目錄
Buffer Pool是什么??
redo log(Innodb獨有)?
為什么需要redolog??
類比的方式巧記redolog
binlog(Server層獨有)
binlog是干啥的?
為什么有了 binlog, 還要有 redo log?
redo log 和 binlog 有什么區別?
update流程在兩個日志中是怎樣的?
兩階段提交詳細過程?
異常重啟會出現什么現象?
事務還沒提交的時候,redo log 能不能被持久化到磁盤呢??
為什么說事務還沒提交的時候,redolog 也有可能被持久化到磁盤呢??
那就有了一個新問題:因為事務還沒提交,如果在redolog刷盤之后宕機或者是發現該事物中出現錯誤需要回滾,又該對redolog做什么操作呢?是否應該刪除redolog對該事務的記錄??
怎樣讓數據庫恢復到半個月內任意一秒的狀態??
定期全量備份的周期“取決于系統重要性,有的是一天一備,有的是一周一備”。那么在什么場景下,一天一備會比一周一備更有優勢呢?或者說,它影響了這個數據庫系統的哪個指標?
筆記來自MySQL45講+小林coding+自己總結歸納
Buffer Pool是什么??
首先我們知道MySQL的所有數據都是存儲在磁盤中的,當我們要更新一條數據時,是需要從磁盤中把這條數據拿出來才能更新,那修改完之后肯定要緩存起來,因為后面有語句命中的時候就不需要再從磁盤里讀了,提高了數據庫的讀寫性能。
架構圖:
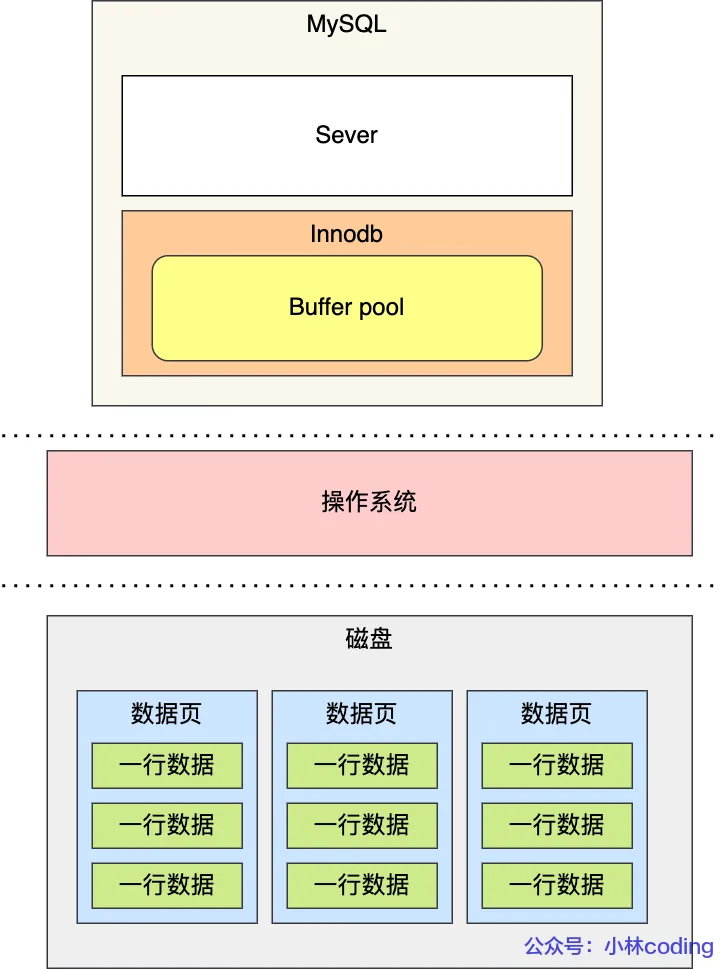
有了Buffer Pool后有兩個好處
- 查數據時,直接從Buffer Pool中取,如果沒有命中就去磁盤中讀取。
- 更新數據時,如果這條數據存在于Buffer Pool中,就直接更新這條數據所在的頁,然后把這頁標記為臟頁,后續由后臺線程選擇一個合適的時機更新到磁盤中。
redo log(Innodb獨有)?
為什么需要redolog??
我們知道Buffer Pool提高了數據庫的讀寫性能,但是Buffer Pool是存在于內存中的,一旦斷電,內存里還沒落盤的臟頁數據就會丟失,所以為了解決這個問題,redolog就誕生了。
那以后要更新記錄時,除了在Buffer Pool標記臟頁外,還會把這條記錄所在的頁的修改以redo log的形式記錄下來,后續在合適的時機由后臺線程刷新到磁盤中,這就是WAL (Write-Ahead Logging)技術,說白了就是先寫日志(寫到redolog buffer中,提交事務時會刷到redolog文件中),此時更新操作就算是完成了,再寫磁盤(把臟頁刷新到磁盤)。?
類比的方式巧記redolog
《孔乙己》這篇文章,酒店掌柜有一個粉板,專門用來記錄客人的賒賬記錄。如果賒賬的人不多,那么他可以把顧客名和賬目寫在板上。但如果賒賬的人多了,粉板總會有記不下的時候,這個時候掌柜一定還有一個專門記錄賒賬的賬本。
如果有人要賒賬或者還賬的話,掌柜一般有兩種做法:
- 一種做法是直接把賬本翻出來,把這次賒的賬加上去或者扣除掉;
- 另一種做法是先在粉板上記下這次的賬,等打烊以后再把賬本翻出來核算。
在生意紅火柜臺很忙時,掌柜一定會選擇后者,因為前者操作實在是太麻煩了。首先,你得找到這個人的賒賬總額那條記錄。你想想,密密麻麻幾十頁,掌柜要找到那個名字,再拿出算盤計算,最后再將結果寫回到賬本上。所以有了粉板,我們的效率就非常高了。
同樣,在 MySQL 里也有這個問題,如果每一次的更新操作都需要寫進磁盤,然后磁盤也要找到對應的那條記錄,然后再更新,整個過程 IO 成本、查找成本都很高。為了解決這個問題,MySQL 的設計者就用了類似酒店掌柜粉板的思路來提升更新效率。
而粉板和賬本配合的整個過程,也就是WAL技術,關鍵點就是先寫日志,再寫磁盤,也就是先寫粉板,等不忙的時候再寫賬本。
具體來說,當有一條記錄需要更新的時候,InnoDB 引擎就會先把記錄寫到 redo log(粉板)里面,并更新內存,這個時候更新就算完成了。同時,InnoDB 引擎會在適當的時候,將這個操作記錄更新到磁盤里面,而這個更新往往是在系統比較空閑的時候做,這就像打烊以后掌柜做的事。
但如果某天賒賬的特別多,粉板寫滿了,又怎么辦呢?這個時候掌柜只好放下手中的活兒,把粉板中的一部分賒賬記錄更新到賬本中,然后把這些記錄從粉板上擦掉,為記新賬騰出空間。
與此類似,InnoDB 的 redo log 是固定大小的,比如可以配置為一組 4 個文件,每個文件的大小是 1GB,那么這塊“粉板”總共就可以記錄 4GB 的操作。從頭開始寫,寫到末尾就又回到開頭循環寫,如下面這個圖所示。?
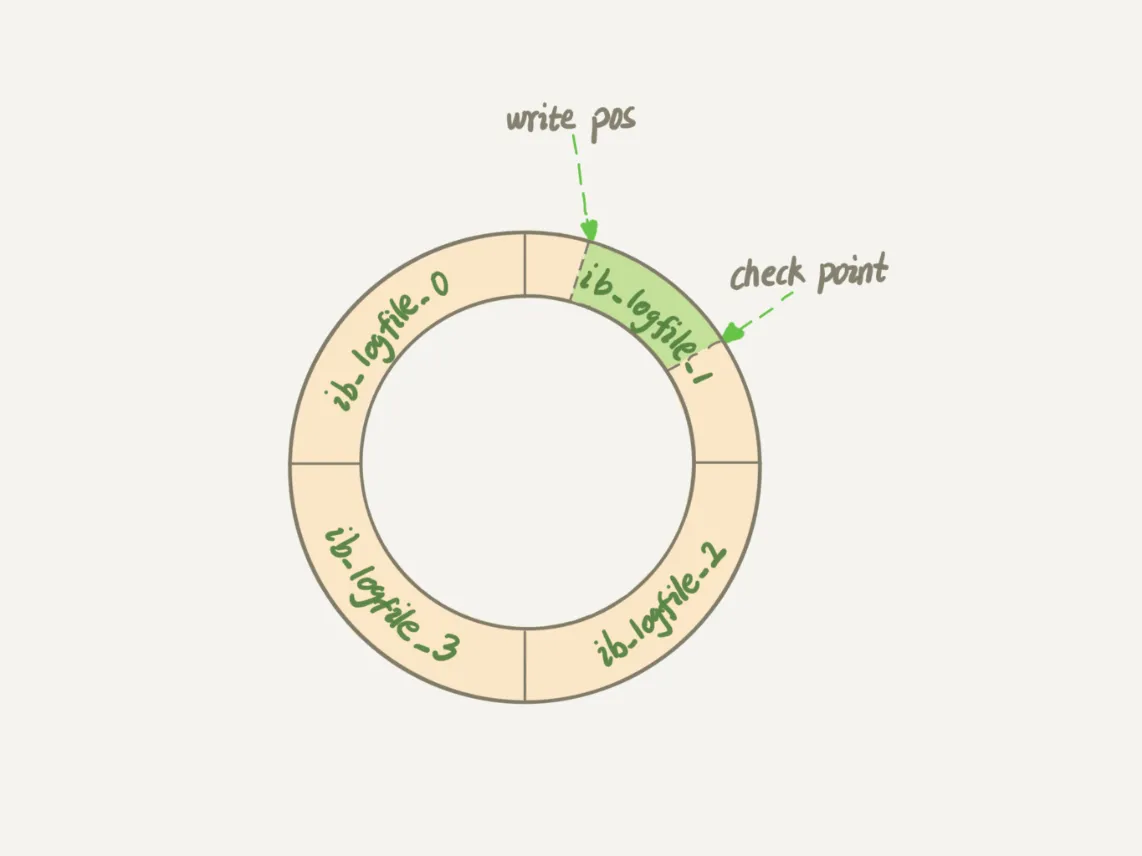
InnoDB 用 write pos 表示 redo log 當前記錄寫到的位置,一邊寫一邊后移,寫到第 3 號文件末尾后就回到 0 號文件開頭。
checkpoint 表示當前要擦除的位置。
- write pos ~ checkpoint 之間的部分(圖中的紅色部分),用來記錄新的更新操作;
- check point ~ write pos 之間的部分(圖中藍色部分):待落盤的臟數據頁記錄
有了 redo log,InnoDB 就可以保證即使數據庫發生異常重啟,之前提交的記錄都不會丟失,這個能力稱為crash-safe。
要理解 crash-safe 這個概念,可以想想我們前面賒賬記錄的例子。只要賒賬記錄記在了粉板上或寫在了賬本上,之后即使掌柜忘記了,比如突然停業幾天,恢復生意后依然可以通過賬本和粉板上的數據明確賒賬賬目。?
binlog(Server層獨有)
binlog是干啥的?
binlog 文件記錄了所有數據庫表結構變更和表數據修改的日志,不會記錄查詢類的操作,比如 SELECT 和 SHOW 操作。
MySQL 在完成一條更新操作后,Server 層還會生成一條 binlog,等之后事務提交的時候,會將該事務執行過程中產生的所有 binlog 統一寫 入 binlog 文件。
為什么有了 binlog, 還要有 redo log?
這個問題跟 MySQL 的時間線有關系。
最開始 MySQL 里并沒有 InnoDB 引擎,MySQL 自帶的引擎是 MyISAM,但是 MyISAM 沒有 crash-safe 的能力,binlog 日志只能用于歸檔。
而 InnoDB 是另一個公司以插件形式引入 MySQL 的,既然只依靠 binlog 是沒有 crash-safe 能力的,所以 InnoDB 使用 redo log 來實現 crash-safe 能力?
redo log 和 binlog 有什么區別?
1、適用對象不同:
- binlog 是 MySQL 的 Server 層實現的日志,所有存儲引擎都可以使用;
- redo log 是 Innodb 存儲引擎實現的日志;
2、文件格式不同:
- binlog 有 3 種格式類型,分別是 STATEMENT(默認格式)、ROW、 MIXED,區別如下:
- STATEMENT:每一條修改數據的 SQL 都會被記錄到 binlog 中(相當于記錄了邏輯操作,所以針對這種格式, binlog 可以稱為邏輯日志),主從復制中 slave 端再根據 SQL 語句重現。但 STATEMENT 有動態函數的問題,比如你用了 uuid 或者 now 這些函數,你在主庫上執行的結果并不是你在從庫執行的結果,這種隨時在變的函數會導致復制的數據不一致;
- ROW:記錄行數據最終被修改成什么樣了(這種格式的日志,就不能稱為邏輯日志了),不會出現 STATEMENT 下動態函數的問題。但 ROW 的缺點是每行數據的變化結果都會被記錄,比如執行批量 update 語句,更新多少行數據就會產生多少條記錄,使 binlog 文件過大,而在 STATEMENT 格式下只會記錄一個 update 語句而已;
- MIXED:包含了 STATEMENT 和 ROW 模式,它會根據不同的情況自動使用 ROW 模式和 STATEMENT 模式;
- redo log 是物理日志,記錄的是在某個數據頁做了什么修改,比如對 XXX 表空間中的 YYY 數據頁 ZZZ 偏移量的地方做了AAA 更新;
3、寫入方式不同:
- binlog 是追加寫,寫滿一個文件,就創建一個新的文件繼續寫,不會覆蓋以前的日志,保存的是全量的日志。
- redo log 是循環寫,日志空間大小是固定,全部寫滿就從頭開始,保存未被刷入磁盤的臟頁日志。
4、用途不同:
- binlog 用于備份恢復、主從復制;
- redo log 用于掉電等故障恢復?
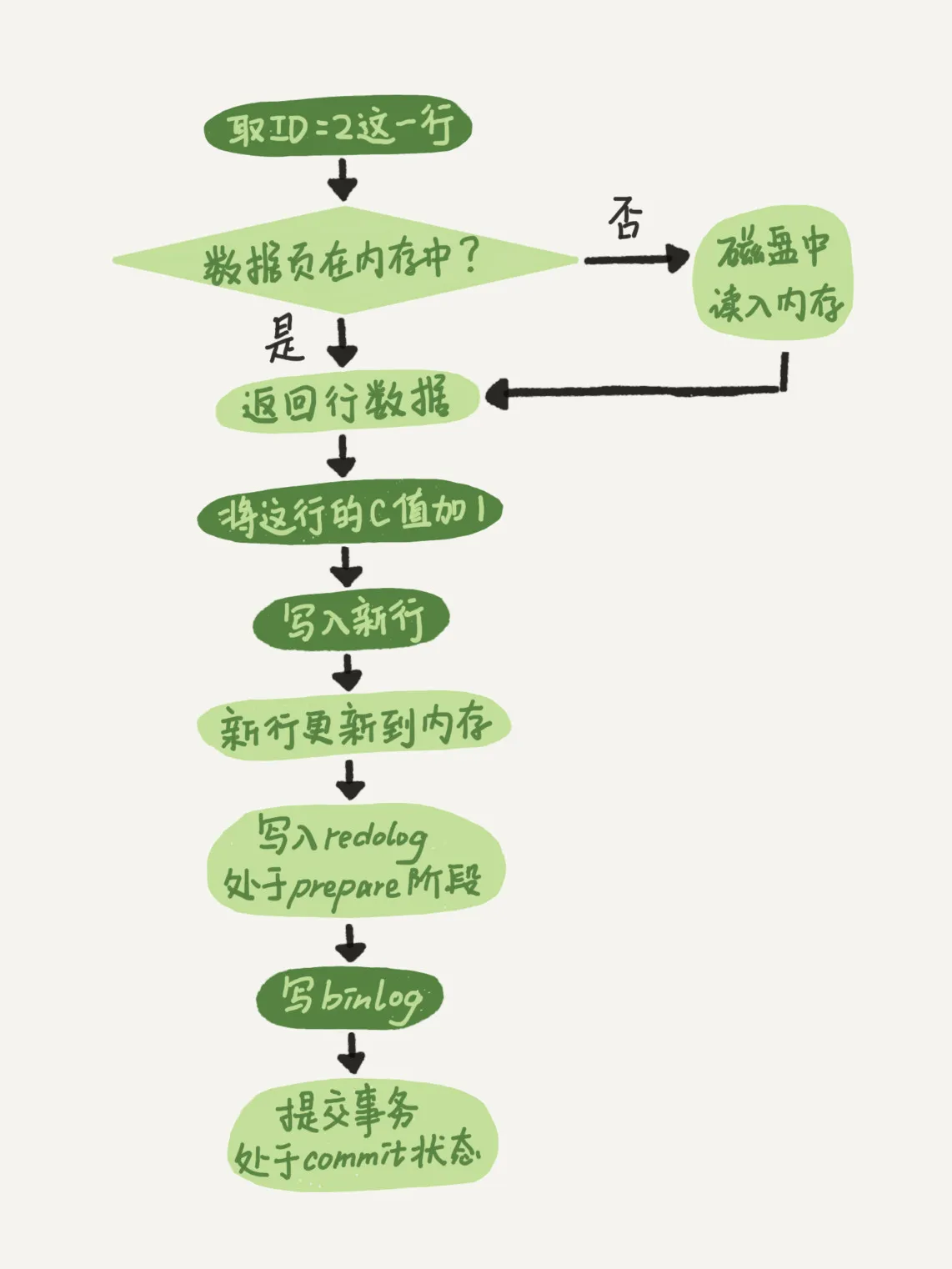
update流程在兩個日志中是怎樣的?
- 執行器先找引擎取 ID=2 這一行。ID 是主鍵,引擎直接用樹搜索找到這一行。如果 ID=2 這一行所在的數據頁本來就在內存中,就直接返回給執行器;否則,需要先從磁盤讀入內存,然后再返回。
- 執行器拿到引擎給的行數據,把這個值加上 1,比如原來是 N,現在就是 N+1,得到新的一行數據,再調用引擎接口寫入這行新數據。
- 引擎將這行新數據更新到內存中,同時將這個更新操作記錄到 redo log 里面,此時 redo log 處于 prepare 狀態。然后告知執行器執行完成了,隨時可以提交事務。
- 執行器生成這個操作的 binlog,并把 binlog 寫入磁盤。
- 執行器調用引擎的提交事務接口,引擎把剛剛寫入的 redo log 改成提交(commit)狀態,更新完成?
兩階段提交詳細過程?
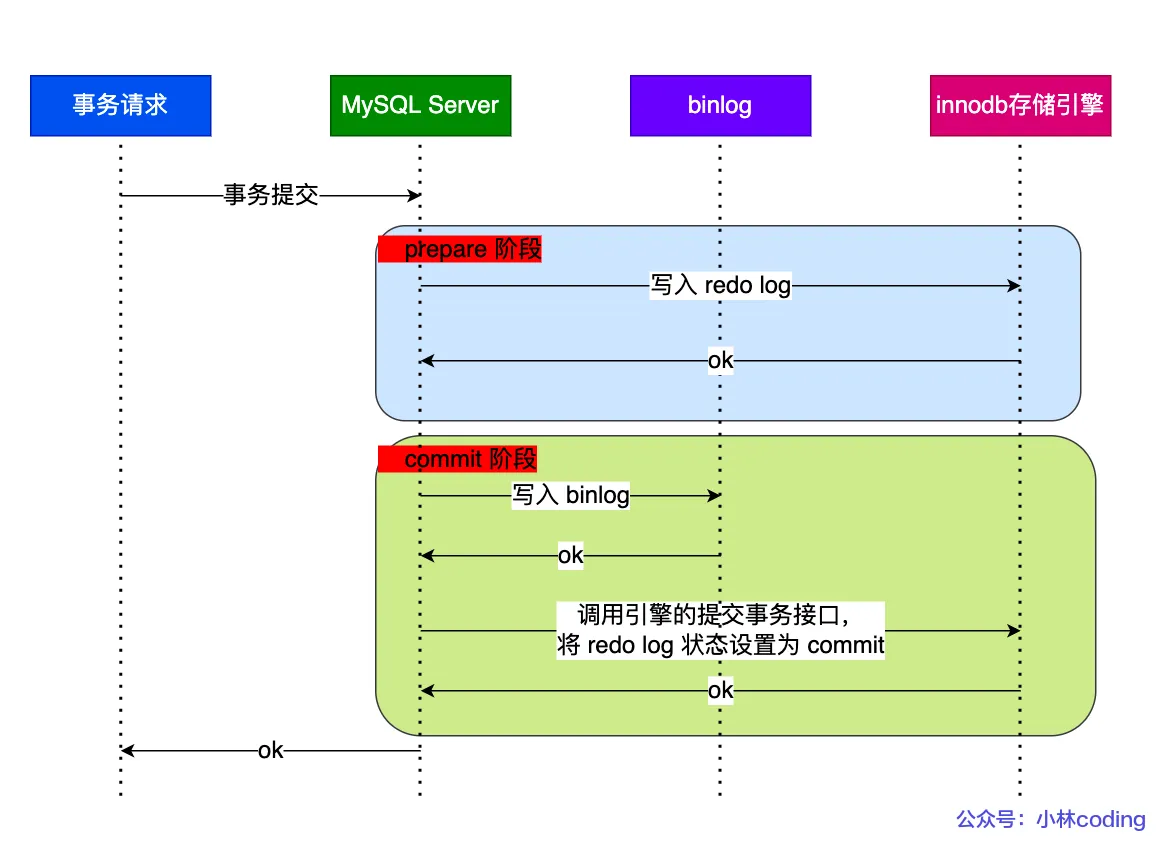
- prepare 階段:將 XID(內部 XA 事務的 ID) 寫入到 redo log,同時將 redo log 對應的事務狀態設置為 prepare,然后將 redo log 持久化到磁盤(innodb_flush_log_at_trx_commit = 1 的作用);
- commit 階段:把 XID 寫入到 binlog,然后將 binlog 持久化到磁盤(sync_binlog = 1 的作用),接著調用引擎的提交事務接口,將 redo log 狀態設置為 commit?
異常重啟會出現什么現象?
下圖中有時刻 A 和時刻 B 都有可能發生崩潰:?
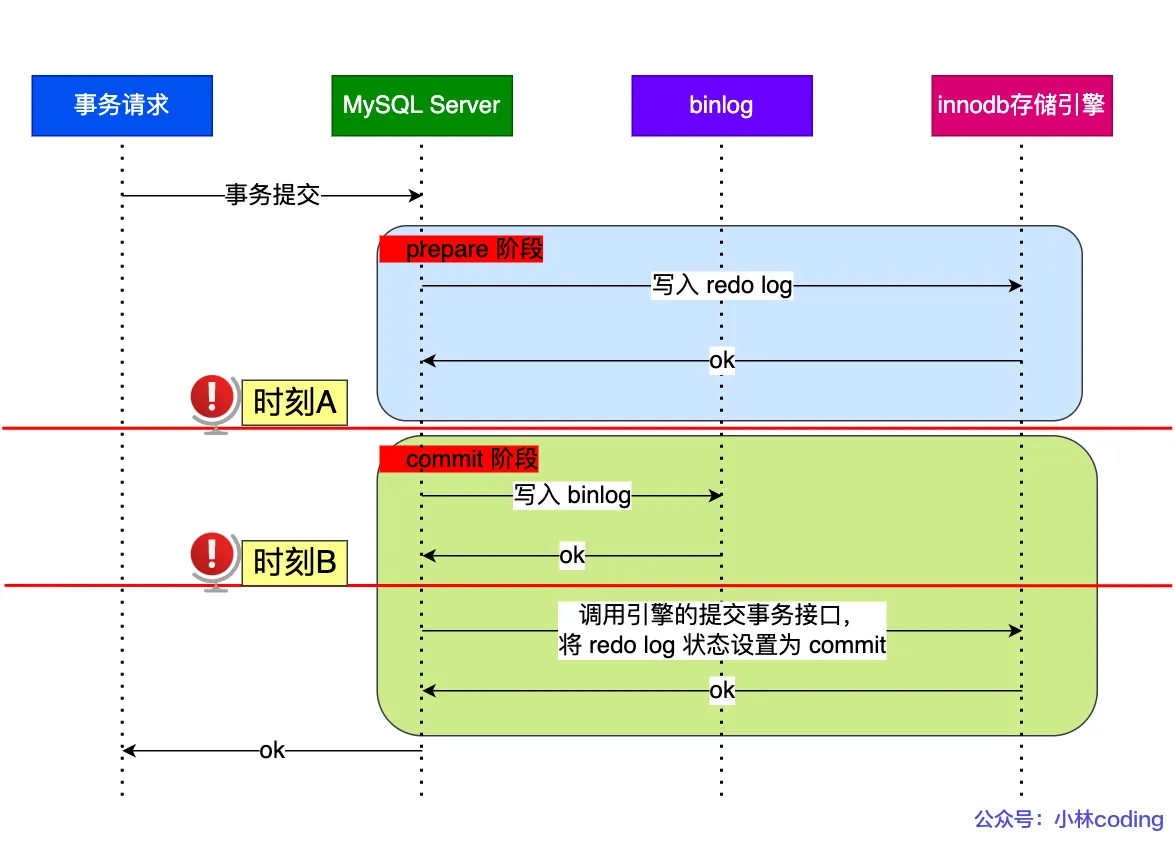
不管是時刻 A(redo log 已經寫入磁盤, binlog 還沒寫入磁盤),還是時刻 B (redo log 和 binlog 都已經寫入磁盤,還沒寫入 commit 標識)崩潰,此時的 redo log 都處于 prepare 狀態。
在 MySQL 重啟后會按順序掃描 redo log 文件,碰到處于 prepare 狀態的 redo log,就拿著 redo log 中的 XID 去 binlog 查看是否存在此 XID:
- 如果 binlog 中沒有當前內部 XA 事務的 XID,說明 redolog 完成刷盤,但是 binlog 還沒有刷盤,則回滾事務。對應時刻 A 崩潰恢復的情況。
- 如果 binlog 中有當前內部 XA 事務的 XID,說明 redolog 和 binlog 都已經完成了刷盤,則提交事務。對應時刻 B 崩潰恢復的情況。?
對于處于 prepare 階段的 redo log,即可以提交事務,也可以回滾事務,這取決于是否能在 binlog 中查找到與 redo log 相同的 XID?
事務還沒提交的時候,redo log 能不能被持久化到磁盤呢??
先說答案,答案就是有可能。
redolog刷盤由 innodb_flush_log_at_trx_commit 參數控制,可取的值有:0、1、2,默認值為 1,這三個值分別代表的策略如下:
- 當設置該參數為 0 時,表示每次事務提交時 ,還是將 redo log 留在 redo log buffer 中
- 當設置該參數為 1 時,表示每次事務提交時,都將緩存在 redo log buffer 里的 redo log 直接持久化到磁盤
- 當設置該參數為 2 時,表示每次事務提交時,都只是緩存在 redo log buffer 里的 redo log 寫到 操作系統層面的page cache中,但是沒有執行 fsync 操作持久化到磁盤?
為什么說事務還沒提交的時候,redolog 也有可能被持久化到磁盤呢??
主要有三種可能的原因:
- 第一種情況:InnoDB 有一個后臺線程,每隔 1 秒輪詢一次,調用 write 將 redolog buffer 中的日志寫到文件系統的 page cache,然后調用 fsync 持久化到磁盤。所以,一個沒有提交的事務的 redolog,也是有可能會被后臺線程一起持久化到磁盤的。
- 第二種情況:innodb_flush_log_at_trx_commit 設置是 1,這個參數的意思就是,每次事務提交的時候,都執行 fsync 將 redolog 直接持久化到磁盤(還有 0 和 2 的選擇,0 表示每次事務提交的時候,都只是把 redolog 留在 redolog buffer 中;2 表示每次事務提交的時候,都只執行 write 將 redolog 寫到文件系統的 page cache 中)。舉個例子,假設事務 A 執行到一半,已經寫了一些 redolog 到 redolog buffer 中,這時候有另外一個事務 B 提交,按照 innodb_flush_log_at_trx_commit = 1 的邏輯,事務 B 要把 redolog buffer 里的日志全部持久化到磁盤,這時候,就會連帶上事務 A 在 redolog buffer 里的日志一起持久化到磁盤。
- 第三種情況:redo log buffer 占用的空間達到 redolog buffer 大小(由參數 innodb_log_buffer_size 控制,默認是 8MB)一半的時候,后臺線程會主動寫盤。不過由于這個事務并沒有提交,所以這個寫盤動作只是 write 到了文件系統的 page cache,仍然是在內存中,并沒有調用 fsync 真正落盤。?
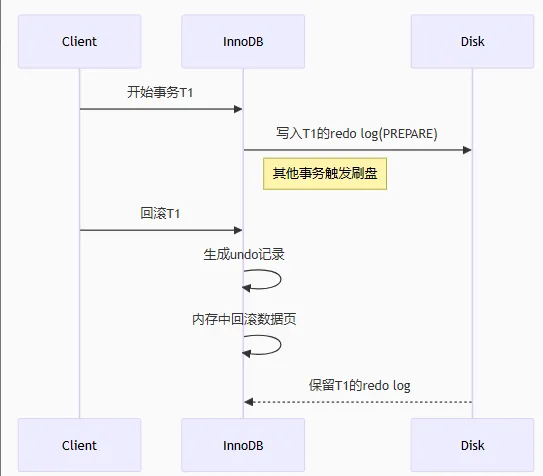
那就有了一個新問題:因為事務還沒提交,如果在redolog刷盤之后宕機或者是發現該事物中出現錯誤需要回滾,又該對redolog做什么操作呢?是否應該刪除redolog對該事務的記錄??
MySQL 不會直接刪除已寫入磁盤的 redo log,而是通過以下方式處理:
正常事務回滾(未崩潰時)
- InnoDB 會在內存中生成對應的 undo log(記錄如何撤銷修改)
- 執行 undo log 回滾數據頁修改
- redo log 仍保留在磁盤,但會被標記為"無效"
- 后續 checkpoint 機制會跳過這些無效日志?
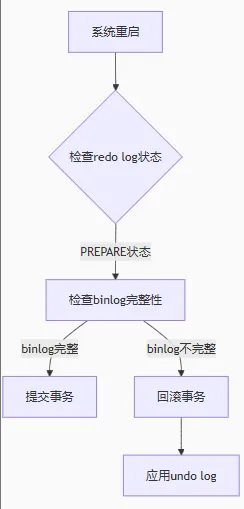
崩潰恢復時(應用兩階段提交)
根據 redo log 的 prepare 狀態和 binlog 完整性決定:
- 如果 binlog 不完整:回滾事務(使用 undo log)
- 如果 binlog 完整:提交事務?
怎樣讓數據庫恢復到半個月內任意一秒的狀態??
如果你的 DBA 承諾說半個月內可以恢復,那么備份系統中一定會保存最近半個月的所有 binlog,同時系統會定期做整庫備份。這里的“定期”取決于系統的重要性,可以是一天一備,也可以是一周一備。
當需要恢復到指定的某一秒時,比如某天下午兩點發現中午十二點有一次誤刪表,需要找回數據,那你可以這么做:
- 首先,找到最近的一次全量備份,如果你運氣好,可能就是昨天晚上的一個備份,從這個備份恢復到臨時庫;
- 然后,從備份的時間點開始,將備份的 binlog 依次取出來,重放到中午誤刪表之前的那個時刻。
這樣你的臨時庫就跟誤刪之前的線上庫一樣了,然后你可以把表數據從臨時庫取出來,按需要恢復到線上庫去。?
定期全量備份的周期“取決于系統重要性,有的是一天一備,有的是一周一備”。那么在什么場景下,一天一備會比一周一備更有優勢呢?或者說,它影響了這個數據庫系統的哪個指標?
- 核心業務(如訂單、支付)推薦 一天一備 + binlog實時同步(RPO近0)。
- 非關鍵業務(如日志、測試庫)可 一周一備,甚至結合快照備份。
一天一備的最長恢復時間更短,最壞情況下需要應用一天的binlog,比如,你每天0點做一次全量備份,而要恢復出一個到昨天晚上23點的備份。
一周一備最壞情況就要應用一周的binlog了。?


















環境搭建)
