?決策樹像人類的思考過程,用一系列“是/否”問題層層逼近答案
?
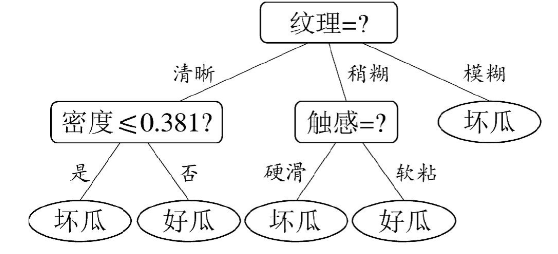
一、決策樹的核心本質
決策樹是一種模仿人類決策過程的樹形結構分類/回歸模型。它通過節點(問題)?? 和 ?邊(答案)?? 構建路徑,最終在葉節點(決策結果)?? 輸出預測值。這種白盒模型的優勢在于極高的可解釋性。
二、決策樹的核心構成
- ?根節點?:初始特征劃分點
- ?內部節點?:特征測試點(每個節點對應一個判斷條件)
- ?分支?:判斷條件的可能結果
- ?葉節點?:最終決策結果(分類/回歸值)
?關鍵概念?:
- ?純度(Purity)??:節點內樣本類別的統一程度(Gini指數/熵越小越純)
- ?信息增益(Information Gain)??:分裂后純度的提升量
- ?剪枝(Pruning)??:防止過擬合的關鍵技術(預剪枝/后剪枝)
三、決策樹的數學原理
決策樹通過遞歸分割尋找最優特征:
1、?選擇分裂特征?:
- ?ID3算法?:使用信息增益?(缺陷:偏好多值特征)
- ?C4.5算法?:改進為增益率?(消除特征取值數量的影響)
- ?CART算法?:使用Gini指數?(計算效率更高) ——Classification and Regression Tree(分類和回歸任務都可用)
?2、停止條件?:
- 節點樣本全屬同一類
- 特征已用完
- 樣本數低于閾值(超參數控制)
四、算法對比
ID3算法概括
ID3(Iterative Dichotomiser 3)算法的計算過程可概括為:?通過遞歸地選擇信息增益最大的特征進行節點分裂,最終構建決策樹。具體步驟為:
- 計算當前節點的信息熵
- 對每個特征計算分裂后的信息增益(原始熵 - 條件熵)
- 選擇增益最大的特征作為分裂節點
- 對子節點重復上述過程,直到滿足停止條件
算法名稱中的"ID3"來源于:
- ?Iterative?(迭代):通過循環過程構建樹
- ?Dichotomiser?(二分):早期版本僅處理二分類(雖然后續支持多分類)
- ?3?:代表第三代改進版本
其核心思想是用信息論量化特征重要性,每次分裂都選擇能最大程度降低系統不確定性的特征。
?ID3算法:信息增益(Information Gain)
信息增益是決策樹(ID3算法)選擇分裂特征的核心指標,它量化了使用某特征進行分割后,系統不確定性的減少程度。要徹底理解這個公式,我們需要分三步拆解:
1、信息熵(Entropy)
?信息熵表示系統的混亂程度,計算公式為:
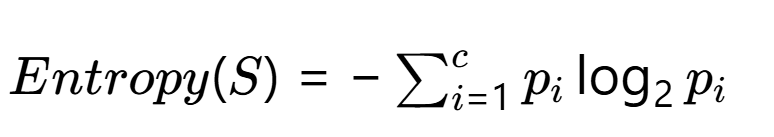
- S:當前節點的樣本集合
- c:類別總數(如二分類時c=2)
- pi?:樣本中第i類所占比例
?示例?:假設某節點有10個樣本,其中6個正例,4個負例:
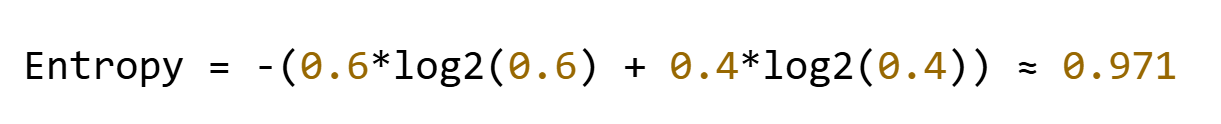
2、條件熵(Conditional Entropy)
當按某個特征A分裂后,需要計算加權平均熵?:
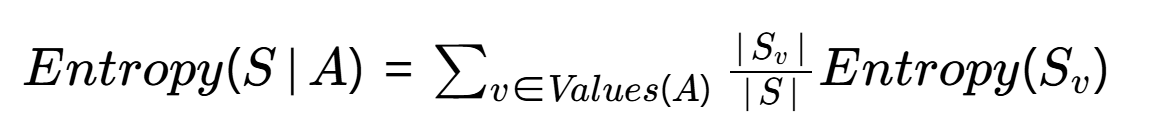
- Values(A):特征A的取值集合(如"年齡"特征可能取{青年,中年,老年})
- Sv?:A取值為v的子集樣本
?示例?:按特征"天氣"(取值為晴/雨/陰)分裂:
- 晴:3正2負 → Entropy=0.971
- 雨:1正4負 → Entropy=0.722
- 陰:4正1負 → Entropy=0.722
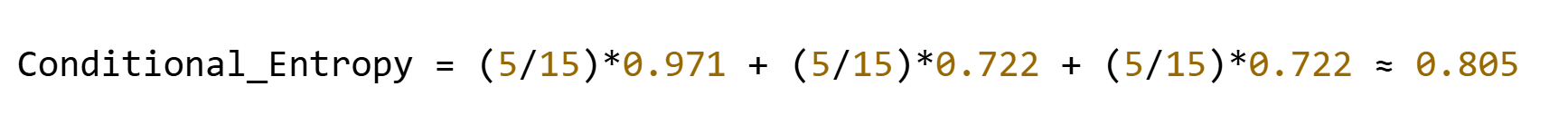
3、信息增益計算公式
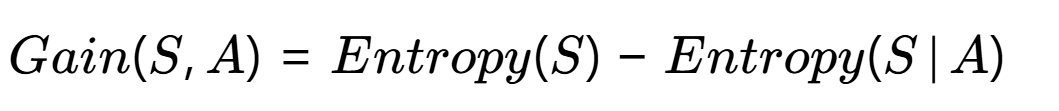
?物理意義?:原始系統的熵減去按特征A分裂后的條件熵
?接前例?:
若原數據集Entropy(S)=0.88,則:

4、計算實例演示
目標?:預測是否打球(二分類問題)
特征?:天氣、溫度、濕度、風力
4個樣本?:
| 天氣 | 溫度 | 濕度 | 風力 | 打球 |
|---|---|---|---|---|
| 晴 | 高 | 高 | 弱 | 否 |
| 晴 | 高 | 高 | 強 | 否 |
| 陰 | 高 | 高 | 弱 | 是 |
| 雨 | 中 | 高 | 弱 | 是 |
?步驟1?:計算原始熵
公式?:![]()
?計算過程?:
- 總樣本數:4個
- 正例("是"):2個 → p? = 2/4 = 0.5
- 反例("否"):2個 → p? = 2/4 = 0.5
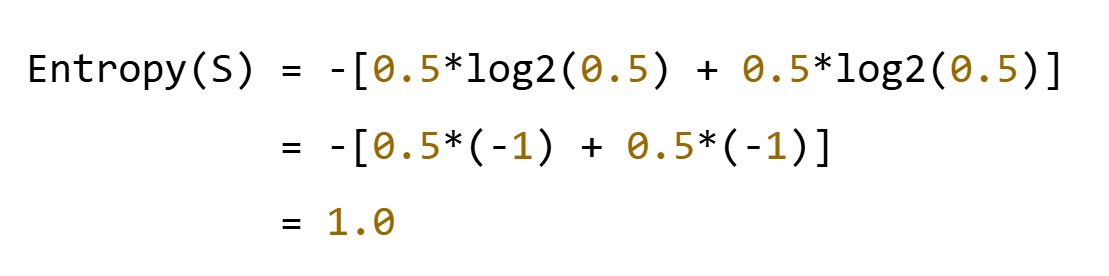
步驟2?:計算各特征的信息增益
1. 特征"天氣"(3個取值:晴/陰/雨)
?子集劃分?:
- 晴:2個(否, 否)→ Entropy = 0
- 陰:1個(是)→ Entropy = 0
- 雨:1個(是)→ Entropy = 0
?條件熵?:
![]()
?信息增益?:Gain(天氣)=1.0?0=1.0
2. 特征"溫度"(2個取值:高/中)
?子集劃分?:
- 高:3個(否, 否, 是)→ p(是)=1/3, p(否)=2/3
Entropy = -[1/3*log2(1/3) + 2/3*log2(2/3)] ≈ 0.918 - 中:1個(是)→ Entropy = 0
?條件熵?:
![]()
?信息增益?:Gain(溫度)=1.0?0.689=0.311
3. 特征"濕度"(僅1個取值:高)
?子集劃分?:
- 高:4個 → 與父節點相同
?信息增益?:Gain(濕度)=1.0?1.0=0
4. 特征"風力"(2個取值:弱/強)
?子集劃分?:
- 弱:3個(否, 是, 是)→ p(是)=2/3, p(否)=1/3
Entropy = -[2/3*log2(2/3) + 1/3*log2(1/3)] ≈ 0.918 - 強:1個(否)→ Entropy = 0
?條件熵?:
![]()
?信息增益?:Gain(風力)=1.0?0.689=0.311
?步驟3?:選擇根節點
各特征增益比較?:
- 天氣:1.0
- 溫度:0.311
- 濕度:0
- 風力:0.311
?選擇標準?:選擇信息增益最大的特征? ? →? ?決策?:選擇"天氣"作為根節點
步驟4:構建子樹
分裂結果?:
天氣
├─ 晴 → 全部為"否"(葉節點)
├─ 陰 → 全部為"是"(葉節點)
└─ 雨 → 全部為"是"(葉節點)停止條件?:
- 所有分支的葉節點純度已達100%
- 無需繼續分裂
最終決策樹
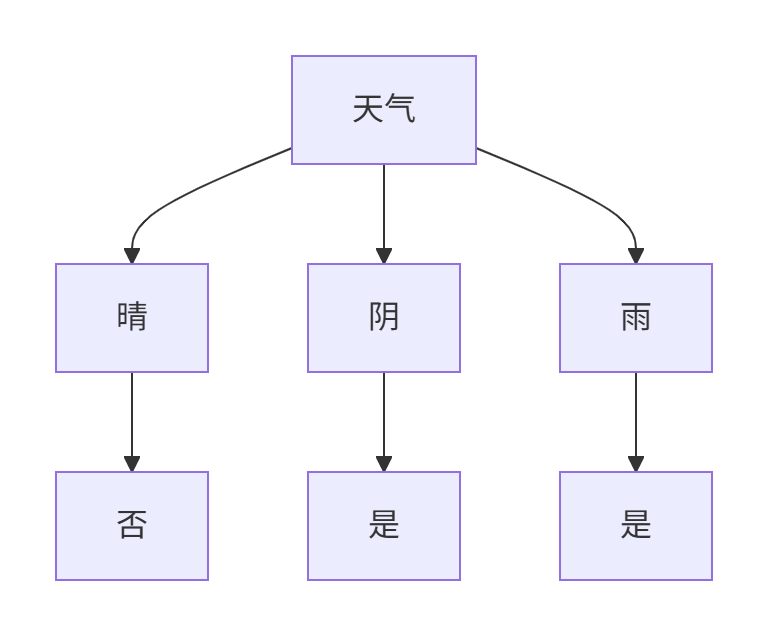
5、注意事項
?偏向性問題?:當特征取值較多時(如"ID"特征),信息增益會傾向于選擇該特征(導致過擬合),因此C4.5算法改用增益率。
?對數底選擇?:雖然理論上可使用任意底數,但機器學習中常用2為底(結果單位為bits)
?與Gini指數的關系?:兩者都衡量純度,但Gini指數計算更快(無對數運算):
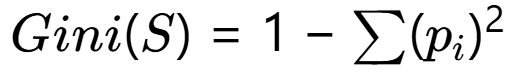
通過這種量化的方式,決策樹可以自動選擇最具區分力的特征進行分裂,這正是它模擬人類決策智能的核心所在。
C4.5算法:增益率(Gain Ratio)
??"信息增益率是給信息增益裝上剎車片,防止它沖向多值特征的懸崖"??
1、為什么要改進信息增益?
信息增益(ID3算法)存在嚴重偏差?:它會優先選擇取值數目多的特征(如"用戶ID"這種唯一值特征),但這會導致:
- ?無效分裂?:每個ID對應一個樣本,Gain達到最大值但毫無預測能力
- ?過擬合風險?:生成過于復雜的樹結構
?示例?:在員工離職預測中:
- 特征A(部門):5個取值 → Gain=0.3
- 特征B(員工ID):1000個唯一值 → Gain=1.0
ID3會錯誤地選擇B作為根節點
2、增益率的數學本質
C4.5算法用增益率(Gain Ratio)?? 修正這一問題,公式為:
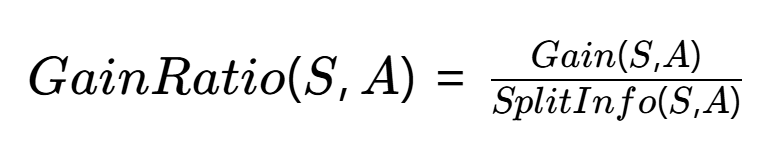
其中分裂信息(Split Information):
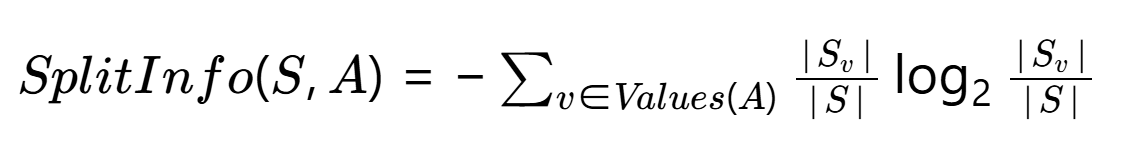
?關鍵點?:
- 分子:原始信息增益
- 分母:特征A本身的信息熵(懲罰多值特征)
- 當特征取值均勻分布時,SplitInfo達到最大值
想象你在水果攤挑西瓜,老板讓你用最少的提問找出最甜的瓜。增益率就是幫你衡量"每個提問的價值"的智能計算器。
1?? ?信息增益 = 提問帶來的信息量?
- 你問:"是紅瓤嗎?"(可能篩掉一半不甜的瓜)
- 信息增益就是這個問題幫你減少的不確定性
2?? ?分裂信息 = 問題本身的復雜程度?
- 如果問:"瓜的編號是多少?"(每個瓜編號唯一)
- 這個問題太"細致"了,雖然能精準找瓜,但沒實際意義
- 分裂信息就會很大,表示問題本身太復雜
3?? ?增益率 = 真正的有效信息量?
就像老板會提醒你:
- "問顏色"(增益率0.8)比"問編號"(增益率0.01)更劃算
- "問產地"(增益率0.3)不如"問敲聲"(增益率0.6)有效
增益率就是防止你被"假聰明問題"忽悠的計算器——有些問題看似能精確分類(比如問身份證號),實際上對挑西瓜毫無幫助。
3、計算實例分步演示
數據集:
| 天氣 | 風速 | 打球 |
|---|---|---|
| 晴 | 弱 | 否 |
| 晴 | 強 | 否 |
| 陰 | 弱 | 是 |
| 雨 | 強 | 是 |
| 雨 | 弱 | 是 |
| 雨 | 強 | 否 |
第一步:計算原始信息熵
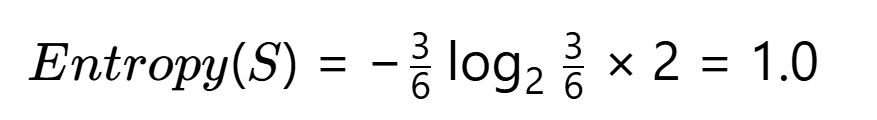
第二步:計算各特征信息增益
1. 特征"天氣"(3個取值)
?子集劃分?:
- 晴:2否 → Entropy=0
- 陰:1是 → Entropy=0
- 雨:2是1否 → Entropy=0.918
?條件熵?:![]()
?信息增益?:![]()
?分裂信息?:![]()
?增益率?:![]()
2. 特征"風速"(2個取值)
?子集劃分?:
- 弱:1否2是 → Entropy=0.918
- 強:2否1是 → Entropy=0.918
?條件熵?:![]()
?信息增益?:![]()
?分裂信息?:![]()
?增益率?:![]()
第三步:特征選擇對比
| 特征 | 信息增益 | 增益率 |
|---|---|---|
| 天氣 | 0.541 | 0.371 |
| 風速 | 0.082 | 0.082 |
?決策?:選擇增益率更高的"天氣"作為分裂節點
第四步:驗證多值特征懲罰
假設新增無關特征"日期"(5個唯一值):
?計算SplitInfo(日期)??:
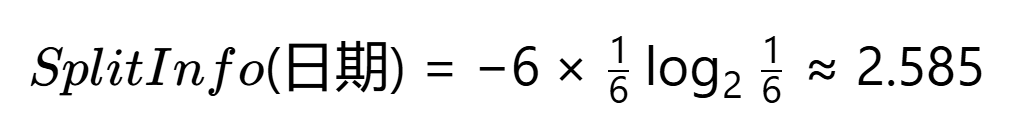
即使Gain(日期)=0.971(最大可能值):
![]()
實際選擇?:雖然"日期"增益率(0.387) > "天氣"(0.371),但:
- 業務上排除無意義特征
- 可設置增益率閾值(如>0.4)過濾偽特征
關鍵結論
- ?增益率機制?:有效壓制了"風速"等弱特征和"日期"等偽特征
- ?計算本質?:用特征自身熵對信息增益進行標準化
- ?業務價值?:選擇天氣(晴/陰/雨)作為首分裂特征,符合"惡劣天氣不打球"的常識
4、C4.5的完整改進措施
(1)?處理連續特征(解決數值型數據問題)?
核心思想?:將"年齡"這類連續數字變成可分類的閾值點
?具體操作?:
- 排序所有取值(如年齡[22, 25, 30])
- 計算相鄰值中點(→23.5, 27.5)
- 將這些中點作為候選分割閾值
?示例?:用年齡預測是否購買保險:
- 測試條件1:年齡≤23.5?
- 測試條件2:年齡≤27.5?
- 選擇信息增益率最高的分割點
?業務意義?:自動找到關鍵年齡分界點(如27.5歲可能是消費習慣轉變的臨界值)
(2)?處理缺失值?(解決數據不完整問題)
核心思想?:按已知數據的比例"分配"缺失樣本
?具體操作?:
- 計算已知數據的類別分布(如A類60%,B類40%)
- 將缺失樣本按此比例分配到各分支
?示例?:
10個客戶數據預測:
- 8個已知數據:5個A類(62.5%),3個B類(37.5%)
- 2個缺失數據:
- 1.25個(≈1個)分到A類分支
- 0.75個(≈1個)分到B類分支
(3)?后剪枝(解決過擬合問題)?
核心思想?:先長完整棵樹,再修剪掉不可靠分支
?具體操作?:
- 用訓練集生成完整決策樹
- 用驗證集測試每個子樹:
- 如果替換為葉節點能提升驗證集準確率
- 則剪掉該子樹
?示例?:某子樹規則
溫度>30? ├─ 是 → 濕度<50%? → 分類A └─ 否 → 分類B驗證發現:
- 直接合并為"溫度>30? → 分類A/分類B"準確率更高
- 則剪除"濕度"判斷分支
三者的內在聯系
- ?連續特征處理?:擴展算法應用范圍(數值型數據)
- ?缺失值處理?:增強算法魯棒性(現實數據總有缺失)
- ?后剪枝?:提升模型泛化能力(防止記住噪聲)
完整工作流圖示?:

5、業務應用中的特殊處理
當遇到極端多值特征?(如城市名稱)時:
- ?業務分組?:將取值按業務邏輯合并(如一線/二線城市)
- ?統計合并?:將低頻取值合并為"其他"類別
- ?特征重要性篩選?:先計算所有特征的增益率,人工剔除異常值
通過這種改進,C4.5算法實現了:
- ?抗多值干擾?:避免選擇無意義的細分特征
- ?更好的泛化性?:生成的決策規則更具普適性
- ?業務可解釋性?:分裂特征更符合業務邏輯
這種思想也深刻影響了后續的機器學習算法設計——任何純粹的統計指標都需要考慮其潛在的分布偏差。
CART算法:Gini指數
??"Gini指數像一把快刀,用最簡單的計算實現最有效的分割"??
1、CART算法的核心特點
Classification and Regression Trees (CART) 是決策樹家族的里程碑算法,其獨特之處在于:
- ?二叉樹結構?:每個節點只做二元分裂(即使特征有多個取值)
- ?萬能性?:唯一能同時處理分類(Gini指數)和回歸(方差最小化)的樹算法
- ?高效率?:Gini指數計算比信息熵節省約40%的計算量(無對數運算)
2、Gini指數的數學本質
?定義?:從數據集中隨機抽取兩個樣本,其類別標記不一致的概率
?計算公式?:
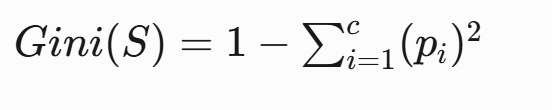
- c:類別總數
- pi?:第i類樣本的占比
?計算示例?:某節點有10個樣本:
- 7個類別A → pA?=0.7
- 3個類別B → pB?=0.3
Gini = 1 - (0.72 + 0.32) = 1 - (0.49 + 0.09) = 0.423、Gini增益計算流程
- ?計算父節點Gini指數?(前例得0.42)
- ?計算特征分裂后的加權Gini指數?:
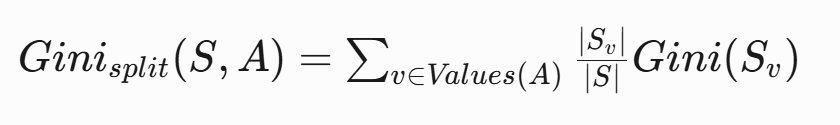
- ?計算Gini增益?:
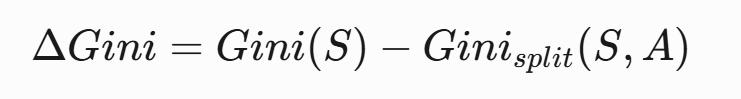
?實例演算?(天氣數據集):
| 天氣 | 風速 | 打球 |
|---|---|---|
| 晴 | 弱 | 否 |
| 晴 | 強 | 否 |
| 陰 | 弱 | 是 |
| 雨 | 強 | 是 |
| 雨 | 弱 | 是 |
| 雨 | 強 | 否 |
第一步:計算根節點Gini指數
總樣本6個:3"是",3"否"
第二步:計算各特征Gini增益
1. 特征"天氣"(3個取值:晴/陰/雨)
??候選二分方案??(CART必須做二元分裂):
- {晴} vs {陰,雨}
- {陰} vs {晴,雨}
- {雨} vs {晴,陰}
??方案1計算({晴} vs {陰,雨})??:
- 左節點(晴):2否 → Gini=0
- 右節點(陰+雨):1陰是 + 2雨是 + 1雨否
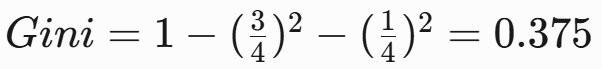
- 加權Gini:
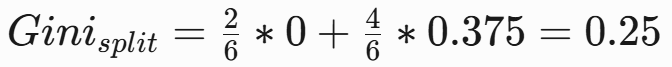
- Gini增益:
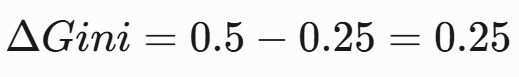
??方案2/3計算??(計算過程略):
- 方案2({陰} vs {晴,雨}):ΔGini=0.1
- 方案3({雨} vs {晴,陰}):ΔGini=0.056
詳細計算過程放在文章尾部
??最佳分裂??:選擇方案1({晴} vs {陰,雨}),ΔGini=0.25
2. 特征"風速"(2個取值:弱/強)
??二元分裂方案??:{弱} vs {強}
??計算過程??:

第三步:特征選擇對比
| 特征 | 最佳分裂方案 | Gini增益 |
|---|---|---|
| 天氣 | {晴} vs {陰,雨} | 0.25 |
| 風速 | {弱} vs {強} | 0.056 |
??決策??:選擇"天氣"的{晴} vs {陰,雨}分裂方案
第四步:構建子樹
當前分裂狀態
根節點分裂:
天氣是晴?
├─ 是 → 2個樣本(否, 否)
└─ 否 → 4個樣本(陰-是, 雨-是, 雨-是, 雨-否)1:處理純分支(晴分支)
??左分支(天氣=晴)??:
樣本完全純凈(全部為"否")
??直接作為葉節點??:不打球
C4.5改進應用:無需剪枝(已達最大純度)
2:處理混合分支(陰/雨分支)
??右分支(天氣≠晴)??:
4個樣本:
天氣 | 風速 | 打球 |
|---|---|---|
陰 | 弱 | 是 |
雨 | 強 | 是 |
雨 | 弱 | 是 |
雨 | 強 | 否 |
1. 計算當前節點Gini指數
![]()
2. 候選特征選擇(應用C4.5改進)
(1) 連續特征處理(無)。本例無連續特征
(2) 缺失值處理(無)。當前分支無缺失值
(3) 計算各特征增益率
??a. 天氣特征??(已用父特征,不再考慮)
??b. 風速特征??:
分裂方案??:{弱} vs {強}

3. 分裂決策
- 唯一可用特征:風速(ΔGini=0.125)
- ??執行分裂??(雖然增益率不高,但能提升純度)
3:構建子樹結構
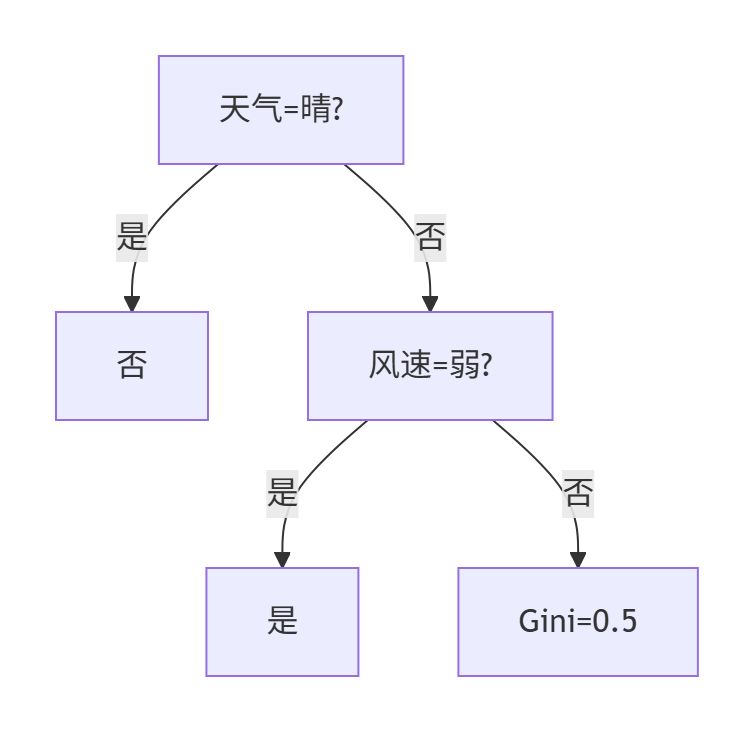
節點說明:
- ??風速=弱??:陰-是 + 雨-是 → 純凈葉節點(打球)
- ??風速=強??:樣本:雨-是 + 雨-否 → 仍需分裂但無更多特征
4:后剪枝處理(關鍵改進)
??評估風速=強分支??:
- 不分裂時:直接預測多數類(是:1, 否:1 → 無法確定)
- 替代方案:合并為葉節點并計算驗證集誤差
- 若驗證集支持"多數表決"(如選"是"),則剪枝
??最終優化樹??:
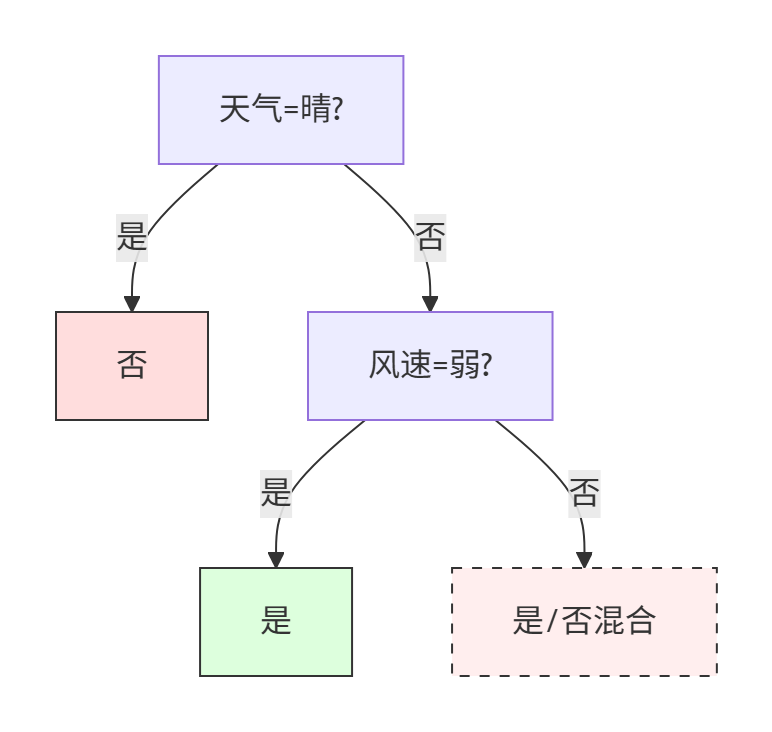
當特征信息不足時,允許存在未完全純化的節點。
完整決策規則
- 晴天 → 不打球
- 非晴天且弱風 → 打球
- 非晴天且強風 → 打球(剪枝后保守決策)
??業務解釋??:
雨天強風時實際存在不打球樣本,但C4.5通過剪枝犧牲局部精度換取泛化能力,這與ID3追求100%訓練集準確率形成鮮明對比。
關鍵結論
??CART特性??:
- 強制二叉樹結構(即使天氣有3個取值也轉為二元問題)
- 對陰/雨節點的風速分裂產生混合結果,說明需要更多特征
??與ID3/C4.5對比??:
# ID3會直接選擇天氣三路分裂: # 晴→否, 陰→是, 雨→混合 # CART通過二元分裂更適應集成學習??業務解釋??:
- 晴天絕對不打球
- 非晴天時,弱風天打球,強風天需結合溫度等其他因素判斷
5、CART的二叉樹分裂機制
?連續特征處理?:
- 將特征值排序(如年齡[22,25,30])
- 計算相鄰值中點(23.5, 27.5)
- 選擇使Gini增益最大的分割點
?類別特征處理?:
- 對k個取值生成2k?1?1種可能劃分
- 選擇最優二分方案(計算復雜度優化關鍵)
?Python實現示例?:
# 最佳分割點查找函數
def find_best_split(X, y):best_gain = -1for feature in range(X.shape[1]):thresholds = np.unique(X[:, feature])for thresh in thresholds:left_idx = X[:, feature] <= threshp_left = np.mean(y[left_idx])p_right = np.mean(y[~left_idx])gini_left = 1 - (p_left**2 + (1-p_left)**2)gini_right = 1 - (p_right**2 + (1-p_right)**2)gain = gini_parent - (len(left_idx)/len(y))*gini_left - (len(~left_idx)/len(y))*gini_rightif gain > best_gain:best_gain = gainreturn best_gain6、回歸樹中的方差最小化
當用于回歸任務時,CART改用方差作為分裂標準:
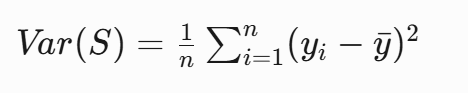
選擇使加權方差最小的分割:
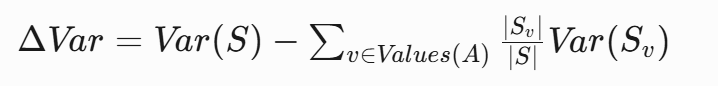
?房價預測示例?:
- 分割前方差:100
- 按"房間數≤3"分割:
- 左節點方差:60(樣本占比0.6)
- 右節點方差:30(樣本占比0.4)
ΔVar = 100 - (0.6 * 60 + 0.4 * 30) = 648、CART的局限性及解決方案
| 局限性 | 解釋 | 解決方案 |
|---|---|---|
| 過擬合 | CART 會不斷分裂直到純度最大化,可能導致模型過于復雜,泛化能力差。 | 后剪枝(Post-Pruning): 使用? 預剪枝(Pre-Pruning): 設置? |
| 數據不平衡 | 如果某一類樣本占主導,CART 可能會偏向該類,忽略少數類。 | 類別權重: 使用? 采樣方法: 過采樣少數類(SMOTE)或欠采樣多數類。 |
| 不穩定性 | 訓練數據的微小變化可能導致完全不同的樹結構。 | 隨機森林(Random Forest): 通過多棵樹的投票降低方差。 梯度提升樹(GBDT/XGBoost/LightGBM): 使用 Boosting 方式逐步修正錯誤。 |
| 只能生成二叉樹 | 相比 ID3/C4.5 的多叉樹,CART 的二叉樹結構可能在某些數據集上效率較低。 | 需要多叉樹?→ 使用 ID3/C4.5(如 Weka 的? 需要更魯棒的樹?→ 使用?條件推斷樹(CIT,? |
| 類別特征處理低效 | 直接處理類別特征時,CART 可能不如信息增益(ID3/C4.5)高效。 | 分箱(Binning): 對連續特征離散化,提高穩定性。 避免高基數類別特征: 對類別特征進行編碼(如 Target Encoding)。 |
貪心分裂 (局部最優) | 每次分裂只考慮當前最優,而非全局最優,可能導致次優樹結構。 | 動態規劃優化樹結構(如?OSDT 算法,但計算成本高)。 |
CART算法因其簡潔高效,成為現代集成學習(如隨機森林、GBDT)的基礎組件。Gini指數的設計體現了機器學習中一個重要原則:?在保證效果的前提下,最簡單的計算方法往往是最優選擇。這種思想在XGBoost等現代算法中得到了進一步發揚光大。
五、Python實戰(以sklearn為例)
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt# 加載數據
iris = load_iris()
X, y = iris.data, iris.target# 創建決策樹(使用Gini指數)
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X, y)# 可視化決策樹
plt.figure(figsize=(12,8))
plot_tree(model, feature_names=iris.feature_names,class_names=iris.target_names,filled=True)
plt.show()?關鍵參數說明?:
max_depth:樹的最大深度(控制復雜度)min_samples_split:節點最小分裂樣本數criterion:分裂標準(gini/entropy)
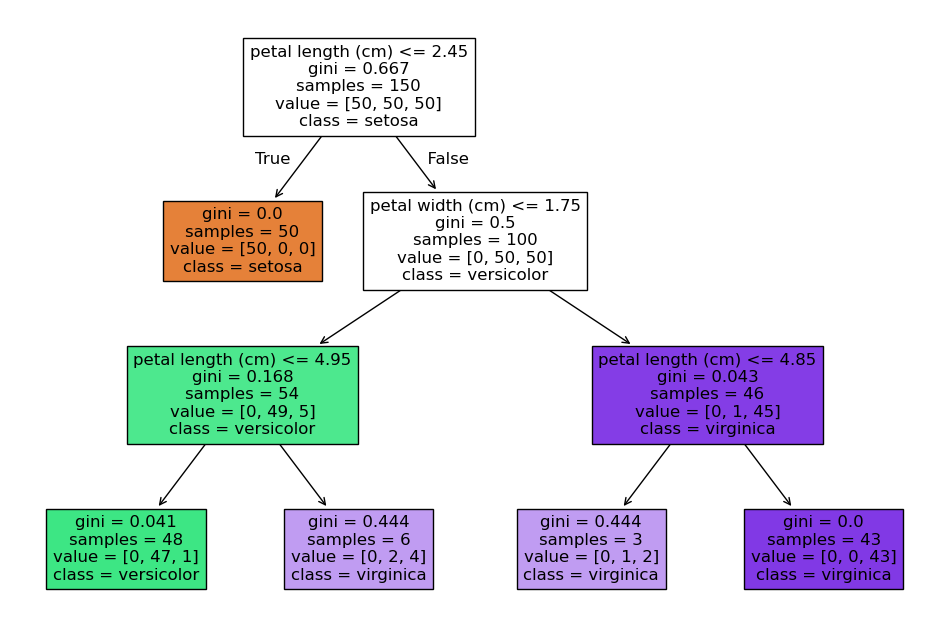
六、進階優化策略
- ?剪枝實戰(預防過擬合)??:
# 后剪枝示例(代價復雜度剪枝)
pruned_model = DecisionTreeClassifier(ccp_alpha=0.02)
pruned_model.fit(X, y)?處理連續特征?:尋找最佳分割點(如排序后取中位數)
?處理缺失值?:替代分裂(surrogate splits)
七、決策樹的雙面性
?優勢 ?:
- 直觀可視化(業務人員可理解)
- 無需數據標準化
- 支持混合特征(數值+類別)
?局限 ???:
- 對數據擾動敏感(小變動可能導致結構劇變)
- 容易過擬合(必須剪枝)
- 不適合學習復雜關系(如異或問題)
?延展思考?:決策樹作為集成學習的基模型(如隨機森林/XGBoost)時,通過“群體智慧”能極大克服自身缺陷。在實際應用中,超過80%的預測場景會優先嘗試樹模型家族。
八、Gini指數計算過程
方案2:{陰} vs {晴,雨} 二元分裂
1. 計算子集Gini指數
??左節點(陰)??:
樣本:1是
Gini = 1 - (1/1)2 - (0/1)2 = 0
??右節點(晴+雨)??:
樣本:2晴否 + 3雨(2是,1否)
是占比 = 2/5
否占比 = 3/5
Gini = 1 - (2/5)2 - (3/5)2 = 0.48
2. 計算加權Gini
3. 計算Gini增益
ΔGini=0.5?0.4=0.1
方案3:{雨} vs {晴,陰} 二元分裂
1. 計算子集Gini指數
??左節點(雨)??:
樣本:2是,1否
Gini = 1 - (2/3)2 - (1/3)2 ≈ 0.444
??右節點(晴+陰)??:
樣本:2晴否 + 1陰是
是占比 = 1/3
否占比 = 2/3
Gini = 1 - (1/3)2 - (2/3)2 ≈ 0.444
2. 計算加權Gini
3. 計算Gini增益
ΔGini=0.5?0.444=0.056



】密封)

)







)




)
