一、MySQL主從同步
1.1 主從同步是什么
-
MySQL 主從同步是一種數據復制機制,通過該機制可以實現將主數據庫(Master)的 DDL(數據定義語言)和 DML(數據操縱語言,如 update、insert、delete)等操作同步到從數據庫(Slave),從而保證主從數據庫的數據一致性。
-
這種機制在提高數據可用性、實現讀寫分離、進行數據備份與恢復等場景中發揮著重要作用。
1.2 主從同步原理
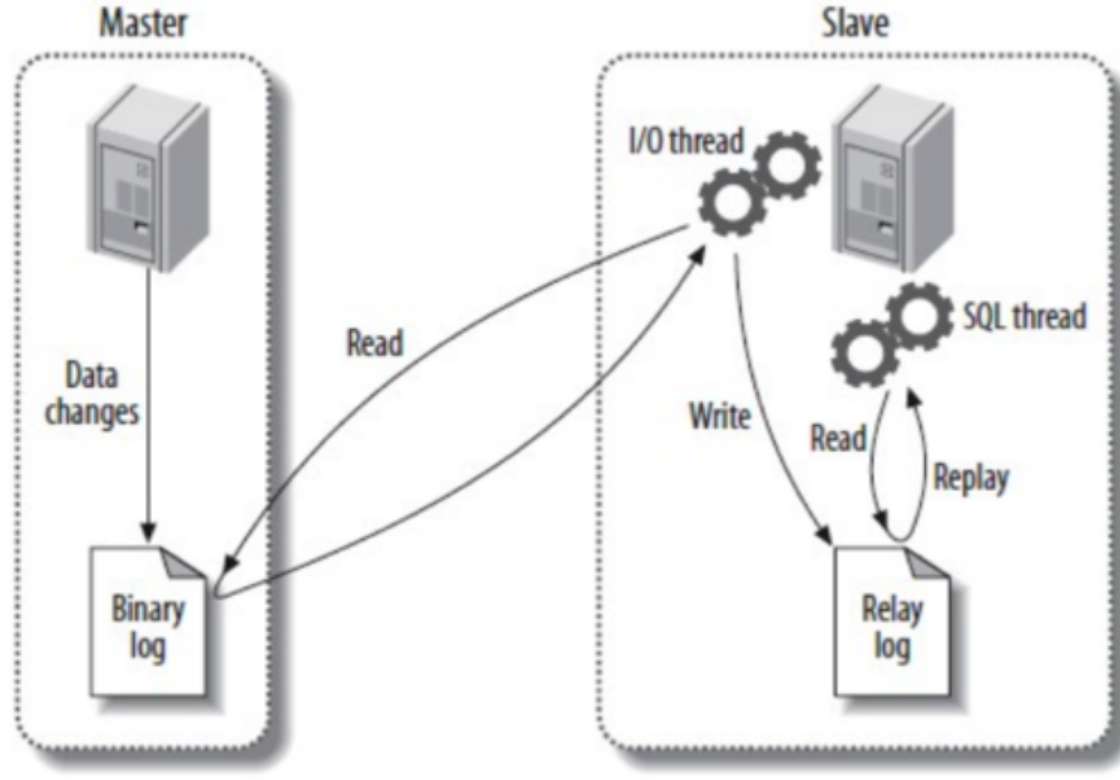
1.2.1 主從同步的組件
主從同步的實現依賴以下的組件:
-
binlog(二進制日志):主庫產生的日志文件,記錄了主庫上所有的數據變更操作(如創建表、插入數據等),是主從同步的基礎數據來源。
-
relay-log(中繼日志):從庫上的日志文件,用于存儲從主庫的 binlog 中復制過來的日志內容,相當于一個中間過渡的日志。
-
io-thread(IO 線程):
- 主庫的 IO 線程:負責接收從庫 IO 線程的請求,并將 binlog 中指定位置后的日志內容發送給從庫。
- 從庫的 IO 線程:負責連接主庫,請求并接收主庫發送的 binlog 日志,然后將其寫入從庫的 relay-log。
-
sql-thread(SQL 線程):從庫上的線程,負責讀取 relay-log 中的內容,并解析成具體的 SQL 語句在從庫上執行,實現數據的重放(replay),從而保證從庫與主庫數據一致。
-
master-info 文件:從庫上的文件,記錄了已讀取到的主庫 binlog 的文件名和位置,方便從庫下次請求主庫時明確起始讀取點。
1.2.2 主從同步的流程
主從同步的流程可以分為三部分:
- 主庫生成
binlog - 從庫獲取
binlog并寫入relay-log - 從庫重放中繼日志
主庫生成binlog
主庫執行 DML(如 update、insert、delete)或 DDL 操作后,會將這些操作記錄到自身的 binlog 中,完成數據變更的日志化存儲。
從庫獲取binlog并寫入relay-log
-
從庫的 IO 線程主動連接主庫,并請求從指定 binlog 文件的指定位置(首次可從最開始)之后的日志內容。
-
主庫接收到請求后,其負責復制的 IO 線程會根據請求的位置,讀取對應 binlog 中的日志信息,然后返回給從庫的 IO 線程。返回的信息除了日志內容,還包括當前主庫 binlog 的文件名和位置。
-
從庫的 IO 線程收到信息后,將日志內容追加到從庫的 relay-log 末尾,同時將主庫的 binlog 文件名和位置記錄到 master-info 文件中,為下一次請求提供起始點。
從庫重放中繼日志
從庫的 SQL 線程實時監測 relay-log,當發現有新增內容時,會解析這些內容,還原成主庫上執行過的具體 SQL 語句,并在從庫上執行這些語句,從而實現數據同步。
1.3 讀寫分離
MySQL 讀寫分離是基于主從同步機制實現的數據庫架構優化方案,其核心思想是將數據庫的寫操作(如 INSERT、UPDATE、DELETE)集中在主庫(Master)處理,而讀操作(如 SELECT)分散到從庫(Slave)執行,從而有效分擔主庫壓力、提升系統整體性能。
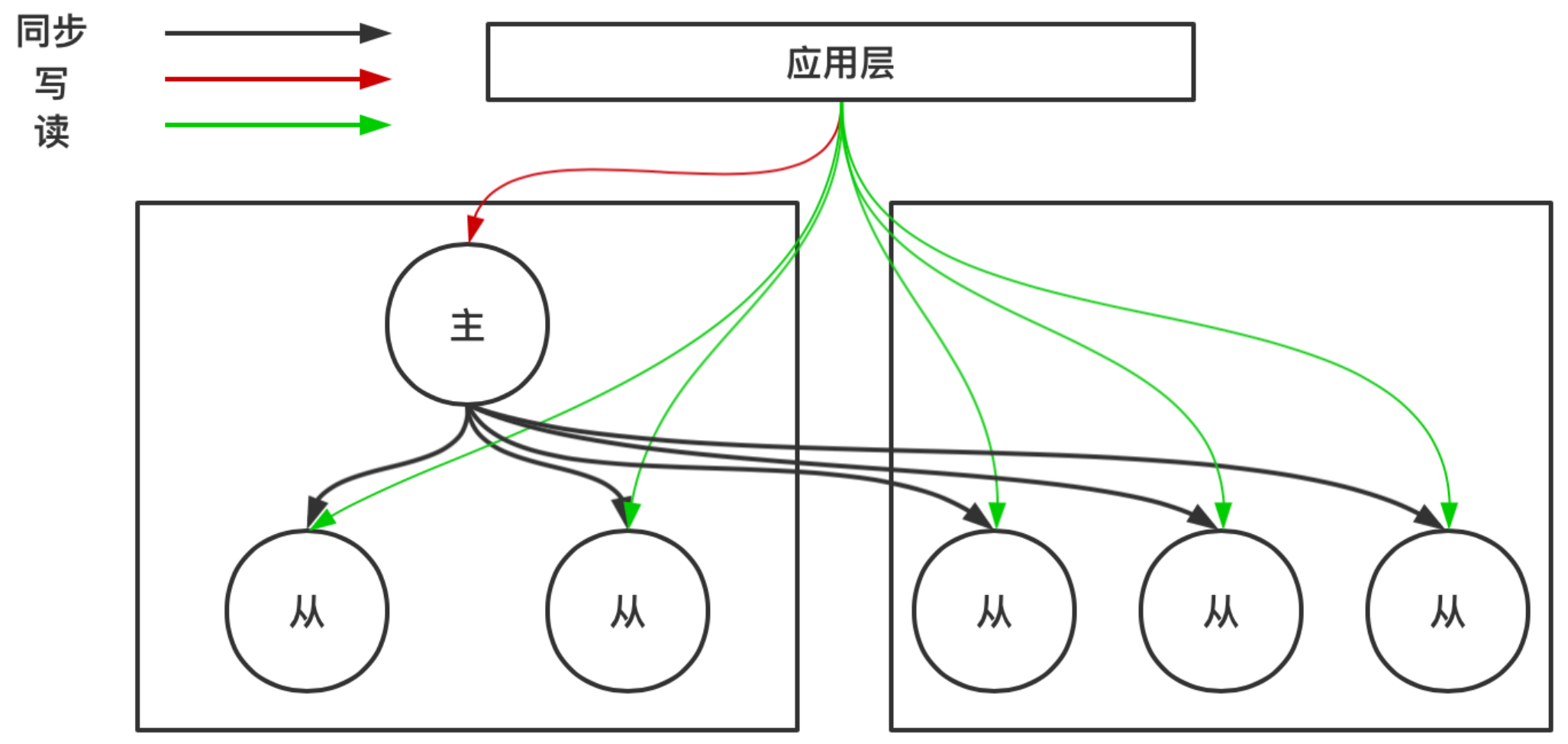
1.3.1 讀寫分離的優點
-
減輕主庫負載:主庫僅處理寫操作和必要的核心讀操作,避免因大量讀請求占用資源(如 CPU、IO)而影響寫操作效率。
-
提高讀操作吞吐量:通過多個從庫分擔讀請求,利用分布式部署的優勢提升系統整體的讀性能,支持更多并發查詢。
-
提升系統可用性:即使主庫故障,從庫仍可提供讀服務,減少業務中斷時間。
-
支持業務擴展:可根據讀請求壓力靈活增加從庫數量,實現橫向擴展,而無需修改核心業務邏輯。
1.3.2 讀寫分離的缺點
- 數據不一致:主從同步依賴 binlog 復制和 SQL 重放,從庫數據通常滯后于主庫,若寫操作后立即從從庫讀取,可能獲取舊數據,導致數據不一致
1.3.3 讀寫分離的適用場景
-
讀多寫少業務:如電商商品列表、新聞資訊、社交平臺動態等,讀請求量遠大于寫請求。
-
高并發查詢場景:單庫讀性能無法滿足并發需求(如秒殺活動中的商品庫存查詢),需通過從庫分擔壓力。
-
非核心寫操作場景:寫操作頻率低(如后臺數據錄入),主庫壓力小,適合通過從庫擴展讀能力。
1.4 MySQL緩沖層
在 “讀多寫少、以 MySQL 為核心數據源、Redis 為緩存層” 的場景中,基于 MySQL 與 Redis 的緩存策略核是利用 Redis 的內存級讀寫速度提升讀性能,同時通過合理的同步機制保證緩存與 MySQL 的數據一致性,避免因緩存引入臟數據或業務異常
1.4.1 為什么需要引入Redis
-
MySQL也有緩沖層,它的作用是用來緩存熱點數據,這些數據包括索引、記錄等,mysql 緩沖層是從自身出發,跟具體的業務無關,緩沖策略主要是 LRU,由于 mysql 的緩沖層(buffer pool)不由用戶來控制,也就不能由用戶來控制緩存具體數據
-
MySQL 數據主要存儲在磁盤當中,適合大量重要數據的存儲。磁盤當中的數據一般是遠大于內存當中的數據,一般業務場景關系型數據庫(mysql)作為主要數據庫;
-
Redis是內存數據庫,它的所有數據都存儲在內存當中,當然也可以持久化到磁盤中,因此它的速度很快,很適合作為MySQL的緩存,存儲與業務相關的熱點數據,這些熱點數據可以由用戶自己定義
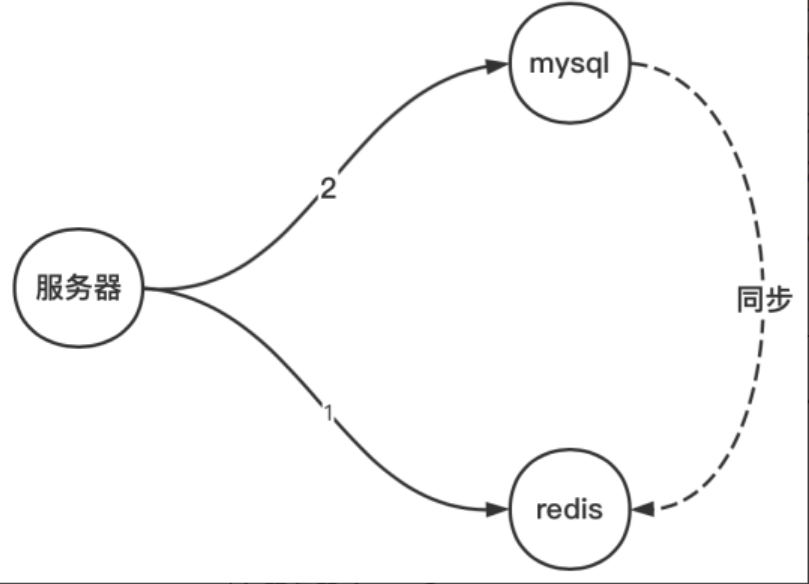
1.4.2 MySQL和Redis的同步問題
我們這里討論的數據基于用戶定義的熱點數據,當引入 Redis 后,緩存與 MySQL 的數據可能存在 5 種狀態:
- MySQL有,緩存無(正常)
- MySQL有,緩存有(正常)
- 二者都有,數據一致(正常)
- MySQL無,緩存有(不正常)
- 二者都有,數據不一致(不正常)
-
需要明確的是,我們獲取數據主要依據MySQL為主,如果緩存中不存在,那么我們只需要將MySQL中的數據同步到緩存即可,沒有什么大問題
-
如果緩存有,但是MySQL沒有,這樣就會產生臟數據
-
如果MySQL和緩存都有這個數據,但是數據不一致,這樣也會有問題
1.4.3 同步問題解決方案
解決方案1
讀數據:
- 先從緩存獲取,如果有直接返回
- 如果沒有,從MySQL中獲取
- 如果MySQL有,同步到緩存并返回
- 如果MySQL沒有,返回空
作用:
- 通過 “緩存未命中時從 MySQL 加載并同步”,保證緩存數據最終與 MySQL 一致
寫數據:
- 先刪除緩存,再寫MySQL,后續數據同步使用中間件
go-mysql-transfer等中間件處理
作用:
- 避免 “緩存與 MySQL 數據不一致”:刪除緩存后,寫 MySQL 期間緩存為空,其他服務讀時會直接查 MySQL,拿到最新數據并同步到緩存
- 保證 “寫后立即讀” 的正確性:服務 A 寫完 MySQL 后立即讀數據時,因緩存已被刪除,讀流程會查 MySQL 拿到最新數據
問題:
- 中間件同步延遲:若中間件同步緩存的過程延遲,緩存會在短時間內為空,此時讀請求全部走 MySQL,可能短暫增加 MySQL 壓力
解決方案2
讀數據:
- 先從緩存獲取,如果有直接返回
- 如果沒有,從MySQL中獲取
- 如果MySQL有,同步到緩存并返回
- 如果MySQL沒有,返回空
作用:讀數據的流程和解決方案1完全一致
寫數據:
- 先寫緩存,并設置過期時間(如200ms),再寫MySQL
- 后續數據同步使用中間件實現
作用:
-
減少緩存空窗期:寫操作后 Redis 立即有新數據(而非像策略 1 那樣先刪除),短時間內讀請求可直接從 Redis 獲取,減輕 MySQL 壓力。
-
控制臟數據時長:即使 MySQL 寫入失敗,臟數據僅存在 200ms,過期后緩存失效,讀請求會查 MySQL 拿到正確狀態
問題:
- 短暫臟數據:若 MySQL 寫入失敗,Redis 中 200ms 內的新數據是 “假數據”,可能導致用戶看到錯誤信息
1.4.3 其他緩存問題
在 MySQL 與 Redis 組成的緩存架構中,由于數據同步策略、并發請求及緩存特性等因素,可能出現緩存穿透、緩存擊穿、緩存雪崩三種典型問題
1.4.3.1 緩存穿透
當請求查詢的數據在 Redis 中不存在,且在 MySQL 中也不存在時,該請求會繞過 Redis 直接穿透到MySQL,若此類請求大量并發,會導致 MySQL 壓力劇增,甚至崩潰
原因:請求的是 “不存在的數據”,緩存(Redis)和數據庫(MySQL)均無記錄,導致每次請求都直接訪問
數據庫
解決方案:
-
緩存空值(<key, nil>)
- 當 MySQL 中查詢到數據不存在時,在 Redis 中緩存該 key 對應的空值(如
nil),并設置較短的過期時間(如幾分鐘)。 - 下次相同請求會直接從 Redis 獲取空值,避免穿透到 MySQL。
- 當 MySQL 中查詢到數據不存在時,在 Redis 中緩存該 key 對應的空值(如
-
布隆過濾器
- 預先將 MySQL 中所有存在的 key 存入布隆過濾器(一種高效的概率性數據結構)。
- 請求到來時,先通過布隆過濾器判斷 key 是否可能存在:
- 若不存在,直接返回空結果,避免訪問 Redis 和 MySQL;
- 若可能存在,再依次查詢 Redis 和 MySQL。
1.4.3.2 緩存擊穿
當某個熱點數據在 Redis 中過期(或不存在),但在 MySQL 中存在時,大量并發請求會同時穿透到 MySQL 讀取該數據,導致 MySQL 瞬間壓力驟增
原因:熱點數據的緩存失效,引發并發請求集中訪問數據庫。
解決方案:
-
分布式鎖
- 當 Redis 中查詢不到數據時,先嘗試獲取分布式鎖,只有獲取鎖的請求才能訪問 MySQL。
- 該請求從 MySQL 讀取數據后,更新 Redis 緩存,再釋放鎖;其他未獲取到鎖的請求則休眠一段時間后重試,直到從 Redis 中獲取到數據。
-
熱點 key 永不過期
- 對于訪問頻率極高的熱點數據,在 Redis 中設置為永不過期,避免因過期導致的緩存失效。
1.4.3.3 緩存雪崩
在某一時間段內,Redis 中大量緩存 key 集中過期失效,或 Redis 服務宕機,導致大量請求無法從緩存獲取數據,全部涌向 MySQL,造成 MySQL 壓力過載,甚至整個系統服務崩潰
原因:
- 緩存集中失效(如大量 key 設置了相同的過期時間);
- Redis 集群宕機(如節點故障、網絡問題);
- 系統重啟導致 Redis 緩存數據丟失(未開啟持久化或重啟時間過長)。
解決方案:
-
避免緩存集中失效
- 過期時間隨機化:為 key 設置過期時間時,在基礎時間上增加隨機值,避免大量 key 同時過期。
- 分批更新緩存:對熱點數據的緩存過期時間進行錯峰設計,通過定時任務分批刷新,避免集中失效。
-
Redis 高可用集群
- 采用 Redis 哨兵模式(Sentinel)或集群模式(Cluster),確保單個節點宕機時,其他節點能自動接管服務,避免 Redis 整體不可用。
-
緩存持久化與預熱
- 開啟持久化:Redis 開啟 RDB 或 AOF 持久化,確保重啟時能恢復緩存數據(包括過期信息)。
- 熱數據預熱:若系統重啟時間較長,重啟前通過腳本將 MySQL 中的熱點數據提前加載到 Redis,避免重啟后緩存為空導致請求沖擊數據庫。
更多資料:https://github.com/0voice
).decode(‘utf-8‘)作用)


















