python實現word 自動化
- 重復性文檔制作,手動填充模板,效率低下還易錯
- 1.python-docx入門:Word文檔的“瑞士軍刀”!
- 1.1 安裝與基礎概念:文檔、段落、運行、表格
- 1.2 打開/創建Word文檔:Python與Word的初次接觸
- 1.3 讀寫文本內容:讓Python填寫Word
- 2.Python批量生成個性化Word文檔
- 2.1 設計Word模板:word自動化開始
- 2.2 讀取數據與智能填充:數據
- 3.Python實現批量替換、格式調整!
- 3.1 批量替換內容:告別Ctrl+H,一鍵修改文檔
- 3.2 字體、顏色、大小與對齊:自動化專業排版
- 4.Word文檔工廠
- 5.Word自動化,開啟智能文檔管理新時代!
重復性文檔制作,手動填充模板,效率低下還易錯
在職場中,Word文檔是公認的“好伙伴”,但你有沒有被它“折磨”過?
批量生成合同: 每月幾十份合同,內容大同小異,卻要手動修改日期、客戶名、金額,重復勞動讓人抓狂。
制作報告: 不同的季度報告,框架一樣,數據更新,但排版、圖表插入每次都要從頭來過。
發放證書/通知: 幾百份個性化證書,只改個姓名、編號,卻要手動復制粘貼幾百次,效率低下還易錯!
這些重復、低效的文檔制作和排版耗時問題,嚴重拖慢了你的辦公自動化進程。

今天,我將帶你進入Python操作Word的奇妙世界!我們將手把手教你如何利用python-docx庫,輕松實現:
Word文檔批量生成: 數據驅動,自動生成海量個性化文檔。
智能模板填充: 告別手動復制粘貼,精準填充文本、圖片。
內容修改與排版優化: 批量替換文本、調整格式,讓文檔瞬間專業!
1.python-docx入門:Word文檔的“瑞士軍刀”!
要實現Python操作Word,我們離不開強大的python-docx庫。它是Python中專門用于創建、修改和讀取.docx格式Word文檔的庫。
作用: python-docx將Word文檔視為一個包含“文檔”、“段落”、等元素的層次結構。通過操作這些元素,你可以精確控制文檔的每一個部分。
安裝python-docx:
pip install python-docx
1.1 安裝與基礎概念:文檔、段落、運行、表格
我們先了解python-docx中的幾個核心概念:
Document (文檔): 整個Word文件,是最高層級的對象。
Paragraph (段落): Word文檔中的一個文本塊,由一個或多個“運行”組成。
Run (運行): 段落中具有相同樣式(如字體、顏色、加粗)的連續文本。通常,一個段落內部的樣式變化會導致新的“運行”的生成。
Table (表格): Word文檔中的表格對象,可以訪問行、列和單元格。
1.2 打開/創建Word文檔:Python與Word的初次接觸
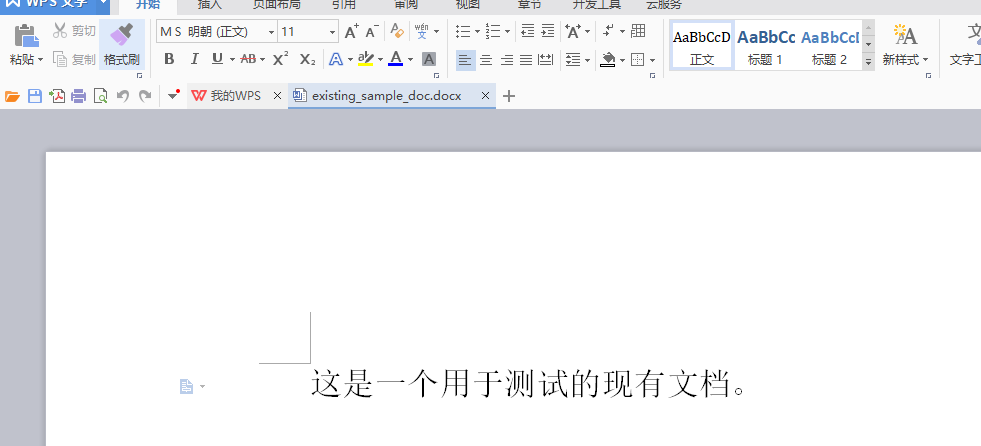
場景: 你想用Python創建一個新的Word文檔,或者打開一個已有的文檔進行修改。
方案: python-docx提供了簡單的方法來創建空文檔或加載現有文檔。
代碼:
from docx import Document # 導入Document類
import osdef create_or_open_word_doc(file_path, mode="new"):"""創建或打開Word文檔。這是Python操作Word的基礎。:param file_path: Word文檔路徑:param mode: "new" (創建新文檔) 或 "open" (打開現有文檔):return: Document對象"""os.makedirs(os.path.dirname(file_path), exist_ok=True) # 確保目錄存在doc = Nonetry:if mode == "new":doc = Document() # 創建一個空文檔print(f"? 成功創建新Word文檔對象。")elif mode == "open":if not os.path.exists(file_path):print(f"? 文件不存在,無法打開:{file_path}")return Nonedoc = Document(file_path) # 打開現有文檔print(f"? 成功打開Word文檔:{file_path}")# 打印文檔中的段落數量print(f" 文檔包含 {len(doc.paragraphs)} 個段落。")else:print("?? 無效的模式。")return Nonereturn docexcept Exception as e:print(f"? 處理Word文檔失敗:{e}")return Noneif __name__ == "__main__":new_doc_path = os.path.expanduser("~/Desktop/new_empty_doc.docx")existing_doc_path = os.path.expanduser("~/Desktop/existing_sample_doc.docx")# 創建一個示例現有文檔用于測試if not os.path.exists(existing_doc_path):doc = Document()doc.add_paragraph("這是一個用于測試的現有文檔。")doc.save(existing_doc_path)# 示例1:創建新文檔new_doc = create_or_open_word_doc(new_doc_path, mode="new")if new_doc:new_doc.add_paragraph("這是Python創建的第一個段落。")new_doc.save(new_doc_path)print(f"新文檔已保存到:{new_doc_path}")# 示例2:打開現有文檔opened_doc = create_or_open_word_doc(existing_doc_path, mode="open")if opened_doc:# 可以對 opened_doc 進行后續操作pass
步驟:
準備環境: pip install python-docx。
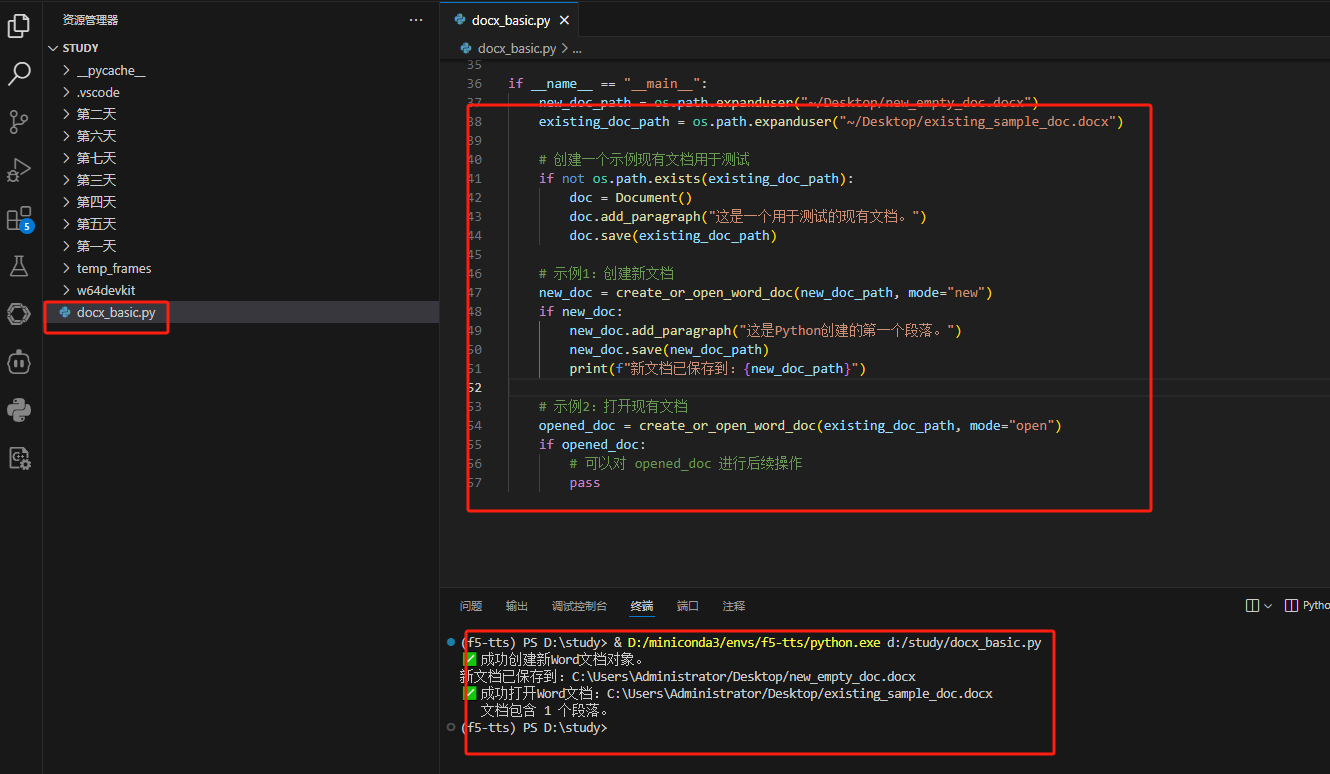
修改代碼路徑: 復制上方代碼到VS Code,保存為docx_basic.py。修改 new_doc_path 和 existing_doc_path。
運行: 運行 python docx_basic.py。
效果展示:
1.3 讀寫文本內容:讓Python填寫Word
場景: 你需要從Word文檔中提取文本內容進行分析,或者向Word文檔中插入新的文字、段落。
方案: python-docx能讓你像操作字符串一樣,方便地讀寫Word文檔中的文本內容,實現文檔批量修改。
代碼:
from docx import Document
from docx.shared import Inches # 用于設置圖片大小
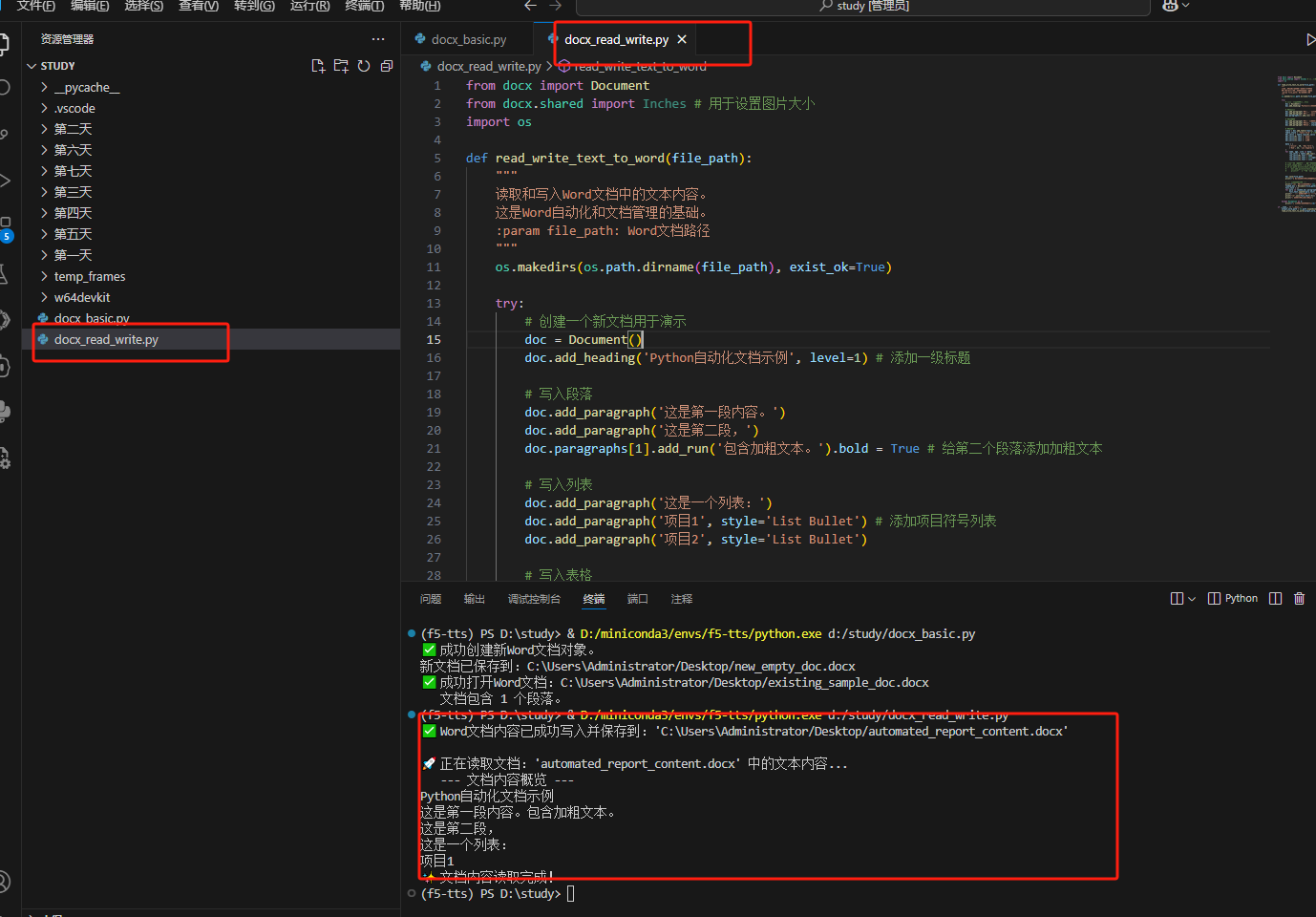
import osdef read_write_text_to_word(file_path):"""讀取和寫入Word文檔中的文本內容。這是Word自動化和文檔管理的基礎。:param file_path: Word文檔路徑"""os.makedirs(os.path.dirname(file_path), exist_ok=True)try:# 創建一個新文檔用于演示doc = Document()doc.add_heading('Python自動化文檔示例', level=1) # 添加一級標題# 寫入段落doc.add_paragraph('這是第一段內容。')doc.add_paragraph('這是第二段,')doc.paragraphs[1].add_run('包含加粗文本。').bold = True # 給第二個段落添加加粗文本# 寫入列表doc.add_paragraph('這是一個列表:')doc.add_paragraph('項目1', style='List Bullet') # 添加項目符號列表doc.add_paragraph('項目2', style='List Bullet')# 寫入表格table = doc.add_table(rows=1, cols=3)table.style = 'Table Grid' # 設置表格樣式hdr_cells = table.rows[0].cellshdr_cells[0].text = '姓名'hdr_cells[1].text = '年齡'hdr_cells[2].text = '城市'data = [('Alice', 30, 'New York'),('Bob', 25, 'Los Angeles')]for name, age, city in data:row_cells = table.add_row().cellsrow_cells[0].text = namerow_cells[1].text = str(age)row_cells[2].text = city# 插入圖片 (需要準備一張圖片文件)# test_image_path = os.path.expanduser("~/Desktop/sample_image.png")# if os.path.exists(test_image_path):# doc.add_picture(test_image_path, width=Inches(1.25)) # 插入圖片并設置寬度# print(f" ? 圖片 '{os.path.basename(test_image_path)}' 已插入。")doc.save(file_path)print(f"? Word文檔內容已成功寫入并保存到:'{file_path}'")# --- 讀取文檔內容 ---print(f"\n🚀 正在讀取文檔:'{os.path.basename(file_path)}' 中的文本內容...")loaded_doc = Document(file_path)full_text = []for para in loaded_doc.paragraphs:full_text.append(para.text)print(" --- 文檔內容概覽 ---")print("\n".join(full_text[:5])) # 打印前5個段落print("? 文檔內容讀取完成!")except Exception as e:print(f"? 讀寫Word文檔失敗:{e}")if __name__ == "__main__":output_word_path = os.path.expanduser("~/Desktop/automated_report_content.docx")read_write_text_to_word(output_word_path)
步驟:
準備環境: pip install python-docx。
修改代碼路徑: 復制上方代碼到VS Code,保存為docx_read_write.py。修改 output_word_path。
運行: 運行 python docx_read_write.py。
效果展示:
2.Python批量生成個性化Word文檔
這是Word自動化最核心的應用之一!批量生成文檔如合同、報告、證書等,通過模板填充實現個性化,徹底告別手動復制粘貼!
作用: 預先設計好包含“占位符”的Word模板文件,Python腳本讀取外部數據(如Excel),然后用真實數據替換模板中的占位符,生成新的文檔。
2.1 設計Word模板:word自動化開始
場景: 你有100份需要發給不同客戶的合同,其中只有“客戶名稱”、“合同金額”、“日期”等少數信息不同。
方案: 在Word中創建帶有特殊標記(如{{客戶名稱}})的文本,作為Python識別和替換的占位符。
模板:
這是一份重要的合同
合同編號:{{合同編號}}
甲方:{{甲方名稱}}
乙方:{{乙方名稱}}
簽訂日期:{{簽訂日期}}
合同金額:人民幣 {{合同金額}} 元整
… (其他合同條款) …
請雙方簽字確認。
2.2 讀取數據與智能填充:數據
場景: 你有100個客戶的合同數據存在Excel里,需要自動生成100份定制化的合同。
方案: Python腳本(通常結合Pandas讀取Excel)能讀取這些數據,然后遍歷數據,逐個生成個性化文檔。
代碼:
pip install xlrd
from docx import Document
import pandas as pd
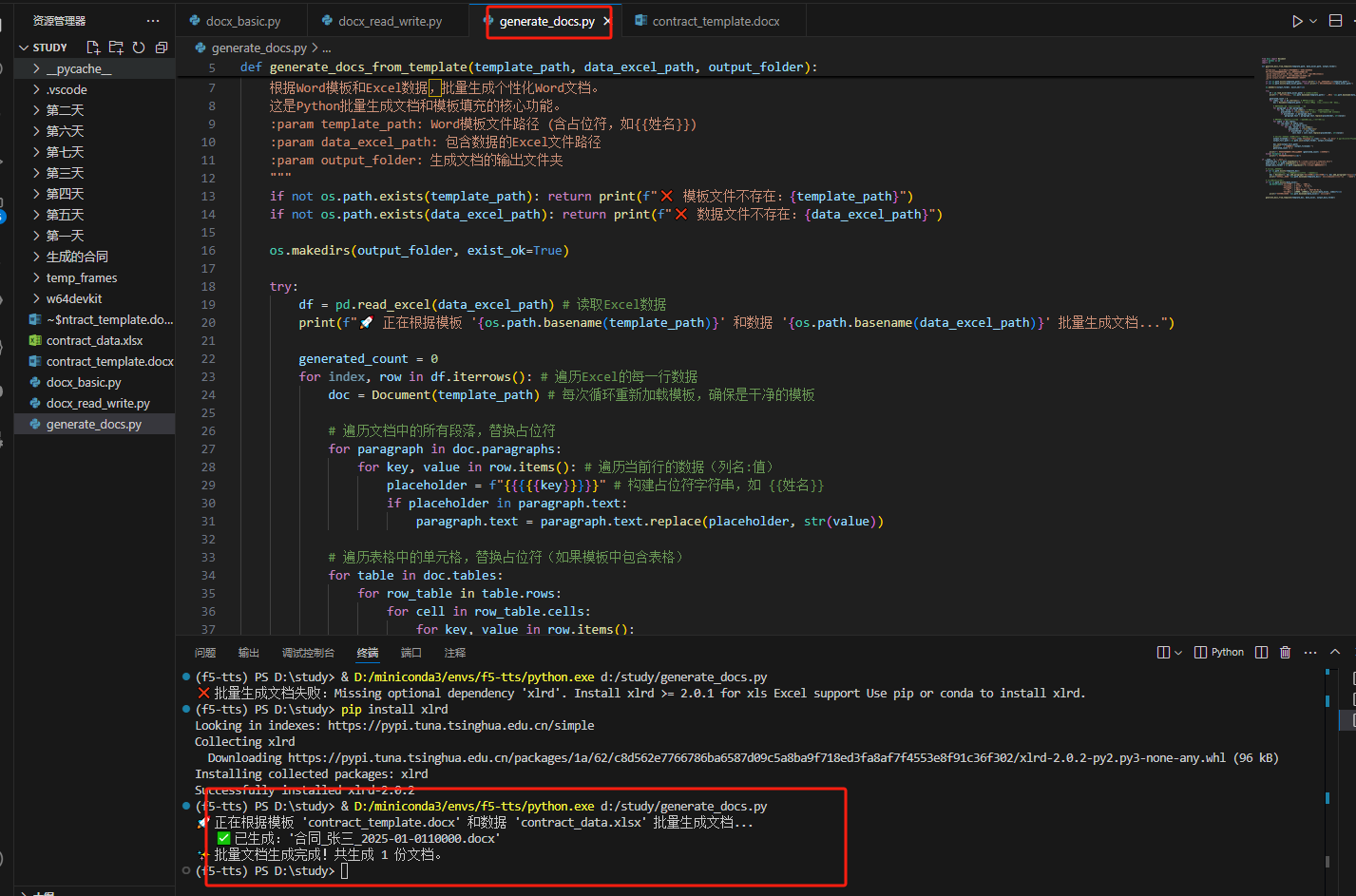
import osdef generate_docs_from_template(template_path, data_excel_path, output_folder):"""根據Word模板和Excel數據,批量生成個性化Word文檔。這是Python批量生成文檔和模板填充的核心功能。:param template_path: Word模板文件路徑 (含占位符,如{{姓名}}):param data_excel_path: 包含數據的Excel文件路徑:param output_folder: 生成文檔的輸出文件夾"""if not os.path.exists(template_path): return print(f"? 模板文件不存在:{template_path}")if not os.path.exists(data_excel_path): return print(f"? 數據文件不存在:{data_excel_path}")os.makedirs(output_folder, exist_ok=True)try:df = pd.read_excel(data_excel_path) # 讀取Excel數據print(f"🚀 正在根據模板 '{os.path.basename(template_path)}' 和數據 '{os.path.basename(data_excel_path)}' 批量生成文檔...")generated_count = 0for index, row in df.iterrows(): # 遍歷Excel的每一行數據doc = Document(template_path) # 每次循環重新加載模板,確保是干凈的模板# 遍歷文檔中的所有段落,替換占位符for paragraph in doc.paragraphs:for key, value in row.items(): # 遍歷當前行的數據(列名:值)placeholder = f"{{{{{key}}}}}" # 構建占位符字符串,如 {{姓名}}if placeholder in paragraph.text:paragraph.text = paragraph.text.replace(placeholder, str(value))# 遍歷表格中的單元格,替換占位符(如果模板中包含表格)for table in doc.tables:for row_table in table.rows:for cell in row_table.cells:for key, value in row.items():placeholder = f"{{{{{key}}}}}"if placeholder in cell.text:cell.text = cell.text.replace(placeholder, str(value))# 構建輸出文件名 (例如:合同_客戶名稱.docx)output_filename = f"合同_{row['乙方名稱']}_{row['簽訂日期']}.docx" # 假設Excel有“乙方名稱”和“簽訂日期”列output_full_path = os.path.join(output_folder, output_filename)doc.save(output_full_path)print(f" ? 已生成:'{output_filename}'")generated_count += 1print(f"? 批量文檔生成完成!共生成 {generated_count} 份文檔。")except Exception as e:print(f"? 批量生成文檔失敗:{e}")if __name__ == "__main__":template_doc = os.path.expanduser("~/Desktop/contract_template.docx")data_excel = os.path.expanduser("~/Desktop/contract_data.xlsx")output_docs_folder = os.path.expanduser("~/Desktop/生成的合同")# 確保模板文件存在if not os.path.exists(template_doc):# 簡單創建模擬模板 (用戶需手動創建帶有占位符的docx)doc = Document(); doc.add_paragraph("合同編號:{{合同編號}}"); doc.add_paragraph("甲方:{{甲方名稱}}"); doc.save(template_doc)print(f"臨時模板文件 '{os.path.basename(template_doc)}' 已創建。請手動在其中添加占位符。")# 確保數據Excel存在if not os.path.exists(data_excel):pd.DataFrame({'合同編號': ['C001', 'C002'], '甲方名稱': ['A公司', 'B公司'], '乙方名稱': ['張三', '李四'], '簽訂日期': ['2025-01-01', '2025-02-01'], '合同金額': [10000, 15000]}).to_excel(data_excel, index=False)print(f"臨時數據文件 '{os.path.basename(data_excel)}' 已創建。")generate_docs_from_template(template_doc, data_excel, output_docs_folder)
步驟:
準備模板: 創建一個contract_template.docx文件,按照示例添加{{占位符}}。
準備數據: 創建一個contract_data.xlsx文件,包含與占位符對應的列數據。
修改代碼路徑: 修改 template_doc、data_excel、output_docs_folder。
運行: 運行 python generate_docs.py。
效果:
 ## 2.3 圖片與圖表的自動插入:讓文檔圖文并茂
## 2.3 圖片與圖表的自動插入:讓文檔圖文并茂
場景: 你的報告需要插入多張圖片或由Python生成的圖表,手動調整大小和位置非常耗時。
方案: python-docx支持圖片和圖表的自動插入,并能控制其大小,讓你的報告瞬間變得圖文并茂、專業美觀!
代碼:
from docx import Document
from docx.shared import Inches # 用于設置圖片大小
import os
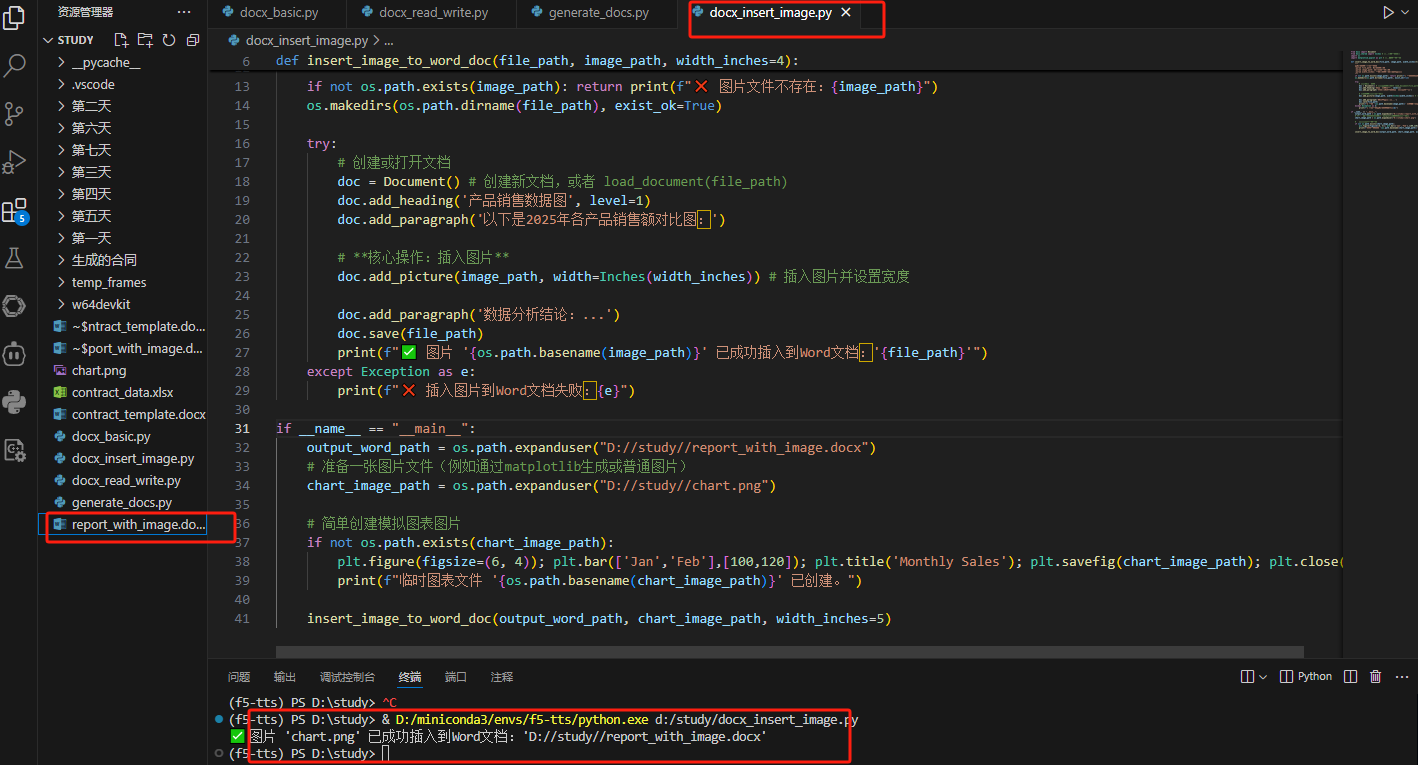
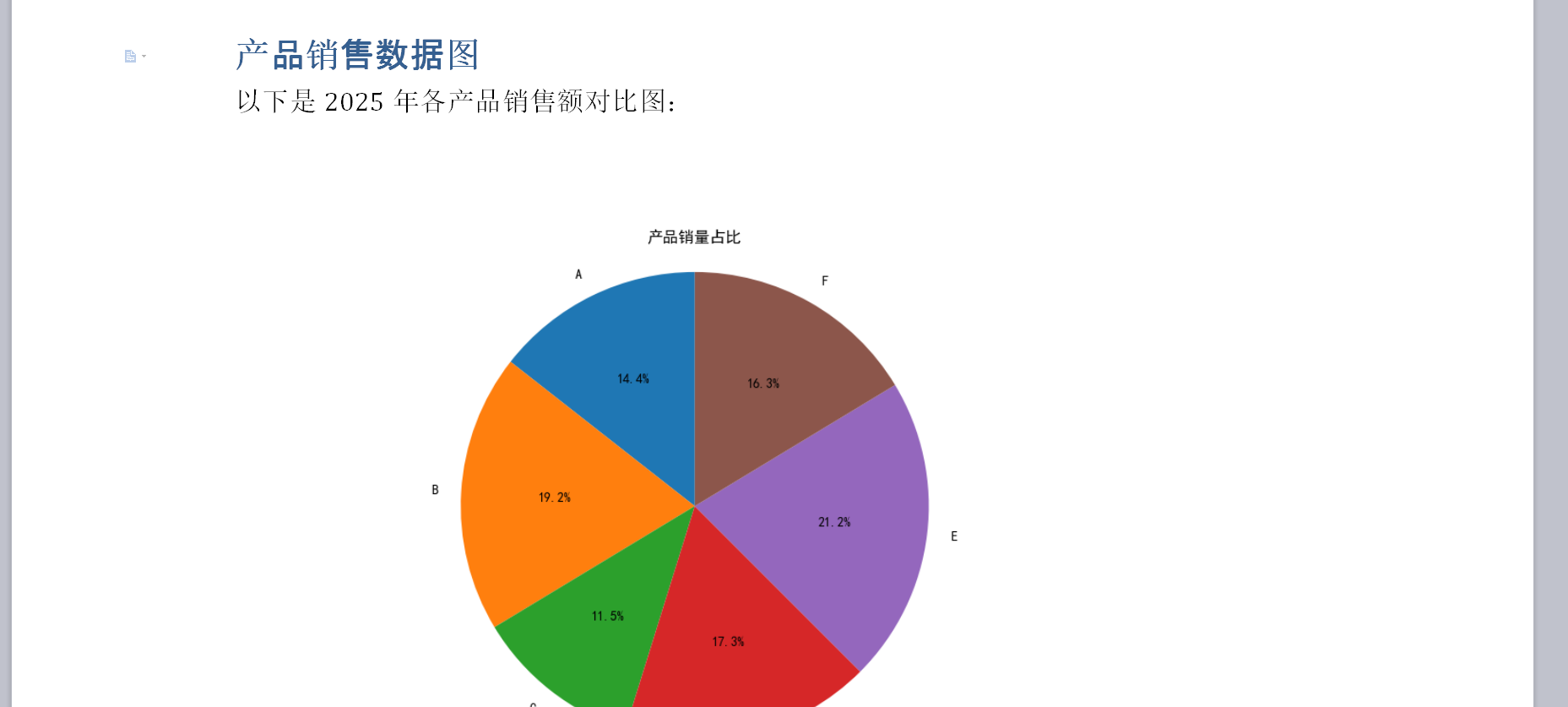
import matplotlib.pyplot as plt # 用于生成圖表圖片def insert_image_to_word_doc(file_path, image_path, width_inches=4):"""向Word文檔中插入圖片。:param file_path: Word文檔路徑:param image_path: 要插入的圖片路徑:param width_inches: 圖片在文檔中的寬度(英寸)"""if not os.path.exists(image_path): return print(f"? 圖片文件不存在:{image_path}")os.makedirs(os.path.dirname(file_path), exist_ok=True)try:# 創建或打開文檔doc = Document() # 創建新文檔,或者 load_document(file_path)doc.add_heading('產品銷售數據圖', level=1)doc.add_paragraph('以下是2023年各產品銷售額對比圖:')# **核心操作:插入圖片**doc.add_picture(image_path, width=Inches(width_inches)) # 插入圖片并設置寬度doc.add_paragraph('數據分析結論:...')doc.save(file_path)print(f"? 圖片 '{os.path.basename(image_path)}' 已成功插入到Word文檔:'{file_path}'")except Exception as e:print(f"? 插入圖片到Word文檔失敗:{e}")if __name__ == "__main__":output_word_path = os.path.expanduser("~/Desktop/report_with_image.docx")# 準備一張圖片文件(例如通過matplotlib生成或普通圖片)chart_image_path = os.path.expanduser("~/Desktop/sample_chart_for_word.png")# 簡單創建模擬圖表圖片if not os.path.exists(chart_image_path):plt.figure(figsize=(6, 4)); plt.bar(['Jan','Feb'],[100,120]); plt.title('Monthly Sales'); plt.savefig(chart_image_path); plt.close()print(f"臨時圖表文件 '{os.path.basename(chart_image_path)}' 已創建。")insert_image_to_word_doc(output_word_path, chart_image_path, width_inches=5)
步驟:
準備環境: pip install python-docx matplotlib。
準備圖片: 準備一張圖片文件(如sample_chart_for_word.png),最好是圖表圖片。
修改代碼路徑: 修改 output_word_path 和 chart_image_path。
運行: 運行 python docx_insert_image.py。
效果展示:
3.Python實現批量替換、格式調整!
僅僅生成和填充還不夠,Word自動化的真正威力在于對文檔內容的靈活修改和自動化排版,徹底告別繁瑣排版!
作用: python-docx允許你遍歷文檔的段落和運行(Run),查找并替換文本,以及直接修改文本的字體、顏色、大小、對齊方式。
3.1 批量替換內容:告別Ctrl+H,一鍵修改文檔
場景: 公司名稱變更,你需要修改幾十份舊合同中的公司名稱;或者一個報告中多次出現的某個關鍵詞需要批量更新。手動Ctrl+H查找替換,效率低下且容易遺漏。
方案: Python腳本可以打開Word文檔,遍歷所有段落,并對其中的文本進行批量替換,效率遠超手動操作!
代碼:
from docx import Document
import os
from docx.text.run import Run # 導入Run類,用于更細致的文本操作
from docx.enum.text import WD_ALIGN_PARAGRAPH # 可能會用到,為了樣式操作
import shutil # 用于文件操作,如復制文件def _replace_text_in_run(run: Run, old_text: str, new_text: str):"""替換單個Run中的文本,并返回是否發生了替換。盡量保留原有Run的格式。"""if old_text not in run.text:return False# 替換Run的文本,并嘗試保留格式# 這是一種簡單粗暴的替換,可能會丟失復雜格式,但對大多數情況有效# 更高級的替換需要刪除舊Run,創建新Run并逐個復制格式屬性run.text = run.text.replace(old_text, new_text)return Truedef _replace_text_in_paragraph_robust(paragraph, replacements):"""魯棒地替換段落中的文本,處理跨Run的情況。"""original_text = paragraph.text # 獲取段落的完整文本found_and_replaced = Falsefor old_text, new_text in replacements.items():if old_text in original_text: # 如果段落的完整文本中包含要替換的字符串# 標記需要替換,即使現在不立即替換Runfound_and_replaced = True # 這是一個簡化的處理策略:先刪除所有舊的Run,再添加一個新Run來替換# 這種方法會丟失段落內部的格式(如粗體、斜體),但能保證替換的準確性# 如果需要保留格式,實現會非常復雜,涉及掃描和拆分Run# 簡單策略:如果找到匹配,清空段落所有runs,然后寫入新的文本# 這種方法會丟失原段落內所有格式,但最簡單有效paragraph.clear() # 清空段落所有內容new_run = paragraph.add_run(original_text.replace(old_text, new_text))# TODO: 復制舊Run的格式到新Run,這里僅做示意,實際需要更復雜的邏輯# for r in original_runs:# new_run.bold = r.bold# new_run.italic = r.italic# new_run.font.size = r.font.size# ...等等所有格式屬性print(f" ? 替換:'{old_text}' -> '{new_text}' 在段落中。")# 更新 original_text 以便處理同一段落內的多個替換original_text = original_text.replace(old_text, new_text)return found_and_replaceddef batch_replace_text_in_doc(file_path, replacements):"""批量替換Word文檔中的文本內容。這是文檔批量修改的核心功能,告別手動Ctrl+H。:param file_path: Word文檔路徑:param replacements: 替換字典,格式為 {舊文本: 新文本}"""if not os.path.exists(file_path): return print(f"? Word文件不存在:{file_path}")# 構建輸出路徑,避免覆蓋原文件output_path = os.path.join(os.path.dirname(file_path), "modified_" + os.path.basename(file_path))temp_doc_path = os.path.join(os.path.dirname(file_path), "temp_" + os.path.basename(file_path))try:# 先將原始文檔復制一份進行操作,避免直接修改源文件shutil.copyfile(file_path, temp_doc_path)doc = Document(temp_doc_path) # 打開臨時文檔進行修改print(f"🚀 正在批量替換 '{os.path.basename(file_path)}' 中的文本...")replaced_count = 0# 遍歷文檔中的所有段落for paragraph in doc.paragraphs:if _replace_text_in_paragraph_robust(paragraph, replacements):replaced_count += 1# 遍歷表格中的單元格 (如果文檔中包含表格)for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph_in_cell in cell.paragraphs: # 單元格內也可能有多個段落if _replace_text_in_paragraph_robust(paragraph_in_cell, replacements):replaced_count += 1doc.save(output_path)print(f"? 批量文本替換完成!共進行 {replaced_count} 處替換。修改后的文檔已保存到:'{output_path}'")except Exception as e:print(f"? 批量文本替換失敗:{e}")finally:# 清理臨時文件if os.path.exists(temp_doc_path):os.remove(temp_doc_path)if __name__ == "__main__":# 準備一個包含要替換內容的Word文檔test_doc_path = os.path.expanduser("D://study//company_report_v11.docx")# 簡單創建模擬文檔 (確保有多個包含關鍵字的段落和表格)if not os.path.exists(test_doc_path):doc = Document()doc.add_heading("年度運營報告 - 【繁星娛樂】", level=1)doc.add_paragraph("本報告由【繁星娛樂】撰寫,版本為v1.0。")doc.add_paragraph("請【繁星娛樂】的所有員工注意。")# 添加一個表格table = doc.add_table(rows=2, cols=2)table.cell(0, 0).text = "部門"table.cell(0, 1).text = "負責人"table.cell(1, 0).text = "銷售部"table.cell(1, 1).text = "【繁星娛樂】代表"doc.save(test_doc_path)print(f"臨時測試文檔 '{os.path.basename(test_doc_path)}' 已創建。")replacements_dict = {"【繁星娛樂】": "【11111111】","v1.0": "v2.0"}batch_replace_text_in_doc(test_doc_path, replacements_dict)
步驟:
準備Word文檔: 在桌面創建一個company_report_v1.docx,其中包含一些需要替換的文本。
修改代碼路徑和替換字典: 修改 test_doc_path 和 replacements_dict。運行: 運行 python docx_batch_replace.py。
效果展示:

3.2 字體、顏色、大小與對齊:自動化專業排版
場景: 你需要為報告中的某個標題加粗、設為紅色,某個段落調整字體大小和對齊方式。手動逐個設置,耗時且難以保持一致性。
方案: python-docx可以精確控制文本的字體、大小、顏色、粗斜體,以及段落的對齊方式,實現文檔排版自動化。
代碼:
from docx import Document
from docx.shared import Pt, RGBColor # Pt用于磅數,RGBColor用于顏色
from docx.enum.text import WD_ALIGN_PARAGRAPH # 用于段落對齊
import osdef auto_format_word_doc(file_path):"""自動化設置Word文檔的字體、顏色、大小與對齊方式。這是文檔排版自動化和Python操作Word的高級功能。:param file_path: Word文檔路徑"""os.makedirs(os.path.dirname(file_path), exist_ok=True)try:# 創建新文檔用于演示doc = Document()# 1. 添加標題并設置樣式heading = doc.add_heading('Python自動化排版報告', level=1)# 訪問標題的run,設置字體大小和加粗heading.runs[0].font.size = Pt(24) # 24磅heading.runs[0].font.bold = Trueheading.runs[0].font.color.rgb = RGBColor(0x42, 0x24, 0xE9) # 藍色# 2. 添加段落并設置樣式paragraph1 = doc.add_paragraph('這是一段重要的摘要內容。')paragraph1.runs[0].font.name = 'Arial' # 設置字體paragraph1.runs[0].font.size = Pt(12)paragraph1.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY # 兩端對齊paragraph2 = doc.add_paragraph('本段內容將居中顯示,并設置為斜體。')paragraph2.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中對齊paragraph2.runs[0].font.italic = True # 斜體doc.save(file_path)print(f"? Word文檔排版已成功設置并保存到:'{file_path}'")except Exception as e:print(f"? Word文檔排版失敗:{e}")if __name__ == "__main__":output_word_path = os.path.expanduser("~/Desktop/automated_formatted_doc.docx")auto_format_word_doc(output_word_path)
步驟:
準備環境: pip install python-docx。
修改代碼路徑: 修改 output_word_path。
運行: 運行 python docx_auto_format.py。
效果展示:

4.Word文檔工廠
恭喜你!通過本篇文章,你已經掌握了Word文檔自動化的各項核心魔法,親手打造了一個能夠批量生成、模板填充、內容修改的* Word文檔工廠”
們深入學習了python-docx庫,它堪稱Word文檔的**“瑞士軍刀”**,實現了:
Word文檔批量生成: 結合數據,一鍵生成海量個性化文檔,告別重復性文檔制作。
智能模板填充: 利用占位符,精準將數據填充到Word模板,杜絕手動填充模板的低效。
文檔內容修改與排版優化: 批量替換文本,自動化設置字體、顏色、大小、對齊方式,徹底告別繁瑣排版。
5.Word自動化,開啟智能文檔管理新時代!
通過本篇文章,你已經掌握了Word文檔自動化的強大能力,為你的辦公自動化之旅又增添了一個重量級技能!你學會了如何利用Python的python-docx庫,高效地進行Word文檔的創建、填充、修改與排版。
除了今天學到的Word自動化功能,你還希望Python能幫你實現哪些更復雜的文檔處理需求?比如:自動提取Word文檔中的特定信息?將Word文檔內容智能生成摘要?在評論區分享你的需求和想法,你的建議可能會成為我們未來文章的靈感來源!
敬請期待! Word自動化系列至此告一段落。在下一篇文章中,我們將繼續深入Python辦公自動化的寶庫,探索如何利用Python實現PDF文檔自動化,包括PDF的合并、拆分、加水印、文本提取等,讓你的文檔管理更高效、更智能!同時,本系列所有代碼都將持續更新并匯總在我的GitHub倉庫中,敬請關注!未來,這個**“Python職場效率專家實戰包”還將包含更多開箱即用、功能強大**的自動化工具。









)









)