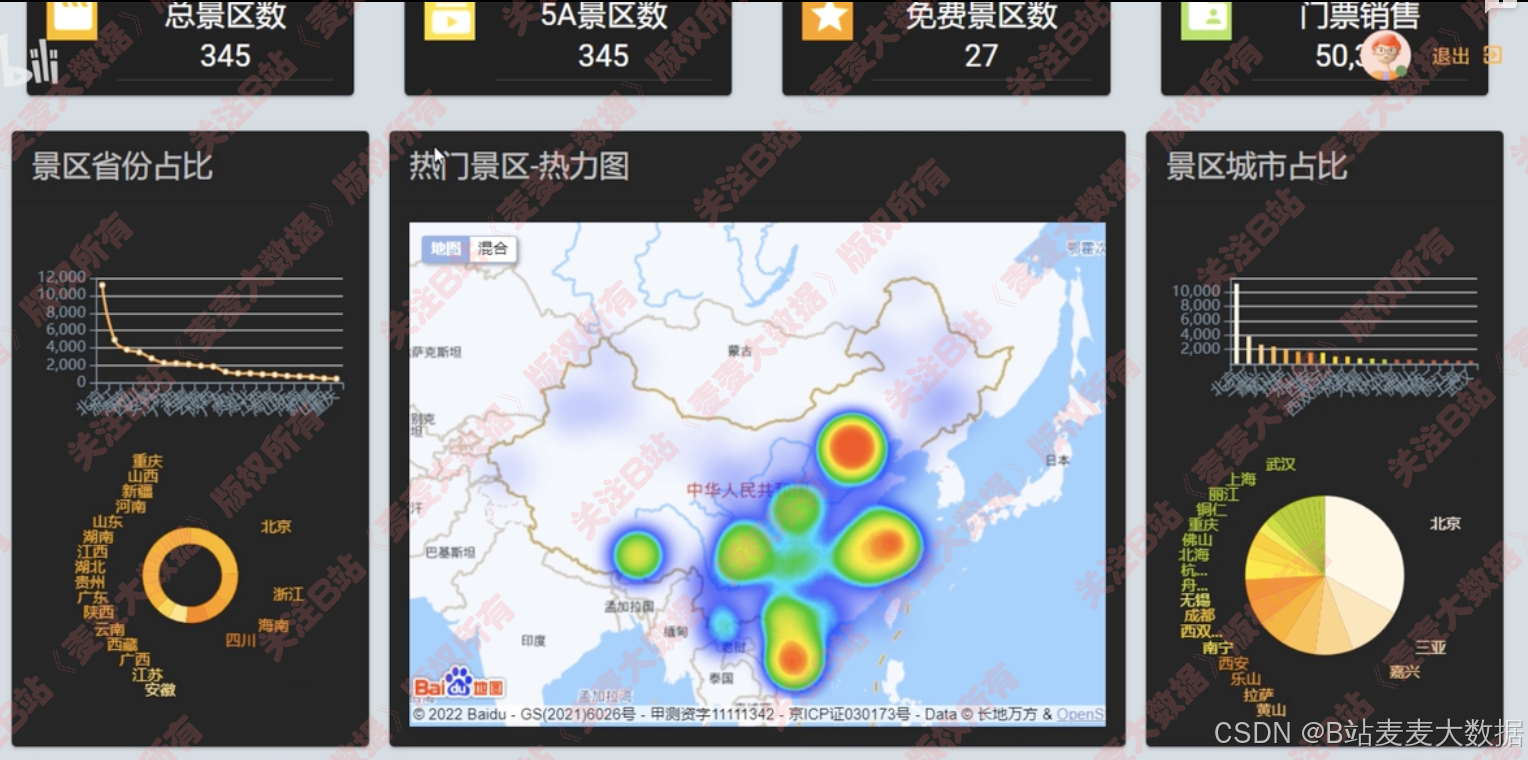
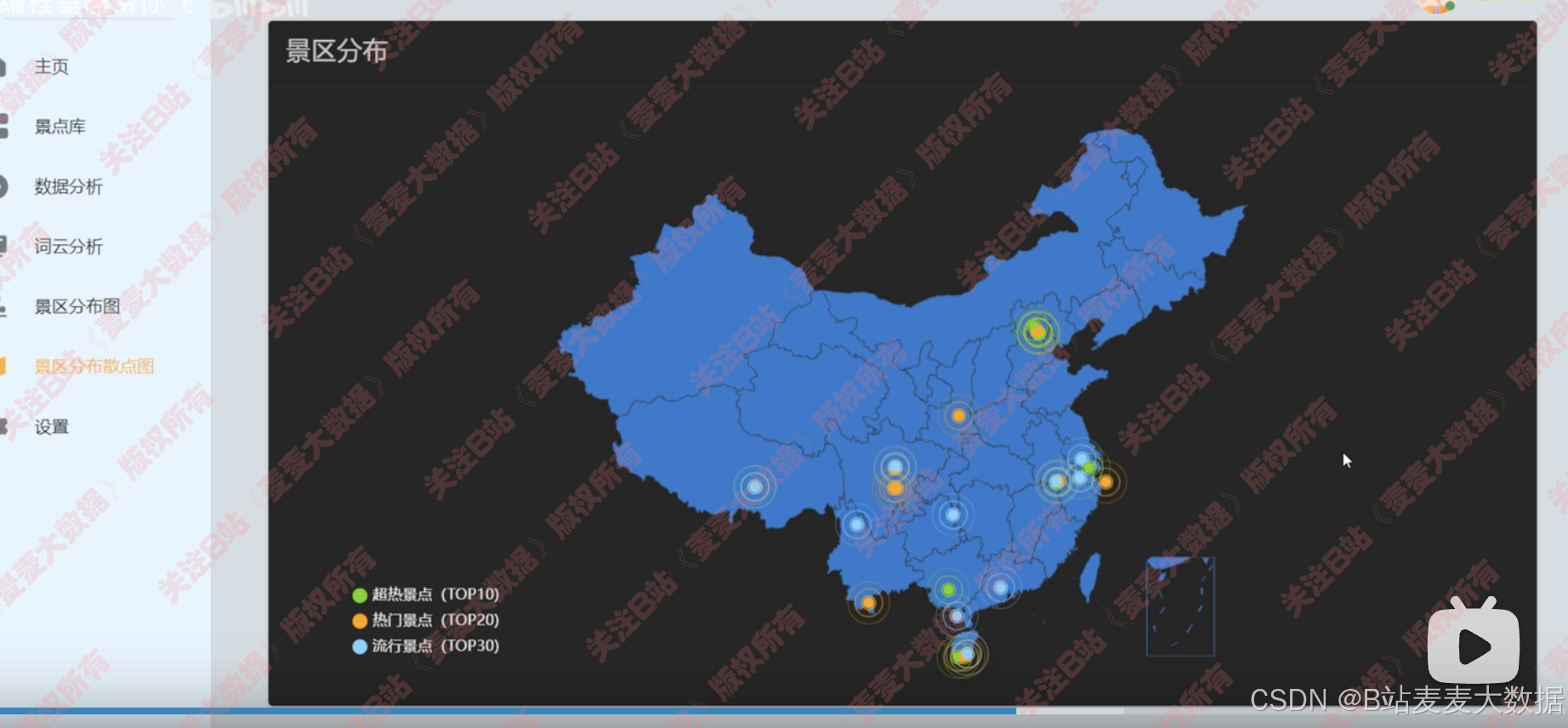
地圖分析(分布熱力圖)

散點圖+地圖的分析
詞云分析

4.4 個人設置
4.5 爬蟲
5 開發環境和關鍵技術
- 服務端技術:Flask 、百度地圖API、百度AI識別、支付寶沙箱支付、SQLAlchemy、MarshMallow、Blueprint 等
- 前端技術:Vue 、Echarts 、Axios、Vuex、WordCloud 等
- 爬蟲技術: requests 等
- 數據庫:MySQL
- 開發語言: Python 3.8 Vue 2.x
- 集成開發環境: PyCharm-2025 WebStorm-2025 Windows-11 Node-16
6 推薦算法
算法介紹:
該協同過濾推薦算法基于用戶相似性為中國旅游景點提供個性化推薦。首先構建用戶-景點評分矩陣,使用余弦相似度計算用戶間的偏好相似性。對于目標用戶,系統查找與其最相似的K個用戶,通過聚合相似用戶對未評分景點的評價,生成評分預測。最終推薦預測評分最高的景點。該算法能夠有效解決旅游信息過載問題,幫助用戶發現符合興趣的新景點。在實際應用中,可配合在線旅游平臺收集真實用戶行為數據,進一步優化模型并通過A/B測試評估推薦質量。

import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd# 生成模擬數據
np.random.seed(42)
users = [f'User{i}' for i in range(1, 101)]
attractions = ['故宮博物院', '長城', '西湖', '兵馬俑', '九寨溝', '張家界', '漓江', '黃山', '布達拉宮', '鼓浪嶼'
]# 創建用戶-景點評分矩陣 (0分表示未訪問)
ratings = np.zeros((len(users), len(attractions)))
for i in range(len(users)):# 每個用戶隨機評價2-5個景點rated_indices = np.random.choice(len(attractions), np.random.randint(2, 6), replace=False)ratings[i, rated_indices] = np.random.randint(1, 6, len(rated_indices))# 轉換為DataFrame
ratings_df = pd.DataFrame(ratings, index=users, columns=attractions)def recommend_attractions(user_id, k=3):"""協同過濾景點推薦:param user_id: 目標用戶ID:param k: 使用的最相似用戶數量:return: 推薦景點列表"""# 計算用戶相似度user_similarity = pd.DataFrame(cosine_similarity(ratings_df),index=ratings_df.index,columns=ratings_df.index)# 獲取目標用戶未評分的景點user_idx = np.where(ratings_df.index == user_id)[0][0]unrated_attractions = ratings_df.columns[ratings_df.iloc[user_idx] == 0]# 預測評分predictions = {}for attraction in unrated_attractions:# 找到評價過該景點的用戶rated_users = ratings_df.index[ratings_df[attraction] > 0]# 計算加權評分numerator = 0denominator = 0count = 0# 獲取k個最相似用戶similar_users = user_similarity[user_id].drop(user_id).sort_values(ascending=False)[:k]for other_user in similar_users.index:if other_user not in rated_users:continuesimilarity = user_similarity.loc[user_id, other_user]rating = ratings_df.loc[other_user, attraction]numerator += similarity * ratingdenominator += abs(similarity)count += 1# 僅當有有效評分時才預測if count > 0:predicted_rating = numerator / denominator if denominator != 0 else 0predictions[attraction] = predicted_rating# 返回前3個推薦景點return [attraction for attraction, _ in sorted(predictions.items(), key=lambda x: x[1], reverse=True)[:3]]# 測試推薦系統
if __name__ == "__main__":target_user = 'User1'recommendations = recommend_attractions(target_user)print(f"{target_user} 的推薦景點:")for i, attraction in enumerate(recommendations, 1):print(f"{i}. {attraction}")

)



——Xml序列化、反序列化、IXmlSerializable接口)




![VUE的中 computed: { ...mapState([‘auditObj‘]), }寫法詳解](http://pic.xiahunao.cn/VUE的中 computed: { ...mapState([‘auditObj‘]), }寫法詳解)







