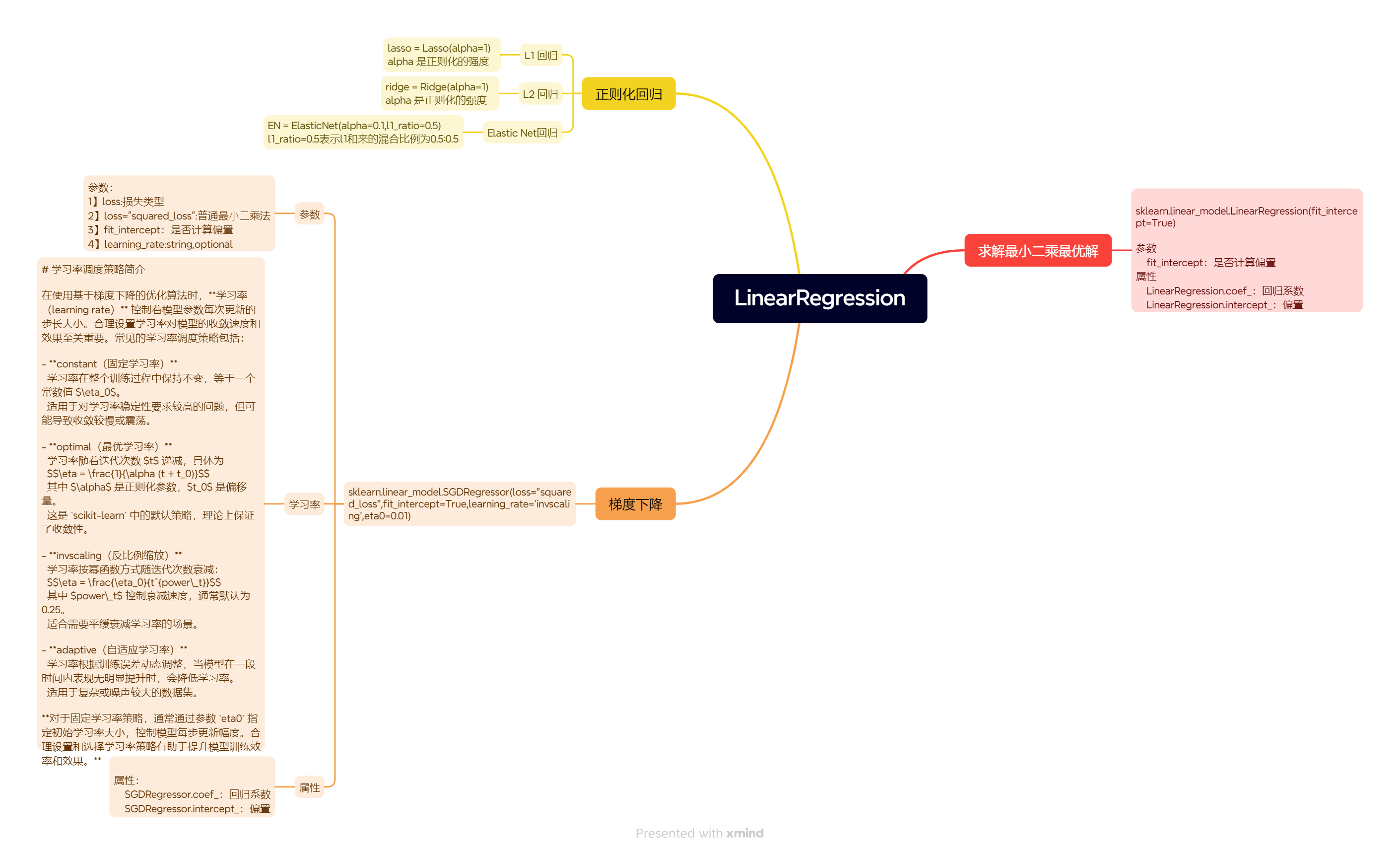
1、 關鍵數學知識點:
邊緣概率密度 = 聯合密度對非關注變量積分:fX(x)=∫fX,Y(x,y)dyf_X(x)=∫f_{X,Y}(x,y)dyfX?(x)=∫fX,Y?(x,y)dy;
條件概率密度 = 切片 fX∣Y(x∣y)=fX,Y(x,y)/fY(y)f_{X|Y}(x|y)=f_{X,Y}(x,y)/f_Y(y)fX∣Y?(x∣y)=fX,Y?(x,y)/fY?(y)。
概率密度函數和似然函數的區別:概率密度函數回答:“給定參數,數據出現的可能性有多大?”似然函數回答:“給定觀測到的數據,哪些參數值更合理?”
2、 線性回歸需要滿足的假設:
1 殘差獨立同分布:獨立同分布下邊緣概率密度的乘積=聯合概率密度,用于模型求似然函數
2 殘差正態性:模型的根本假設,模型的邊緣概率密度由正態函數求得,這個正態函數來源于殘差
3、 目標函數的推導過程:
1. 建模假設
y(i)=θ?x(i)+ε(i)y (i) =θ ? x (i) +ε (i)y(i)=θ?x(i)+ε(i),
ε(i)~i.i.d.N(0,σ2)ε (i) ~i.i.d. N(0,σ 2 )ε(i)~i.i.d.N(0,σ2)
p(ε)=12π?σexp?(?ε22σ2)p(\varepsilon)=\frac{1}{\sqrt{2\pi}\,\sigma}\exp\left(-\frac{\varepsilon^{2}}{2\sigma^{2}}\right)p(ε)=2π?σ1?exp(?2σ2ε2?)
2. 單個樣本的概率密度(也就是邊緣概率密度,借由ε\varepsilonε的分布計算而來):
(只需要將ε\varepsilonε代入, ε(i)=yi?θ?xi\varepsilon^{(i)} = y^{i} - \theta^{\top} x^{i}ε(i)=yi?θ?xi 且ε\varepsilonε的概率密度函數和y(i)y^{(i)}y(i)的概率密度函數實際上是相等的,ε\varepsilonε只是yiy^{i}yi平移了y(i)?θ?x(i)y^{(i)} - \theta^{\top} x^{(i)}y(i)?θ?x(i),對于概率密度函數,只要形狀不變,坐標軸變了也是相等的)
p(y(i)∣x(i);θ)=12πσexp???(?(y(i)?θ?x(i))22σ2)p\bigl(y^{(i)}\mid x^{(i)};\theta\bigr)= \frac{1}{\sqrt{2\pi}\sigma}\exp\!\left(-\frac{(y^{(i)}-\theta^\top x^{(i)})^2}{2\sigma^2}\right)p(y(i)∣x(i);θ)=2π?σ1?exp(?2σ2(y(i)?θ?x(i))2?)
p(y(i)∣x(i);θ)p\bigl(y^{(i)}\mid x^{(i)};\theta\bigr)p(y(i)∣x(i);θ) 可理解為:在給定輸入 x??? 并且模型參數取 θ 的條件下,觀測到 y??? 的概率密度是多少?
3. 寫出整個數據集的似然函數(即把觀測值y固定、把參數θ當作變量的聯合概率密度函數,稱之為似然函數,由邊緣概率密度的乘積計算得來)
(邊緣概率密度的乘積=聯合概率密度,也就是似然函數,這是獨立同分布的數學定理)
L(θ)=∏i=1mp(y(i)∣x(i);θ)=∏i=1m12πσexp???(?(y(i)?θ?x(i))22σ2)=(2πσ2)?m2exp???(?12σ2∑i=1m(y(i)?θ?x(i))2).\begin{aligned}
L(\theta)
&= \prod_{i=1}^{m} p\bigl(y^{(i)}\mid x^{(i)};\theta\bigr) \\
&= \prod_{i=1}^{m} \frac{1}{\sqrt{2\pi}\sigma}\exp\!\left(-\frac{(y^{(i)}-\theta^\top x^{(i)})^2}{2\sigma^2}\right) \\
&= (2\pi\sigma^2)^{-\frac{m}{2}}\exp\!\left(-\frac{1}{2\sigma^2}\sum_{i=1}^{m}(y^{(i)}-\theta^\top x^{(i)})^2\right).
\end{aligned}L(θ)?=i=1∏m?p(y(i)∣x(i);θ)=i=1∏m?2π?σ1?exp(?2σ2(y(i)?θ?x(i))2?)=(2πσ2)?2m?exp(?2σ21?i=1∑m?(y(i)?θ?x(i))2).?
4. 取對數得到對數似然
?(θ)=log?L(θ)=?m2log?(2πσ2)?12σ2∑i=1m(y(i)?θ?x(i))2.\ell(\theta)=\log L(\theta) = -\frac{m}{2}\log(2\pi\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^{m}(y^{(i)}-\theta^\top x^{(i)})^2.?(θ)=logL(θ)=?2m?log(2πσ2)?2σ21?∑i=1m?(y(i)?θ?x(i))2.
5. 最大化對數似然 ? 最小化殘差平方和
( 在誤差服從高斯分布的假設下,極大似然估計與最小二乘估計恰好得到同一解)
θ^MLE=arg?max?θ?(θ)=arg?min?θ∑i=1m(y(i)?θ?x(i))2.\hat\theta_{\text{MLE}}
= \arg\max_{\theta}\ell(\theta)
= \arg\min_{\theta}\sum_{i=1}^{m}(y^{(i)}-\theta^\top x^{(i)})^2.θ^MLE?=argmaxθ??(θ)=argminθ?∑i=1m?(y(i)?θ?x(i))2.
(arg?max?\arg\maxargmax找出讓某個函數達到最大值的輸入值(θ\thetaθ),而不是最大值本身)
6. 結論(對目標函數求極值)
根據最大似然估計的一階最優條件U(θ)=?θ?(θ)=0U(\theta) = \nabla_{\theta} \ell(\theta) = 0U(θ)=?θ??(θ)=0對對數似然函數求導并令其為零(求極值),可以推導出以下正規方程:
θ^MLE=(X?X)?1X?y,
\hat\theta_{\text{MLE}} = (X^\top X)^{-1}X^\top y,
θ^MLE?=(X?X)?1X?y,
其中
X=[x(1)??x(m)?]∈Rm×n,y=[y(1)?y(m)]∈Rm×1.
X=\begin{bmatrix}
x^{(1)\top}\\ \vdots\\ x^{(m)\top}
\end{bmatrix}\in\mathbb R^{m\times n},\qquad
y=\begin{bmatrix}
y^{(1)}\\ \vdots\\ y^{(m)}
\end{bmatrix}\in\mathbb R^{m\times 1}.
X=?x(1)??x(m)???∈Rm×n,y=?y(1)?y(m)??∈Rm×1.
求解正規方程時X要加上一列x0,x0列全為1即可
在高斯噪聲假設下,線性回歸的最大似然估計等價于最小二乘估計
7. 最后對U(θ)U(\theta)U(θ)再次求導可以進一步求檢驗統計量
#%% md
4、解釋為什么有些時候為什么必須要滿足線性回歸假設,即使明明可以用OLS,而OLS不需要這些假設
1、為了使得OLS和MLE相同,因為MLE有無法替代的優勢:
(1)一致性(樣本越大,估計越接近真值);
(2)漸近有效性(樣本足夠大時,它的方差是所有估計里最小的);
(3)可推導分布(可以算出估計量的分布,從而做假設檢驗)。
2、 讓 t/F 檢驗的 p 值和置信區間在小樣本下完全準確
3、在滿足 高斯馬爾可夫定理 條件(零均值、同方差、無自相關)的線性回歸模型里,OLS 是所有線性無偏估計中(在給定解釋變量條件下)方差最小的那一個,即 BLUE(Best Linear Unbiased Estimator)。如果 GM 條件不滿足,OLS 仍是無偏且線性的,但 不再保證方差最小;這時可能有其他線性無偏估計(例如 GLS)方差更小。
結論 :對于純粹的預測,不一定需要滿足條件,因為不需要假設檢驗自然也不不需要MLE的性質,只要結果好就行
5梯度下降(SGD)
數學推導過程
-
假設模型:
y^=w?x+b \hat{y} = w \cdot x + b y^?=w?x+b -
定義損失函數:(這一步是和正規方程方法一樣的)
L=12m∑i=1m(w?xi+b?yi)2 L = \frac{1}{2m} \sum_{i=1}^{m} \left( w \cdot x_i + b - y_i \right)^2 L=2m1?i=1∑m?(w?xi?+b?yi?)2 -
對 www 求偏導:
?L?w=1m∑i=1m(w?xi+b?yi)?xi \frac{\partial L}{\partial w} = \frac{1}{m} \sum_{i=1}^{m} \left( w \cdot x_i + b - y_i \right) \cdot x_i ?w?L?=m1?i=1∑m?(w?xi?+b?yi?)?xi? -
對 bbb 求偏導:
?L?b=1m∑i=1m(w?xi+b?yi) \frac{\partial L}{\partial b} = \frac{1}{m} \sum_{i=1}^{m} \left( w \cdot x_i + b - y_i \right) ?b?L?=m1?i=1∑m?(w?xi?+b?yi?)
梯度下降更新規則:
-
w=w?α?(1m∑(y^?y)?x) w = w - \alpha \cdot \left( \frac{1}{m} \sum ( \hat{y} - y ) \cdot x \right) w=w?α?(m1?∑(y^??y)?x)
-
b=b?α?(1m∑(y^?y)) b = b - \alpha \cdot \left( \frac{1}{m} \sum ( \hat{y} - y ) \right) b=b?α?(m1?∑(y^??y))
其中 α\alphaα 是學習率,mmm 是樣本數量。
梯度下降和正規方程區別:
正規方程是根據損失函數,設損失函數的所有參數的偏導(直接求導)的結果為0,通過矩陣運算一次性推出損失函數的最優參數
梯度下降是對損失函數各個參數求偏導,并不需要將偏導設為0求最優參數,而是只求偏導的結果(梯度),然后根據學習率沿著梯度的方向走,并逐步迭代

)

















