上一篇文章在介紹完信號的產生和保存后,我們現在對信號有了一個基本的認識,信號由鍵盤、系統調用、硬件異常、軟件條件等方式產生,然后被保存在三張表中,再將信號遞達,操作系統有三種處理方式:默認處理、忽略處理、自定義處理。雖然我們現在已經知道這三種處理方式,但是操作系統底層是到底怎么做到在合適的時候處理信號?合適的時候又是什么時候呢?下面我們就來深入了解。
1. 信號捕捉的流程
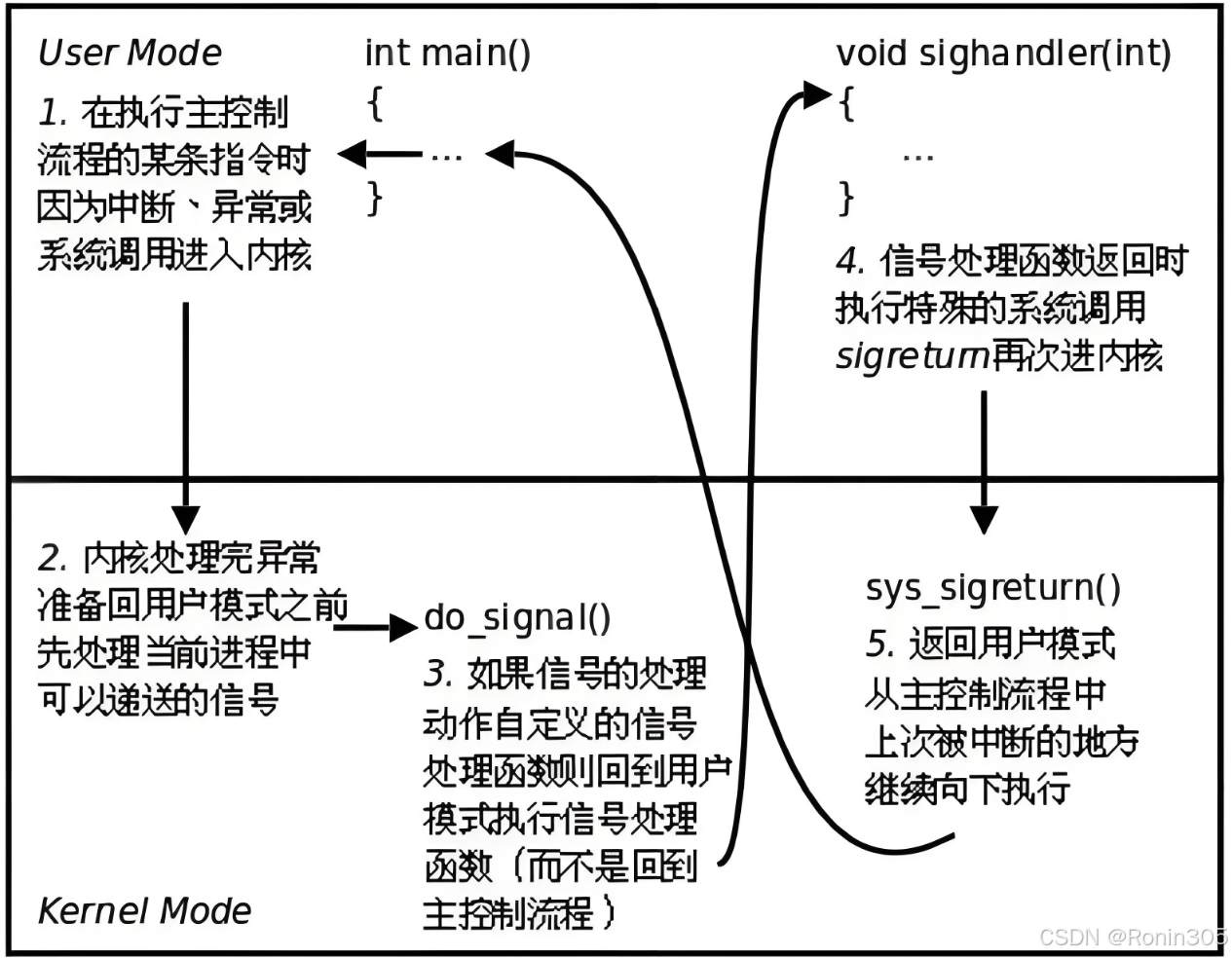
- 用戶態(Ring 3):運行應用程序代碼,權限受限
- 內核態(Ring 0):運行操作系統代碼,擁有最高權限
- 關鍵設計:用戶自定義函數必須在用戶態執行,防止惡意代碼獲取內核特權
信號捕捉的完整流程
1. 信號處理函數注冊
// 用戶程序注冊SIGQUIT信號的處理函數
signal(SIGQUIT, sighandler);進程通過?
signal()?或?sigaction()?系統調用,告訴內核:"當收到 SIGQUIT 信號時,請調用我的?sighandler?函數"。內核將此信息記錄在進程的?
task_struct->sighand->action[SIGQUIT]?中。
2. 正常執行與信號產生
進程正在用戶態執行?
main?函數中的代碼。此時,一個 SIGQUIT 信號產生(例如用戶按下了 Ctrl+\)。
內核收到信號,檢查目標進程的信號屏蔽字,如果信號未被阻塞,則設置該信號的未決標志。
3. 內核態到用戶態的返回檢查
當進程因系統調用、中斷或異常進入內核態,處理完畢后準備返回用戶態時,內核會執行一個關鍵操作:檢查當前進程是否有未決的、未被阻塞的信號。
這就是所謂的"在返回用戶態之前檢查信號"。
4. 信號遞達與處理框架構建
如果發現有待處理的信號,且其處理方式是用戶自定義函數,內核不會簡單地返回原來的用戶態執行上下文,而是:
在內核棧中保存完整的用戶態上下文,包括所有寄存器狀態、指令指針等。
修改用戶態棧幀,精心構造一個特殊的棧結構,使得從內核態返回時,CPU 會開始執行信號處理函數。
修改指令指針,使其指向信號處理函數?
sighandler?的地址。安排返回用戶態后首先執行?
sighandler?函數。
5. 執行信號處理函數
進程返回用戶態,但不再是繼續執行?
main?函數,而是開始執行?sighandler。sighandler?與?main?函數使用不同的棧幀,它們是兩個獨立的控制流。信號處理函數在一個特殊的上下文中運行,它可以看到信號編號作為參數,但不知道被信號中斷的代碼執行到了哪里。
6. 信號處理函數返回
當?
sighandler?執行到?return?語句時,并不是返回到?main?函數中被中斷的地方。而是執行一個特殊的系統調用?
sigreturn()(這通常由 C 庫自動處理,對程序員透明)。
7. 恢復原始上下文
sigreturn()?系統調用再次進入內核態。內核從之前保存的上下文信息中恢復原來的用戶態棧幀和寄存器狀態。
內核清除信號處理相關的臨時數據結構。
8. 返回正常執行
如果沒有新的信號要遞達,內核這次真正地恢復?
main?函數的上下文。進程繼續從原來被信號中斷的地方執行,就像什么都沒有發生過一樣。
關鍵技術細節
1. 內核棧與用戶棧的協作
內核需要精心管理兩種棧:
內核棧:存儲內核態執行時的數據,包括保存的用戶態上下文。
用戶棧:信號處理函數?
sighandler?在執行時使用的棧。
內核會在用戶棧上構建一個特殊的幀(Frame),使得信號處理函數能夠正常執行并在返回時調用?sigreturn。
2. sigreturn 系統調用的重要性
sigreturn?是信號處理機制中的關鍵環節,它的作用是:
通知內核信號處理已經完成
讓內核恢復之前保存的上下文
清理為信號處理設置的臨時結構
3. 信號處理函數的限制
由于信號處理函數的執行上下文特殊,它受到很多限制:
只能調用異步信號安全的函數(如?
write,但不能調用?printf、malloc?等)需要避免處理全局數據時的競態條件
應該盡量簡單快速地執行完畢
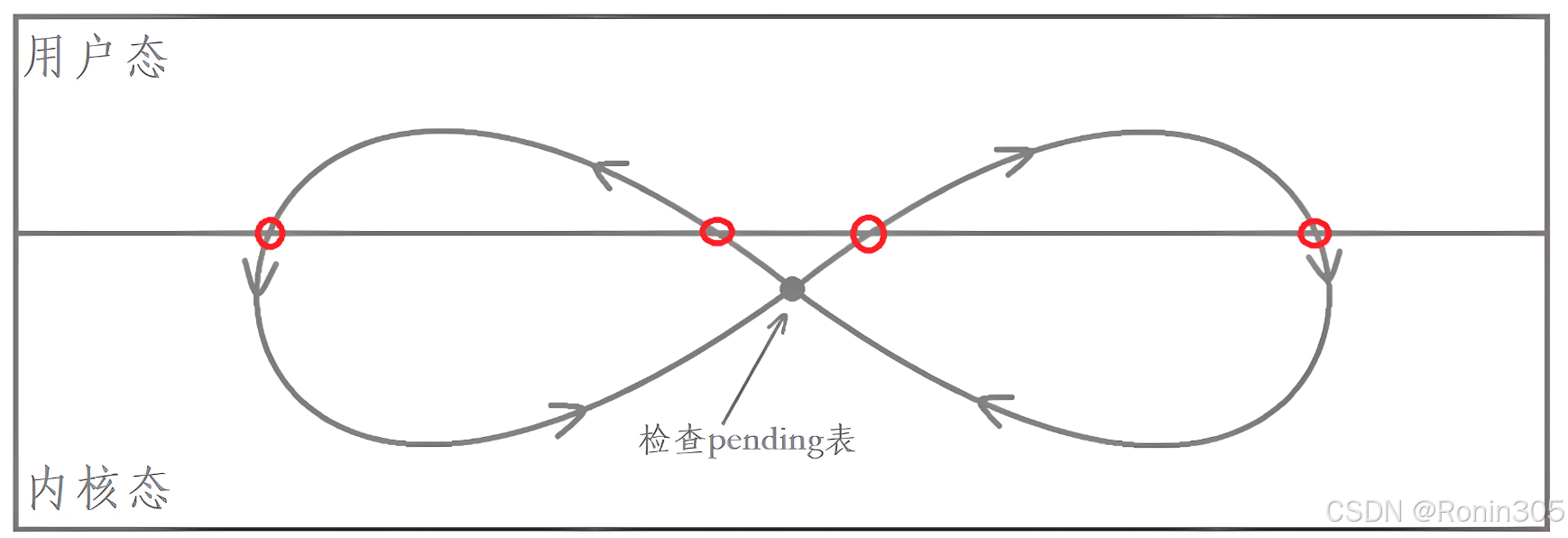
四重狀態切換的本質
| 切換點 | 方向 | CPU特權級 | 觸發機制 | 目的 |
|---|---|---|---|---|
| 1 (用戶→內核) | 系統調用/中斷 | 3→0 | 硬件中斷指令 | 進入內核處理事件 |
| 2 (內核→用戶) | 執行handler | 0→3 | 內核修改CS:EIP | 安全執行用戶代碼 |
| 3 (用戶→內核) | 調用sigreturn | 3→0 | 軟中斷(int 0x80) | 返回內核恢復上下文 |
| 4 (內核→用戶) | 恢復主程序 | 0→3 | 恢復原CS:EIP | 繼續執行被中斷代碼 |
💡?為什么需要四次切換?
若直接從內核態執行用戶函數:
- 危險:用戶代碼可能破壞內核棧
- 失控:無法保證返回路徑安全
2.?sigaction函數詳解
?sigaction?是 Linux/UNIX 系統中用于精細控制信號行為的核心系統調用,相比傳統的?signal()?函數,它提供了更強大的功能(如信號屏蔽、附加數據傳遞)和更可靠的行為。
函數原型
#include <signal.h>int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);參數說明
signum:要操作的信號編號(如?SIGINT,?SIGTERM?等)act:指向?struct sigaction?的指針,包含新的信號處理配置
如果為?
NULL,則不改變信號的處理方式
oldact:指向?struct sigaction?的指針,用于保存信號先前的處理配置
如果為?
NULL,則不保存舊配置
返回值
成功時返回?
0失敗時返回?
-1?并設置?errno
struct sigaction?結構體
這是?sigaction?函數的核心,它包含了信號處理的完整配置:
struct sigaction {void (*sa_handler)(int); // 簡單的信號處理函數void (*sa_sigaction)(int, siginfo_t *, void *); // 高級信號處理函數sigset_t sa_mask; // 在執行處理函數期間要阻塞的信號集int sa_flags; // 修改信號行為的標志位void (*sa_restorer)(void); // 已廢棄,不應使用
};關鍵字段詳解
1. 信號處理函數選擇
sa_handler?和?sa_sigaction?實際上是同一個聯合體的不同字段,只能使用其中一個:
sa_handler:簡單的信號處理函數,只接收信號編號作為參數void handler(int sig) {// 處理信號 }sa_sigaction:高級信號處理函數,接收更多信息void handler(int sig, siginfo_t *info, void *ucontext) {// 可以訪問更多關于信號的信息 }使用哪個函數由?
sa_flags?中的?SA_SIGINFO?標志決定。
2.?sa_mask?- 執行處理函數期間阻塞的信號
指定在信號處理函數執行期間,額外需要阻塞的信號集合
即使沒有明確指定,當前正在處理的信號也會被自動阻塞
這可以防止信號處理函數被同一信號重入(遞歸調用)
工作流程:
- 內核自動將?
sa_mask?中的信號添加到進程的阻塞信號集 - 處理函數結束后自動恢復原阻塞集
- 內核自動將?
3.?sa_flags?- 行為標志位
通過位掩碼組合來修改信號行為,常用標志包括:
| 標志 | 說明 |
|---|---|
SA_SIGINFO | 使用?sa_sigaction?而不是?sa_handler?作為處理函數 |
SA_RESTART | 被信號中斷的系統調用自動重啟(推薦設置) |
SA_NOCLDSTOP | 如果?signum?是?SIGCHLD,當子進程停止時不接收通知 |
SA_NOCLDWAIT | 如果?signum?是?SIGCHLD,不創建僵尸進程 |
SA_NODEFER | 在執行處理函數期間不自動阻塞當前信號(不推薦) |
SA_RESETHAND | 信號處理完成后重置為默認動作(類似?signal()?的不可靠行為) |
siginfo_t?結構體(當使用?SA_SIGINFO?時)
當設置了?SA_SIGINFO?標志時,信號處理函數可以接收更多信息:
siginfo_t {int si_signo; // 信號編號int si_errno; // 錯誤號(如果有)int si_code; // 信號來源代碼pid_t si_pid; // 發送信號的進程IDuid_t si_uid; // 發送信號的進程的真實用戶IDvoid *si_addr; // 導致錯誤的內存地址(對于SIGSEGV等)int si_status; // 退出值或信號(對于SIGCHLD)// ... 其他字段
}與?signal()?的區別
| 特性 | signal() | sigaction() |
|---|---|---|
| 可移植性 | 不同系統行為不一致 | POSIX 標準,行為一致 |
| 控制精度 | 有限 | 精細控制 |
| 信號阻塞 | 自動阻塞當前信號 | 可自定義阻塞信號集 |
| 系統調用重啟 | 依賴具體實現 | 可通過?SA_RESTART?明確控制 |
| 信號信息 | 只能獲取信號編號 | 可獲取詳細信息(siginfo_t) |
| 推薦程度 | 已過時,不推薦在新代碼中使用 | 現代程序的首選 |
示例:
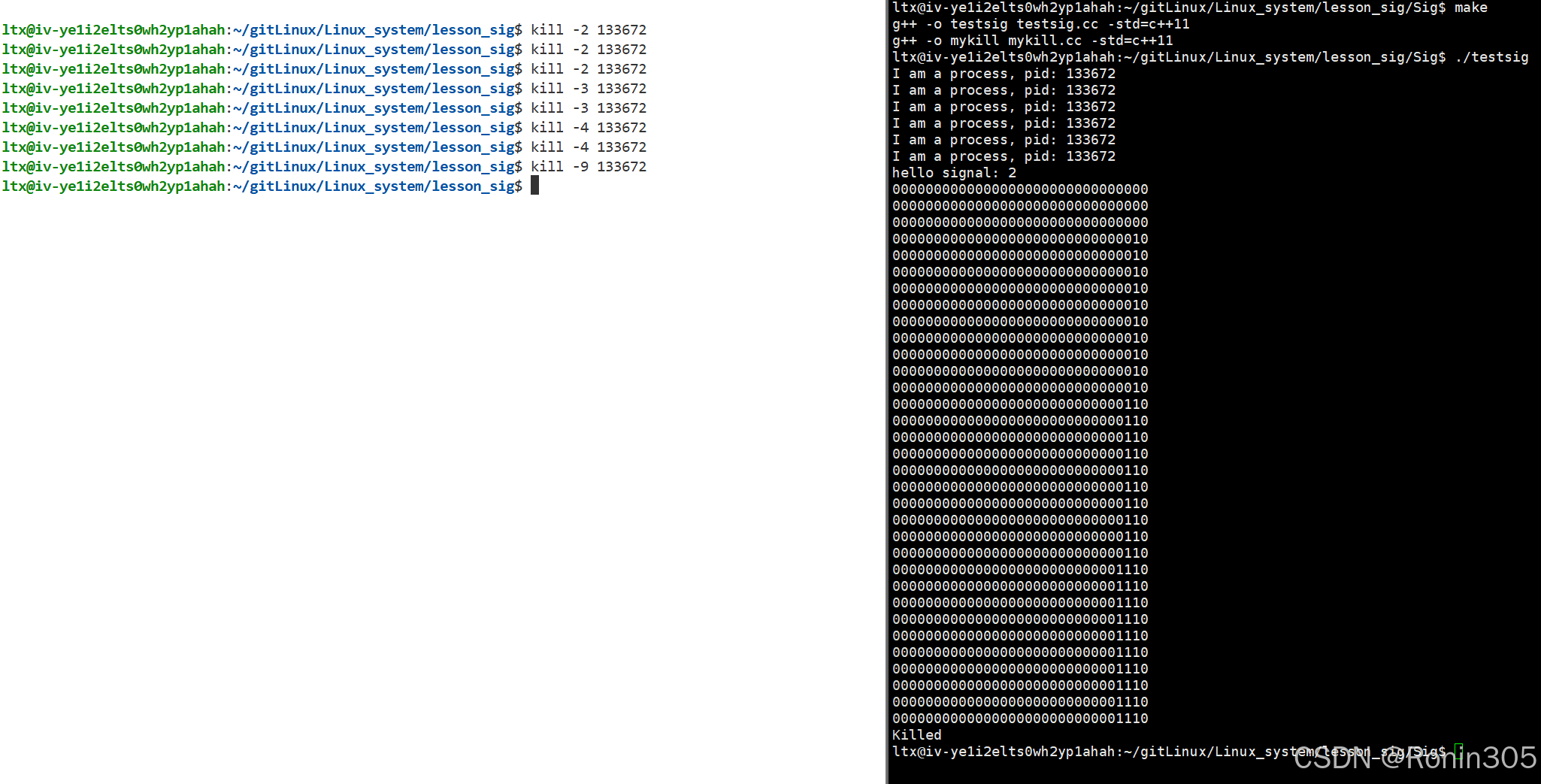
void handler(int signum)
{std::cout << "hello signal: " << signum << std::endl;while(true){//不斷獲取pending表!sigset_t pending;sigpending(&pending);for(int i = 31; i >= 1; i--){if(sigismember(&pending, i))std::cout << "1";elsestd::cout << "0";}std::cout << std::endl;sleep(1);}exit(0);
}int main()
{struct sigaction act, oldact;act.sa_handler = handler;sigemptyset(&act.sa_mask);sigaddset(&act.sa_mask, 3);sigaddset(&act.sa_mask, 4);act.sa_flags = 0;// 默認信號處理邏輯sigaction(SIGINT, &act, &oldact); // 對2號信號進行捕捉while(true){std::cout << "I am a process, pid: " << getpid() << std::endl;sleep(1);}return 0;
}將3號和4號信號加入到阻塞表中,使用?sigaction?來捕獲?SIGINT?信號,第一次捕獲2號信號時,會執行我們自定義函數handler,所以第一次捕獲到2號信號時,pending表中2號信號并不處于未決狀態,因為已經在執行自定義函數了,然后會在handler中死循環獲取pending表,所以我們后續不斷發送2號,3號和4號信號時,都會被屏蔽,也就是阻塞住,那么pending表中這些信號就會因為阻塞處于未決狀態。
運行結果:
總結:
在Linux信號處理機制中,當進程捕獲到某個信號并觸發其處理函數時,內核會自動執行以下重要操作:
- 信號屏蔽機制
- 內核首先將該信號自動加入進程的信號屏蔽字(signal mask)
- 這種設計確保了在處理某個信號期間,如果同類型信號再次產生,會被阻塞直到當前處理完成
- 這種機制有效避免了信號處理函數的遞歸調用問題
- 擴展屏蔽功能(sa_mask字段)
- 通過sigaction結構的sa_mask字段,可以指定需要額外屏蔽的信號集
- 這些被屏蔽的信號會在信號處理期間被暫時阻塞
- 處理函數返回時,系統會自動恢復原先的信號屏蔽字狀態
- 示例:處理SIGINT時可能需要同時屏蔽SIGQUIT
- 其他字段說明
- sa_flags:包含控制信號處理行為的各種選項標志
- 常見選項包括SA_RESTART(中斷系統調用自動重啟)
- 本節示例代碼中統一設為0表示使用默認行為
- sa_sigaction:用于實時信號處理的擴展函數指針
- 與標準信號處理函數sa_handler互斥
- 提供更豐富的信號上下文信息(如發送者PID)
- 本章不涉及實時信號的詳細處理機制
補充說明:
- 這種自動屏蔽機制對于保證信號處理的原子性至關重要
- 典型應用場景:在信號處理函數中修改全局變量時避免競態條件
- 錯誤示例:若未屏蔽相關信號,處理SIGALRM時再次收到SIGALRM可能導致處理函數重入
3.?操作系統是怎么運行的
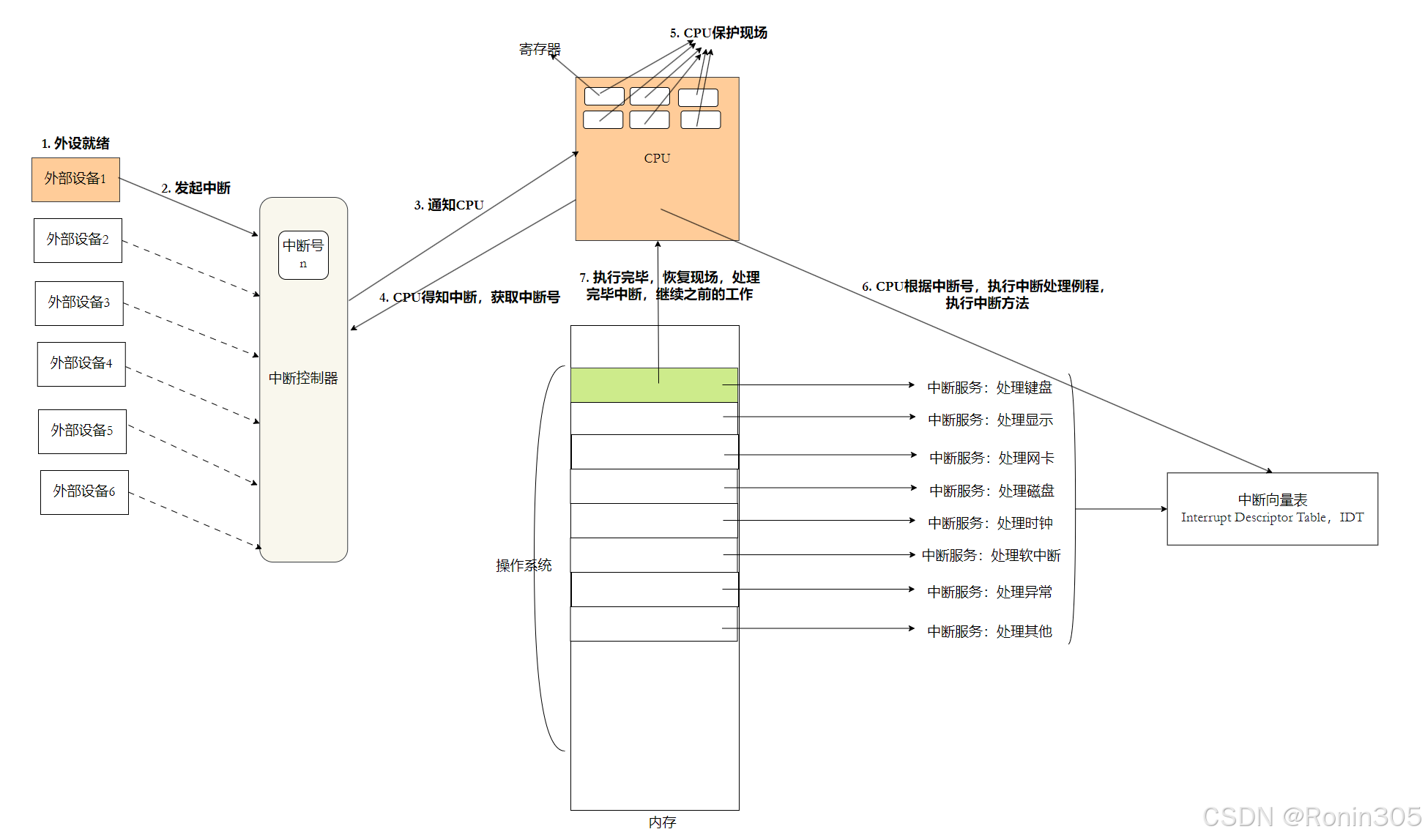
3.1 硬件中斷
硬件中斷的本質
什么是硬件中斷?
硬件中斷是外部設備(如鍵盤、磁盤、網卡)向CPU發出的信號,表示需要處理某個事件或請求服務。這是一種異步事件,可以在任何時候發生,打斷CPU當前正在執行的任務,其核心目的是避免CPU輪詢外設造成的資源浪費。
基本概念
中斷請求(IRQ):硬件設備發出的中斷信號
中斷向量:唯一標識中斷類型的編號
中斷處理程序:對應每個中斷向量的處理函數
中斷控制器:管理和優先級排序多個中斷請求的硬件
觸發原理:
當設備完成操作(如磁盤讀取結束)或狀態變化(如按鍵按下),通過?中斷控制器(如8259A)?向CPU發送中斷請求(IRQ)。
硬件協作流程:
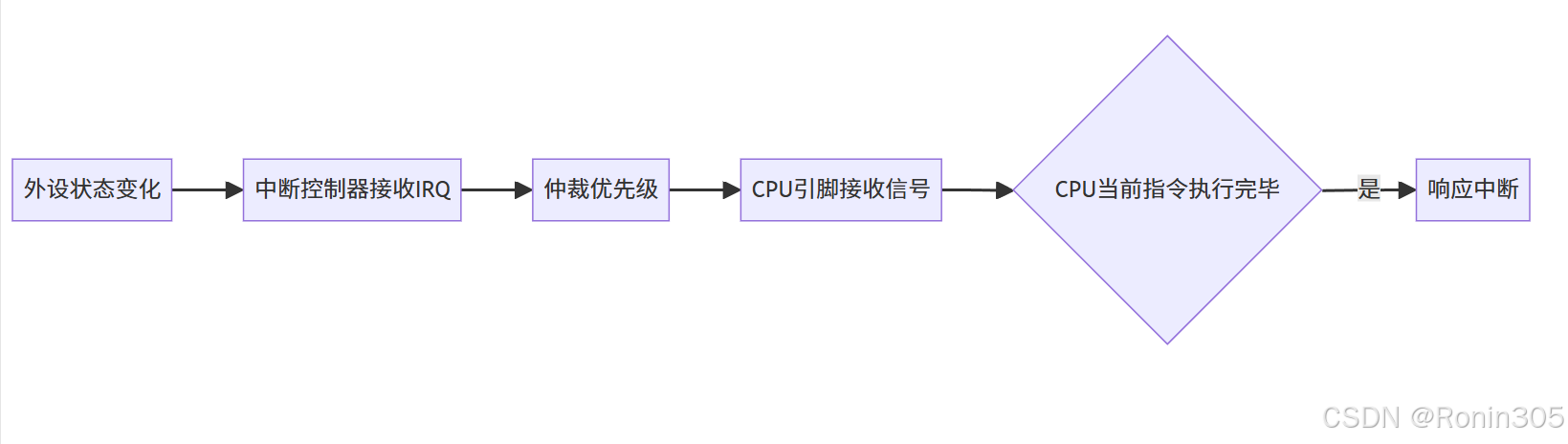
📌?關鍵設計:CPU僅在指令邊界檢查中斷,確保指令原子性。
中斷向量表:操作系統的中斷調度中樞
中斷向量表(IDT)?是操作系統啟動時加載到內存的數據結構,實現中斷號到處理程序的映射。
1. 核心組成與初始化
| 組件 | 作用 | Linux 0.11示例 |
|---|---|---|
| 中斷門(Interrupt Gate) | 處理外部硬件中斷,自動禁用中斷響應 | set_intr_gate(0x24, rs1_interrupt)(串口中斷) |
| 陷阱門(Trap Gate) | 處理內部異常(如除零錯誤),允許嵌套中斷 | set_trap_gate(14, &page_fault)(缺頁異常) |
| 中斷屏蔽寄存器 | 控制中斷使能狀態 | outb(inb_p(0x21) & \~0x01, 0x21)(開啟時鐘中斷) |
2. 中斷號解析機制
- 中斷號 = 中斷向量表偏移量,如IRQ0(時鐘中斷)對應向量0x20。
- 中斷向量條目包含:
- 處理程序入口地址(
&timer_interrupt) - CPU狀態字(權限級別、棧指針等)。
- 處理程序入口地址(
//Linux內核0.11源碼
void trap_init(void)
{int i;set_trap_gate(0,÷_error);// 設置除操作出錯的中斷向量值。以下雷同。set_trap_gate(1,&debug);set_trap_gate(2,&nmi);set_system_gate(3,&int3); /* int3-5 can be called from all */set_system_gate(4,&overflow);set_system_gate(5,&bounds);set_trap_gate(6,&invalid_op);set_trap_gate(7,&device_not_available);set_trap_gate(8,&double_fault);set_trap_gate(9,&coprocessor_segment_overrun);set_trap_gate(10,&invalid_TSS);set_trap_gate(11,&segment_not_present);set_trap_gate(12,&stack_segment);set_trap_gate(13,&general_protection);set_trap_gate(14,&page_fault);set_trap_gate(15,&reserved);set_trap_gate(16,&coprocessor_error);// 下?將int17-48 的陷阱?先均設置為reserved,以后每個硬件初始化時會重新設置??的陷阱?。for (i=17;i<48;i++)set_trap_gate(i,&reserved);set_trap_gate(45,&irq13);// 設置協處理器的陷阱?。outb_p(inb_p(0x21)&0xfb,0x21);// 允許主8259A 芯?的IRQ2 中斷請求。outb(inb_p(0xA1)&0xdf,0xA1);// 允許從8259A 芯?的IRQ13 中斷請求。set_trap_gate(39,¶llel_interrupt);// 設置并??的陷阱?。
}
void rs_init (void)
{set_intr_gate (0x24, rs1_interrupt); // 設置串??1 的中斷?向量(硬件IRQ4信號)。set_intr_gate (0x23, rs2_interrupt); // 設置串??2 的中斷?向量(硬件IRQ3信號)。init (tty_table[1].read_q.data); // 初始化串??1(.data 是端?號)。init (tty_table[2].read_q.data); // 初始化串??2。outb (inb_p (0x21) & 0xE7, 0x21); // 允許主8259A 芯?的IRQ3,IRQ4 中斷信號請求。
}完整處理流程圖:
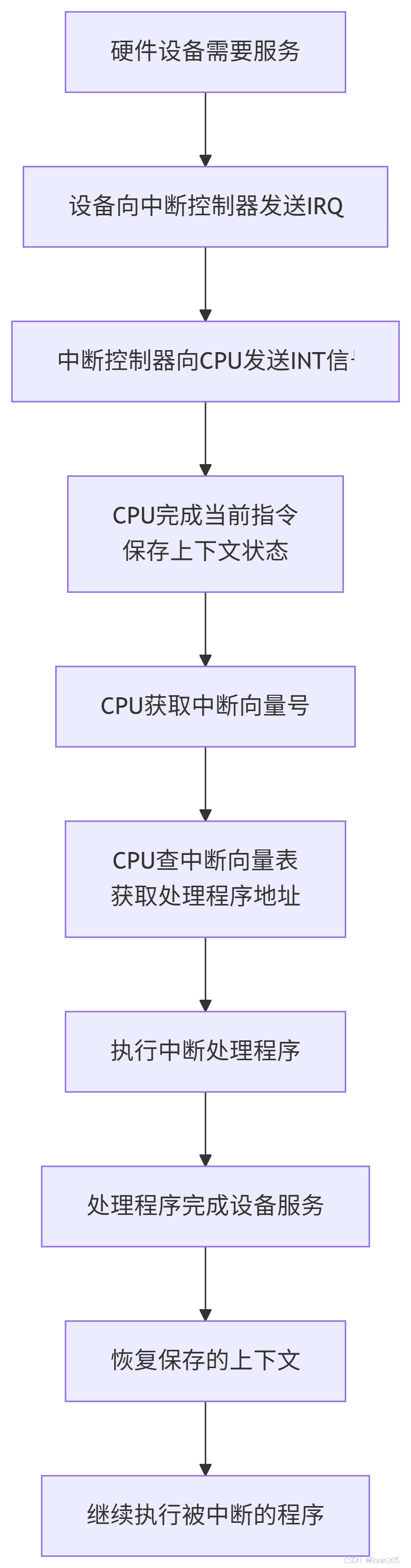
CPU中斷響應全流程深度解析
一、中斷觸發階段:從請求到CPU感知
1.?中斷請求的產生
中斷源分類:
- 外部硬件中斷:由外設(如鍵盤、磁盤、網卡)通過物理引腳(IRQ)發出請求。
- 內部異常:CPU執行指令時觸發(如除零錯誤、缺頁異常)。
- 軟中斷:由程序主動發起(如
int 0x80系統調用)。
中斷控制器的仲裁:
中斷請求首先送達中斷控制器(如8259A或APIC),進行優先級仲裁: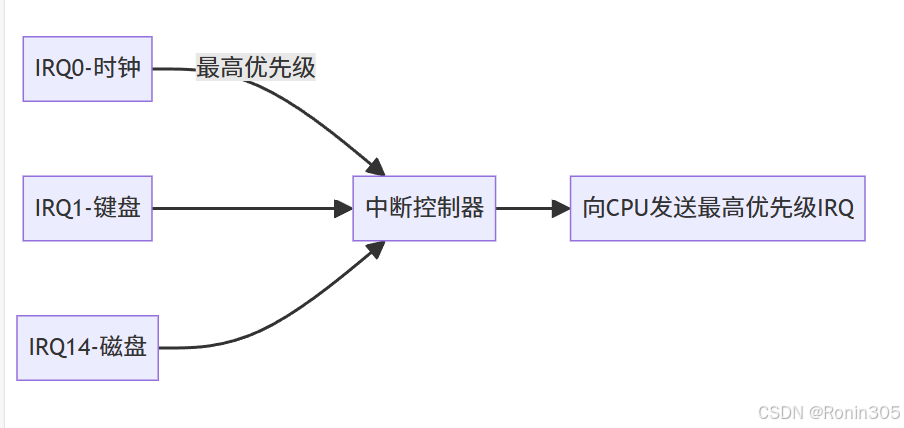
控制器通過菊花鏈或并行仲裁確定優先級。
2.?CPU的響應條件
CPU僅在同時滿足以下條件時響應中斷:
- 當前指令執行完畢:確保指令原子性。
- 中斷未被屏蔽:
- 全局中斷使能標志
IF=1(x86的STI指令開啟)。 - 該中斷在中斷屏蔽寄存器(IMR)中未被禁用。
- 全局中斷使能標志
- 無更高優先級中斷處理中:避免嵌套中斷導致狀態混亂。
📌?關鍵細節:x86架構中,
NMI(不可屏蔽中斷)無視IF標志,用于處理硬件故障等緊急事件。
二、硬件自動操作:上下文保存與跳轉
1.?現場保護(由CPU微碼自動完成)
當CPU決定響應中斷時,硬件依次執行:
壓棧保護關鍵寄存器:
- 程序計數器(PC/IP)?:保存下一條待執行指令地址(斷點)。
- 程序狀態字(PSW/FLAGS)?:保存當前CPU狀態(如中斷使能位)。
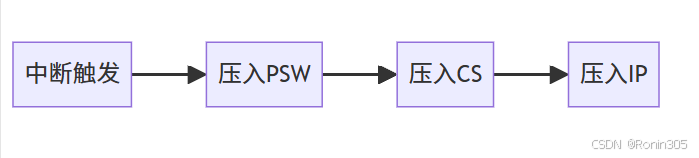
?? 此過程無需軟件介入,由CPU硬件直接完成。
關閉中斷響應:
自動清除IF標志(CLI等效操作),防止同級中斷干擾。
2.?跳轉至中斷處理程序
- 查詢中斷向量表(IDT):
CPU根據中斷向量號(如0x20對應時鐘中斷),在IDT中定位處理程序入口地址。 - 加載入口地址:
將CS:IP設置為中斷服務程序(ISR)的入口,開始執行ISR。
🔧?操作系統角色:啟動時初始化IDT,例如Linux 0.11綁定時鐘中斷:
set_intr_gate(0x20, &timer_interrupt); // 0x20向量→timer_interrupt
三、中斷服務階段:操作系統的接管與處理
1.?保存完整上下文(操作系統責任)
ISR首先保存所有可能被破壞的寄存器,確保主程序狀態無損:
; x86示例
pushad ; 保存通用寄存器
push ds
push es ; 保存段寄存器
此步驟由操作系統編寫,需覆蓋所有架構相關寄存器。
2.?中斷服務程序(ISR)的核心邏輯
設備交互:
- 讀取設備狀態寄存器(如鍵盤掃描碼端口
0x60)。 - 清除設備中斷請求標志。
- 讀取設備狀態寄存器(如鍵盤掃描碼端口
通知中斷控制器:
發送EOI(End of Interrupt)信號:outb(0x20, 0x20); // x86 8259A的EOI喚醒關聯任務:
若中斷關聯進程(如磁盤I/O完成),調用wake_up()喚醒等待隊列。觸發軟中斷(可選):
將耗時操作移交軟中斷線程(如Linux的ksoftirqd)。
3.?中斷嵌套管理
允許嵌套的條件:
sti(); // 顯式開啟中斷,允許高優先級中斷搶占需謹慎控制嵌套深度,避免棧溢出。
嵌套現場保護:
每次嵌套需獨立保存上下文,形成中斷棧幀鏈。
四、中斷返回:恢復與繼續執行
1.?恢復現場
彈出寄存器:
pop es pop ds popad ; 恢復通用寄存器執行返回指令:
iret指令自動從棧中恢復IP、CS、PSW。
2.?返回主程序
CPU根據恢復的PC值繼續執行被中斷的指令流,如同未發生中斷。
一張圖總結:
3.2 時鐘中斷
問題
? 操作系統自己被誰指揮,被誰推動執行?
答案:操作系統被時鐘中斷指揮和推動執行。
操作系統不是一個主動的"管理者",而是一個被動的"響應者"。它通過時鐘中斷這個規律性的心跳來獲得執行機會,從而進行調度、管理和維護工作。
? 有沒有可以定期觸發的設備?
答案:有,這就是系統定時器/時鐘芯片。
計算機中有專門的硬件定時器(如8253/8254 PIT或HPET),它們能夠以固定的頻率產生中斷信號,這就是時鐘中斷的來源。
時鐘中斷的硬件基礎
系統定時器硬件
8253/8254 PIT(可編程間隔定時器):傳統PC中的定時器芯片
HPET(高精度事件定時器):現代系統中的高精度定時器
APIC定時器:多處理器系統中的本地定時器
定時器工作原理
定時器芯片被編程為以特定頻率(如100Hz或1000Hz)生成中斷信號。這意味著每秒會產生100次或1000次時鐘中斷。
Linux 0.11 時鐘中斷機制詳解
初始化過程
// 在sched_init()中設置時鐘中斷
void sched_init(void) {// ...set_intr_gate(0x20, &timer_interrupt); // 設置時鐘中斷處理程序outb(inb_p(0x21) & ~0x01, 0x21); // 允許時鐘中斷(IRQ0)// ...
}時鐘中斷處理程序
// 匯編代碼:timer_interrupt
_timer_interrupt:push %dspush %eaxmovl $0x10, %eaxmov %ax, %dsmovb $0x20, %aloutb %al, $0x20 # 向8259A發送EOI(中斷結束)信號movl $0, %eaxincl %eaxmovl %eax, jiffies # 更新系統時鐘滴答計數pushl $0x10 # 參數:CPL(當前特權級)call _do_timer # 調用C函數處理定時任務popl %eaxpopl %eaxpop %dsiretdo_timer 函數:核心處理邏輯
// kernel/sched.c
void do_timer(long cpl) {extern int beepcount;extern void sysbeepstop(void);// 更新系統時間if (beepcount)if (!--beepcount)sysbeepstop();// 更新當前進程時間片if (--current->counter > 0)return;// 時間片用完,需要重新調度current->counter = 0;schedule(); // 調用調度程序
}調度函數 schedule
// kernel/sched.c
void schedule(void) {int i, next, c;struct task_struct **p;// 尋找就緒狀態且counter值最大的進程while (1) {c = -1;next = 0;i = NR_TASKS;p = &task[NR_TASKS];while (--i) {if (!*--p)continue;if ((*p)->state == TASK_RUNNING && (*p)->counter > c)c = (*p)->counter, next = i;}if (c) break; // 找到了可運行的進程// 所有進程的時間片都已用完,重新分配時間片for (p = &LAST_TASK; p > &FIRST_TASK; --p)if (*p)(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;}// 切換到選中的進程switch_to(next);
}時鐘中斷的完整工作流程
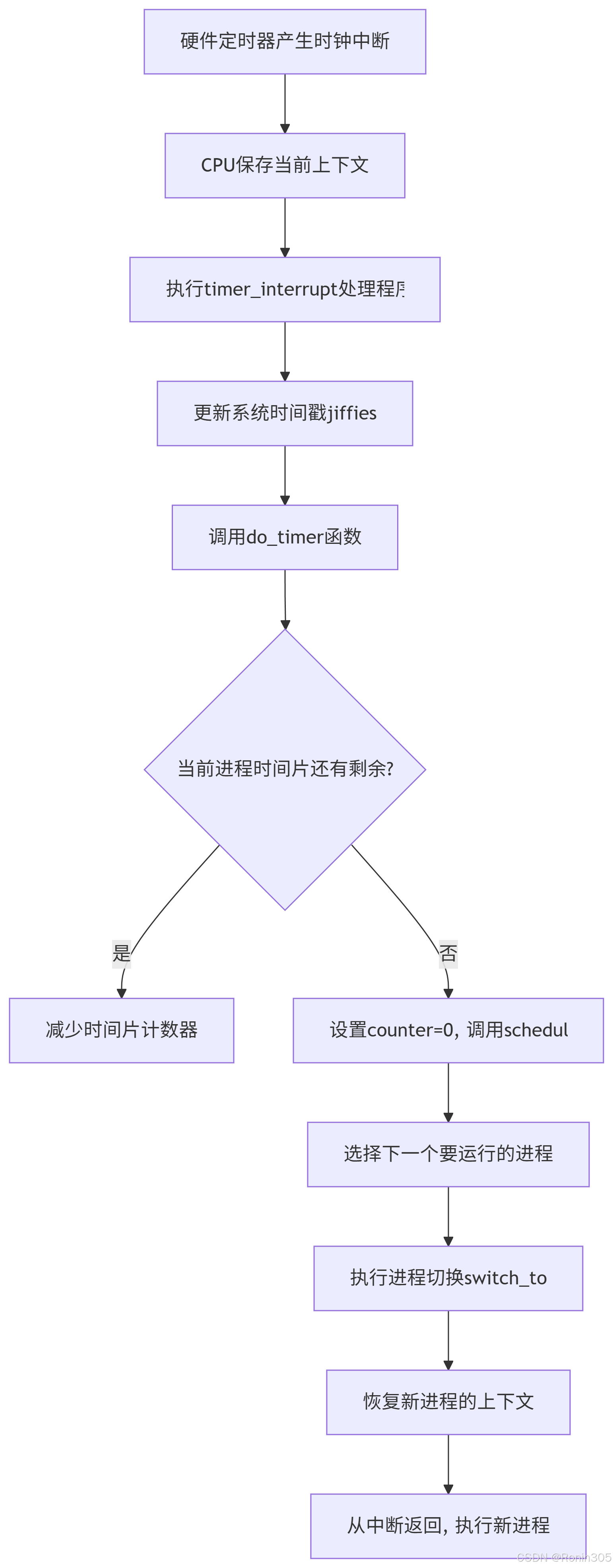
?時間片與調度機制
時間片(Time Quantum)
每個進程被分配一個執行時間單位(時間片)
在Linux 0.11中,時間片大小與進程的
counter值相關時鐘中斷每次發生時,當前進程的
counter減1當
counter減到0時,進程被剝奪CPU使用權
優先級與時間片分配
// 重新計算時間片的公式
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;這個公式確保:
進程的剩余時間片會繼承一半到下一個周期
加上固定的優先級值,保證每個周期都有基本的時間片
優先級高的進程獲得更多CPU時間
??調度算法演進
原始輪轉調度(Linux 0.11):
if (timer++ % 2 == 0) pcb = pcb_A; // 簡單交替執行 else pcb = pcb_B;現代O(1)調度器(Linux 2.6+):
- 使用
active/expired雙隊列避免遍歷 - 時間片耗盡時移入
expired隊列:if (--current->time_slice <= 0) move_to_expired_queue(current);
- 使用
在前面章節進程調度時,我們對O(1)調度有做過詳細介紹
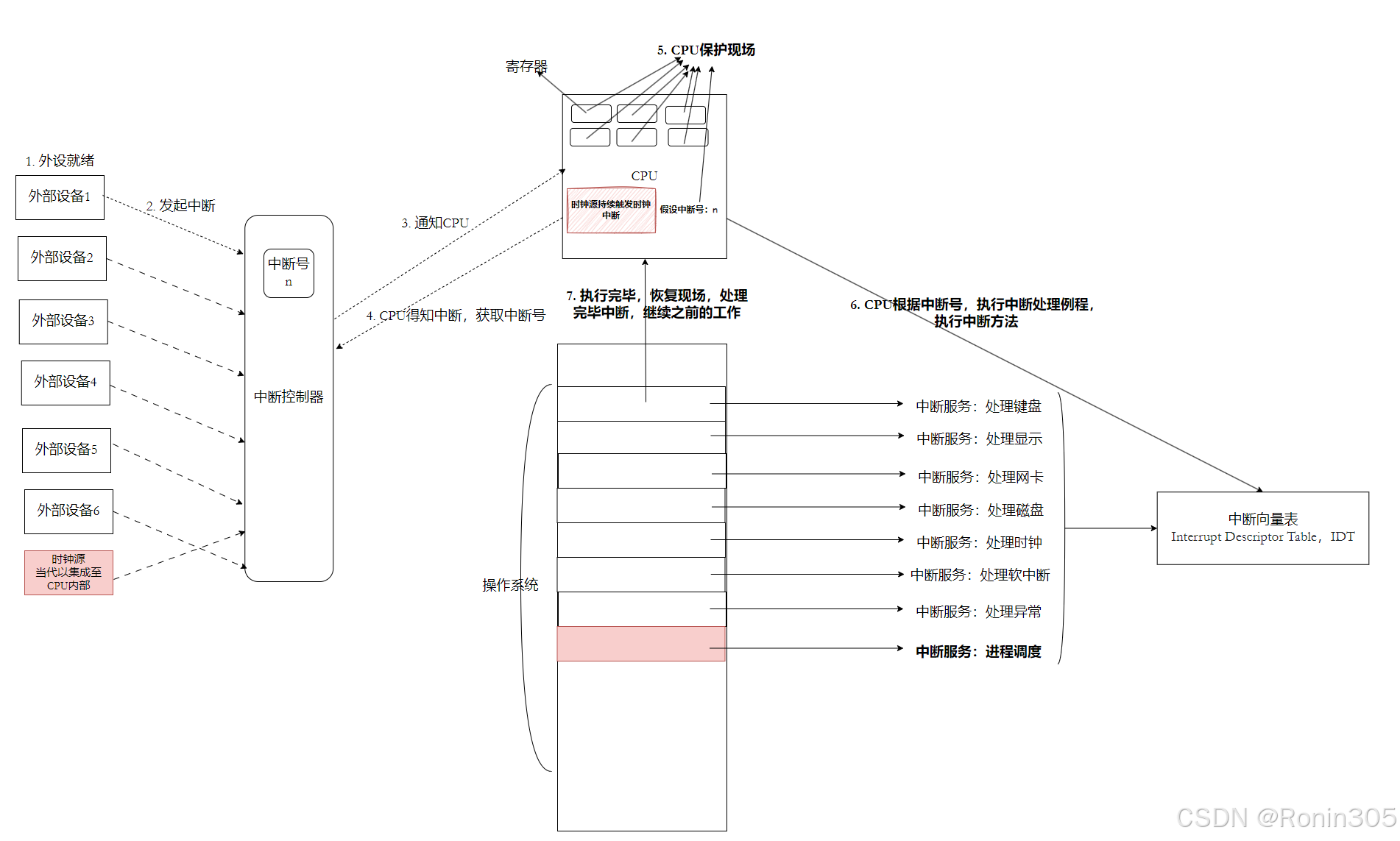
時鐘中斷的多重角色
時鐘中斷不僅是進程調度的觸發器,還負責:
1. 系統時間維護
通過jiffies變量記錄系統啟動后的時鐘滴答數,維護系統時間。
2. 內核統計信息更新
更新系統負載統計、進程運行時間統計等。
3. 定時器處理
處理內核和進程設置的各種定時器(timer)。
4. 資源監控
監控系統資源使用情況,必要時進行回收或調整。
一張圖總結:
3.3 死循環
如果是這樣,操作系統不就可以躺平了嗎?對,操作系統自己不做任何事情,需要什么功能,就向中斷向量表里面添加方法即可。操作系統的本質:就是一個死循環!
Linux 0.11 的主函數結構
void main(void) {// 初始化階段:設置整個系統的基礎設施mem_init(); // 內存管理初始化trap_init(); // 中斷向量表初始化blk_dev_init(); // 塊設備初始化sched_init(); // 調度器初始化// ... 其他初始化工作// 創建init進程(用戶空間的第一個進程)if (!fork()) {init();}// 主循環:操作系統的"休息"狀態for (;;) {pause(); // 等待中斷發生}
}這個死循環的真正含義
不是忙等待:
pause()?系統調用會讓CPU進入低功耗狀態中斷驅動:只有在中斷發生時,CPU才會跳出暫停狀態
事件響應:操作系統作為中斷處理程序的"調度中心"
注意!! 對于任何其它的任務,'pause()'將意味著我們必須等待收到?個信號才會返回就緒運?態,但任務0(task0)是唯?的意外情況(參?'schedule()'),因為任務0 在任何空閑時間?都會被激活(當沒有其它任務在運?時),因此對于任務0'pause()'僅意味著我們返回來查看是否有其它任務可以運?,如果沒有的話我們就回到這?,?直循環執?'pause()'。
pause() 的內部機制
// pause() 的簡化實現
int pause(void) {// 將當前進程狀態設為可中斷睡眠current->state = TASK_INTERRUPTIBLE;// 調用調度器,選擇其他進程運行schedule();// 當信號到達時,從這里恢復執行return -EINTR;
}為什么使用 pause() 而不是空循環?
| 方式 | CPU使用率 | 功耗 | 響應速度 |
|---|---|---|---|
空循環(while(1);) | 100% | 高 | 即時 |
pause() | 接近0% | 低 | 依賴中斷響應時間 |
示例:時鐘中斷觸發調度
// 當時鐘中斷發生時
void timer_interrupt(void) {// 更新系統時間jiffies++;// 減少當前進程時間片current->counter--;// 如果時間片用完或需要調度if (current->counter <= 0) {schedule(); // 進程調度}
}在Linux內核的早期版本(如0.11版)中,任務調度機制有一個特殊設計:通常情況下,當任務調用pause()系統調用時,該任務會進入等待狀態,直到接收到信號才會返回就緒運行態。但任務0(即內核啟動后創建的第一個任務)是一個特例。
具體來說:
對于普通任務:
- 調用
pause()會使任務進入可中斷的等待狀態(TASK_INTERRUPTIBLE) - 任務會從運行隊列中移除
- 必須等待信號喚醒才能重新進入就緒隊列
- 調用
對于任務0的特殊處理:
- 當沒有其他任務需要運行時,調度器會主動選擇任務0
- 任務0的
pause()實現不同:它不會真正進入等待狀態 - 而是立即返回,讓調度器有機會再次檢查是否有其他任務需要運行
- 如果沒有其他任務,又回到任務0繼續執行
- 這樣就形成了一個"空閑循環":pause() -> schedule()檢查 -> 若無任務則繼續pause()
這種設計的原因:
- 任務0作為系統的空閑任務
- 需要保證CPU時刻都有任務在執行
- 通過這種特殊處理避免了CPU完全空閑的狀態
- 同時為后續可能出現的任務提供快速的響應能力
這種機制在內核代碼中的具體實現可以參考schedule()函數中的特殊處理邏輯,它會明確檢查當前任務是否是任務0,并做出不同的調度決策。
3. 4 軟中斷
上述外部硬件中斷,需要硬件設備通過特定信號線(如IRQ線)觸發。例如,當鍵盤按鍵被按下時,鍵盤控制器會通過中斷請求線向CPU發送電信號,CPU檢測到后會暫停當前任務處理中斷。
有沒有可能,因為軟件原因,也觸發上面的邏輯?有!這被稱為"軟件中斷"或"陷阱中斷"。這種中斷不是由外部設備產生,而是由CPU執行特定指令主動觸發。常見的場景包括:
- 除零錯誤等異常情況
- 調試斷點
- 系統調用
為了讓操作系統支持進行系統調用,CPU廠商設計了專門的匯編指令:
- x86架構使用int指令(如int 0x80)
- x86_64架構使用syscall/sysenter指令
- ARM架構使用SWI/SVC指令 這些指令會讓CPU內部產生中斷邏輯,切換到內核模式。
與硬件中斷的對比
| 特性 | 硬件中斷 | 軟中斷(系統調用) | 設計意義 |
|---|---|---|---|
| 觸發源 | 外設(鍵盤、磁盤等) | 程序指令(int 0x80) | 用戶主動請求內核服務 |
| 可預測性 | 隨機性高 | 精確控制觸發時機 | 保障程序邏輯完整性 |
| 權限切換 | 自動進入內核態 | 通過指令顯式切換 | 安全隔離用戶與內核空間? |
軟中斷的觸發原理
- 指令級操作:
- x86架構:
int 0x80?或?sysenter?指令引發CPU異常,向量號128(0x80)對應系統調用入口?。 - ARM架構:
svc(Supervisor Call)指令實現同等效果?。
- x86架構:
問題:
1. 用戶層如何傳遞系統調用號給操作系統?
通過寄存器傳遞(以x86架構為例)
EAX寄存器是傳遞系統調用號的主要寄存器:
; 示例:調用write系統調用
mov eax, 4 ; 將write的系統調用號存入EAX
mov ebx, 1 ; 第一個參數:文件描述符(stdout)
mov ecx, buffer ; 第二個參數:緩沖區地址
mov edx, length ; 第三個參數:數據長度
int 0x80 ; 觸發軟中斷不同架構的寄存器使用
| 架構 | 系統調用號寄存器 | 參數寄存器 | 調用指令 |
|---|---|---|---|
| x86 (32位) | EAX | EBX, ECX, EDX, ESI, EDI, EBP | int 0x80 |
| x86-64 | RAX | RDI, RSI, RDX, R10, R8, R9 | syscall |
| ARM | R7 | R0-R6 | svc 0 |
2. 操作系統如何返回結果給用戶?
通過寄存器返回簡單結果
對于簡單的返回值(如整數、指針),操作系統通過EAX/RAX寄存器返回:
// 系統調用處理函數示例
asmlinkage long sys_getpid(void) {return current->pid; // 返回值通過EAX傳遞給用戶程序
}通過用戶提供的緩沖區返回復雜數據
對于復雜數據結構或大量數據,操作系統將數據寫入用戶提供的緩沖區:
// 讀取文件數據的系統調用
asmlinkage long sys_read(unsigned int fd, char __user *buf, size_t count) {// ... 從文件讀取數據copy_to_user(buf, kernel_buffer, bytes_read); // 將數據復制到用戶空間return bytes_read; // 返回實際讀取的字節數
}錯誤處理
系統調用通過兩種方式報告錯誤:
返回負的錯誤碼:通常返回
-errno設置全局errno變量:標準庫會將其轉換為正數并設置errno
// 用戶程序中的錯誤處理
int fd = open("file.txt", O_RDONLY);
if (fd == -1) {// open系統調用返回-1,標準庫設置errnoperror("open failed"); // 輸出"open failed: No such file or directory"
}3. 系統調用號的本質:數組下標
系統調用表結構
系統調用號確實是數組下標,指向系統調用表中的函數指針:
// 系統調用函數指針表
fn_ptr sys_call_table[] = {sys_setup, sys_exit, sys_fork, sys_read,sys_write, sys_open, sys_close, sys_waitpid,// ... 更多系統調用
};系統調用分發
當用戶程序執行系統調用時,內核使用系統調用號作為索引:
// 通過系統調用號索引函數指針表
call [sys_call_table + eax * 4]這里:
eax?包含系統調用號每個函數指針占4字節(32位系統)
通過?
eax * 4?計算偏移量,找到對應的系統調用處理函數
完整的系統調用流程
步驟1:用戶層準備
// 用戶程序調用write()
write(fd, buffer, count);// 標準庫將其轉換為系統調用
mov eax, 4 ; SYS_write = 4
mov ebx, fd ; 文件描述符
mov ecx, buffer ; 緩沖區地址
mov edx, count ; 字節數
int 0x80 ; 觸發軟中斷內核處理流程
保存用戶態上下文:CPU自動保存寄存器狀態
切換到內核態:提升特權級別,使用內核棧
查找系統調用表:根據系統調用號找到處理函數
參數驗證:檢查用戶提供的參數是否有效
執行系統調用:調用對應的內核函數
返回用戶態:恢復保存的上下文,降低特權級別
步驟2:進入內核態
; 系統調用入口點(kernel/system_call.s)
_system_call:; 1. 驗證系統調用號有效性cmp eax, nr_system_calls-1ja bad_sys_call; 2. 保存用戶態寄存器push dspush espush fspush edxpush ecxpush ebx; 3. 設置內核數據段mov edx, 0x10mov ds, dxmov es, dx; 4. 調用對應的系統調用處理函數call [sys_call_table + eax * 4]; 5. 保存返回值push eax步驟3:執行系統調用處理函數
// write系統調用的實現(fs/read_write.c)
int sys_write(unsigned int fd, char *buf, int count) {// ... 實際的文件寫入邏輯return bytes_written; // 返回寫入的字節數
}步驟4:返回用戶態
; 恢復上下文并返回
pop eax ; 獲取系統調用返回值
pop ebx ; 恢復寄存器
pop ecx
pop edx
pop fs
pop es
pop ds
iret ; 返回到用戶空間更多Linux0.11內核源碼:
// sys.h
// 系統調?函數指針表。?于系統調?中斷處理程序(int 0x80),作為跳轉表。
extern int sys_setup (); // 系統啟動初始化設置函數。 (kernel/blk_drv/hd.c,71)
extern int sys_exit (); // 程序退出。 (kernel/exit.c, 137)
extern int sys_fork (); // 創建進程。 (kernel/system_call.s, 208)
extern int sys_read (); // 讀?件。 (fs/read_write.c, 55)
extern int sys_write (); // 寫?件。 (fs/read_write.c, 83)
extern int sys_open (); // 打開?件。 (fs/open.c, 138)
extern int sys_close (); // 關閉?件。 (fs/open.c, 192)
extern int sys_waitpid (); // 等待進程終?。 (kernel/exit.c, 142)
extern int sys_creat (); // 創建?件。 (fs/open.c, 187)
extern int sys_link (); // 創建?個?件的硬連接。 (fs/namei.c, 721)
extern int sys_unlink (); // 刪除?個?件名(或刪除?件)。 (fs/namei.c, 663)
extern int sys_execve (); // 執?程序。 (kernel/system_call.s, 200)
extern int sys_chdir (); // 更改當前?錄。 (fs/open.c, 75)
extern int sys_time (); // 取當前時間。 (kernel/sys.c, 102)
extern int sys_mknod (); // 建?塊/字符特殊?件。 (fs/namei.c, 412)
extern int sys_chmod (); // 修改?件屬性。 (fs/open.c, 105)
extern int sys_chown (); // 修改?件宿主和所屬組。 (fs/open.c, 121)
extern int sys_break (); // (-kernel/sys.c, 21)
extern int sys_stat (); // 使?路徑名取?件的狀態信息。 (fs/stat.c, 36)
extern int sys_lseek (); // 重新定位讀/寫?件偏移。 (fs/read_write.c, 25)
extern int sys_getpid (); // 取進程id。 (kernel/sched.c, 348)
extern int sys_mount (); // 安裝?件系統。 (fs/super.c, 200)
extern int sys_umount (); // 卸載?件系統。 (fs/super.c, 167)
extern int sys_setuid (); // 設置進程??id。 (kernel/sys.c, 143)
extern int sys_getuid (); // 取進程??id。 (kernel/sched.c, 358)
extern int sys_stime (); // 設置系統時間?期。 (-kernel/sys.c, 148)
extern int sys_ptrace (); // 程序調試。 (-kernel/sys.c, 26)
extern int sys_alarm (); // 設置報警。 (kernel/sched.c, 338)
extern int sys_fstat (); // 使??件句柄取?件的狀態信息。(fs/stat.c, 47)
extern int sys_pause (); // 暫停進程運?。 (kernel/sched.c, 144)
extern int sys_utime (); // 改變?件的訪問和修改時間。 (fs/open.c, 24)
extern int sys_stty (); // 修改終端?設置。 (-kernel/sys.c, 31)
extern int sys_gtty (); // 取終端?設置信息。 (-kernel/sys.c, 36)
extern int sys_access (); // 檢查??對?個?件的訪問權限。(fs/open.c, 47)
extern int sys_nice (); // 設置進程執?優先權。 (kernel/sched.c, 378)
extern int sys_ftime (); // 取?期和時間。 (-kernel/sys.c,16)
extern int sys_sync (); // 同步?速緩沖與設備中數據。 (fs/buffer.c, 44)
extern int sys_kill (); // 終??個進程。 (kernel/exit.c, 60)
extern int sys_rename (); // 更改?件名。 (-kernel/sys.c, 41)
extern int sys_mkdir (); // 創建?錄。 (fs/namei.c, 463)
extern int sys_rmdir (); // 刪除?錄。 (fs/namei.c, 587)
extern int sys_dup (); // 復制?件句柄。 (fs/fcntl.c, 42)
extern int sys_pipe (); // 創建管道。 (fs/pipe.c, 71)
extern int sys_times (); // 取運?時間。 (kernel/sys.c, 156)
extern int sys_prof (); // 程序執?時間區域。 (-kernel/sys.c, 46)
extern int sys_brk (); // 修改數據段?度。 (kernel/sys.c, 168)
extern int sys_setgid (); // 設置進程組id。 (kernel/sys.c, 72)
extern int sys_getgid (); // 取進程組id。 (kernel/sched.c, 368)
extern int sys_signal (); // 信號處理。 (kernel/signal.c, 48)
extern int sys_geteuid (); // 取進程有效??id。 (kenrl/sched.c, 363)
extern int sys_getegid (); // 取進程有效組id。 (kenrl/sched.c, 373)
extern int sys_acct (); // 進程記帳。 (-kernel/sys.c, 77)
extern int sys_phys (); // (-kernel/sys.c, 82)
extern int sys_lock (); // (-kernel/sys.c, 87)
extern int sys_ioctl (); // 設備控制。 (fs/ioctl.c, 30)
extern int sys_fcntl (); // ?件句柄操作。 (fs/fcntl.c, 47)
extern int sys_mpx (); // (-kernel/sys.c, 92)
extern int sys_setpgid (); // 設置進程組id。 (kernel/sys.c, 181)
extern int sys_ulimit (); // (-kernel/sys.c, 97)
extern int sys_uname (); // 顯?系統信息。 (kernel/sys.c, 216)
extern int sys_umask (); // 取默認?件創建屬性碼。 (kernel/sys.c, 230)
extern int sys_chroot (); // 改變根系統。 (fs/open.c, 90)
extern int sys_ustat (); // 取?件系統信息。 (fs/open.c, 19)
extern int sys_dup2 (); // 復制?件句柄。 (fs/fcntl.c, 36)
extern int sys_getppid (); // 取?進程id。 (kernel/sched.c, 353)
extern int sys_getpgrp (); // 取進程組id,等于getpgid(0)。(kernel/sys.c, 201)
extern int sys_setsid (); // 在新會話中運?程序。 (kernel/sys.c, 206)
extern int sys_sigaction (); // 改變信號處理過程。 (kernel/signal.c, 63)
extern int sys_sgetmask (); // 取信號屏蔽碼。 (kernel/signal.c, 15)
extern int sys_ssetmask (); // 設置信號屏蔽碼。 (kernel/signal.c, 20)
extern int sys_setreuid (); // 設置真實與/或有效??id。 (kernel/sys.c,118)
extern int sys_setregid (); // 設置真實與/或有效組id。 (kernel/sys.c, 51)// 系統調?函數指針表。?于系統調?中斷處理程序(int 0x80),作為跳轉表。
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,sys_setreuid, sys_setregid
};// 調度程序的初始化?程序。
void sched_init(void)
{...// 設置系統調?中斷?。set_system_gate(0x80, &system_call);
}_system_call:cmp eax,nr_system_calls-1 ;// 調?號如果超出范圍的話就在eax 中置-1 并退出。ja bad_sys_callpush ds ;// 保存原段寄存器值。push espush fspush edx ;// ebx,ecx,edx 中放著系統調?相應的C 語?函數的調?參數。push ecx ;// push %ebx,%ecx,%edx as parameterspush ebx ;// to the system callmov edx,10h ;// set up ds,es to kernel spacemov ds,dx ;// ds,es 指向內核數據段(全局描述符表中數據段描述符)。mov es,dxmov edx,17h ;// fs points to local data spacemov fs,dx ;// fs 指向局部數據段(局部描述符表中數據段描述符)。
;// 下?這句操作數的含義是:調?地址 = _sys_call_table + %eax * 4。參?列表后的說明。
;// 對應的C 程序中的sys_call_table 在include/linux/sys.h 中,其中定義了?個包括72個
;// 系統調?C 處理函數的地址數組表。call [_sys_call_table+eax*4]push eax ;// 把系統調?號?棧。mov eax,_current ;// 取當前任務(進程)數據結構地址??eax。
;// 下?97-100 ?查看當前任務的運?狀態。如果不在就緒狀態(state 不等于0)就去執?調度程序。
;// 如果該任務在就緒狀態但counter[??]值等于0,則也去執?調度程序。cmp dword ptr [state+eax],0 ;// statejne reschedulecmp dword ptr [counter+eax],0 ;// counterje reschedule
;// 以下這段代碼執?從系統調?C 函數返回后,對信號量進?識別處理。
ret_from_sys_call:?可是為什么我們用的系統調用,從來沒有見過什么 int 0x80 或者 syscall 呢?都是直接調用上層的函數的啊?
?那是因為Linux的gnu C標準庫(glibc),給我們把幾乎所有的系統調用全部封裝了。glibc作為用戶空間和內核之間的橋梁,它:
- 提供了POSIX標準接口
- 處理了不同架構的系統調用差異
- 添加了錯誤處理和緩沖區管理等額外功能
- 維護了向后兼容性
系統調用封裝機制深度解析:從?int 0x80?到透明 API 的演進
一、用戶不可見底層指令的核心原因:Glibc 的標準化封裝
用戶編程時無需直接調用?int 0x80?或?syscall?指令,是因為?GNU C 標準庫(glibc)?對系統調用進行了全棧抽象,其設計目標包括:
跨平臺兼容性
不同 CPU 架構使用不同的陷入指令:- x86 傳統:
int 0x80(32 位) - x86 現代:
sysenter/sysexit(32 位高效指令) - x86_64:
syscall(64 位專用指令) - ARM:
svc(Supervisor Call)
glibc 通過宏定義屏蔽差異,用戶只需調用?open()、read()?等標準函數
- x86 傳統:
安全邊界強化
直接執行匯編指令可能導致:- 寄存器設置錯誤引發內核崩潰
- 未經驗證參數導致安全漏洞
glibc 在封裝層添加以下安全檢查:// 偽代碼:glibc 對 write() 的封裝 ssize_t write(int fd, const void *buf, size_t count) {if (buf == NULL) return -EFAULT; // 指針有效性校驗if (count > MAX_IO_SIZE) return -EINVAL; // 參數范圍校驗return syscall(SYS_write, fd, buf, count); // 安全轉入內核 }
? ? ? 3.?錯誤處理標準化
內核返回?-ERRNO,glibc 自動設置?errno?并返回 -1,簡化用戶邏輯:
封裝示例:open()系統調用
// 應用程序員看到的接口
int fd = open("file.txt", O_RDONLY);// glibc內部的實現大致如下:
int open(const char *pathname, int flags, mode_t mode) {#ifdef __i386__return syscall(SYS_open, pathname, flags, mode);#elif __x86_64__return syscall(SYS_open, pathname, flags, mode);#elif __arm__return syscall(SYS_open, pathname, flags, mode);// ... 其他架構#endif
}二、系統調用號傳遞機制:宏的魔法
?#define SYS_ify(syscall_name) __NR_##syscall_name?是 glibc 的核心轉換引擎:
將用戶友好的系統調用名稱轉換為內核識別的系統調用號
編譯時轉換:
SYS_ify(open)?→ 預處理器展開為?__NR_open?→ 替換為數字(如 5)內核與用戶空間協作:
角色 職責 實現方式 內核 定義系統調用號 /include/uapi/asm/unistd.h?中定義?__NR_open=5glibc 映射名稱到編號 包含內核頭文件,使用? SYS_ify?宏轉換用戶程序 調用? open()無需感知數字編號
內核提供的系統調用號
系統調用號確實是由內核定義的,通常在內核頭文件中:
// 內核頭文件中的系統調用號定義(如asm/unistd_32.h)
#define __NR_restart_syscall 0
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5
// ...glibc的封裝宏
// glibc中的封裝宏
#define SYS_ify(syscall_name) __NR_##syscall_name// 使用示例
int syscall_num = SYS_ify(open); // 展開為 __NR_openglibc的系統調用封裝實現
不同架構的實現
glibc為每種架構提供了專門的系統調用封裝:
// i386架構的實現(使用int 0x80)
#define INTERNAL_SYSCALL(name, err, nr, args...) \internal_syscall##nr (__NR_##name, err, args)// x86_64架構的實現(使用syscall)
#define INTERNAL_SYSCALL(name, err, nr, args...) \internal_syscall##nr (__NR_##name, err, args)INTERNAL_SYSCALL_NCS 宏詳解
前面提到的宏是glibc內部用于實現系統調用的關鍵機制:
#define INTERNAL_SYSCALL_NCS(name, err, nr, args...) \
({ \unsigned long int resultvar; \LOAD_ARGS_##nr (args) \ // 加載參數到寄存器LOAD_REGS_##nr \ // 設置寄存器asm volatile ( \"syscall\n\t" \ // 執行syscall指令: "=a" (resultvar) \ // 輸出:結果放在resultvar: "0" (name) ASM_ARGS_##nr \ // 輸入:系統調用號和參數: "memory", "cc", "r11", "cx" \ // 破壞的寄存器); \(long int) resultvar; \ // 返回結果
})參數加載宏示例
// 加載3個參數的宏
#define LOAD_ARGS_3(a1, a2, a3) \register unsigned long int _a1 __asm__ ("rdi") = (unsigned long int) (a1); \register unsigned long int _a2 __asm__ ("rsi") = (unsigned long int) (a2); \register unsigned long int _a3 __asm__ ("rdx") = (unsigned long int) (a3);#define ASM_ARGS_3 , "r" (_a1), "r" (_a2), "r" (_a3)三、指令選擇策略:從?int 0x80?到?syscall?的進化
glibc 動態選擇最優陷入指令,其決策邏輯如下:
| 指令 | 觸發方式 | 性能開銷 | 適用場景 | glibc 選擇策略 |
|---|---|---|---|---|
int 0x80 | 軟中斷 | 高 (~200 cycles) | 老式 32 位 CPU | 兼容舊硬件 |
sysenter | 專用快速指令 | 中 (~50 cycles) | 32 位 Pentium II+ | 內核檢測 CPU 支持后啟用 |
syscall | 64 位原生指令 | 低 (~20 cycles) | 所有 x86_64 系統 | 64 位程序默認 |
從int 0x80到syscall
// 傳統int 0x80方式(i386)
#define INTERNAL_SYSCALL_INT80(name, err, nr, args...) \
({ \unsigned long int resultvar; \asm volatile ( \"int $0x80\n\t" \: "=a" (resultvar) \: "a" (__NR_##name) ASM_ARGS_##nr \: "memory", "cc" \); \(long int) resultvar; \
})// 現代syscall方式(x86_64)
#define INTERNAL_SYSCALL_SYSCALL(name, err, nr, args...) \
({ \unsigned long int resultvar; \asm volatile ( \"syscall\n\t" \: "=a" (resultvar) \: "0" (__NR_##name) ASM_ARGS_##nr \: "memory", "cc", "r11", "cx" \); \(long int) resultvar; \
})現代 glibc 的實現流程:
void* vsyscall_page = map_vsyscall(); // 映射內核提供的陷入指令頁if (cpu_supports_syscall()) {vsyscall_page->entry = syscall_instruction; // 64位優先使用 syscall
} else if (cpu_supports_sysenter()) {vsyscall_page->entry = sysenter_instruction; // 32位新機器用 sysenter
} else {vsyscall_page->entry = int80_instruction; // 舊機器回退到 int 0x80
}
兩種方式的對比
| 特性 | 直接系統調用 | 庫函數 |
|---|---|---|
| 可移植性 | 低(依賴具體架構) | 高(跨架構統一接口) |
| 易用性 | 低(需要處理底層細節) | 高(簡單函數調用) |
| 錯誤處理 | 需要手動處理 | 自動設置errno |
| 性能 | 稍好(少一層調用) | 稍差(多一層調用) |
| 類型安全 | 無 | 有參數類型檢查 |
💎?終極本質:glibc 是用戶態與內核間的?“協議轉換器”?,通過標準化封裝:
- 將底層硬件差異轉化為統一 API
- 將危險的裸系統調用轉化為安全調用
- 使應用程序員聚焦業務邏輯而非硬件細節
正如 Linux 內核開發者所述:“glibc 不是簡單的包裝,而是操作系統用戶體驗的最終定義者”
3.5?缺頁中斷?內存碎片處理?除零野指針錯誤?
缺頁中斷、內存碎片處理、除零錯誤、野指針訪問等系統級問題,在硬件層面都會被轉換為CPU內部的軟中斷信號。這些中斷信號會觸發預先注冊的中斷處理例程(Interrupt Service Routine),由操作系統內核完成相應的處理邏輯。
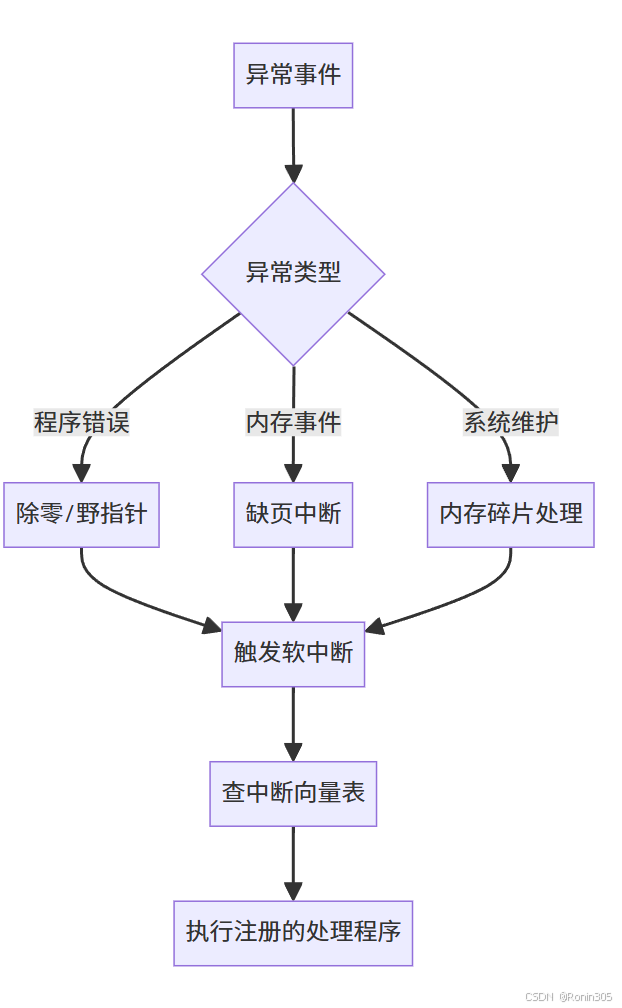
- 設計哲學:所有異常統一走中斷處理路徑,實現事件驅動架構(操作系統本質是"躺在中斷處理例程上的代碼塊")
三種類型的CPU內部事件
| 類型 | 觸發原因 | 示例 | 處理方式 |
|---|---|---|---|
| 陷阱 (Trap) | 程序主動請求 | 系統調用(int 0x80) | 執行請求的服務 |
| 故障 (Fault) | 可修復錯誤 | 缺頁異常 | 修復后重新執行指令 |
| 中止 (Abort) | 嚴重錯誤 | 硬件錯誤、雙重故障 | 終止進程 |
三類核心異常的處理機制
1. 缺頁中斷(Page Fault)
中斷號:x86為14(
#PF)觸發條件:
- 訪問未映射的虛擬地址
- 權限不足(用戶態訪問內核頁)
- 寫只讀頁(Copy-on-Write場景)
處理流程:
// Linux 0.11處理邏輯 void do_page_fault(struct pt_regs *regs) {unsigned long address = read_cr2(); // 讀取觸發地址if (handle_vmalloc_fault(address)) // 處理vmalloc區域return;if (handle_copy_on_write(address)) // 寫時復制處理return;__do_page_fault(address); // 核心頁表處理 }關鍵操作:
- 分配物理頁幀
- 建立頁表映射
- 重新執行觸發指令
📌?延遲分配優勢:節省90%內存初始化開銷(僅虛擬地址分配,物理內存按需分配)
2. 內存碎片處理
非直接中斷:由kswapd內核線程周期性執行
觸發條件:
- 缺頁中斷時發現連續物理頁不足
- 內存水位低于閾值(lowmem_reserve)
核心算法:
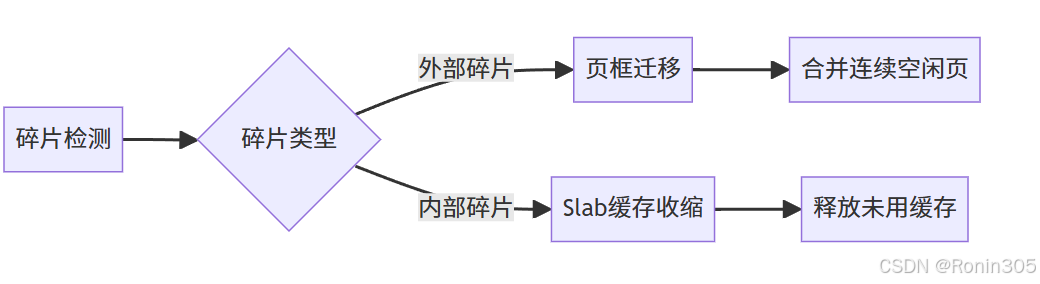
優化策略:
- 反碎片(Anti-Fragmentation)分組:
MOVABLE/RECLAIMABLE頁類型隔離 - Compaction機制:遷移頁框實現連續物理空間
- 反碎片(Anti-Fragmentation)分組:
3. 除零/野指針錯誤
中斷號:
- 除零錯誤:0(
#DE) - 野指針:13(
#GP通用保護錯誤)
- 除零錯誤:0(
處理流程:
// Linux 0.11異常處理鏈 void divide_error(void) {send_signal(current, SIGFPE); // 發送浮點異常信號 }void general_protection(void) {if (is_user_ptr_fault()) // 檢查是否用戶態野指針send_signal(current, SIGSEGV); // 發送段錯誤信號elsekernel_panic(); // 內核態錯誤直接崩潰 }信號傳遞機制:
錯誤類型 信號值 默認行為 可捕獲性 除零錯誤 SIGFPE 終止+core dump 是 野指針 SIGSEGV 終止+core dump 是
中斷向量表:異常處理的調度中樞
Linux 0.11通過trap_init()注冊異常處理程序:
void trap_init(void)
{int i;set_trap_gate(0,÷_error);// 設置除操作出錯的中斷向量值。以下雷同。set_trap_gate(1,&debug);set_trap_gate(2,&nmi);set_system_gate(3,&int3); /* int3-5 can be called from all */set_system_gate(4,&overflow);set_system_gate(5,&bounds);set_trap_gate(6,&invalid_op);set_trap_gate(7,&device_not_available);set_trap_gate(8,&double_fault);set_trap_gate(9,&coprocessor_segment_overrun);set_trap_gate(10,&invalid_TSS);set_trap_gate(11,&segment_not_present);set_trap_gate(12,&stack_segment);set_trap_gate(13,&general_protection);set_trap_gate(14,&page_fault);set_trap_gate(15,&reserved);set_trap_gate(16,&coprocessor_error);// 下?將int17-48 的陷阱?先均設置為reserved,以后每個硬件初始化時會重新設置??的陷阱?。for (i=17;i<48;i++)set_trap_gate(i,&reserved);set_trap_gate(45,&irq13);// 設置協處理器的陷阱?。outb_p(inb_p(0x21)&0xfb,0x21);// 允許主8259A 芯?的IRQ2 中斷請求。outb(inb_p(0xA1)&0xdf,0xA1);// 允許從8259A 芯?的IRQ13 中斷請求。set_trap_gate(39,¶llel_interrupt);// 設置并??的陷阱?。
}中斷門 vs 系統門:
| 類型 | 特權級切換 | 典型應用 | 注冊函數 |
|---|---|---|---|
| 陷阱門(Trap) | 不自動關中斷 | 除零/缺頁等異常 | set_trap_gate() |
| 系統門(System) | 允許用戶態觸發 | 系統調用(int 0x80) | set_system_gate() |
???關鍵區別:陷阱門處理期間不屏蔽中斷,允許更高優先級中斷搶占
異常分類學:陷阱與異常的本質區別
1.?陷阱(Trap)
- 本質:主動觸發的可控中斷
- 特點:
- 同步觸發(指令執行時立即發生)
- 返回后繼續執行下條指令
- 典型代表:系統調用(
int 0x80/syscall)
- 應用場景:
mov eax, 4 ; sys_write調用號 int 0x80 ; 主動觸發陷阱 ; 返回后繼續執行此處
2.?異常(Exception)
本質:非預期的錯誤事件
特點:
- 異步或同步觸發
- 可能無法恢復執行(如野指針)
- 典型代表:缺頁異常、除零錯誤
處理差異:
特性 陷阱(Trap) 異常(Exception) 觸發意圖 程序主動請求 程序非預期錯誤 返回位置 下條指令 可能無法返回 特權級 用戶態→內核態 當前特權級處理 典型應用 系統調用 硬件錯誤處理
總結:
📌 操作系統架構的核心要點:
? 操作系統本質上是通過中斷處理機制驅動的代碼集合!內核的主要功能都是通過響應各種中斷事件來實現的,包括:
- 硬件中斷(時鐘中斷、設備IO中斷)
- 軟件中斷(系統調用)
- 異常處理(CPU產生的錯誤條件)
? 在x86架構中,CPU內部的軟中斷分為兩類:
- 陷阱(Trap):由程序主動觸發的可控中斷,如:
- int 0x80(傳統系統調用)
- syscall/sysenter(現代快速系統調用)
- 異常(Exception):由CPU自動觸發的錯誤條件,如:
- 除零錯誤(#DE,中斷號0)
- 頁錯誤(#PF,中斷號14)
- 一般保護錯誤(#GP,中斷號13)
(現在可以理解"缺頁異常"的命名由來:它本質上是CPU在地址轉換過程中檢測到頁表無效時自動觸發的異常條件,屬于被動觸發的錯誤處理機制)
4.?如何理解內核態和用戶態
一、核心定義:特權級與地址空間的綁定
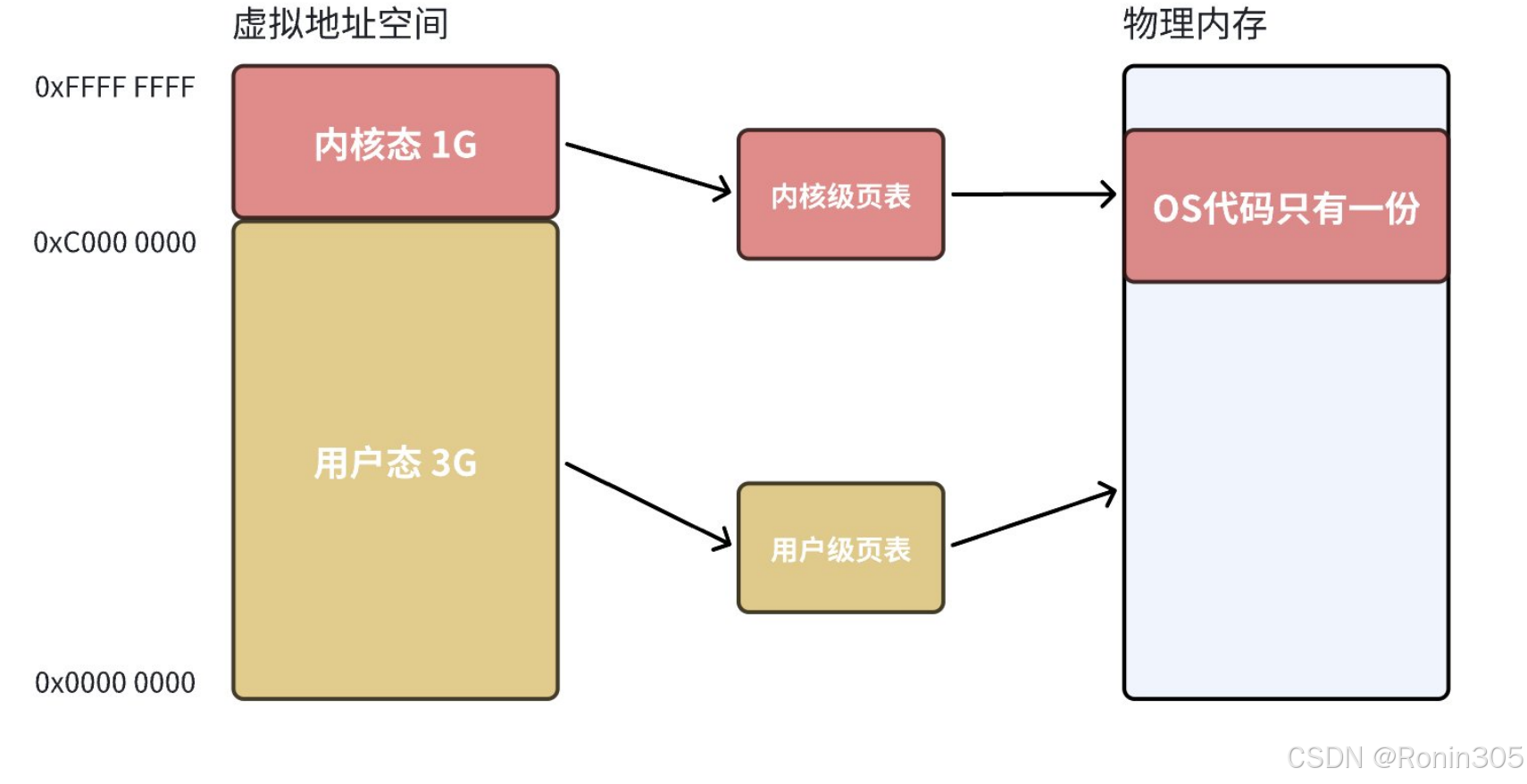
特權級(Privilege Level)
CPU 通過?當前特權級(CPL)?動態標記運行環境權限,x86 架構采用四級特權環(Ring 0-3):- 用戶態(Ring 3)?:CPL=3,僅能訪問用戶空間(0x00000000-0xBFFFFFFF)
- 內核態(Ring 0)?:CPL=0,可訪問全部內存(包括內核空間 0xC0000000-0xFFFFFFFF)
// CPU通過當前特權級別(CPL)控制訪問權限 #define USER_CPL 3 // 用戶態特權級 #define KERNEL_CPL 0 // 內核態特權級
地址空間映射
空間類型 虛擬地址范圍 可訪問性 存儲內容 用戶空間 0x00000000-0xBFFFFFFF 僅用戶態程序 用戶代碼/數據/堆棧 內核空間 0xC0000000-0xFFFFFFFF 僅內核態程序 內核代碼/全局數據/設備驅動 📌?關鍵特性:所有進程共享同一內核空間,但用戶空間相互隔離。系統調用執行時,CPU 仍在當前進程的地址空間內操作,僅特權級提升至 Ring 0。
二、狀態切換機制:軟中斷驅動的安全轉換
1. 觸發方式與硬件協作
用戶態→內核態通過三類事件觸發:
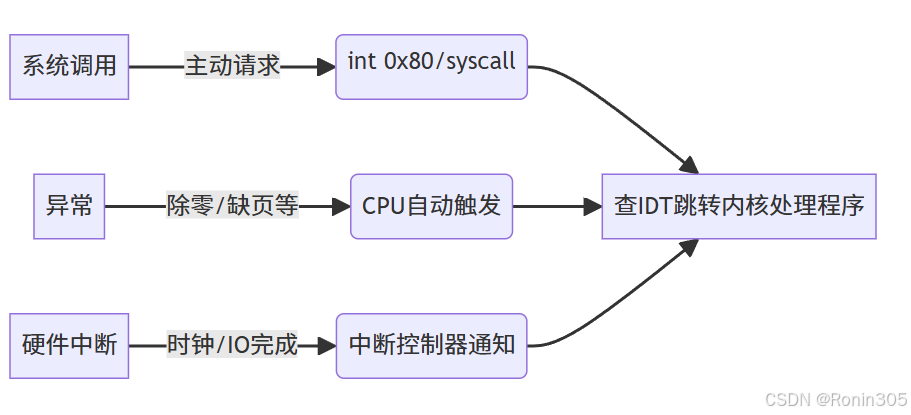
- 軟中斷指令:
int 0x80(傳統)或?syscall(現代)顯式請求 - 硬件自動校驗:CPU 比較?CPL(當前特權級)、DPL(目標段描述符特權級)、RPL(請求特權級),僅當 CPL ≤ DPL 時允許切換
2. 切換流程詳解
- 上下文保存
CPU 自動將用戶態寄存器(EFLAGS/CS/EIP)壓入當前進程的內核棧。 - 特權級與棧切換
- 從任務狀態段(TSS)加載內核棧指針(ESP0)
- CPL 從 3→0,CS 寄存器指向內核代碼段
- 執行內核服務
通過中斷向量號定位處理函數(如系統調用查?sys_call_table) - 返回用戶態
iret?指令恢復保存的寄存器,CPL 從 0→3
???性能代價:一次切換約消耗 100-200 CPU 周期,現代 CPU 通過?
syscall?指令優化至 20 周期。
三、安全性設計:三重防護機制
機制1:硬件級別的特權檢查
當執行?int 0x80?或?syscall?時,CPU會進行嚴格的安全檢查:
; 系統調用入口的硬件檢查流程
system_call_entry:; 1. 檢查目標代碼段的DPL(描述符特權級)是否允許當前CPL調用; 如果CPL > DPL,觸發通用保護異常(#GP); 2. 檢查中斷描述符表(IDT)的門描述符類型; 確保只能通過正確的門類型進入內核; 3. 自動切換棧指針到內核棧; 防止用戶棧污染內核; 4. 保存用戶態寄存器狀態; 保證能夠正確返回機制2:內存保護單元(MMU)的保護
MMU通過頁表機制確保內存訪問的安全性:
// 頁表項中的保護位
#define _PAGE_PRESENT 0x001 // 頁存在
#define _PAGE_RW 0x002 // 可寫
#define _PAGE_USER 0x004 // 用戶可訪問
#define _PAGE_SUPERVISOR 0x000 // 只能內核訪問// 內核頁表設置:用戶空間可訪問,內核空間僅內核可訪問
void setup_page_tables(void) {// 用戶空間頁表:設置_USER標志set_page_flags(user_vaddr, _PAGE_PRESENT | _PAGE_RW | _PAGE_USER);// 內核空間頁表:不設置_USER標志set_page_flags(kernel_vaddr, _PAGE_PRESENT | _PAGE_RW);
}機制3:系統調用參數驗證
內核不信任任何來自用戶空間的參數:
// 系統調用參數安全檢查
asmlinkage long sys_write(unsigned int fd, const char __user *buf, size_t count) {// 1. 檢查文件描述符有效性if (fd >= NR_OPEN) return -EBADF;// 2. 檢查用戶指針有效性(重要!)if (!access_ok(VERIFY_READ, buf, count))return -EFAULT;// 3. 檢查計數合理性if (count > MAX_WRITE_SIZE) return -EINVAL;// 只有通過所有檢查才會真正執行操作return do_write(fd, buf, count);
}從用戶態到內核態的安全切換
用戶程序調用系統調用 → 執行int 0x80/syscall↓
CPU自動進行特權級檢查(CPL vs DPL)↓
如果檢查失敗 → 觸發#GP異常 → 殺死進程↓
如果檢查通過 → 切換棧指針到內核棧↓
保存用戶態寄存器狀態↓
根據系統調用號查找系統調用表↓
執行對應的內核函數(進行參數驗證)↓
完成操作后返回用戶態關鍵的安全屏障
門描述符檢查:確保只能通過預設的安全入口進入內核
棧切換:防止用戶棧數據污染內核
參數驗證:所有用戶提供的參數都必須經過嚴格驗證
返回地址驗證:確保返回到合法的用戶空間地址
四、地址空間統一性:操作系統“永不消失”的奧秘
內核空間全局共享
所有進程的頁表中,3GB-4GB 區域映射同一物理內存(內核代碼區)。
→ 進程切換時 CR3 寄存器(頁表基址)更新,但內核映射不變。系統調用執行位置
當進程通過?write()?等調用進入內核時:- CPU 仍在該進程的上下文中執行內核函數
- 通過?
current?宏(x86 通過 FS 寄存器)獲取當前進程的?task_struct
🌰?示例:進程 A 調用?
read()?時,內核通過?current->files?獲取 A 的文件描述符表,不會訪問進程 B 的數據。
五、軟中斷安全性:CPL 自動變更的保障
執行?int 0x80?后 CPL 自動變 0 是否危險?
答案是否定的,原因如下:
1. 入口可控性
- 中斷門目標地址固定:由 OS 啟動時寫入 IDT,用戶無法修改
- 非任意跳轉:僅能跳轉到內核預定義的入口(如?
entry_SYSCALL_64)
2. 執行范圍約束
- 棧隔離:使用內核棧而非用戶棧,避免用戶操控內核執行流
- 代碼段限制:CS 寄存器指向內核代碼段(DPL=0),用戶無法注入代碼
3. 返回時的安全恢復
iret?指令從內核棧恢復用戶態寄存器,自動降權至 CPL=3。
總結:設計哲學與工程意義
空間復用與隔離的平衡
通過共享內核空間減少內存冗余,通過用戶空間隔離保障進程安全。特權切換的本質
軟中斷不是“漏洞”,而是硬件輔助的安全通道,其權限變更受嚴格校驗。操作系統的“不變性”根源
內核代碼位于所有進程共享的 3-4GB 區域,進程切換僅改變用戶空間映射,故操作系統始終可被訪問。
💎?終極啟示:用戶態與內核態的劃分是計算機科學中?“最小權限原則”?的典范——用戶程序僅在必要時獲取有限內核權限,且所有操作受硬件與操作系統的雙重監護。這種設計使系統在提供高性能服務的同時,將安全風險控制在最低水平。
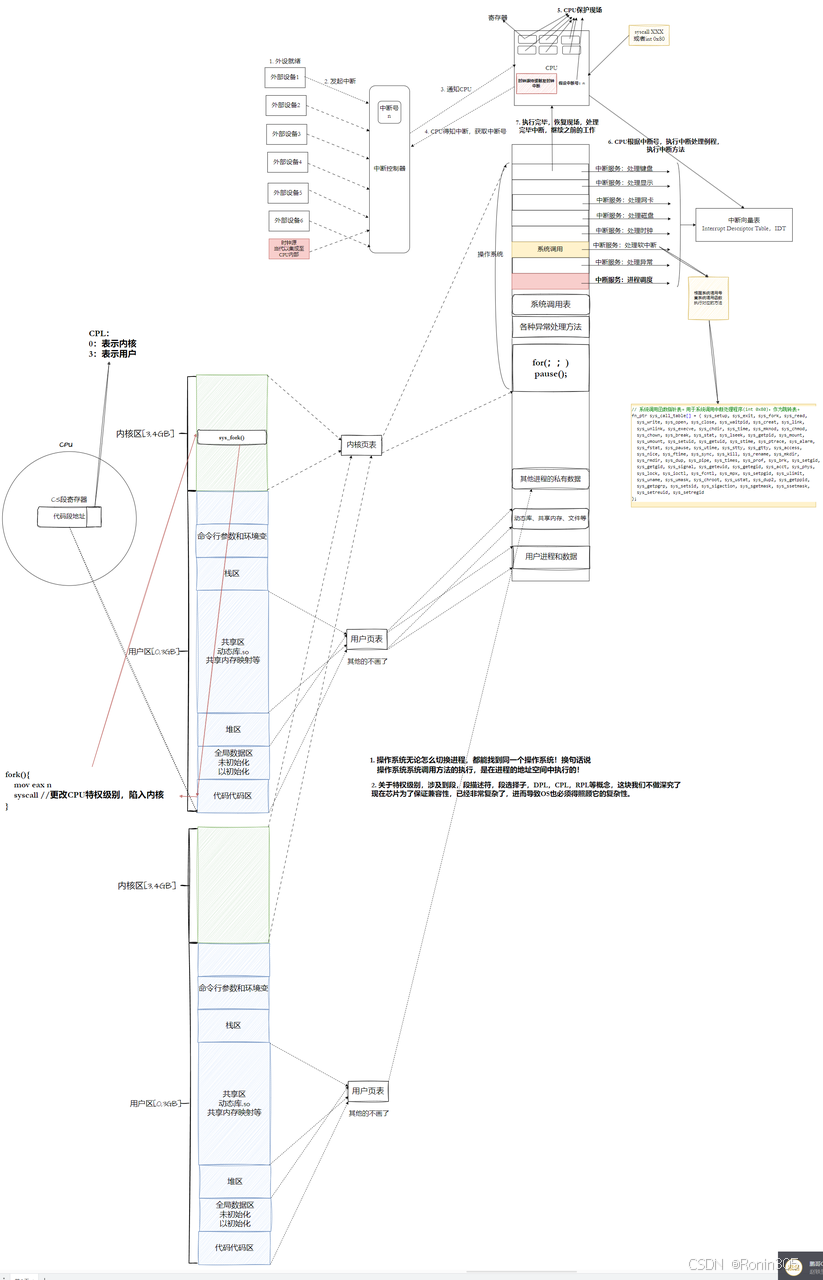
最后通過一張圖來總結:
5.?可重入函數
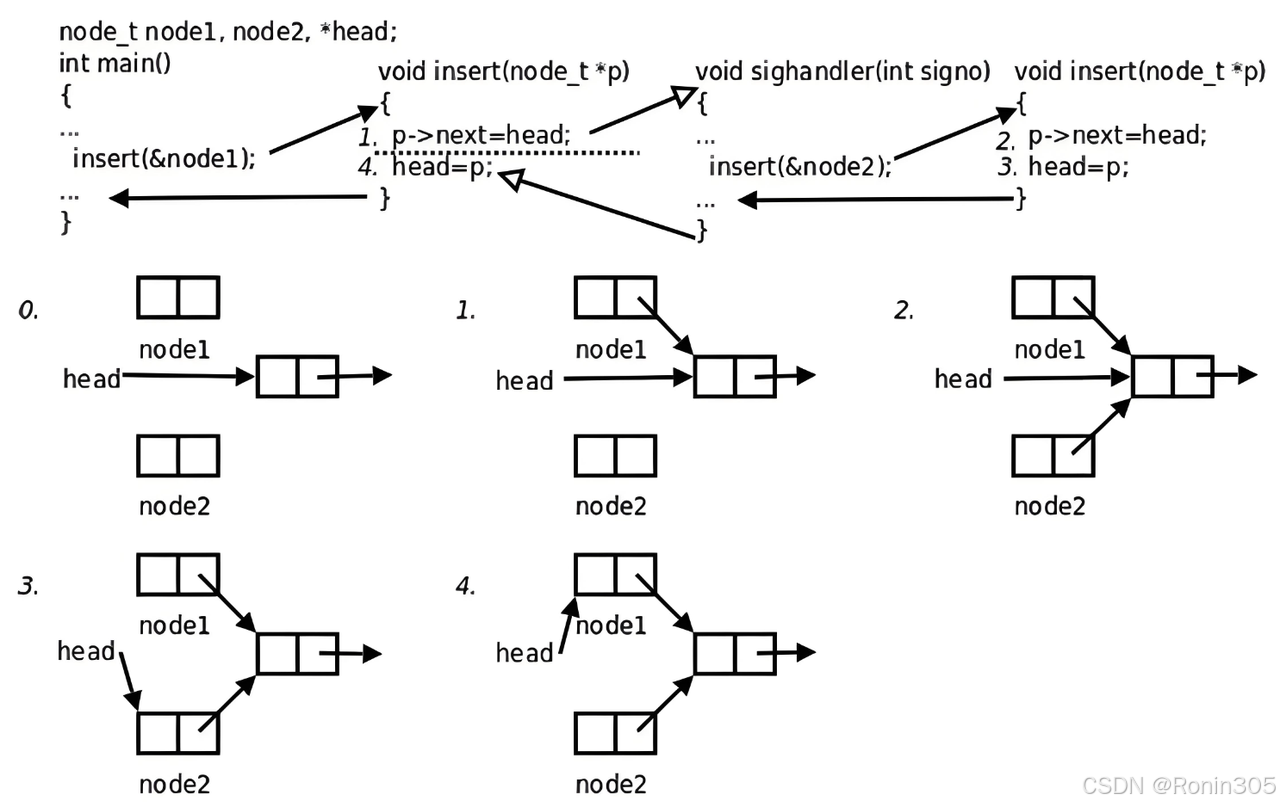
5.1 詳細場景描述
初始操作:
main函數調用insert函數,向鏈表頭節點head插入新節點node1- 插入操作分為兩個關鍵步驟: a. 將
node1的next指針指向head的當前下一個節點 b. 將head的next指針更新為指向node1
中斷發生:
- 當
insert函數剛完成步驟a(指針調整)但尚未執行步驟b(指針更新)時 - 硬件中斷觸發,進程切換到內核態
- 當
信號處理:
- 內核發現有待處理的信號,于是切換到用戶態執行信號處理函數
sighandler sighandler同樣調用insert函數,向同一個鏈表頭節點head插入節點node2- 這次
insert函數完整執行了兩個步驟,沒有被打斷
- 內核發現有待處理的信號,于是切換到用戶態執行信號處理函數
返回主流程:
- 信號處理完成后,控制權返回內核態,再回到用戶態
- 繼續從
main函數中被打斷的insert函數處執行,完成之前未執行的步驟b
最終結果:
- 由于步驟b的重復執行,導致
node1最終覆蓋了node2的插入 - 雖然兩個插入操作都執行了,但鏈表中實際上只保留了
node1,造成數據丟失
- 由于步驟b的重復執行,導致
5.2 關鍵沖突點分析
共享資源競爭
- 全局鏈表頭
head是共享狀態 - 兩個獨立控制流(main和sighandler)同時修改同一資源
- 全局鏈表頭
操作原子性破壞
插入操作被拆分為非原子步驟:void insert(Node* node) {node->next = head; // 步驟1head = node; // 步驟2 }當步驟1和步驟2之間被中斷時,鏈表處于不一致狀態(
head尚未更新)。信號處理特殊性
信號處理函數與主程序共享用戶態上下文(包括全局變量),但擁有獨立棧幀。
💥?結果:node2的插入被node1的步驟2覆蓋,造成數據丟失(僅node1存在于鏈表中)。
5.3 為什么訪問局部變量不會造成錯亂?
關鍵原因:棧的獨立性
每個執行流(函數調用)都有自己獨立的棧幀,局部變量存儲在棧中,因此不同調用之間的局部變量是隔離的。
// 可重入的函數示例
int add(int a, int b) {int result; // 局部變量,在棧上分配result = a + b; // 只操作局部變量和參數return result;
}棧內存布局
進程地址空間:
┌────────────────┐
│ 棧區 │ ← 每個函數調用有自己的棧幀
│ (Stack) │ 局部變量在這里分配
├────────────────┤
│ 堆區 │
│ (Heap) │ ← 全局變量和malloc內存在這里
├────────────────┤
│ 數據區 │ ← 全局變量在這里
│ (Data) │
├────────────────┤
│ 代碼區 │
│ (Text) │
└────────────────┘安全機制:
- 棧幀隔離:每次函數調用創建獨立棧幀
- 狀態私有化:參數和局部變量存儲在調用者專屬棧中
- 無共享依賴:不訪問全局內存或靜態存儲區
| 存儲區域 | 用戶態訪問 | 內核態訪問 | 重入安全性 |
|---|---|---|---|
| 棧空間 | 私有 | 私有 | ? 安全 |
| 全局變量區 | 共享 | 共享 | ? 危險 |
| 堆空間 | 共享 | 共享 | ? 危險 |
| 靜態存儲區 | 共享 | 共享 | ? 危險 |
線程安全 vs 可重入性
| 特性 | 可重入函數 | 線程安全函數 | 關系 |
|---|---|---|---|
| 核心目標 | 單線程內中斷安全 | 多線程并發安全 | 正交但常重疊 |
| 實現方式 | 避免所有共享狀態 | 可通過鎖保護共享狀態 | 可重入?線程安全 |
| 中斷場景 | 必須支持 | 不要求 | 可重入要求更嚴格 |
| 信號處理 | 唯一安全選擇 | 可能死鎖 | 信號處理必須可重入 |
📌?關鍵結論:所有可重入函數都是線程安全的,但線程安全函數不一定可重入。
5.4 不可重入函數的典型模式與風險
1. 內存管理函數(malloc/free)
危險根源:
// malloc內部偽代碼
void* malloc(size_t size) {static HeapSegment* free_list; // 全局空閑鏈表lock_mutex(); // 線程安全但不可重入!HeapSegment* block = find_free_block(free_list);unlock_mutex();return block;
}
- 全局狀態:
free_list管理堆內存的全局數據結構 - 中斷風險:若在
find_free_block執行中被信號中斷,二次調用將破壞鏈表完整性 - 死鎖風險:信號處理中調用malloc可能導致鎖重入死鎖
2. 標準I/O函數(printf/fgets)
危險案例:
void log_message(const char* msg) {static FILE* logfile; // 靜態變量!if (!logfile) logfile = fopen("app.log", "a");fprintf(logfile, "%s\n", msg); // 使用全局I/O緩沖區
}
- 緩沖區共享:
FILE結構包含I/O緩沖區,多控制流寫入導致數據混合 - 位置指針沖突:文件偏移量
fpos被并發修改
3. 不可重入函數特征總結
符合以下任一條件即不可重入:
- 使用全局變量(如
errno) - 操作靜態局部變量
- 調用非原子性的共享資源操作
- 依賴不可重入庫函數(如標準I/O)
- 返回靜態存儲區指針(如
ctime())
5.5?可重入函數設計實踐
1. 基礎設計模式
// 安全版本鏈表插入
void reentrant_insert(Node** head_ptr, Node* node) {node->next = *head_ptr; // 通過指針參數訪問*head_ptr = node; // 修改調用者提供的指針
}
調用方式:
Node* private_list = NULL; // 每個控制流獨立維護// main函數
reentrant_insert(&private_list, node1);// 信號處理函數
reentrant_insert(&sig_list, node2); // 使用獨立鏈表
2. 高級技術:線程局部存儲(TLS)
__thread Node* thread_local_head; // GCC擴展void thread_safe_insert(Node* node) {node->next = thread_local_head;thread_local_head = node;
}
__thread關鍵字:每個線程擁有獨立變量實例- 信號處理適配:需配合
sigaltstack使用獨立棧
3. 可重入標準庫替代方案
| 傳統函數 | 危險原因 | 可重入替代 | 頭文件 |
|---|---|---|---|
strtok | 靜態狀態指針 | strtok_r | <string.h> |
ctime | 返回靜態緩沖區 | asctime_r | <time.h> |
rand | 靜態種子狀態 | rand_r | <stdlib.h> |
gmtime | 靜態結構體 | gmtime_r | <time.h> |
💡 命名規律:
_r后綴表示reentrant(可重入)
5.6 特殊場景:信號處理函數設計規范
1. 信號安全函數清單(POSIX標準)
僅允許調用以下異步信號安全函數:
// 典型信號安全函數
_Exit() abort() accept() access()
alarm() bind() cfgetispeed() cfgetospeed()
...
write() // 部分實現安全
禁止項:
malloc/free:可能破壞堆結構printf:共享I/O緩沖區- 任何非異步信號安全函數
2. 信號處理最佳實踐
void signal_handler(int sig) {// 1. 僅設置原子標志volatile sig_atomic_t flag = 1;// 2. 通過管道通知主循環char byte = 1;write(self_pipe[1], &byte, 1); // write是信號安全的
}
主程序處理:
while (read(self_pipe[0], &byte, 1) > 0) {// 在安全環境執行實際邏輯process_signal_events();
}
總結:可重入函數的設計要義
狀態隔離原則
- 只操作棧數據(參數/局部變量)
- 絕不觸碰全局或靜態存儲區
資源訪問規范
- 避免動態內存管理(malloc/free)
- 禁用標準I/O庫(使用無緩沖I/O如
write) - 調用鏈確保全可重入
信號處理特別約束
- 僅使用POSIX規定的異步信號安全函數
- 通過標志位+事件循環解耦處理邏輯
架構級解決方案
- 為中斷/信號分配專用內存池
- 采用Actor模型或消息隊列隔離控制流
6. 信號機制深度總結與思考
6.1?為什么信號產生和執行最終都要由OS來進行?
根本原因:操作系統是進程的管理者和資源的協調者
權限控制:只有操作系統內核擁有最高權限,能夠修改任何進程的內核數據結構(如?
task_struct)。安全性:如果允許用戶進程直接向其他進程發送信號或修改其狀態,會導致系統安全性崩潰。
資源管理:OS負責管理系統中的所有資源,信號作為一種進程間通信機制,必須由OS統一管理以確保公平性和正確性。
抽象接口:OS為進程提供了統一的信號處理接口(如?
signal(),?sigaction()),隱藏了底層實現的復雜性。
類比:就像一個國家中,只有中央政府(OS)有權向地方政府(進程)下達正式指令(信號),地方政府之間不能隨意互相指揮。
6.2 信號的處理是否是立即處理的?
不是立即處理,而是在"合適的時候"處理
異步性:信號可能在任何時間點到達,進程無法預測其確切到達時間。
處理時機:信號的處理發生在進程從內核態返回用戶態之前。具體時機包括:
系統調用完成時
中斷處理完成時
進程時間片用完,發生調度時
為什么不能立即處理?
進程可能正在執行關鍵代碼段,不能被中斷
可能正在處理更重要的任務
信號處理函數需要在自己的上下文中執行
6.3 信號是否需要被暫時記錄?記錄在哪里最合適?
是的,信號需要被暫時記錄
記錄位置:進程的內核數據結構中最合適
具體來說,信號被記錄在進程的?task_struct?結構中的兩個關鍵位圖中:
未決信號集(pending):記錄哪些信號已經產生但尚未處理
阻塞信號集(blocked/mask):記錄哪些信號被暫時屏蔽(不處理)
為什么記錄在內核數據結構中最合適?
內核數據結構對所有進程是隔離的,保證安全性
內核可以高效地管理和訪問這些信息
符合UNIX"一切皆文件/資源"的設計哲學
6.4 進程在沒有收到信號時,能否知道應對合法信號作何處理?
是的,進程提前知道如何處理信號
信號處理表:每個進程在創建時就從父進程繼承了一張信號處理方式表,存儲在?
task_struct?的?sighand?字段中。三種處理方式:
默認操作(SIG_DFL)
忽略信號(SIG_IGN)
自定義處理函數
提前注冊:進程可以通過?
signal()?或?sigaction()?系統調用提前注冊信號處理方式。
類比:就像你提前告訴秘書:"如果有A類郵件,直接歸檔;如果有B類郵件,立即通知我;如果有C類郵件,轉交給某部門處理"。
6.5 如何理解OS向進程發送信號?完整的發送處理過程
完整發送處理過程可以分為以下步驟:
階段一:信號產生
信號由某種事件產生(硬件異常、軟件條件、其他進程調用kill等)
OS確定目標進程
階段二:信號記錄(內核完成)
OS檢查目標進程的阻塞信號集
如果信號未被阻塞,OS在目標進程的未決信號集中設置對應位
如果信號被設置為立即傳遞(實時信號)或進程正在可中斷的睡眠中,OS會喚醒進程
階段三:信號檢測(內核完成)
當目標進程從內核態返回用戶態前,OS會檢查其未決信號集
OS查找信號處理方式表,確定如何處理每個未決信號
階段四:信號處理
對于需要默認處理的信號,OS直接執行默認操作(終止、停止等)
對于需要忽略的信號,OS清除未決位,不做其他處理
對于有自定義處理函數的信號:
OS在用戶棧上精心構造一個"信號處理幀"
修改進程的用戶態指令指針,使其指向信號處理函數
進程返回用戶態后,首先執行信號處理函數
階段五:處理完成
信號處理函數執行完畢后,調用?
sigreturn()?系統調用OS恢復進程原來的執行上下文,清除信號處理幀
進程繼續從被信號中斷的地方執行
整個過程體現了OS的核心作用:
OS是信號的"郵局",負責接收、分類和投遞
OS是信號的"交通警察",決定何時投遞信號
OS是信號的"秘書",維護著每個進程的信號處理偏好表
OS是信號的"保鏢",確保信號處理不會破壞系統穩定性
至此,我們對信號從產生,到保存,再處理,這三個階段從內到外都有了一個深刻的認識



與同義詞治理)











下載及配置)



