目錄
一、數據編排的定義與概念
1.數據編排的基本含義
2.數據編排與相關概念的區別
3.數據編排的重要性
二、數據編排的流程
1.需求分析:
2.數據源識別與連接:
3.數據抽取:
4.數據轉換:
5.數據加載:
6.監控與優化:
三、數據編排的優勢
四、數據編排面臨的挑戰
五、數據編排的工具
總結
Q&A常見問答
現在企業里數據量日益增多,但往往東一塊西一塊,散落在各處。想把這些數據真正用起來,變成對業務有用的東西,就得靠數據編排。說白了,數據編排就是把數據的來龍去脈管起來,讓數據能順利地流到需要它的地方。今天咱就聊聊,數據編排到底是個啥,它具體怎么干、有啥好處、會遇到哪些坎兒,以及市面上有啥趁手的工具。
文中示例數據編排工具>>>免費試用FDL
一、數據編排的定義與概念
1.數據編排的基本含義
簡單來說,數據編排就是對數據的“一生”做個規劃和管理。從它出生(產生)的地方,到它發揮作用(被使用)的地方,中間怎么走、怎么變,都得安排好。核心就是:把散在四面八方的數據撈出來,按業務需要的規矩收拾干凈、變個樣,然后穩穩當當地送到該去的地方。整個過程得保證數據是準的、是及時的、是完整的,這樣才能真正支撐企業做決定、跑業務。
2.數據編排與相關概念的區別
數據編排常跟數據集成、數據治理這些詞放一起,但它們各有側重。
- 數據集成:主要解決“合”的問題,把不同源頭的數據拼到一塊兒,讓大家能看到個統一的樣子。
- 數據編排:管得更寬,不光要“合”,還得管數據怎么“動”(抽取、轉換、加載),怎么“管”(調度、監控),重點是數據流動的整個過程。
- 數據治理:站得更高,定規矩:數據質量咋保證、安全咋管、合規咋做。說白了,數據治理是定戰略定規則,數據編排是落地執行的具體戰術之一。數據編排是在數據治理的大框框下,把數據集成和價值挖掘做實的法子。
3.數據編排的重要性
現在企業搞數字化,數據又多又雜,源頭五花八門。要是沒個好的數據編排,數據就真成一盤散沙了,看著多,用不上。我一直強調,數據編排能幫你:
- 把散亂的數據管起來,讓它真正能流動、能共享。
- 讓業務部門及時拿到靠譜的數據做分析、做決策。
- 提升整個企業的運營效率和競爭力。聽著是不是很熟?很多效率問題就卡在數據不通上。
二、數據編排的流程
數據編排不是一錘子買賣,是個有章法的持續過程:
1.需求分析:
這是打地基的一步。得跟業務部門坐一塊兒,好好聊聊:你們到底要啥數據?拿它干啥用(做報表、做分析、做預測)?對數據的快慢(及時性)、準頭(準確性)有啥具體要求?把目標搞清楚了,后面才知道勁兒往哪使。
2.數據源識別與連接:
知道要啥了,下一步就是找“糧倉”——數據在哪?可能是內部數據庫(MySQL,Oracle)、文件服務器、云存儲(S3,OSS),也可能是外部API。找到后,得用合適的技術(比如JDBC連數據庫,API調用連服務)把它們穩穩當當地連上,確保能穩定、安全地拿到數據。

3.數據抽取:
連上了,就該把數據“搬”出來了。怎么搬?
- 全量抽:適合數據量不大、變化不多的情況,一次全搬出來。
- 增量抽:數據量大、變化快?那就只搬上次之后新加的、改動的部分,省時省力。用過來人的經驗告訴你,增量抽是常態,但得解決好怎么精準識別“變化”這個技術點。
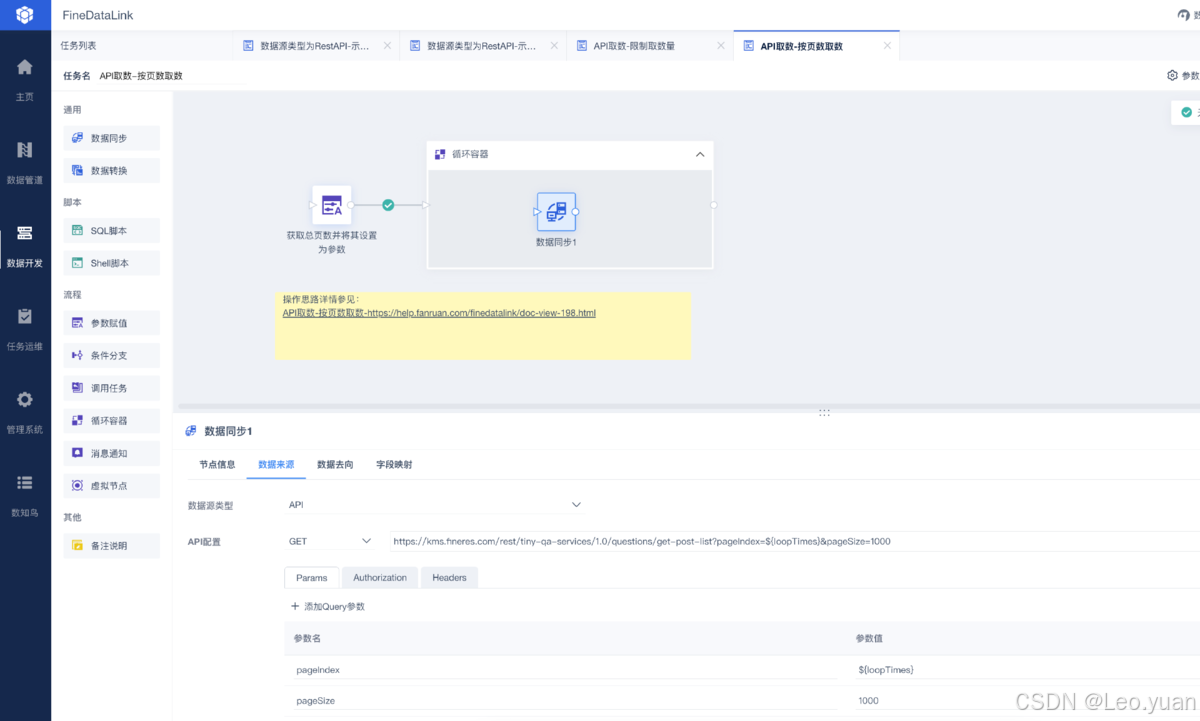
4.數據轉換:
剛搬出來的“原料”數據,往往不能直接用,得“加工”:
- 清洗:把臟東西去掉——錯的、重復的、缺胳膊少腿的(缺失值)。
- 整合:不同來源的數據,結構可能不一樣,得把它們“對齊”、合并,弄成一個統一的、好用的樣子。
- 計算/衍生:可能需要算點新東西出來,比如總和、平均值、增長率啥的。這一步的目標,就是把數據收拾成業務真正需要、能直接用的樣子。
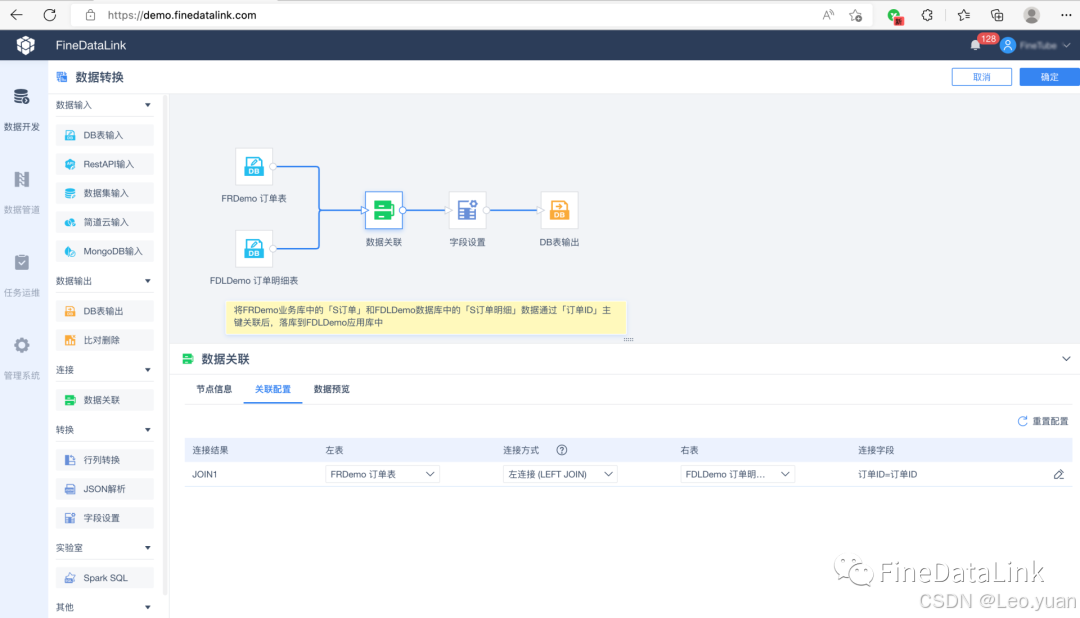
5.數據加載:
加工好的數據,得存到“目的地”——可能是數據倉庫(像Hive,Redshift)、數據湖、或者直接給業務系統(BI平臺、CRM系統)。加載時得考慮:
- 數據量多大?
- 業務需要多快看到新數據(實時?準實時?T+1?)
- 目標系統能不能扛住?選批量加載還是實時流式加載。
6.監控與優化:
流程跑起來不是終點。得盯著點:數據按時到了嗎?量對不對?處理過程中出錯沒?性能咋樣(會不會太慢)?根據監控到的情況,持續調優:改改配置、加加資源、優化下轉換邏輯。數據編排是個動態活兒,得持續維護。
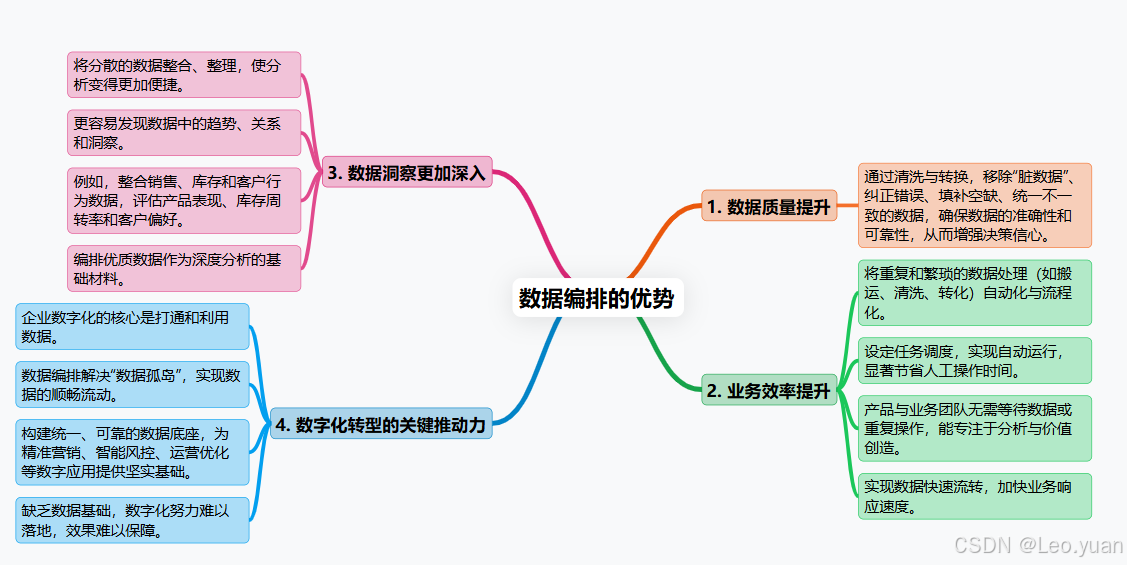
三、數據編排的優勢
為啥要費勁搞數據編排?好處實實在在:
1.數據質量往上走:靠清洗、轉換這些步驟,把數據里的“臟東西”篩掉,錯誤糾正,空缺補上,不一致的弄一致。數據干凈了、準了,做決定心里才有底,不怕被錯誤數據帶溝里。
2.業務效率提上來:把那些重復、繁瑣的數據搬、洗、轉的活兒自動化、流程化。設定好任務調度,到點自動跑,省下大量人工操作時間。業務人員不用等數據、折騰數據,能更專注在分析數據、創造價值上。數據流轉更快,業務響應也能更及時。
3.數據洞察更透亮:把分散的數據規整到一起、收拾干凈,分析起來才順手。更容易發現數據里的門道、趨勢和關聯。比如,銷售、庫存、客戶行為數據一整合,就能看清產品賣得好不好、庫存周轉快不快、客戶喜歡啥。說白了,編排好的數據是深度分析的“好原料”。
4.數字化轉型的助推器:企業搞數字化,核心之一就是打通數據、用好數據。數據編排正是解決“數據孤島”、實現數據順暢流動的關鍵手段。它幫著構建統一、可靠的數據底座,各種數字化應用(精準營銷、智能風控、運營優化)才有堅實的數據基礎。你懂我意思嗎?沒這個基礎,數字化就是空中樓閣。
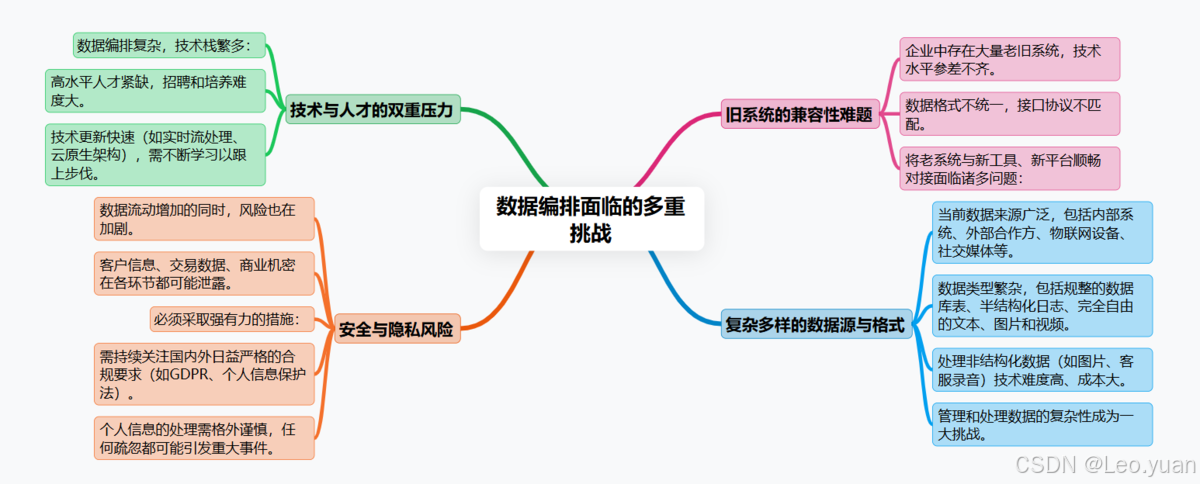
四、數據編排面臨的挑戰
路好走,但坑也不少,得心里有數:
1.數據太復雜:現在數據來源多(內部系統、外部合作方、物聯網設備、社交媒體)、類型雜(規整的數據庫表、半結構化的日志、純自由的文本圖片視頻)。特別是處理那些非結構化數據(像圖片、客服錄音),技術難度和成本都更高。怎么有效管理、處理這種復雜性是個大挑戰。
2.安全與隱私是紅線:數據流動起來,風險也跟著動。客戶信息、交易數據、商業機密,在抽取、傳輸、處理、存儲的每個環節都可能泄露。必須上硬手段:數據傳輸加密、存儲加密、嚴格的訪問權限控制(最小權限原則)、操作審計日志。還得時刻盯著國內外越來越嚴的合規要求(GDPR、個人信息保護法),處理個人信息要特別小心。聽著是不是很熟?一出事就是大事。
3.技術和人才跟不上趟:搞數據編排,技術棧不簡單:得懂數據庫、會點編程(SQL,Python)、熟悉數據處理框架、了解各種工具平臺。市場上能玩轉這些的熟手不多,招人難、培養人也費勁。技術更新還快(比如實時流處理、云原生架構),得持續學習。
4.老系統難兼容:企業里往往一堆老系統,用的技術五花八門,數據格式也不統一。讓這些“老古董”和新工具、新平臺順暢對話,把數據抽出來、送進去,經常遇到接口不對、協議不通、性能跟不上等兼容性問題,很頭疼。
五、數據編排的工具
工欲善其事,必先利其器。市面上主流工具盤點一下:
1.FineDataLink:國內選手,亮點在可視化拖拉拽設計流程,對新手友好;能連各種常見數據源;數據轉換功能比較豐富;監控調度做得不錯。適合想快速上手、整合能力要求高的場景。
作為一款低代碼/高時效的企業級一站式數據集成平臺,FDL在面向用戶大數據場景下,可回應實時和離線數據采集、集成、管理的訴求,提供快速連接、高時效融合各種數據、靈活進行ETL數據開發的能力,幫助企業打破數據孤島,大幅激活企業業務潛能,使數據成為生產力>>>免費試用FDL

2.TalendOpenStudio:開源免費,社區活躍,組件庫豐富,能快速搭流程。圖形化界面降低了使用門檻。但處理超大規模數據時,可能需要額外優化性能。
3.InformaticaPowerCenter:企業級老牌選手,功能全、性能強,尤其擅長處理超大規模、超復雜的數據流,支持分布式計算。但價格不菲,對硬件要求也高,一般是大企業的選擇。
4.IBMDataStage:同樣是重量級選手,性能強勁,適合高并發大數據量場景;和IBM自家產品(如Db2)集成好;監控管理功能全面。學習曲線比較陡峭。
5.MicrosoftSSIS:微軟SQLServer親兒子,和SQLServer無縫集成是最大優勢;可視化設計界面易用;尤其適合微軟技術棧(SQLServer,Azure)的企業。跨平臺或連非微軟系數據源可能稍弱。
6.PentahoDataIntegration(Kettle):開源工具,也叫Kettle;圖形化操作,支持廣泛的數據源和目標;插件擴展性強。處理極其復雜的業務邏輯時性能可能是個考驗。
選工具關鍵看:你家數據啥情況(來源、類型、規模)?業務要啥(實時性要求、復雜度)?團隊技術棧和技能咋樣?預算多少?工具好不好學、好不好維護?我一直強調,沒有最好的,只有最合適的。
總結
數據編排,說白了就是給企業數據的流動和管理立規矩、建管道。它有一套清晰的流程:從搞清楚業務要啥(需求分析),到找到數據源頭連上線(源識別連接),把數據搬出來(抽取),收拾干凈變個樣(轉換),再穩穩送到目的地(加載),最后還得盯著管著不斷優化(監控優化)。
好處明擺著:數據更干凈可靠了(提質量),處理數據的效率上去了(提效率),從數據里能看出更多門道了(強洞察),更是企業搞數字化轉型離不開的“筑基”工程(撐轉型)。
當然,路上有坎兒:數據本身又雜又亂(復雜性),安全和隱私一點馬虎不得(安全隱私),懂行的技術人才不好找(人才缺),讓老系統和新工具和諧共處也挺費勁(兼容難)。
好在工具不少,從開源的Talend、Pentaho,到企業級的Informatica、DataStage,還有國內順手好用的FineDataLink,各有千秋。選工具得擦亮眼,看功能、看成本、看團隊能不能玩轉、看未來發展。
說到底,在數據就是競爭力的今天,把數據編排整明白了、整順暢了,企業才能真正把數據用起來,變成決策的底氣、業務的推力,在數字化的路上跑得更穩更快。
Q&A常見問答
Q:數據編排和數據挖掘是一回事嗎?
A:不是一回事,但緊密相關。數據編排重點是管好數據流:怎么把數據從源頭穩定、干凈、及時地搬到分析平臺。數據挖掘重點是從數據里挖金子:用算法模型發現規律、預測趨勢。簡單來說,數據編排是給數據挖掘打好地基、備好材料。沒有編排好的高質量數據,挖掘就是空談。
Q:選數據編排工具最該看啥?
A得綜合掂量幾個事:
- 功能匹配度:它能不能輕松連上你家的各種數據源(數據庫、文件、API、云)?支持你需要的轉換清洗操作嗎?調度監控功能夠用不?處理性能(速度、數據量)達標嗎?
- 團隊搞得定嗎?工具好學嗎(界面友不友好)?好維護嗎?跟你家現有的技術棧(比如都用Java或者都在云上)搭不搭?需不需要專門招人或培訓?
- 錢袋子問題:軟件許可費多少?云服務怎么收費?后期維護升級、硬件資源投入要多少?開源工具雖然免費,但隱性成本(自己維護、二次開發)也得算。
- 擴展性和未來:業務量漲了、數據類型多了,這工具還能不能撐住?廠商靠不靠譜、技術更不更新?用過來人的經驗告訴你,別光看眼前,長遠點看。
Q:數據編排對搞數字化轉型有多重要?
A:非常核心,可以說是“筑基”工程。企業數字化轉型,核心目標之一就是數據驅動。但數據要是散著、臟著、流不動,拿啥驅動?數據編排就是解決這些痛點的:
- 打破數據墻:把各部門、各系統的數據連通,告別“孤島”。
- 保障數據質:提供干凈、可信的數據原料。
- 加速數據用:讓業務系統、分析平臺能及時拿到需要的數據。
- 支撐新應用:為實時分析、AI預測、個性化服務這些數字化場景提供可靠的數據流水線。你懂我意思嗎?沒它,數字化轉型的地基就不牢。









:基于 Qt Widgets 搭建串口調試界面)



)
)



)
