摘要:本文整理自阿里云的高級技術專家、Apache Flink PMC 成員李麟老師在?Flink Forward Asia 2025 新加坡[1]站 —— 實時 AI 專場中的分享。將帶來關于 Flink 2.1 版本中 SQL 在實時數據處理和 AI 方面進展的話題。
Tips:點擊「閱讀原文」跳轉阿里云實時計算 Flink~
Flink 2.1 SQL 的關鍵進展
本篇將探討三個部分:
Data + AI:在 Flink SQL 中連接實時數據處理與AI能力
首先,將介紹?Flink SQL 2.1 如何連接實時數據處理與AI能力。您將看到我們如何增強對 AI 函數的支持,從模型注冊到通過?ML_PREDICT?與 SQL 的無縫集成,支持大模型文本生成和RAG工作流等任務。
優化 Join:解決 Flink 流式 Join 中的關鍵挑戰
接下來,了解一下解決流式連接中的一個關鍵挑戰。深入探討兩個關鍵改進:Delta Join,通過結合索引和變更日志處理來消除狀態存儲;以及 Multi-way Join,在保持低延遲的同時減少多流連接中的冗余。
未來展望:Flink SQL 在數據與 AI 方面的持續增強和路線圖
最后,將分享未來的路線圖,包括 RAG 管道中的向量搜索支持和擴展的AI函數支持。
接下來我將展示 Flink 2.1 如何讓您無縫構建可擴展的實時 AI 管道。在深入 Flink AI 函數之前,讓我們先從一個現實世界的問題開始。
案例:實時產品合規性
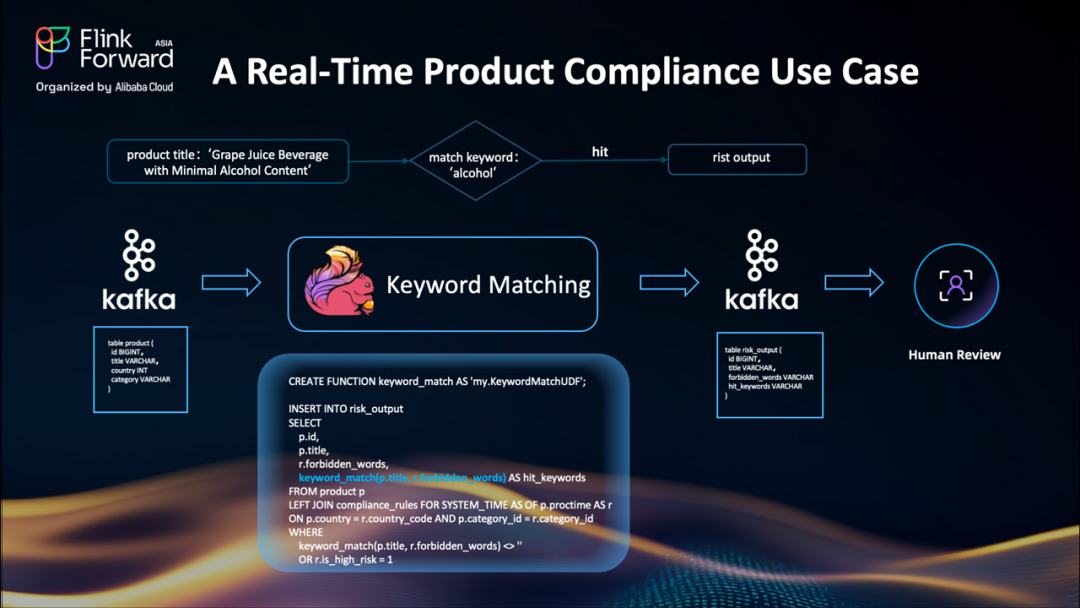
想象一下您正在運營一個全球電商平臺。平臺賣家每天會發布數百萬個產品。但問題是:您需要確保每一個產品發布都符合您運營的每個國家的當地法律。
例如,一個標題為"含微量酒精的葡萄汁飲料"的產品在特定國家違反了政策,因為它包含"酒精"。
目前,團隊使用 Flink SQL 構建管道來幫助人工審核:
首先從 Kafka 主題讀取產品列表數據
使用自定義 UDF 如?
keyword_match,根據禁用關鍵詞列表檢查標題輸出風險列表供人工審核
但問題是——基于規則的系統非常僵化。
基于規則的關鍵詞匹配的挑戰:誤報和漏報
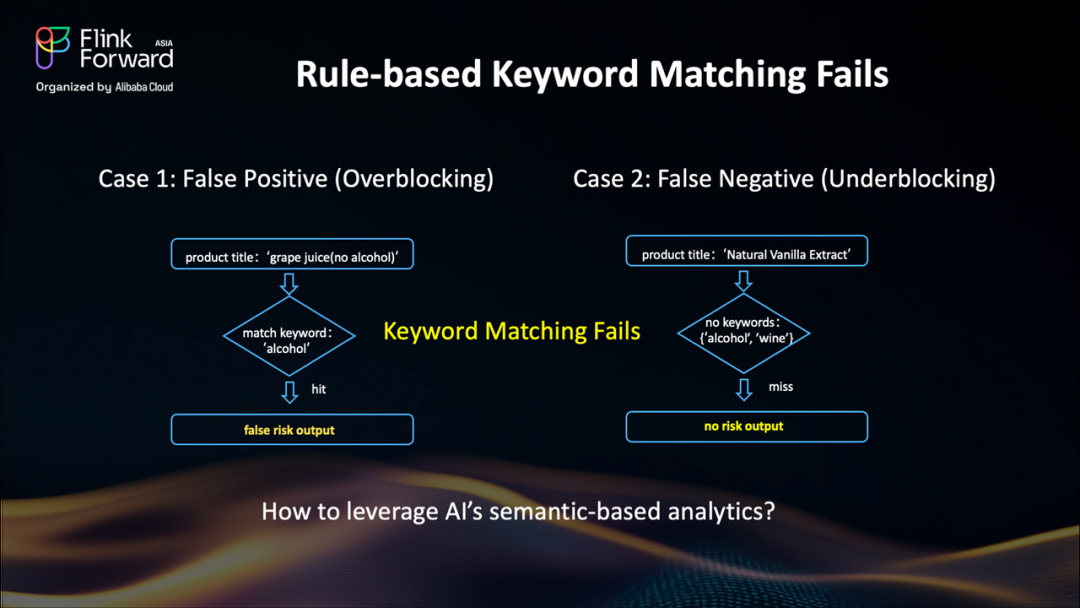
好的,讓我們看兩個基于規則的關鍵詞匹配失敗的具體例子。
案例1:過度阻攔案例(誤報)
想象一個標題為"葡萄汁(無酒精)"的產品。關鍵詞"酒精"觸發了規則,系統將其標記為風險。但它明確說了"無酒精"!這是一個誤報——我們阻攔了一個安全的產品,浪費了人工審核時間,并可能導致客戶不滿。
案例2:阻攔不足案例(漏報)
現在,看看這個標題:"天然香草提取物"。我們的關鍵詞列表包括"酒精"和"酒",但香草提取物通常含有酒精!規則完全遺漏了它——這是一個漏報。這可能導致嚴重的處罰。
那么...我們如何解決這個問題?這就需要比關鍵詞匹配更智能的檢測能力。
利用AI的語義分析實現更智能的合規性
讓我們測試一下 AI 是否更優秀。這里有一個 ChatGPT 的簡單例子——這可以是您訓練的任何 LLM 或自定義模型。
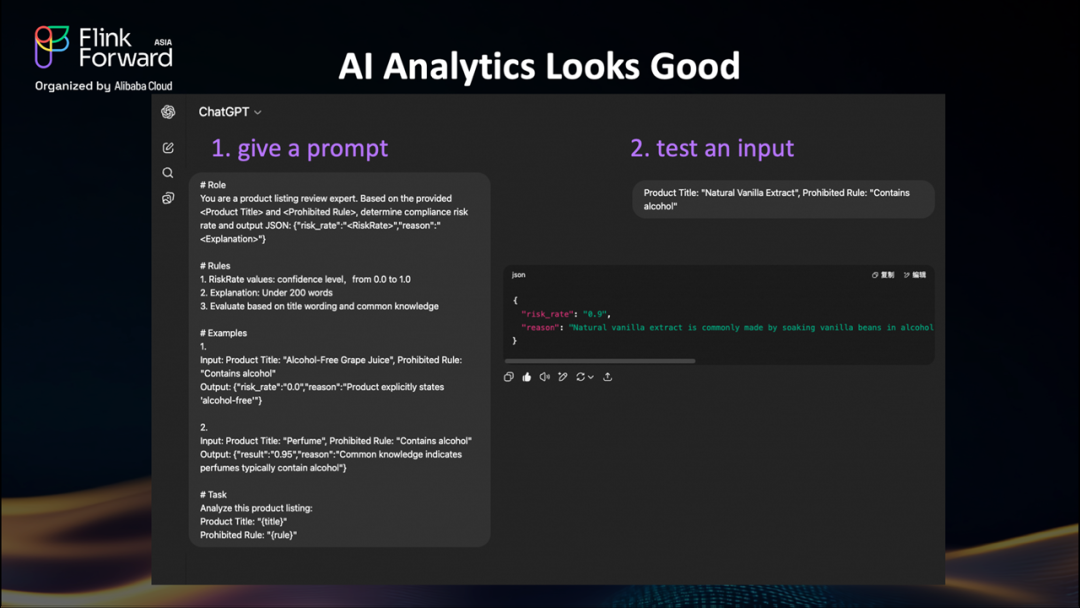
步驟1:教AI任務
我們給模型一個清晰的提示,包括角色、規則和示例。
步驟2:用我們的問題案例測試
當我們輸入棘手的"天然香草提取物"案例時,AI推導出它"含有酒精"。這正是我們需要的。
現在,讓我們嘗試將其集成到 UDF 中。
Flink 自定義 AI UDF 的隱性成本
我們構建了一個直接連接到 LLM 的新 UDF,管道看起來幾乎和以前一樣。相同的流程:
Kafka 輸入(產品標題流入)
升級到新 UDF 后,決策現在更加智能
Kafka 輸出(結果進入相同的審核主題——下游無需更改)
看起來完美...但是等等。
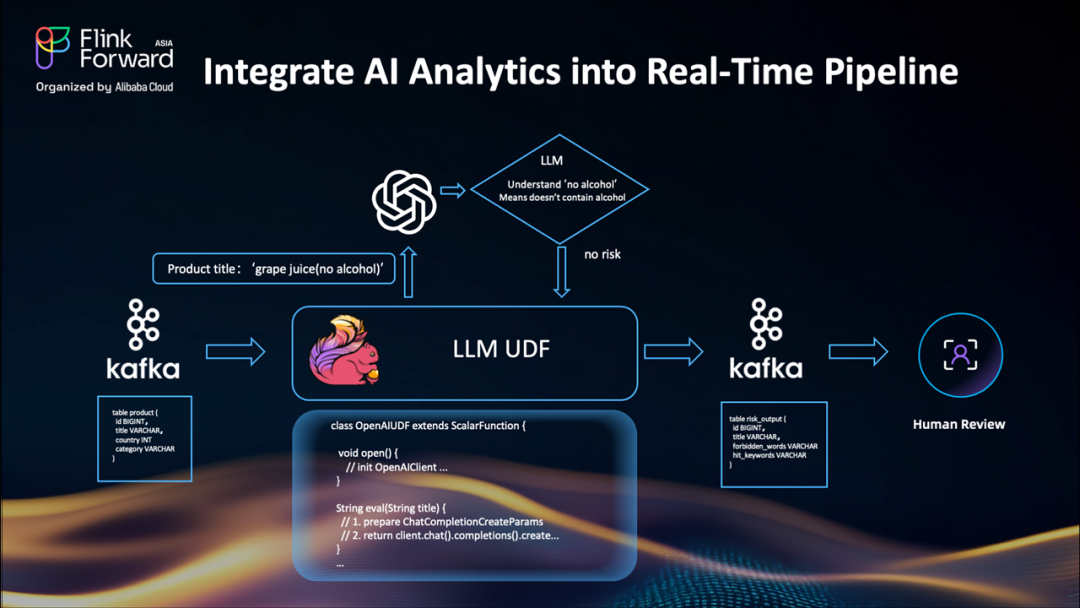
雖然這對小規模測試有效,但現實的挑戰很快就會出現。
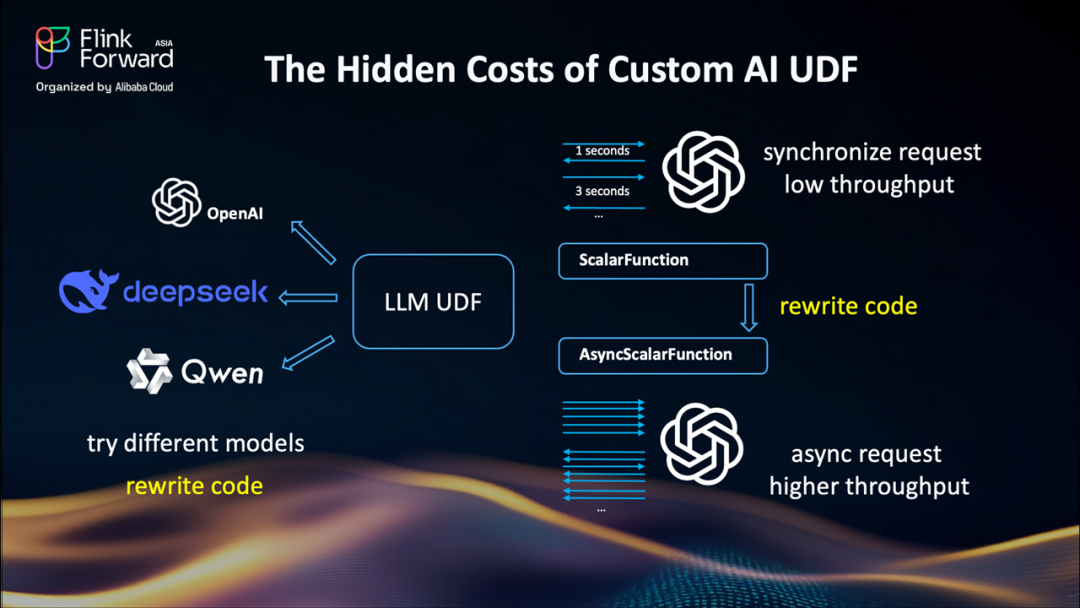
構建自定義 LLM UDF一開始感覺很棒,但現實情況是
代碼重寫:如果我們想從 OpenAI 切換到阿里云,我們需要重寫 UDF 代碼。測試不同的模型?更多的代碼更改。這種方法無法擴展。每次新模型或 API 更改時重寫 UD F代碼是不高效的。
同步請求 = 交通堵塞:每個產品標題都會觸發對 LLM 的同步 API 調用。每次調用需要1-3秒——那么吞吐量將非常低。所以如果我們想要使用異步請求獲得更高的吞吐量,我們需要通過使用?
AsyncScalarFunction?再次重寫 UDF。現在我們應該更多地關注異步回調和錯誤處理。這不有趣,必須有更好的方法。
讓我們看看 Flink 2.1 如何解決這個問題。
Apache Flink SQL 原生 AI 函數:簡化AI集成
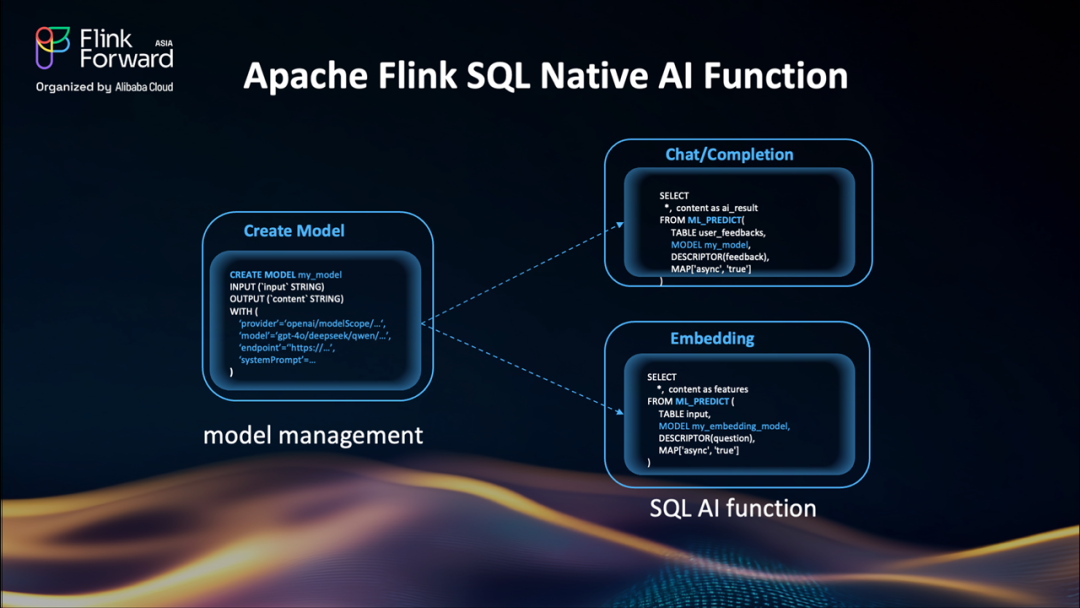
以下是利用 Flink SQL 原生 AI 函數的工作流程:
使用?CREATE MODEL?通過簡單的 SQL 命令注冊需要的 LLM。需要切換模型?只需更改?MODEL?參數——無需重寫代碼。模型管理變得如此簡單。
Flink 2.1 中的新?ML_PREDICT()函數已為這些用例做好準備:
聊天/生成式任務:對于產品合規性檢查、情感分析等場景,只需將文本傳遞給模型,它就會返回分析結果。
embedding:進行特征提取,通過從文本生成向量嵌入來為您的 RAG 管道提供支持。
一切都直接在 SQL 中工作。啟用異步處理:只需添加一個簡單的參數。切換模型:在 SQL 查詢中引用?MODEL名稱,無需 UDF 代碼更改。
使用 Flink SQL AI 函數的實時產品合規性:具體示例
讓我們通過一個具體的示例將所有內容整合在一起。以下是 Flink AI 函數如何解決我們的產品合規性挑戰:
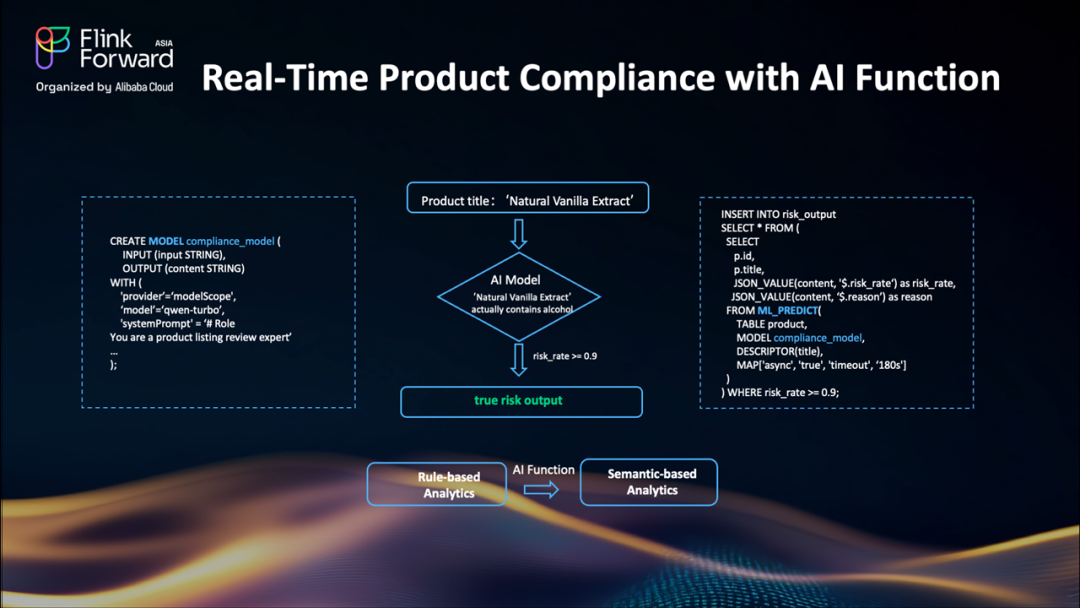
首先,我們使用?CREATE MODEL?語法創建一個合規性模型——需要指定提供商(這里是阿里云的百煉平臺)、模型名稱?qwen-turbo,以及告訴AI其作為產品列表審核專家角色的系統提示。
當像"天然香草提取物"這樣的產品標題到達時,Flink 通過?ML_PREDICT?函數將其發送到 AI 模型。這是一個異步請求以確保高吞吐量。模型分析它并返回 JSON 響應。
最后,當?risk_rate超過定義的閾值時,我們將結果插入風險輸出 topic。
優化 Flink SQL AI 函數:異步調優和資源規劃以提升性能

讓我們深入了解兩個關鍵優化:異步配置和資源設置。
異步執行是首選:在?
ML_PREDICT()調用中啟用異步執行可以是首選。與增加任務并行度相比,這更具成本效益。對于僅追加的流,使用?allow_unordered output_mode,這樣 Flink 可以處理得更快。設置?max-concurrent-operations?以匹配您的 LLM 容量。如果您不想觸發任務失敗,可以將異步超時參數設置得比 AI 的最大延遲更大。有關異步操作的更多詳細信息,請參考?Flink文檔[2]。基于 Little 定律進行資源規劃:應用此公式進行容量規劃:
L:隊列槽位(對應?
max-concurrent-operations)λ:請求速率(對應預期的 QPS)
W:平均延遲(對應模型的響應時間)
例如:對于目標100 QPS和1.2秒的99百分位延遲,我們需要120個最大并發請求(max-concurrent-operations)。此外,考慮到隊列長度和平均行大小,我們需要更多關注 TaskManager 中的內存設置。適當的調優可能顯著提升運行 AI 函數的吞吐量和穩定性。
JSON 無處不在:從大數據到AI工作流
在深入了解 Join 之前,先聊一聊一個基礎的數據類型:JSON。
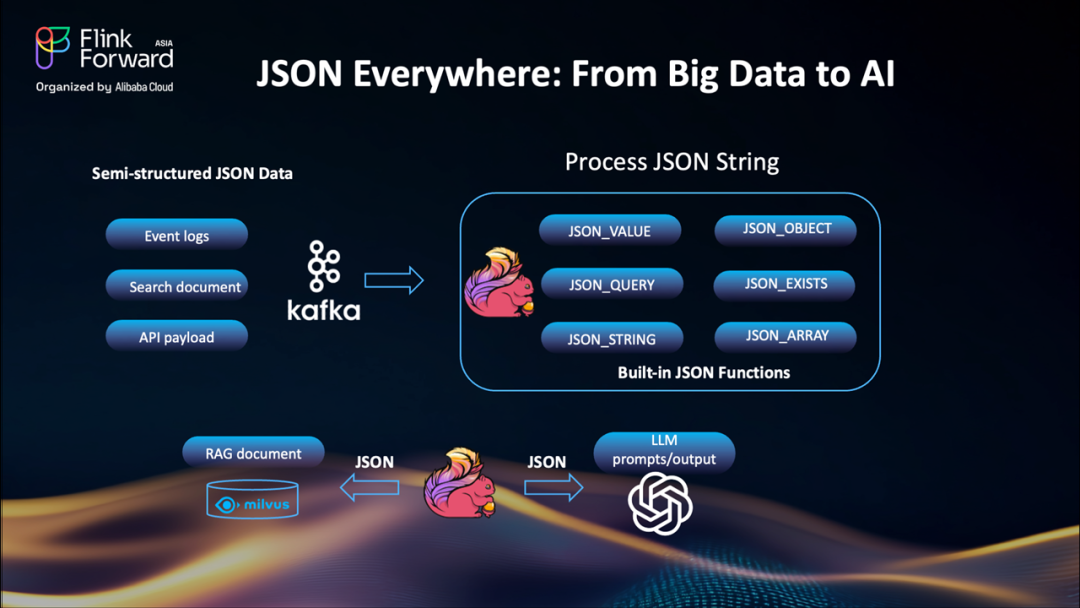
讓我們從一個簡單的事實開始:JSON 無處不在。從傳統數據管道到新的 AI 工作流,JSON 是表示結構化和半結構化數據的重要格式。我們在事件日志、搜索文檔、API 負載中看到它。RAG 管道依賴 JSON 來存儲和查詢文檔。甚至 LLM 提示和輸出通常也格式化為 JSON。
到目前為止,Flink SQL 已經支持許多內置的 JSON 函數。但隨著 JSON 變得更深入和更動態,這里有一個性能挑戰。
過去 Flink 中 JSON 解析的隱性成本
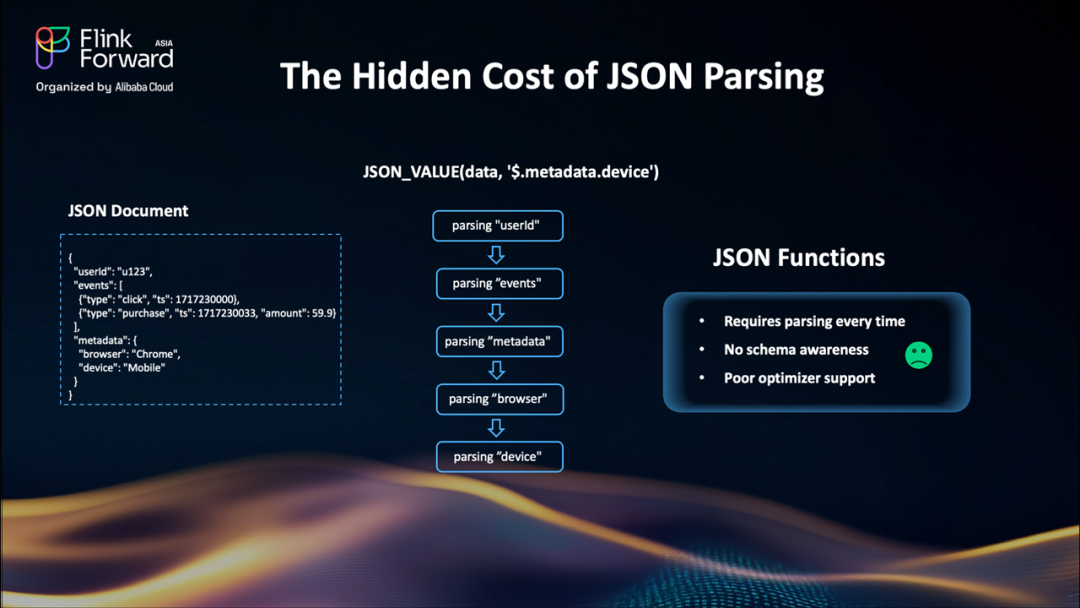
表面上,JSON_VALUE?和類似的函數使得訪問 JSON 字符串內的數據變得容易。但在底層,每次調用都會觸發完整的 JSON 解析。每次都是如此,對每一行都是如此。這對簡單情況可能工作得很好,但在處理大型數據集、嵌套結構或深度查詢路徑時——比如 JSON 路徑?$.metadata.device——性能會快速下降。
沒有 schema 感知,JSON 內部沒有索引,所以 SQL 優化器無法優化訪問。
Flink SQL 的新 VARIANT 類型:高效的半結構化數據處理
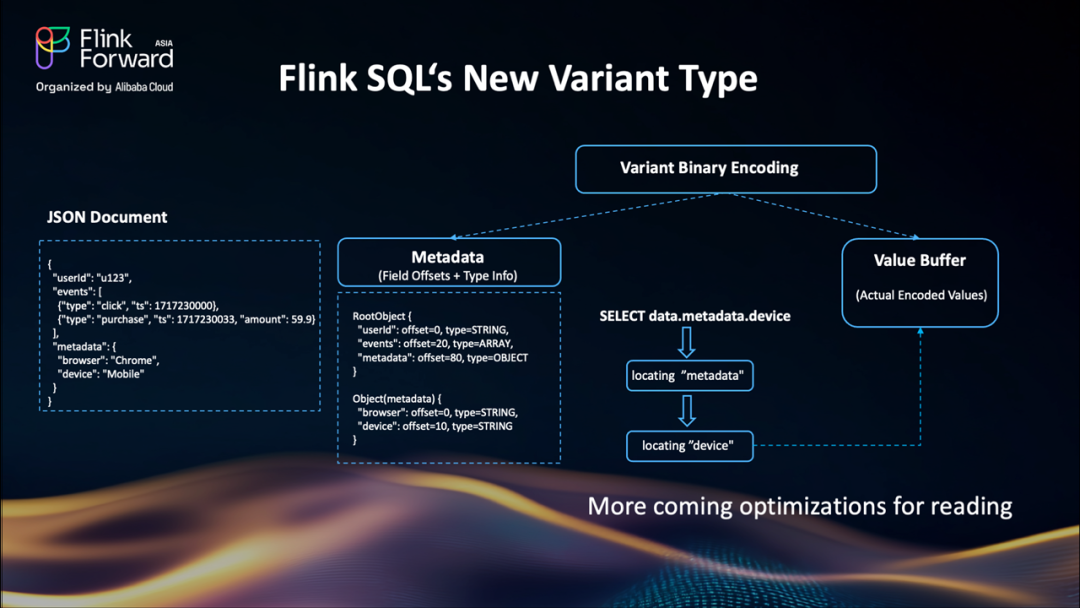
Flink 2.1 引入了新的?VARIANT?類型,這是一個原生的、二進制編碼的半結構化類型。與普通的 JSON 字符串不同,VARIANT以結構化方式存儲元數據和值。因此訪問?data.metadata.device?只是一個直接的偏移查找,不再是完整的解析。
因為它是感知 schema 的,SQL 規劃器可以在未來版本中應用查詢優化。這使其非常適合數據管道。VARIANT為大規模處理 JSON 解鎖了性能和靈活性。了解更多關于?Flink VARIANT 類型[3]的信息。
優化連接:解決 Flink 流處理中的關鍵挑戰
現在讓我們轉向流式連接,這是實時處理中的另一個核心挑戰。Flink SQL 支持豐富的連接類型:Regular Join、Interval Join、Temporal Join、Lookup Join 等等。每種都是為特定用例設計的。其中,regular join 是最直觀的——它看起來完全像傳統的 SQL 連接,使其易于編寫和理解。
Flink 流式連接的限制:大規模可擴展性
讓我們看看 Regular Join 是如何工作的:我們有兩個輸入流:頁面瀏覽和訂單從 Kafka 到達,它們將通過?product_id?列實現 Join。Join 操作符有兩個狀態存儲,左狀態和右狀態,都按?product_id?分組存儲。當新事件到達時,Flink 在對端的狀態表中查找匹配的條目,執行連接邏輯并輸出。
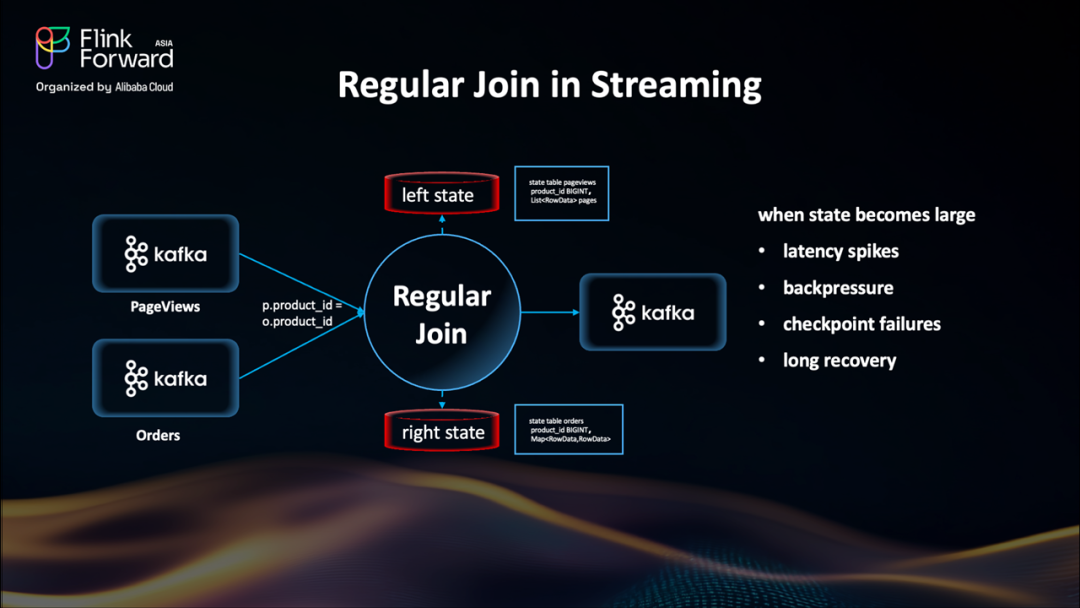
Regular Join 嚴重依賴 Flink 的狀態后端來緩沖輸入流。當正確使用時,這提供了高吞吐量和低延遲,特別是對于小到中等大小的數據流。但隨著流大小的增長,Regular Join 開始出現問題。連接節點每一側維護的狀態變得越來越大。最終,這導致狀態訪問緩慢、檢查點時間長和恢復時間長。您可能開始看到延遲峰值、背壓,甚至檢查點失敗。這是一個經典的權衡——簡單性和靈活性以可擴展性為代價。
那么我們如何解決 ?Regular Join 的大狀態問題呢?
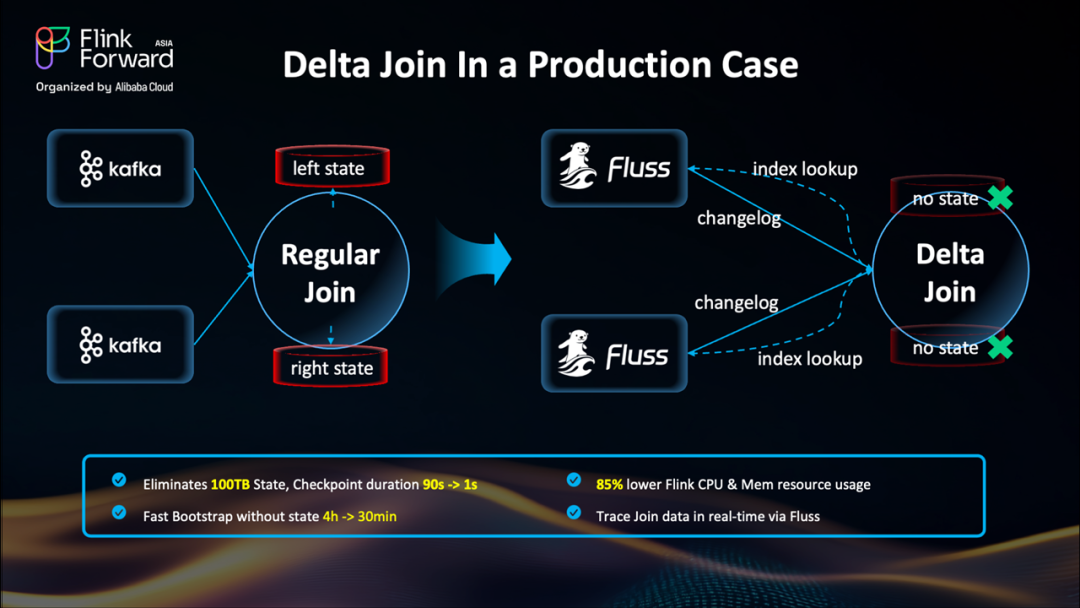
Delta Join:無狀態 Join 的全新范式
這就是 Delta Join 的用武之地——它帶來了一種截然不同的設計思路。與傳統 Join 方式將所有數據緩存在 Flink 狀態后端不同,Delta Join 轉而依賴外部存儲系統(例如基于 RocksDB 構建的 ?Apache Fluss),將數據存于外部,實現真正的無狀態計算。
其工作原理如下:
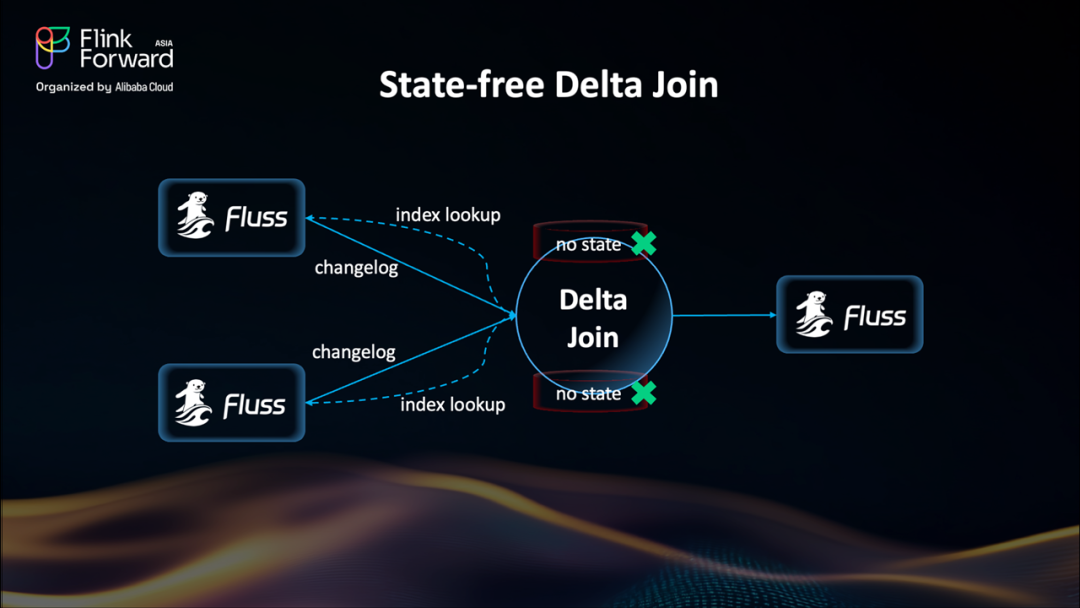
Fluss 會持續發送變更日志(changelog)更新,確保 Join 數據始終最新。每當有新事件到達時,Delta Join 只需在 Fluss 中執行一次索引查詢——就像訪問一個鍵值存儲(key-value store)一樣簡單高效。
可以看到,現在的 Delta Join 已經完全無狀態。此前困擾流處理的各種“大狀態”問題也隨之消失。這使得過去難以實現的大規模 Join 任務,如今成為可能。
Delta Join 實戰表現:真實場景下的性能飛躍
在生產環境中的實際表現印證了 Delta Join 的巨大價值。
傳統的流式 Join 在數據規模擴大后迅速變得難以維系:狀態體積膨脹至 100TB 以上,檢查點耗時極長,故障恢復復雜且耗時。而通過 Delta Join,我們將狀態外卸至 Fluss 等外部存儲系統,實現了秒級檢查點,CPU 與內存使用降低超 80%,啟動冷啟時間縮短 87%,并首次實現了 Join 算子的實時可追溯性。這使得 Flink 在處理超大規模 Join 任務時,變得更加穩定、高效、可擴展。
級聯 Regular Join vs. Multi-way Join:從冗余中突圍
讓我們深入看看傳統 Join 的一個“隱形陷阱”——尤其是在多流關聯場景下的性能瓶頸。
Flink 的 Regular Join 是一個二元操作:一次只能連接兩條流。如果我們想關聯 T1、T2 和 T3 三張表,系統必須構建一個級聯式執行計劃:先將 T1 與 T2 關聯,再將結果與 T3 關聯。
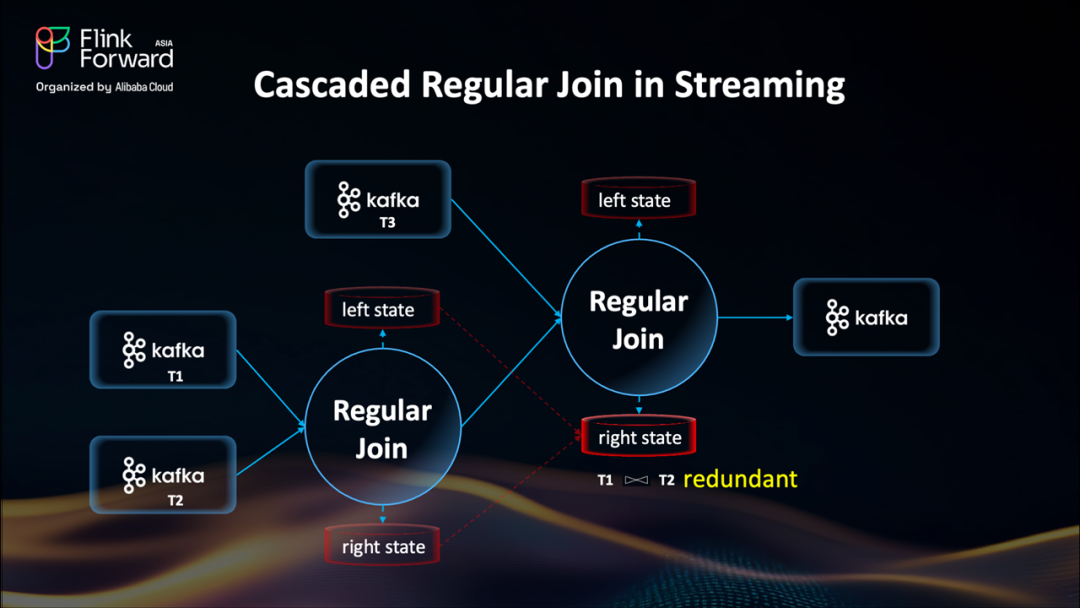
這種模式帶來了嚴重的效率問題:
每個 Join 階段都需要維護自己完整的狀態;
中間結果(如 T1 與 T2 的關聯結果)會被重復存儲;
整體狀態體積呈倍數增長,檢查點時間急劇上升。
雖然?FLIP-415 的 mini-batch join[4]?能緩解部分中間結果輸出的壓力,但無法解決狀態重復存儲的根本問題。
那么,如何破局?
答案就是:Multi-Way Join。
流式 Multi-Way Join:高效 Join 的新范式
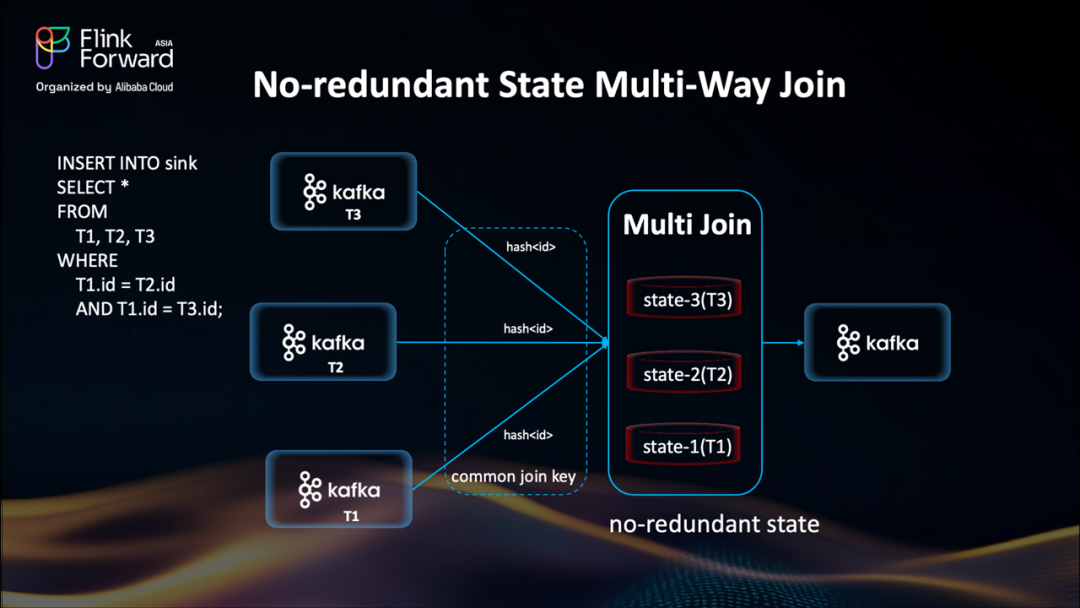
Multi-Way Join 是一種全新的 Join 策略,從設計源頭就杜絕了冗余。
它允許使用同一個關聯鍵,在單個算子內同時關聯多條流。不同于級聯式的二元 Join,Multi-Way Join 為每條輸入流維護一個獨立的索引狀態表,不再生成中間 Join 結果,也無需嵌套存儲。
這意味著:
沒有中間狀態復制
沒有嵌套檢查點延遲
關聯的流越多,優勢越明顯。尤其在復雜事件處理、多維事實表關聯等場景下,性能提升顯著。
未來展望:Flink SQL 的 AI 與數據融合之路
接下來,讓我們看看 Flink SQL 的未來發展方向。
Flink SQL 支持端到端 RAG 流水線
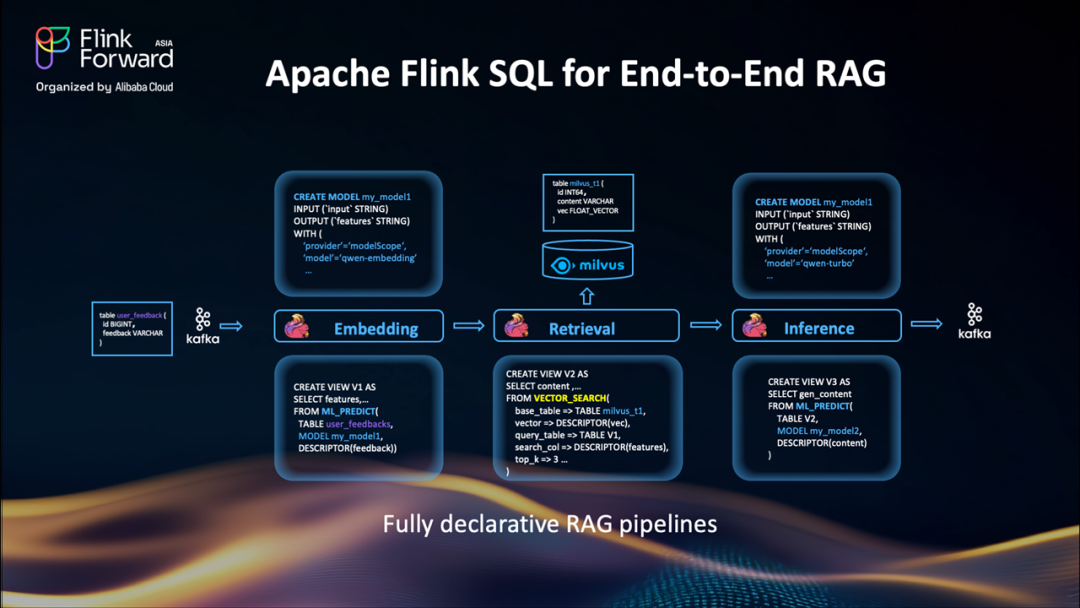
一個重要的短期目標是:在 SQL 中原生支持端到端的 RAG(檢索增強生成)流程。
目前,用戶可以使用 Flink 生成嵌入向量并寫入 Milvus 等系統,但檢索環節仍無法通過 SQL 直接處理。
未來,我們將引入?VECTOR_SEARCH?函數,直接在 Flink SQL 中實現向量檢索,并結合?ML_PREDICT?完成嵌入與生成,實現完全聲明式的 RAG 流水線:
數據攝入與向量化
通過向量檢索獲取 top-k 相似結果
將檢索結果用于下游模型推理
整個流程無需編寫 Java/Python 代碼,真正實現“用 SQL 寫 AI 流水線”。
AI 能力擴展:支持多模態與評估函數
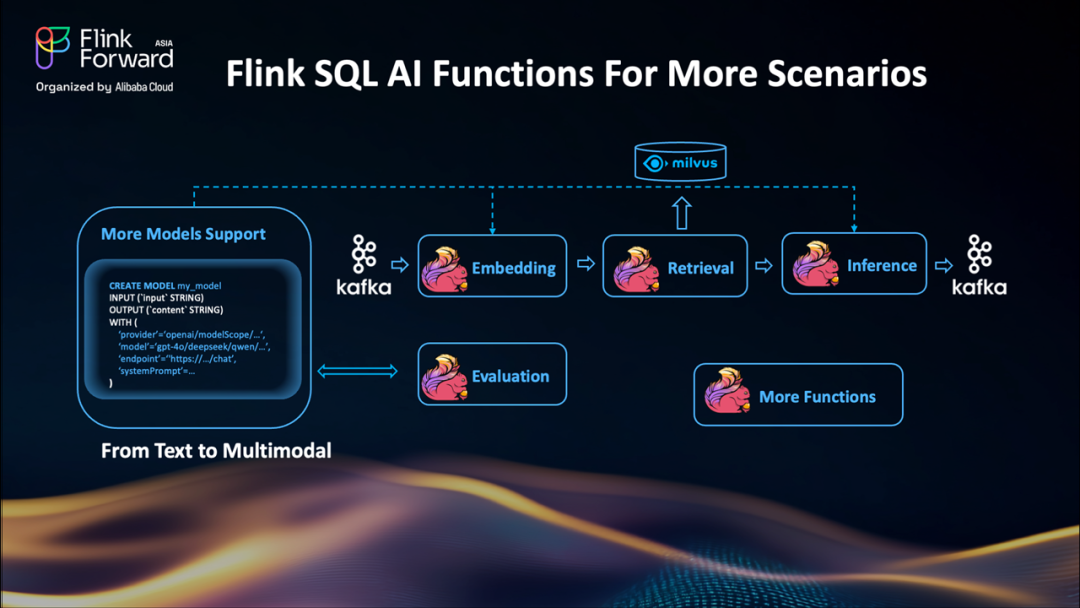
我們也在持續拓展 Flink SQL 的 AI 能力邊界。除了現有的文本處理和嵌入函數,未來將支持:
多模態處理:支持圖像、音頻等非文本輸入;
評估函數(Evaluation Functions):在流水線執行過程中,實時評估模型輸出的質量(如相關性、毒性、重復率等)。
這些能力將幫助用戶在數據流中直接集成、監控和調優模型行為,實現更完整的智能處理。
持續優化:流式 Join 性能再突破

Join 性能始終是流式計算的核心課題。Delta Join 已通過解耦了 Flink Task 與本地狀態的強綁定,有效解決了大數據量 Join 的擴展性難題。未來,我們將進一步支持更多存儲引擎(如 Apache Paimon),以實現近實時 Delta Join。同時,我們也在增強對復雜多流 Join 的支持,包括:
放寬 Schema 對齊要求;
支持更豐富的查詢模式;
目標是讓 Flink 在面對復雜關聯場景時,更加靈活、高效、易用。
要點總結:Flink 2.1 SQL 的三大關鍵點

最后,總結本次分享的三大關鍵點:
Flink SQL 融合 AI:讓數據與智能無縫集成 原生支持模型管理與 AI 函數,讓 AI 流水線在 SQL 中更統一、更易用; 新增?
VARIANT?類型,高效處理 JSON 等半結構化數據,為未來 Planner 優化奠定基礎。攻克流式 Join 頑疾 Delta Join:通過狀態卸載,徹底擺脫本地大狀態束縛,提升穩定性與資源效率; Multi-Way Join:消除多流關聯中的冗余狀態,實現更輕量、更快速的 Join 處理。
未來路線圖:更智能、更靈活 擴展 AI 支持:集成向量檢索、多模態處理; 持續優化 Join 性能:支持更多存儲、更復雜查詢。
所有這些努力,都是為了一個目標:讓 Flink SQL 成為構建實時、智能數據流水線的終極利器。
[1] https://asia.flink-forward.org/singapore-2025
[2] https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/sql/queries/model-inference/#configuration-options
[3] https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/types/#variant
[4] https://cwiki.apache.org/confluence/display/FLINK/FLIP-415:+Introduce+a+new+join+operator+to+support+minibatch
)












)





)