1、概念
目標檢測(Object Detection)是計算機視覺中的一個重要領域,它涉及到識別圖片或視頻某一幀中的物體是什么類別,并確定它們的位置。通常用于多個物體的識別,可以同時處理圖像中的多個實例,并為每個實例提供一個邊界框和類別標簽
目標檢測面臨到的問題:
目標種類和數量問題
目標尺度問題
環境干擾問題
2、標注
在目標檢測任務中,標注主要涉及的是邊界框標注,即為圖像中的每一個需要檢測的目標物體畫出一個邊界框,并給定類別標簽
在訓練目標檢測模型的時候,我們就需要先為數據集做標注
3、本質
對于目標檢測,主要是關注兩個問題:
目標在哪里?where
目標是什么?what
以下圖為例說明:
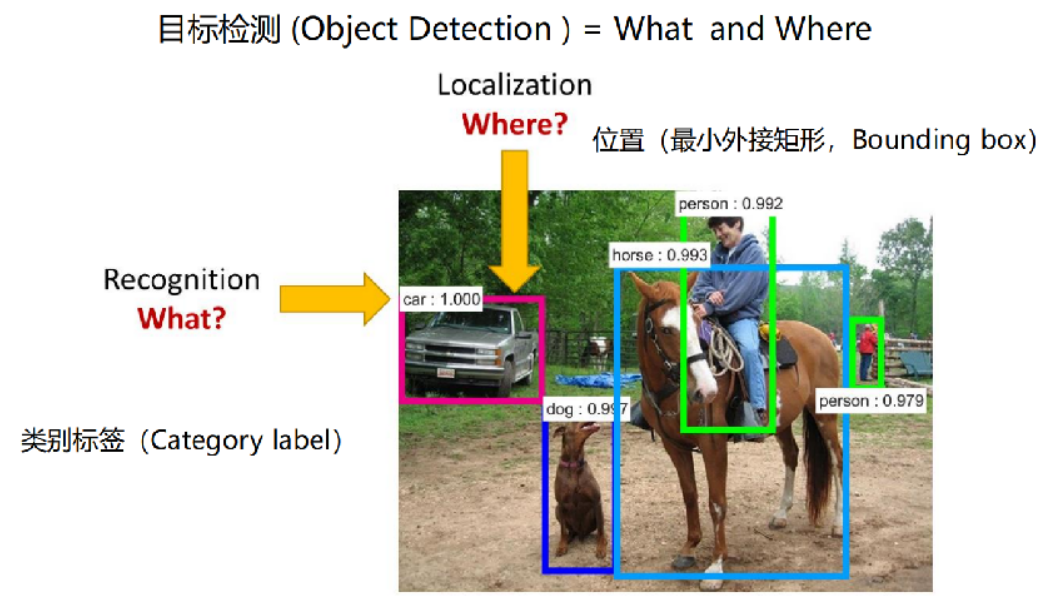
4、目標檢測、圖像分類、圖像分割
目標檢測是指在圖像中找到特定類別的物體,并用邊界框(Bounding Boxes)標出它們的位置。除了識別圖像中的物體外,目標檢測還需要確定這些物體的具體位置
圖像分類是指識別圖像中的主要物體或類別。它只關心圖像屬于哪個類別,而不關心物體的具體位置
圖像分割是指在圖像中識別特定類別的物體,并用像素級別的標簽來表示這些物體的位置。它不僅需要識別物體是什么,還需要精確地描繪物體的輪廓,目標分割為了了兩類
語義分割(Semantic Segmentation):僅識別物體的類別,不區分不同的實例,即為整個圖像中的每個像素分配一個類別標簽
實例分割(Instance Segmentation):不僅識別物體的類別,還區分不同的實例(個體),即為每個物體提供一個精確的分割掩碼
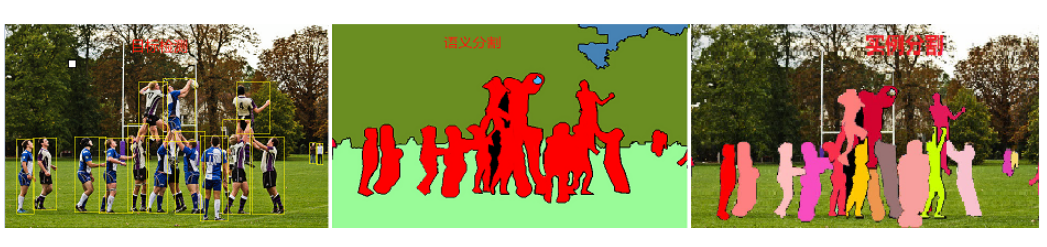
目標檢測和目標分割的區別圖示:
目標檢測:識別圖像中存在的內容和檢測其位置,如下圖,以識別和檢測人(person)為例
語義分割:對圖像中的每個像素打上類別標簽,如下圖,把圖像分為人(紅色)、樹木(深綠)、草地(淺綠)、天空(藍色)標簽
實例分割:目標檢測和語義分割的結合,在圖像中將目標檢測出來(目標檢測),然后對每個像素打上標簽(語義分割)。對比上圖、下圖,如以人(person)為目標,語義分割不區分屬于相同類別的不同實例(所有人都標為紅色),實例分割區分同類的不同實例(使用不同顏色區分不同的人)
5、應用場景
自動駕駛:檢測周圍的車輛、行人、交通燈、道路標志等
安防監控:監控公共場,發現異常行為,保障公共安全
人臉檢測
醫學影像分析:在醫學影像方面可以識別腫瘤、組織變異等,用于醫療輔助
無人機應用:識別特定目標,引導無人機飛行,比如監測天氣、線路檢測、搜尋救援、軍事等
缺陷檢測:工業
6、技術架構
目標檢測方法可以根據其架構和技術特點進行分類。目前主流的目標檢測方法可以分為兩大類:兩階段檢測方法(Two-stage Detection Methods)和單階段檢測方法(One-stage Detection Methods)
分類信息如下表:
| one-stage | two-stage | |
|---|---|---|
| 主要算法 | YOLO系列、SSD | R-CNN、Fast R-CNN、Faster R-CNN |
| 檢測精度 | 較低(版本不斷更新,精度不斷增加) | 較高 |
| 檢測速度 | 較快(達到視頻流檢測級別) | 較慢 |
6.1 two-stage
兩階段檢測開始于 2014 年左右,是目標檢測領域中非常重要的一類方法,這類方法通常因為其高檢測精度和可靠性而被廣泛應用于各種復雜的目標檢測任務中
兩階段檢測方法將目標檢測任務分為兩個連續的階段:
第一階段:第一階段是生成候選區域(Region Proposals),即可能包含目標的區域,通常通過區域提議網絡(RPN)或其他方法實現
第二階段:對生成的候選區域進行分類和邊界框回歸,即確定候選區域中的物體類別以及調整候選區域的位置,以更精確地框中目標
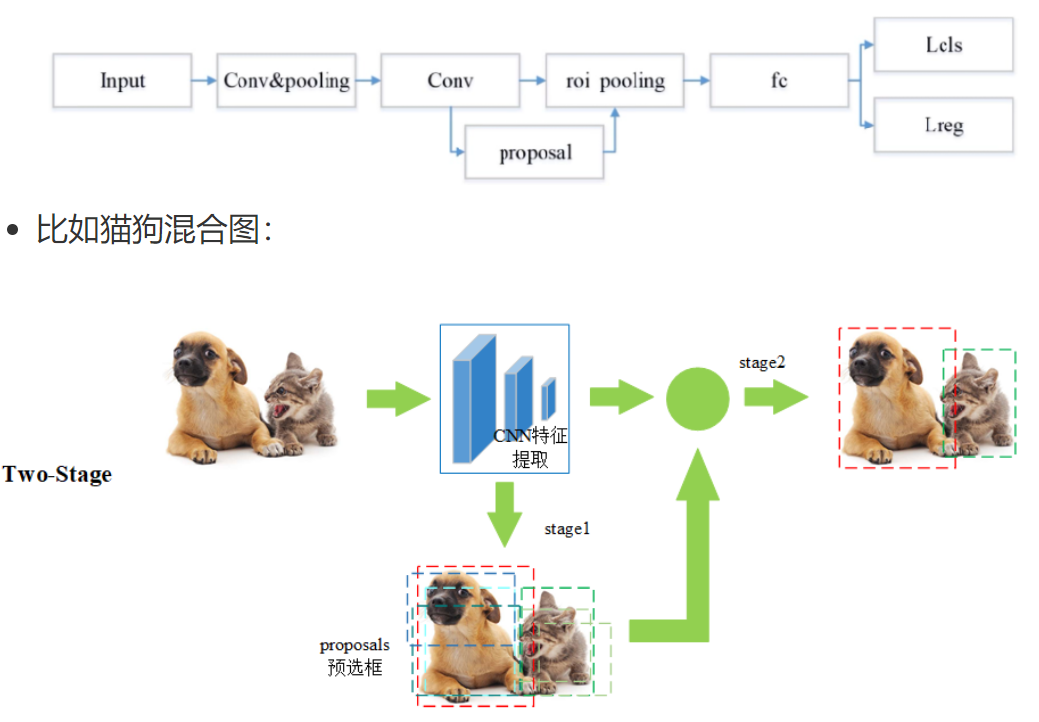
基本流程如下:
第一步 Input:輸入一張圖像
第二步 Conv&pooling:使用卷積神經網絡做深度特征提取,通過稱這個卷積神經網絡為主干神經網
第三步 Conv-proposal:使用 RPN 網絡生成候選區域,并對這些區域進行初步的分類(區分背景和目標)以及位置預測?
第四步 roi pooling:候選區域進一步精確進行位置回歸和修正,對不同大小的候選區域提取固定尺寸的特征圖
第五步 fc:全連接層,對候選區域的特征進行表示
第六步 Lcls、Lreg:通過分類和回歸來分別完成對候選目標的類別的預測以及候選目標位置的優化,這里的類別不同于 RPN 網絡的類別,這里通常會得到物體真實的類別,回歸主要得到當前目標具體的坐標位置,通常表示為一個矩形框,即四個值(x,y,w,h)
6.2 one-stage
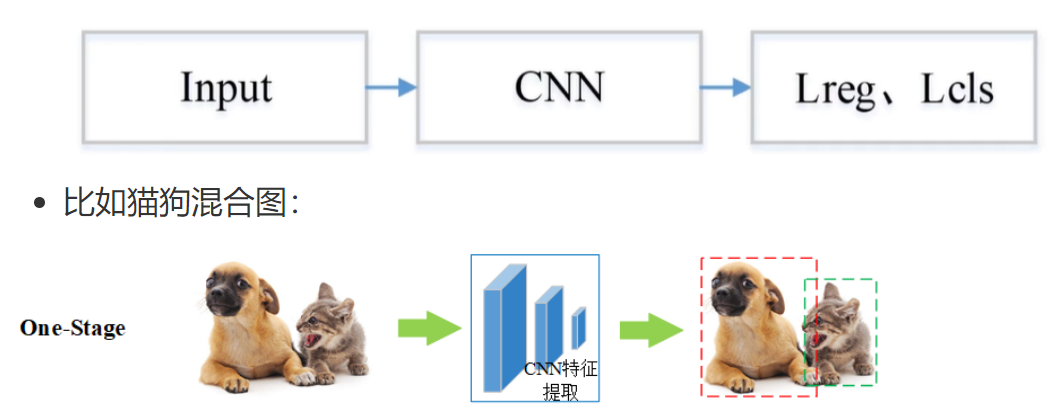
單階段目標檢測開始于 2016 年左右,沒有像 two-stage 那樣先生成候選框,而是直接回歸物體的類別概率和位置坐標值
基本流程圖如下:
第一步 Input:輸入一張圖像
第二步 CNN:使用卷積神經網絡做深度特征提取,通過稱這個卷積神經網絡為主干網絡
第三步 Lcls、Lreg:通過分類和回歸來分別完成對候選目標的類別的預測以及候選目標位置的優化
7、指標
7.1 邊界框
在目標檢測任務中,Bounding Box(邊界框) 是用來定位圖像中檢測到的物體位置的一個矩形框。每個檢測出的物體都會被分配一個邊界框,用來表示該物體在圖像中的位置和大小
邊界框通常由以下信息表示:
類別標簽(Class Label):表示這個物體是什么,例如“貓”、“車”、“人”等
置信度分數(Confidence Score):表示模型對該檢測結果的置信程度,通常是一個 0 到 1 之間的值
邊界框坐標(Bounding Box Coordinates):表示矩形框的位置和大小
7.2 交并比
在目標檢測任務中,IoU(Intersection over Union,交并比)是一個非常關鍵的評估指標,用于衡量模型預測的邊界框(Predicted Bounding Box)與真實邊界框(Ground Truth Bounding Box)之間的重合程度
IoU 的計算方式是兩個邊界框的交集面積除以它們的并集面積,公式如下:
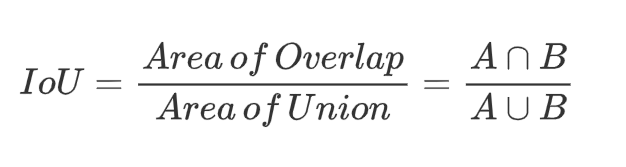
- IoU 計算公式圖形表示如下
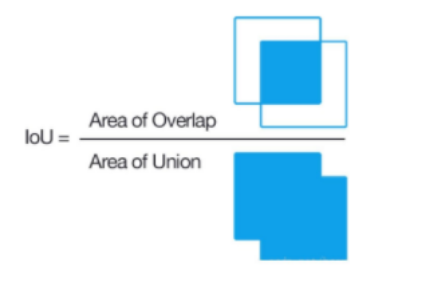
IoU 值是介于 [0,1] 之間的,以下是對不同取值的一個說明:
| IoU 值 | 含義說明 |
|---|---|
| IoU = 0 | 兩個框完全不重合,預測框與真實框沒有任何交集 |
| 0 < IoU < 0.5 | 有一定重合,但重合度較低,預測效果一般 |
| 0.5 ≤ IoU < 1 | 重合度較高,預測框接近真實框,效果較好 |
| IoU = 1 | 完全重合,預測框與真實框完全一致,可能是理想情況或存在過擬合風險 |
圖示:紅框是預測框,綠色框是真實框
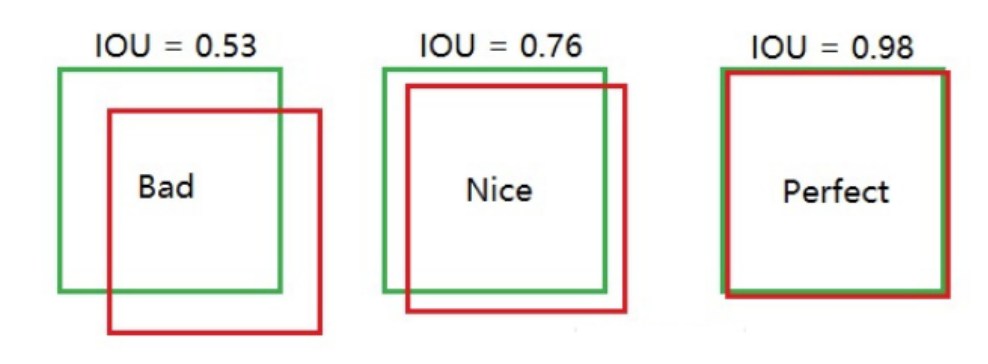
7.3 置信度
在目標檢測中,置信度是模型對預測框是否包含目標物體、以及框的位置是否準確的“信心值”,取值范圍 0 到 1 之間的數值
在一些經典的目標檢測模型中(如 YOLO),置信度通常由兩個部分組成:置信度 = Pr(Object) × 預測的 IOU
Pr(Object)=1:邊界框內有對象
Pr(Object)=0:邊界框內沒有對象
預測的 IoU:不是真實計算出來的,而是模型自己“估計”的,表示它認為這個框和真實框有多接近
在深度學習的目標檢測任務中,置信度是由網絡的輸出層(通常包括卷積層、池化層和全連接層等)共同作用的結果
在目標檢測任務中,通常涉及到三種類型的置信度:目標存在置信度、類別置信度、綜合置信度
| 類型 | 含義 |
|---|---|
| 目標存在置信度 | 表示當前預測框中存在目標物體的概率(不管是什么類別) |
| 類別置信度 | 表示當前框中的物體屬于某個類別的概率(如“貓”、“狗”、“人”等) |
| 綜合置信度 | 最終輸出的置信度,等于目標存在置信度 × 類別置信度 |
總結:
| 階段 | 置信度的計算方式 | 說明 |
|---|---|---|
| 訓練階段 | 使用真實框(Ground Truth)計算 IoU | 模型通過對比預測框與真實框,學習如何提升置信度 |
| 預測階段 | 模型無法訪問真實框,置信度完全由網絡直接輸出 | 通過設置置信度閾值(如 0.5)過濾低質量預測框,再通過 NMS 去除重復框 |
7.4 混淆矩陣
混淆矩陣是一種用于評估分類模型性能的表格形式,特別適用于監督學習中的分類任務。它通過將模型的預測結果與真實標簽進行對比,幫助我們直觀地理解模型在各個類別上的表現
在混淆矩陣中:
列(Columns):表示真實類別(True Labels)
行(Rows):表示預測類別(Predicted Labels)
單元格中的數值:表示在該真實類別與預測類別組合下的樣本數量
在目標檢測任務中,混淆矩陣的構建依賴于 IoU 閾值,因為 IoU 決定了哪些預測被認為是“正確檢測”,從而影響 TP、FP、FN 的統計,最終影響混淆矩陣的結構和數值
| 實際為正類 | 實際為負類 | |
|---|---|---|
| 預測為正類 | TP(真正例) | FP(假正例) |
| 預測為負類 | FN(假反例) | TN(真反例) |
7.5 精確度和召回率
精確度(Precision):在所有預測為正類的樣本中,預測正確的比例,也稱為查準率
召回率(Recall):在所有實際為正類的樣本中,預測正確的比例,也稱為查全率
準確度、精確度、召回率、F1 分數在機器學習中已經講過,定義和公式如下圖:

- 混淆矩陣在目標檢測中的 TP、FP、FN、TN 的含義
| 類型 | 定義 | 通俗解釋 | 示例 |
|---|---|---|---|
| TP(True Positive) 真正例 | 預測類別正確,且預測框與真實框的 IoU ≥ 閾值 | 模型正確識別了目標,位置也大致準確 | 模型預測這是一個“貓”,IoU=0.85,確實是一只貓 |
| FP(False Positive) 假正例 | 兩種情況: 1. 類別錯誤:預測類別錯誤,即使 IoU ≥ 閾值 2. 類別正確,但 IoU < 閾值 | 模型誤以為檢測到了目標,但實際上錯了 | 模型預測該物體為“貓”,且預測框與真實框的 IoU 為 0.4,但實際類別為“狗”;或者模型預測為“貓”,IoU 為 0.3,類別雖然正確,但定位精度未達到設定的閾值 |
| FN(False Negative) 假反例 | 真實存在目標,但模型沒有檢測出來 | 模型漏掉了真實目標 | 圖片里有一只貓,但模型沒檢測到 |
| TN(True Negative) 真反例 | 圖像背景區域被正確識別為“無目標” | 模型沒有把背景誤認為是目標 | 圖像背景區域沒有預測框,模型正確識別為“無物體” |
7.6 mAP
7.6.1 PR曲線
PR曲線,即精確率(Precision)- 召回率(Recall)曲線,是評估分類模型性能的重要工具之一,尤其是在類別不平衡問題中。它通過展示不同閾值下的精確率和召回率之間的關系,幫助我們理解模型在不同決策邊界上的表現
PR 曲線的生成過程:
對于每個樣本,模型會輸出一個預測分數或置信度,表示該樣本屬于某一類別的概率
設定多個置信度閾值:通常會設定一系列的置信度閾值,比如從 0 到 1,每隔 0.1 設置一個閾值,這些閾值將用于決定哪些預測被視為“正例”(Positive),哪些被視為“負例”(Negative)
對于每一個閾值,根據預測分數與該閾值的比較結果,我們可以計算出當前閾值下的精確率(Precision)和召回率(Recall)
將每個閾值下的精確率和召回率作為坐標點,繪制在二維平面上,橫軸為召回率,縱軸為精確率,從而形成一條曲線
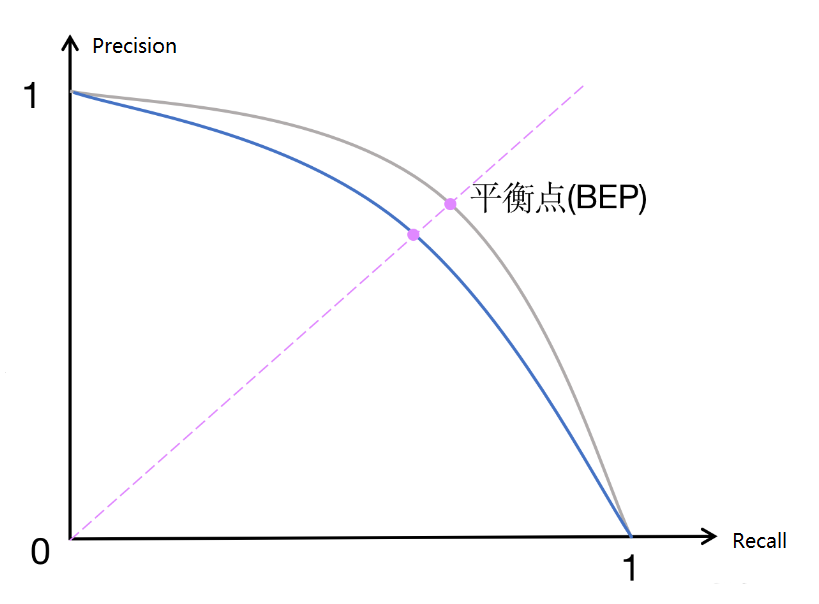
7.6.2 AP
在 PR 曲線中,曲線上每個點表示了在對應召回率下的最大精確率值。當 P=R 時成為平衡點(BEP),如果這個值較大,則說明學習器的性能較好。所以 PR 曲線越靠近右上角性能越好。即 PR 曲線的面積越大,表示分類模型在精確率和召回率之間有更好的權衡,性能越好
常用的評估指標是 PR 曲線下的面積,即 AP(Average Precision),通過 PR 曲線下的面積來計算 AP,從而綜合評估模型在不同置信度閾值下的性能,值越接近 1 越好
平均精度(Average Precision, AP)通過計算每個類別在不同置信度閾值下的 Precision(查準率)和 Recall(查全率)的平均值來綜合評估模型的性能。AP 被廣泛應用于評估模型在不同置信度閾值下的表現,并且是計算 mAP(平均平均精度)的基礎
AP 就是用來衡量一個訓練好的模型在識別每個類別時的表現好壞。AP 越高,說明模型在這個類別上的識別能力越強
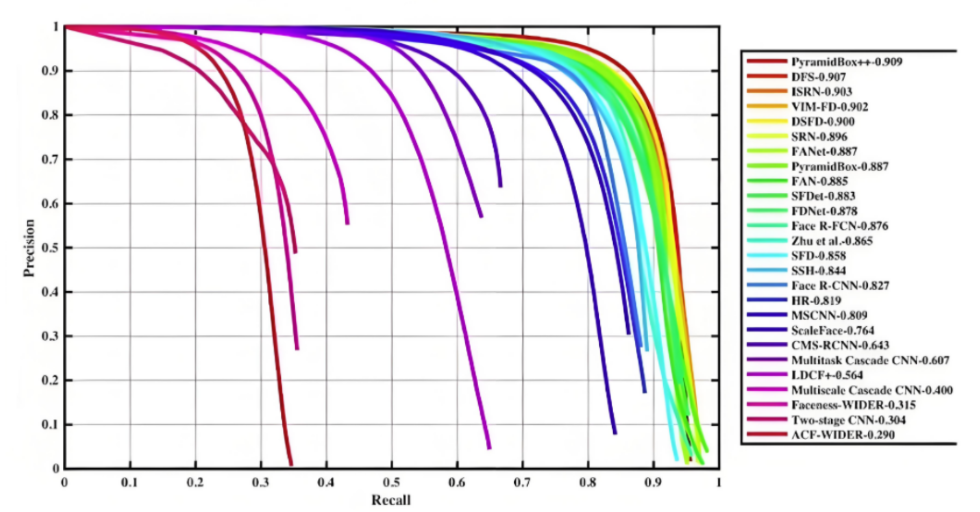
7.6.3 AP計算
11 點插值法:只需要選取當 Recall >= 0, 0.1, 0.2, …, 1 共11個點,找到所有大于等于該 Recall 值的點,并選取這些點中最大的 Precision 值作為該 Recall 下的代表值,然后 AP 就是這 11 個 Precision 的平均值

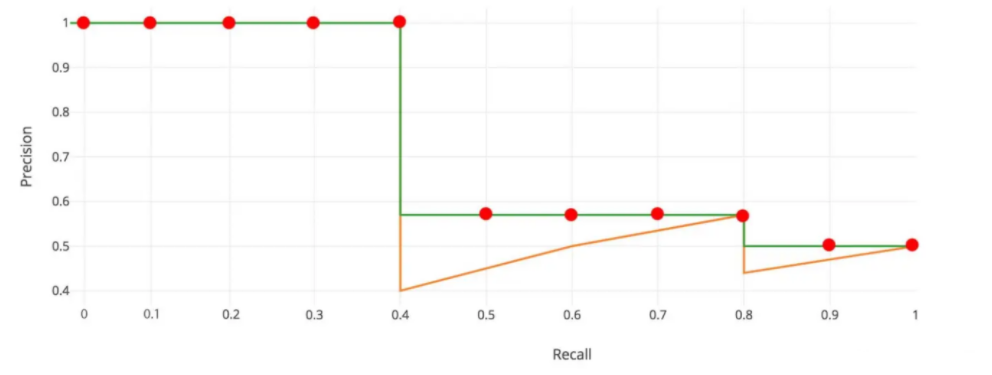
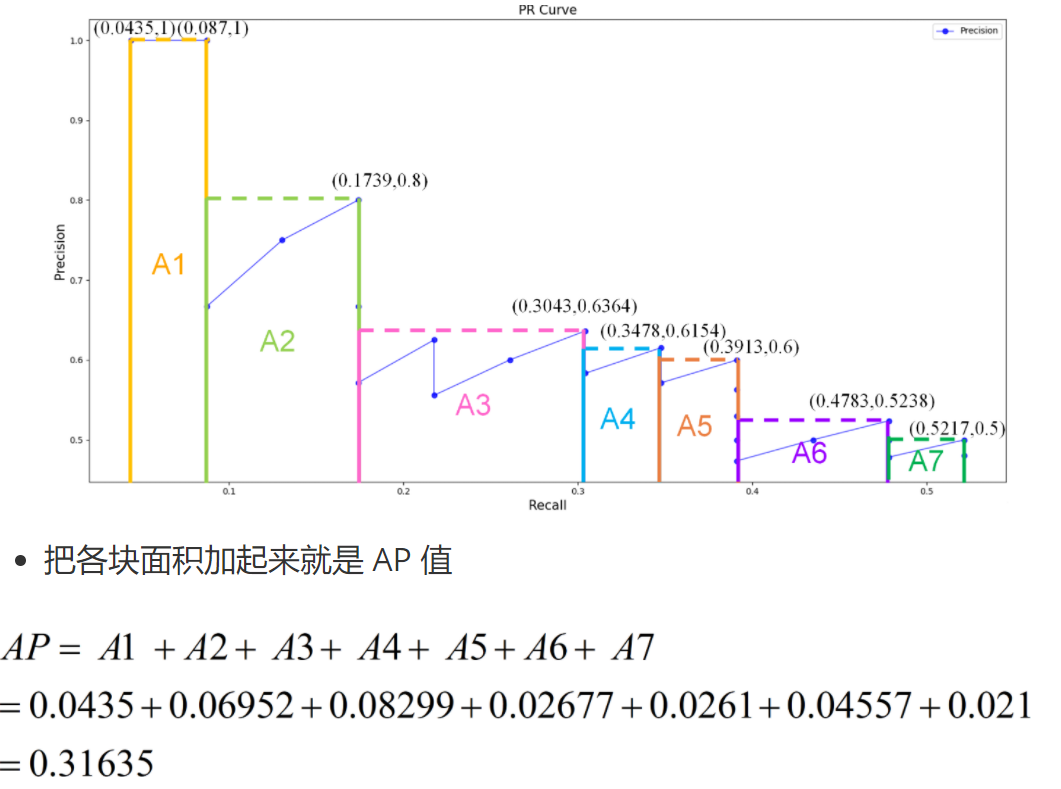
面積法:需要針對每一個不同的Recall值(包括0和1),選取其大于等于這些 Recall 值時的 Precision 最大值,然后計算 PR 曲線下面積作為 AP 值,假設真實目標數為 M,recall 取樣間隔為 [0, 1/M, …, M/M],假設有 8 個目標,recall 取值 = [0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0]
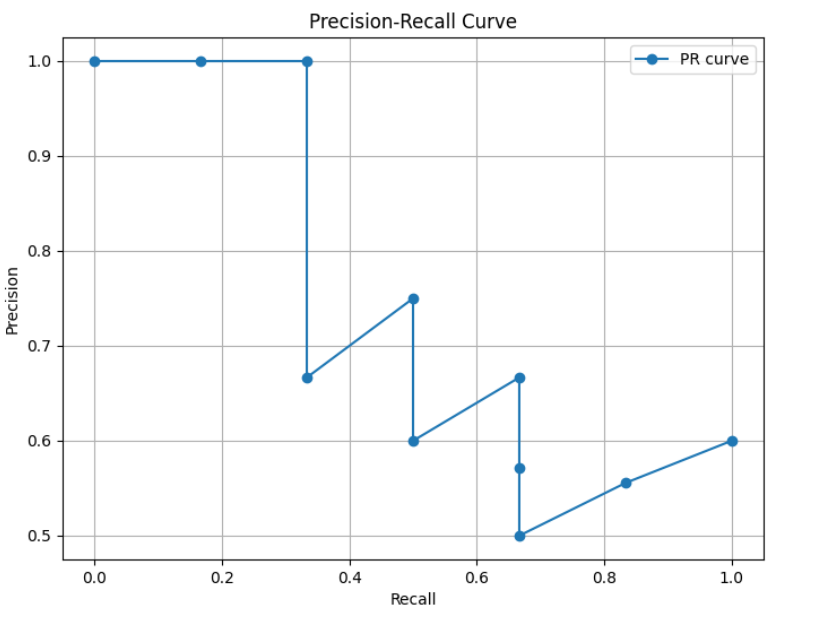
7.6.4? 繪制圖形
繪制 PR 曲線,計算 AP 值
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, average_precision_score# 真實標簽,表示每個樣本的實際類別
y_true = np.array([1, 1, 0, 1, 0, 1, 0, 0, 1, 1])
# 模型預測的概率分數,表示每個樣本屬于正類的可能性
probas_pred = np.array([0.9, 0.8, 0.7, 0.6, 0.55, 0.54, 0.53, 0.52, 0.51, 0.50])
# 計算精確度和召回率
precision, recall, thresholds = precision_recall_curve(y_true=y_true, probas_pred=probas_pred)
# 計算平均精確度
AP = average_precision_score(y_true=y_true, y_score=probas_pred)
print("平均精確度:", AP)
# 繪制PR曲線
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, marker='o', label='PR curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend()
plt.grid(True)
plt.show()運行結果:
7.6.5 mAP
平均平均精度(mean Average Precision,mAP) 是在不同置信度閾值下計算的平均精確度(Average Precision, AP)的平均值AP 是在不同召回率水平下的精確度平均值,而 mAP 則是多個類別上的 AP 的平均值
| 名稱 | 含義 | 說明 |
|---|---|---|
| AP(Average Precision) | 衡量模型在某一類別上的檢測或分類性能 | 通過 Precision-Recall 曲線下的面積來計算,值越高表示模型在該類別上的性能越好 |
| mAP(mean Average Precision) | 模型在所有類別上的 AP 的平均值 | 衡量模型整體性能的綜合指標,值越高表示模型在所有類別上的平均表現越好 |
mAP 計算步驟:
計算每個類別的 AP:對于數據集中包含的每個類別,分別計算 AP
計算 mAP:將所有類別的 AP 取平均值,得到 mAP
8、NMS后處理
非極大值抑制(Non-Maximum Suppression,NMS) 是目標檢測任務中常用的后處理技術,用于去除冗余的邊界框(Bounding Boxes),保留最有可能的檢測結果
在目標檢測中,模型通常會對同一目標生成多個邊界框(預測框),這些邊界框之間可能高度重疊。NMS 的作用就是篩選出置信度高、位置準確的邊界框,抑制其他冗余的預測框
NMS 的基本思想是:對于每一個預測的類別,按照預測邊界框的置信度(Confidence Score)對所有邊界框進行排序,然后依次考慮每個邊界框,將其與之前的邊界框進行比較,如果重疊度過高,則丟棄當前邊界框,保留置信度更高的那個,對于每個類別會獨立進行操作
NMS 的步驟:
設定目標框置信度閾值,常設置為 0.5,小于閾值的目標框被過濾掉
將所有預測的滿足置信度范圍的邊界框按照它們的置信度從高到低排序
選取置信度最高的框(不同類型分開處理)添加到輸出列表,并將其從候選框列表中刪除
對于當前正在考慮的邊界框,計算其與前面已選定的邊界框的重疊程度(IoU),如果當前邊界框與已選定邊界框的 IoU 大于某個閾值(如 0.5),則將其抑制(即不保留,重合度過高);否則保留當前邊界框,并繼續處理下一個邊界框
重復上述步驟,直到所有邊界框都被處理完畢
輸出列表就是最后留下來的目標框

9、檢測速度
9.1前向傳播耗時
前向傳播耗時是指從輸入圖像到輸出最終檢測結果所消耗的總時間(單位:毫秒 ms),包括以下三個階段:
前處理耗時(Preprocessing):
圖像歸一化(如 0~255 → 0~1)
圖像縮放、填充、通道轉換(如 BGR → RGB)
張量格式轉換(如 NHWC → NCHW)
網絡前向傳播耗時(Forward Pass):
模型推理過程,即從輸入圖像經過網絡各層計算得到輸出結果的時間
后處理耗時(Postprocessing):
應用非極大值抑制(NMS)
置信度過濾、類別篩選等
9.2 FPS
FPS(每秒幀數)是指模型每秒鐘可以處理的圖像幀數,是衡量實時性的重要指標,計算公式
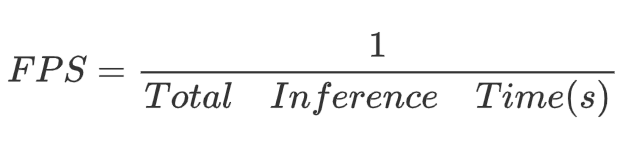
實時性要求:
實時檢測:通常要求 FPS ≥ 30
低延遲場景(如無人機、自動駕駛):要求 FPS ≥ 60
移動端/嵌入式設備:常要求在 15~25 FPS 之間達到可用性
9.3 FLOPS
FLOPS(Floating Point Operations Per Second,每秒浮點運算次數)是衡量計算設備性能的一個重要指標,特別是在高性能計算和深度學習領域。它表示設備在一秒內可以執行的浮點運算次數
| 單位 | 全稱 | 中文含義 | 數值表示 |
|---|---|---|---|
| KFLOPS | Kilo FLOPS | 千次浮點運算每秒 | 10^3FLOPS |
| MFLOPS | Mega FLOPS | 百萬次浮點運算每秒 | 10^6FLOPS |
| GFLOPS | Giga FLOPS(常用單位) | 十億次浮點運算每秒 | 10^9FLOPS |
| TFLOPS | Tera FLOPS | 萬億次浮點運算每秒 | 10^{12}FLOPS |
| PFLOPS | Peta FLOPS | 千萬億次浮點運算每秒 | 10^{15}FLOPS |
10、YOLO整體網絡結構
YOLO(You Only Look Once)是一類單階段目標檢測器(One-stage Detector),其核心特點是速度快、端到端推理。其網絡結構通常由以下 三個主要模塊 組成:Backbone(主干網絡)、Neck(頸部網絡)、Detection Head(檢測頭)
網絡結構圖:

內部結構圖:
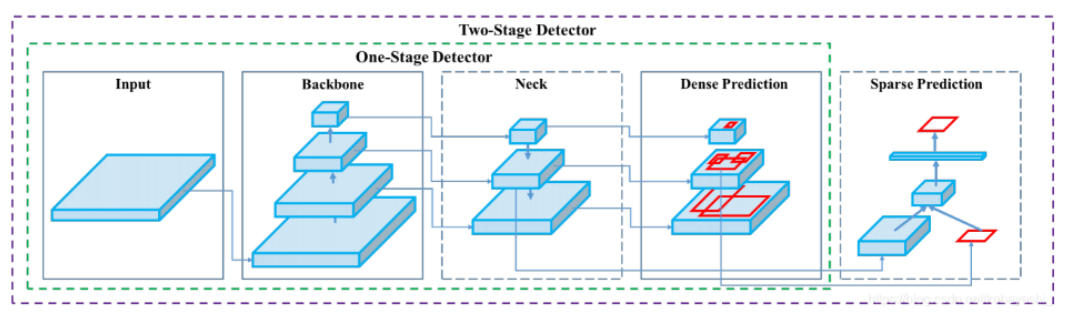
10.1 Backbone network
描述:
Backbone network,即主干網絡(骨干網絡),目標檢測網絡最為核心的部分,主要是使用不同的卷積神經網絡構建
任務:
特征提取:從輸入圖像中提取特征信息,這些特征通常包含豐富的信息,能夠幫助后續模塊進行目標檢測
10.2 Neck network
描述:
Neck network,即頸部網絡,主要對主干網絡輸出的特征進行整合
任務:
特征融合:將主干網絡提取的多尺度特征進行融合,以增強特征的表達能力和魯棒性
10.3 Detection head
描述:
Detection head,即檢測頭,在特征之上進行預測,包括物體的類別和位置
任務:
目標檢測:檢測頭的主要任務是基于融合后的特征圖,通過回歸任務預測邊界框的坐標,通過分類任務預測目標的類別,生成最終的檢測結果,包括邊界框和類別
10.4 總結
YOLOV1-YOLOV4:學習掌握 YOLO 作者的涉及思路和優化方式【理論】
YOLOV5 和 YOLO11:學習掌握使用 YOLO 開源算法完成模型的訓練、應用、優化等【實踐】
| Model | Backbone | Neck | Head |
|---|---|---|---|
| v1 | GoogLeNet | None | FC → 7×7×(2x5+20) |
| v2 | Darknet19 | Passthrough | 13×13×5×(5+20) |
| v3 | Darknet53 | FPN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) |
| v4 | Darknet53_CSP | SPP、FPN、PAN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) |
| v5 | Darknet53_CSP | SPP、cspFPN、cspPAN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) |




)












、查找子串(strncmp函數的應用)多維數組(一維數組指針、二維數組指針)、返回指針值函數、關鍵字(const))

