摘要
????????ClickHouse物化視圖通過預計算和自動更新機制,顯著提升大數據分析查詢性能,尤其適合高并發聚合場景。本文將深入解析其技術原理、生產實踐中的優化策略,以及數據遷移的實戰經驗。
一、物化視圖核心概念
????????ClickHouse的物化視圖(Materialized View)是一種?預計算技術?,它將查詢結果持久化存儲,當基表數據變化時自動更新。與普通視圖不同,物化視圖實際占用存儲空間,但能顯著提升查詢性能,特別適合以下場景:
- 高頻執行的聚合查詢
- 需要實時分析的大數據量場景
- 多維度組合分析需求
在騰訊云的實際項目中,物化視圖集群成功支撐了?5000+ QPS?的高并發查詢,證明了其在生產環境中的可靠性。
二、技術架構與實現原理
2.1 底層機制
????????ClickHouse物化視圖通過?觸發器機制?實現數據同步,當源表發生INSERT操作時自動更新。其核心組件包括:
- ?存儲引擎?:默認使用與原表相同的引擎(通常為MergeTree系列)
- ?更新策略?:支持全量刷新和增量更新兩種模式
- ?查詢重寫?:優化器會自動將適合的查詢路由到物化視圖
2.1.1 存儲引擎?
1. ClickHouse物化視圖存儲引擎與原表相同的原因
?原因分類? | ?具體說明? | ?示例/影響? |
?數據一致性保障? | 物化視圖是原表的衍生數據,相同引擎確保索引結構、分區策略等特性一致 | 原表使用ReplicatedMergeTree時,物化視圖自動繼承副本同步機制 |
?性能對齊? | 相同引擎的壓縮算法、存儲格式一致,減少ETL過程中的轉換開銷 | 共享底層數據分片策略,優化分布式查詢性能 |
?功能兼容性? | 特定功能(如TTL、數據跳過索引)僅在部分引擎中支持,引擎不一致會導致功能失效 | 若原表支持TTL而物化視圖引擎不支持,則數據自動清理功能無法生效 |
2. ClickHouse存儲引擎分類表
?引擎類型? | ?核心特性? | ?適用場景? | ?是否支持物化視圖? |
?MergeTree系列? | 列存/分區/主鍵索引/數據壓縮 | 大規模數據分析(默認推薦) | 是 |
ReplicatedMergeTree | 增加副本同步與故障恢復能力 | 高可用生產環境 | 是 |
Memory | 純內存存儲,無持久化 | 臨時數據/高速緩存 | 否 |
Log | 輕量級日志存儲,追加寫入 | 流式數據日志 | 否 |
Kafka | 直接消費Kafka消息流 | 實時數據管道 | 否 |
MySQL | 映射外部MySQL表 | 跨數據庫查詢 | 否 |
Dictionary | 內置字典數據存儲 | 維度表/配置表 | 否 |
2.1.2 更新策略
?操作類型? | ?是否支持? | ?具體行為? | ?實現方式與限制? |
?增量插入? | ? 支持 | 自動同步源表INSERT的新數據 | 依賴源表插入事件觸發,僅追加新數據塊(無法修改歷史數據) |
?全量刷新? | ?? 間接支持 | 完全重建物化視圖數據(覆蓋舊版本) | 需手動執行REFRESH或替換表,資源消耗高 |
?數據更新? (含修改/刪除) | ? 不支持 | 無法直接更新或刪除物化視圖中的已有數據 | 源表的UPDATE/DELETE不會同步到物化視圖,需全量刷新或通過ReplacingMergeTree等方案繞行 |
????????ReplacingMergeTree是ClickHouse專門用于處理數據更新的引擎,通過版本號字段實現?去重合并?機制:
- 相同排序鍵(ORDER BY字段)的數據行會被視為同一邏輯記錄
- 后臺合并時保留版本號最大的記錄(或根據其他策略)
- 最終實現類似"更新"的效果?
示例
CREATE TABLE example_table
(id UInt32,name String,value Float64,version UInt32, -- 版本號字段event_time DateTime
)
ENGINE = ReplacingMergeTree(version)
ORDER BY (id, name)- version字段作為合并依據,數值大的會覆蓋小的
- ORDER BY定義去重邏輯(相當于主鍵)?
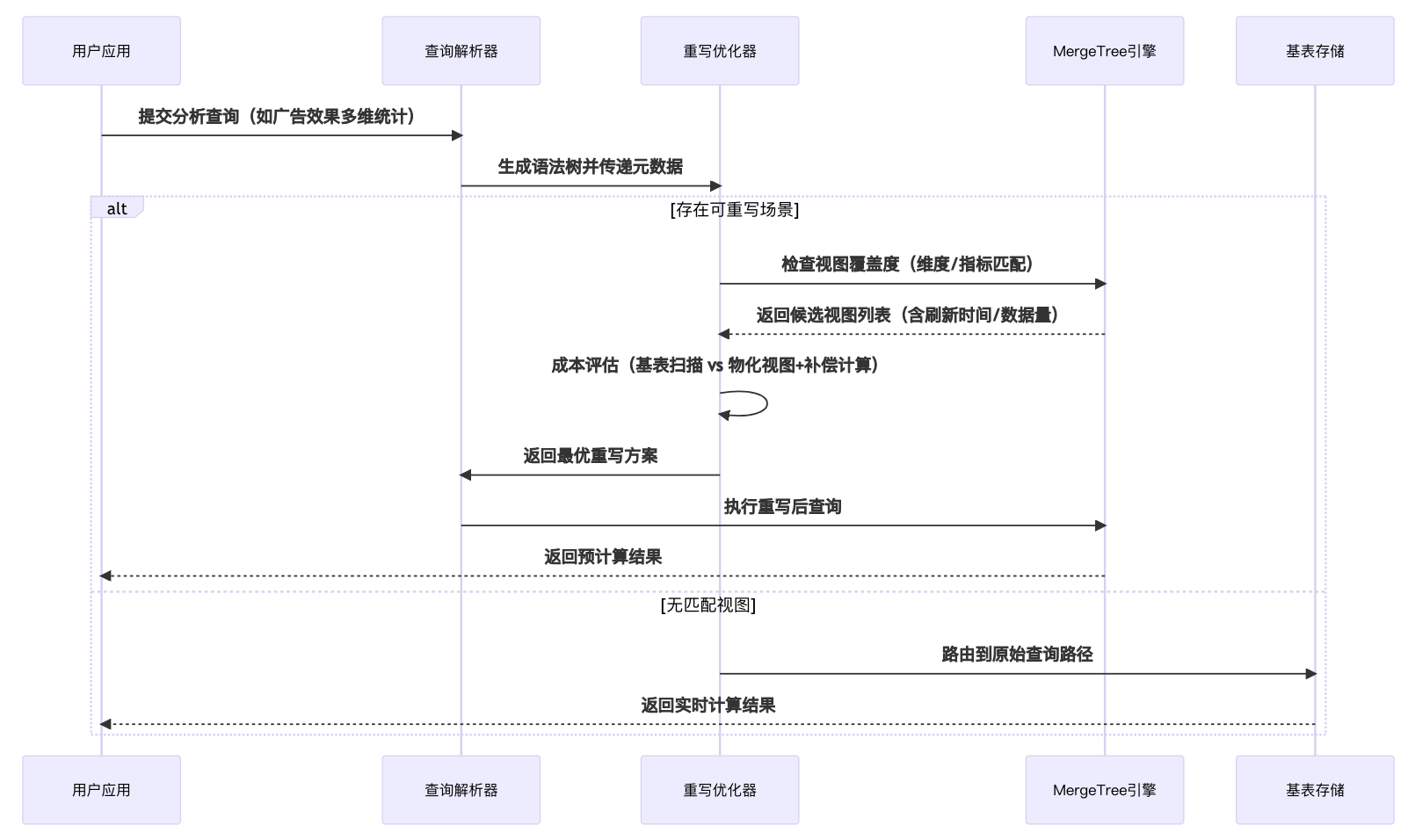
2.1.3 查詢重寫
????????是指數據庫優化器自動將針對基表的查詢轉換為對物化視圖的查詢,從而提升性能的技術。當滿足條件時,優化器會"路由"(即重定向)查詢到已預計算好的物化視圖,避免重復計算原始數據。
自動路由機制詳解
- 匹配條件?:查詢的SELECT/WHERE/GROUP BY等子句與物化視圖定義邏輯兼容
- ?數據覆蓋?:物化視圖包含查詢所需的所有數據(或可通過計算派生)
- ?時效性?:物化視圖數據滿足查詢的時效性要求(特別是增量更新場景)
工作原理時序圖如下:
2. 與分層架構的結合
在騰訊云項目中,物化視圖與數據分層架構深度整合:
原始底表 → DWD(輕聚合明細層) → DWS(指標服務層) → 物化視圖
數據分層架構:
層級 | 名稱 | 技術實現 | 數據處理方式 | 項目應用案例 | 優化效果 |
ODS | 原始數據層 | Flink實時采集+Kafka管道 | 無加工原始日志存儲 | 用戶行為事件原始日志 | 保留完整數據溯源能力 |
DWD | 明細數據層 | Flink窗口聚合+維度關聯 | 輕度清洗標準化 | 廣告點擊與訂單關聯明細表 | 查詢復雜度降低40% |
DWS | 服務數據層 | ClickHouse物化視圖預聚合 | 多維度指標計算 | 廣告效果分析聚合表(PV/UV/CTR) | 支撐5000+ QPS查詢 |
ADS | 應用數據層 | 動態查詢接口+Redis緩存 | 業務定制聚合 | 傭金結算實時報表API | 響應時間<300ms |
三、最佳實踐要點:ClickHouse物化視圖生產級管理
3.1 庫表規劃原則
對象類型 | 命名規范 | 存儲策略 | 案例 |
基表 | ods_[業務域]_原始表名 | 按日期分區+TTL 7天 | ods_adsdk_click_log |
物化視圖表 | mview_[聚合維度]_指標 | 與基表同分區策略+TTL 30天 | mview_advertiser_daily_stats |
中間過程表 | tmp_[用途]_日期 | 內存表或MergeTree臨時分區 | tmp_uv_calc_202407 |
?關鍵建議:?
- 使用ON CLUSTER語句統一創建分布式對象
- 為物化視圖單獨建立數據庫(如mviews)隔離資源
3.2 安全變更流程(生產環境)
-- 錯誤做法(阻塞寫入且資源消耗大)
CREATE MATERIALIZED VIEW mview_stats
ENGINE=ReplicatedMergeTree
POPULATE -- 全量初始化會導致表鎖
AS SELECT...-- 正確做法(分步執行)
-- 1. 創建空視圖
CREATE MATERIALIZED VIEW mview_stats
ENGINE=ReplicatedMergeTree
AS SELECT... WHERE 1=0-- 2. 分批插入歷史數據
INSERT INTO mview_stats
WITH 3000000 AS batch_size
SELECT * FROM source_table
WHERE create_time <= '2024-07-01'
LIMIT batch_size
-- 循環執行直到覆蓋全部歷史數據3.3 維度控制黃金法則
- ?基數控制?:單個物化視圖的維度組合不超過5個(如advertiser_id×campaign_id×day)
- ?聚合粒度?:預聚合到可接受的最粗粒度(分鐘級→小時級)
- ?字段選擇?:僅包含查詢必需的列,避免SELECT *
四、數據遷移中的物化視圖處理
?1. 分布式環境遷移核心挑戰?
- 物化視圖不會自動分片?:直接使用CREATE MATERIALIZED VIEW ON CLUSTER會導致數據分布不均
- ?數據一致性風險?:基表與物化視圖存在時間差時可能產生臟數據
- ?性能瓶頸?:全量遷移可能阻塞生產查詢
?2. 遷移方案
以下是簡版遷移腳本:
#!/bin/bash
# 物化視圖友好型遷移腳本
# 版本:v2.1-mv-safe# ===== 安全配置 =====
NODES=("node1" "node2" "node3" "node4" "node5") # 邏輯節點標識
TIME_RANGE=("2023-01-01" "2023-12-31")
CHUNK_SIZE=500000 # 每批處理量# ===== 執行遷移 =====
for node in "${NODES[@]}"; doclickhouse-client -h $node --query "INSERT INTO dwd_retail.sales_factSELECT order_id, -- 示例字段customer_code, -- 已脫敏amount,create_timeFROM ods_retail.sales_sourceWHERE create_time BETWEEN '${TIME_RANGE[0]}' AND '${TIME_RANGE[1]}'LIMIT ${CHUNK_SIZE}-- 關鍵優化參數(無事務保證):SET max_insert_block_size = ${CHUNK_SIZE};SET max_threads = 8; -- 根據CPU核數調整SET parallel_view_processing=1; -- 允許物化視圖并行處理"
done?3. 生產環境必須遵守的規則?
風險點 | 解決方案 |
?ZK鎖沖突? | 每個分片單獨執行腳本,禁止并發創建相同物化視圖 |
?數據丟失? | 先遷移基表數據,驗證通過后再創建物化視圖 |
?查詢中斷? | 通過SET max_execution_time=300控制單批執行時間 |
?4. 遷移后的校驗方法?
- ?記錄數校驗缺陷?
????????物化視圖的聚合粒度受時間窗口影響,相同源數據可能因條件不同產生不同記錄數,僅用count()校驗會存在誤判。
- ?物化視圖數據校驗策略表?
?校驗維度? | ?校驗方法? | ?檢測目標? | ?實施頻率? | ?異常處理? | ?技術實現? |
?基礎完整性校驗? | SELECT hostName(), count(), uniqExact(order_no) FROM source_table GROUP BY shard | 分片數據是否完整 | 每次遷移后立即執行 | 觸發數據重傳機制 | 分布式計數+唯一鍵校驗 |
?金額總和比對? | ABS((SELECT sum(amt) FROM source) - (SELECT sum(amt) FROM mview)) < 0.001 | 聚合金額一致性 | 每日全量校驗 | 記錄差異明細并告警 | 高精度Decimal計算 |
?時間窗口覆蓋? | SELECT min(insert_time), max(insert_time) FROM mview WHERE day = '2025-07-18' | 物化視圖是否覆蓋完整時間范圍 | 按批次校驗 | 補數缺失時間段 | 時間區間邊界檢測 |
?維度下鉆校驗? | WITH dim_diff AS ( SELECT ka_id FROM source_dim EXCEPT SELECT ka_id FROM mview_dim ) SELECT count() FROM dim_diff | 關鍵維度是否缺失 | 每周全量掃描 | 觸發維度表刷新 | 維度差異分析(EXCEPT子句) |
?分布式一致性? | SELECT hostName(), sum(amt) FROM mview GROUP BY shard HAVING abs(sum - avg_sum) > threshold | 分片間數據分布是否均衡 | 隨機抽查 | 重新平衡分片 | 分片級聚合比對 |
?數據新鮮度? | SELECT now() - max(update_time) FROM mview WHERE day = '2025-07-18' | 數據更新是否及時 | 每小時監控 | 觸發物化視圖刷新 | 時間間隔監控 |
?業務規則校驗? | SELECT count() FROM mview WHERE paid_amount > 0 AND order_status = 'CANCELED' | 違反業務規則的數據 | 按需執行 | 數據修復工單 | 自定義規則引擎 |
?歷史數據追溯? | SELECT sumIf(amt, day = '2025-07-18') FROM mview FINAL | MV與源表歷史版本一致性 | 每月歸檔時校驗 | 使用FINAL關鍵字強制合并 | ReplacingMergeTree引擎專用校驗 |
我采用了如下校驗策略:

?5. 特別注意事項?
- ?時間片選擇?:腳本中需要根據數據密度調整時間參數,例如:
- 高頻數據:10-30分鐘為時間窗口
- 低頻數據:4-8小時為時間窗口
- ?錯誤恢復?:記錄每批次的MIN_TIME/MAX_TIME,失敗時可從斷點續傳
五、性能優化策略
1. 設計原則
- ?聚合粒度?:根據查詢模式選擇適當的聚合維度
- ?字段精簡?:只包含必要字段,減少存儲和計算開銷
- ?TTL設置?:為歷史數據設置合理的生命周期
2. 實戰優化技巧
- ?預聚合計算?:將分鐘級數據預聚合為小時/天級別
- ?多級物化?:構建層級式物化視圖金字塔
- ?資源隔離?:為物化視圖更新分配獨立資源池
六、與替代方案對比
方案 | 查詢性能 | 數據實時性 | 存儲開銷 | 適用場景 |
物化視圖 | ★★★★★ | ★★★★ | ★★★ | 高頻聚合查詢 |
普通視圖 | ★★ | ★★★★★ | ★ | 臨時分析 |
預聚合表 | ★★★★ | ★★ | ★★★★ | 固定維度分析 |
實時計算 | ★★★ | ★★★★★ | ★★ | 復雜事件處理 |
七、結論?
????????物化視圖作為數據庫性能優化的利器,其核心價值在于通過?預計算+持久化?的架構思想,將查詢時的計算壓力前置到寫入階段。這種設計在實時分析、聚合統計等場景下能帶來顯著的查詢加速效果,但同時也對存儲資源和數據一致性管理提出了更高要求。
????????在實際應用中,開發者需要權衡?查詢性能提升?與?存儲/維護成本?之間的關系:
- 對于高頻分析的固定維度聚合,物化視圖能帶來數量級的性能提升
- 需配套設計基表更新策略和TTL機制,避免"物化膨脹"問題
- 在分布式系統中要特別注意跨節點數據一致性的處理????????
????????隨著實時數倉的發展,物化視圖技術正在與流式計算、增量更新等能力深度融合,成為現代數據架構中不可或缺的加速層組件。
)


















