名人說:博觀而約取,厚積而薄發。——蘇軾《稼說送張琥》
創作者:Code_流蘇(CSDN)(一個喜歡古詩詞和編程的Coder😊)
目錄
- 一、什么是DeepSeek V3.1?為什么這么火🚀
- 1. 發布時間線回顧
- 2. 核心創新點
- 二、技術原理揭秘:一個模型如何擁有兩個大腦?
- 1. 混合推理架構詳解
- 2. 參數精度的黑科技
- 三、性能表現:真的能打過Claude嗎?
- 1. 編程能力測試
- 2. 搜索和推理能力
- 3. 效率提升的秘密
- 四、上手體驗:如何玩轉V3.1的雙重人格?
- 1. 官方體驗入口
- 2. 使用技巧
- 3. API使用示例
- 五、商業化策略:免費午餐要結束了?
- 1. 價格調整時間表
- 2. 開源策略持續
- 六、未來展望:智能體時代真的來了嗎?
- 1. 技術趨勢分析
- 2. 給開發者的建議
- 總結
很高興你打開了這篇博客,更多AI知識,請關注我、訂閱專欄《AI知識圖譜》,內容持續更新中…
大家好👋,我是流蘇
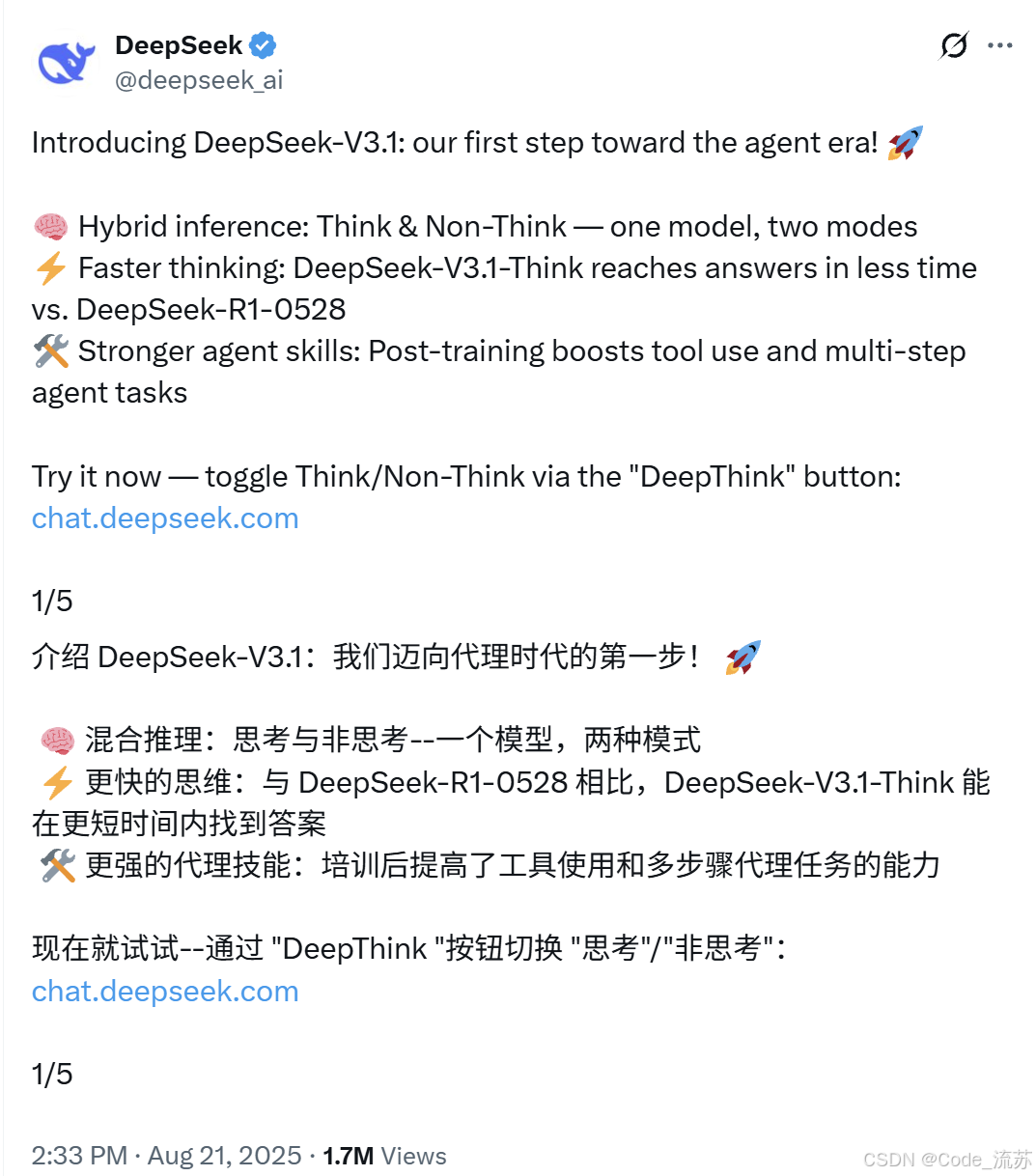
2025年8月21日,國產AI再次刷屏! DeepSeek低調發布V3.1,混合推理架構讓人眼前一亮,成本降低60倍,據說性能部分超越Claude?這到底是什么神仙操作,是如何設計的,我們一起來看看!
一、什么是DeepSeek V3.1?為什么這么火🚀
還記得今年年初DeepSeek R1橫空出世,讓全球AI圈都震驚的場面嗎?現在,DeepSeek又來"搞事情"了!
DeepSeek V3.1可以說是DeepSeek家族的"集大成者",它最牛的地方就是實現了"一個模型,兩種大腦"的神奇操作。
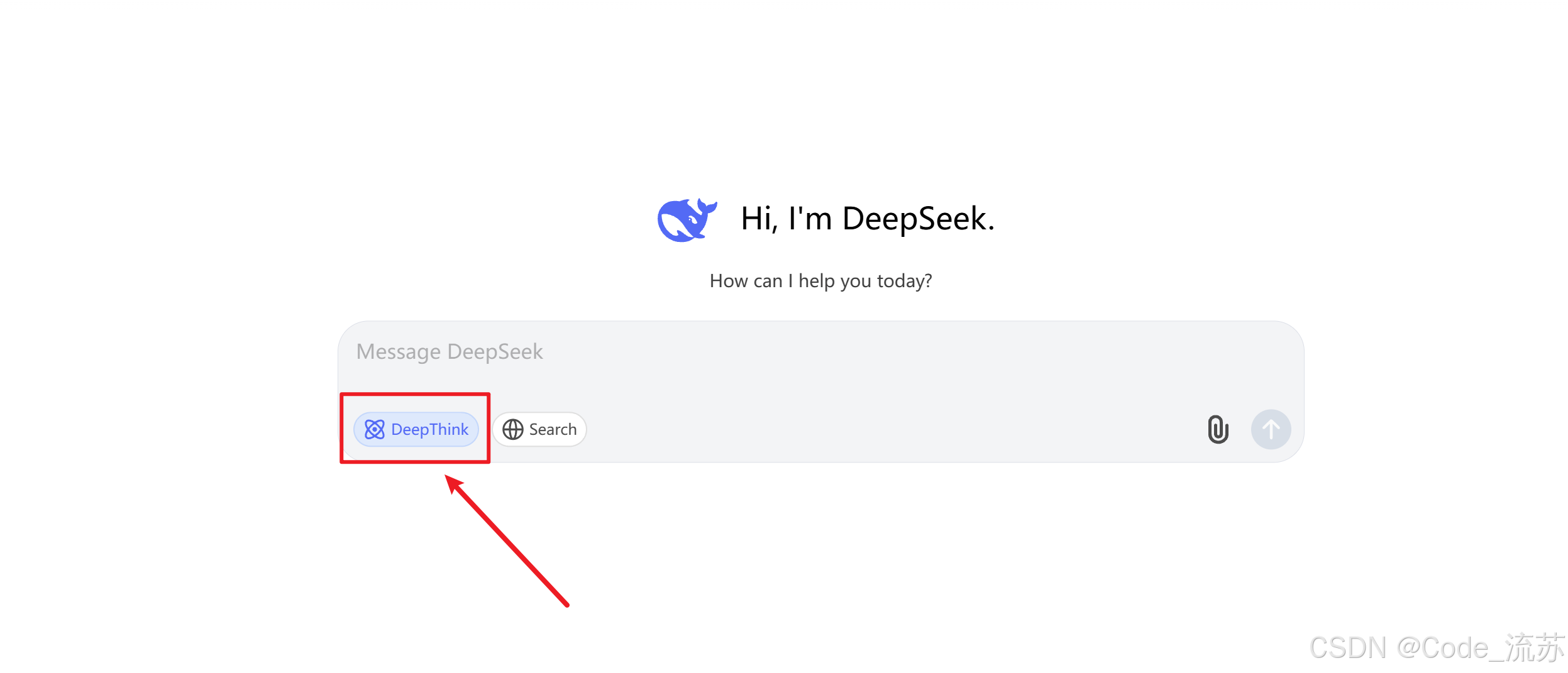
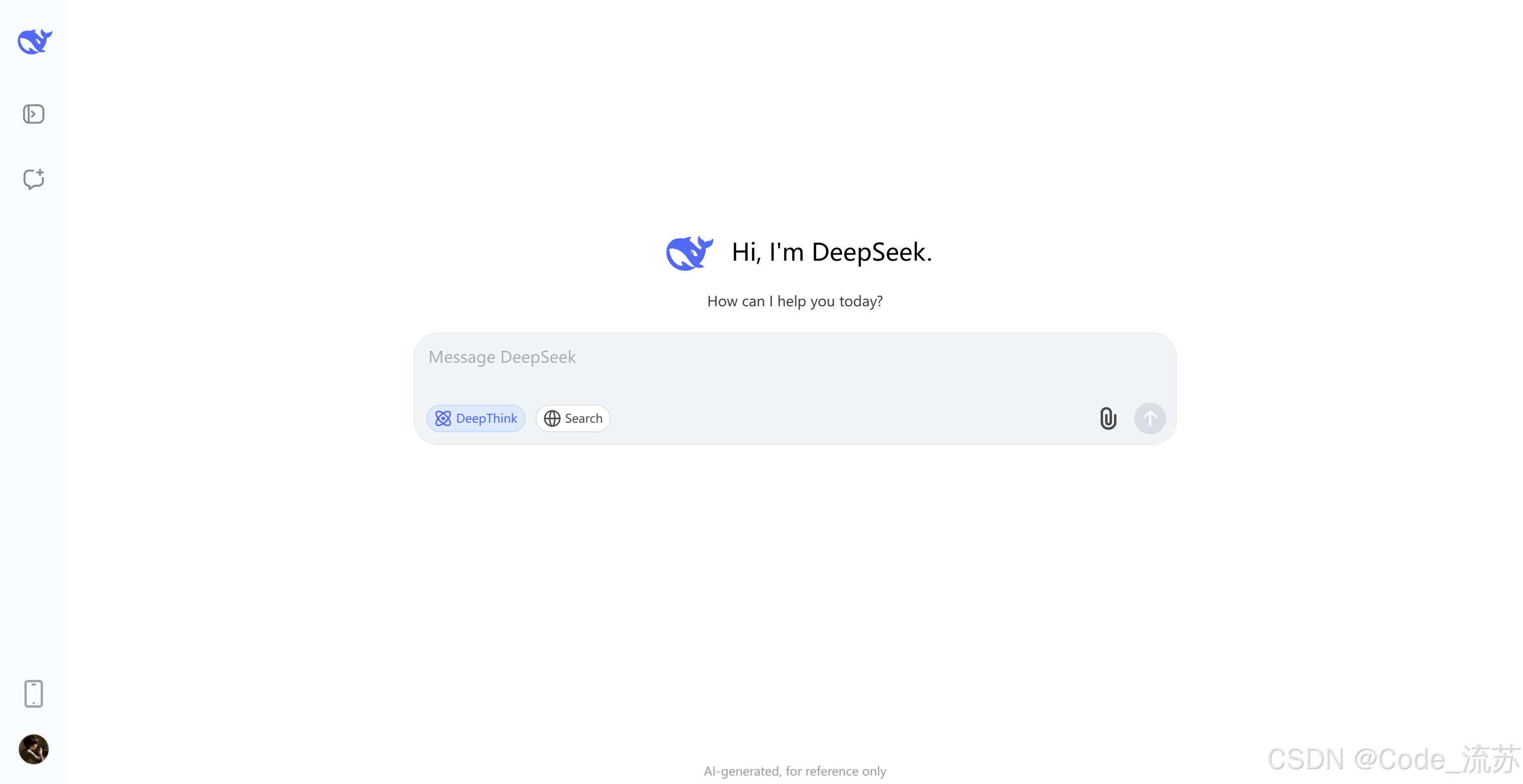
在官網對話聊天框下方可以看到,現在已經出現了DeepThink模式,打開DeepThink就會進入思考模式,關閉就是非思考常規模式。
官網:https://chat.deepseek.com/
1. 發布時間線回顧
- 8月20日晚:DeepSeek悄悄上線V3.1
- 8月21日下午:正式宣布發布
- 發布當天:直接沖上HuggingFace(HF)趨勢榜第三名
HF首頁:https://huggingface.co/deepseek-ai/DeepSeek-V3.1
2. 核心創新點
想象一下,如果你的大腦可以隨時在"快思考"和"慢思考"之間切換,會是什么感覺?V3.1就做到了這一點:
- 🧠 快思考模式:日常聊天、快速問答
- 🤔 慢思考模式:復雜推理、深度分析
這種混合推理架構讓一個模型可以"因題制宜",該快的時候快,該深的時候深!
二、技術原理揭秘:一個模型如何擁有兩個大腦?
1. 混合推理架構詳解
傳統的AI模型就像是"單核處理器",只有一種工作模式。而V3.1更像是"雙核處理器":
傳統模型:問題 → 單一推理 → 答案
V3.1模型:問題 → 選擇模式 → 快思考/慢思考 → 答案
技術實現機制:
- API端點分離:
deepseek-chat(快思考)+deepseek-reasoner(慢思考) - 統一模型架構:底層共享685B參數,上層分化推理路徑
- 智能切換:用戶可通過 “深度思考(DeepThink)” 按鈕隨時切換

2. 參數精度的黑科技

官推評論區,官方運營特意強調:V3.1使用了UE8M0 FP8 Scale參數精度,這聽起來很技術,其實就是為了后面使用國產芯片做準備:
- 🎯 專門為國產芯片優化:提前適配下一代國產AI芯片
- ? 計算效率更高:更少的存儲空間,更快的計算速度
- 💡 前瞻性布局:為國產硬件生態建設貢獻力量
三、性能表現:真的能打過Claude嗎?
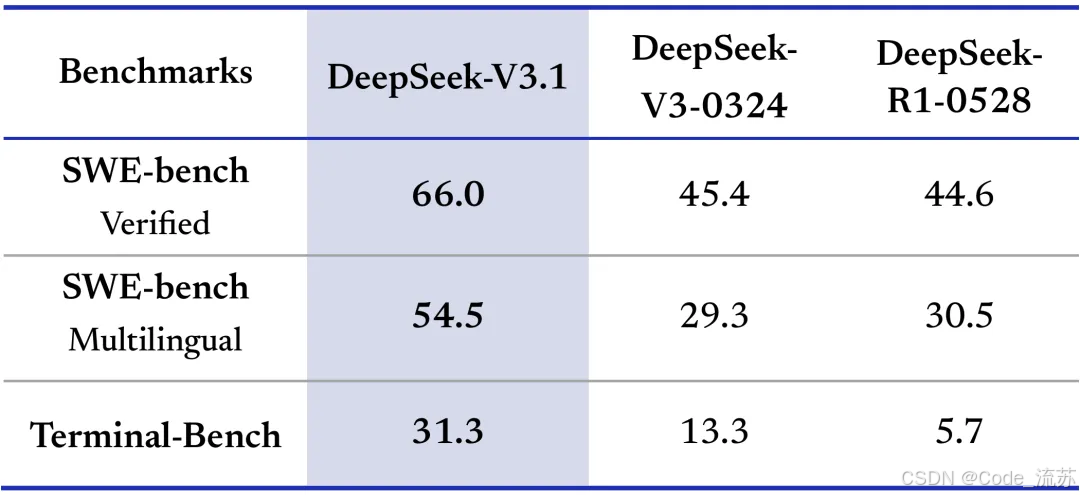
1. 編程能力測試
在AiderPolyglot多語言編程測試中,V3.1交出了令人驚艷的成績單,成本優勢驚人:完成同樣的編程任務,V3.1編程性能比Claude 4高1%,成本要低68倍。

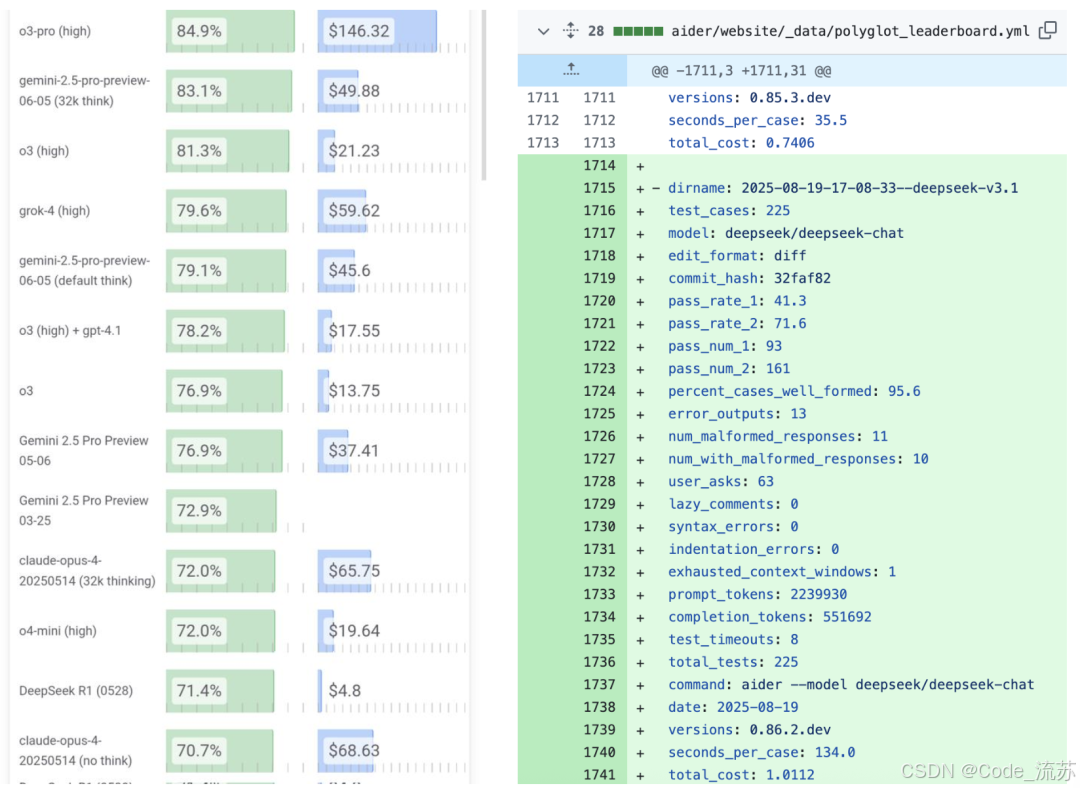

對于編程智能體,相對于前代的能力提升明顯,這也是官方說的邁向Agent時代的第一步中的一部分!
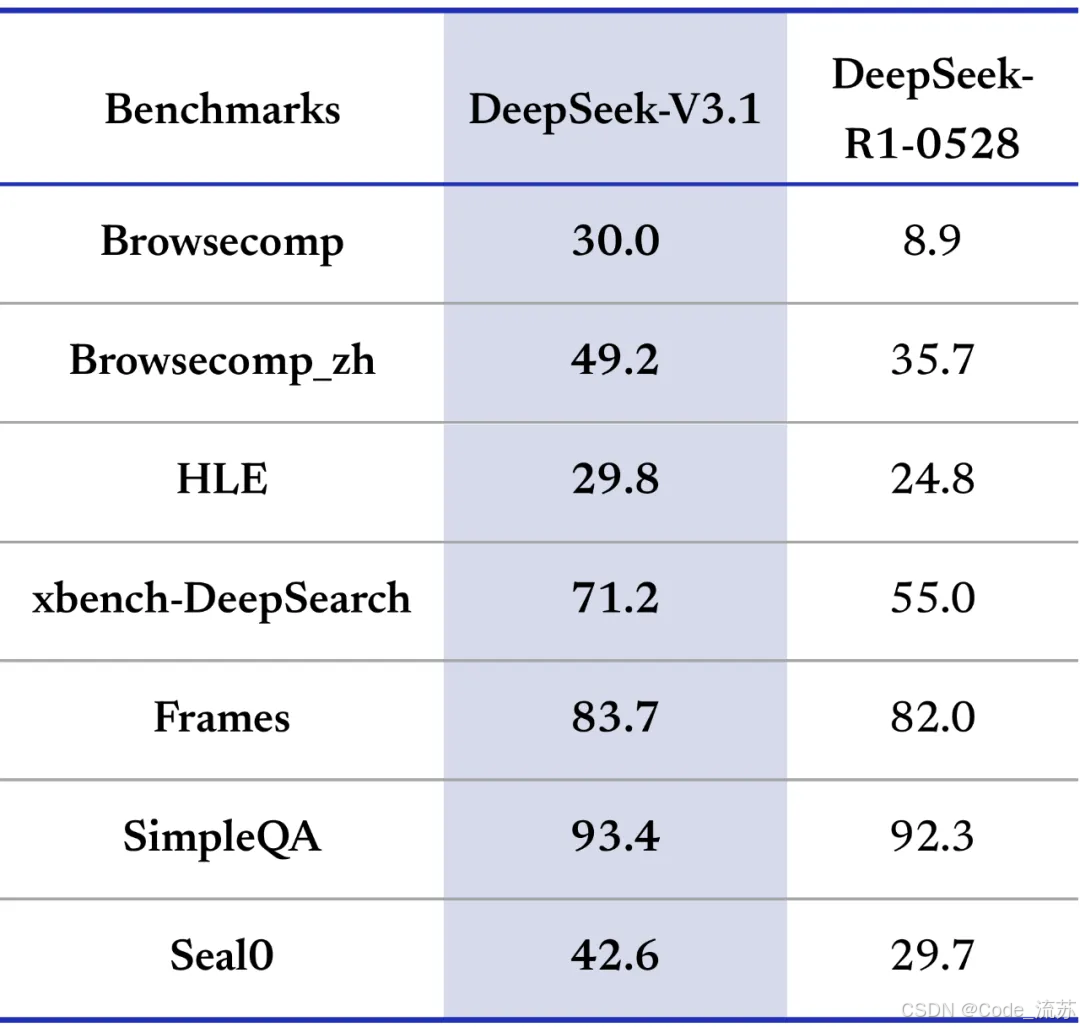
2. 搜索和推理能力
在復雜搜索測試中,V3.1展現出了強大的多步推理能力:
- browsecomp測試:需要多步推理的復雜搜索,大幅領先前代
- HLE測試:多學科專家級難題,性能顯著提升
- Terminal-Bench:命令行環境復雜任務,表現出色
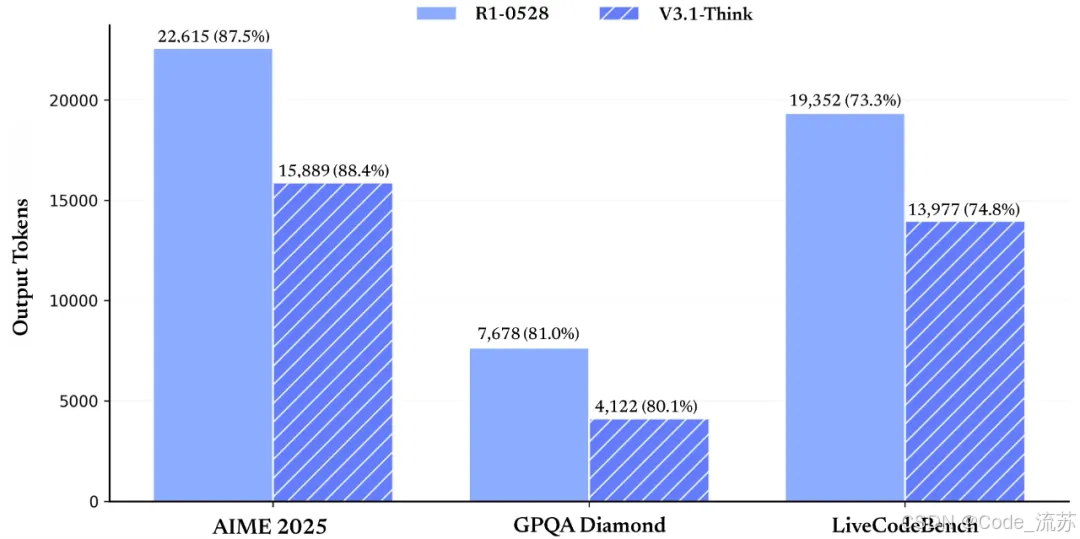
3. 效率提升的秘密
思考效率革命性提升:
- Token消耗量減少20%-50%
- 保持相同任務表現的同時,"思考"更快了
- 相比V3-0324版本,整體token使用量下降13%
四、上手體驗:如何玩轉V3.1的雙重人格?
官推中,官方運營特別回復,目前已在各平臺更新,只是新模型自我認知為DeepSeek-V3。

1. 官方體驗入口
- 網頁版:https://chat.deepseek.com
- 移動App:已同步升級到V3.1
- API接口:支持128K上下文窗口
2. 使用技巧
1??何時使用快思考模式?
取消這里的選擇即可。

適用場景:
- 日常閑聊
- 快速問答
- 簡單代碼解釋
- 翻譯任務
2??何時切換到慢思考模式?
這里選擇即可。

適用場景:
- 復雜數學問題
- 邏輯推理題
- 多步驟編程任務
- 深度分析報告
3. API使用示例
# 快思考模式
response = client.chat.completions.create(model="deepseek-chat", # 快思考messages=[{"role": "user", "content": "寫個Hello World"}]
)# 慢思考模式
response = client.chat.completions.create(model="deepseek-reasoner", # 慢思考messages=[{"role": "user", "content": "證明哥德巴赫猜想"}]
)
五、商業化策略:免費午餐要結束了?

1. 價格調整時間表
重要時間節點:2025年9月6日凌晨
新定價標準:
- 輸入:0.5元/百萬tokens(緩存命中),4元/百萬tokens(緩存未命中)
- 輸出:12元/百萬tokens
- 取消夜間時段優惠(之前夜間可享受50%-75%折扣)

2. 開源策略持續
盡管商業化加速,DeepSeek依然堅持開源路線:
開源地址:
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-V3.1
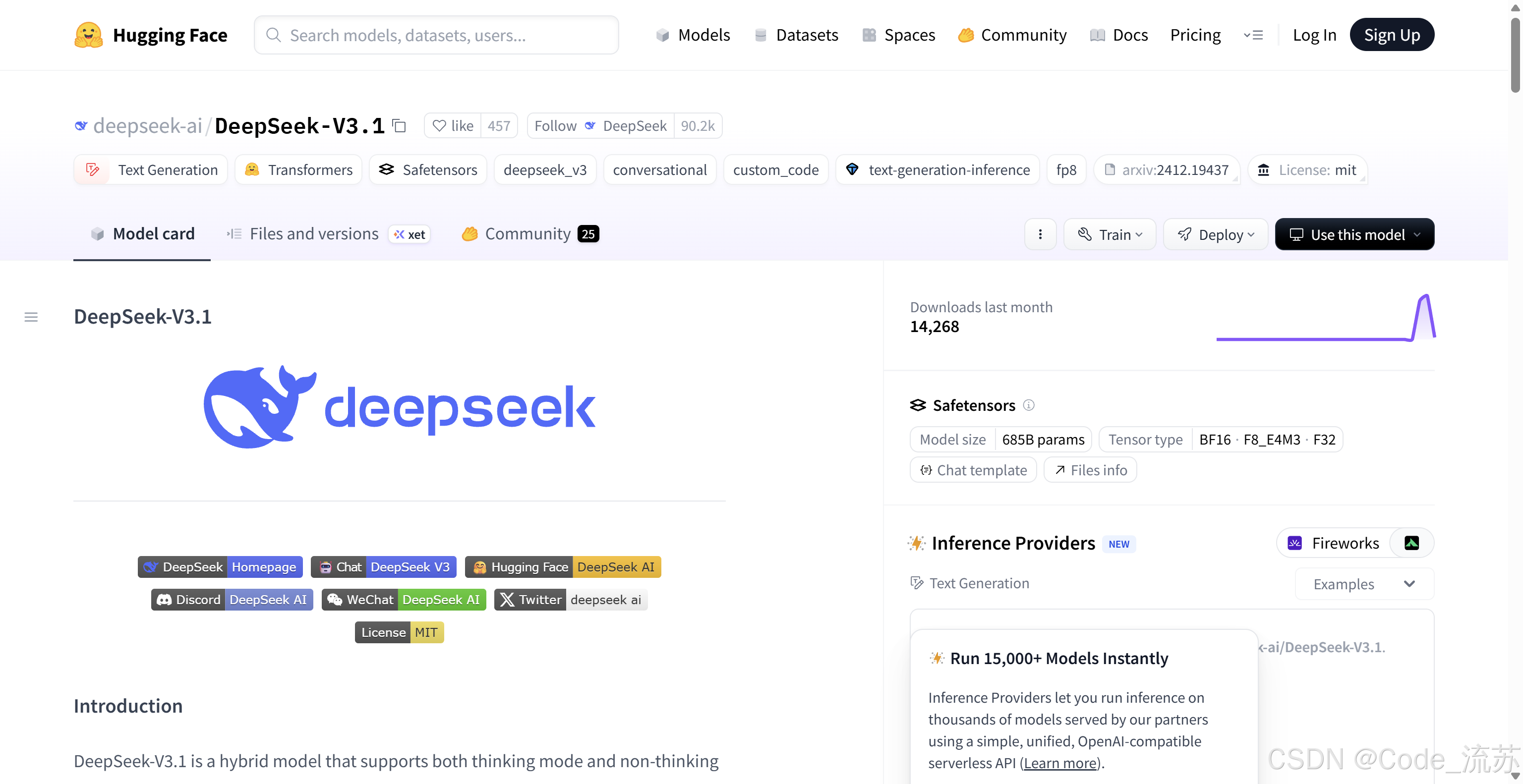
- 魔搭:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1

開源范圍:
- Base模型(基礎版):https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base

- 后訓練模型(完整版):https://huggingface.co/deepseek-ai/DeepSeek-V3.1

-
完整技術文檔:https://api-docs.deepseek.com/
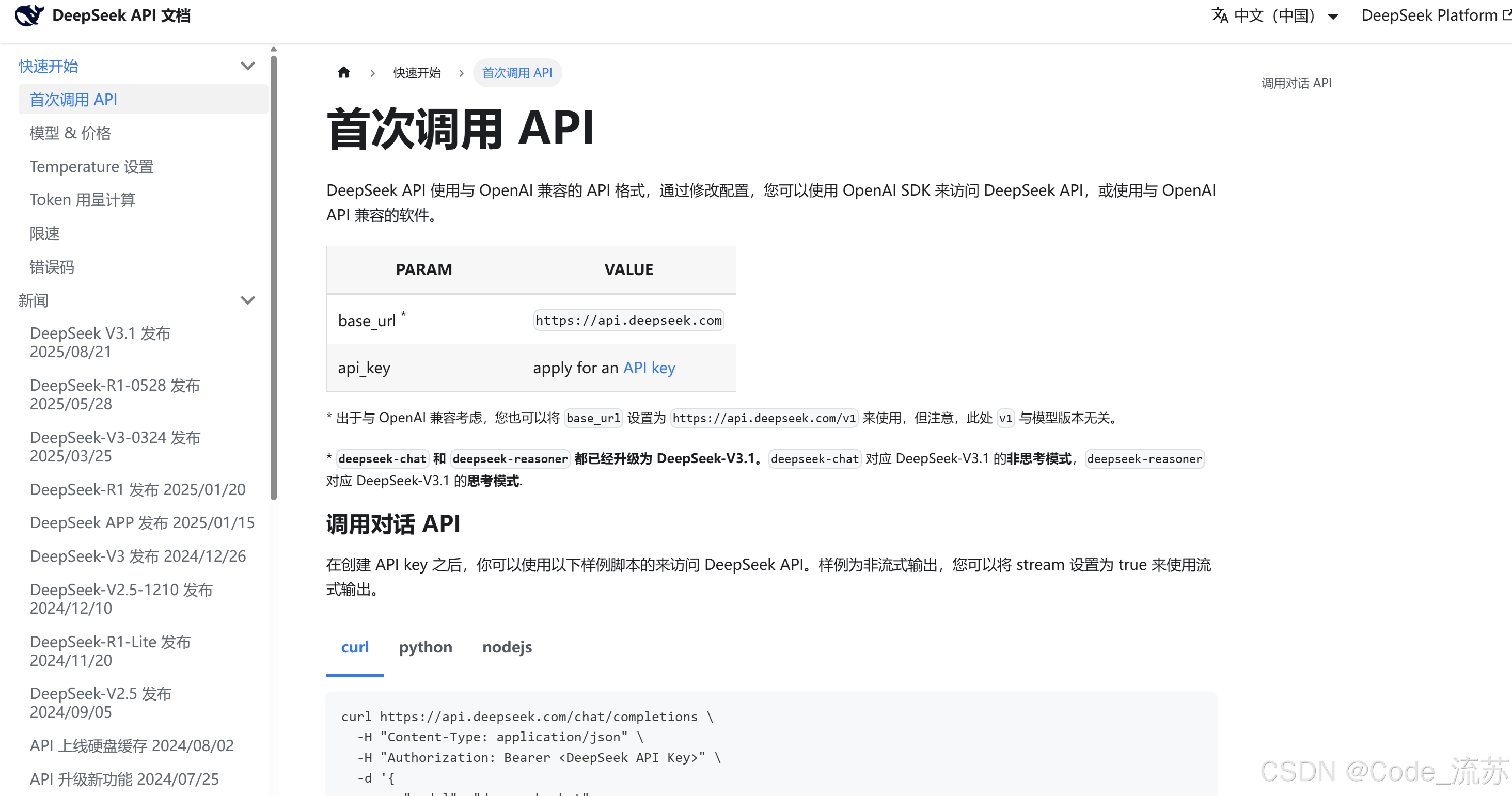
六、未來展望:智能體時代真的來了嗎?
1. 技術趨勢分析
V3.1的發布釋放了幾個重要信號:
1??混合推理將成為標配
- 單一模式已經不能滿足復雜需求
- "因題制宜"的智能分配將成為主流
- 效率和效果的平衡是關鍵
2??Agent能力成為核心競爭力
- 工具調用能力不斷增強
- 多步驟任務執行更加可靠
- 自主決策能力持續提升
2. 給開發者的建議
1??適合使用V3.1的場景:
- 成本敏感的商業應用
- 需要頻繁工具調用的智能體開發
- 中文優化要求較高的項目
2??需要謹慎考慮的場景:
- 對推理準確性要求極高的任務
- 需要最前沿性能的科研項目
總結
DeepSeek V3.1的發布標志著AI模型設計理念的重要轉變:從單一模式向混合架構演進,從通用能力向智能體特化發展。
雖然在某些方面還有提升空間,但其成本優勢、開源策略和本土化特色讓它在AI生態中占據了重要地位。對于國產AI來說,這不僅是技術實力的展現,更是向智能體時代邁進的重要一步。
最后的最后:如果你還在猶豫要不要試試V3.1,建議趁著9月6日價格調整前,先體驗一波!說不定你會發現,這個"雙重人格"的AI比你想象的更有趣呢~
📝 本文參考資料:DeepSeek官方發布公告、Hugging Face模型頁面、社區測試數據
- DeepSeek官網
- API文檔
- Hugging Face模型頁面
創作者:Code_流蘇(CSDN)(一個喜歡古詩詞和編程的Coder😊)
下載及配置)


















