摘要
本文章旨在系統性地探討一個前沿的交叉學科研究課題:如何通過深層語義分析,探索并建模人類認知中普遍存在的底層邏輯一致性。此研究橫跨自然語言處理(NLP)、知識圖譜(KG)、認知科學、腦神經科學、系統科學(信息論)、哲學、符號學、邏輯學、中國傳統語言文字學及認知語義學等多個領域。報告將提出一個整合性的理論框架、具體的研究方法、可行的實施步驟以及前瞻性的學術觀點,旨在為構建更接近人類智能、具備可解釋性和魯棒性的新一代人工智能系統提供理論基礎和技術路徑。
1. 引言:研究的宏大背景與核心問題
當前,以大型語言模型(LLM)為代表的人工智能技術在自然語言處理任務上取得了革命性進展?。然而,這些模型在事實一致性、可解釋性和深層邏輯推理方面仍面臨嚴峻挑戰,例如“幻覺”(hallucination)現象頻發,即生成看似合理但與事實相悖的內容?。這暴露了一個根本性問題:現有模型主要依賴于海量數據的統計關聯,而未能真正捕捉和理解人類語言與思維背后所蘊含的深層語義結構與邏輯規律。
本研究的核心問題是:我們能否通過整合多學科的理論與方法,構建一個能夠模擬、解釋并驗證人類底層邏輯一致性的計算框架?
我們提出的核心假設是:人類的邏輯一致性并非等同于數理邏輯中的形式化、剛性體系,而是一種在認知層面更具柔韌性與適應性的“認知似然一致性”(Cognitively Plausible Consistency)。它是在符號知識、具身認知、神經活動與文化-語言演化之間復雜互動中涌現出的特性。因此,要探索這一規律,必須打破學科壁壘,進行深度融合。本報告將從理論框架、研究方法、實施步驟和評估體系四個方面,闡述如何實現這一宏偉目標。
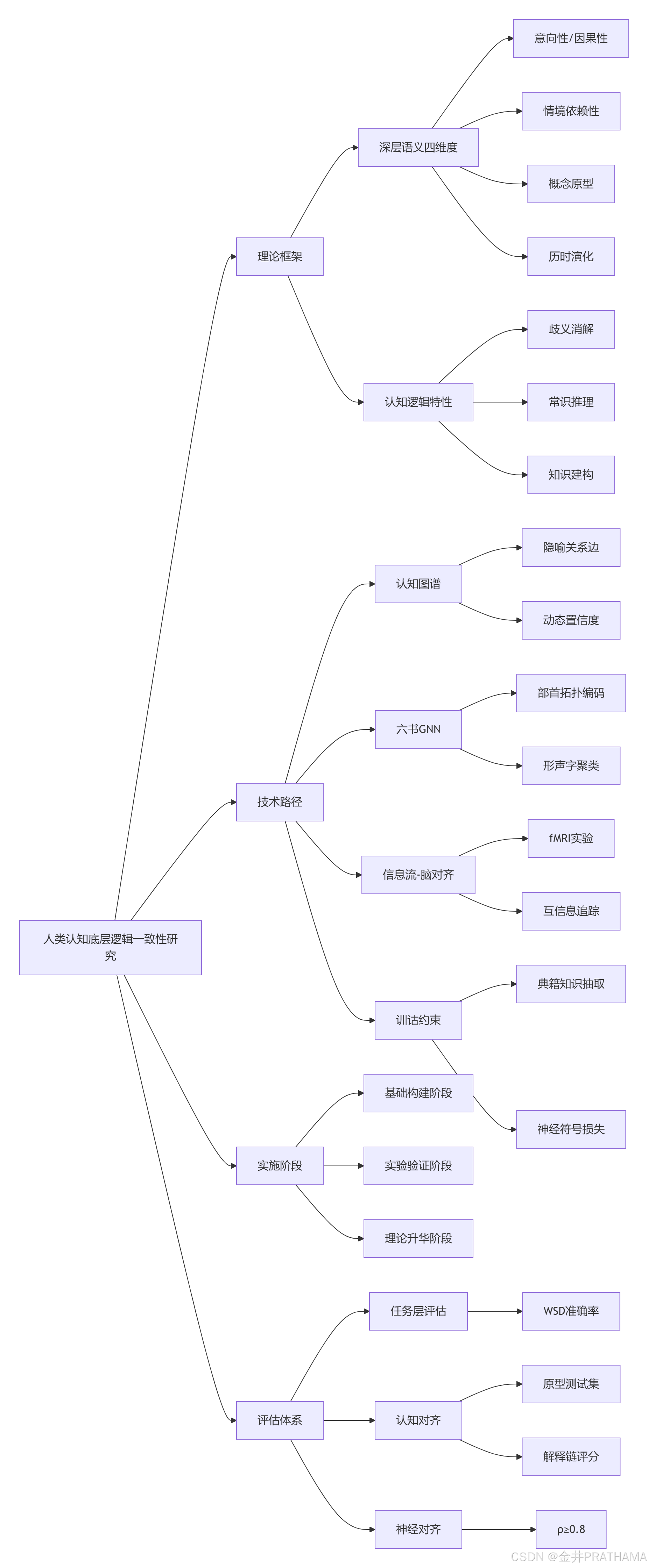
2. 核心理念與理論框架(我們的看法)
要探索人類的底層邏輯,我們首先需要構建一個能夠承載這一探索的理論框架。
2.1. “深層語義”的再定義
我們主張,研究必須超越詞向量或句子嵌入所代表的分布語義。深層語義應至少包含以下維度:
- 意向性與因果性:?理解語言背后的意圖、信念以及事件間的因果關聯。
- 情境依賴性:?語義在不同物理、社會、文化情境下的動態變化和消歧。
- 概念結構與原型理論:?知識并非扁平化的事實羅列,而是圍繞原型組織的、具有層次和家族相似性特征的概念網絡,這與認知語義學的觀點一致。
- 歷時演化性:?語言和概念的意義是隨時間演變的。中國傳統訓詁學等學科為我們提供了觀察這種演化的獨特窗口。
2.2. “邏輯一致性”的認知詮釋
我們挑戰將人類邏輯等同于經典一階邏輯的觀點。人類思維充滿了模糊、類比、隱喻和直覺,但在宏觀上表現出高度的一致性和可預測性。這種一致性體現在:
- 歧義消解:?人類能高效利用語境信息解決詞義和結構歧義?。
- 常識推理:?在不完備信息下做出合理的推斷。
- 知識建構:?系統地組織和更新世界知識。
因此,我們的目標是建模這種認知層面的、動態的、與情境高度相關的邏輯一致性。
2.3. 跨學科整合的必然性
單一學科無法獨立解決此問題,各學科的角色如下:
- NLP與知識圖譜:?提供核心的計算工具與結構化知識的表示方法。知識圖譜被視為增強LLM事實性的關鍵資源?。
- 認知與腦神經科學:?為計算模型提供來自人類的“地面真實”(ground truth)。腦成像技術(如fMRI)可以揭示語義處理和歧義解決的神經基礎?為模型驗證提供生物學證據。
- 系統科學與信息論:?提供數學語言來量化和分析復雜系統中的信息流動。例如,互信息(Mutual Information)可用于分析NLP模型內部的信息傳遞?以及與大腦活動模式的關聯?。
- 哲學、邏輯學、符號學:?提供關于意義、真理、推理和符號表征的元理論指導。
- 中國傳統語言文字學:?以漢字“六書”和訓詁學為例,提供了一個獨特的、非拼音文字系統的視角,揭示了符號(字形)與意義(字義)之間深刻的、歷時性的關聯,是檢驗深層語義模型的絕佳案例?。
3. 研究方法與技術路徑(我們的建議和方法)
基于上述理論框架,我們提出以下四條具體且相互關聯的技術路徑。
3.1. 構建認知增強的知識圖譜(Cognitive-Enhanced Knowledge Graphs)
當前研究多集中于利用事實性知識圖譜增強LLM?。我們需要超越這一范疇,構建更符合人類認知結構的“認知圖譜”。
- 方法:
- 擴展節點與邊的內涵:?除了傳統的(實體,關系,實體)三元組,引入認知語義學概念。例如,邊的類型可以區分為“因果關系”、“原型隸屬關系”、“隱喻映射關系”等。
- 編碼情境與不確定性:?為知識三元組附加情境標簽(如時間、地點、文化背景)和置信度分數,以處理語義的動態性和知識的模糊性。
- 融合多模態信息:?將視覺、聽覺等非文本信息融入圖譜,以反映人類具身認知的特點。
- 意義:?這種認知圖譜將作為模型推理的“腳手架”,使其不僅能“知其然”(事實),更能“知其所以然”(背后的認知結構與邏輯)。這為解決LLM的泛化和常識推理問題提供了新的途徑?。
3.2. 漢字“六書”原理的圖神經網絡拓撲編碼
漢字是形、音、義的結合體,“六書”理論深刻揭示了其內部的構造邏輯?。將其計算化,是探索符號與語義深層關系的關鍵一步。
- 方法:
- 符號解構與圖譜構建:?基于“六書”原理(象形、指事、會意、形聲等),將漢字解構為獨立的表意或表音部件(如部首、聲旁)。將每個漢字表示為一個圖,其中節點是部件,邊代表它們的空間結構關系(上/下、左/右)和功能關系(形旁/聲旁)。
- GNN拓撲特征學習:?應用圖神經網絡(GNN)技術學習這些“漢字圖”的向量表示。GNN的結構善于捕捉拓撲信息?能夠將“六書”所蘊含的構造規則編碼到低維向量空間中。
- 向量空間可視化與驗證:?使用t-SNE等降維技術將漢字向量可視化?。我們預期,具有相同造字邏輯(如均為形聲字)或相同部首的漢字將在向量空間中聚集,從而驗證編碼的有效性。
- 意義:?此方法將古老的語言學理論轉化為可計算的神經特征,為模型提供了超越筆畫序列的、更深層次的漢字語義理解能力。雖然目前尚缺乏直接的開源實現 (Query: Open-source GNN code...), 但其技術路線是清晰的。
3.3. 基于信息論的“模型-大腦”語義流對齊分析
要驗證模型是否在模擬人類的邏輯過程,就需要比較其內部信息處理動態與大腦的神經活動。
- 方法:
- 設計受控的神經科學實驗:?設計fMRI實驗,讓被試閱讀精心控制的漢語歧義句和無歧義句。fMRI研究已證實,處理語義或句法歧義會引發特定腦區(如左額下回LIFG)更強的BOLD信號?。
- 量化模型內部的語義信息流:?在我們構建的認知增強LLM中,輸入同樣的歧義/無歧義句。使用信息論工具(如互信息)來追蹤和量化“消歧”相關信息在模型不同層級間的流動強度與路徑?。
- 進行相關性分析:?統計分析模型內部的信息流量化值與fMRI實驗中對應腦區BOLD信號的幅度變化之間的相關性。盡管目前缺乏直接報告互信息值與BOLD信號幅度的公開數據集 (Query: Public fMRI datasets...), 但設計此類實驗并進行分析是完全可行的。
- 意義:?若模型的信息處理模式與大腦活動模式呈現顯著正相關,將為“模型在模擬人類認知過程”這一論斷提供強有力的實證支持,實現從“行為模擬”到“過程模擬”的跨越。
3.4. 傳統訓詁學知識的神經可計算化
訓詁學蘊含了豐富的關于漢語詞義演變、語境依賴和深層關聯的知識。將其融入現代NLP模型是一個巨大挑戰,但也蘊含巨大機遇。
- 方法:
- 知識抽取與結構化:?從《說文解字》、《爾雅》等訓詁學典籍中,系統性地抽取出詞義解釋、同義/反義關系、通假關系、以及詞義在不同時代和文獻中的具體用法,并將其整合進3.1節提到的“認知圖譜”中。
- 設計語義約束的損失函數:?借鑒神經符號方法中的思想?設計一個“訓詁語義損失函數”。當模型生成對古文的解釋或在特定語境下進行詞義選擇時,如果其輸出與訓詁學提供的權威解釋相悖,則施加懲罰。
- 意義:?這相當于為模型聘請了一位“國學大師”作為指導,迫使模型的語義空間不僅要擬合現代語料的統計分布,還要與數千年來積淀的語言知識體系保持一致,從而獲得更深厚的歷史縱深和文化底蘊。
4. 實施步驟與評估體系(我們的步驟)
一個宏大的研究計劃需要分階段實施和評估。
4.1. 實施步驟
第一階段:基礎資源與模型構建(1-2年)
- 認知圖譜構建:?啟動中文認知圖譜項目,融合現有開放知識庫與結構化的傳統語言學知識。
- 漢字編碼模型開發:?實現基于“六書”的GNN漢字表示模型,并發布開源代碼和預訓練向量。
- 原型模型訓練:?在上述資源基礎上,訓練一個認知增強的中文LLM原型。
第二階段:計算建模與神經科學實驗(2-4年)
- 開展fMRI實驗:?與神經科學實驗室合作,完成針對中文歧義處理的fMRI數據采集。
- 數據分析與模型對齊:?分析fMRI數據,并進行模型信息流與大腦BOLD信號的相關性分析,迭代優化模型架構。
第三階段:綜合評估與理論升華(4-5年)
- 多維度評估:?使用下文定義的綜合評估體系,全面評測模型的性能。
- 理論構建:?在實驗和模型結果的基礎上,提煉出關于人類底層邏輯一致性的計算理論。
4.2. 綜合評估體系
評估模型的“深層語義理解能力”和“邏輯一致性”不能僅靠傳統的準確率指標。我們需要一個全新的、多維度的評估框架。
- 任務層評估(Task-based Evaluation):
- 在標準的中文詞義消歧(WSD)基準(如SemEval的部分中文任務)上進行測試?。
- 將模型性能與其它SOTA模型以及人類表現基準進行直接比較?。當前研究顯示,即使是頂級LLM,在許多任務上與人類仍有差距?。
- 認知對齊評估(Cognitive Alignment Evaluation):
- 概念結構探測:?設計新的測試集,專門評估模型對原型、隱喻、轉喻等認知語義現象的理解能力。
- 推理鏈可解釋性:?借鑒AlignBench??或KGLens??等框架的思想,要求模型在完成推理任務(如歧義消解)后,生成自然語言的“解釋”,由人類專家評估其解釋的認知合理性。
- 神經對齊評估(Neural Alignment Evaluation):
- 將模型信息流與大腦BOLD信號的相關系數本身作為一個核心評估指標。更高的相關性意味著模型在處理機制上更接近生物大腦。
5. 結論與展望(我們的看法和建議)
本報告描繪了一個宏大而長遠的研究藍圖。我們堅信,探索人類心智的奧秘、構建真正通用的人工智能,其路徑不在于單一學科的埋頭猛進,而在于跨學科的深度融合與協同創新。
我們提出的核心觀點是:?要理解并實現人類水平的邏輯一致性,必須從“數據驅動”和“知識驅動”走向“認知驅動”?。這意味著我們的AI模型不僅要學習海量文本,整合結構化知識,更要使其內部的表示和運算過程,與人類認知及大腦處理信息的底層機制相對齊。
這一研究方向的成功推進,將可能帶來:
- 更魯棒、可解釋的AI:?AI系統的決策過程將更符合人類的直覺和邏輯,減少不可預測的“幻覺”,增強人機協作的信任度?。
- 計算認知科學的突破:?建立一個連接語言學、心理學、腦科學和計算機科學的橋梁,形成一個可計算、可驗證的關于人類語言和思維的新理論?。
- “計算人文”新范式:?讓中國傳統語言文字學等古老的人文智慧,不再僅僅是數字化的館藏,而是成為啟發和構建下一代人工智能的鮮活源泉。
這項探索無疑是充滿挑戰的,它要求研究者具備跨領域的廣博知識和勇于探索未知的精神。然而,其潛在的回報也是巨大的——它不僅關乎技術上的下一次飛躍,更關乎我們對人類自身智能本質的深刻理解。



 Sentinel篇)



:點燈前的準備 —— 從軟件安裝到硬件原理)



與Grafana配置)




)


