CLIP
數據大小
- 4億個文本-圖像對,而且是高質量的
預訓練方法
Text encoder
“The text sequence is bracketed with [SOS] and [EOS] tokens and the activations of the highest layer of the transformer at the [EOS] token are used as the feature representation” ([Radford 等, 2021, p. 4]
🔤文本序列用 [SOS] 和 [EOS] 令牌括起來,并使用 [EOS] 令牌處變壓器最高層的激活作為特征表示🔤
text encoder一個簡單的transformer模型,可以類別Bert,采用了類似的完型填空等等方法預訓練。特點是每個句子都有類似[CLS]的特殊含義token。- 簡單來說就是一個句子過去,經過text encoder后,形狀應該是
(batch_size,sequence_length,dim),現在我們只要首個[EOS]token作為特征向量,因此最終得到的特征維度是(batch_size,1,dim)=(batch_size,dim)
Image encoder
We make several modifications to the original version using the ResNetD improvements from He et al. (2019) and the antialiased rect-2 blur pooling from Zhang (2019). We also replace the global average pooling layer with an attention pooling mechanism. The attention pooling is implemented as a single layer of “transformer-style” multi-head QKV attention where the query is conditioned on the global average-pooled representation of the image. For the second architecture, we experiment with the recently introduced Vision Transformer (ViT) (Dosovitskiy et al., 2020).
我們使用He等人(2019)的ResNetD改進和Zhang(2019)的抗鋸齒rect-2模糊池對原始版本進行了一些修改。我們還將全局平均池化層替換為注意力池化機制。注意力池被實現為一個單層的“變壓器式”多頭QKV注意力,其中查詢是基于圖像的全局平均池表示。對于第二個架構,我們使用最近引入的視覺變壓器(ViT)進行實驗(Dosovitskiy等人,2020)。
- 簡單來說就是卷積網絡ResNet和VIT。
- 得到的特征就是
(batch_size,dim)
對比學習
- 正例就是預先構建的文本-圖像對,負例就是其他不匹配的對。
- 方法是兩兩算cosine相似度,然后得到一個大小為
(n,n)的相似度矩陣。
損失計算
- 損失不是直接構建對角線為1,其余元素為0的標簽矩陣實現的。
- CLIP是通過分別按行和按列來計算交叉熵來計算損失的。

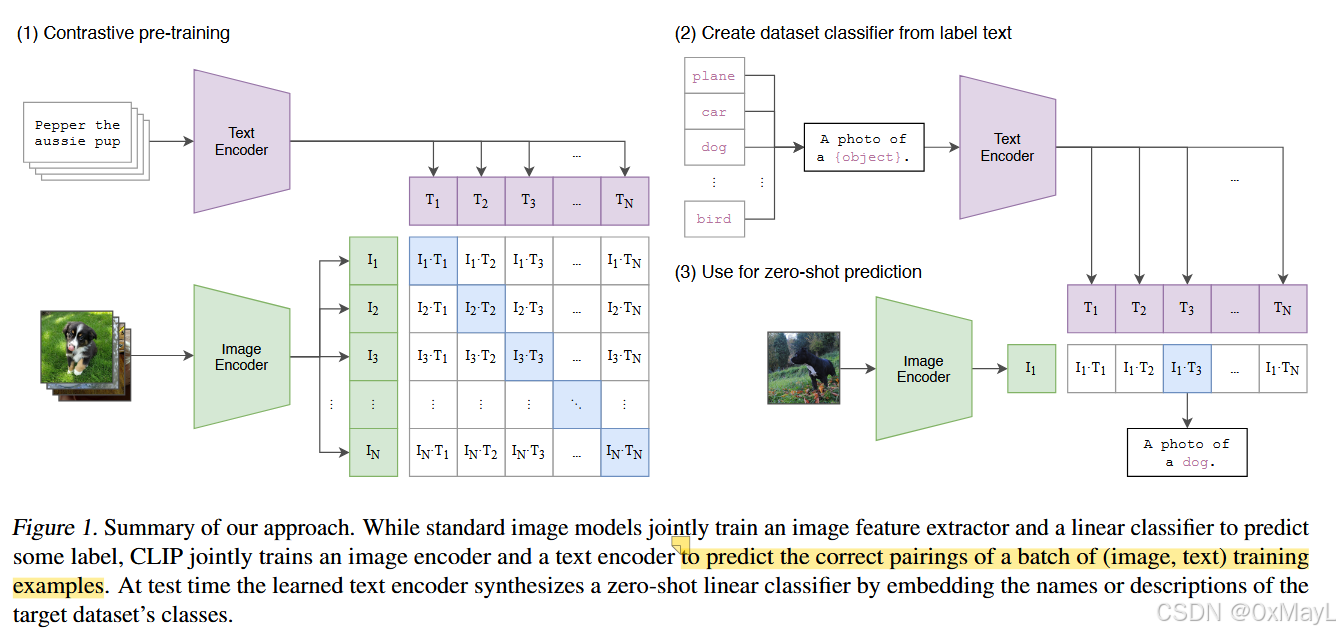
推理
For each dataset, we use the names of all the classes in the dataset as the set of potential text pairings and predict the most probable (image, text) pair according to CLIP. We additionally experiment with providing CLIP with text prompts to help specify the task as well as ensembling multiple of these templates in order to boost performance. However, since the vast majority of unsupervised and self-supervised computer vision research focuses on representation learning, we also investigate this for CLIP using the common linear probe protocol.
對于每個數據集,我們使用數據集中所有類的名稱作為潛在文本配對的集合,并根據CLIP預測最可能的(圖像,文本)配對。我們還嘗試為CLIP提供文本提示以幫助指定任務,并集成多個模板以提高性能。然而,由于絕大多數無監督和自監督計算機視覺研究都集中在表示學習上,我們也使用通用線性探測協議對CLIP進行了研究。

設計原則之開閉原則)
![[Linux入門] Linux 網絡設置入門:從查看、測試到配置全攻略](http://pic.xiahunao.cn/[Linux入門] Linux 網絡設置入門:從查看、測試到配置全攻略)










)



)

