PCA(主成分分析)降維詳解
一、什么是 PCA
PCA(Principal Component Analysis,主成分分析)是一種常用的數據降維方法。它通過線性變換將原始的高維數據映射到低維空間,同時盡可能保留原數據的主要信息(即方差信息)。
一句話總結:
PCA 找到數據變化最大的方向,把數據投影到這些方向上,從而減少維度、壓縮數據,同時降低冗余和噪聲。
二、PCA 的主要作用
數據降維
減少特征數量,加快模型訓練速度。降噪
去除方差較小、貢獻不大的特征,減少噪聲影響。特征提取
把原特征組合成新的主成分,減少相關性。可視化
將高維數據映射到二維或三維,方便繪圖觀察。
三、PCA 的核心思想
PCA 的核心思想是:
找到數據方差最大的方向(主成分方向)
將數據投影到這些方向上
選擇前 k 個主成分作為新的特征空間
方差越大,表示數據在該方向的變化信息越多,保留它可以最大化信息量。
四、PCA 數學推導(簡化版)
假設數據集為 X(已中心化):
計算協方差矩陣
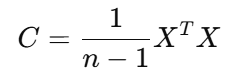
求特征值和特征向量
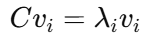
特征向量 vi?表示主成分方向
特征值 λi 表示方差大小
按特征值從大到小排序
取前 k?個特征向量組成投影矩陣 W降維
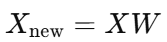
五、PCA 實現步驟
數據標準化(均值為 0,方差為 1)
計算協方差矩陣
求特征值和特征向量
選擇前 k 個主成分
將數據投影到新空間
六、PCA 的優缺點
優點
降維有效,速度快
去除冗余特征,減少過擬合
對噪聲有一定抑制作用
缺點
僅適用于線性降維
主成分是特征組合,不易解釋含義
對特征縮放敏感,需要標準化
七、PCA 應用場景
圖像壓縮(如人臉識別中的特征提取)
高維數據可視化(如基因數據、股票數據)
機器學習前的數據預處理
八、PCA() 函數原型和參數表:
class sklearn.decomposition.PCA(n_components=None,*,copy=True,whiten=False,svd_solver='auto',tol=0.0,iterated_power='auto',n_oversamples=10,power_iteration_normalizer='auto',random_state=None
)
| 參數 | 類型 / 取值范圍 | 默認值 | 作用說明 |
|---|---|---|---|
| n_components | int / float / 'mle' / None | None | - int:降到指定維度- float ∈ (0,1]:保留的累計方差比例(svd_solver='full' 時有效)- 'mle':自動估計最佳維度(svd_solver='full' 時)- None:保留 min(n_samples, n_features) 個主成分 |
| copy | bool | True | 是否在降維前復制數據,False 則在原數組上執行(可能修改原數據) |
| whiten | bool | False | 是否將輸出的主成分縮放為單位方差(去相關+標準化),可能改變原數據的尺度含義 |
| svd_solver | 'auto' / 'full' / 'arpack' / 'randomized' / 'covariance_eigh' | 'auto' | - 'auto':自動選擇- 'full':精確 SVD- 'arpack':截斷 SVD(適合小規模特征子集)- 'randomized':隨機近似 SVD(高維快)- 'covariance_eigh':特征值分解協方差矩陣(樣本?特征時快) |
| tol | float | 0.0 | SVD 收斂閾值(對迭代方法有效) |
| iterated_power | int / 'auto' | 'auto' | 隨機 SVD 的迭代次數(通常保持默認) |
| n_oversamples | int | 10 | 隨機 SVD 的過采樣參數(svd_solver='randomized' 時) |
| power_iteration_normalizer | 'auto' / 'QR' / 'LU' / None | 'auto' | 隨機 SVD 的冪迭代歸一化方式 |
| random_state | int / RandomState / None | None | 隨機種子(svd_solver='randomized' 時保證結果可復現) |
九、PCA Python 實戰
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 使用微軟雅黑字體
plt.rcParams['axes.unicode_minus'] = False # 處理負號顯示異常# 1. 加載數據
iris = load_iris()
X = iris.data
y = iris.target# 2. 創建 PCA 模型(降到 2 維)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)# 3. 可視化
plt.figure(figsize=(8,6))
for target, color, label in zip([0,1,2], ['r','g','b'], iris.target_names):plt.scatter(X_pca[y == target, 0], X_pca[y == target, 1], c=color, label=label)plt.xlabel('主成分 1')
plt.ylabel('主成分 2')
plt.title('PCA 降維后的鳶尾花數據')
plt.legend()
plt.show()# 4. 方差貢獻率
print("各主成分方差貢獻率:", pca.explained_variance_ratio_)
# 輸出結果:各主成分方差貢獻率: [0.92461872 0.05306648]輸出示例:
各主成分方差貢獻率: [0.92461872 0.05306648]說明前兩個主成分保留了約 97.7% 的信息。
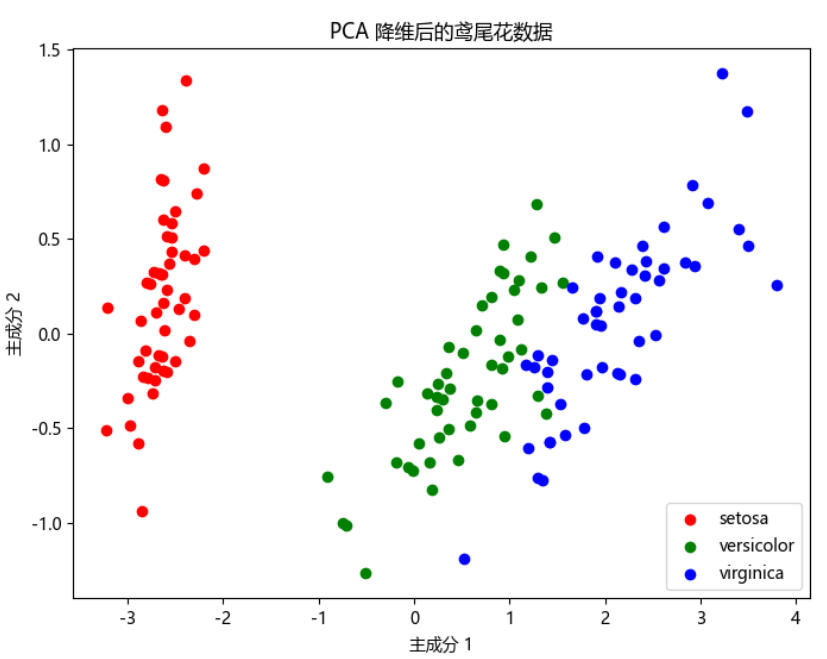
十、PCA 可視化原理
PCA 本質上是在找一組新的坐標軸(主成分軸),數據被重新投影到這些軸上,從而實現降維。
在二維圖中,這些主成分軸相當于旋轉后的新坐標系。
十一、總結
PCA 是通過最大化方差來提取主要特征的線性降維方法。
核心步驟是計算協方差矩陣 → 求特征值和特征向量 → 投影到主成分。
適合在特征數量大、存在相關性、需要可視化的場景使用。






)




)







方法的作用和場景說明)