????
近日,卡內基梅隆大學(Carnegie Mellon University)的研究團隊在動態場景重建領域取得重要進展。其發表于ICCV 2025的論文《MonoFusion: Sparse-View 4D Reconstruction via Monocular Fusion》提出創新方法MonoFusion 。該方法突破常規,僅需少量(如4個)稀疏視角相機,便能對彈鋼琴、修理自行車這類復雜人體行為實現高質量4D重建。它巧妙避開稀疏視角下直接重建的難點,通過融合各相機獨立的單目重建結果,在全新視角渲染方面展現出超越以往技術的顯著優勢,為相關領域發展帶來新契機。
另外我整理了ICCV 2025計算機視覺相關論文,感興趣的dd!
論文這里

2. 【論文基本信息】

- 論文標題:MonoFusion: Sparse-View 4D Reconstruction via Monocular Fusion
- 論文鏈接:https://arxiv.org/pdf/2507.23782v1
- 項目代碼鏈接:https://github.com/ImNotPrepared/MonoFusion
- 核心模塊:
- 3D Gaussian Scene Representation(3D高斯場景表示模塊)
- Space-Time Consistent Depth Initialization(時空一致的深度初始化模塊)
- Grouping-based Motion Initialization(基于分組的運動初始化模塊)
- Optimization(優化模塊)
3. 【算法創新點】
3.1 時空一致的深度初始化方法
通過將單目深度預測與多視圖一致的點圖對齊,解決單目深度估計在尺度和偏移上的不一致問題,利用靜態背景的時間一致性進行優化,并針對高斯尺度初始化和密度問題提出改進策略。
3.2 基于特征聚類的運動初始化機制
采用特征聚類構建運動基,通過DINOv2提取像素級特征并進行聚類,使語義相似的場景部分運動一致,避免了基于噪聲3D軌跡初始化的缺陷,提高了運動估計的魯棒性。
3.3 結合多種損失的聯合優化策略
融合光度損失、剛性損失等多種損失函數,同時考慮 photometric 監督、數據驅動先驗以及對幾何和運動的正則化,有效避免在稀疏視圖設置中陷入不良局部最小值。

4. 【算法框架與核心模塊】
4.1 算法框架
MonoFusion旨在從稀疏視圖(3-4個)視頻中恢復動態3D場景的幾何和運動信息。整體流程為:首先以規范3D高斯模型表示場景,這些高斯通過運動基的線性組合實現平移和旋轉;接著通過對齊多視圖的幾何預測初始化一致的場景幾何,并通過聚類從2D基礎模型提取的3D語義特征初始化運動軌跡;最后通過聯合優化同時恢復幾何和運動信息,最終得到可用于渲染新視圖的4D場景表示。
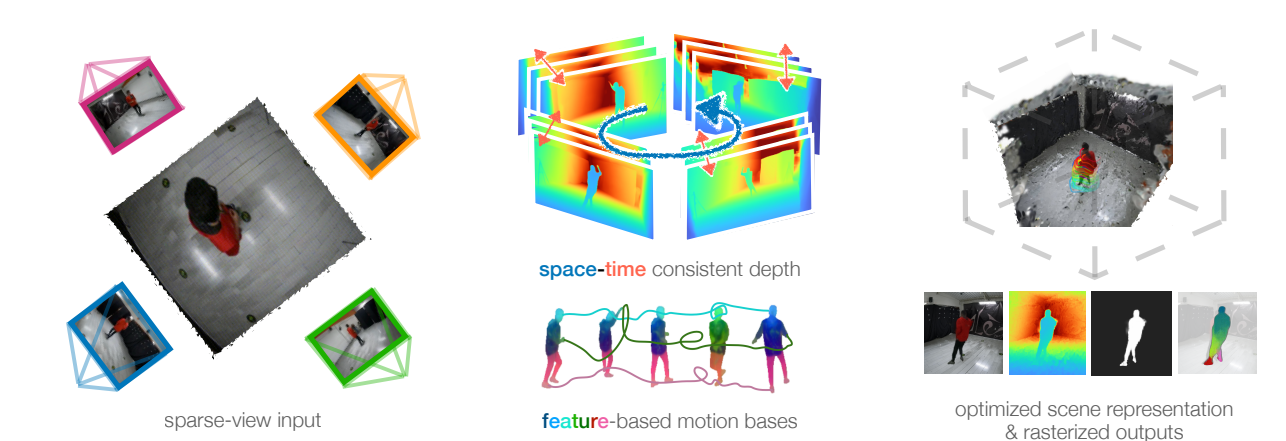
4.2 核心模塊
4.2.1 3D Gaussian Scene Representation(3D高斯場景表示)
采用3D Gaussian Splatting表示動態3D場景的幾何和外觀,每個高斯在規范幀t0t_0t0?中由(x0,R0,s,α,c)(x_0, R_0, s, \alpha, c)(x0?,R0?,s,α,c)參數化,其中x0∈R3x_0 \in \mathbb{R}^3x0?∈R3是位置,R0∈SO(3)R_0 \in \mathbb{SO}(3)R0?∈SO(3)是方向,s∈R3s \in \mathbb{R}^3s∈R3是尺度,α∈R\alpha \in \mathbb{R}α∈R是不透明度,c∈R3c \in \mathbb{R}^3c∈R3是顏色。位置和方向隨時間變化,而尺度、不透明度和顏色保持不變。此外,每個高斯還被分配一個語義特征f∈RNf \in \mathbb{R}^Nf∈RN(N=32N=32N=32)。對于第i個3D高斯,可優化的屬性為Θ(i)={x0(i),R0(i),s(i),f(i)}\Theta^{(i)} = \{x_0^{(i)}, R_0^{(i)}, s^{(i)}, f^{(i)}\}Θ(i)={x0(i)?,R0(i)?,s(i),f(i)},并通過基于瓦片的光柵化過程從給定相機渲染出RGB圖像和特征圖。
4.2.2 Space-Time Consistent Depth Initialization(時空一致的深度初始化)
- 多視圖點圖預測:使用DUSt3R在時間t的多視圖圖像上預測多視圖一致的點圖,通過已知相機參數將點圖投影回圖像計算深度圖,公式為dkt(u,v)[uv1]T=KkPkχkt(u,v)d_k^t(u, v) \begin{bmatrix} u & v & 1 \end{bmatrix}^T = K_k P_k \chi_k^t(u, v)dkt?(u,v)[u?v?1?]T=Kk?Pk?χkt?(u,v),得到的深度在度量尺度上多視圖一致,但時間上不一致。
- 單目深度與多視圖一致點圖的時空對齊:以DUSt3R的多視圖深度圖為度量目標,對齊單目深度預測mkt(u,v)m_k^t(u, v)mkt?(u,v),通過最小化誤差argmin{akt,bkt}∑t=1T∑k=1K∑u,v∈BGkt∥(aktmkt(u,v)+bkt)?dkt(u,v)∥2\underset{\{a_k^t, b_k^t\}}{arg\ min} \sum_{t=1}^T \sum_{k=1}^K \sum_{u, v \in BG_k^t} \left\| (a_k^t m_k^t(u, v) + b_k^t) - d_k^t(u, v) \right\|^2{akt?,bkt?}arg?min?∑t=1T?∑k=1K?∑u,v∈BGkt??∥(akt?mkt?(u,v)+bkt?)?dkt?(u,v)∥2確定尺度和偏移因子akta_k^takt?、bktb_k^tbkt?,并利用背景點的時間靜態性,用時間平均或規范參考時間戳的靜態目標dk(u,v)d_k(u, v)dk?(u,v)替代dkt(u,v)d_k^t(u, v)dkt?(u,v),得到時間和視圖一致的深度圖并反投影為3D點圖。
- 優化:針對高斯尺度初始化問題,基于投影像素面積初始化,公式為scale=d0.5(fx+fy)scale = \frac{d}{0.5(f_x + f_y)}scale=0.5(fx?+fy?)d?;針對高斯密度不足問題,每個輸入像素初始化5個高斯。
4.2.3 Grouping-based Motion Initialization(基于分組的運動初始化)
- 運動模型:將動態3D場景建模為規范3D高斯集合及隨時間變化的剛性變換SE(3)SE(3)SE(3),從規范空間到時間t的變換為xt=R0→tx0+t0→tx_t = R_{0 \to t} x_0 + t_{0 \to t}xt?=R0→t?x0?+t0→t?,Rt=R0→tR0R_t = R_{0 \to t} R_0Rt?=R0→t?R0?。
- 運動基:動態場景的3D運動是低維的,由剛性運動單元組成,時間變化的剛性變換表示為基軌跡的加權組合,公式為T0→t(i)=∑b=1Bw(i,b)T0→t(i,b)T_{0 \to t}^{(i)} = \sum_{b=1}^B w^{(i, b)} T_{0 \to t}^{(i, b)}T0→t(i)?=∑b=1B?w(i,b)T0→t(i,b)?。
- 基于特征聚類的運動基:通過DINOv2提取輸入圖像的像素級特征,經PCA降維到32維,對每個點的特征進行k均值聚類得到初始3D點簇,設置運動基權重w(i,b)w^{(i, b)}w(i,b)為簇中心與3D高斯中心的L2距離,初始化基軌跡T0→t(b)T_{0 \to t}^{(b)}T0→t(b)?為單位矩陣并通過可微渲染優化。
4.2.4 Optimization(優化)
- 重建損失:在每個訓練步驟,采樣隨機時間步t和相機k,渲染圖像、掩碼、特征和深度,計算重建損失Lrecon=∥I^?I∥1+λm∥M^?M∥1+λf∥F^?F∥1+λd∥D^?D∥1\mathcal{L}_{recon} = \|\hat{I} - I\|_1 + \lambda_m \|\hat{M} - M\|_1 + \lambda_f \|\hat{F} - F\|_1 + \lambda_d \|\hat{D} - D\|_1Lrecon?=∥I^?I∥1?+λm?∥M^?M∥1?+λf?∥F^?F∥1?+λd?∥D^?D∥1?。
- 剛性損失:對隨機采樣的動態高斯及其k個最近鄰施加剛性損失,公式為Lrigid=∑neighborsi∥X^t?X^t(i)∥22?∥X^t′?X^t′(i)∥22\mathcal{L}_{rigid} = \sum_{neighbors\ i} \left\| \hat{X}_t - \hat{X}_t^{(i)} \right\|_2^2 - \left\| \hat{X}_{t'} - \hat{X}_{t'}^{(i)} \right\|_2^2Lrigid?=∑neighbors?i??X^t??X^t(i)??22???X^t′??X^t′(i)??22?。
4.3 模塊配置
- 優化器使用Adam,前景使用18k個高斯,背景使用1.2M個高斯,SE(3)運動基數量固定為28,通過特征聚類獲得。
- 深度對齊使用置信度閾值95%以上的點,在7個10秒長、30fps、分辨率512×288的序列上進行實驗,單個NVIDIA A6000 GPU訓練約30分鐘,渲染速度約30fps。
5.【適用任務】
5.1 動態場景的稀疏視圖4D重建
- 適用場景:從少量(3-4個)稀疏分布的靜態相機拍攝的視頻中重建動態場景,如修理自行車、跳舞、彈鋼琴、進行心肺復蘇等人類動態行為場景,可應用于AR/VR、自動駕駛、機器人等領域。
- 核心作用:解決密集多視圖重建方法成本高、難以適應野外多樣化場景的問題,通過對齊獨立單目重建結果,生成時間和視圖一致的動態場景重建結果,實現對動態場景幾何和運動信息的恢復。
5.2 新視圖渲染
- 適用場景:為重建的動態場景渲染全新視角的視圖,尤其是在視圖間重疊有限的稀疏視圖設置下,如渲染與訓練視圖成45°角的新視圖等場景。
- 核心作用:相比現有技術,能在渲染新視圖時實現更高質量的重建,更好地呈現動態前景的運動和場景細節,提升新視圖渲染的準確性和真實性。
5.3 動態人類行為重建
- 適用場景:針對野外捕捉的具有完整場景覆蓋范圍的稀疏視圖視頻,重建人類的熟練行為,如體育活動、烹飪、音樂演奏等場景。
- 核心作用:突破傳統方法對密集相機設置的依賴,利用稀疏視圖相機實現對復雜人類動態行為的高質量重建,為相關行為分析和研究提供支持。
6.【實驗結果與可視化分析】
6.1 實驗設置與數據集
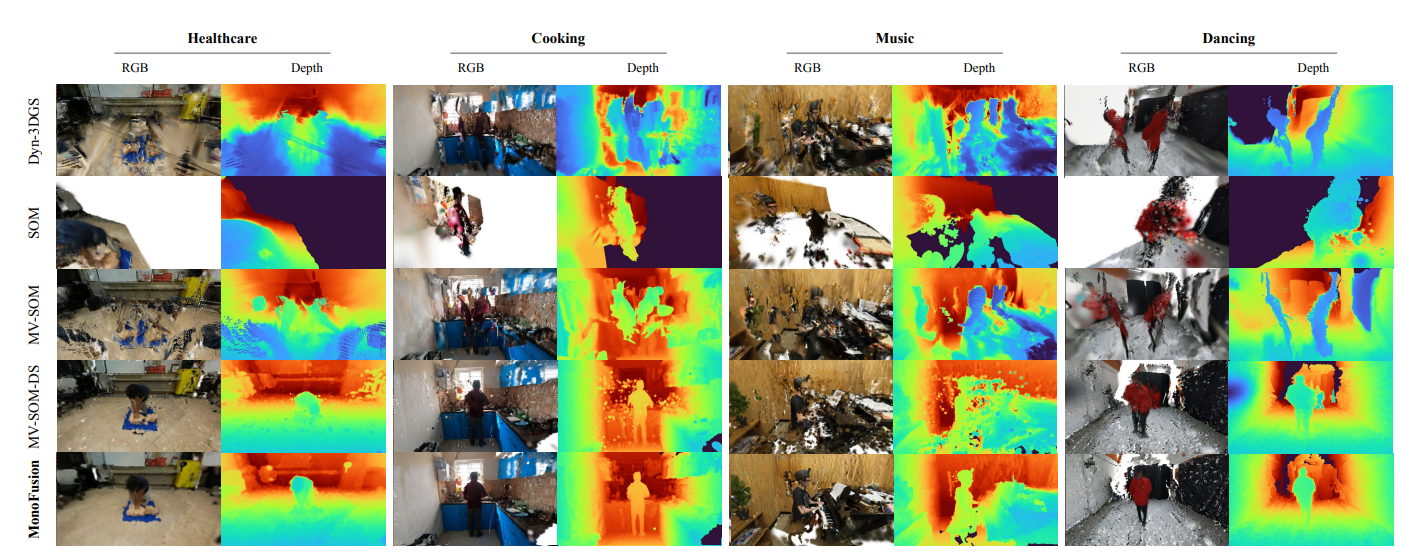
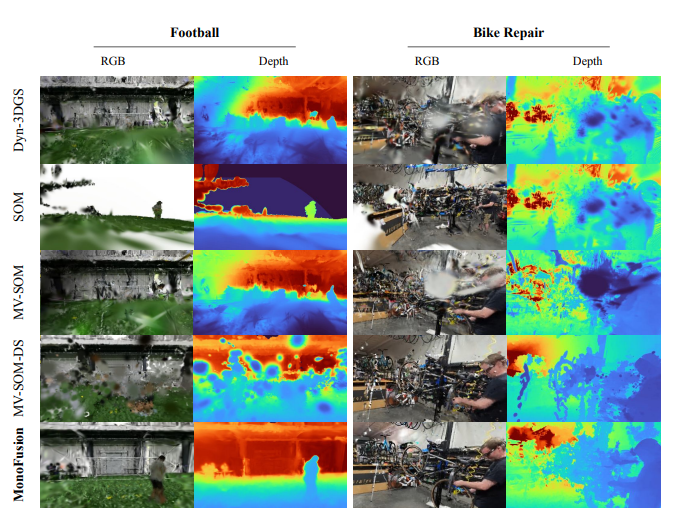
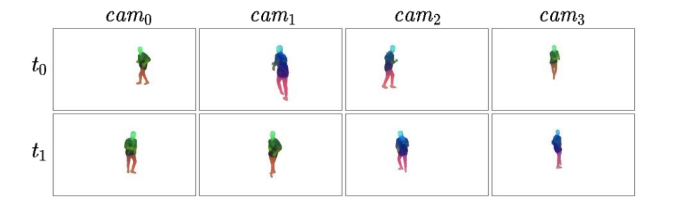
- 數據集:在Panoptic Studio和Ego-Exo4D的子集ExoRecon上進行實驗。Panoptic Studio是一個大規模多視圖捕捉系統,包含480個視頻流,實驗從中選取4個呈90°分布的相機視圖作為訓練視圖,4個呈45°分布的中間相機視圖用于評估45°新視圖合成;ExoRecon則是從Ego-Exo4D中選取的包含6種場景(舞蹈、運動、自行車修理、烹飪、音樂、醫療)的子集,每個場景提取300幀同步RGB視頻流,由4個已知參數的相機拍攝。
- 實現細節:使用Adam優化器,前景采用18k個高斯,背景采用1.2M個高斯,SE(3)運動基數量固定為28且通過特征聚類獲得,深度對齊使用置信度閾值95%以上的點。在7個10秒長、30fps、分辨率512×288的序列上實驗,單個NVIDIA A6000 GPU訓練約30分鐘,渲染速度約30fps。
- 評估指標:采用PSNR、SSIM、LPIPS評估感知質量,AbsRel評估深度幾何質量,mask IoU評估動態前景輪廓質量,這些指標在整個圖像和僅前景區域分別計算。
6.2 與現有技術的對比結果
-
held-out視圖合成評估:在Panoptic Studio和ExoRecon數據集上,MonoFusion在PSNR、SSIM、LPIPS、AbsRel等指標上均優于SOM、Dyn3D-GS、MV-SOM等基線方法。例如在Panoptic Studio的動態區域,MonoFusion的PSNR為27.52,高于Dyn3D-GS的26.11和MV-SOM的26.80;在ExoRecon的全幀評估中,其PSNR達30.43,顯著高于其他方法。
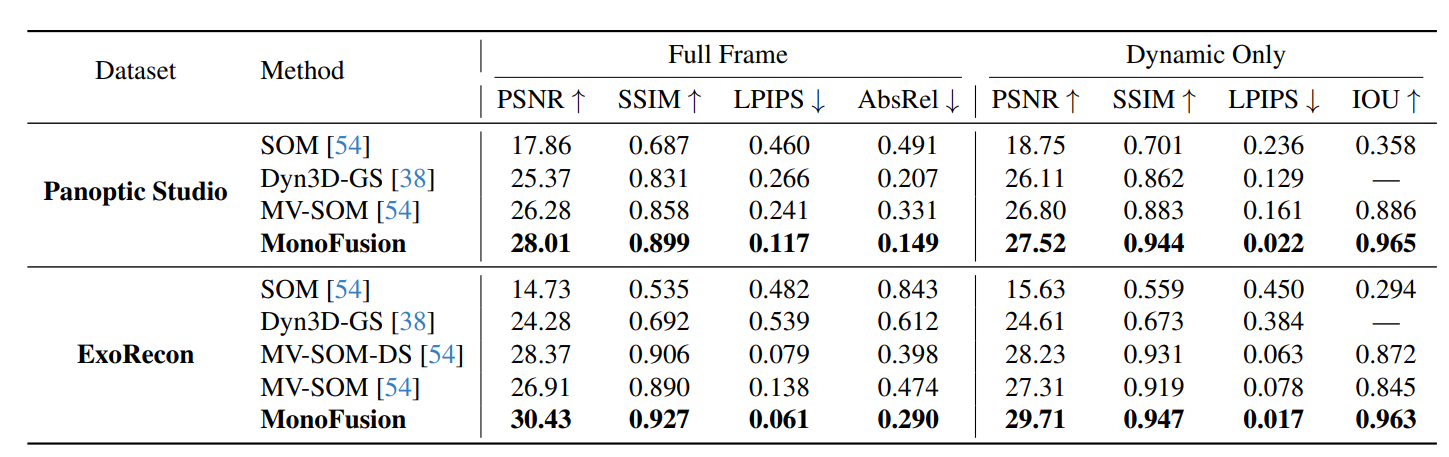
-
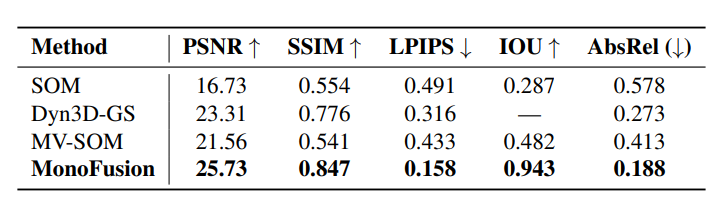
45°新視圖合成評估:在Panoptic Studio上,針對與訓練視圖至少成45°的新視圖,MonoFusion的各項指標仍領先于基線,PSNR為25.73,SSIM為0.847,LPIPS為0.158,AbsRel為0.188,且渲染的RGB圖像與真實值高度接近,而其他基線在極端新視圖上表現不佳。

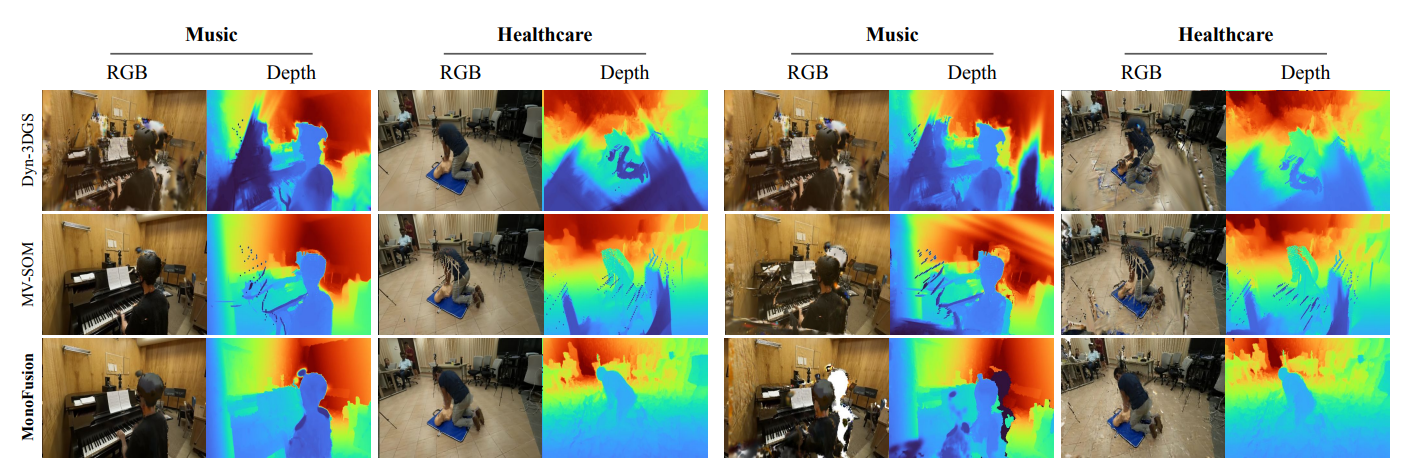
-
定性結果:在ExoRecon的多個場景(如醫療、烹飪、舞蹈等)中,MonoFusion渲染的RGB圖像和深度圖在動態前景運動插值和新視圖生成上質量更高,有效避免了Dyn3D-GS的幾何約束不足和MV-SOM的前景重復等問題。
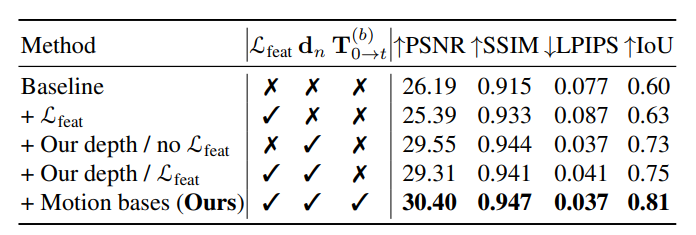
6.3 消融實驗結果
-
各組件的影響:時空一致的深度初始化使PSNR提升3.4,對學習準確的場景幾何和外觀至關重要;特征度量損失雖降低PSNR,但提高了mask IoU,有助于學習前景運動和輪廓;基于特征聚類的運動基進一步優化了場景重建,使PSNR達30.40,IoU達0.81。
-
運動基設計對比:在4相機稀疏視圖設置中,基于特征的運動基比基于速度的運動基表現更好,因后者受噪聲前景深度估計影響大,而前者從更可靠的圖像級觀測初始化特征,對噪聲3D初始化更穩健,能迫使語義相似部分運動一致。
-
運動基數量影響:當運動基數量少于20時,重建易出現缺陷(如缺失手臂、腿部合并);實驗中28個運動基的設計能有效處理不同場景動態,且增加數量未觀察到性能下降。
7.【總結展望】
7.1 總結
該研究針對稀疏視圖視頻的動態場景重建問題,提出了MonoFusion方法,通過四個等距向內的靜態相機實現對動態人類行為的重建。其核心是將各相機的獨立單目重建結果進行仔細對齊,生成時間和視圖一致的動態場景重建,巧妙解決了密集多視圖方法成本高、難以適應野外場景的問題。通過在Panoptic Studio和Ego-Exo4D數據集上的實驗,證明了該方法在渲染新視圖時質量優于現有技術,尤其在45°極端新視圖合成上表現突出,且通過消融實驗驗證了時空一致深度初始化、特征度量損失和基于特征聚類的運動基等組件的有效性。
7.2 展望
未來將致力于解決當前方法的局限性,一方面,針對依賴2D基礎模型估計先驗(如深度和動態掩碼)可能導致的渲染問題,計劃從基礎模型中提取動態掩碼或從圖像級先驗中推斷動態掩碼;另一方面,鑒于現有前饋深度估計網絡在動態場景中對人類深度估計不準確的問題,打算進一步在現有的動態人類數據集上微調DUSt3R或MonST3R,以提升深度預測質量,從而完善稀疏視圖4D重建效果。
8.【項目速通指南】
MonoFusion 使用說明
安裝步驟
克隆代碼倉庫并更新子模塊:
git clone --recurse-submodules https://github.com/ImNotPrepared/MonoFusion
進入項目目錄:
cd MonoFusion/
創建并激活conda環境:
conda create -n monofusion python=3.10
conda activate monofusion
根據實際的CUDA版本更新requirements.txt中PyTorch和cuUML的配置,例如將cu122和cu12替換為對應的版本。
安裝依賴包:
pip install -r requirements.txt
pip install git+https://github.com/nerfstudio-project/gsplat.git
使用方法
項目團隊深知數據處理過程可能復雜且耗時。該解決方案簡化了這一工作流程——只需一次運行,就能獲得經過校正、同步的稀疏視圖數據,以及所有必要的先驗信息。
獲取Ego-Exo4D訪問權限
要使用Ego-Exo4D數據,請遵循以下步驟:
-
獲取許可:在https://docs.ego-exo4d-data.org/getting-started/獲取Ego-Exo4D的許可。
-
下載VRS文件:下載包含特定場景RGB流的VRS文件:
egoexo -o <output_directory> --parts take_vrs --uids <uid1>
注意:VRS文件是確保數據流同步所必需的。
- 提取圖像:從VRS序列中提取校正后的圖像:
viewer_map --vrs aria01.vrs --task vis --resize 512
默認的縮放分辨率為512像素。
預處理
項目提供了一鍵式先驗生成腳本,可保存深度圖、人體掩碼、dino特征和2D軌跡:
./fetch_priors.sh
)










)







