論文閱讀筆記:《Curriculum Coarse-to-Fine Selection for High-IPC Dataset Distillation》
- 1.背景與動機
- 2.核心貢獻
- 3.方法詳解
- 4.實驗結果與貢獻
- 主體代碼
- 算法整體邏輯
CVPR25 github
一句話總結:
CCFS基于組合范式(軌跡匹配+選擇真實圖像),通過“粗過濾+精選”課程式框架,動態補充合成集弱點,顯著提升高IPC設定下的數據集蒸餾性能,是目前高IPC場景下的SOTA方法。
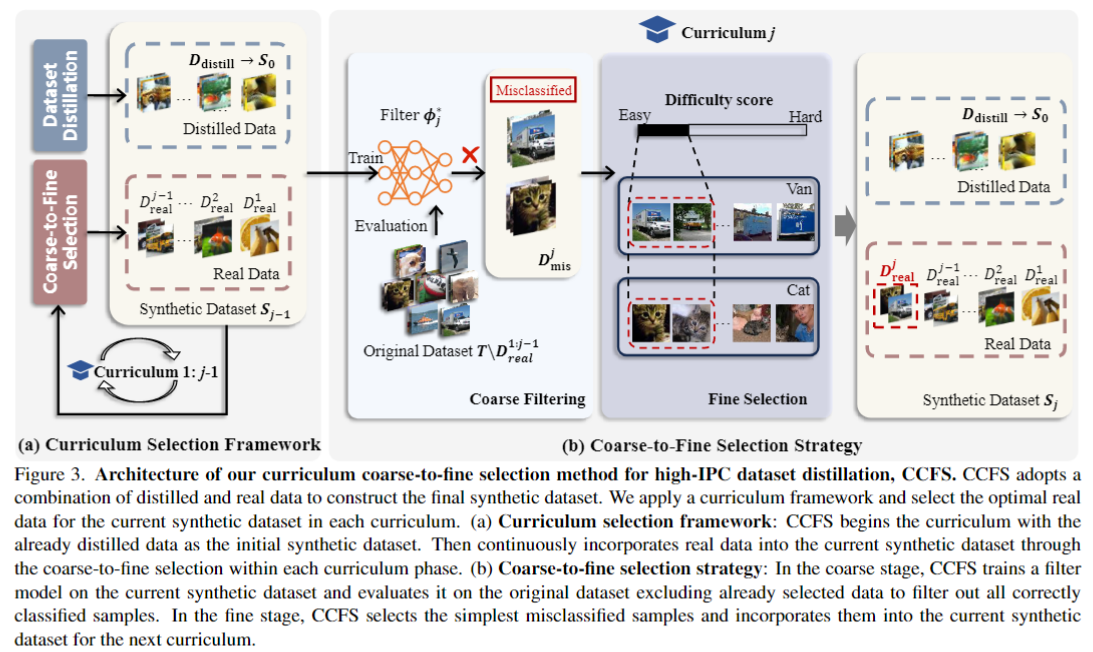
1.背景與動機
- Dataset Distillation: 將一個大規模訓練集壓縮成一個小型合成數據集,使得在此合成集上訓練的模型性能接近用原始全量數據訓練的模型。
- IPC(Image Per Class):每類合成圖像數。低IPC場景下(每類幾張圖),已有方法表現不錯;但IPC增大(要合成更多圖像)時,性能往往退化,甚至不如簡單隨機抽樣。
- 核心問題:高IPC時合成集過于“平均”,缺少稀有/復雜特征(hard samples),導致合成集覆蓋不足;已有的混合蒸餾+真實樣本方法(如SelMatch)是一次性靜態選樣,缺乏與合成集的動態互補。
2.核心貢獻
- 不兼容性診斷:分析了“先選真實樣本再蒸餾”范式下,靜態真樣本與動態蒸餾集互補不足的問題。
- CCFS方法:提出一種課程式(Curriculum)“從粗到細”動態選真樣本框架,將選樣分為兩階段:
- 粗過濾(Coarse):用當前合成集訓練的filter模型識別“還沒學會”的真實樣本(即被錯分的樣本)
- 精細選擇(fine):在這些候選中,根據“難度分數”或直接用filter logits選出“最簡單但尚未學會”的樣本,逐步補充到合成集中。
- 實證效果:在CIFAR-10/100和Tiny-ImageNet的高IPC設置(壓縮比5%~30%)下,CCFS刷新多項SOTA,部分場景下性能僅比全量訓練低0.3%。
3.方法詳解
整體流程:
- 初始化
- 從任一基礎蒸餾算法(如CDA)得到初始合成集DdistillD_{distill}Ddistill?
- 令當前合成集S0=DdistillS_0=D_{distill}S0?=Ddistill?
- 課程循環(共j階)
- 訓練Filter:在Sj?1S_{j-1}Sj?1?上蒸餾訓練一個filter模型?j?_j?j?, 讓它學會當前合成集的決策邊界。
- Coarse:用?j?_j?j?在原始訓練集T上做推理,挑出被錯分的樣本集合DmisjD_{mis}^jDmisj?
- Fine:對DmisjD_{mis}^jDmisj?內部進行排序,選出每類最“簡單未學會”的前kjk_jkj?張,構成DrealjD_{\mathrm{real}}^jDrealj?
- 更新:Sj=Sj?1∪DrealjS_j = S_{j-1} \cup D^j_{\mathrm{real}}Sj?=Sj?1?∪Drealj?
解釋一下為什么選“簡單未學會”的樣本:
錯分樣本集合DmissD_{miss}Dmiss?反映了S中的局限性。在這些局限性中,更簡單的特征相對于更復雜的特征而言,對模型訓練的益處更大,因為它們更容易被學習。預選計算的難度分數能夠從全局角度有效衡量樣本特征的相對難度,指導下一步的精細選擇。通過從誤分類樣本中選擇最簡單的特征,可以獲得最優的DrealD_{real}Dreal?,同時避免引入可能阻礙S性能的過于復雜的特征。
4.實驗結果與貢獻
- 數據集:CIFAR-10/100,Tiny-ImageNet
- 高IPC設置刷新SOTA
- CIFAR-10/100 在 10% IPC 下,分別較最佳基線提升 ~6.1% / ~5.8%;
- Tiny-ImageNet 20% IPC 下,僅比全量訓練低 0.3%。
- 跨架構泛化
用 ResNet-18 生成合成集,訓練 ResNet-50/101、DenseNet-121、RegNet 等網絡,均優于 CDA、SelMatch 等方法 - 詳盡消融
- 驗證 coarse(錯分 vs 自信分對)、fine(簡單 vs 困難 vs 隨機)策略組合;
- 不同難度分數對比,Forgetting score 最好;
- 課程輪數對性能與效率影響,3 輪是良好折中。
主體代碼
import os
import datetime
import time
import warnings
import numpy as np
import random
import torch
import torch.utils.data
import torchvision
import utils
from torch import nn
import torchvision.transforms as transforms
from imagenet_ipc import ImageFolderIPC
import torch.nn.functional as F
from tqdm import tqdm
import json
warnings.filterwarnings("ignore", category=UserWarning, module="torch.optim.lr_scheduler")def get_args_parser(add_help=True):import argparseparser = argparse.ArgumentParser(description="CCFS on CIFAR-100", add_help=add_help)parser.add_argument("--data-path", default=None, type=str, help="path to CIFAR-100 data folder")parser.add_argument("--filter-model", default="resnet18", type=str, help="filter model name")parser.add_argument("--teacher-model", default="resnet18", type=str, help="teacher model name")parser.add_argument("--teacher-path", default=None, type=str, help="path to teacher model")parser.add_argument("--eval-model", default="resnet18", type=str, help="model for final evaluation")parser.add_argument("--device", default="cuda", type=str, help="device (Use cuda or cpu Default: cuda)")parser.add_argument("-b", "--batch-size", default=64, type=int, help="Batch size")parser.add_argument("--epochs", default=90, type=int, metavar="N", help="# training epochs for both the filter and the evaluation model")parser.add_argument("-j", "--workers", default=4, type=int, metavar="N", help="number of data loading workers (default: 16)")parser.add_argument("--opt", default="sgd", type=str, help="optimizer")parser.add_argument("--lr", default=0.1, type=float, help="initial learning rate")parser.add_argument("--momentum", default=0.9, type=float, metavar="M", help="momentum")parser.add_argument("--wd", "--weight-decay", default=1e-4, type=float, metavar="W", help="weight decay (default: 1e-4)", dest="weight_decay")parser.add_argument("--lr-scheduler", default="steplr", type=str, help="the lr scheduler (default: steplr)")parser.add_argument("--lr-warmup-epochs", default=0, type=int, help="the number of epochs to warmup (default: 0)")parser.add_argument("--lr-warmup-method", default="constant", type=str, help="the warmup method (default: constant)")parser.add_argument("--lr-warmup-decay", default=0.01, type=float, help="the decay for lr")parser.add_argument("--lr-step-size", default=30, type=int, help="decrease lr every step-size epochs")parser.add_argument("-T", "--temperature", default=20, type=float, help="temperature for distillation loss")parser.add_argument("--print-freq", default=1000, type=int, help="print frequency")# --- CCFS parameters ---# 目標每類最終的圖像數量IPCparser.add_argument("--image-per-class", default=50, type=int, help="number of synthetic images per class")parser.add_argument("--distill-data-path", default=None, type=str, help="path to already distilled data")# distillation portion,決定合成(蒸餾)圖像與真實選擇的比例;# cpc=IPC*alpha 是每類的合成圖像 (condensed per class)# spc=IPC-cpc是每類要選的真實圖像數 (selected per class)parser.add_argument('--alpha', type=float, default=0.2, help='Distillation portion')# 分幾個階段做”課程式“選樣(例如3輪)parser.add_argument('--curriculum-num', type=int, default=None, help='Number of curricula')# 粗階段式選被filter預測錯的(True)還是預測對的(false)parser.add_argument('--select-misclassified', action='store_true', help='Selection strategy in coarse stage')# 細階段的選法 ,simple/hard/random(對應論文里”最簡單未學會“/"最難"/"隨機")parser.add_argument('--select-method', type=str, default='simple', choices=['random', 'hard', 'simple'], help='Selection strategy in fine stage')# 是否每類均衡選parser.add_argument('--balance', action='store_true', help='Whether to balance the amount of the synthetic data between classes')# 選擇哪種方法評分parser.add_argument('--score', type=str, default='forgetting', choices=['logits', 'forgetting', 'cscore'], help='Difficulty score used in fine stage')# 如果不是logits而是預先算好的難度分(如forgetting score),用這個路徑讀入parser.add_argument('--score-path', type=str, default=None, help='Path to the difficulty score')parser.add_argument("--output-dir", default=".", type=str, help="path to save outputs")parser.add_argument("--num-eval", default=1, type=int, help="number of evaluations")return parserdef load_data(args):'''數據集加載Returns:dataset: 蒸餾數據集image_og, labels_og: 全量原始訓練樣本(用于選樣)dataset_test: 驗證集(test)以及對應sampler'''# Data loading codenormalize = transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],std=[0.2023, 0.1994, 0.2010])print("Loading distilled data")train_transform = transforms.Compose([transforms.RandomResizedCrop(32),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize,])# ImageFolderIPC自定義數據讀取,可以從大的ipc蒸餾數據集中每類選擇或隨機選擇cpc個圖像# cpc=IPC * alpha,是每類的合成圖像數dataset = ImageFolderIPC(root=args.distill_data_path, ipc=args.cpc, transform=train_transform)print("Loading validation data")val_transform = transforms.Compose([transforms.ToTensor(),normalize,])# 加載驗證集(test)dataset_test = torchvision.datasets.CIFAR100(root=args.data_path, train=False, download=True, transform=val_transform)print("Loading original training data")# 加載原始訓練集(用于做coarse selection / teacher correctness等)dataset_og = torchvision.datasets.CIFAR100(root=args.data_path, train=True, download=True, transform=val_transform)# 構造原始訓練數據:直接把全量CIFAR100d的所有圖像展開到一個大tensor image_og 和對應標簽labels_og。# 這在內存允許時可行,但規模增大時可以優化成分batch處理或lazy訪問images_og = [torch.unsqueeze(dataset_og[i][0], dim=0) for i in range(len(dataset_og))]labels_og = [dataset_og[i][1] for i in range(len(dataset_og))]images_og = torch.cat(images_og, dim=0)labels_og = torch.tensor(labels_og, dtype=torch.long)print("Creating data loaders")train_sampler = torch.utils.data.RandomSampler(dataset)test_sampler = torch.utils.data.SequentialSampler(dataset_test)return dataset, images_og, labels_og, dataset_test, train_sampler, test_samplerdef create_model(model_name, device, num_classes, path=None):# 根據名稱構造backbone(TODO:默認不加載預訓練權重)model = torchvision.models.get_model(model_name, weights=None, num_classes=num_classes)# 將下采樣第一層conv和pooling修改為適配CIFAR風格model.conv1 = nn.Conv2d(3, 64, kernel_size=(3,3), stride=(1,1), padding=(1,1), bias=False)model.maxpool = nn.Identity()# 加載預訓練權重 (TODO:是否加載預訓練權重)if path is not None:checkpoint = torch.load(path, map_location="cpu")if "model" in checkpoint:checkpoint = checkpoint["model"]elif "state_dict" in checkpoint:checkpoint = checkpoint["state_dict"]if "module." in list(checkpoint.keys())[0]:checkpoint = {k.replace("module.", ""): v for k, v in checkpoint.items()}model.load_state_dict(checkpoint)model.to(device)return modeldef curriculum_arrangement(spc, curriculum_num):'''課程分配安排將總共要選的每類真實圖像數spc等分到curriculum_num輪:例如spc=7,curriculum_num=3會分成[3,2,2](前面多余的向前分)'''remainder = spc % curriculum_numarrangement = [spc // curriculum_num] * curriculum_numfor i in range(remainder):arrangement[i] += 1return arrangementdef train_one_epoch(model, teacher_model, criterion, optimizer, data_loader, device, epoch, args):"""在一個 epoch(遍歷一遍 data_loader)里,用 KL 散度蒸餾(distillation)student(model)去學習 teacher_model 的“軟標簽”。具體做法是:把 teacher 和 student 的 logits 都除以溫度 T 后做 log_softmax,然后用 KLDivLoss;最后乘上 T^2 做梯度縮放,確保溫度對 loss 的影響保持一致。"""# 切換student到train模式model.train()# 切換teacher到eval模式,只做前向不更新teacher_model.eval()metric_logger = utils.MetricLogger(delimiter=" ")metric_logger.add_meter("lr", utils.SmoothedValue(window_size=1, fmt="{value}"))metric_logger.add_meter("img/s", utils.SmoothedValue(window_size=10, fmt="{value}"))header = f"Epoch: [{epoch}]"for i, (image, target) in enumerate(metric_logger.log_every(data_loader, args.print_freq, header)):start_time = time.time()image, target = image.to(device), target.to(device)# 1)teacher 前向teacher_output = teacher_model(image)# 2)student前向output = model(image)# 把Logits除以溫度系數,再做log_softmaxteacher_output_log_softmax = F.log_softmax(teacher_output/args.temperature, dim=1)output_log_softmax = F.log_softmax(output/args.temperature, dim=1)# 用KL散度計算loss,乘上T^2以抵消溫度縮放帶來的梯度變換loss = criterion(output_log_softmax, teacher_output_log_softmax) * (args.temperature ** 2)# 標準的 backward 流程optimizer.zero_grad()loss.backward()optimizer.step()# 計算 student 在原始 hard label(target)上的 top1/top5 準確率acc1, acc5 = utils.accuracy(output, target, topk=(1, 5))batch_size = image.shape[0]# 更新 metric_logger 里的各項指標metric_logger.update(loss=loss.item(), lr=optimizer.param_groups[0]["lr"])metric_logger.meters["acc1"].update(acc1.item(), n=batch_size)metric_logger.meters["acc5"].update(acc5.item(), n=batch_size)metric_logger.meters["img/s"].update(batch_size / (time.time() - start_time))def evaluate(model, criterion, data_loader, device, log_suffix=""):"""在測試/驗證集上跑一個完整的 forward,計算交叉熵 loss 和 top1/top5 準確率。不做梯度更新,只做推理。"""model.eval()metric_logger = utils.MetricLogger(delimiter=" ")header = f"Test: {log_suffix}"num_processed_samples = 0 # 累計處理樣本數with torch.inference_mode():for image, target in data_loader:image = image.to(device, non_blocking=True)target = target.to(device, non_blocking=True)# 前向output = model(image)# 用硬標簽算交叉熵loss = criterion(output, target)# 計算 top1/top5acc1, acc5 = utils.accuracy(output, target, topk=(1, 5))batch_size = image.shape[0]metric_logger.update(loss=loss.item())metric_logger.meters["acc1"].update(acc1.item(), n=batch_size)metric_logger.meters["acc5"].update(acc5.item(), n=batch_size)num_processed_samples += batch_size# 如果是分布式,需要把各卡的樣本數累加num_processed_samples = utils.reduce_across_processes(num_processed_samples)if (hasattr(data_loader.dataset, "__len__")and len(data_loader.dataset) != num_processed_samplesand torch.distributed.get_rank() == 0):warnings.warn(f"It looks like the dataset has {len(data_loader.dataset)} samples, but {num_processed_samples} ""samples were used for the validation, which might bias the results. ""Try adjusting the batch size and / or the world size. ""Setting the world size to 1 is always a safe bet.")metric_logger.synchronize_between_processes()return metric_logger.acc1.global_avgdef curriculum_train(current_curriculum, dst_train, test_loader, model, teacher_model, args):"""對當前的”合成數據+已選真實數據“ dst_train進行一次完整的filter模型訓練(蒸餾學習):- 根據數據規模動態調整batch_size- 構造 DataLoader / Criterion / Optimizer / LR Scheduler(含 warmup)- 訓練 args.epochs 輪,后 20% 輪做驗證并記錄最佳 acc1返回:訓練好的 model 和最佳 top-1 準確率 best_acc1"""best_acc1 = 0# 1. 根據dst_train(合成+真實)大小粗略選batch sizeif len(dst_train) < 50 * args.num_classes:args.batch_size = 32elif 50 * args.num_classes <= len(dst_train) < 100 * args.num_classes:args.batch_size = 64else:args.batch_size = 128# 2. 用隨機采樣器包裝訓練集,保證每個epoch順序打散train_sampler = torch.utils.data.RandomSampler(dst_train)train_loader = torch.utils.data.DataLoader(dst_train,batch_size=args.batch_size,sampler=train_sampler,num_workers=args.workers,pin_memory=True,)# 3. 損失函數:硬標簽用CrossEntropy,蒸餾軟標簽用KLDivcriterion = nn.CrossEntropyLoss()criterion_kl = nn.KLDivLoss(reduction='batchmean', log_target=True)parameters = utils.set_weight_decay(model, args.weight_decay)# 構造優化器opt_name = args.opt.lower()if opt_name.startswith("sgd"):optimizer = torch.optim.SGD(parameters,lr=args.lr,momentum=args.momentum,weight_decay=args.weight_decay,nesterov="nesterov" in opt_name,)elif opt_name == "rmsprop":optimizer = torch.optim.RMSprop(parameters, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay, eps=0.0316, alpha=0.9)elif opt_name == "adamw":optimizer = torch.optim.AdamW(parameters, lr=args.lr, weight_decay=args.weight_decay)else:raise RuntimeError(f"Invalid optimizer {args.opt}. Only SGD, RMSprop and AdamW are supported.")# 6. 構造主學習率調度器:StepLR / CosineAnnealingLR / ExponentialLRargs.lr_scheduler = args.lr_scheduler.lower()if args.lr_scheduler == "steplr":main_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=args.lr_step_size, gamma=args.lr_gamma)elif args.lr_scheduler == "cosineannealinglr":main_lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=args.epochs - args.lr_warmup_epochs, eta_min=0.0)elif args.lr_scheduler == "exponentiallr":main_lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=args.lr_gamma)else:raise RuntimeError(f"Invalid lr scheduler '{args.lr_scheduler}'. Only StepLR, CosineAnnealingLR and ExponentialLR ""are supported.")# 7. 如果設置了 warmup,就把 warmup scheduler 和主 scheduler 串聯if args.lr_warmup_epochs > 0:if args.lr_warmup_method == "linear":warmup_lr_scheduler = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=args.lr_warmup_decay, total_iters=args.lr_warmup_epochs)elif args.lr_warmup_method == "constant":warmup_lr_scheduler = torch.optim.lr_scheduler.ConstantLR(optimizer, factor=args.lr_warmup_decay, total_iters=args.lr_warmup_epochs)else:raise RuntimeError(f"Invalid warmup lr method '{args.lr_warmup_method}'. Only linear and constant are supported.")# milestones 指在第 args.lr_warmup_epochs 次后切換到 main_lr_schedulerlr_scheduler = torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers=[warmup_lr_scheduler, main_lr_scheduler], milestones=[args.lr_warmup_epochs])else:lr_scheduler = main_lr_scheduler# 8. 開始訓練print("Start training on synthetic dataset...")start_time = time.time()pbar = tqdm(range(args.epochs), ncols=100)for epoch in pbar:# 每個 epoch 都調用前面寫好的 train_one_epoch(KL 蒸餾)train_one_epoch(model, teacher_model, criterion_kl, optimizer, train_loader, args.device, epoch, args)# 訓練完一輪后,調度學習率lr_scheduler.step()# 只在最后 20% 的輪次做驗證,節省時間if epoch > args.epochs * 0.8:acc1 = evaluate(model, criterion, test_loader, device=args.device) # 這里 evaluate 用硬標簽 loss & 準確率# 更新 best_acc1if acc1 > best_acc1:best_acc1 = acc1# 在進度條上顯示當前/最佳準確率pbar.set_description(f"Epoch[{epoch}] Test Acc: {acc1:.2f}% Best Acc: {best_acc1:.2f}%")print(f"Best Accuracy {best_acc1:.2f}%")total_time = time.time() - start_timetotal_time_str = str(datetime.timedelta(seconds=int(total_time)))print(f"Training time {total_time_str}")return model, best_acc1def coarse_filtering(images_all, labels_all, filter, batch_size, args, get_correct=True):"""對全量原始訓練集 images_all 用 filter 模型做一次完整的推理:- 如果 get_correct=True,返回“預測正確”的樣本索引列表;否則返回“預測錯誤”的樣本索引列表。- 同時返回所有樣本的 raw logits(未 softmax)。"""true_labels = labels_all.cpu()filter.eval() # 只做前向,不更新參數logits = None# 分批推理,防止一次OOMfor select_times in range((len(images_all)+batch_size-1)//batch_size):# slice出當前batch的圖像# detach 防止梯度追溯,再搬到devicecurrent_data_batch = images_all[batch_size*select_times : batch_size*(select_times+1)].detach().to(args.device)# 前向batch_logits = filter(current_data_batch)# concatenate 到一起if logits == None:logits = batch_logits.detach()else:logits = torch.cat((logits, batch_logits.detach()),0)# 取每行最大值的下標作為預測標簽predicted_labels = torch.argmax(logits, dim=1).cpu()# 根據get_correct 選正確或錯誤的索引target_indices = torch.where(true_labels == predicted_labels)[0] if get_correct else torch.where(true_labels != predicted_labels)[0]target_indices = target_indices.tolist()print('Acc on training set: {:.2f}%'.format(100*len(target_indices)/len(images_all) if get_correct else 100*(1-len(target_indices)/len(images_all))))return target_indices, logitsdef selection_logits(selected_idx, teacher_correct_idx, images_all, labels_all, filter, args):"""用 filter 模型的 logits 做 fine 階段的選樣:- teacher_correct_idx: teacher 在原始訓練集上預測正確的樣本索引- selected_idx: 已經在前幾輪中選過的樣本索引,避免重復返回當前輪要新增的選樣索引列表"""batch_size = 512true_labels = labels_all.cpu()filter.eval()print('Coarse Filtering...')# --- Coarse 階段:決定哪些樣本進入fine階段# 如果select_misclassified=True,就filter"預測錯誤"的樣本if args.select_misclassified:target_indices, logits = coarse_filtering(images_all, labels_all, filter, batch_size, args, get_correct=False)else:target_indices, logits = coarse_filtering(images_all, labels_all, filter, batch_size, args, get_correct=True)# —— 交叉過濾:只保留 teacher 也預測正確的樣本,且去除已選過的# teacher_correct_idx 是 teacher 在原始訓練集上預測正確的索引(論文里是“只有 teacher 也能正確的樣本才考慮”這一類過濾)。if teacher_correct_idx is not None:# 取 teacher_correct_idx 與 target_indices 的交集,再減去 selected_idxtarget_indices = list(set(teacher_correct_idx) & set(target_indices) - set(selected_idx))else:target_indices = list(set(target_indices) - set(selected_idx))print('Fine Selection...')selection = []if args.balance:# 如果要 class-balance,每個類單獨選 args.curpc 個target_idx_per_class = [[] for c in range(args.num_classes)]for idx in target_indices:target_idx_per_class[true_labels[idx]].append(idx)for c in range(args.num_classes):if args.select_method == 'random':# 隨機抽樣selection += random.sample(target_idx_per_class[c], args.curpc)elif args.select_method == 'hard':# 按 logits[c] 升序,logit 越低表示模型越“不自信” ? “更難”selection += sorted(target_idx_per_class[c], key=lambda i: logits[i][c], reverse=False)[:args.curpc]elif args.select_method == 'simple':# 按 logits[c] 降序,logit 越高表示模型越“自信” ? “簡單”selection += sorted(target_idx_per_class[c], key=lambda i: logits[i][c], reverse=True)[:args.curpc]else:# 不做 class-balance,直接在所有 target_indices 中選總數 = curpc * num_classesif args.select_method == 'random':selection = random.sample(target_indices, args.curpc*args.num_classes)elif args.select_method == 'hard':selection = sorted(target_indices, key=lambda i: logits[i][true_labels[i]], reverse=False)[:args.curpc*args.num_classes]elif args.select_method == 'simple':selection = sorted(target_indices, key=lambda i: logits[i][true_labels[i]], reverse=True)[:args.curpc*args.num_classes]return selectiondef selection_score(selected_idx, teacher_correct_idx, images_all, labels_all, filter, score, reverse, args):"""用預先計算好的difficult score 做fine階段的選樣:- score: numpy array, score[i]表示樣本i的難度分數- reverse: bool其余流程同 selection_logits,只是排序依據改為 score"""batch_size = 512true_labels = labels_all.cpu()filter.eval()print('Coarse Filtering...')# Coarse 階段同上if args.select_misclassified:target_indices, _ = coarse_filtering(images_all, labels_all, filter, batch_size, args, get_correct=False)else:target_indices, _ = coarse_filtering(images_all, labels_all, filter, batch_size, args, get_correct=True)# 交叉過濾 teacher_correct_idx & 去除已選if teacher_correct_idx is not None:target_indices = list(set(teacher_correct_idx) & set(target_indices) - set(selected_idx))else:target_indices = list(set(target_indices) - set(selected_idx))print('Fine Selection...')selection = []if args.balance:target_idx_per_class = [[] for c in range(args.num_classes)]for idx in target_indices:target_idx_per_class[true_labels[idx]].append(idx)for c in range(args.num_classes):if args.select_method == 'random':selection += random.sample(target_idx_per_class[c], min(args.curpc, len(target_idx_per_class[c])))elif args.select_method == 'hard':selection += sorted(target_idx_per_class[c], key=lambda i: score[i], reverse=reverse)[:args.curpc]elif args.select_method == 'simple':# 用外部 score(預先計算的 difficulty)selection += sorted(target_idx_per_class[c], key=lambda i: score[i], reverse=not reverse)[:args.curpc]else:if args.select_method == 'random':selection = random.sample(target_indices, min(args.curpc*args.num_classes, len(target_indices)))elif args.select_method == 'hard':selection = sorted(target_indices, key=lambda i: score[i], reverse=reverse)[:args.curpc*args.num_classes]elif args.select_method == 'simple':selection = sorted(target_indices, key=lambda i: score[i], reverse=not reverse)[:args.curpc*args.num_classes]return selectiondef main(args):'''Preparation'''print('=> args.output_dir', args.output_dir)start_time = datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S')log_dir = os.path.join(args.output_dir, 'CIFAR-100', start_time)os.makedirs(log_dir, exist_ok=True)device = torch.device(args.device)if device.type == 'cuda':print('Using GPU')torch.backends.cudnn.benchmark = True# 計算cpc(合成每類)和spc(要從真實數據選的每類數)args.cpc = int(args.image_per_class * args.alpha) # condensed images per classargs.spc = args.image_per_class - args.cpc # selected real images per classargs.num_classes = 100print('Target IPC: {}, num_classes: {}, distillation portion: {}, distilled images per class: {}, real images to be selected per class: {}'.format(args.image_per_class, args.num_classes, args.alpha, args.cpc, args.spc))# 加載數據dataset_dis, images_og, labels_og, dataset_test, train_sampler, test_sampler = load_data(args)# 加載difficulty scoreif args.score == 'forgetting':score = np.load(args.score_path)reverse = Trueelif args.score == 'cscore':score = np.load(args.score_path)reverse = Falsecurriculum_num = args.curriculum_num# 構造curriculum_arrangement分配:每輪要選多少個真實樣本arrangement = curriculum_arrangement(args.spc, curriculum_num)# 加載測試集test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=512, sampler=test_sampler, num_workers=args.workers, pin_memory=True)# 加載教師模型teacher_model = create_model(args.teacher_model, device, args.num_classes, args.teacher_path)# 凍結教師模型參數for p in teacher_model.parameters():p.requires_grad = Falseteacher_model.eval()# 使用教師模型在原始數據集上做一次初篩,只有teacher預測對的樣本才可能被選入teacher_correct_idx, _ = coarse_filtering(images_og, labels_og, teacher_model, 512, args, get_correct=True)print('teacher acc@1 on original training data: {:.2f}%'.format(100*len(teacher_correct_idx)/len(images_og)))'''Curriculum selection'''idx_selected = []dataset_sel = Nonedst_sel_transform = transforms.Compose([transforms.RandomResizedCrop(32),transforms.RandomHorizontalFlip(),])print('Selected images per class arrangement in each curriculum: ', arrangement)# 開始課程學習for i in range(curriculum_num):print('----Curriculum [{}/{}]----'.format(i+1, curriculum_num))args.curpc = arrangement[i]# 第0輪以蒸餾合成集為起點if i == 0:print('Begin with distilled dataset')syn_dataset = dataset_disdataset_sel = []print('Synthetic dataset size:', len(syn_dataset), "distilled data:", len(dataset_dis), "selected data:", len(dataset_sel))# 訓練一個新的filter(每輪都從頭開始訓練)filter = create_model(args.filter_model, device, args.num_classes)# TODO:課程訓練,教師模型打軟標簽filter, best_acc1 = curriculum_train(i, syn_dataset, test_loader, filter, teacher_model, args)print('Selecting real data...')if args.score == 'logits':selection = selection_logits(idx_selected, teacher_correct_idx, images_og, labels_og, filter, args)else:selection = selection_score(idx_selected, teacher_correct_idx, images_og, labels_og, filter, score, reverse, args)idx_selected += selectionprint('Selected {} in this curriculum'.format(len(selection)))imgs_select = images_og[idx_selected]labs_select = labels_og[idx_selected]dataset_sel = utils.TensorDataset(imgs_select, labs_select, dst_sel_transform)syn_dataset = torch.utils.data.ConcatDataset([dataset_dis, dataset_sel])print('----All curricula finished----')print('Final synthetic dataset size:', len(syn_dataset), "distilled data:", len(dataset_dis), "selected data:", len(dataset_sel)) print('Saving selected indices...')idx_file = os.path.join(log_dir, f'selected_indices.json')with open(idx_file, 'w') as f:json.dump({'ipc': args.image_per_class,'alpha': args.alpha, 'idx_selected': idx_selected}, f)f.close()'''Final evaluation'''num_eval = args.num_evalaccs = []for i in range(num_eval):print(f'Evaluation {i+1}/{num_eval}')eval_model = create_model(args.eval_model, device, args.num_classes)_, best_acc1 = curriculum_train(0, syn_dataset, test_loader, eval_model, teacher_model, args)accs.append(best_acc1)acc_mean = np.mean(accs)acc_std = np.std(accs)print('----Evaluation Results----')print(f'Acc@1(mean): {acc_mean:.2f}%, std: {acc_std:.2f}')print('Saving results...')log_file = os.path.join(log_dir, f'exp_log.txt')with open(log_file, 'w') as f:f.write('EXP Settings: \n')f.write(f'IPC: {args.image_per_class},\tdistillation portion: {args.alpha},\tcurriculum_num: {args.curriculum_num}\n')f.write(f'filter model: {args.filter_model},\tteacher model: {args.teacher_model},\tbatch_size: {args.batch_size},\tepochs: {args.epochs}\n')f.write(f"coarse stage strategy: {'select misclassified' if args.select_misclassified else 'select correctly classified'}\n")f.write(f'fine stage strategy: {args.select_method},\tdifficulty score: {args.score},\tbalance: {args.balance}\n')f.write(f'eval model: {args.eval_model},\tAcc@1: {acc_mean:.2f}%,\tstd: {acc_std:.2f}\n')f.close()if __name__ == "__main__":args = get_args_parser().parse_args()main(args)
算法整體邏輯
算法輸入
- 蒸餾合成集DdistillD_{distill}Ddistill?: 已經經過某種蒸餾算法生成的小規模“合成”數據集,每類包含CPC=IPC×αCPC=IPC×\alphaCPC=IPC×α。
- 原始訓練集(image_og,labels_og):完整的CIFAR100訓練樣本,用于選樣。
- 教師模型?teacher?_{teacher}?teacher?: 在原始訓練集上表現優秀的固定模型,用于提供“正確”的軟標簽參考。
- 超參數: IPCIPCIPC(每類最終圖數)、α\alphaα(蒸餾比例)、課程輪數 JJJ、粗篩策略、精篩策略、難度分數類型等。
整體流程
-
初始化
- 解析命令行參數,計算:cpc=?IPC×α?cpc=?IPC×α?cpc=?IPC×α?, spc=IPC×cpcspc=IPC×cpcspc=IPC×cpc。
- 加載DdistillD_{distill}Ddistill?、原始訓練集和驗證集。
- 加載并凍結教師模型?teacher?_{teacher}?teacher?,在原始訓練集上做一次推理,記錄教師預測正確的索引集合 IteacherI_{teacher}Iteacher?。
-
課程分配
將每類總共要選的spcspcspc張真實圖,均勻分配到JJJ輪: [k1,k2,…,kJ],∑jkj=spc[k_1,k_2,…,k_J],\sum_{j}{k_j} =spc[k1?,k2?,…,kJ?],∑j?kj?=spc
-
多輪“粗-細”選樣循環
令當前集合S0=DdistillS_0=D_{distill}S0?=Ddistill?,已選索引集合Isel=?I_{sel}=?Isel?=?
對每個課程階段j=1...Jj=1...Jj=1...J:
i. 蒸餾訓練Filter:
- 在Sj?1S_{j-1}Sj?1?上,用教師模型的“軟標簽”蒸餾訓練一個新的filter模型?j?_j?j?
ii. Coarse(粗過濾)
- 用?j?_j?j?在整個原始訓練集上做推理,得到所有樣本的logits和預測標簽。
- 根據
select_misclassified決定保留“錯分”樣本索引,或保留“分對”樣本索引,記為候選集 CCC。 - 交叉過濾:僅保留既在 CCC 中、又在IteacherI_{teacher}Iteacher?中,且不在 IselI_{sel}Isel? 中的索引。
iii. Fine(精細選擇)
- 在上述候選索引里,依據“logits”或外部
pre-computed difficulty score,對每個索引排序,規則可以是simple、hard、random - 如選
--balance,則每類各取kjk_jkj?張;否則全體一并取總數 kj×num_classesk_j×num\_classeskj?×num_classes。 - 將本輪選中的新索引加入IselI_{sel}Isel?。
iv. 更新合成集
Sj←Ddistill∪{真實樣本i:i∈Isel}.S_j←D_{distill}∪\{真實樣本 i:i∈I_{sel}\}. Sj?←Ddistill?∪{真實樣本i:i∈Isel?}. -
保存 & 最終評估
- 將IselI_{sel}Isel?輸出到Json以供后續復現
- 用最終的混合集SjS_jSj?訓練一個新的evaluation模型,測多次Top-1準確率,取均值與標準差。
這個流程確保每輪都針對模型“真正沒有學到”的部分,有序補充,最終合成集既覆蓋常見知識,也涵蓋關鍵難點

- 繪制子圖)

















