目錄
一. 為什么需要 Kubernetes
1. 對于開發人員
2. 對于運維人員
3. Kubernetes 帶來的挑戰
二. Kubernetes 架構解析
1. master 節點的組件
2. Node 節點包含的組件
3. kubernetes網絡插件
三. kubeadm塊速安裝kubernetes集群
1. 基礎環境準備(此步驟在三個節點都執行)
2. 部署 docker 環境(此步驟在三個節點都執行)
3. 部署 Kubernetes 集群(注意命令執行的節點)
四. Metrics-server部署
1. 下載Metrics-server的yaml 文件
2. 修改yaml文件并安裝
3. 測試安裝結果
五. kuboard部署
1. 資源管理與可視化展示
2. 集群監控與運維
3. 多集群管理
4. 應用部署與管理
5. 部署Kuboard
六. 安裝helm
一. 為什么需要 Kubernetes
很多人會有疑問,有了 Docker 為什么還用 Kubernetes?
在業務開始進行容器化時,前期需要容器化的項目可能并不多,涉及的容器也并不多,此時基于Docker 容器直接部署至宿主機也能實現基本的需求。但是隨著項目越來越多,管理的容器也會越來越多此時使用“裸容器”部署的方式管理起來就顯得很吃力,并且隨著業務量的增加,會明顯體會到“裸容器的不足。
比如:
宿主機宕機造成該宿主機上的容器不可用,且無法自動恢復。
容器明明在運行,接口就是不通(健康檢查做得不到位)
應用程序部署、回滾、擴縮容困難。
成百上千的容器和涉及的端口難以維護。
kubernetes跟裸容器對比
| 對比維度 | Kubernetes 架構 | 裸容器(單機容器) |
|---|---|---|
| 集群管理 | 支持大規模集群(上千節點),自動調度和負載均衡。 | 僅支持單機部署,無法跨節點管理容器。 |
| 服務發現與負載均衡 | 內置服務(Service)機制,自動注冊和發現容器實例,支持 TCP/UDP 負載均衡。 | 需手動配置 Nginx、HAProxy 等外部工具,或依賴容器網絡插件。 |
| 伸縮與彈性 | 支持水平自動擴縮容(HPA),基于 CPU / 內存 / 自定義指標動態調整副本數。 | 需手動創建或刪除容器,無法自動響應流量變化。 |
| 可靠性與自愈 | 提供副本控制器(ReplicaSet)、部署(Deployment)等機制,自動重啟失敗容器、替換故障節點。 | 容器故障需手動重啟,無自動恢復能力。 |
| 部署與更新策略 | 支持滾動更新、藍綠部署、金絲雀發布,確保服務不中斷。 | 部署需停機,更新過程可能導致服務中斷。 |
| 資源管理 | 基于標簽(Label)和選擇器(Selector)精細調度資源,支持資源配額和限制。 | 資源分配依賴手動配置(如docker run --memory),可能導致資源浪費或競爭。 |
| 網絡與存儲 | 內置網絡插件(如 Calico、Flannel)支持容器間通信,支持 PV/PVC 動態管理存儲。 | 需手動配置容器網絡(如橋接、主機模式),存儲掛載需手動維護。 |
| 監控與日志 | 集成 Prometheus、Fluentd 等生態工具,支持集群級監控和日志聚合。 | 需單獨配置單機監控(如 Docker Stats),日志分散在各容器中。 |
| 生態與工具鏈 | 擁有豐富的生態系統(Helm、Istio、Argo CD 等),支持 CI/CD 自動化。 | 工具鏈碎片化,需手動集成各組件,自動化難度高。 |
1. 對于開發人員
由于公司業務多,開發環境、測試環境、預生產環境和生產環境都是隔離的,而且除了生產環境,為了節省成本,其他環境可能沒有進行日志收集。在沒有用 Kubernetes 的時候,查看線下測試的日志,需要開發者或測試人員找到對應的機器,再找到對應的容器,才能査看對應的日志。在使用 Kubernetes 之后,開發人員和測試者直接在 Kubernetes 的 Dashboard 上找到對應的 namespace,即可定位到業務所在的容器,然后可以直接通過控制臺查看到對應的日志,大大降低了操作時間。
把應用部署到 Kubernetes 之后,代碼的發布、回滾以及藍綠發布、金絲雀發布等變得簡單可控,不僅加快了業務代碼的迭代速度,而且全程無須人工干預。生產環境可以使用 jenkins、git 等工具進行發版或回滾等。從開發環境到測試環境,完全遵守一次構建,多集群、多環境部,通過不同的啟動參數、不同的環境變量、不同的配置文件區分不同的環境。
在使用服務網格后,開發人員在開發應用的過程中,無須去關心代碼的網絡部分,這些功能被服務網格實現,讓開發人員可以只關心代碼邏輯部分,即可輕松實現網絡部分的功能,比如斷流、分流、路由、負載均衡、限速和觸發故障等功能。
在測試過程中,可能同時存在多套環境,當然也會創建其他環境或臨時環境,之前測試環境的創建需要找運維人員或者自行手工搭建。在遷移至 Kubernetes 集群后,開發人員如果需要新的環境,無須再找運維,只需要在 jenkins 上點點鼠標即可在 Kubernetes 集群上創建一套新的測試環境。
2. 對于運維人員
對于運維人員,可能經常因為一些重復、煩瑣的工作感到厭倦,比如一個項目需要一套新的測試環境。另一個項目需要遷移測試環境至其他平臺。傳統架構可能需要裝系統、裝依賴環境、部署域名、開通權限等,這一套下來,不僅耗時,而且可能會因為有某些遺漏而造成諸多問題。而如今,可以直接使用Kubernetes 包管理工具,一鍵式部署一套新的測試環境,甚至全程無須自己干預,開發人員通過 jenkins或者自動化運維平臺即可一鍵式創建,大大降低了運維成本。
在傳統架構體系下,公司業務故障可能是因為基礎環境不一致、依賴不一致、端口沖突等問題,而現在使用 docker 鏡像部署,Kubernetes 進行編排,所有的依賴、基礎都是一樣的,并且環境的自動化擴容、健康檢査、容災、恢復都是自動的,大大減少了因為這類基礎問題引發的故障。另外,也有可能公司業務由于服務器宕機、網絡等問題造成服務不可用,此類情況均需要運維人員及時去修復,而在Kubernetes 中,可能在收到嚴重告警信息時,Kubernetes 已經自動恢復完成了。
在沒有使用 Kubernetes 時,業務應用的擴容和縮容需要人工去處理,從采購服務器、上架到部署依賴環境,不僅需要大量的人力物力,而且非常容易在中間過程出現問題,又要花大量的時間去查找問題。成功上架后,還需要在前端負載均衡添加該服務器,而如今,可以利用 Kubernetes 的彈性計算一鍵式擴容和縮容,不僅大大提高了運維效率,而且還節省了不少的服務器資源,提高了資源利用率。
在反向代理配置方面,可能對 nginx的配置規則并不熟悉,一些高級的功能也很難實現,但是在Kubernetes 上,利用 Kubernetes 的 ingress 即可簡單的實現那些復雜的邏輯,并且不會再遇到 nginx少加一個斜杠和多加一個斜杠的問題。
在負載均衡方面,之前負載均衡可能是 nginx、LVS、Haproxy、F5 等,云上可能是云服務商提供的負載均衡機制。每次添加和刪除節點時,都需要手動去配置前端負載均衡,手動去匹配后端節點。在使用Kubernetes 進行編排服務時,使用 Kubernetes 內部的 Service 即可實現自動管理節點,并且支持自動擴容、縮容。
在高可用方面,Kubernetes 天生的高可用功能讓運維人員徹底釋放了雙手,無需再去創建各類高可用工具,以及檢測腳本。Kubernetes 支持進程、接口級別的健康檢査,如果發現接口超時或者返回值不正確,會自動處理該問題。
在中間件搭建方面,根據定義好的資源文件,可以實現秒級搭建各類中間件高可用集群,且支持一鍵式擴容、縮容,如 Redis、RabbitMQ、Zookeeper 等,并且大大減少了出錯的概率。
在應用端口方面,傳統架構中,一臺服務器可能跑了很多進程,每個進程都有一個端口,要認為的去配置端口,并且還需要考慮端口沖突的問題,如果有防火墻的話,還需要配置防火墻,在 Kubernetes 中,端口統一管理、統一配置,每個應用的端口都可以設置成一樣的,之后通過 Service 進行負載均衡,大大降低了端口管理的復雜度和端口沖突。
無論是對于開發人員、測試人員還是運維人員,Kubernetes 的誕生不僅減少了工作的復雜度,還減少了各種運維成本。
3. Kubernetes 帶來的挑戰
Kubernetes 從誕生至今,一路突飛猛進,在容器編排的領域過關斬將,最終拿下了容器編排的冠軍寶座,成為最無可替代、不可撼動的佼佼者,但是針對 Kubernetes 的學習和使用始終是一個很大的難題。
首先,Kubernetes 本身的學習就很困難,因為Kubernetes 概念太多,涉及的知識面也非常廣泛可能學習了一個月也無法入門,甚至連集群也搭建不出來,使人望而卻步。并且 Kubernetes 的技術能力要求也比較高,因為運維不僅僅均線于傳統運維,有時候可能要修改業務代碼、制定業務上線體系、給研發人員在開發應用中提供更好的建議等。需要掌握的知識也有很多,可能需要掌握公司內所有使用帶的代碼,比如代碼如何進行編譯、如何正確發布、如何修改代碼配置文件等,這對于運維人員也是一種挑戰。Kubernetes 的誕生把運維從傳統的運維轉變到了 DevOps 方向,需要面臨的問題更多,需要面臨的新技術也很多,但是當真正掌握 Kubernetes 的核心和涉及理念,就會收益終身。
二. Kubernetes 架構解析
Kubernetes 的架構圖:

由圖可知,Kubernetes 架構可以簡單分為主(master)節點,從(worker/node)節點和數據庫 ETCD其中主節點為集群的控制單元,一般不會運行業務應用程序,主要包含的組件 Kube-APIServer.Kube-ControllerManager、Kube-scheduler。從節點為工作節點,也就是部署應用程序容器的節點,主要包含的組件有 Kubelet、Kube-Proxy,當然如果 master 節點也要部署容器,也會包含這兩個組件
同時,可以看出一個集群中可以有多個 node 節點,用于保證集群容器的分布式部署,以保證業務的高可用性,也可以有很多的 master 節點,之后通過一個負載均衡保證集群控制節點的高可用。負載均衡可以使用軟件負載均衡 Nginx、LVS、Haproxy+Keepalived 或者硬件負載均衡 F5 等,通過負載均衡對Kube-APIServer 提供的 VIP 即可實現 master 節點的高可用,其他組件通過該 VIP 連接至Kube-APIServer。ETCD 集群可以和 master 節點部署在同一個宿主機,也可以單獨部署,生產環境建議部署大于3的奇數臺 ETCD 節點用于實現 ETCD 集群的高可用。etcd 的 Leader 選舉和數據寫入都需要半數以上的成員投票通過確認,因此,集群最好由奇數個成員組成,以確保集群內部一定能夠產生多數投票通過的場景。這也就是為什么 etcd 集群至少需要 3 個以上的成員。
1. master 節點的組件
master 節點是 Kubernetes 集群的控制節點,在生產環境中不建議部署集群核心組件外的任何容器(在 kubeadm 安裝方式下,系統組件以容器方式運行在 master 節點的宿主機上;二進制安裝方式下,系統組件以守護進程的方式運行,master節點可以不運行任何容器),公司業務程序的容器是不建議部署在 master 節點上,以免升級或者維護時對業務在成影響。
(1) API server
API server 提供了集群網關,是整個集群的控制中樞,提供集群中各個模塊之間的數據交換,并將集群信息存儲到 ETCD 集群中。同時,它也是集群管理、資源配額、提供完備的集群安全機制的入口,頭集群各類資源對象提供增刪改査。API server 在客戶端對集群進行訪問, 客戶端需要通過認證, 并使用 API server 作為訪問節點和 pod (以及服務)的堡壘和代理/通道。
- API 服務器公開 Kubernetes API。
- REST/kubect1 的入口點--它是 Kubernetes 控制平面的前端。
- 它跟蹤所有集群組件的狀態并管理它們之間的交互。
- 它旨在水平擴展。
- 它使用 YAML/JSON manifest 文件。
- 它驗證和處理通過 API 發出的請求
(3) scheduler
Scheduler 主要功能是資源調度,將 pod 調度到對應的主機上。依據請求資源的可用性、服務請求的質量等約束條件,K8s 也支持用戶自己提供的調度器。
- 它將 pod 調度到工作節點。
- 它監視 api-server 以査找沒有分配節點的新創建的 Pod,并選擇一個健康的節點讓它們運行。
- 如果沒有合適的節點,則 Pod 將處于掛起狀態,直到出現這樣一個健康的節點。
- 它監視 API Server 的新工作任務。
(3) Controller Manager
Controller Manager 負責維護集群的狀態,比如故障檢測、內存垃圾回收、滾動更新等,也執行API 業務邏輯;K8s 默認提供 replication controller、replicaset controller、daemonsetcontroller 等控制器。
- 它監視它管理的對象的期望狀態并通過 API 服務器監視它們的當前狀態。
- 采取糾正措施以確保當前狀態與所需狀態相同。
- 它是控制器的控制器。
- 它運行控制器進程。從邏輯上講,每個控制器都是一個單獨的進程,但為了降低復雜性,它們都被編譯成一個二進制文件并在單個進程中運行。
(4) etcd
etcd 用于可靠的存儲集群的配置數據,是一種持久性、輕量型、分布式的鍵值數據存儲組件。可以理解為一種分布式的非關系型數據庫。etcd 是集群的狀態, K8s 默認使用分布式的 etcd 集群整體存儲用來實現發現服務和共享配置集群的所有狀態都存儲在 etcd 實例中,并具有監控的能力,因此當 etcd中的信息發生變化時,能夠快速地通知集群中相關的組件。
- 它是一個一致的、分布式的、高度可用的鍵值存儲。
- 它是有狀態的持久存儲,用于存儲所有 Kubernetes 集群數據(集群狀態和配置)
- 它是集群的真相來源。
- 它可以是控制平面的一部分,也可以在外部進行配置
etcd 集群最少3個節點,容錯點才會有1個。3個節點和4個節點的容錯能力是一樣的,所以有時候保持奇數節點更好,從這里可以判斷出我們在部署 k8s 的時候,至少有3個節點,才保證 etcd 有1個節點容錯性。
另外,etcd 的 Leader 選舉和數據寫入都需要半數以上的成員投票通過確認,因此,集群最好由奇數個成員組成,以確保集群內部一定能夠產生多數投票通過的場景。所以 etcd 集群至少需要 3 個以上的奇數個成員。
如果使用偶數個節點,可能出現以下問題:
- 偶數個節點集群不可用風險更高,表現在選主(Leader 選舉)過程中,有較大概率的等額選票從而觸發下一輪選舉。
- 偶數個節點集群在某些網絡分割的場景下無法正常工作。當網絡分割發生后,將集群節點對半分割開,形成腦裂。
2. Node 節點包含的組件
Node 節點也被成為 worker 節點,是主要負責部署容器的主機,集群中的每個節點都必須具備容器的Runtime(運行時),比如docker
kubelet 作為守護進程運行在 Node 節點上,負責監聽該節點上所有的 pod,同時負責上報該節點上所有 pod 的運行狀態,確保節點上的所有容器都能正常運行。當 Node 節點宕機或故障時,該節點上運行的 pod 會被自動轉移到其他節點上。
(1) 容器運行時
docker 引擎是本地的容器運行時環境,負責鏡像管理以及 pod 和容器的真正運行。K8s 本身并不提供容器運行時環境,但提供了接口,可以插入所選擇的容器運行時環境,目前支持 Docker 和 rkt。容器運行時是負責運行容器(在 Pod 中)的軟件,為了運行容器,每個工作節點都有一個容器運行時引擎,它從容器鏡像注冊表(container image registry)中提取鏡像并啟動和停止容器。
Kubernetes 支持多種容器運行時:
- Docker
- containerd
- CRI-0
- Kubernetes CRI(Container Runtime Interface,容器運行時接口)的任何實現。
(2) kubelet
kubelet 是 node 節點上最主要的工作代理,用于匯報節點狀態并負責維護 pod 的生命周期,也負責volume(CVI)和網絡(CNI)的管理。kubelet 是 pod 和節點 API 的主要實現者,負責驅動容器執行層作為基本的執行單元,pod 可以擁有多個容器和存儲卷,能夠方便地在每個容器中打包一個單一的應用,從而解耦了應用構建時和部署時所關心的事項,方便在物理機或虛擬機之間進行遷移。
- 它是在集群中的每個節點上運行的代理。
- 它充當 API 服務器和節點之間的管道。
- 它確保容器在 Pod 中運行并且它們是健康的,
- 它實例化并執行 Pod。
- 它監視 API Server 的工作任務。
- 它從主節點那里得到指令并報告給主節點。
(3) kube-proxy代理
kube-proxy 代理對抽象的應用地址的訪問,服務提供了一種訪問一群pod 的途徑, kube-proxy 負責為服務提供集群內部的服務發現和應用的負載均衡(通常利用 iptables 規則),實現服務到 pod 的路由和轉發。此方式通過創建一個虛擬的 IP 來實現,客戶端能夠訪問此 IP,并能夠將服務透明地代理至 pod。
- 它是網絡組件,在網絡中起著至關重要的作用。
- 它管理 IP 轉換和路由。
- 它是運行在集群中每個節點上的網絡代理。
- 它維護節點上的網絡規則。這些網絡規則允許從集群內部或外部與Pod 進行網絡通信。
- 它確保每個 Pod 獲得唯一的 IP 地址。
- 這使得 pod 中的所有容器共享一個 IP 成為可能。
- 它促進了 Kubernetes 網絡服務和服務中所有 pod 的負載平衡。
- 它處理單個主機子網并確保服務可供外部各方使用。
3. kubernetes網絡插件
CNI(容器網絡接口)是一個云原生計算基金會項目,它包含了一些規范和庫,用于編寫在 Linux
容器中配置網絡接口的一系列插件。CNI 只關注容器的網絡連接,并在容器被刪除時移除所分配的資源。
Kubernetes 使用 CNI 作為網絡提供商和 Kubernetes Pod 網絡之間的接口。

(1) Flannel網絡
由 Coreosk 開發的一個項目,很多部署工具或者 k8s 的發行版都是默認安裝,flanne1 是可以用集群現有的 etcd,利用 api 方式存儲自身狀態信息,不需要專門的數據存儲,是配置第三層的 ipv4 0verlay網絡,在此網絡內,每個節點一個子網,用于分配 ip 地址,配置 pod 時候,節點上的網橋接口會為每個新容器分配一個地址,同一主機中的 pod 可以使用網橋通信,不同主機的 pod 流量封裝在 udp 數據包中,路由到目的地。
Flannel 通過每個節點上啟動一個 f1nnel 的進程,負責給每一個節點上的子網劃分、將子網網段等信息保存至 etcd,具體的報文轉發是后端實現,在啟動時可以通過配置文件指定不同的后端進行通信目前有 UDP、VXLAN、host-gateway 三種,VXLAN 是官方推薦,因為性能良好,不需人工干預。UDP、VXLAN是基于三層網絡即可實現,host-gateway 模式需要集群所有機器都在同一個廣播域、就是需要在二層網絡在同一個交換機下才能實現,host-gateway 用于對網絡性能要求較高的常見,需要基礎網絡架構支持。UDP 用于測試或者不支持 VXLAN 的 linux 內核。反正一般小規模集群是完全夠用的,直到很多功能無法提供時在考慮其他插件。

(2) calico 網絡
雖然 fa1nne1 很好,但是 calico 因為其性能、靈活性都好而備受歡迎,calico 的功能更加全面,不但具有提供主機和 pod 間網絡通信的功能,還有網絡安全和管理的功能,而且在 CNI 框架之內封裝了calico 的功能,calico 還能與服務網絡技術 Istio 集成,不但能夠更加清楚的看到網絡架構也能進行靈活的網絡策略的配置,calico 不使用 overlay 網絡,配置在第三層網絡,使用 BGP 路由協議在主機之間路由數據包,意味著不需要包裝額外的封裝層。主要點在網絡策略配置這一點,可以提高安全性和網絡環境的控制。
如果集群規模較大,選擇 calico 沒錯,當然 calico 提供長期支持,對于一次配置長期使用的目的來說,是個很好的選擇。

三. kubeadm塊速安裝kubernetes集群
實驗環境
| 主機名 | IP地址 | 操作系統 | 主要軟件 |
| k8s-master | 192.168.10.101 | OpenEuler 2核、4G | docker CE、kube-apiserver、kub-controller-manager、kub-scheduler、kubelet、Etcd、kube-proxy |
| k8s-node01 | 192.168.10.102 | OpenEuler 2核、4G | docker CE、kubectl、kube-proxy、calico |
| k8s-node02 | 192.168.10.106 | OpenEuler 2核、4G | docker CE、kubectl、kube-proxy、calico |
備注:
依據案例環境為三臺主機配置 IP 地址、網關、DNS 等基礎信息,確保可連接互聯網,推薦虛擬機使用 NAT 模式。k8s-master 主機最小建議配置為 2 核 4G,k8s-node 節點最小建議配置 為 2 核 2G。
Kubernetes v1.23 支持高達 5000 節點。更準備地說,在使用 Kubernetes 時,應當遵循以下所有準則:
- 每個節點不要超過 110 個 Pod,
- 集群不要超過 5000 節點,
- 集群不要超過 150000 個 Pod,
- 不要超過 300080 個Container。
1. 基礎環境準備(此步驟在三個節點都執行)
正式開始部署 kubernetes 集群之前,先要進行如下準備工作。基礎環境相關配置操作在三臺主機k8s-master、k8s-node01、k8s-node02 上都需要執行
2. 部署 docker 環境(此步驟在三個節點都執行)
完成基礎環境準備之后,在三臺主機上分別部署 Docker 環境,因為 Kubernetes 對容器的編排需要 Docker 的支持。以 k8s-master 主機為例進行操作演示,首先安裝一些 Docker 的依賴包,然后將Docker 的 YUM 源設置成國內地址,最后通過 YUM 方式安裝 Docker 并啟動。
(1) 關閉防火墻、禁用SELinux
(2) 安裝docker(已有docker環境忽略詞步驟)
wget -0 /etc/yum.repos.d/centos-Base.repo https://mirrors.aliyun.com/repo/centos-7.repo
wget -0 /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo安裝必要工具
yum install -yyum-utils安裝docker-ce
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum clean all
yum makecache
yum -y install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin添加國內鏡像站
由于工信部網絡政策調整,docker.10、gcr.io 等國際鏡像站的訪問受限,無法使用這些國外的鏡像站拉取鏡像,因此我們需要設置國內的鏡像站。cat>/etc/docker/daemon.json<<E0F
{
exec-opts":["native.cgroupdriver=systemd"]"registry-mirrors":["https://docker.m.daocloud.io","https://docker.imgdb.de","https://docker-0.unsee.tech""https://docker.hlmirror.com"]
}
EOF開啟 Docker 服務
systemctl daemon-reload
systemctl restart docker
systemctl enable docker優化內核參數
cat>>/etc/sysctl.conf <<EOFnet.ipv4.ip forward=1
net.bridge.bridge-nf-call-ip6tables =1
net.bridge.bridge-nf-call-iptables =1
EOFsysctl -p備注:問題分析:
docker 的 cgroup 驅動程序默認設置為 Cgroupfs。默認情況下 Kubernetes cgroup 驅動為 systemd,
我們需要更改 Docker cgroup 驅動。
Kubernetes 的默認驅動和 docker 的驅動是一致的。
因為多數 linux 發行版的 cgroup 的驅動為systemd,所以當再選擇 cgroupfs 作為驅動時,會致使操作系統中存在兩個 cgroup 驅動,會帶來不穩定的影響。所以在系統已經使用 systemd 的基礎上,配置不推薦使用 cgroupfs,直接使用 systemd 即可。
修改方法:在 daemon.json 中添加"exec-opts":[native.cgroupdriver=systemd”]
cgroup 全稱是 control groups
control groups:控制組,被整合在了 1inux 內核當中,把進程(tasks)放到組里面,對組設置權限,對進程進行控制。可以理解為用戶和組的概念,用戶會繼承它所在組的權限。cgroups 是 linux 內核中的機制,這種機制可以根據特定的行為把一系列的任務,子任務整合或者分離,按照資源劃分的等級的不同,從而實現資源統一控制的框架,cgroup 可以控制、限制、隔離進程所需要
的物理資源,包括 cpu、內存、I0,為容器虛擬化提供了最基本的保證,是構建 docker 一系列虛擬化的管理工具
3. 部署 Kubernetes 集群(注意命令執行的節點)
(1) 配置三臺主機的主機名
節點一

節點二

節點三

(2) 綁定hosts

(3) 關閉交換分區

(4) 配置kubernetes的yum源
操作節點:k8s-master、k8s-node01、k8s-node02





(5) 安裝kubelet、kubeadm、和kubectl
操作節點:k8s-master、k8s-node01、k8s-node02

如果在命令執行過程中出現索引 gPg 檢查失敗的情況,請使用 yum instal1-y--nogpgcheckkubelet-1.23.0 kubeadm-1.23.0 kubect1-1.23.0 來安裝,或者將gpgcheck=1和repo_gpgcheck=1設置為 0
(6) kubelet設置開機啟動
操作節點:k8s-master、k8s-node01、k8s-node02

kubelet 剛安裝完成后,通過 systemctl start kubelet 方式是無法啟動的,需要加入節點或初始化為 master 后才可啟動成功。
(7) 生成初始化配置文件
操作節點:k8s-master

Kubeadm 提供了很多配置項,Kubeadm 配置在 Kubernetes 集群中是存儲在 configMap 中的,也可將這些配置寫入配置文件,方便管理復雜的配置項。Kubeadm 配置內容是通過 kubeadm config 命令寫入配置文件的。
其中,kubeadm config 除了用于輸出配置項到文件中,還提供了其他一些常用功能
- kubeadm config view:查看當前集群中的配置值。
- kubeadm config print join-defaults:輸出 kubeadm join 默認參數文件的內容。
- kubeadm config images list:列出所需的鏡像列表。
- kubeadm config images pull:拉取鏡像到本地。
- kubeadm config upload from-flags: 由配置參數生成 ConfigMap。
(8) 修改初始化配置文件
操作節點:k8s-master

分別是 12行,17行,30行,36行




注意:1.24.0 的版本中 apiVersion: kubeadm.k8s.io/v1beta2 被棄用
servicesubnet:指定使用 ipvs 網絡進行通信,ipvs 稱之為 IP 虛擬服務器(IP Virtual Server簡寫為 IPVS)。是運行在 LVS下的提供負載平衡功能的一種技術。含義 IPVS 基本上是一種高效的Layer-4交換機
podsubnet 10.244.0.0/16 參數需要和后文中 kube-flannel.yml 中的保持一致,否則,可能會使得 Node 間 Cluster Ip 不通。
默認情況下,每個節點會從 Podsubnet 中注冊一個掩碼長度為 24 的子網,然后該節點的所有 podip 地址都會從該子網中分配。
(9) 拉取所需鏡像
操作節點:k8s-master
如果地址無法解析,可以使用阿里的公共 DNS:223.5.5.5或223.6.6.6

kubeadm config images pull --config=init-config.yaml備注:
此步驟是拉取 k8s 所需的鏡像,如果已經有離線鏡像,可以直接導入,這一步就不需要了

(10) 初始化 k8s-master
操作節點:k8s-master
注意:master 節點最少需要2個CPU

執行完該命令后一定記下最后生成的 token:

Kubeadm 通過初始化安裝是不包括網絡插件的,也就是說初始化之后是不具備相關網絡功能的,比如k8s-master 節點上査看節點信息都是“Not Ready”狀態、Pod 的 CoreDNS 無法提供服務等。
備注:
如果要重復初始化,先重置 kubeadm
[root@k8s-master ~l# kubeadm reset(11) 復制文件到用戶的home目錄
操作節點:k8s-master



(12) node節點加入群集
操作節點:k8s-node01、k8s-node02
注意:master中生成的token,直接復制過來即可

(13) 在k8s-master節點設置環境變量
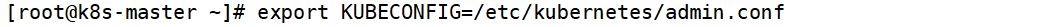

末尾添加?




因為此時還沒安裝網絡插件,coredns 無法獲得解析的 IP,就會使得 coredns 處于 pending 狀態各個節點的狀態也處于 NotReady 的狀態,這些異常情況待安裝過網絡插件后都會自行解決。
(14) 部署 Calico 網絡插件
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml備注:
也可以提前下載好 calica 的資源清單直接部署
[root@k8s-master ~l# kubectl create -f calico.yaml

四. Metrics-server部署
Metrics server 是一種可擴展、高效的容器資源指標來源,適用于 Kubernetes 內置的自動縮放管道。Metrics Server 從 Kubelets 收集資源指標,并通過 Metrics API 將它們暴露在 Kubernetesapiserver 中,供 Horizontal Pod Autoscaler 和 Vertical Pod Autoscaler 使用。指標 API 也可以通過 訪問 kubectl top,從而更容易調試自動縮放管道。
Metrics Server 對集群和網絡配置有特定的要求。這些要求并不是所有集群分布的默認要求。在使用 Metrics server 之前,請確保您的集群分布支持這些要求:
- kube-apiserver 必須啟用聚合層。
- 節點必須啟用 webhook 身份驗證和授權。
- Kubelet 證書需要由集群證書頒發機構簽名(或通過傳遞--kubelet-insecure-tls 給Metrics Server 來禁用證書驗證)注意這里是重點,如果本地沒有簽名需要傳遞 args"_-kubelet-insecure-tls"給Metrics Server
- 容器運行時必須實現容器指標 RPC(或具有cAdvisor 支持)
- 網絡應支持以下通信:
- (1)控制平面到指標服務器。控制平面節點需要到達 Metrics Server 的 pod IP 和端口10250(或節點 IP 和自定義端口,如果 hostNetwork 已啟用)
- (2)所有節點上的 Kubelet 的指標服務器。指標服務器需要到達節點地址和 Kubelet 端口。地址和端口在 Kubelet 中配置并作為 Node 對象的一部分發布。字段中的地址.status.addresses 和端口.status.daemonEndpoints.kubeletEndpoint.port(默認 10250)。Metrics Server 將根據 kubelet-preferred-address-types 命令行標志(InternalIP,ExternalIP.Hostname 清單中的默認值)提供的列表選擇第一個節點地址
源碼位置:
metrics-server的github 地址:https://github.com/kubernetes-sigs/metrics-server
1. 下載Metrics-server的yaml 文件
curl https://github.com/kubernetes-sigs/metricsserver/releases/download/v0.6.3/components.yaml2. 修改yaml文件并安裝
這里用的離線安裝的



3. 測試安裝結果


五. kuboard部署
Kuboard 是一款專為 Kubernetes 設計的開源可視化管理工具,它在 Kubernetes 環境中具有多種重要作用
1. 資源管理與可視化展示
(1)直觀呈現資源狀態
Kuboard 以圖形化界面的方式展示 Kubernetes 集群中的各類資源,如 Pod、Deployment、service、Node 等。用戶無需記憶復雜的命令,通過簡單直觀的界面就能快速了解資源的運行狀態、配置信息等。例如,在査看 Pod 時,可以直接看到 Pod 的啟動時間、運行狀態(如 Running、Pending 等)、所在節點等詳細信息。
(2)資源拓撲結構展示
能夠清晰地展示資源之間的拓撲關系。比如,展示 Deployment 與它所管理的 Replicaset 以及 Pod 之間的關聯,Service 與后端 Pod 的映射關系等。這有助于用戶更好地理解整個應用的架構和運行邏輯。
2. 集群監控與運維
(1) 實時監控指標
提供豐富的監控指標,實時展示集群和應用的性能數據。包括CPU 使用率、內存使用率、網絡帶寬、磁盤 I/0 等。通過這些指標,用戶可以及時發現性能瓶頸和異常情況,以便采取相應的措施進行優化和調整.
(2) 日志查看與分析
支持查看 Pod 的日志信息,方便用戶進行故障排査和問題診斷。用戶可以直接在界面上查看某個 Pod的標準輸出和錯誤輸出日志,無需通過命令行登錄到節點上進行査看,大大提高了排査問題的效率。
(3) 一鍵式運維操作
允許用戶在界面上直接進行各種運維操作,如創建、刪除、更新資源等。例如,用戶可以通過 Kuboard輕松創建一個新的 Deployment,配置其副本數量、鏡像版本等參數;也可以對現有的資源進行擴縮容操作,只需在界面上調整相應的參數即可,
3. 多集群管理
(1)集中管理多個集群
Kuboard 支持同時管理多個 Kubernetes 集群,用戶可以在一個界面上切換不同的集群進行操作和管理。這對于擁有多個 Kubernetes 集群的企業來說非常方便,無需在不同的命令行工具或管理界面之間頻繁切換。
(2) 統一的權限管理
可以對不同的用戶或用戶組設置不同的權限,控制他們對不同集群和資源的訪問和操作權限。例如,管理員可以為開發人員分配只讀權限,讓他們只能查看集群和應用的狀態,而不能進行修改操作。
4. 應用部署與管理
(1) 簡化應用部署流程
提供向導式的應用部署界面,用戶只需按照提示填寫必要的信息,如應用名稱、鏡像地址、端口映射即可快速完成應用的部署。同時,還支持使用 YAML 文件進行部署,滿足不同用戶的需求。
(2) 應用版本管理
方便用戶對應用的不同版本進行管理和切換。例如,在進行應用升級時,可以先在測試環境中部署新版本進行測試,測試通過后再一鍵切換到生產環境,確保應用的穩定性和可靠性。
5. 部署Kuboard
(1) 安裝kuboard 插件

(2)查看dashboard 的狀態
kubectl get pods -n kuboard(3) 查看dashboard前端的service
kubectl get svc -n kuboard
(4) 訪問測試
瀏覽器訪問http://<Kubernetes>集群任意節點的IP>:30080
用戶名:admin
密碼:Kuboard123


六. 安裝helm
(1)下載安裝包
wget https://get.helm.sh/helm-v3.9.4-linux-amd64.tar.gz這里使用壓縮包
(2) 解壓

(3) 安裝

(4) 查看版本

小技巧:
在使用 kubectl 命令的時候,如果覺得單詞不好打,可以設置一個別名:

?重啟后生效
關閉所有的節點,為實驗環境做快照,所有的節點都做快照
用bash也可以








》推薦)











