作者:來自 Elastic?Alex Salgado

學習如何使用四種實用方法在 Elasticsearch 中重命名索引。
想獲得 Elastic 認證?看看下一期 Elasticsearch Engineer 培訓什么時候開始!
Elasticsearch 擁有豐富的新功能,幫助你根據使用場景構建最佳搜索方案。深入了解我們的示例筆記本,開始免費云試用,或立即在本地機器上體驗 Elastic。
你是否曾嘗試在 Elasticsearch 中重命名索引,卻發現根本沒有 rename 的 API 接口?很多人都會遇到這種情況,因為與操作系統中的普通文件不同,Elasticsearch 的索引是復雜且分布式的結構。因此,你不能直接更改名稱。如果你想了解如何創建、列出、查詢和刪除索引,可以查看這篇指南。
在本文中,我們將解釋為什么會這樣,并介紹四種實用方法來應對這個限制,具體包括:
-
別名,是最輕量的選項;
-
Clone API,可以快速復制索引;
-
快照與恢復,用于基于完整備份的復制;
-
Reindex API,功能最強大,但資源消耗也最大。
為什么 Elasticsearch 不允許直接重命名索引?
Elasticsearch 將數據組織成索引,而索引由分布在集群多個節點上的分片組成。每個分片本質上是一個獨立的 Lucene 引擎實例,負責物理存儲數據。
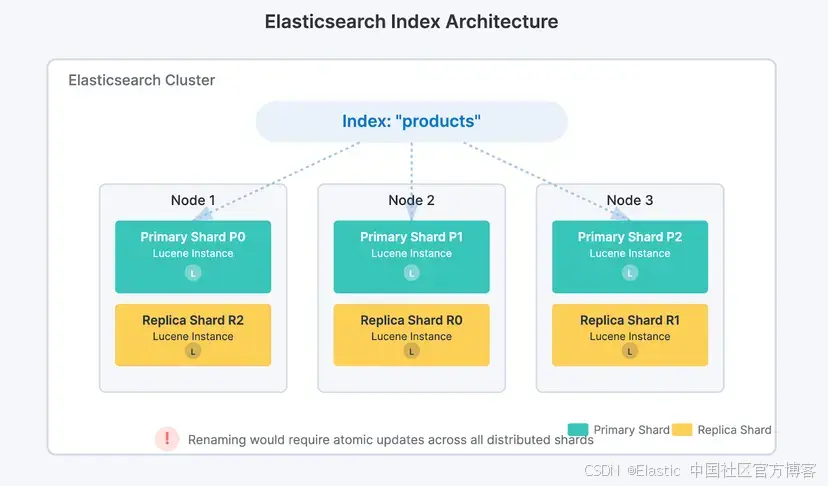
如果可以直接重命名索引,系統就必須在所有節點的所有分片中以絕對原子的方式更新索引名稱,以避免不一致。這種復雜性以及數據損壞的風險讓開發者決定不實現這個功能。
然而,在很多場景下確實有重命名索引的需求,例如更改字段映射或數據類型、使命名符合公司新標準、解決多租戶集群中的沖突,或替換從舊系統繼承的名稱。
別名:最簡單且最靈活的解決方案
當我們只需要讓應用程序通過另一個名字訪問索引時,最好的解決方案是使用別名(alias)。可以把別名看作索引的昵稱。它們不會復制數據,也不會更改磁盤上的任何內容 —— 它們只是更新集群中的元數據,使新名稱 “指向” 真實索引。這種更改幾乎是瞬時完成的,因為它只更新集群元數據,不會影響查詢性能,無論索引有多大。
例如,如果我們有一個名為 old_index 的索引,并希望應用程序開始使用 new_index,只需添加如下別名:
POST /_aliases
{"actions": [{"add": {"index": "old_index","alias": "new_index"}}]
}如果你的應用程序通過別名寫入數據,你可能需要指定寫入索引(write index):
POST /_aliases
{"actions": [{"add": {"index": "new_index","alias": "production_alias","is_write_index": true}}]
}關于寫入索引的行為及其適用場景的更多詳情,請參閱 Write index 文檔。
這種方式為我們的應用程序提供了靈活性,有助于實現平滑過渡和邏輯隔離,尤其適用于基于微服務的架構,每個服務可能需要不同的訪問數據方式或命名約定。
Clone API:快速復制,但有一些限制
如果不能使用別名,并且需要一個具有新名稱的索引,下一步可以使用 Clone API。這一功能會創建原始索引的物理副本,但不會復制數據,而是通過文件系統中的硬鏈接重用數據文件。這使得操作比完全重建索引要快得多。
重要提示: Clone API 有多個限制。它不會復制索引元數據,如別名、ILM 策略或 CCR 設置。目標索引必須不存在,并且兩個索引必須擁有相同數量的主分片。完整的要求與限制請參見 Clone Index API 文檔。
在克隆之前,原始索引需要處于只讀模式且健康狀態為 green,以確保操作期間數據不會被修改:
PUT /old_index/_settings
{"settings": {"index.blocks.write": true}
}然后,只需執行克隆操作:
POST /old_index/_clone/new_index最后,如有需要,我們可以解除新索引的寫入限制:
PUT /new_index/_settings
{"settings": {"index.blocks.write": false}
}即使數據通過硬鏈接被重用,確保有足夠的磁盤空間仍然很重要,因為新索引需要保持獨立。
快照/恢復:基于備份的重命名
如果你需要索引的完整且獨立的副本,快照和恢復提供了一個有趣的替代方案,尤其對于大索引來說,可能比重建索引更快。此方法利用了 Elasticsearch 的備份功能,并且在恢復過程中支持重命名索引。
這種方法特別適合已經將快照作為備份策略一部分的情況。它也適用于處理大索引時重建索引過于耗時、在集群間遷移數據,或需要保證數據的時間點一致性副本的場景。
首先,確保你已經配置了快照倉庫。如果沒有,而這是使用此方法的前提條件,請參閱快照倉庫文檔。你可以用以下命令檢查現有倉庫:
GET /_snapshot接下來,創建索引的快照:
PUT /_snapshot/my_repository/rename_snapshot?wait_for_completion=true
{"indices": "old_index","include_global_state": false
}重要提示:和重建索引一樣,確保在快照過程中索引沒有寫操作,以保證數據一致性。
最后,使用 rename_pattern 和 rename_replacement 以新名稱恢復快照:
POST /_snapshot/my_repository/rename_snapshot/_restore
{"indices": "old_index","rename_pattern": "old_index","rename_replacement": "new_index"
}對于更復雜的重命名模式,你可以使用正則表達式:
POST /_snapshot/my_repository/rename_snapshot/_restore
{"indices": "logs-*","rename_pattern": "logs-(.+)","rename_replacement": "archived-logs-$1"
}重建索引:最強大且靈活的工具
當需要超越簡單復制或重命名時,應該使用 Reindex API。它不僅允許我們將數據從一個索引復制到另一個索引,還可以執行轉換、過濾、結構調整、合并多個索引等復雜操作。
可選的安全步驟:重建索引操作本身不會修改或影響原始索引。但如果你計劃在重建后刪除原索引(如本文后面所示),建議先創建備份:
PUT /_snapshot/my_backup/snapshot_before_reindex?wait_for_completion=true
{"indices": "old_index"
}對于大索引,考慮使用 wait_for_completion=false 來避免超時,然后通過 GET /_snapshot/my_backup/snapshot_before_reindex/_status 監控快照進度。
接下來,我們獲取原始索引的設置和映射,以正確創建目標索引:
GET /old_index 這個命令會同時返回設置和映射。
現在,我們需要用這些設置創建目標索引。如果你沒有配置索引模板,必須在重建索引之前手動創建索引:
PUT /new_index
{"settings": {// paste the settings obtained from the original index here, but remove any system-generated settings like index.provided_name, etc.},"mappings": {// paste the mappings obtained from the original index here}
}重要注意事項:
- 復制設置時,刪除所有只讀和系統生成的屬性。只保留可配置的設置,如 number_of_replicas、refresh_interval、analysis 等。關于哪些設置可以在創建索引時指定,詳見索引設置文檔。
- 如果跳過這一步且沒有模板,Elasticsearch 會在重建索引時自動創建索引,使用動態映射,可能導致字段數據類型錯誤。
- 正確創建目標索引后,按如下方式執行基本的重建索引操作:
POST /_reindex
{"source": { "index": "old_index" },"dest": { "index": "new_index" }
}對于大索引,我們可以通過后臺運行、使用 slices 并行處理,以及控制吞吐量來優化操作,避免集群過載。還可以應用腳本,在復制數據時修改內容。
例如:
POST /_reindex?slices=auto&wait_for_completion=false&refresh=false
{"source": { "index": "old_index" },"dest": {"index": "new_index"},"conflicts": "proceed","script": {"source": "ctx._source.status = 'migrated';"}
}讓我們了解每個參數的作用:
-
slices=auto:通過將任務分成多個片(線程)實現并行處理。auto 讓 Elasticsearch 根據分片數量自動決定最佳線程數。
-
wait_for_completion=false:后臺執行操作,立即返回任務 ID,而不是等待完成。
-
"refresh": false:復制期間禁用目標索引的自動刷新,顯著提升性能。數據只有在手動刷新后才可被搜索。重建完成后,運行:POST /new_index/_refresh。
-
"conflicts": "proceed":遇到文檔版本沖突時繼續執行重建,而不是在第一個錯誤停止。
-
"script":在復制時對每個文檔應用轉換。例如,在此示例中,給所有文檔添加了一個值為 "migrated" 的字段 "status"。
控制傳輸速率(限流)
為了避免集群過載,我們可以限制重建索引的速度:
POST /_reindex?requests_per_second=500
{"source": { "index": "old_index" },"dest": { "index": "new_index" }
}使用 wait_for_completion=false 時,響應會立即返回一個任務 ID:
{"task": "oTUltX4IQMOUUVeiohTt8A:12345"
}保存這個 ID,因為你需要用它來跟蹤進度,尤其是當你同時運行多個重建索引操作時。
要跟蹤特定任務的進度,可以這樣使用任務 ID:
GET /_tasks/oTUltX4IQMOUUVeiohTt8A:12345 或者,要查看所有正在進行的重建索引操作:
GET /_tasks?actions=*reindex&detailed=true如果你丟失了任務 ID,可以列出所有活動任務并查找你的任務:
GET /_tasks?actions=*reindex&detailed=true&group_by=parents 在修改別名前,先確認重建索引是否成功。檢查文檔數量、索引大小和健康狀態,并運行一些測試搜索,確保數據正確。
-
比較文檔數量:
GET /old_index/_count GET /new_index/_count -
檢查索引大小和健康狀態:
GET /_cat/indices/old_index,new_index?v&h=index,docs.count,store.size,health -
運行一些測試搜索,確保數據正確:
GET /new_index/_search {"size": 5,"query": {"match_all": {}} }確認并驗證無誤后,更新別名指向新索引,確保應用程序持續正常運行:
POST /_aliases {"actions": [{ "remove": { "index": "old_index", "alias": "production_alias" } },{ "add": { "index": "new_index", "alias": "production_alias", "is_write_index": true } }] }只有在確認無誤后,才能安全地刪除舊索引:
DELETE /old_index
什么時候使用 Reindex API?
這個工具適用于多種日常場景。它可以用來遷移遺留數據到新結構、修正字段或值的數據類型、將多個索引的數據合并到一個索引中、只重建符合特定條件的文檔,甚至在遷移過程中應用 ingest pipeline 來豐富數據。
盡管功能多樣,重建索引消耗資源較大,因此務必先進行測試并密切監控集群。
各方法特點總結:
| 方法 | 什么時候使用 | 速度 | 集群影響 |
|---|---|---|---|
| Alias | 只需要更改訪問名稱 | Instantaneous | None |
| Clone | 需要完全相同的物理副本 | Fast (hard links) | Low |
| Snapshot/Restore | 需要硬拷貝或跨集群復制 | Moderate | Low |
| Reindex | 需要轉換數據或結構 | Slow (copies everything) | High |
結論
在 Elasticsearch 中,不能直接重命名索引。這個限制源自系統的分布式架構,索引由分布在集群節點上的多個分片組成。
如果只需更改應用訪問索引的名稱,可以使用別名 —— 速度快、安全且無影響。需要完全相同的物理副本時,使用克隆。對于完整的硬拷貝或跨集群操作,快照/恢復提供可靠方案。只有在必須轉換數據或結構時,才使用重建索引,但需謹慎操作。
無論哪種情況,都要在操作后驗證數據、記錄變更,并保持備份更新,以確保操作的完整性和連續性。
參考資料
有關本文討論概念的詳細信息,請參閱官方 Elasticsearch 文檔:
-
Aliases API — 創建和管理索引別名的完整指南
-
Clone Index API — 使用硬鏈接克隆索引的文檔
-
Reindex API — 重建索引操作的全面指南,包括限流和異步執行
-
Task Management API — 如何監控重建等長時間運行的操作
-
Index Settings — 了解索引設置,包括只讀限制
-
Restore a snapshot — 恢復 API 的完整指南,包括 rename_pattern 的使用
-
Snapshot and restore overview — 覆蓋快照/恢復整個流程的綜合指南
原文:Elasticsearch rename index - Elasticsearch Labs

)





 vs toAjax(rows): 何時用)


)








