前言
上篇文章給大家介紹了DTL模板結構
這篇文章將講述Django框架與MySQL數據庫的綜合使用
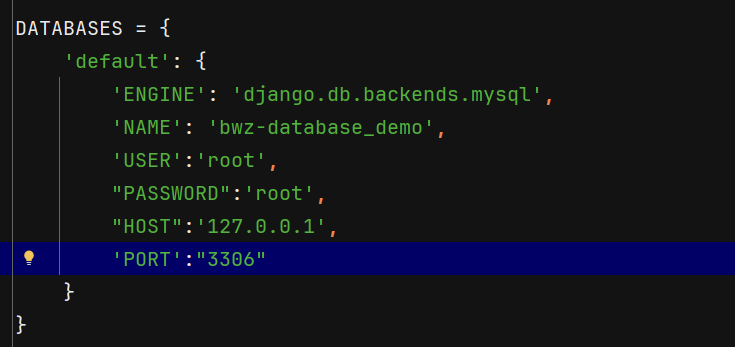
一、Django配置連接數據庫
在操作數據庫之前,首先先要連接數據庫,這里我們以配置MySQL為例來講解。Diango連接數據庫,不需要單獨的創建一個連接對象。 只需要在 settings.py 文件中做好數據庫相關的配置就可以了。
二、在Django中操作數據庫(原生SQL語句操作)
在Django 中操作數據庫有兩種方式。第一種方式就是使用原生SQL語句操作,第二種就是使用ORM模型來操作。
在Django中使用原生 SQL 語句操作其實就是使用 python db api的接口來操作。如果你的mysql驅動使用的是pymysql,那么你就是使用 pymysql來操作的,只不過Django將數據庫連接的這一部分封裝好了,我們只要在 settings.py中配置好了數據庫連接信息后直接使用Diango封裝好的接口就可以操作了。
1.安裝pymysql
pip install pymysql2.在init.py文件當中寫上如下代碼
import pymysql
pymysql.install_as_MySQLdb()3.編寫視圖函數
#app應用下的 view.py
def index(request):#獲取游標對象cursor = connection.cursor()#拿到游標對象后執行sql語句cursor.execute("select * from cangku")#獲取所有數據rows = cursor.fetchall()#便利查詢for row in rows:print(row)return HttpResponse("查找成功")4.編寫路由
#app應用下的 urls.py
from django.urls import path
from . import viewsapp_name = 'app'
urlpatterns = [path('cangku',views.index,name='index')
]
#database應用下的 urls.py
from django.contrib import admin
from django.urls import path, includeurlpatterns = [path('admin/', admin.site.urls),path('app/',include("app.urls"))
]
三、ORM模型介紹
1.ORM模型介紹
隨著項目越來越大,采用寫原生SQL的方式在代碼中會出現大量的SQL語句,那么問題就出現了
SQL語句重復利用率不高,越復雜的SQL語句條件越多,代碼越長。會出現很多相近的SQL語句。
很多SQL語句是在業務邏輯中拼出來的,如果有數據庫需要更改,就要去修改這些邏輯,這會很容易漏掉對某些SQL語句的修改。
寫SQL時容易忽略web安全問題,給未來造成隱患。SQL注入。
ORM,全稱object Relational Mapping,中文叫做對象關系映射,通過 ORM我們可以通過類的方式去操作數據庫,而不用再寫原生的SQL語句。通過把表映射成類,把行作實例,把字段作為屬性,ORM在執行對象操作的時候最終還是會把對應的操作轉換為數據庫原生語句。使用ORM有許多優點:
易用性:使用ORM做數據庫的開發可以有效的減少重復SQL語句的概率,寫出來的模型也更加直觀、清晰.
性能損耗小:ORM轉換成底層數據庫操作指令確實會有一些開銷。但從實際的情況來看,這種性能損耗很少(不足5%),只要不是對性能有嚴苛的要求,綜合考慮開發效率、代碼的閱讀性,帶來的好處要遠遠大于性能損耗,而且項目越大作用越明顯。
設計靈活:可以輕松的寫出復雜的查詢。
可移植性: Django封裝了底層的數據庫實現,支持多個關系數據庫引擎,包括流行的MySQL、PostgresQL和 SQLite。可以非常輕松的切換數據庫。
2.創建ORM模型
ORM模型一般都是放在 app的 models.py文件中。每個app都可以擁有自己的模型。并且如果這個模型想要映射到數據庫中,那么這個 app必須要放在settings.py的INSTALLED_APP 中進行安裝。以下是寫一個簡單的倉庫ORM 模型。
#app應用中 models.py文件
from django.db import models
#電子產品
class Dianzichanpin(models.Model):objects = Nonename = models.CharField(max_length=100)factory =models.CharField(max_length=100)pub_time = models.DateTimeField(auto_now_add=True)price = models.FloatField(default=0)3.映射模型到數據庫中
將 ORM 模型映射到數據庫中,總結起來就是以下幾步:
在settings.py中,配置好 DATABASES,做好數據庫相關的配置,
在 app 中的 mode1s.py中定義好模型,這個模型必須繼承自 django.db.models。
將這個app添加到settings.py的INSTALLED_APP中。
在命令行終端,進入到項目所在的路徑,然后執行命令 python manage.py makemigrations 來生成遷移腳本文件。
同樣在命令行中,執行命令 python manage.py migrate 來將遷移腳本文件映射到數據庫中。
四、CRUD操作
在 ORM框架中,所有模型相關的操作,比如添加/刪除等。其實都是映射到數據庫中一條數據的操作。因此模型操作也就是數據庫表中數據的操作。
1.添加一個模型到數據庫當中
編寫視圖函數
#app應用下 views.py
def add(request):Dianzi =Dianzichanpin(name='手機',factory='福建',price=1200)Dianzi.save()return HttpResponse("圖書插入成功")編寫路由
#app應用下的 urls.pypath('add',views.add,name='add')2.查找數據
查找數據都是通過模型下的 objects 對象來實現的。
2.1查找所有數據
要查找 Dianzichanpin 這個模型對應的表下的所有數據。
編寫視圖函數
#app應用下 views.py
def query(request):Dianzi = Dianzichanpin.objects.all()for Dian in Dianzi:print(Dian.id,Dian.name,Dian.pub_time,Dian.price)return HttpResponse("查找成功")編寫路由
#app應用下的 urls.pypath('query',views.query,name='query')2.2數據過濾
在查找數據的時候,有時候需要對一些數據進行過濾。那么這時候需要調用objects的 filter 方法。
編寫視圖函數
def query(request):# Dianzi = Dianzichanpin.objects.all()Dianzi = Dianzichanpin.objects.filter(name='手機')for Dian in Dianzi:print(Dian.id,Dian.name,Dian.pub_time,Dian.price)return HttpResponse("查找成功")2.3獲取單個對象(多用于登陸注冊)
使用 filter返回的是所有滿足條件的結果集。有時候如果只需要返回第一個滿足條件的對象。那么可以使用 get方法。
編寫視圖函數
def query(request):Dianzi = Dianzichanpin.objects.get(name='手機')print(Dianzi.name)return HttpResponse("查找成功")2.4數據排序
在之前的例子中,數據都是無序的。如果你想在査找數據的時候使用某個字段來進行排序,那么可以使用order_by方法來實現。
編寫視圖函數
def query(request):Dianzi = Dianzichanpin.objects.order_by("pub_time")for Dian in Dianzi:print(Dian.name)return HttpResponse("查找成功")默認為從小到大排列,如果想要倒敘,在對應數據前面放上-號
3.修改數據
在查找到數據后,便可以進行修改了。修改的方式非常簡單,只需要將查找出來的對象的某個屬性進行修改,然后再調用這個對象的 save 方法便可以進行修改。
編寫視圖函數
def update(reuqest):Dianzi = Dianzichanpin.objects.first()Dianzi.name ='耳機'Dianzi.save()return HttpResponse('修改成功')編寫路由
#app應用下的 urls.py
path('update',views.update,name='update')4.刪除數據
在查找到數據后,便可以進行刪除了。刪除數據非常簡單,只需要調用這個對象的 delete方法即可
編寫視圖函數
def delete_(request):Dianzi = Dianzichanpin.objects.get(name='電子手表')Dianzi.delete()return HttpResponse('刪除成功')編寫路由
path('delete',views.delete_,name='delete')
配置)
 深度優先遍歷(dfs) 暴力搜索 C++解題思路 每日一題)







)



制作傷害計算的流程)




