?函數:返回GPU
def try_gpu(i=0): #@save"""如果存在,則返回gpu(i),否則返回cpu()"""if torch.cuda.device_count() >= i + 1: # 如果存在第 i 個 GPUreturn torch.device(f'cuda:{i}') # 返回第 i 個 GPU 設備return torch.device('cpu') # 若系統中無足夠的GPU設備(即GPU數量<i+1),則返回CPU設備def try_all_gpus(): #@save"""返回所有可用的GPU,如果沒有GPU,則返回[cpu(),]"""devices = [torch.device(f'cuda:{i}')for i in range(torch.cuda.device_count())]# 如果存在可用的 GPU,則返回一個包含所有 GPU 設備的列表return devices if devices else [torch.device('cpu')]# from common import try_gpu, try_all_gpus
print(f"{try_gpu(), try_gpu(10), try_all_gpus()}")
print(f"默認嘗試返回第1個GPU設備:{try_gpu()}")
print(f"嘗試返回第11個GPU設備:{try_gpu(10)}")
print(f"返回所有可用的GPU:{try_all_gpus()}")函數:生成數據集(生成 “符合線性關系 y=Xw+b+噪聲” 的合成數據集)synthetic_data
'''(與 線性神經網絡 的一樣)
# 生成 “符合線性關系 y=Xw+b+噪聲” 的合成數據集
# w: 權重向量(決定線性關系的斜率)
# b: 偏置項(決定線性關系的截距)
# num_examples: 要生成的樣本數量
在指定正態分布中隨機生成特征矩陣X,
然后根據傳入的權重和偏置再加上隨機生成的噪聲計算得到標簽向量y。
'''
def synthetic_data(w, b, num_examples): # @save"""生成y=Xw+b+噪聲"""# 生成一個形狀為 (num_examples, len(w)) 的矩陣,每個元素從均值為0、標準差為1的正態分布中隨機采樣X = torch.normal(0, 1, (num_examples, len(w)))print(f"X的形狀{X.shape}")y = torch.matmul(X, w) + b # 計算線性部分 Xw + by += torch.normal(0, 0.01, y.shape) # 添加噪聲(均值為0,標準差為0.01的正態分布)使數據更接近真實場景(避免完全線性可分)return X, y.reshape((-1, 1)) # 返回特征矩陣X和標簽向量y, y.reshape((-1, 1)) 確保y是列向量(形狀為 (num_examples, 1))使用示例:
# 定義真實的權重 w = [2, -3.4] 和偏置 b = 4.2
true_w = torch.tensor([2, -3.4])
true_b = 4.2# features: 形狀為 (1000, 2) 的矩陣,每行皆包含一個二維數據樣本
# labels: 形狀為 (1000, 1) 的向量,每行皆包含一維數據標簽值(一個標量)
# 標簽由線性關系 y = 2*x1 - 3.4*x2 + 4.2 + 噪聲 生成
features, labels = synthetic_data(true_w, true_b, 1000) # 生成1000個樣本
print('features:', features[0],'\nlabel:', labels[0])# 生成數據
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05train_data = common.synthetic_data(true_w, true_b, n_train)
train_iter = common.load_array(train_data, batch_size)test_data = common.synthetic_data(true_w, true_b, n_test)
test_iter = common.load_array(test_data, batch_size, is_train=False)函數:繪圖函數plot & 設置軸屬性set_axes
# 封裝了 Matplotlib 軸屬性的常用設置
def set_axes(axes, xlabel=None, ylabel=None, xlim=None, ylim=None,xscale='linear', yscale='linear', legend=None):"""設置繪圖的軸屬性"""if xlabel: axes.set_xlabel(xlabel) # 設置x軸標簽(如果提供)if ylabel: axes.set_ylabel(ylabel) # 設置y軸標簽(如果提供)if xlim: axes.set_xlim(xlim) # 設置x軸范圍(如 [0, 10])(如果提供)if ylim: axes.set_ylim(ylim) # 設置y軸范圍(如 [0, 10])(如果提供)axes.set_xscale(xscale) # 設置x軸刻度類型(線性linear或對數log)axes.set_yscale(yscale) # 設置y軸刻度類型(線性linear或對數log)if legend: axes.legend(legend) # 添加圖例文本列表(如 ['train', 'test'])(如果提供)axes.grid(True) # 顯示背景網格線,提升可讀性# 繪圖函數
def plot(X, Y=None, xlabel=None, ylabel=None, legend=None,xlim=None, ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:', 'c-.', 'y-', 'k:'), figsize=(5, 2.5), axes=None):"""繪制數據點"""if legend is None: legend = [] # 默認圖例為空列表(避免后續判斷報錯)# 創建畫布(如果未提供外部axes)plt.figure(figsize=figsize)axes = axes if axes is not None else plt.gca() # 獲取當前軸# 如果X有一個軸,輸出True。判斷輸入數據是否為一維(列表或一維數組)def has_one_axis(X):return (hasattr(X, "ndim") and X.ndim == 1 or isinstance(X, list)and not hasattr(X[0], "__len__"))# 標準化X和Y的形狀:確保X和Y都是列表的列表(支持多條曲線)if has_one_axis(X):X = [X] # 將一維X轉換為二維(單條曲線)if Y is None: # 如果未提供Y,則X是Y的值,X軸為索引(如 plot(y))X, Y = [[]] * len(X), Xelif has_one_axis(Y):Y = [Y] # 將一維Y轉換為二維if len(X) != len(Y): # 如果X和Y數量不匹配,復制X以匹配Y的數量X = X * len(Y)axes.clear() # 清空當前軸(避免重疊繪圖)for x, y, fmt in zip(X, Y, fmts):if len(x): axes.plot(x, y, fmt) # 如果提供了x和y,繪制xy曲線else: axes.plot(y, fmt) # 如果未提供x,繪制y關于索引的曲線(如 plot(y))set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend) # 設置軸屬性# 自動調整布局并顯示圖像plt.tight_layout() # 自動調整子圖參數,使之填充整個圖像區域,防止標簽溢出plt.show()使用示例:
T = 1000 # 總共產生1000個點
time = torch.arange(1, T + 1, dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))
common.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3))freqs = [freq for token, freq in vocab.token_freqs] # 詞頻(降序)
# 對比 三種模型中的詞元頻率:一元語法、二元語法和三元語法
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
common.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',ylabel='frequency: n(x)', xscale='log', yscale='log',legend=['unigram', 'bigram', 'trigram'])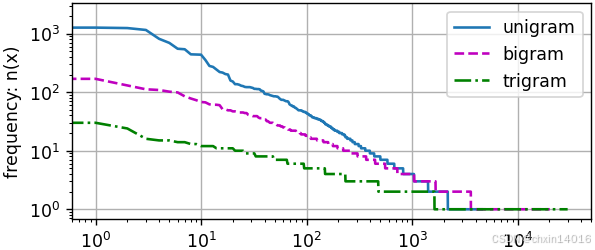
函數:加載數據集 load_array
from torch.utils.data import DataLoader, TensorDataset
import torchdef load_array(data_arrays, batch_size, is_train=True):dataset = TensorDataset(*data_arrays)return DataLoader(dataset, batch_size, shuffle=is_train)使用示例:
train_iter = common.load_array((train_features, train_labels.reshape(-1,1)),batch_size) # 將數據加載為可迭代的批量數據test_iter = common.load_array((test_features, test_labels.reshape(-1,1)),batch_size, is_train=False) # is_train=False表示測試集不需要打亂數據函數:自定義優化算法 sgd
# 定義優化算法
'''
# 實現小批量隨機梯度下降(Stochastic Gradient Descent, SGD)優化算法params: 需更新的參數列表。通常為神經網絡的可訓練權重w和偏置blr: 學習率(learning rate),是一個標量,用于控制每次參數更新的步長
batch_size: 批量大小,用于調整梯度更新的幅度
'''
def sgd(params, lr, batch_size): #@save"""小批量隨機梯度下降"""with torch.no_grad(): # 禁用梯度計算,所有的操作都不會被記錄到計算圖中,因此不會影響自動微分的過程。參數更新操作時必須的,因為參數更新本身不應該被微分for param in params:# 計算參數更新的步長, /batch_size 是為了對小批量數據的梯度進行平均param -= lr * param.grad / batch_size # (param -= ...是將計算出的更新步長應用到參數上,從而更新參數)param.grad.zero_() # 將參數的梯度手動清零(因為梯度是累積的,以免影響下一次的梯度計算)sgd([w, b], lr, batch_size) # 使用參數的梯度更新參數 # 具體使用見線性回歸的從0開始實現
sgd(net.params, lr, batch_size) # 具體使用見train_ch8函數定義函數:預測函數—生成prefix之后的新字符?predict_ch8
# 預測函數:生成prefix之后的新字符
def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device) # 初始化隱藏狀態,批量大小為1 (單序列預測)# 將prefix的第一個字符轉換為索引# prefix[0]第一個字符,vocab[prefix[0]]獲取第一個字符的索引outputs = [vocab[prefix[0]]] # 存儲生成的索引(用列表存儲)# 輔助函數:獲取當前輸入 (形狀為 (1, 1))# [outputs[-1]]獲取索引列表中的最后一個,即 剛剛存進去的那個,也就是當前個get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))# 預熱期:處理前綴中的剩余字符# 模型自我更新(例如,更新隱狀態),但不進行預測for y in prefix[1:]: # 遍歷前綴中除第一個字符外的所有字符_, state = net(get_input(), state) # 前向傳播(忽略輸出,只更新隱藏狀態)(把類當作函數使用,調用__call__)outputs.append(vocab[y]) # 將當前字符添加到輸出列表# 預測階段:生成新字符,預測num_preds步# 預熱期結束后,隱狀態的值比剛開始的初始值更適合預測,現在開始預測字符并輸出for _ in range(num_preds): # 預測指定數量的字符# y 形狀為 (1, vocab_size)(批量大小=1)y, state = net(get_input(), state) # 前向傳播,獲取預測輸出# argmax(dim=1) 獲取概率最高的詞索引# int(y.argmax(dim=1).reshape(1)) 轉換為 Python整數pred_idx = int(y.argmax(dim=1).reshape(1)) # 從輸出中選擇概率最高的索引outputs.append(pred_idx) # 將預測索引添加到輸出列表# 將索引序列 轉換回 字符序列# ''.join(...)將字符列表中的所有字符串(每個字符是一個長度為1的字符串)連接成一個字符串return ''.join([vocab.idx_to_token[i] for i in outputs])print(f"未訓練網絡的情況下,測試函數基于time traveller這個前綴生成10個后續字符:\n"f"{common.predict_ch8('time traveller ', 10, net, vocab, common.try_gpu())}")# 具體使用見train_ch8函數定義 ↓# 4. 定義預測函數,用于生成 以給定前綴開頭的文本(生成50個字符)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device) # 設置預測函數函數:計算正確預測數?accuracy
def accuracy(y_hat, y): # @save"""計算預測正確的數量"""# len是查看矩陣的行數# y_hat.shape[1]就是取列數if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:# 第2個維度為預測標簽,取最大元素y_hat = y_hat.argmax(axis=1) # 變成一列,列中每行元素為 行里的最大值下標# 將y_hat轉換為y的數據類型然后作比較,cmp函數存儲bool類型cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum()) # 將正確預測的數量相加使用示例:?單周期訓練函數中有調用該函數。
函數:單周期訓練 train_epoch_ch3
def train_epoch_ch3(net, train_iter, loss, updater): # @save"""訓練模型一個迭代周期(定義見第3章)"""# 判斷net模型是否為深度學習類型,將模型設置為訓練模式if isinstance(net, torch.nn.Module):net.train() # 要計算梯度,啟用訓練模式(啟用Dropout/BatchNorm等訓練專用層)# Accumulator(3)創建3個變量:訓練損失總和、訓練準確度總和、樣本數metric = Accumulator(3) # 用于跟蹤訓練損失、準確率和樣本數for X, y in train_iter:# 計算梯度并更新參數y_hat = net(X) # 前向傳播:模型預測l = loss(y_hat, y) # 計算損失(向量形式,每個樣本一個損失值)# 判斷updater是否為優化器if isinstance(updater, torch.optim.Optimizer): # 使用PyTorch內置優化器# 使用PyTorch內置的優化器和損失函數updater.zero_grad() # 把梯度設置為0(清除之前的梯度,避免梯度累加)l.mean().backward() # 計算梯度(反向傳播:計算梯度(對損失取平均))l.mean()表示對批次損失取平均后再求梯度updater.step() # 自更新(根據梯度更新模型參數)else: # 使用自定義更新邏輯# 使用定制的優化器和損失函數# 自我實現的話,l出來是向量,先求和再求梯度l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回訓練損失(平均損失)和訓練精度,metric的值由Accumulator得到return metric[0] / metric[2], metric[1] / metric[2]使用示例: 繪制器類調用示例中已包含該函數調用。?
函數:梯度裁剪?grad_clipping
''' 梯度裁剪,目的:
防止梯度爆炸
穩定訓練過程
特別適合 RNN 這類容易出現梯度問題的模型
'''
def grad_clipping(net, theta): #@save"""裁剪梯度"""# 獲取需要梯度的參數if isinstance(net, nn.Module): # PyTorch 模塊:獲取所有可訓練參數params = [p for p in net.parameters() if p.requires_grad]else: # 自定義模型:使用模型自帶的參數列表params = net.params# 計算所有參數的 梯度的 L2 范數norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta: # 如果范數超過閾值θ,進行裁剪(將所有梯度按比例縮放)for param in params: # 保持梯度方向不變,只縮小幅度param.grad[:] *= theta / norm # 按比例縮放梯度grad_clipping(net, 1) # 梯度裁剪,具體使用見train_epoch_ch8函數定義函數:單迭代周期訓練—用困惑度做評估指標 train_epoch_ch8
# 單迭代周期訓練,以困惑度(Perplexity)作為評估指標
# 返回困惑度 和 訓練速度(每秒處理的詞元數量,用于衡量訓練效率)
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""訓練網絡一個迭代周期(定義見第8章)"""state, timer = None, Timer() # 初始化狀態和計時器metric = Accumulator(2) # 訓練損失之和,詞元數量[loss_sum, token_count]for X, Y in train_iter: # 遍歷數據批次# 狀態初始化:如果是第一次迭代 或 使用隨機抽樣if state is None or use_random_iter:# 在第一次迭代 或 使用隨機抽樣時初始化state (創建全零的初始隱藏狀態)state = net.begin_state(batch_size=X.shape[0], device=device)else:# 否則,分離狀態,斷開與歷史計算圖的連接,即 斷開計算圖(防止梯度傳播到前一批次)# 訓練循環中,對于非隨機抽樣(即順序抽樣),# 希望狀態能跨批次傳遞,但又不希望梯度從當前批次反向傳播到前一批次# (因為那樣會導致計算圖非常長,占用大量內存且可能梯度爆炸)。# 因此每次迭代開始時,需要將狀態從計算圖中分離出來if isinstance(net, nn.Module) and not isinstance(state, tuple):# 如果net是PyTorch模塊,且狀態非元組(例如GRU,它的狀態是一個張量)# state對于nn.GRU是個張量state.detach_() # 用detach_()斷開 狀態與歷史計算圖 的連接(對張量進行原地分離操作)else:# 若狀態是元組(例如LSTM的狀態是兩個張量,或者自定義的模型狀態可能是元組)# state對于nn.LSTM 或 對于從零開始實現的模型 是個張量# LSTM 狀態 或 自定義模型狀態是元組for s in state:s.detach_()# 準備數據:轉置標簽并展平# 先轉置再展平 是為了 讓標簽的順序與模型輸出的順序一致,從而正確計算損失# Y 原始形狀: (batch_size, num_steps)# 轉置后: (num_steps, batch_size); 展平后: (num_steps * batch_size)# 與 y_hat 形狀 (num_steps * batch_size, vocab_size) 匹配y = Y.T.reshape(-1) # 形狀: (num_steps * batch_size)X, y = X.to(device), y.to(device) # 將數據轉移到設備y_hat, state = net(X, state) # 前向傳播l = loss(y_hat, y.long()).mean() # 計算每個詞元的損失后取平均=對整個批次的加權平均# 反向傳播if isinstance(updater, torch.optim.Optimizer):updater.zero_grad() # PyTorch 優化器l.backward()grad_clipping(net, 1) # 梯度裁剪updater.step()else: # 自定義優化器l.backward()grad_clipping(net, 1)# 因為已經調用了mean函數updater(batch_size=1) # 因為損失已經取平均,batch_size=1metric.add(l * y.numel(), y.numel()) # 累積指標:損失 * 詞元數,詞元數perplexity = math.exp(metric[0] / metric[1]) # 計算困惑度 = exp(平均損失)speed = metric[1] / timer.stop() # 計算訓練速度 = 詞元數/秒return perplexity, speed# 具體使用見train_ch8函數定義 ↓# 5. 主訓練循環:訓練和預測for epoch in range(num_epochs):# 5.1 訓練一個epoch,返回困惑度(ppl)和訓練速度(speed)(每秒處理多少個詞元)# speed 表示每秒處理的詞元數量,用于衡量訓練效率ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)# 5.2 每10個epoch進行一次評估和可視化if (epoch + 1) % 10 == 0: # 每10個epochprint(predict('time traveller')) # 使用前綴'time traveller'生成文本并打印animator.add(epoch + 1, [ppl]) # 將當前epoch的困惑度添加到動畫中函數:精度評估 evaluate_accuracy
def evaluate_accuracy(net, data_iter): # @save"""計算在指定數據集上模型的精度"""if isinstance(net, torch.nn.Module): # 判斷模型是否為深度學習模型net.eval() # 將模型設置為評估模式# Accumulator(2)創建2個變量:正確預測的樣本數總和、樣本數metric = Accumulator(2) # metric:度量,累加正確預測數、預測總數with torch.no_grad(): # 梯度不需要反向傳播for X, y in data_iter: # 每次從迭代器中拿出一個X和y# net(X):X放在net模型中進行softmax操作# numel()函數:返回數組中元素的個數,在此可以求得樣本數metric.add(accuracy(net(X), y), y.numel())# metric[0, 1]分別為網絡預測正確數量和總預測數量return metric[0] / metric[1]函數:精度評估GPU版?evaluate_accuracy_gpu
"""
# 評估函數定義精度評估函數:1、將數據集復制到顯存中2、通過調用accuracy計算數據集的精度
"""
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save"""使用GPU計算模型在數據集上的精度"""if isinstance(net, nn.Module): # 判斷net是否屬于torch.nn.Module類(模型是否為深度學習模型)net.eval() # 設置為評估模式(關閉Dropout和BatchNorm的隨機性)if not device: # 如果沒有指定設備,自動使用模型參數所在的設備(如GPU)device = next(iter(net.parameters())).device # 自動檢測設備# 初始化計數器:累計 正確預測的數量 和 總預測的數量metric = Accumulator(2) # metric[0]=正確數, metric[1]=總數with torch.no_grad(): # 禁用梯度計算(加速評估并減少內存占用)for X, y in data_iter: # 每次從迭代器中拿出一個X和y# 將數據X,y移動到指定設備(如GPU)if isinstance(X, list):# BERT微調所需的(之后將介紹)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)# 計算預測值和準確率,并累加到metric中metric.add(accuracy(net(X), y), y.numel()) # 累加準確率和樣本數# metric[0, 1]分別為網絡預測正確數量和總預測數量return metric[0] / metric[1] # 計算準確率使用示例: 用GPU訓練模型函數中已包含該函數調用。
函數:用GPU訓練模型 train_ch6
"""定義GPU訓練函數:1、為了使用gpu,首先需要將每一小批量數據移動到指定的設備(例如GPU)上;2、使用Xavier隨機初始化模型參數;3、使用交叉熵損失函數和小批量隨機梯度下降。
"""
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU訓練模型(在第六章定義)"""def init_weights(m): # 定義初始化參數,對線性層和卷積層生效if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight) # Xavier初始化,保持輸入輸出的方差穩定net.apply(init_weights) # 應用初始化到整個網絡(初始化權重)# 在設備device上進行訓練print('training on', device)net.to(device) # 模型移至指定設備(如GPU)optimizer = torch.optim.SGD(net.parameters(), lr=lr) # 定義優化器:隨機梯度下降(SGD),學習率為lrloss = nn.CrossEntropyLoss() # 交叉熵損失# 初始化動畫繪圖器,用于動態繪制訓練曲線animator = Animator(xlabel='epoch',xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])# 初始化計時器和計算總批次數timer, num_batches = Timer(), len(train_iter) # 調用Timer函數統計時間# 開始訓練循環for epoch in range(num_epochs):# Accumulator(3)創建3個變量:訓練損失總和、訓練準確度總和、樣本數metric = Accumulator(3) # 用于跟蹤訓練損失、準確率和樣本數net.train() # 切換到訓練模式(啟用Dropout和BatchNorm的訓練行為)for i, (X, y) in enumerate(train_iter):timer.start() # 開始計時optimizer.zero_grad() # 清空梯度X, y = X.to(device), y.to(device) # 將數據移動到設備y_hat = net(X) # 前向傳播:模型預測l = loss(y_hat, y) # 計算損失(向量形式,每個樣本一個損失值)l.backward() # 反向傳播計算梯度optimizer.step() # 更新參數with torch.no_grad(): # 禁用梯度計算后累計指標metric.add(l * X.shape[0], accuracy(y_hat, y), X.shape[0])timer.stop() # 停止計時train_l = metric[0] / metric[2] # 平均訓練損失train_acc = metric[1] / metric[2] # 平均訓練準確率# 每訓練完1/5的epoch 或 最后一個batch時,更新訓練曲線if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))# 測試精度test_acc = evaluate_accuracy_gpu(net, test_iter) # 測試集準確率animator.add(epoch + 1, (None, None, test_acc)) # 更新測試集準確率曲線print(f'最終結果:loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}') # 輸出損失值、訓練精度、測試精度print(f'訓練速度(樣本數/總時間):{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}') # 設備的計算能力
lr, num_epochs = 0.9, 10 # 學習率,訓練輪數(訓練10輪)
train_ch6(net, train_iter, test_iter, num_epochs, lr, common.try_gpu())函數:訓練字符級循環神經網絡模型?train_ch8
''' 訓練一個 字符級循環神經網絡(RNN)模型
包含了訓練循環、梯度裁剪、困惑度計算和文本生成預測
net : 要訓練的RNN模型(可以是PyTorch模塊或自定義模型)
train_iter : 訓練數據迭代器
vocab : 詞匯表對象,用于索引和字符之間的轉換
lr : 學習率
num_epochs : 訓練的總輪數
device : 訓練設備(CPU或GPU)
use_random_iter : 是否使用隨機采樣(否則使用順序分區)
'''
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):"""訓練模型(定義見第8章)"""# 1. 初始化損失函數loss = nn.CrossEntropyLoss() # 使用交叉熵損失# 2. 初始化可視化工具:初始化動畫器,用于繪制訓練過程中的困惑度變化animator = Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 3. 初始化優化器:根據net的類型選擇不同的優化器if isinstance(net, nn.Module): # 如果是PyTorch模塊,使用SGD優化器updater = torch.optim.SGD(net.parameters(), lr) # 則使用PyTorch的SGD優化器else: # 如果是自定義模型,使用自定義的SGD優化器# 注意:這里的sgd函數需要三個參數:參數列表、學習率和批量大小(通過閉包捕獲net.params和lr)# lambda batch_size: sgd(...) 創建閉包函數# 固定學習率 lr,動態傳入 batch_sizeupdater = lambda batch_size: sgd(net.params, lr, batch_size)# 4. 定義預測函數,用于生成 以給定前綴開頭的文本(生成50個字符)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device) # 設置預測函數# 5. 主訓練循環:訓練和預測for epoch in range(num_epochs):# 5.1 訓練一個epoch,返回困惑度(ppl)和訓練速度(speed)(每秒處理多少個詞元)# speed 表示每秒處理的詞元數量,用于衡量訓練效率ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)# 5.2 每10個epoch進行一次評估和可視化if (epoch + 1) % 10 == 0: # 每10個epochprint(predict('time traveller')) # 使用前綴'time traveller'生成文本并打印animator.add(epoch + 1, [ppl]) # 將當前epoch的困惑度添加到動畫中# 6. 訓練結束后的最終評估:打印最終的困惑度和速度# 困惑度:語言模型質量指標(越低越好)# 處理速度:每秒處理的詞元數量print(f'困惑度 {ppl:.1f}, {speed:.1f} 詞元/秒 {str(device)}')# 使用兩個不同的前綴生成文本print(predict('time traveller'))print(predict('traveller'))num_epochs, lr = 500, 1 # 迭代周期為500,即訓練500輪;學習率為1
common.train_ch8(net, train_iter, vocab, lr, num_epochs, common.try_gpu())# 重新初始化一個RNN模型
net = RNNModelScratch(len(vocab), num_hiddens, common.try_gpu(), get_params,init_rnn_state, rnn)
# 使用隨機抽樣訓練模型
common.train_ch8(net, train_iter, vocab, lr, num_epochs, common.try_gpu(),use_random_iter=True)函數:加載文本數據《time_machine》read_time_machine
'''
加載文本數據
# 下載器與數據集配置
# 為 time_machine 數據集注冊下載信息,包括文件路徑和校驗哈希值(用于驗證文件完整性)
downloader = common.C_Downloader()
DATA_HUB = downloader.DATA_HUB # 字典,存儲數據集名稱與下載信息
DATA_URL = downloader.DATA_URL # 基礎URL,指向數據集的存儲位置
DATA_HUB['time_machine'] = (DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')
'''
def read_time_machine(downloader): #@save"""將時間機器數據集加載到文本行的列表中"""# 通過 downloader.download('time_machine') 獲取文件路徑with open(downloader.download('time_machine'), 'r') as f:lines = f.readlines() # 逐行讀取文本文件# 用正則表達式 [^A-Za-z]+ 替換所有非字母字符為空格# 調用 strip() 去除首尾空格,lower() 轉換為小寫# 返回值:處理后的文本行列表(每行是純字母組成的字符串)return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]lines = common.read_time_machine(downloader)
print(f'# 文本總行數: {len(lines)}')
print(lines[0]) # 第1行內容
print(lines[10]) # 第11行內容tokens = common.tokenize(common.read_time_machine(downloader))
# 因為每個文本行不一定是一個句子或一個段落,因此我們把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = common.Vocab(corpus)
print(f"前10個最常用的(頻率最高的)單詞:\n{vocab.token_freqs[:10]}")函數:詞元化 (按單詞或字符拆分文本) tokenize
# 詞元化函數:支持按單詞或字符拆分文本
# lines:預處理后的文本行列表
# token:詞元類型,可選 'word'(默認)或 'char
# 返回值:嵌套列表,每行對應一個詞元列表
def tokenize(lines, token='word'): #@save"""將文本行拆分為單詞或字符詞元"""if token == 'word':return [line.split() for line in lines] # 按空格分詞elif token == 'char':return [list(line) for line in lines] # 按字符拆分else:print('錯誤:未知詞元類型:' + token)tokens = common.tokenize(lines)
for i in range(11):print(f"第{i}行:{tokens[i]}")函數:獲取《time_machine》的詞元索引序列和詞表對象load_corpus_time_machine
# 獲取《時光機器》的 詞元索引序列和詞表對象
# max_tokens:限制返回的詞元索引序列的最大長度(默認 -1 表示不限制)
def load_corpus_time_machine(downloader, max_tokens=-1): #@save"""返回時光機器數據集的詞元索引列表和詞表"""lines = read_time_machine(downloader) # 加載文本數據,得到文本行列表tokens = tokenize(lines, 'char') # 詞元化:文本行列表→詞元列表,按字符級拆分vocab = Vocab(tokens) # 構建詞表# 因為時光機器數據集中的每個文本行不一定是一個句子或一個段落,# 所以將所有文本行展平到一個列表中# vocab[token] 查詢詞元的索引(若詞元不存在,則返回0,即未知詞索引)# corpus:list,每個元素為詞元的對應索引corpus = [vocab[token] for line in tokens for token in line] # 展平詞元并轉換為索引if max_tokens > 0: # 限制詞元序列長度corpus = corpus[:max_tokens] # 截斷 corpus 到前 max_tokens 個詞元# corpus:詞元索引列表(如 [1, 2, 3, ...])# vocab:Vocab對象,用于管理詞元與索引的映射return corpus, vocabcorpus, vocab = common.load_corpus_time_machine(downloader) # 加載數據
print(f"corpus詞元索引列表的長度:{len(corpus)}")
print(f"詞表大小:{len(vocab)}")
print(f"詞頻統計(降序):\n{vocab.token_freqs}")
# 索引 ? 詞元轉換
print(f"前10個索引對應的詞元:\n{vocab.to_tokens(corpus[:10])}")
print(f"前10個詞元對應的索引:\n{corpus[:10]}")
print(f"前10個詞元對應的索引:\n{[idx for idx in corpus[:10]]}")函數:【隨機采樣】(數據生成器) seq_data_iter_random
# 數據生成器:【隨機采樣】從長序列中隨機抽取子序列,生成小批量數據
# batch_size:指定每個小批量中子序列樣本的數目
# num_steps:每個子序列中預定義的時間步數(每個子序列長度)
def seq_data_iter_random(corpus, batch_size, num_steps): #@save"""使用隨機抽樣生成一個小批量子序列"""# 從隨機偏移量開始對序列進行分區,隨機范圍包括num_steps-1# 隨機范圍若超過[0,num_steps-1],則從num_steps開始,往后都會與已有的重復,且少了開頭的部分子序列# random.randint(0, num_steps-1) 生成一個隨機整數offset,范圍是[0, num_steps-1]# corpus[random.randint(0, num_steps - 1):]截取從該偏移量到序列末尾的子序列corpus = corpus[random.randint(0, num_steps - 1):] # 隨機偏移起始位置# 減去1,是因為需要考慮標簽,標簽是右移一位的序列num_subseqs = (len(corpus) - 1) // num_steps # 總可用 子序列數# 生成隨機起始索引:長度為num_steps 的子序列 的起始索引initial_indices = list(range(0, num_subseqs * num_steps, num_steps)) # 起始索引列表# 在隨機抽樣的迭代過程中,來自兩個相鄰的、隨機的、小批量中的子序列不一定在原始序列上相鄰random.shuffle(initial_indices) # 隨機打亂順序def data(pos): # 返回從pos位置開始的長度為num_steps的序列return corpus[pos: pos + num_steps]# 序列長度35,時間步數5,則最多可有(35-1)/5=34/5=6個子序列# 批量大小2,則可生成批量數=6個子序列/批量大小2=3個小批量num_batches = num_subseqs // batch_size # 可生成的小批量數=總可用子序列數÷批量大小# 構造小批量數據(每次取batch_size個隨機起始索引,生成輸入X和標簽Y)# i就是 當前批量在 總子序列中的第幾批開頭位置# 從已有的 打亂好的 起始索引list中,選出當前批量對應的那個下標位置上 的起始索引for i in range(0, batch_size * num_batches, batch_size):# 在這里,initial_indices包含子序列的隨機起始索引initial_indices_per_batch = initial_indices[i: i + batch_size] # 每批次對應的起始索引X = [data(j) for j in initial_indices_per_batch] # 輸入子序列Y = [data(j + 1) for j in initial_indices_per_batch] # 標簽(右移一位)yield torch.tensor(X), torch.tensor(Y) # 使用yield實現生成器,節省內存my_seq = list(range(35)) # 生成一個從0到34的序列
# 批量大小為2,時間步數為5
for idx, (X, Y) in enumerate(common.seq_data_iter_random(my_seq, batch_size=2, num_steps=5)):print(f" 隨機取樣 —————— idx={idx} —————— \n"f"X: {X}\nY:{Y}")函數:【順序分區】(數據生成器) seq_data_iter_sequential
# 數據生成器:【順序分區】按順序劃分長序列,生成小批量數據,保證完整覆蓋序列
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save"""使用順序分區生成一個小批量子序列"""# 從隨機偏移量開始劃分序列offset = random.randint(0, num_steps) # 隨機偏移起始位置# 確保能整除 batch_size,避免最后一個小批量不足# (len(corpus) - offset - 1) 起始位置偏移后,剩余右側 所需的最少長度num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size # 有效詞元數# 重構為批量優先格式:將序列重塑為 (batch_size批量大小, sequence_length序列長度) 的張量,便于批量處理# sequence_length序列長度:每個樣本(序列)的時間步數(或詞元數)Xs = torch.tensor(corpus[offset: offset + num_tokens]) # 截取有效詞元區域,這里得到的向量形式的張量Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens]) # 可作為標簽的有效詞元區域# 重塑張量形狀,每列皆為一個批量,每行皆為單批量的序列長度 即總詞元數大小Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)num_batches = Xs.shape[1] // num_steps # 批量數=/每個小批量的時間步數 即序列長度# 按步長分割小批量:沿序列長度維度(axis=1)滑動窗口,生成連續的小批量# 將單次批量的總序列大小分割為多個子序列for i in range(0, num_steps * num_batches, num_steps):# 從第i列開始,取num_steps列X = Xs[:, i: i + num_steps] # 輸入子序列Y = Ys[:, i: i + num_steps] # 標簽yield X, Y # 使用yield實現生成器my_seq = list(range(35)) # 生成一個從0到34的序列
for idx, (X, Y) in enumerate(common.seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5)):print(f" 順序分區 —————— idx={idx} —————— \n"f"X: {X}\nY:{Y}")函數:數據加載load_data_time_machine,同時返回數據迭代器和詞表
'''
數據加載函數:同時返回數據迭代器和詞表
batch_size :每小批量的子序列數量
num_steps :每個子序列的時間步數(詞元數)
use_random_iter:是否使用隨機采樣(默認順序分區)
max_tokens :限制語料庫的最大詞元數返回值
data_iter:SeqDataLoader 實例(可迭代)
vocab :詞表對象(用于詞元與索引的映射)
'''
def load_data_time_machine(downloader, batch_size, num_steps, #@saveuse_random_iter=False, max_tokens=10000):"""返回時光機器數據集的迭代器和詞表"""data_iter = SeqDataLoader(downloader, batch_size, num_steps, use_random_iter, max_tokens)return data_iter, data_iter.vocabbatch_size, num_steps = 32, 35 # 每個小批量包含32個子序列,每個子序列的詞元數為35
train_iter, vocab = common.load_data_time_machine(downloader, batch_size, num_steps) # 詞表對象?函數:
計時器類?Timer
可用于進行 運行時間的基準測試
import time
import numpy as npclass Timer: # @save"""記錄多次運行時間"""def __init__(self):self.times = []self.start()def start(self):"""啟動計時器"""self.tik = time.time()def stop(self):"""停止計時器并將時間記錄在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def avg(self):"""返回平均時間"""return sum(self.times) / len(self.times)def sum(self):"""返回時間總和"""return sum(self.times)def cumsum(self):"""返回累計時間"""return np.array(self.times).cumsum().tolist()?使用示例:
from common import Timer
import torch# 實例化兩個全為1的10000維向量
n = 10000
a = torch.ones([n])
b = torch.ones([n])# 開始對工作負載進行基準測試
c = torch.zeros(n)
timer = Timer()for i in range(n):c[i] = a[i] + b[i]
print(f"方法一:使用循環遍歷向量,耗時:{timer.stop():.5f} sec")timer.start()
d = a + b
print(f"方法二:使用重載的+運算符來計算按元素的和,耗時:{timer.stop():.5f} sec")累加器類:記錄正確預測數和預測總數?Accumulator
定義一個實用程序類Accumulator,用于對多個變量進行累加,Accumulator實例中創建了2個變量, 分別用于存儲正確預測的數量和預測的總數量。
__init__():創建一個類,初始化類實例時就會自動執行__init__()方法。該方法的第一個參數為self,表示的就是類的實例。self后面跟隨的其他參數就是創建類實例時要傳入的參數。zip():將多個可迭代對象作為參數,依次將對象中對應的元素打包成一個個元組,然后返回由這些元組組成的對象,里面的每個元素大概為(self.data,? args)的形式。reset();重新設置空間大小并初始化。__getitem__():接收一個idx參數,這個參數就是自己給的索引值,返回self.data[idx],實現類似數組的取操作。
# 實用程序類,示例中創建兩個變量:正確預測的數量 和 預測總數
class Accumulator: # @save"""在n個變量上累加"""# 初始化根據傳進來n的大小來創建n個空間,全部初始化為0.0def __init__(self, n):self.data = [0.0] * n# 把原來類中對應位置的data和新傳入的args做a + float(b)加法操作然后重新賦給該位置的data,從而達到累加器的累加效果def add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]# 重新設置空間大小并初始化。def reset(self):self.data = [0.0] * len(self.data)# 實現類似數組的取操作def __getitem__(self, idx):return self.data[idx]使用示例:
def evaluate_accuracy(net, data_iter): #@save"""計算在指定數據集上模型的精度"""if isinstance(net, torch.nn.Module): # 判斷模型是否為深度學習模型net.eval() # 將模型設置為評估模式# Accumulator(2)創建2個變量:正確預測的樣本數總和、樣本數metric = Accumulator(2) # metric:度量,累加正確預測數、預測總數with torch.no_grad(): # 梯度不需要反向傳播for X, y in data_iter: # 每次從迭代器中拿出一個X和y# net(X):X放在net模型中進行softmax操作# numel()函數:返回數組中元素的個數,在此可以求得樣本數metric.add(accuracy(net(X), y), y.numel()) # metric[0, 1]分別為網絡預測正確數量和總預測數量return metric[0] / metric[1]?繪制器類:動態繪制數據?Animator
from IPython import display# import matplotlib
# # 強制使用 TkAgg 或 Qt5Agg 后端 (使用獨立后端渲染)
# matplotlib.use('TkAgg') # 或者使用 'Qt5Agg',根據你的系統安裝情況
# # matplotlib.use('Qt5Agg') # 或者使用 'Qt5Agg',根據你的系統安裝情況
import matplotlib.pyplot as plt# 實用程序類,動畫繪制器,動態繪制數據
class Animator: # @save"""在動畫中繪制數據"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地繪制多條線if legend is None:legend = []# 創建圖形和坐標軸self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ] # 確保axes是列表形式(即使只有1個子圖)# 設置坐標軸配置的函數def set_axes(ax, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):ax.set_xlabel(xlabel)ax.set_ylabel(ylabel)if xlim:ax.set_xlim(xlim)if ylim:ax.set_ylim(ylim)ax.set_xscale(xscale)ax.set_yscale(yscale)if legend:ax.legend(legend)ax.grid()# 使用lambda函數捕獲參數self.config_axes = lambda: [set_axes(ax, xlabel, ylabel, xlim, ylim,xscale, yscale, legend) for ax in self.axes]self.X, self.Y, self.fmts = None, None, fmtsplt.ion() # 開啟交互模式,使圖形可以實時更新def add(self, x, y):# 向圖表中添加多個數據點# x: x值或x值列表# y: y值或y值列表# hasattr(y, "__len__"):檢查 y 是否為多值(如列表或數組)if not hasattr(y, "__len__"):y = [y] # 如果y不是列表/數組,轉換為單元素列表n = len(y)if not hasattr(x, "__len__"):x = [x] * n # 如果x是標量,擴展為與y長度相同的列表if not self.X:self.X = [[] for _ in range(n)] # 初始化n條曲線的x數據存儲if not self.Y:self.Y = [[] for _ in range(n)] # 初始化n條曲線的y數據存儲for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a) # 添加x數據self.Y[i].append(b) # 添加y數據for ax in self.axes: # 清除并重新繪制所有子圖ax.cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):for ax in self.axes:ax.plot(x, y, fmt) # 重新繪制所有曲線self.config_axes()self.fig.canvas.draw() # 更新畫布self.fig.canvas.flush_events() # 刷新事件time.sleep(0.1) # 添加短暫延遲以模擬動畫效果plt.show() # pycharm社區版沒有科學模塊,通過在循環里show來實現動畫效果def close(self):"""關閉圖形"""plt.ioff() # 關閉交互模式plt.close(self.fig)使用示例:(完整版調用在 學習多層感知機的多項式回歸 的訓練函數中,詳情:動手學深度學習——多層感知機實現-CSDN博客)
# 繪制訓練過程中的損失曲線animator = common.Animator(xlabel='epoch', ylabel='loss', yscale='log', # yscale='log':使用對數刻度顯示損失值xlim=[1, num_epochs], ylim=[1e-3, 1e2], # 設置坐標軸范圍legend=['train', 'test']) # 圖例標簽for epoch in range(num_epochs): # 循環訓練common.train_epoch_ch3(net, train_iter, loss, trainer)if epoch == 0 or (epoch + 1) % 20 == 0:animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),evaluate_loss(net, test_iter, loss)))plt.show() # pycharm社區版沒有科學模塊,通過在循環里show來實現動畫效果animator.close() # 最后記得關閉圖形下載器類:下載和緩存數據集?C_Downloader
import hashlib
import os
import tarfile
import zipfile
import requests3個功能函數:
- download:下載數據集,將數據集緩存在本地目錄(默認為../data)中,并返回下載文件的名稱(數據集只是表格格式可直接調用)
- download_extract:下載并解壓一個zip或tar文件
- download_all:將使用的所有數據集從DATA_HUB下載到緩存目錄中
# 下載器類:下載和緩存數據集
class C_Downloader:def __init__(self, data_url = 'http://d2l-data.s3-accelerate.amazonaws.com/'):# DATA_HUB字典,將數據集名稱的字符串映射到數據集相關的二元組上# DATA_HUB為二元組:包含數據集的url和驗證文件完整性的sha-1密鑰self.DATA_HUB = dict()self.DATA_URL = data_url # 數據集托管在地址為DATA_URL的站點上''' download下載數據集,將數據集緩存在本地目錄(默認為../data)中,并返回下載文件的名稱若緩存目錄中已存在此數據集文件,且其sha-1與存儲在DATA_HUB中的相匹配,則使用緩存的文件,以避免重復的下載name:要下載的文件名,必須在DATA_HUB中存在cache_dir:緩存目錄,默認為../datasha-1:安全散列算法1'''def download(self, name, cache_dir=os.path.join('..', 'data')): # @save"""下載一個DATA_HUB中的文件,返回本地文件名"""# 檢查指定的文件名是否存在于DATA_HUB中# 如果不存在,則拋出斷言錯誤,提示用戶該文件不存在# 斷言檢查:確保name在DATA_HUB中存在,避免下載不存在的文件assert name in self.DATA_HUB, f"{name} 不存在于 {self.DATA_HUB}"url, sha1_hash = self.DATA_HUB[name] # 從DATA_HUB中獲取該文件的URL和SHA-1哈希值# 若目錄不存在,則創建目錄# exist_ok=True:若目錄已存在,也不會拋出錯誤os.makedirs(cache_dir, exist_ok=True)# 構建本地文件路徑# 從URL中提取文件名(通過分割URL字符串獲取最后一個部分)# 并將該文件名與緩存目錄組合成完整的本地文件路徑fname = os.path.join(cache_dir, url.split('/')[-1])if os.path.exists(fname): # 檢查本地文件是否已存在sha1 = hashlib.sha1() # 計算本地文件的SHA-1哈希值(shal.sha1():創建一個字符串hashlib_,并將其加密后傳入)with open(fname, 'rb') as f:# 讀取文件內容,每次讀取1MB的數據塊,以避免大文件占用過多內存while True:data = f.read(1048576) # 1048576 bytes = 1MBif not data:breaksha1.update(data) # 更新哈希值# 比較計算出的哈希值與DATA_HUB中存儲的哈希值if sha1.hexdigest() == sha1_hash:# 若哈希值匹配,說明文件完整且未被篡改,直接返回本地文件路徑(命中緩存)return fname # 命中緩存# 如果本地文件不存在或哈希值不匹配,則從URL下載文件print(f'正在從{url}下載{fname}...')# 使用requests庫發起HTTP GET請求,stream=True表示以流的方式下載大文件# verify=True表示驗證SSL證書(確保下載的安全性)r = requests.get(url, stream=True, verify=True)# 將下載的內容寫入到本地文件中with open(fname, 'wb') as f:f.write(r.content) # 將請求的內容寫入文件return fname # 返回本地文件路徑''' 下載并解壓一個zip或tar文件name:要下載并解壓的文件名,必須在DATA_HUB中存在folder:解壓后的目標文件夾名(可選)'''def download_extract(self, name, folder=None): # @save"""下載并解壓zip/tar文件"""fname = self.download(name) # 調用download函數下載指定的文件,獲取本地文件路徑base_dir = os.path.dirname(fname) # 獲取緩存目錄路徑(即下載文件所在的目錄)data_dir, ext = os.path.splitext(fname) # 分離文件名和擴展名if ext == '.zip': # 如果是zip文件,使用zipfile.ZipFile 打開文件fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'): # 如果是tar或gz文件,使用tarfile.open 打開文件fp = tarfile.open(fname, 'r')else: # 如果文件擴展名不是zip、tar或gz,拋出斷言錯誤assert False, '只有zip/tar文件可以被解壓縮'fp.extractall(base_dir) # 將文件解壓到緩存目錄中# 返回解壓后的路徑# 如果指定了folder參數,返回解壓后的目標文件夾路徑# 否則返回解壓后的文件路徑(即去掉擴展名的文件名)return os.path.join(base_dir, folder) if folder else data_dir# 將使用的所有數據集從DATA_HUB下載到緩存目錄中def download_all(self): # @save"""下載DATA_HUB中的所有文件"""for name in self.DATA_HUB:self.download(name)使用示例:
import os
import pandas as pddownloader = C_Downloader()
DATA_HUB = downloader.DATA_HUB
DATA_URL = downloader.DATA_URL# 下載并緩存Kaggle房屋數據集
DATA_HUB['kaggle_house_train'] = ( #@saveDATA_URL + 'kaggle_house_pred_train.csv','585e9cc93e70b39160e7921475f9bcd7d31219ce')DATA_HUB['kaggle_house_test'] = ( #@saveDATA_URL + 'kaggle_house_pred_test.csv','fa19780a7b011d9b009e8bff8e99922a8ee2eb90')# 調用download函數下載文件
cache_dir=os.path.join('.', 'data', 'kaggle_house') # 緩存路徑為 .\data\kaggle_house
trainData_path = downloader.download('kaggle_house_train', cache_dir)
testData_path = downloader.download('kaggle_house_test', cache_dir)
print(f'【訓練集】文件已下載到:{trainData_path}')
print(f'【測試集】文件已下載到:{testData_path}')# 使用pandas分別加載包含訓練數據和測試數據的兩個CSV文件
train_data = pd.read_csv(trainData_path)
test_data = pd.read_csv(testData_path)
# train_data = pd.read_csv(downloader.download('kaggle_house_train'))
# test_data = pd.read_csv(downloader.download('kaggle_house_test'))print(f"【訓練集】:{train_data.shape} 包括1460個樣本,每個樣本80個特征和1個標")
print(f"【測試集】:{test_data.shape} 包含1459個樣本,每個樣本80個特征")
print(f"查看前四個和最后兩個特征,以及相應標簽(房價)\n{train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]}")# 對于每個樣本:刪除第一個特征ID,因為其不攜帶任何用于預測的信息
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))Vocab類:構建文本詞表 &?統計詞元(tokens)的頻率 count_corpus
'''
Vocab類:構建文本詞表(Vocabulary),管理詞元與索引的映射關系
功能:
構建詞表,管理詞元與索引的映射關系,支持:
詞元 → 索引(token_to_idx)
索引 → 詞元(idx_to_token)
過濾低頻詞
保留特殊詞元(如 <unk>未知, <pad>填充符, <bos>起始符, <eos>結束符)
'''
class Vocab: #@save"""文本詞表"""# tokens:原始詞元列表(一維或二維)# min_freq:最低詞頻閾值,低于此值的詞會被過濾# reserved_tokens:預定義的特殊詞元(如 ["<pad>", "<bos>"])def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):if tokens is None: tokens = []if reserved_tokens is None: reserved_tokens = []# 統計詞頻,按出現頻率排序counter = count_corpus(tokens) # 統計詞頻# key=lambda x: x[1] 指定排序依據為第二個元素# reverse=True 降序排序# _var:弱私有(Protected),# 表示變量是內部使用的,提示開“不要從類外部直接訪問”,但實際上仍然可訪問(Python不會強制限制)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True) # 詞元頻率(詞頻),按頻率降序排序# 初始化詞表,未知詞元的索引為0(<unk>)# idx_to_token:索引 → 詞元,索引0 默認是 <unk>(未知詞元),后面是reserved_tokens# token_to_idx:詞元 → 索引,是 idx_to_token 的反向映射self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idxfor idx, token in enumerate(self.idx_to_token)} # 字典# 按詞頻從高到低添加詞元,過濾低頻詞for token, freq in self._token_freqs:if freq < min_freq: # 跳過低頻詞breakif token not in self.token_to_idx: # 若詞元不在token_to_idx中,則添加到詞表self.idx_to_token.append(token) # 壓入新詞元self.token_to_idx[token] = len(self.idx_to_token) - 1 # 新詞元對應的索引# __len__用于定義對象的長度行為。對類的實例調用len()時,Python會自動調用該實例的__len__方法def __len__(self): # 詞表大小(包括 <unk> 和 reserved_tokens)return len(self.idx_to_token) # 返回詞表大小# 詞表索引查詢:支持單個詞元或詞元列表查詢 ↓# vocab["hello"] → 返回索引(如 1)# vocab[["hello", "world"]] → 返回索引列表 [1, 2]# 若詞元不存在,返回 unk 的索引(默認 0)# __getitem__定義對象如何響應obj[key]這樣的索引操作,實現后 實例可像列表或字典一樣通過方括號[]訪問元素def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)): # 若傳入參數不為列表或元組,而是單個# 字典的內置方法 dict.get(key, default) 用于安全地獲取字典中某個鍵(key)對應的值# 若鍵不存在,則返回指定的默認值(default),而不會拋出 KeyError 異常return self.token_to_idx.get(tokens, self.unk) # 單個詞元返回索引,未知詞返回0return [self.__getitem__(token) for token in tokens] # 遞歸處理列表# 索引轉詞元# 支持單個索引或索引列表轉換:# vocab.to_tokens(1) → 返回詞元(如 "hello")# vocab.to_tokens([1, 2]) → 返回詞元列表 ["hello", "world"]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)): # 若傳入參數不為列表或元組,而是單個return self.idx_to_token[indices] # 單個索引返回詞元return [self.idx_to_token[index] for index in indices] # 遞歸處理列表@propertydef unk(self): # 返回未知詞元的索引(默認為0)return 0@propertydef token_freqs(self): # 返回原始詞頻統計結果(降序排列)return self._token_freqs # 返回詞頻統計結果# 輔助函數:統計詞元(tokens)的頻率,返回一個 Counter對象
def count_corpus(tokens): #@save"""統計詞元的頻率"""# 這里的tokens是1D列表或2D列表# 如果tokens是空列表或二維列表(如句子列表),則展平為一維列表if len(tokens) == 0 or isinstance(tokens[0], list):# 將詞元列表展平成一個列表tokens = [token for line in tokens for token in line]# collections.Counter統計每個詞元的出現次數,返回類似{"hello":2, "world":1}的字典return collections.Counter(tokens)使用示例:
vocab = common.Vocab(tokens) # 構建詞表,管理詞元與索引的映射關系
print(f"前幾個高頻詞及其索引:\n{list(vocab.token_to_idx.items())[:10]}")for i in [0, 10]: # 將每一條文本行轉換成一個數字索引列表print(f"第{i}行信息:")print('文本:', tokens[i])print('索引:', vocab[tokens[i]])print(f"詞表大小:{len(vocab)}")
print(f"詞頻統計(降序):\n{vocab.token_freqs}")

數據加載器類:整合隨機采樣和順序分區,并用作數據迭代器 SeqDataLoader
# 數據加載器類:將隨機采樣和順序分區包裝到一個類中,以便稍后可以將其用作數據迭代器
class SeqDataLoader: #@save"""加載序列數據的迭代器"""# max_tokens:限制返回的詞元索引序列的最大長度(默認 -1 表示不限制)def __init__(self, downloader, batch_size, num_steps, use_random_iter, max_tokens):# 初始化選擇采樣方式if use_random_iter:self.data_iter_fn = seq_data_iter_random # 隨機取樣else:self.data_iter_fn = seq_data_iter_sequential # 順序分區self.corpus, self.vocab = load_corpus_time_machine(downloader, max_tokens) # 加載語料和詞表self.batch_size, self.num_steps = batch_size, num_steps# __iter__實現迭代器協議:使對象可迭代,直接用于for循環# 從語料庫(self.corpus)中 按指定的batch_size和num_step(即sequence_length) 生成批量數據def __iter__(self):return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)







之認識Pod)








![[硬件電路-121]:模擬電路 - 信號處理電路 - 模擬電路中常見的難題](http://pic.xiahunao.cn/[硬件電路-121]:模擬電路 - 信號處理電路 - 模擬電路中常見的難題)
)
