12、synchronized和Lock有什么區別
語法層面
synchronized是關鍵字,源碼在jvm中,用c++實現
Lock是接口,源碼又jdk提供,用Java實現
使用synchronized時,退出同步代碼塊鎖會自動釋放,而使用Lock時,需要手動調用unlock方法釋放
功能層面
二者都是使用悲觀鎖,都具備基本的互斥、同步、鎖重入功能
Lock提供了許多Synchronized不具備的功能,例如公平鎖、可打斷、可超時、多條件變量
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class LockRaceExample {private static final Lock lock = new ReentrantLock();public static void main(String[] args) throws InterruptedException {// 🧍 線程 A:一上來就搶鎖Thread threadA = new Thread(() -> {System.out.println("線程 A 開始搶鎖...");lock.lock();try {System.out.println("線程 A 獲得了鎖!");Thread.sleep(2000);} catch (InterruptedException e) {Thread.currentThread().interrupt();} finally {lock.unlock();}}, "Thread-A");// main 線程:先睡一下,再搶鎖System.out.println("main 線程準備...");Thread.sleep(100); // main 線程故意延遲// 啟動線程 AthreadA.start();// main 線程再去搶鎖System.out.println("main 線程開始搶鎖...");lock.lock();try {System.out.println("main 線程獲得了鎖!");} finally {lock.unlock();}threadA.join();}
}Lock有適合不同場景的實現,如
ReentrantLock,ReentrantReadWriteLock(讀寫鎖)性能層面
在沒有競爭時,synchronized做了很多優化,如偏向鎖、輕量級鎖,性能不賴
在競爭激烈的時候,Lock的實現通常會提供更好的性能
13、死鎖的條件
這里用我自己的話來舉個例子
就是吃飯的時候你要拿到叉子和刀子才能完成吃飯這個動作,那么現在有線程A和B,線程A首先拿的是刀子然后刀子就會鎖住,然后線程B拿的是叉子然后叉子就會鎖住,那么假如線程A現在又去想要拿到叉子但是現在叉子被鎖著呢,然后線程B就想拿到刀子而刀子也鎖住了,這個時候就會發生死鎖
簡單來說就是線程A持有刀子然后等待線程B釋放叉子,而線程B又在等待線程A釋放刀子
互斥條件(資源一次只能被一個線程占用)
占有并等待(線程已經占有至少一個資源,又等待獲取其他被占用的資源)
不可剝奪(線程持有的資源不能被其他線程或系統強制剝奪,只能有現成自己釋放)
循環等待(存在一組線程,形成首尾相連的等待環路)
死鎖的診斷
1、當程序出現死鎖現象,我們可以使用jdk自帶的工具:jps和jstack
2、
jps:輸出JVM中運行的進程狀態信息3、
jstack:查看java進程內線程的堆棧信息,查看日志,檢查是否有死鎖,如果有死鎖現象,需要查看具體代碼后修復4、可視化工具
jconsole、VisualVm也可以檢查死鎖問題
14、ConcurrentHashMap
1、底層數據結構
JDK1.7底層采用的是分段的數組+鏈表實現的JDK1.8采用的數據結構跟HashMap1.8的結構一樣,都是數據+鏈表/紅黑二叉樹
2、加鎖的方式
JDK1.7采用的是Segment分段鎖,底層采用的是ReentrantLockJDK1.8采用的是CAS添加新節點,采用synchronized鎖定鏈表或紅黑樹的首節點,相對Segment分段鎖粒度更細,性能更好
15、導致并發程序出現問題的原因是什么
并發程序出現問題,主要原因有三個核心:原子性、可見性、有序性
原子性:多個操作未作為一個整體執行,導致中間狀態被其他線程看到。可以加鎖來解決
可見性:線程緩存導致修改未及時同步,可用
volatile或同步塊解決排序性:指令重排序破壞邏輯,
volatile可禁止重排
16、說一下線程池的核心參數
new ThreadPoolExecutor(2, // corePoolSize5, // maximumPoolSize60L, // keepAliveTimeTimeUnit.SECONDS, // unitnew LinkedBlockingQueue<>(10), // workQueueExecutors.defaultThreadFactory(), // threadFactorynew ThreadPoolExecutor.AbortPolicy() // handler
);corePoolSize:核心線程數目maximumPoolSize:最大線程數目=核心線程數目+救急線程的最大數目keepAliveTime: 生存時間-救急線程的生存時間,生存時間內沒有新任務,此線程資源會釋放unit:時間單位-救急線程的生存時間單位workQueue:當沒有空閑核心線程時,新來任務會加入到此隊列排隊,隊列滿會創建救急線程執行任務threadFactory:線程工廠可以定制線程對象的創建handler:拒絕策略,當所有線程都在繁忙,workQueue也會被放滿時,會觸發拒絕策略
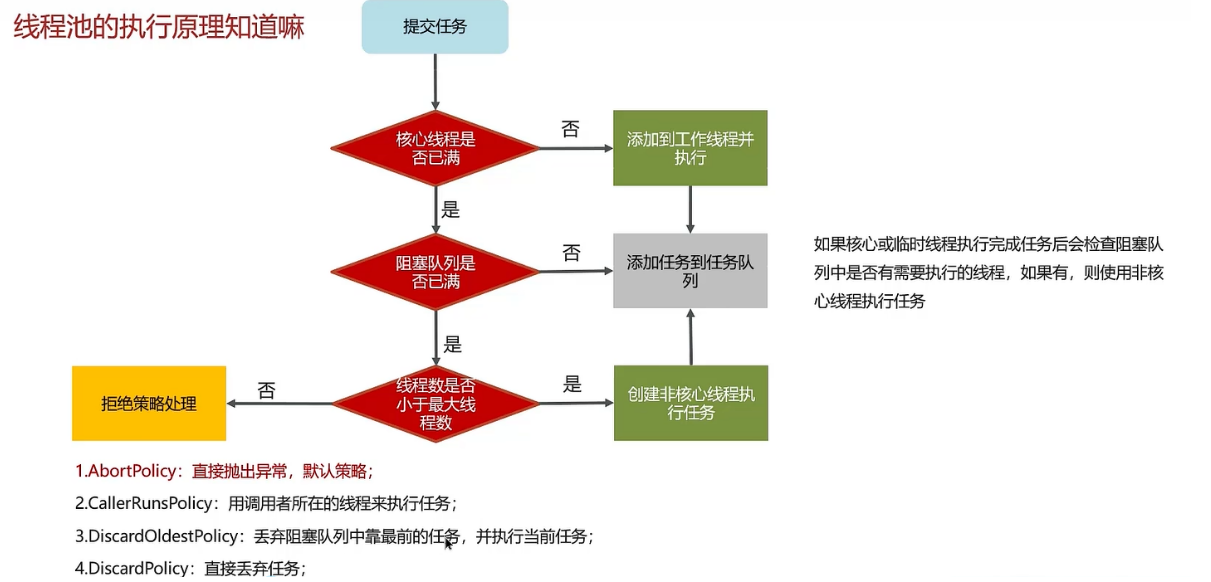
17、線程池中有哪些常見的阻塞隊列
1、ArrayBlockingQueue:基于數組結構的有界阻塞隊列,FIFO
2、LinkedBlockingQueue:基于鏈表結構的有界阻塞隊列,FIFO
3、DelayedWorkQueue:是一個優先級隊列,可以保證每次出隊的任務都是當前隊列中執行時間最靠前的
4、SynchronousQueue:不存儲元素的阻塞隊列,每個插入操作都必須等待一個移出操作
面試官最喜歡考的就是這個ArrayBlockingQueue和LinkedBlockingQueue
ArrayBlockingQueue:
強制有界
底層是數組
提前初始化Node數組
Node需要時提前創建好的
一把鎖
LinkedBlockingQueue:
默認無界
底層是鏈表
是懶惰的,創建節點的時候添加數據
入隊會生成新Node
兩把鎖(頭尾)
18、如何確定核心線程數
1、高并發、任務時間執行短——>(CPU核數+1),減少線程上下文切換
2、并發不高、任務執行時間長
IO密集型任務——>(CPU核數*2+1)
計算密集型任務——>(CPU核數+1)
3、并發高、業務執行時間長,解決這種類型任務的關鍵不在于線程池而在于整體架構的設計,看看這些業務里面某些數據是否能做緩存是第一步,增加服務器是第二步,然后到時候線程池的配置就看第2個小點
19、線程池的種類有哪些
1、newFixedThreadPool:創建一個定長線程池,可控制線程最大并發數,超出的線程會在隊列中等待
2、newSingleThreadExecutor:創建一個單線程化的線程池,只能用唯一的工作線程來執行任務,保證所有的任務都是按順序執行的
3、newCacheThreadPool:創建一個可緩存的線程池,如果線程長度超過處理需要,就會生成對應的臨時線程如果不用的話也會自己回收
4、newScheduledThreadPool:可以執行延遲任務的線程池,支持定時及周期任務執行
20、為什么不建議用Executors創建線程池
1、FixedThreadPool和SingleThreadPool
允許的請求隊列長度為Integer.MAX_VALUE,可能會堆積大量的請求,從而導致OOM
2、CacheThreadPool
允許的創建線程數量為Integer.MAX_VALUE,可能會堆積大量的請求,從而導致OOM











)
重排多樣性提升)

實例代碼演示與API文檔說明)
![[Sync_ai_vid] UNet模型 | 音頻特征提取器(Whisper)](http://pic.xiahunao.cn/[Sync_ai_vid] UNet模型 | 音頻特征提取器(Whisper))



