
8月2日,滴滴宣布其開源云原生操作系統可觀測性項目HUATUO正式入駐中國計算機學會(CCF),加入其重點孵化項目序列。本次入駐不僅體現了滴滴長期踐行開源共建共享的理念,也希望通過行業協作,共同推動可觀測領域操作系統基礎設施的高效標準化發展。

HUATUO(華佗)是滴滴自研并開源的云原生操作系統可觀測性項目,聚焦解決云原生環境中故障現場缺失、復現困難、診斷成本高等問題。面對容器漂移、架構復雜、上下游依賴多等挑戰,HUATUO基于 BPF技術,整合 kprobe、tracepoint、ftrace等動態追蹤手段,構建了低損耗、零侵擾的多維度內核觀測能力體系,包括精細化指標埋點、異常上下文捕獲、系統毛刺自動追蹤及多語言持續性能剖析。當前,HUATUO已在滴滴生產環境中實現規模化部署,覆蓋多類復雜故障場景,在系統高可用性保障與性能優化中發揮了關鍵作用。

技術架構
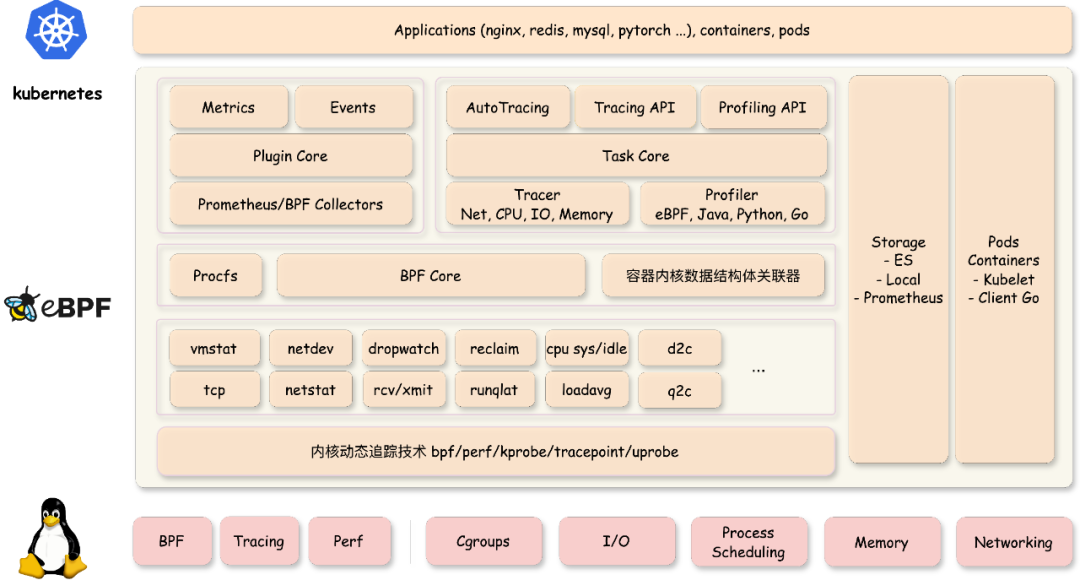
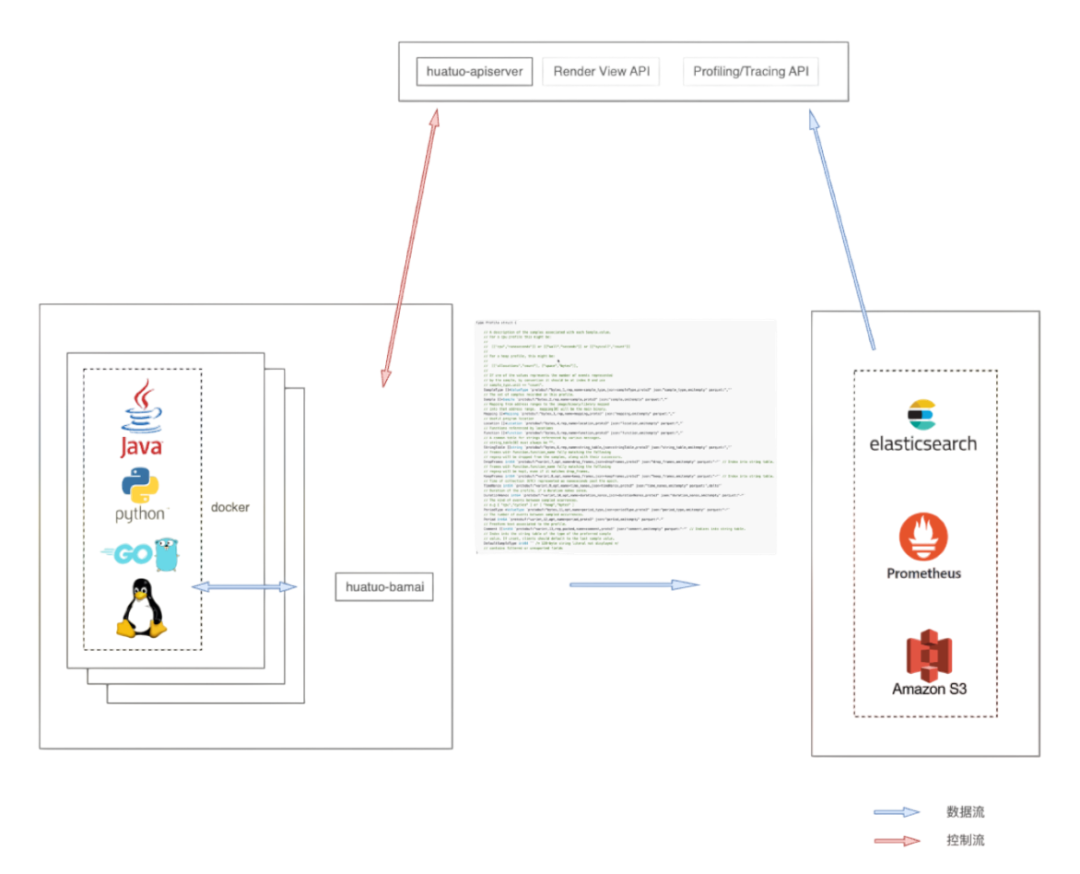
HUATUO系統在設計上重點考量了可擴展性、易用性、穩定性、可降級性、模塊獨立性以及接口設計等核心要素。系統主要由底層數據采集器和 apiserver 兩部分構成。上圖展示了數據采集器的架構,下面主要從軟件架構進行說明:
- 在指標采集方面,為提升指標的擴展性和易用性,HUATUO實現了一套統一的指標框架。該框架向上層提供符合Prometheus標準的開源指標格式輸出,同時向下為開發者暴露簡潔的Go語言接口。開發者僅需實現此接口,即可高效便捷地集成新的監控指標。
- 針對內核事件處理,HUATUO提供了專門的事件框架。該框架核心負責實時感知與處理各類內核事件,并為開發者封裝了大量底層實現細節。開發者只需專注于實現一個輕量級的特定接口,即可快速擴展新的內核事件類型。
- 任務追蹤(Tracing)管理,HUATUO承擔著管理來自AutoTracing和 apiserver的完整任務生命周期的職責,確保追蹤任務的順暢執行與狀態維護。
- 系統支持采集多種類型的觀測數據,HUATUO實現了統一的存儲接口,后端包括本地文件系統、Elasticsearch (ES) 以及Amazon S3等。這一設計使得具體的存儲實現細節對開發者完全透明,簡化了存儲選型與接入。
- 基于成熟的Cilium BPF庫,HUATUO重新設計了 BPF 管理功能。創新地采用BPF對象文件的方式,實現了業務應用邏輯與底層操作系統的解耦。
- HUATUO支持火焰圖處理功能。該功能通用強,支持處理生成 CPU 使用、內存分配、網絡 I/O 等關鍵子系統性能瓶頸的火焰圖。
- 最后,HUATUO建立了一套關聯機制,將內核數據結構體和容器信息關聯。為了實現內核數據和容器信息關聯,HUATUO從云原生組件獲取pod/容器信息,從內核捕獲容器創建刪除事件,通過cgroup id、css、容器 ID 等進行關聯。

核心特性
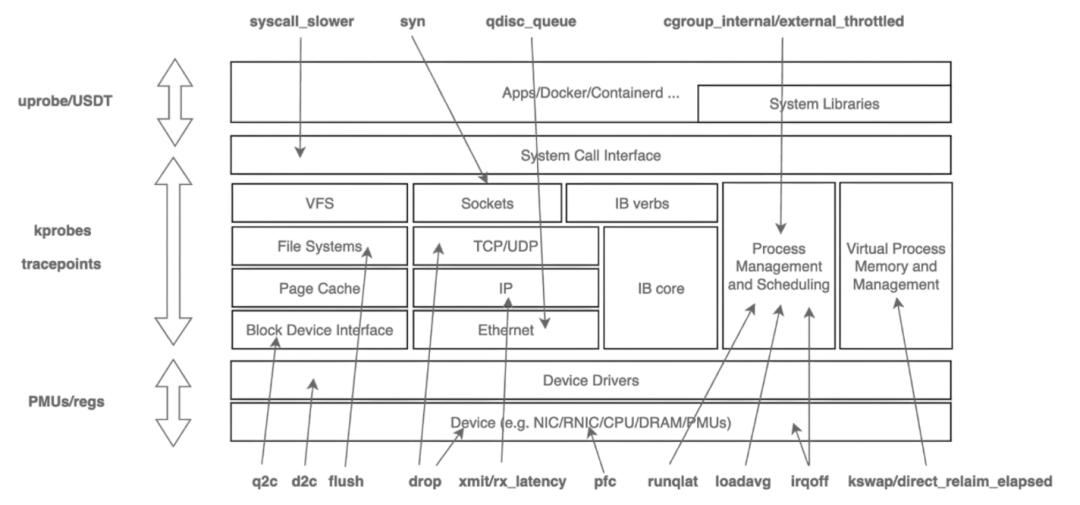
低損耗內核全景觀測
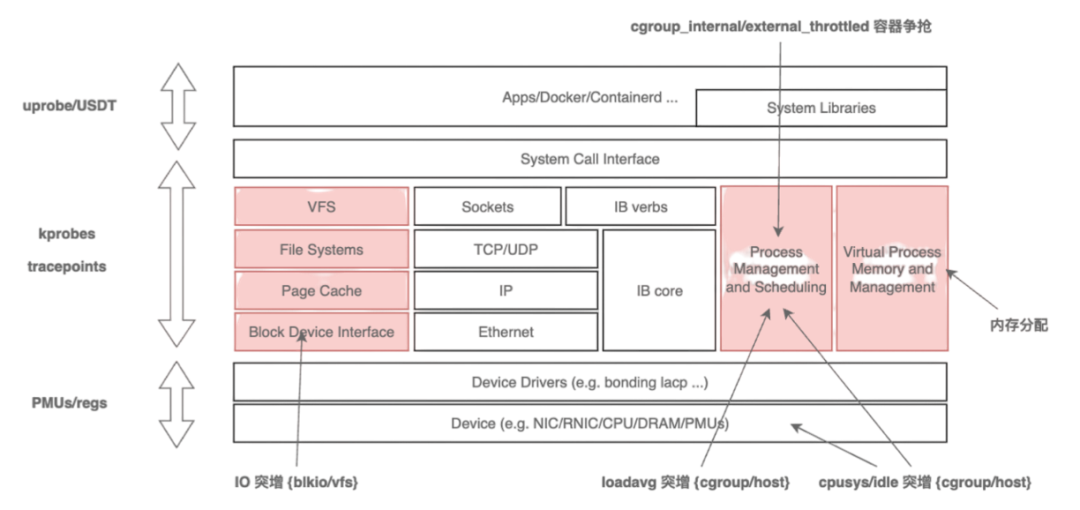
傳統的 procfs 指標粒度較粗,難以回答“是誰、在哪、為何發生”等關鍵問題。HUATUO針對這一痛點,深入內核各子系統的工作機制,在慢路徑和異常路徑進行精細化埋點,捕獲關鍵上下文信息,并基于 BPF 技術實現無侵入、低開銷的動態觀測。同時,為應對高頻異常可能帶來的性能沖擊,HUATUO設計了“限速”機制,實現指標采集的動態降級控制。
在系統架構上,項目注重擴展性:內核側通過 BPF 減少版本依賴,實現可編程觀測;應用側則提供統一框架,支持 metric、event、tracing、profiling等能力的靈活擴展。通過構建內核與 K8s容器間的高效數據映射機制,HUATUO 最終實現了在性能損耗低于 1% 的基礎上,對內存、CPU、網絡、IO 等核心子系統的全景、細粒度觀測能力。下圖是對各子系統的觀測點和前端效果圖。
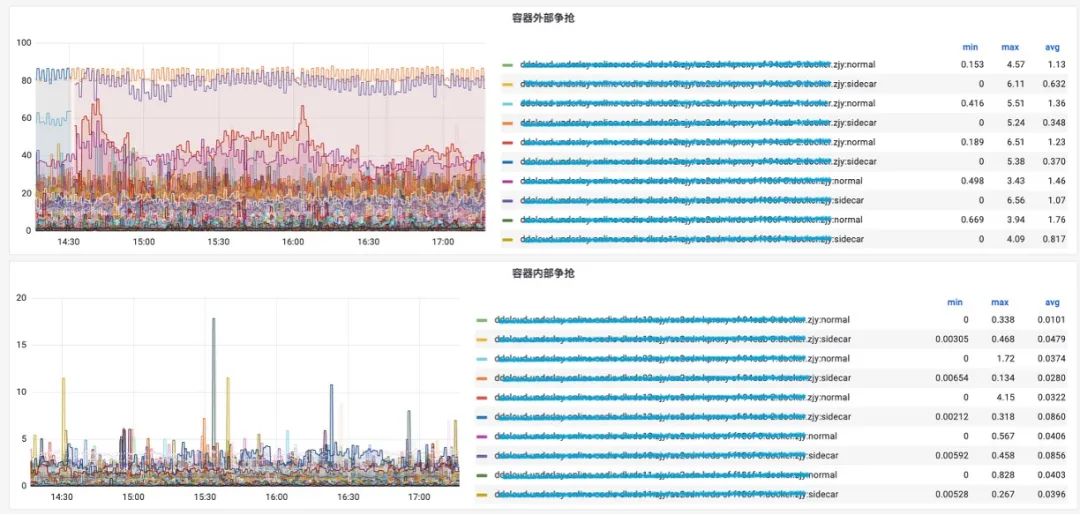
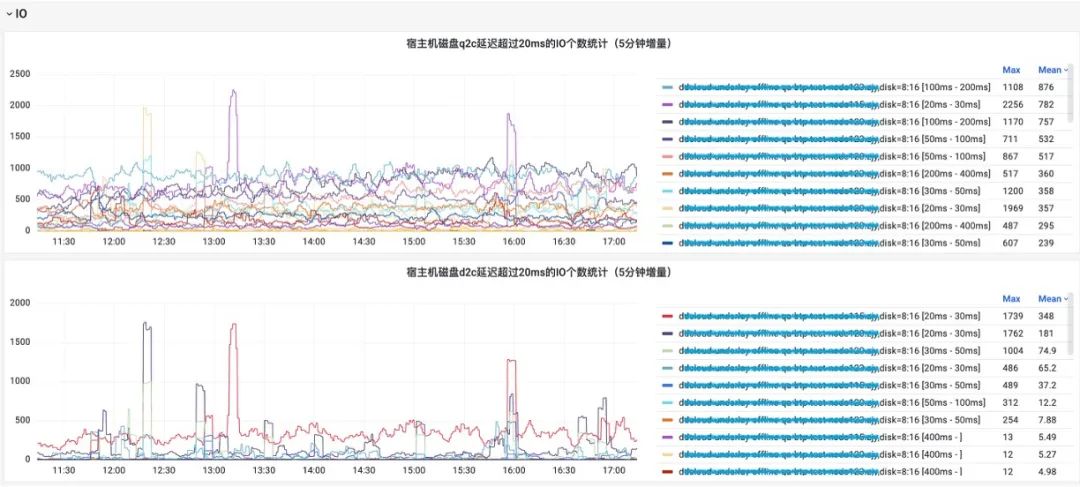
異常事件驅動診斷?
指標是一種整體持續的對系統狀態的表達和描述,而事件是對指標的一種增強,能夠捕獲更嚴重的系統問題,更多的觀測數據。異常事件驅動的診斷不需要事無巨細的獲取系統狀態,只需要根據設定的閾值觸發即可。這種方式相比指標對系統的性能損耗更小,獲取的信息更多,但閾值需要打磨,或者根據用戶的需求選擇。那么我們關注哪些內核事件呢?
從實踐經驗來看,需要圍繞內核的進程上下文,中斷上下文展開,需要關注阻塞和延遲事件,例如網絡事件、調度事件、IO事件、內存事件等等。最終 HUATUO構建基于異常事件驅動的運行時上下文捕獲機制,聚焦內核異常與慢速路徑的精準埋點。當發生缺頁異常、調度延遲、鎖競爭等關鍵事件時,自動觸發追蹤,生成包含寄存器狀態、堆棧軌跡及資源占用的圖譜診斷信息。
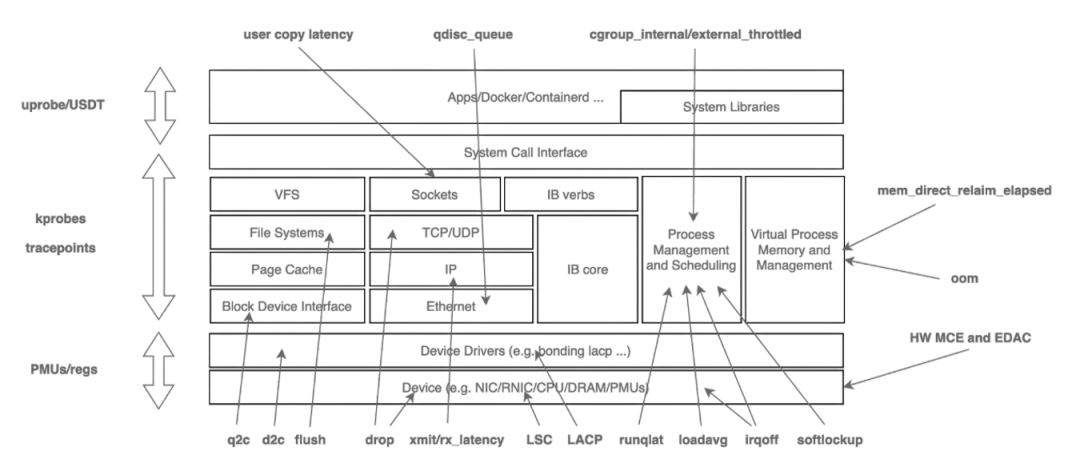

全自動化追蹤 AutoTracing?
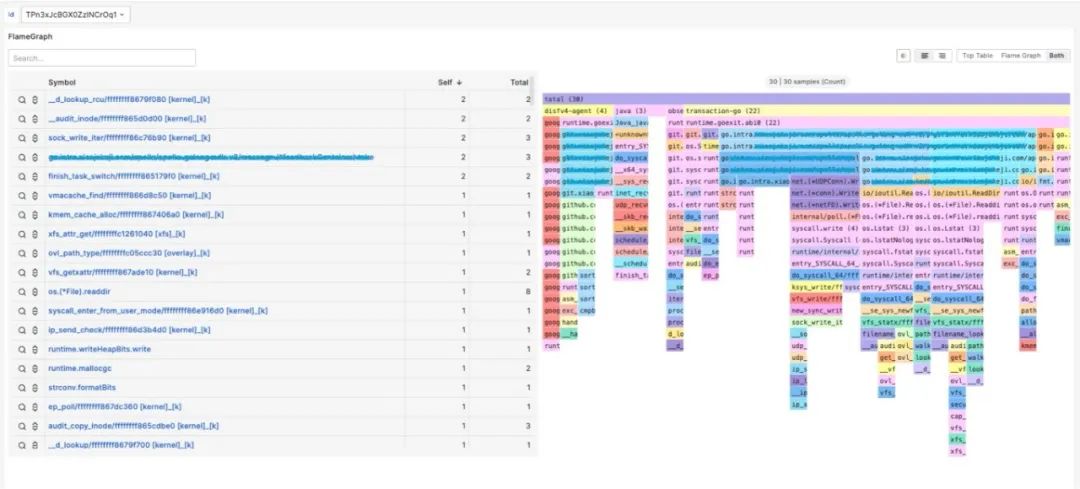
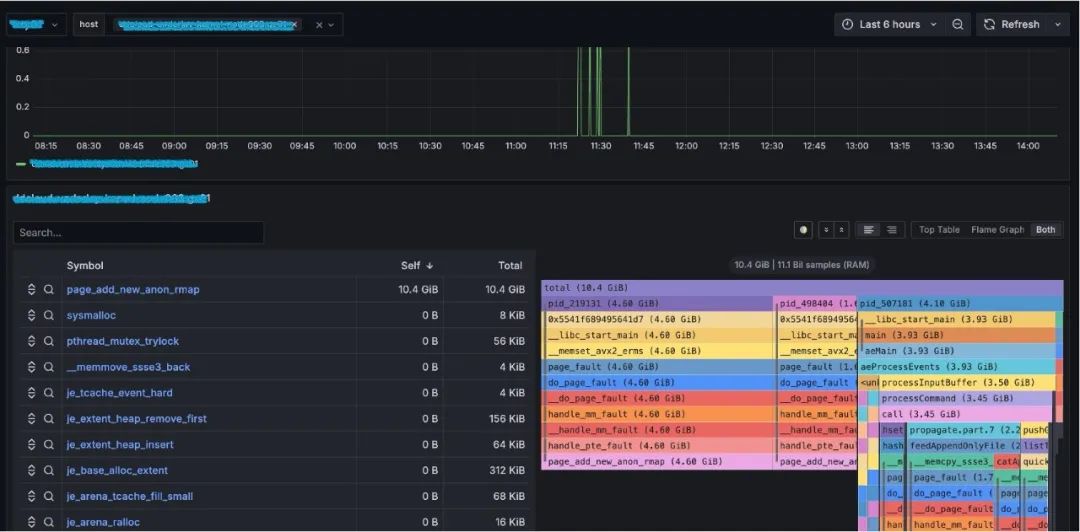
相比指標和事件,全自動化追蹤是為了解決更高維度的系統,業務應用的指標突增,偶發延遲等問題設計的。該方式適合解決如 cpusys、cpuidle、IO、Loadavg、容器爭搶等問題。那么如何組織觀測數據?調用棧,火焰圖?通過實踐經驗發現,火焰圖能夠很好的表達、展示這些突增時采集到的數據。
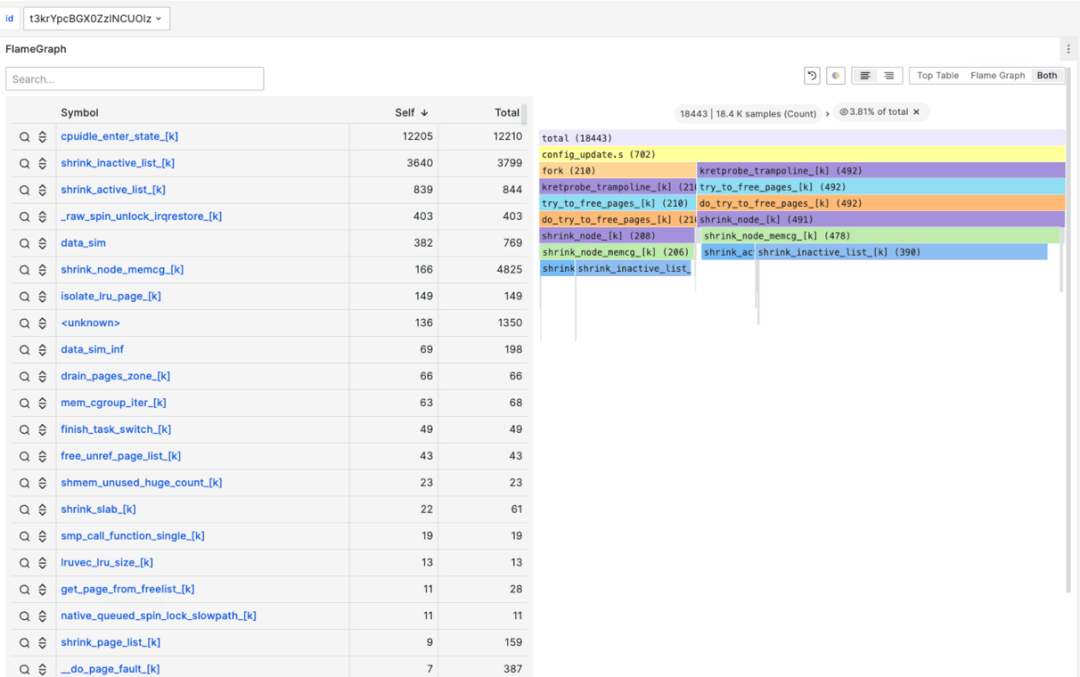
火焰圖能夠表達非常豐富的信息,不局限于CPU、在內存、鎖、loadavg等場景依然非常占據優勢,且診斷結果簡單易懂。這種全自動化的、按需的追蹤也是對性能損耗和獲取觀測數據的有效平衡。最終總結為,AutoTracing模塊采用啟發式追蹤算法,解決云原生復雜場景下的典型性能毛刺故障。針對CPU idle 掉底、CPU sys 突增、IO 突增、loadavg 突增等棘手問題,實現自動化快照留存機制和根因分析。下圖是華佗通過自動化追蹤方式觀測的內核子系統。
如下圖分別為cpuidle、cpusys自動化捕獲,自動生產成火焰圖。
持續性能剖析
操作系統觀測體系已經很豐富了,為什么需要持續性能剖析?持續性能剖析在應用性能分析,故障排查,放火演練,鏈路壓測等場景占據重要位置。這些場景需要一種持續的、可回溯的、全景的、全語言的性能剖析能力。那么剖析哪些資源?
實踐中,不局限于CPU、內存分布、內存分配、鎖競爭等同樣重要。觀測這些對象的維度又是非常豐富的,例如多語言、線程、進程、線程組、進程組、容器、CPU、內核子系統等等。最終HUATUO(華佗),通過標準化底層語言框架,提供統一的語言無關的存儲結構。通過零侵擾,低損耗的方式實現持續對操作系統內核,應用程序進行全方位性能剖析,涉及系統 CPU、內存、I/O、 鎖、以及各種解釋性編程語言,助力業務持續的優化迭代更新。下圖為持續性能剖析的軟件架構和以redis為例的內存剖析。
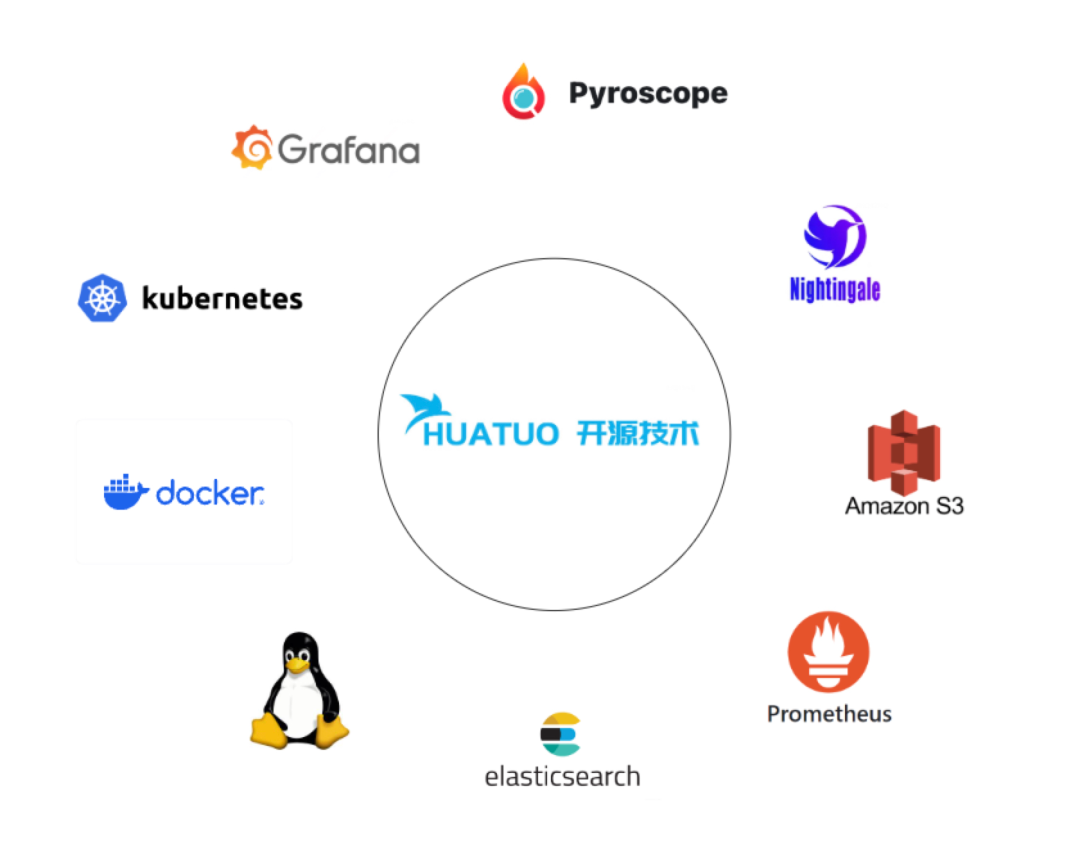
開源生態融合?
無縫對接主流開源可觀測技術棧,如Prometheus、Grafana、Pyroscope、Elasticsearch等。支持獨立物理機和云原生部署,自動感知K8S容器資源/標簽/注解,自動關聯操作系統內核事件指標,消除數據孤島。通過零侵擾、內核可編程方式兼容主流硬件平臺和操作系統發行版。
落地場景
該項目在各種場景都有應用落地,成為支撐滴滴網約車核心業務運行的重要技術保障之一。
鏈路壓測:重要節假日前,各業務線都會進行穩定性鏈路壓測,HUATUO 為這種場景提供系統故障診斷分析,持續性能剖析。
放火演練:業務應用放火不符合預期,則可以通過HUATUO查看底層系統運行狀態。
假期護堤:節假日期間,訪問流量非常高,業務應用可能出現延遲、抖動、I/O 突增和CPU掉地等問題。HUATUO則會自動捕獲這些事件。
性能剖析:業務應用在不同的集群表現有差異,則可以通過HUATUO分別對不同集群應用執行性能剖析,差異化分析。
預發灰度:HUATUO主動發現了很多問題,例如應用程序進程突增、cordump、loadavg 突增、網絡丟包等。
日常排障:系統軟件團隊負責集團業務集群底層基礎設施的穩定性,日常會有很多故障排查,問題解答等工作。HUATUO落地后在很大程度上釋放了團隊人力。
未來,滴滴將與中國計算機學會(CCF)一起加速 HUATUO 項目快速迭代,聚焦操作系統底層的性能剖析與分布式鏈路追蹤,基于實現自動感知、Tracing、Profiling等關鍵技術,實現零侵擾、可編程的內核監測,為各行業提供一個一站式系統化的系統故障分析解決方案。此外,在產學研合作生態支持下,不斷提升技術影響力,助力打造具備全球競爭力的國產開源基礎設施。
感謝大家閱讀至此,讓我們開源社區見!
https://github.com/ccfos/huatuo

|SVM-軟邊界理解)





![[windows]torchsig 1.1.0 gr-spectrumdetect模塊安裝](http://pic.xiahunao.cn/[windows]torchsig 1.1.0 gr-spectrumdetect模塊安裝)







)


)

