第2章:LatentSync UNet模型
在第1章:唇形同步推理流程中,我們了解到唇形同步推理流程如同電影導演,協調各"專家模塊"生成完美唇形同步視頻。
本章將深入解析這個"工作室"中最核心的專家——LatentSync UNet。
模型定位
想象一位精通面部繪制(尤其是嘴部)的藝術家。
這位藝術家的任務不是繪制全新面部,而是基于原始嘴部動作和參考圖像,巧妙調整現有繪畫中的嘴部運動以匹配新音頻。這正是LatentSync UNet的核心功能——作為LatentSync的核心生成模型。
核心輸入輸出:
- 含噪潛在視頻幀:模糊不清的視頻幀潛在表征
- 音頻線索:描述發音特征的數值化提示(如
"P"音需閉唇,"O"音需圓唇) - 參考圖像:保持面部一致性的基準
通過精修這些含噪幀,基于音頻線索微調,最終輸出唇音完美同步的新視頻幀。
"潛在"空間的意義
如第1章所述,"潛在"空間是AI模型處理復雜數據(如圖像/視頻)的壓縮編碼空間。相比直接處理數百萬像素,UNet在此高效空間操作,大幅提升處理速度。
架構原理:U-Net結構
LatentSync UNet基于U-Net神經網絡架構(因結構形似字母"U"得名):
- 下采樣路徑(U型左側):
壓縮含噪潛在視頻幀,提取時空關鍵特征(3D卷積處理視頻時序關系) - 中間塊(U型底部):最核心處理層,通過**
交叉注意力機制**融合音頻特征 - 上采樣路徑(U型右側):結合下采樣階段的跳躍連接,
重建高清視頻幀
交叉注意力機制
該機制使UNet能動態"關注"音頻特征的關鍵部分(如特定發音對應的口型)。
類比藝術家作畫時:
- 視頻幀作為
query(查詢向量) - 音頻特征作為
key(鍵向量)和value(值向量)
通過交叉參考確保唇形與發音精準匹配
工作流程集成
UNet通過唇形同步推理流程調用,核心交互見以下簡化代碼:
# 唇形同步流程中的擴散過程循環
for j, t in enumerate(timesteps):noise_pred = self.unet(unet_input, t, encoder_hidden_states=audio_embeds).sample# 使用噪聲預測精修潛在表征
每次UNet調用都逐步去除噪聲,使唇形更匹配音頻。該過程迭代執行(次數由num_inference_steps參數控制),直至輸出清晰同步的視頻
配置參數
UNet行為由configs/unet/下的配置文件定義,關鍵參數示例:
model:add_audio_layer: true # 啟用音頻處理層cross_attention_dim: 384 # 匹配Whisper模型的音頻特征維度 in_channels: 13 # 輸入通道數(4+1+4+4)down_block_types: # 下采樣塊類型- "CrossAttnDownBlock3D" # 含交叉注意力的3D塊
技術實現
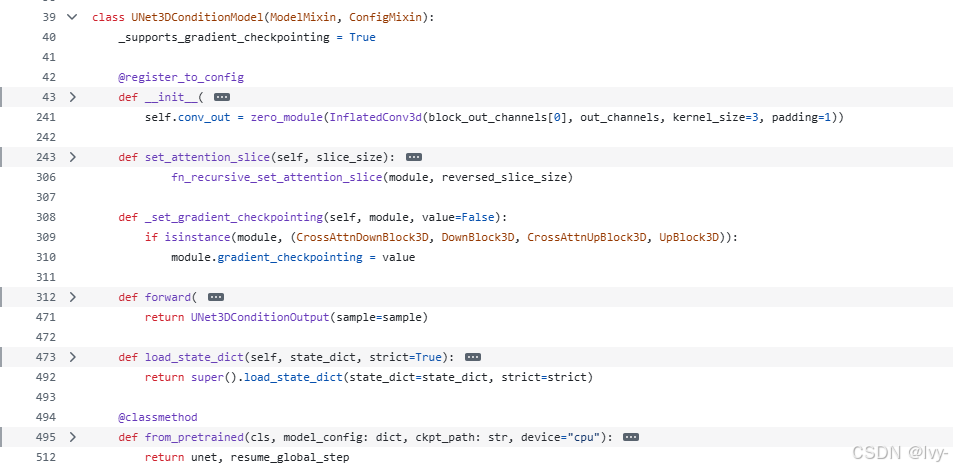
核心代碼位于latentsync/models/unet.py的UNet3DConditionModel類:
1. 初始化構造
class UNet3DConditionModel(ModelMixin, ConfigMixin):def __init__(self, in_channels=13, cross_attention_dim=384):self.conv_in = InflatedConv3d(in_channels, block_out_channels[0])self.time_embedding = TimestepEmbedding(...)# 初始化下采樣/中間/上采樣塊self.down_blocks = nn.ModuleList([CrossAttnDownBlock3D(...)])self.mid_block = UNetMidBlock3DCrossAttn(...)
2. 前向傳播
def forward(self, sample, timestep, encoder_hidden_states):# 1. 時間步處理emb = self.time_embedding(timestep)# 2. 輸入卷積sample = self.conv_in(sample)# 3. 下采樣路徑(含跳躍連接)for downsample_block in self.down_blocks:sample = downsample_block(sample, emb, encoder_hidden_states)# 4. 中間塊處理sample = self.mid_block(sample, emb, encoder_hidden_states)# 5. 上采樣路徑for upsample_block in self.up_blocks:sample = upsample_block(sample, emb, encoder_hidden_states)return UNet3DConditionOutput(sample)
3. 核心注意力模塊
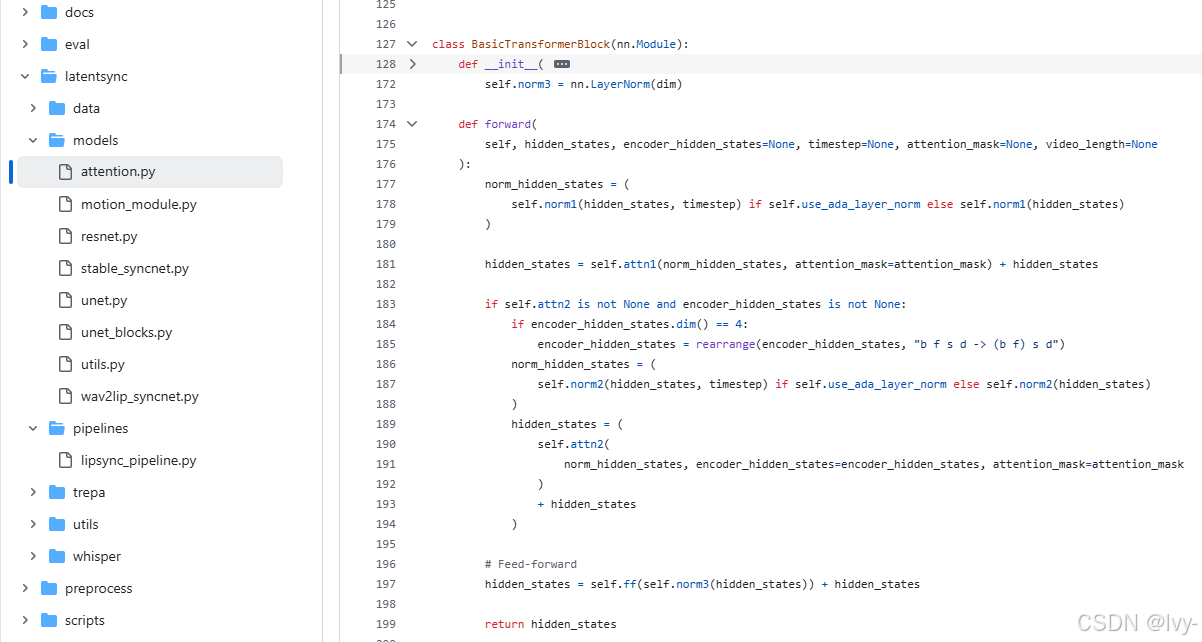
位于latentsync/models/attention.py的交叉注意力實現:
class BasicTransformerBlock(nn.Module):def forward(self, hidden_states, encoder_hidden_states):# 視頻特征作為query,音頻特征作為key/valuehidden_states = self.attn2(norm_hidden_states, encoder_hidden_states=encoder_hidden_states) + hidden_statesreturn hidden_states
總結
LatentSync UNet作為項目的"藝術大腦",通過:
- 3D卷積處理視頻時序特征
- 交叉注意力融合音頻線索
多尺度跳躍連接保持畫質- 迭代式潛在空間優化
實現了從異步視頻到精準唇形同步的轉變。
下一章將解析另一個關鍵模塊——音頻特征提取器(Whisper),其為UNet提供核心音頻線索。
下一章:音頻特征提取器(Whisper)
第3章:音頻特征提取器(Whisper)
在探索LatentSync項目的過程中,我們已經了解了唇形同步推理流程如何像導演一樣協調各模塊工作,并深入研究了核心模塊LatentSync UNet如何基于"音頻線索"調整唇形運動。
但這些關鍵的"音頻線索"從何而來?LatentSync如何解析音頻內容以實現精準唇形同步?
這正是音頻特征提取器的職責所在——它采用了名為Whisper的強大工具。
音頻特征提取器(Whisper)是什么?
想象一位訓練有素的聽覺專家。
這位專家不僅能識別詞語,更能分析發音的細微特征——音色、語調、語速甚至停頓。
隨后生成一份詳細的語音"藍圖",供其他系統(如我們的LatentSync UNet)用于驅動逼真的唇形運動。
LatentSync中的音頻特征提取器就是這樣的專業聽覺系統。它采用特殊的AI模型Whisper。雖然Whisper以語音轉文本(自動語音識別ASR)著稱,但LatentSync僅使用其編碼器模塊,將原始音頻轉換為高維音頻嵌入向量。
這些嵌入向量可視為語音的數字化"藍圖",不是具體文字,而是捕捉語音微妙特征的數值化表征。
這些特征正是UNet理解不同發音對應唇形運動的關鍵(例如發"o"音時的圓唇動作或發"p"音時的閉唇動作)。
為什么使用"嵌入向量"而非純文本?
可能有人疑惑:為何不直接給UNet提供文本(如"你好")?原因很簡單——純文本包含的語音信息不足。
對比以下兩個句子:
- “什么?”(快速疑問語氣)
- “什么。”(緩慢陳述語氣)
文字相同但發音特征迥異,對應的唇形運動也不同。
音頻嵌入向量能捕捉這些細微差別——編碼音素(最小語音單位)、韻律(節奏/重音/語調)等豐富信息,指導UNet生成自然精準的唇形動作。
長音頻處理與效率優化(分塊與緩存)
視頻可能很長,逐幀處理音頻特征效率低下。音頻特征提取器進行了專門優化:
- 分塊處理:不一次性處理完整音頻,而是
將音頻特征切分為對應短視頻片段的"塊",使處理更高效 - 特征緩存:
提取后的特征會被保存。當相同音頻再次處理時可直接讀取緩存,節省大量計算資源
流程集成方式
如第1章所述,唇形同步推理流程是總調度者,它指示音頻特征提取器獲取所需音頻線索:
# 唇形同步流程核心代碼片段
whisper_feature = self.audio_encoder.audio2feat(audio_path)
whisper_chunks = self.audio_encoder.feature2chunks(feature_array=whisper_feature, fps=video_fps)
audio2feat():提取完整音頻特征"藍圖"feature2chunks():將特征切分為UNet可處理的片段
技術實現
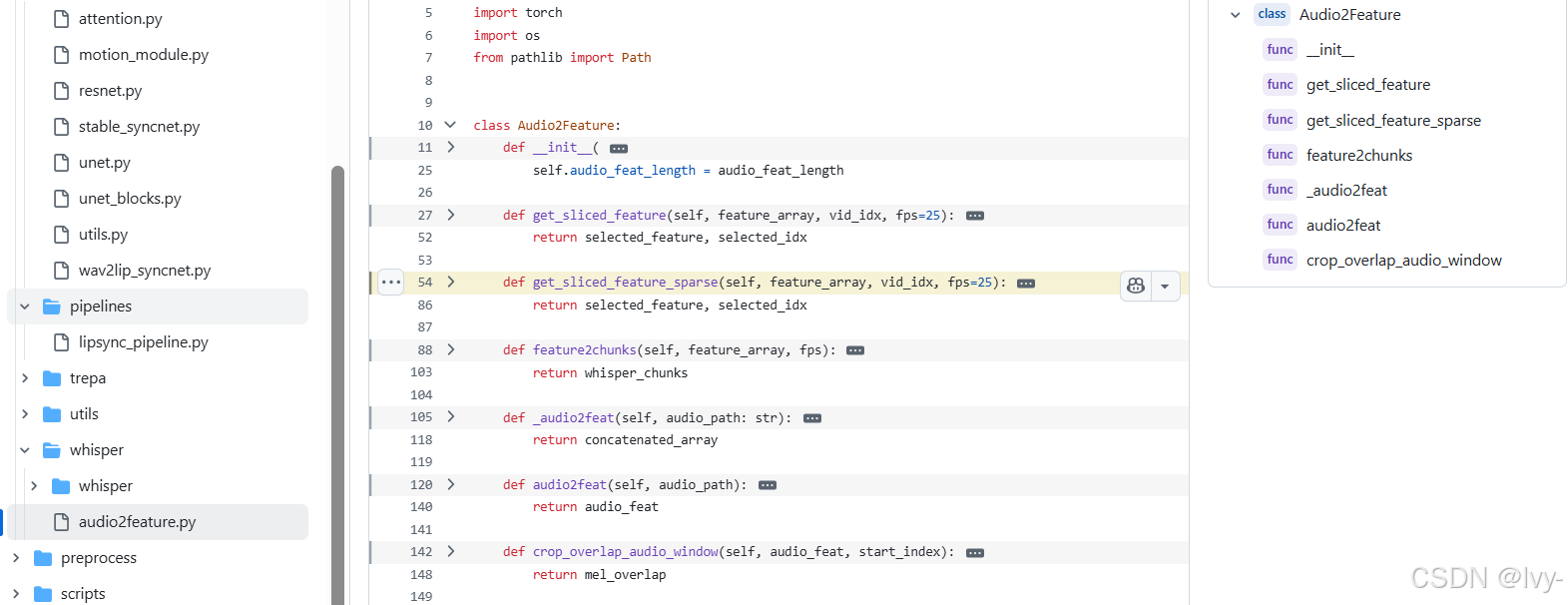
核心代碼位于latentsync/whisper/audio2feature.py:
1. 初始化構造
class Audio2Feature:def __init__(self, model_path="checkpoints/whisper/tiny.pt"):self.model = load_model(model_path) # 加載輕量版Whisper模型self.audio_embeds_cache_dir = None # 特征緩存目錄
2. 特征提取與緩存
def audio2feat(self, audio_path):if 特征已緩存:return 讀取緩存else:features = self._audio2feat(audio_path) # 實際特征提取保存緩存(features)return features
3. Whisper核心處理
def _audio2feat(self, audio_path):result = self.model.transcribe(audio_path) # 調用Whisper模型return result["encoder_embeddings"] # 提取編碼器嵌入向量
4. 特征分塊處理
def feature2chunks(self, feature_array, fps):# 按視頻幀率切分音頻特征return [self.get_sliced_feature(feature_array, i, fps) for i in range(總幀數)]
總結
音頻特征提取器(Whisper)是LatentSync的"聽覺中樞",它:
- 利用Whisper編碼器生成富含
語音特征的嵌入向量 - 通過智能緩存大幅提升處理效率
- 將長音頻
切分為UNet可處理的時序塊 - 為唇形同步提供精準的發音特征指導
下一章將介紹另一位重要"專家"——SyncNet唇形同步評判器,它負責確保生成的唇形動作達到最佳真實感。
下一章:SyncNet唇形同步評判器








Ansible)







:Skywalking 與 Easyearch 集成)


