
🌈?個人主頁:十二月的貓-CSDN博客
🔥?系列專欄:🏀山東大學期末速通專用_十二月的貓的博客-CSDN博客💪🏻?十二月的寒冬阻擋不了春天的腳步,十二點的黑夜遮蔽不住黎明的曙光?
目錄
1. 第二章 網絡爬蟲
1.1 爬蟲基礎知識
1.2 爬蟲分類
1.3?開源工具 Nutch
2. 第三章 網頁分析
2.1 正則表達式
2.2 DOM模型
2.3 Beautiful Soup工具
2.4 Scrapy框架
2.5 不同爬蟲工具比較
2.6 元搜索引擎
3. 第四章 爬蟲與網站的博弈
3.1 Robot協議
3.2 User-agent
3.3 IP屏蔽
3.5 模擬瀏覽器
3.6 懶加載?
3.7 驗證碼
4. 第五章 數據抽取與包裝器
4.1 信息抽取
4.1 Web信息抽取
4.2 Web數據抽取
4.2.1 Web數據抽取定義
4.2.2?Web頁面定義
4.3?包裝器
4.3.1 基于分界符規則
4.3.2 基于樹路徑規則
4.3.3 包裝器分類
4.2 Web數據抽取方法
4.3 Web數據抽取評價標準
5. 第六章 包裝器頁面抽取方法
5.1 網頁分類
5.2 多記錄數據型頁面的抽取方法?
5.2.1 數據記錄抽取
5.2.2 數據項抽取
5.3 單記錄數據型頁抽取方法
5.4 單文檔型頁面抽取方法
6. 第七章 Web數據存儲
6.1 爬取數據存儲
7. 第八章 Web數據預處理
7.1 結構化數據處理
7.2 非結構化數據處理
8. 第九章 文本預處理
8.1 基于詞典的分詞(字符串匹配)
8.2 基于統計的分詞方法
8.2.1 基于HMM的分詞
9. 第十章 文本表示
9.1 文本向量化
9.2 隱語義分析LSA
9.3 主題模型
9.4 文檔哈希
10. 第十一章 語言模型(統計語言模型、神經網絡語言模型)
11. 第十二章 詞嵌入和文檔嵌入
12. 第十三章 文本分類
12.1 文本分類
12.2 fastText
12.3 TextCNN
12.4 大語言模型中的Token化
13. 第十四章 Web圖片數據
13.1 web圖像
13.2 圖像特征
13.3 顏色特征
13.4 紋理特征
13.5 形狀特征
14. 總結

1. 第二章 網絡爬蟲
爬蟲的三個任務:
- 輸入URL,爬取網頁內容(HTML)
- 網頁解析(從HTML中獲得想要的東西)
- 數據存儲
1.1 爬蟲基礎知識
- 爬蟲定義:一種自動獲取網頁內容的程序,通過解析HTML源碼獲得想要的內容。
- 爬蟲過程:1.選擇一個或多個URL作為seed url;2.獲取URL中的文檔內容;3.解析文檔內容,判重后選擇性保留;4.提取文檔中指向其他網頁的URL,在判重后選擇性放入隊列中;5.從隊列中持續選擇URL并重復2.3.4步驟。
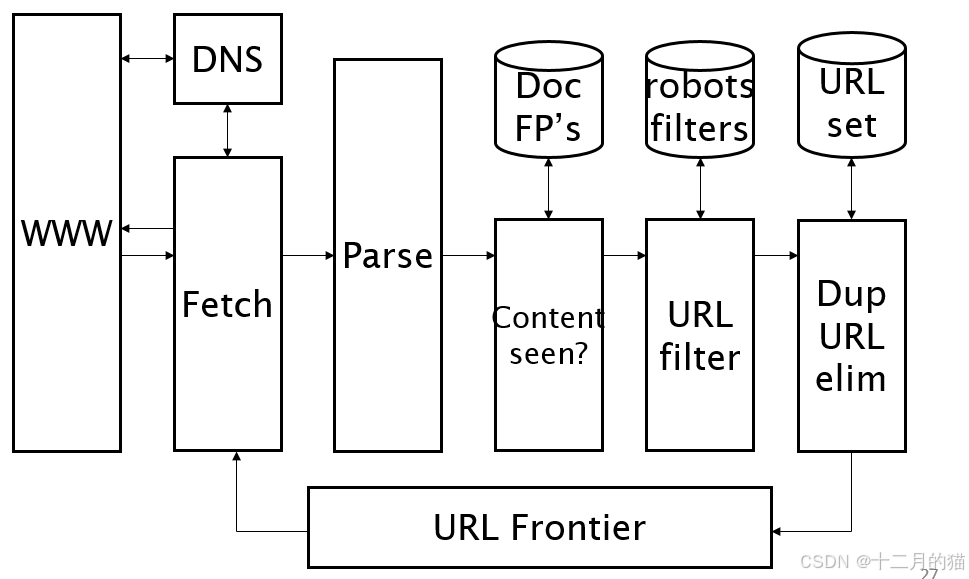
- 判重技術(URL判重、文檔判重):1.文檔指紋:每一個文檔生成一個指紋用來快速判重嗎,例如MinHash,SimHash算法;2. URL判重:建立散列存放訪問過的網址。例如MD5等散列函數。
- 爬蟲必須具有的功能:禮貌性(顯式和隱式禮貌、robots協議)、魯棒性、性能和效率、分布式、新鮮度、功能可拓展性

- 性能和效率:性能考慮充分利用系統資源的程度;效率考慮是否優先爬取“有用的網頁”。爬取網頁的方式分為BFS和DFS。
- BFS爬取網頁優于DFS:可以在有限時間內爬取更重要的網頁(我們認為一個網站的首頁最重要)。
- DFS爬取網頁優于BFS:避免握手次數太多,提升性能(一個網站一般只用一個服務器搭建,如果一直在該網站深度爬取,則只要握手一次)。
- 分布式(意味著多臺機器一起爬蟲,那他們的哈希表就要共享)帶來的問題:1、分布式后有很多機器,用于判重的哈希表太大一臺服務器放不下;2、每臺下載服務器都要維護一張哈希表,通信就成了分布式系統的瓶頸。
- 分布式問題解決:1、明確下載服務器的分工,看到某個URL就知道要交給哪臺服務器執行;2、批量處理,減少通信次數。
1.2 爬蟲分類
- 基于整個web的信息采集(門戶搜索引擎和大型web服務提供商才會去干)

- ?增量式web信息采集

- 用戶個性化Web信息采集

- 主題Web信息采集

1.3?開源工具 Nutch
Nutch是一個基于整合Web的信息采集工具:
- 多線程
- 寬度優先
- 遵循機器人協議
- 采用socket連接
- 邊爬取邊解析
- 頁面評分
2. 第三章 網頁分析
爬蟲包括:選擇URL、獲取網頁、網頁分析、數據存儲。
網頁分析:基于網頁HTML文檔格式,從每個HTML中抽取相關信息。角度有三個:1.將HTML看作字符流,使用正則表達式從字符中提取信息;2.將HTML看作樹結構,使用DOM樹來提取信息;3.使用外部工具來提取信息
2.1 正則表達式
定義:正則表達式是對字符串操作的一種邏輯公式。就是用實現定義好的一些特定字符進行組合,根據自己想要提取的字符串特點按照邏輯定義好一個“規則字符串”,用來表達對字符串的一種過濾邏輯。
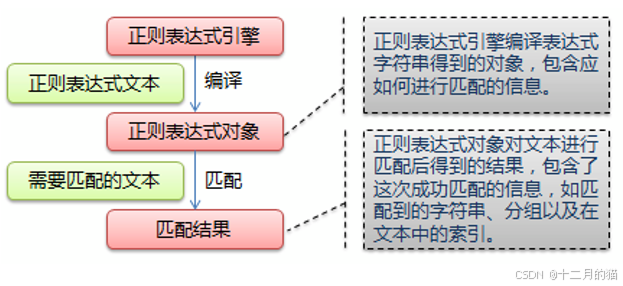
如何使用正則表達式:用多種元字符與運算符將小的表達式結合在一起來創建更大的表達式。
基于正則表達式的網頁分析:
- 獲取數據前(網頁分析)去除無用部分
- 提取網頁內的鏈接
- 提取網頁標題
- 提取網頁內的文本
正則表達式匹配的特點:
- 正則表達式匹配速度快。
- 表達能力弱,只有正規文法的表達能力。
- 在網頁內容信噪比要求不高的情況下可以使用基于正則表達式的網頁分析。網絡噪聲:導航元素、廣告、用戶交互模塊、無關文本塊。
2.2 DOM模型
DOM是什么:
- DOM(文檔對象模型)是處理結構化文檔的一個模型,其可以將文檔轉化為樹結構存儲,從而實現任意處理該對象,這稱為“隨機訪問”機制。
- DOM將HTML處理為樹狀結構,然后所有的元素以及他們的文字和屬性都可以通過DOM樹來操作和訪問。
DOM與正則表達式比較:
- 正則表達式匹配速度快,但表達能力弱,相當于正規文法。
- DOM在解析HTML時速度慢,但其表達能力相當于上下文無關文法。
- 正則表達式適用于信噪比要求不高時;網頁自動分類等需要進行網頁去噪處理時用DOM樹。

jsoup、HTMLParser等HTML解析器用于解析樹,是DOM模型的一部分。?
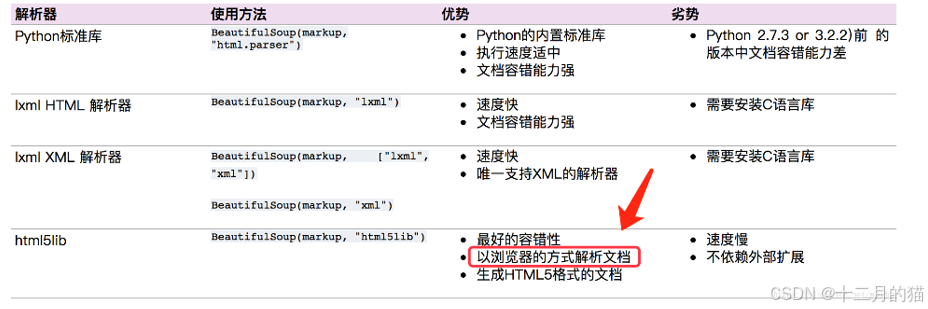
2.3 Beautiful Soup工具
定義:是一個工具箱,為用戶解析文檔得到想要抓取的數據提供工具。
主要工具如下:
- 從HTML文檔構造DOM樹
- 構造DOM樹可以選擇解析器:1.自帶的html.parser(速度慢但通用);2.HTML5Lib(不規范html文本不行);3.lxml(python解析庫;適用于html和xml解析;解析效率高;只會局部遍歷);
編碼方式:
- 中文操作系統默認:ANSI編碼
- Unicode:國際通用編碼
- utf8:是Unicode編碼在網絡傳輸的一個變體,節約數據量
Beautiful Soup工具優缺點:
- 操作簡單,使用方便。
- 在操作過程中,會將整個文檔樹都進行加載,然后再查詢匹配,因此消耗資源較多。
2.4 Scrapy框架
????????Scrapy是一個快速、高層次的屏幕抓取和Web抓取框架;框架意味著整個或部分系統以及思想都是可以復用的,僅僅需要修改/編寫部分代碼即可實現爬蟲。
- 引擎:負責數據和信號在不同模塊間傳遞(總指揮)。
- 調度器:一個隊列,存放引擎發過來的request請求。
- 下載器:處理引擎發送過來的request請求(其實是調度器發來的),并將結果返回給引擎。
- 爬蟲:處理引擎發送過來的respond(其實是下載器發來的),并將結果返回給引擎。
- 管道:接受引擎傳過來的數據(其實是爬蟲處理的結果)。
- 下載中間件:自定義下載拓展。
- 爬蟲中間件:自定義respond和request請求的過濾。
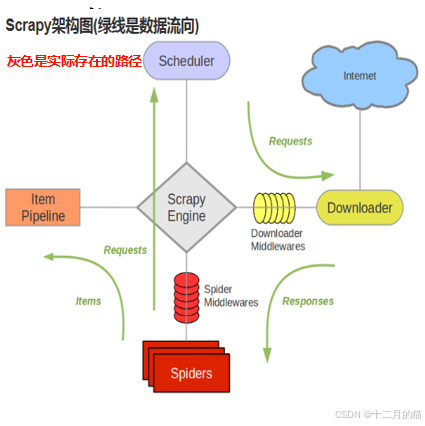
Scrapy實現了底層多線程請求,異步網絡框架處理網絡通訊。
?制作Scrapy爬蟲需要四步:
- 新建項目:新建爬蟲項目(scrapy genspider 爬蟲名 域名)
- 明確目標:編寫items.py,明確要抓取的目標
- 制作爬蟲:制作爬蟲開始爬取網頁
- 存儲內容:創建管道存儲爬取的內容
?我們需要手動寫的只有Item和spider:
用戶關心的只有自己想要爬什么東西,這些東西怎么存下來,其他的部分都不關心。

一、CSV文件
????????特別的,CSV文件是目前比較流行的一種文件存儲格式(以逗號為間隔)

二、yield返回
????????yield是一種特殊的return方法。兩者都會返回后面的值但是存在下面不同:
- return一次性返回所有的值,并銷毀局部變量;yield返回的是一個迭代器,里面包括所有yield的值。
- return后程序停止運行;yield后程序繼續運行。
三、meta字典使用
????????若解析的數據不在同一張頁面中,可以通過meta參數來傳遞數據。在向下一頁發起請求的時候,將本層數據以meta形式傳入,那么下一頁的返回response中就會有meta字典的數據。

2.5 不同爬蟲工具比較
爬蟲包括以下幾個方面:
- 頁面信息獲取
- 頁面信息解析
- 數據存儲
前面介紹了幾個不同的爬蟲工具,不同工具在上面三個方面存在不同。包括:?
- 利用request直接獲取頁面,然后使用正則表達式解析html獲取想要的東西,存儲數據。
- 利用request獲取頁面,使用bs4來解析html建立DOM樹,直接獲得想要的東西。
- 利用scrapy框架獲取信息,解析信息,存儲信息。
request和bs4:
- 頁面級爬蟲,功能庫
- 并行性考慮不足,性能較差
- 初學容易上手
- 大型開發比較麻煩,需要自己造輪子
- 重點在于頁面下載
scrapy:
- 網站級爬蟲,框架
- 并行性考慮好,性能高
- 初學比較麻煩
- 大型開發比較容易,很多輪子和功能都是已經封裝好的
- 重點在于爬蟲結構
2.6 元搜索引擎
????????通過一個統一的用戶界面幫助用戶在多個搜索引擎中選擇和利用合適的搜索引擎來實現檢索,是對分布于網絡的多種檢索工具的全局控制機制。
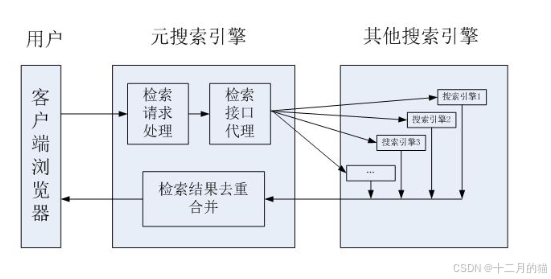
- 元搜索引擎 == 一個搜索引擎包含多個搜索引擎
- 結果合并 和 結果篩選/處理
3. 第四章 爬蟲與網站的博弈
反爬蟲策略:希望能夠在用戶面前正常顯示,同時不給爬蟲顯示。
后端策略:
- user-agent檢測
- referer檢測
- cookie檢測和賬號密碼檢測
- IP限制批次
前端策略:
- 懶加載
- FONT-FACE拼湊式:對于數字不直接展示,而是需要查詢字符集才能識別數據
3.1 Robot協議
- 也稱為爬蟲協議、機器人協議等
- 網站通過Robots協議告訴搜索引擎哪些頁面可以抓取,哪些頁面不可以抓取

3.2 User-agent
????????簡稱UA,是HTTP請求頭的一部分,向網站提供訪問者的信息,包括:瀏覽器類型、語言、操作系統、CPU類型等等。每次請求都會發送給服務器,通過這個標識,服務器能夠提供不同排版適應不同的瀏覽器給用戶更好的體驗。

3.3 IP屏蔽
網站策略:
- 同一個IP頻繁訪問,封IP
- 限制某些IP訪問
爬蟲策略:
- 多IP并行
- 使用IP代理池
- 增大爬取時間間隔
- 代理池:從各大網站上爬取可用IP,定期檢查是否可用。
3.4 用戶賬號密碼登錄與cookie驗證?
流程:
- 通過第一個網頁提交用戶名和口令。
- 后端接受請求后生成cookie,和其他信息一起發給用戶。
- 用戶保存cookie,從文件中讀取,在訪問其他頁面時攜帶cookie信息。
工具:
- cookiejar?
Cookie:
- 記錄了用戶ID、密碼、瀏覽過的網頁、停留的時間等信息
- 小文本文件,服務器在HTTP響應頭中發送給用戶瀏覽器,瀏覽器保存在本地,用于維護客戶端與服務端的狀態。
3.5 模擬瀏覽器
- selenium:模擬用戶進行交互,登錄輸入,鍵盤動作,鼠標動作,ajax響應等等。
- ajax:傳統網頁如果需要更新就要加載整個頁面,使用AJAX可以異步加載頁面。
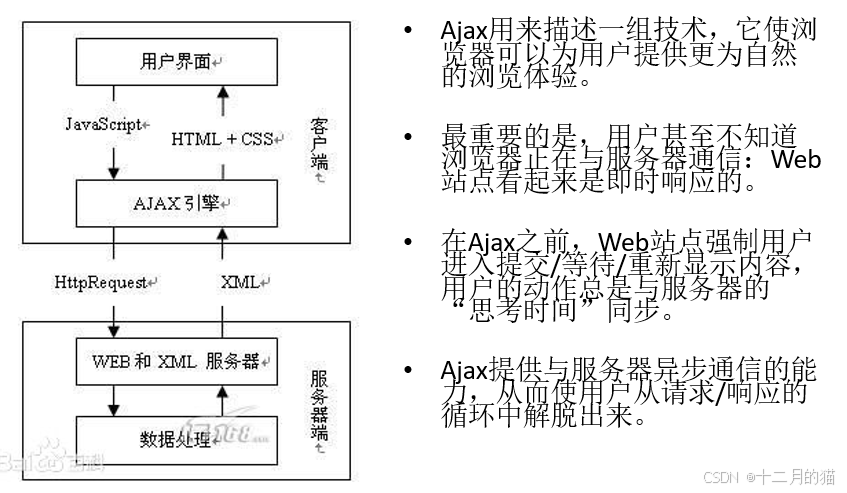
這就導致了爬蟲程序并不知道元素何時加載。因此如果還未加載就去定位爬取則會出現問題,selenium提供了三種等待方式:強制、顯式、隱式等待:


3.6 懶加載?
定義:為了避免頁面一次性向服務器發送大量請求導致問題,可以采用預加載和懶加載。懶加載是指在對象需要時再加載,可以提升前端性能也可以反爬蟲
實現原理:

爬蟲策略:
- 簡單方法:尋找data、src2等暫存器屬性。
- 模擬瀏覽器方法:通過selenium去模擬瀏覽器頁面上下滑動,然后獲取src。
Selenium優點:
- 模擬瀏覽器操作,可以直接獲得渲染后真正的網頁代碼。
- 繞過Ajax和一些JavaScript邏輯。
Selenium缺點:
- 速度太慢。
- 經常會更新。
- 太老的東西了,很多網站有針對Selenium的反爬。
3.7 驗證碼
圖片識別驗證碼:
- 獲取圖片:Selenium可以通過尺寸坐標定位到圖片。然后截圖獲取。
- 圖片處理:Pillow和PIL模塊可以對圖片做很多處理,方便下面的OCR。
- OCR:光學字符識別,將圖像中的文字轉化為文本。
滑動驗證碼:
- 判斷驗證碼什么時候出現。
- 驗證碼出現時,判斷何時加載完成。
- 自動識別出鼠標拖拽的初始位置和終止位置。
- 模擬鼠標拖動。
- 檢驗是否成功。
Selenium獲取初始位置和終止位置的方法:
- 獲取不帶缺口的圖片,再獲取帶缺口的圖片。比較兩種圖片各個坐標的灰度值,找到初始位置和終止位置,進行滑動。
- 滑動不能過于勻速,同時要伴隨y軸上下抖動。? 由于selenium是在后臺完成的滑動,而有些平臺會檢測鼠標光標未移動,可以使用PyAutoGUI。
- 假如不能獲得不帶缺口的圖片,則可以將缺口圖片和滑塊進行圖像匹配。
4. 第五章 數據抽取與包裝器
信息抽取:把文本里包含的信息進行結構化處理,變成表格一樣的組織形式。輸入是原始文本;輸出是固定格式的信息。
信息抽取包括:實體抽取、關系抽取、事件抽取(多元關系)。
4.1 信息抽取
實體抽取NER:
- NER是NLP中一項非常基礎的任務。NER是信息抽取、問答系統、句法分析等眾多NLP任務的重要基礎工具。
- 從狹義來說實體是指現實世界中的具體或抽象實體;廣義來說包含時間、數量表達式。
- NER是一種序列標注問題。
關系抽取:
- 句法分析
事件抽取:
- 知識獲取?
4.1 Web信息抽取
????????Web信息抽取是將Web作為信息源的一類信息抽取,就是從半結構化的Web文檔中抽取信息。其核心:
- 將分散Internet上的半結構化的HTML頁面中隱含的的信息點抽取出來。
- 并將其轉化為更加結構化語義更清晰的形式表示。
- 為用戶在Web中查詢數據,應用程序直接利用Web中的數據提供便利。
通常包括一下幾個步驟:
- 將Web網頁進行預處理
- 用一組信息模式描述所要抽取的信息

- 使用模式匹配方法識別指定的信息模式的各個部分?
- 對文本進行合理的詞法、句法及語義分析
- 進行上下文分析和推理,確定信息的最終形式
- 將結果輸出成結構化的描述形式以便于查詢分析
4.2 Web數據抽取
? ? ? ? 基本前提:包含數據的頁面是通過頁面模板生成的。
4.2.1 Web數據抽取定義
? ? ? ? Web數據抽取是指從頁面中將用戶感興趣的數據利用程序自動抽取到本地的過程。為了能夠保證抽取的準確性,必須能夠識別頁面模板:

- T是頁面模板。W=T(d),W為頁面,d為數據。
- C是相似頁面之間不變的部分,包括導航、版權聲明等。
- L是頁面的格式規范(數據的格式規范)。
- S是從頁面數據中觀察到的數據模式。
4.2.2?Web頁面定義

- Web數據抽取問題可以轉化為從已知的W中逆向推導出T,然后還原出D的部分。
4.3?包裝器
包裝器是一個軟件過程。過程:工程開發中的最佳實踐稱為過程。
- 這個過程使用已經定義好的信息抽取規則,將Web頁面中的信息數據抽取出來,轉化為結構化的格式去描述。
- 因為是最佳實踐,因此一個包裝器一般僅僅針對某一種數據源中的一類頁面。
- 包裝器運用規則執行程序對實際要抽取的數據源進行抽取。
- 包裝器的核心是抽取規則。抽取規則的定義取決于你怎么看待HTML文檔。
4.3.1 基于分界符規則
角度:將HTML文檔看作字符流
方法:給出數據項的起始和結束分界符,將其中的數據抽取出來
例如:某一個數據項的起始規則是"SkipTo<i>“,結束規則是"SkipTo</i>”。意味著從文檔的起始忽略所有的字符直至找到HTML標簽 <i>,接著,忽略所有字符直至 </i>,中間部分即所需的字符串。
另外:基于正則表達式的網頁分析。
4.3.2 基于樹路徑規則
角度:將HTML文檔看作樹結構
方法:將文檔看作樹結構,將所抽取的數據存儲在樹節點中
- 首先根據HTML標簽將文檔分析成樹結構,如DOM樹
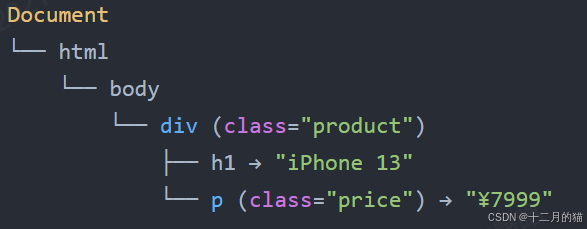
- 然后通過規則中的路徑在樹中搜索相應的節點
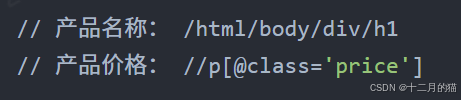
- 最終找得到所需數據
4.3.3 包裝器分類
爬蟲分為三步驟:
- 下載頁面
- 頁面數據提取
- 數據存儲
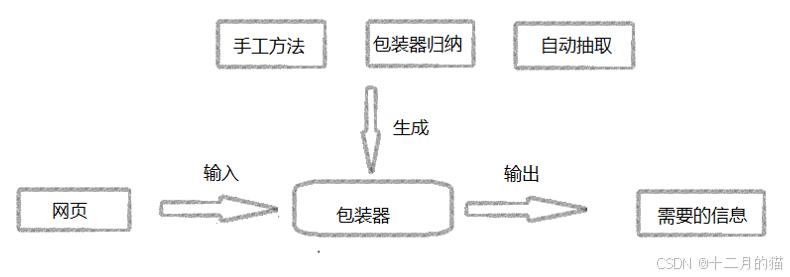
手工方法:爬蟲
包裝器歸納:使用機器學習的方法產生抽取規則,屬于有監督學習:
- 網頁清洗:有些頁面結構不規范,例如前后標簽不對稱,沒有結束標簽等。
- 網頁標注:給網頁中的某個位置打上特殊標簽表明這是要抽取的數據。
- 包裝器空間生成:對標注數據生成XPath集成空間(候選規則);對生成的規則進行歸納,形成若干個子集;歸納的規則是在子集中XPath能夠覆蓋多個標注的數據項。

自動抽取:通過挖掘多個數據記錄中的重復模式來尋找這些模板,是無監督模型,步驟:
- 包裝器訓練:將一組網頁通過聚類將相似的網頁分成若干組;每組的頁面獲得不同的包裝器。
- 包裝器應用:將需要抽取的網頁和之前聚類后的網頁進行比較;在某個分類組下則使用該分類下的包裝器來獲取網頁中的信息。
4.2 Web數據抽取方法
Web數據抽取目的是獲得頁面數據,需要借助一個或多個頁面的逆向推導得到頁面模板T。
按照自動化程度來區分可以分為:
1. 人工抽取:
- 人工分析出頁面模板(XPATH、正則表達式)(頁面模板+抽取規則=包裝器)。
- 針對具體問題生成具體的包裝器(人工包裝途徑容易采納,在具體問題上可以得到滿意的結果)。
- 只適合小規模的即時的數據抽取,不適合大規模的數據抽取。
2. 半自動抽取:
- 由計算機頁面模板抽取數據生成具體的包裝器,但頁面模板分析還需要人工參與。
- 設計一個描述頁面模板的概念模型和一套用來描述抽取意圖的規則語言,用戶通過一定的輔助工具利用概念模型分析出頁面模板,使用規則語言表面抽取意圖。
- 計算機根據分析出的頁面模板和抽取意圖,生成包裝器,完成抽取。
- 這種途徑比手工包裝更加系統化,能大大減少工作量。
3. 自動抽取:
- 僅僅需要很少的人工參與或者完全不需要人工參與。
- 更加適合大規模、系統化、持續性的Web數據抽取。
- 自動抽取工作中,頁面模板的分析通過序列匹配、樹匹配或利用可視化信息完成,并且直接給出抽取結果。
4.3 Web數據抽取評價標準
- 召回率:抽取到的正確結果和要抽取頁面的全部結果的比,即 R=|Ra| / |R|。
- 準確率:指抽取到的正確結果和抽取到的全部結果的比,即?P=|Ra| / |A|。
- F 值:召回率R和查準率P的加權調和平均值,綜合考慮了二者
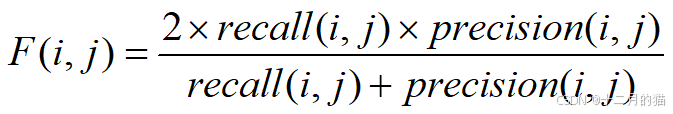
- 抽取的自動化程度:這項標準用來衡量用戶在抽取過程中的參與程度,分為手工、半自動和全自動三類。
- 適應性:指在該頁面的內容和結構有較小變化的情況下,該抽取方法或工具有自適應能力,仍然能夠正常工作。
- 修正率:其含義是需要手工調整使得準確率和召回率達到100%的Web數據庫數量。
5. 第六章 包裝器頁面抽取方法
????????第五章本質上是在帶大家入門一下數據抽取的概念,以及包裝器的概念。然后簡單說了包裝器按自動化程度分為人工編寫、半自動化編寫、全自動化編寫;按實現方法分為人工編寫、包裝器歸納、自動生成。本章我們會真正來帶大家看看如何用包裝器來實現頁面抽取。首先從人工編寫(爬蟲)方法生成包裝器完成數據抽取和信息抽取開始!!!
5.1 網頁分類
????????想要實現手工編寫,我們首先要對網頁進行一個分類,不同類型的網頁使用不同的包裝器方法去提取信息和數據。
按照頁面內數據組織形式的不同分為:
1.單記錄頁面(頁面中僅僅嵌入一個記錄):
- 詳情頁 A Authority
- 每一頁只關注一個特定對象,也有其他相關和無關信息
2.多記錄頁面(頁面嵌入多個記錄):
- 同結構的記錄在頁面內重復排列出現。
- 列表頁 H。列表在頁內的特定位置。每一頁有多個數據記錄。
按照頁面內容的不同分為:
1.數據型頁面(頁面內容是數據):
- 頁面中嵌入了一個或多個結構化的數據記錄。
- 頁面展示的是帶有屬性標簽和數據值的信息。
- 數據記錄按照一定的格式規范和屬性次序被載入在頁面中。

2.文檔型頁面(頁面內容是文檔):
- 頁面嵌入的是半結構化文檔內容或文檔標題。
- 頁面展示的是文本型信息。

兩個不同角度的分類合起來總共有四種頁面類型:
- 單記錄數據型頁面
- 多記錄數據型頁面

- 單記錄文檔型頁面

- 多記錄文檔型頁面

5.2 多記錄數據型頁面的抽取方法?
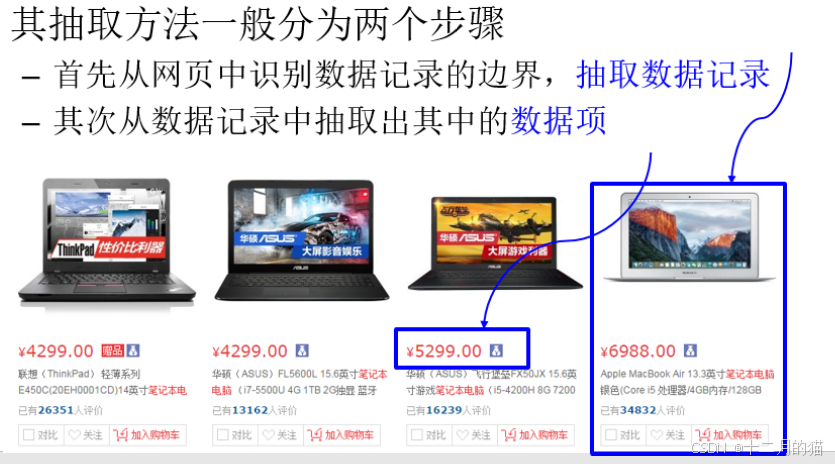
多記錄數據型頁面是指頁面由多條結構相同的數據記錄組成,抽取方法:
- 首先從網頁中識別數據記錄邊界,抽取數據記錄
- 從數據記錄中抽取數據項
1. 數據記錄抽取 == 抽取數據 == 獲得頁面模板? == 逆推導
2. 數據記錄抽取 == 抽取數據 == 直接抽取數據
?章節邏輯:?

5.2.1 數據記錄抽取
? ? ? ? 人工處理包裝器也就是爬蟲。主要有兩個角度的思路:1.看成字符流用正則表達式;2.看成樹結構用DOM樹完成。這里我們想要從樹結構角度去看看怎么抽取數據記錄。抽取數據記錄步驟如下:
- 確定數據區域:比較DOM樹算法、語義塊算法
- 計算數據記錄的邊界:利用規則得到數據記錄?
確定數據區域:
? ? ? ? 方法1·比較DOM樹算法:從兩顆DOM樹根節點開始遞歸深度遍歷,如果兩個節點相同則遞歸下一層,否則標記為不同子樹返回上一層。
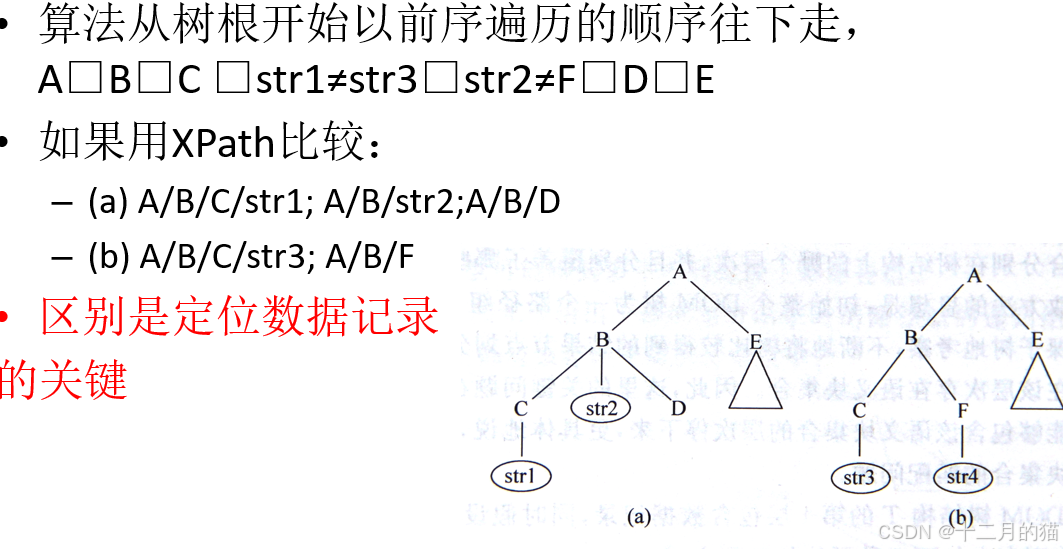
????????方法2·語義塊算法:
? ? ? ? 語義塊:HTML文檔的片段,是邏輯上滿足模式定義的一個HTML文檔子集。一個語義塊可以進一步劃分為最小語義塊。最小語義塊是包裝器在生成和維護中的最基本抽取單位。
? ? ? ? 方法:計算數據記錄邊界本質上就是確定語義塊所在的層次。首先初始化DOM樹的路徑組;從DOM樹根開始逐棵子樹去考察,不斷將樹比較結果劃分到各個路組;直到發現某一層次存在語義塊集合(需要設定好閾值M)
? ? ? ? 規則1、2:關鍵字頻率+共同路徑【關鍵字頻率多那就是數據記錄的共同路徑,可以下一層去找;如果少了很多那就說明進入數據項內部了;回溯確定語義塊層次】
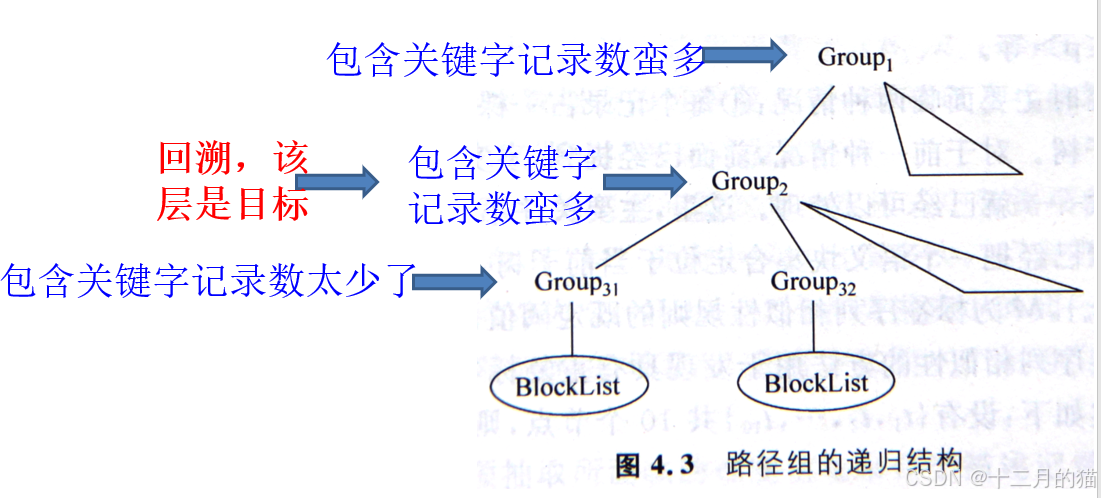
計算數據記錄邊界:
? ? ? ? ?方法:利用規則3、4、5來劃分數據記錄邊界


5.2.2 數據項抽取
數據項邊界–指的就是判斷一個數據項應該覆蓋HTML樹結構上的多少個節點。

數據項識別:
? ? ? ? 規則6:位置相同,標簽序列相同就是不同數據記錄的同一個字段。
數據項匹配:
? ? ? ? 除了直接使用規則6來判斷數據項是否是同一個字段。還可以使用兩個數據項之間的相似性來判斷是否是同一個字段:
- 出現路徑規則:來自不同語義塊的兩個數據項如果具有相同的角色,則它們具有相同的出現路徑。
- 視覺規則:來自不同數據記錄的兩個數據項如果是相同角色(是相同字段),則它們有相同的視覺信息。
- 上下文規則:來自不同數據記錄的兩個數據項如果是相同角色,則它們具有相同的上下文信息。
- 文本特征規則:來自不同數據記錄的兩個數據項如果是相同角色,則它們具有相似的文本特征。

5.3 單記錄數據型頁抽取方法
增量式抽取:以增量方式推導網頁模板。

連續性數據抽取最好的辦法就是確定頁面模板,然后根據頁面模板+頁面來逆推導頁面數據。
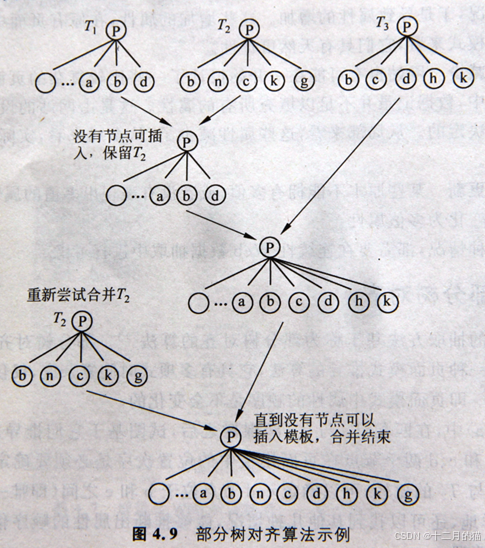
頁面模板存在變化的可能性。雖然單記錄數據型頁面僅僅有一個記錄,頁面模板相對固定,但是也有變化的可能性,因此引入部分樹對齊算法(增量推導網頁模板):
- 首先選擇一棵樹作為對齊開始的種子
- 接下來,將剩下的樹逐個和種子進行對齊
- 首先處理其中一棵樹T2。T2無法和種子T1對齊,屬于歧義情況。于是跳過T2.
- 接下來T1和T3對齊,也就是通過T1和T3的網頁模板,我們推導出了一個新的網頁模板。
- 用新生成的網頁模板和T2繼續對齊
- 如果還剩下跳過的頁面,就繼續對齊,直到不能生成新的頁面模式為止。
- 部分樹對齊后,會產生唯一頁面模式,用來抽取數據
5.4 單文檔型頁面抽取方法
抽取頁面中的文本信息(只有一個記錄的文本信息)
結合視覺信息的抽取方法:
- 基于一個觀察結果:網站中正文普遍占據絕大部分位置,文本塊長度最長

存在問題:
- 短正文沒法很好的提取到
- 包含大量評論的頁面沒法很好提取到
抽取路徑學習:
? ? ? ? 1. 抽取路徑學習:除了使用種子點seedElement找出正文內容外,在內容返回前,還將正文的抽取路徑保存到數據庫中。
? ? ? ? 2.?按照基于視覺信息的抽取抽取出的路徑與數據庫比對,一致時就沒問題,不一致就需要進行選擇(如果頁面發生變化則選擇基于視覺信息;如果是短正文/評論頁則選擇基于數據庫信息)
改進的自適應數據抽取方法:
- 本質是抽取路徑法中的數據庫信息和視覺信息的自動選擇,基于貝葉斯最優決策的方法
- 所用的特征包括:

- 最終決策公式為:
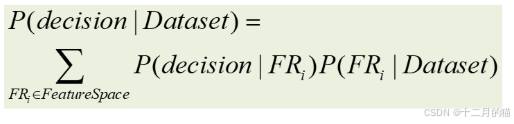
6. 第七章 Web數據存儲
6.1 爬取數據存儲
結構化文件存儲:
- 結構化文件:Excel、CSV、JSON、XML、PICKLE
- CSV:以逗號相隔、存儲容量少
- JSON:是存儲和交換文本信息的語法,比XML小在數據交換中起到載體的作用
- XML:用來交換數據而不是展示數據
- PICKLE:用于序列化和反序列化python對象。pickle是二進制序列化格式,json是文本序列化。JSON可讀,pickle不可讀。JSON可互操作,PICKLE僅僅在python中使用。
結構化數據庫:
- Sqlite:python內置的一個輕量型關系數據庫。
- MySQL
- MongoDB
非結構化文件存儲:
- txt文件
- JPG文件
- Hbase等非結構化數據庫
7. 第八章 Web數據預處理
7.1 結構化數據處理
數據清洗
- 缺失值處理:直接刪除/填充新值
- 噪聲處理:識別、直接刪除、極值處理到一個正常區間
- 不一致處理:刪除再填充新值
結構化數據應用
- 數據集成,展示
- 用機器學習處理數據,展示結果
特征工程
- 特征:在觀測現象中一種獨立、可測量屬性
- 特征工程:把原始數據變成特征的過程,目的是為了更好的訓練數據
方法包括:特征選擇、特征提取、特征組合、特征構造

- 主成分分析法(PCA):無監督學習,將互相相關的特征,通過線性組合,使得數據變換到新的空間,可能最大程度保持原來的信息,并且特征之間互相不相關。
機器學習的數據預處理
- 歸一化:把數據特征轉化為相同尺度的方法。最近鄰分類器就是尺度敏感的,尺度大的特征起主導作用,也有尺度不變性算法。線性分類器尺度不變。【加速收斂、統一尺度、減少冗余信息、提高泛化能力、不能直接解決過擬合問題】
- 標準化:Z-score,讓每一個特征均值為0,方差為1
- 白化:消除不同特征之間的相關性;降低輸入數據特征之間的冗余性;輸入數據經過白化處理后,特征之間的相關性較低,并且特征具有相同的方差;白化的一個主要方法就是PCA。【特征去相關+方差歸一化】
連續值和離散值?
- 離散值:類別特征編碼(標簽編碼、獨熱編碼)

- 連續值:二值化、分箱、聚類、熵、決策樹

7.2 非結構化數據處理
文本數據
- SQL查詢
- NLP文本特征:分詞、預處理、向量描述
文本特征:
- IR:IR模型、倒排表、搜索引擎
- 文本處理:文本分類、文本聚類、情感分析
非結構化數據特征描述:
- 圖像數據——圖像特征——圖像識別、檢索
- 文本+圖片特征——跨模態檢索、文本生成圖片
8. 第九章 文本預處理
- 語言是具有組合性的,只有組合在一起語言才有意義。
- 預處理:將文檔拆解成單詞以便計算機程序能夠解釋。
步驟:
- 文檔解析:移除文檔中不必要的格式,比如HTML標簽。
- 句子分割:從文檔拆成句子。
- 分詞(詞條化):句子變為單詞【基于詞典的分詞、基于統計的分詞、基于理解的分詞】。
- 詞規范化:歸一化(不同表達方式歸一化)、詞干還原(去除單詞兩端詞綴的過程)。
- 去停用詞:刪除不需要的詞(冠詞、介詞、代詞等)。
8.1 基于詞典的分詞(字符串匹配)
步驟:
- 按照一定策略拿出漢字串,然后與“詞典”中的詞條進行匹配
- 如果匹配成功,那么這個漢字串就是一個詞
- 遇到不認識的字串就分割
策略:
- 正向匹配和逆向匹配
- 最大匹配和最小匹配


8.2 基于統計的分詞方法
思想:如果相連的字在不同的文本中出現的次數越多,就證明這相連的字很可能就是一個詞。因此,我們只要判斷各個字組合出現的頻度就可以判定是否為一個詞。

主要統計模型有:
- N元文法模型
- 隱馬爾可夫模型
- 條件隨機場模型
- 深度學習模型
實現上,會將字符串匹配和統計模型結合起來使用:
8.2.1 基于HMM的分詞
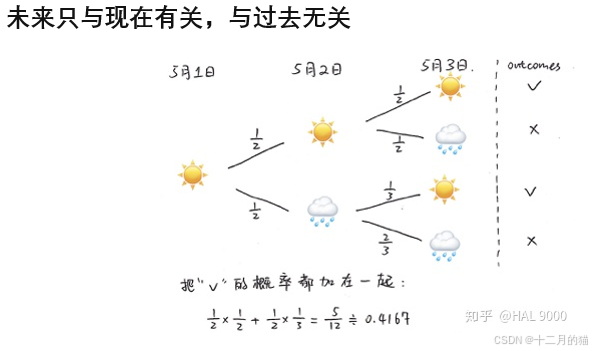
馬爾可夫過程:未來只與現在有關與過去無關;具有無后效性特點的過程稱為馬爾可夫過程。
舉一個例子:天氣預測可以認為就是一個馬爾可夫過程(今天的天氣不會影響后天,只會影響明天)
HMM:Hidden Markov Model 隱馬爾可夫過程(狀態隱藏馬爾可夫過程)
舉個例子:

模型:
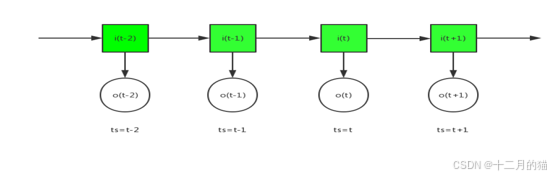

模型涉及的兩個問題:
- 概率計算問題:模型AB矩陣 + 觀察值(輸入) + 狀態值(輸入) ——》 觀察值概率。
- 模型訓練:梯度下降最大化觀察值概率
- 模型使用:觀察值+模型AB矩陣 ——》 狀態值
本質上:模型在通過學習明白觀察值和狀態值之間的聯系,然后我們給出觀測值模型就能夠預測出狀態值。
概率計算問題:
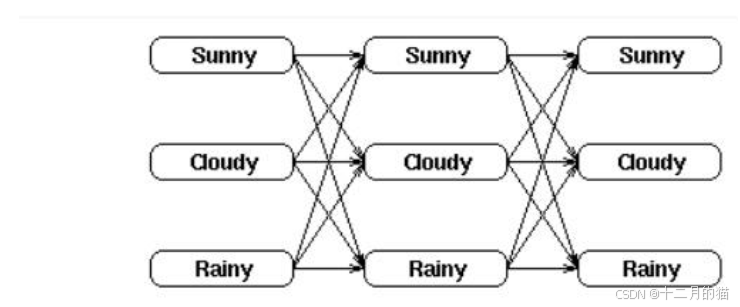
給定 HMM,即,求某個觀察序列的概率。
例如:給定一個天氣的隱馬爾可夫模型,包括第一天的天氣概率分布,天氣轉移概率矩陣,特定天氣下樹葉的濕度概率分布。求第一天濕度為 1,第二天濕度為 2,第三天濕度為 3 的概率。
找到所有狀態序列,得到各狀態概率,得到每種狀態概率對應的觀察概率,求和。
模型訓練:
給定一個觀察序列,得到一個隱馬爾可夫模型。
已知第一天濕度為 1,第二天濕度為 2,第三天濕度為 3。求得一個天氣的隱馬爾可夫模型,包括第一天的天氣,天氣轉移概率矩陣,特定天氣下樹葉的濕度概率分布。
如果產生觀察序列 O 的狀態已知(即存在大量標注的樣本), 可以用最大似然估計來計算?的參數:Baum-Welch 算法(前向后向算法)描述
如果不存在大量標注的樣本:期望值最大化算法(Expectation-Maximization, EM)

模型使用:
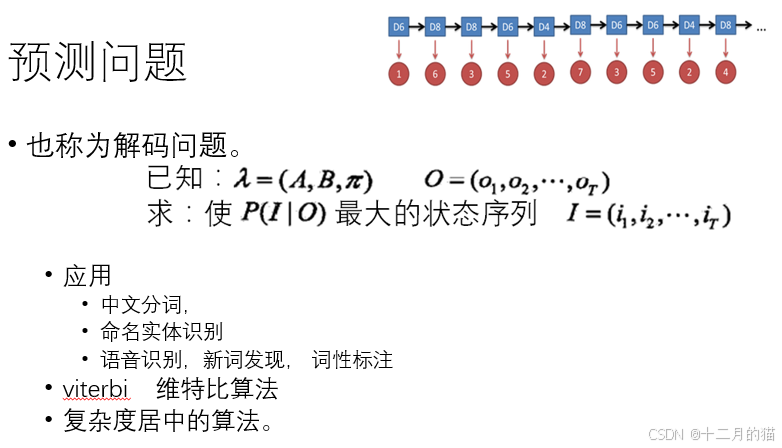
- 在模型已經訓練好的前提下,觀測值和狀態值已經得到綁定。
- 通過AB矩陣將狀態值和觀測值在向量空間中相當靠近
- 對于分詞任務:觀察值為所有的漢字;狀態值為BMES(begin\middle\end\single)。
HMM分詞:
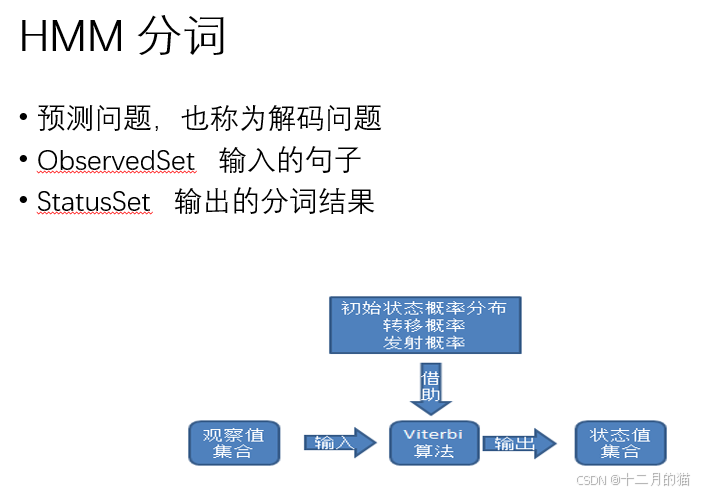
Viterbi算法如下:
本質就是動態規劃算法,計算得到最優的路徑,也就是狀態值集合。具體可以看博客:
(11 封私信) 隱馬爾科夫模型(HMM) — 維特比算法(Viterbi ) - 知乎
動態規劃算法:帶有記憶功能不會重復計算子問題的窮舉法

9. 第十章 文本表示
前一章,我們學習了文本預處理。文本預處理包括:
- 文檔解析
- 句子分割
- 分詞
- 詞規范化
- 去停用詞
在預處理后,我們得到這個文檔處理后非常干凈的一堆詞語。但是這些詞語仍然不能被模型直接使用,因此本章來學習文本表示,把詞語轉化為可以被模型使用的表示形式。?
9.1 文本向量化
- 把字詞處理成向量或矩陣,以便計算機能進行處理。
- 上一章預處理的結果:詞條集合、詞條序列。
- 文本向量化:文檔——詞條集合——無語序信息;文檔——詞條序列——有語序信息
離散表示文本(詞袋模型、TF-IDF):
- 對于給定文本。
- 忽略單詞出現的順序和語法等因素。
- 將其視為詞匯的簡單集合。
- 文檔中每個單詞的出現屬于獨立關系。

分布式表示文本:
- 使用低維向量來表示文本。
- 每一維表示一個詞的語義或主題信息
9.2 隱語義分析LSA
離散文本表示有:詞袋模型和TF-IDF模型
分布式文本表示有:LSA、主題模型、文檔哈希
LSA:對文本進行降維,僅僅考慮其中主要的語義,因此稱為隱語義分析。
步驟:
- 建立詞頻矩陣(為每一個文檔,建立一個初始向量)。
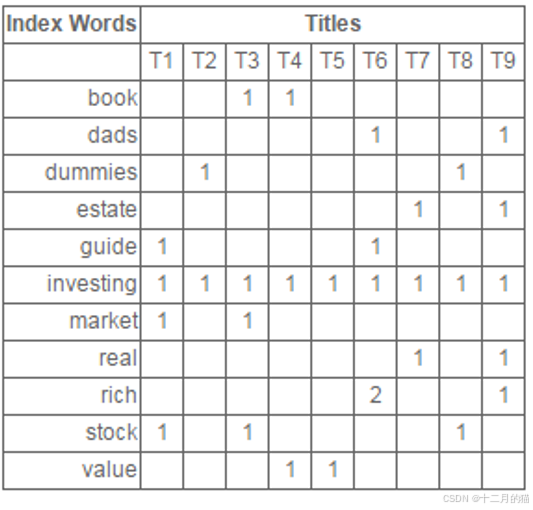
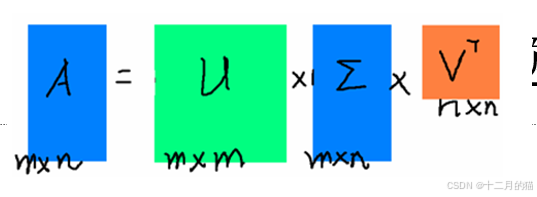
- 計算詞頻矩陣的奇異值分解。
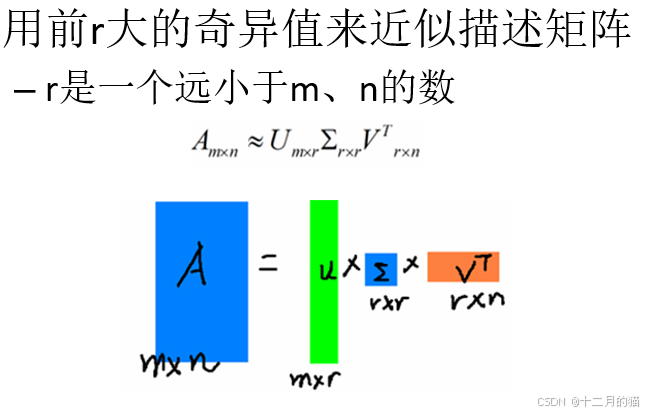
- 對于每一個文檔,進行提取部分特征值后形成的新向量代替原有向量。
- 使用轉化后的新向量表示文檔進行后續計算
使用新的A來表示各個文檔的向量
優點:
- 文章和單詞都能映射到一個語義空間
- 語義空間的維度能夠明顯少于原向量空間,緩解了詞袋法造成稀疏矩陣的問題?
缺點:
- 無法解決多義詞問題。
- 特征向量語義空間等沒有對應的物理解釋。
- LSA和詞袋模型一樣沒有考慮詞語的先后順序,也沒有考慮句子/詞語的相似關系。
- SVD計算復雜度高。?
9.3 主題模型
pLSA主題模型:
????????LSA是純粹從數學矩陣分解保證最小損失的角度去處理,而pLSA則是從統計學/概率學的角度去看待LSA。
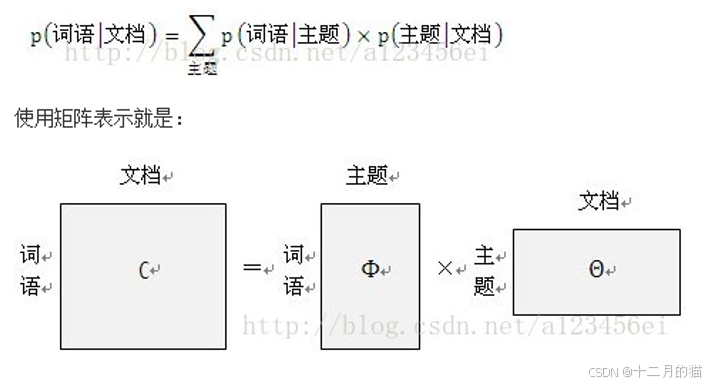
- 根據文檔-單詞信息訓練出單詞-主題信息+主題-文檔信息。
- 我們想要實現的是文檔的主題劃分(模型)。也就是主題-文檔信息,但是手頭只有單詞-文檔信息(數據),缺少單詞-主題信息(不完整)。因此需要EM算法在E步估計單詞-主題信息(偽標簽)。

可以把EM理解為深度學習中的偽標簽。他們都是處理數據信息不完整的問題。?

- LSA隱含高斯分布假設,pLSA多分布假設更符合文本特性。
- 不再是人為限制r的數量,而是從統計學去學習。
- 在數據不充足的情況下,沒有引入先驗經驗,而是直接用模型估計。受初始值影響大。?
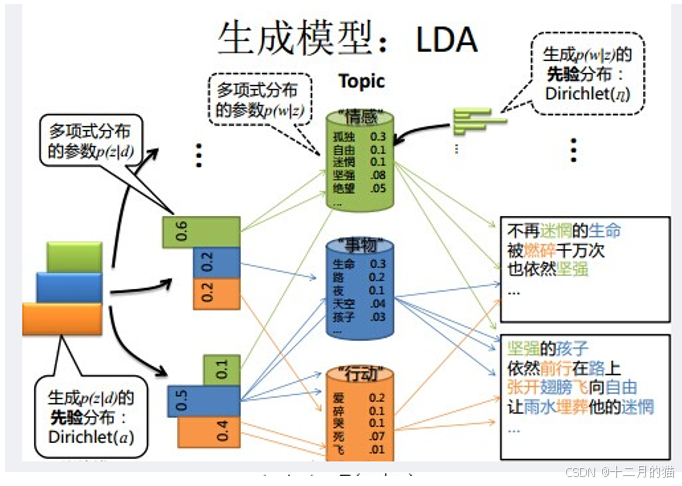
LDA主題模型:
LDA和PLSA思想一致,僅僅是將S改為D,也就是引入先驗分布(狄利克雷分布,Beta分布)
9.4 文檔哈希
思想:把任意長度的輸入(文字、圖像)轉化為固定長度的輸出。
目標:哈希碼的相似程度能夠直接反映輸入內容的相似程度
文檔哈希判斷重復:
- 文本預處理(文檔理解、句子分割、分詞、詞規范化、去停用詞)
- 文本表示(特征表示)
- 將高維特征向量映射成指紋
- 通過比較兩篇文章的f-bit指紋的漢明距離來判斷是否重復
shingle算法(PPT未講)
局部敏感哈希LSH:
- MinHash
- Simhash
Simhash算法:
- 分詞:將語句分詞;計算詞的特征向量;為每一個特征向量設置權重。
- hash:選擇simhash的位數;通過hash函數為每一個特征向量計算hash值。
- 加權:在hash值基礎上給特征向量加權;遇到1則hash值直接乘權重,遇到0則取-1乘權重。

- 合并:將上述各個特征向量的加權結果累加,變成一個序列串。

- 降維:對于合并后的結果,如果大于0則置1,否則置0.

10. 第十一章 語言模型(統計語言模型、神經網絡語言模型)
? ? ? ? 對于文本這個非結構化數據,我們前面幾章研究的算是比較透徹了。從一開始文本預處理(文檔解析、句子分割、分詞(基于詞典的匹配算法、基于統計的方法)、詞規范化、去停用詞)到文本表示(文本向量化、LSA、Plsa、LDA、主題模型、文檔哈希)。
? ? ? ? 接下去,我們來學習語言模型,算是文本表示之后的應用部分。在我們得到文本的向量表示之后,可以利用這個信息來訓練一個語言模型。它能夠反饋一個句子的可信度,也可以生成新的句子(看具體任務)。
n-gram語言模型:?

- 根據大數定理,只要統計量足夠,相對頻度就等于概率。
- 但是當句子長了之后,w1,w2.....wn組合實在太多了會導致概率幾乎為0。
- 解決辦法:1.增加數據量;2.平滑技術(降低已出現的概率,從而使未出現的非0);3.神經網絡模型
提出n-gram語言模型:

- 理論上n越大越好。
- 經驗上,trigram用的最多。
- 盡管如此能用bigram絕不使用trigram。
神經網絡語言模型NNLM:
- N-gram模型無法建模更遠的依賴關系。
- N-gram模型無法建模出詞之間的相似度。
- N-gram模型泛化能力不夠強。
 最早神經網絡模型結構:
最早神經網絡模型結構:
1.線性Embedding層:

2.中間層:

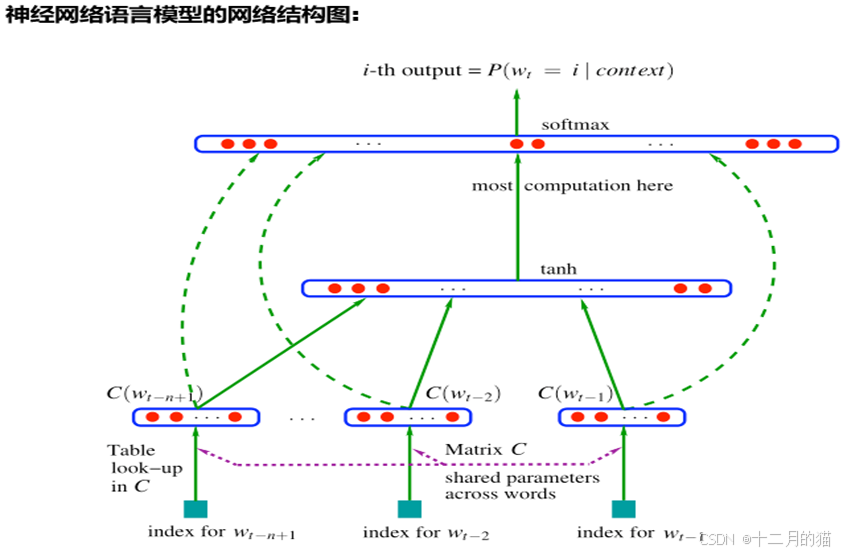
3.輸出層:

優點:?
- 詞語之間的相似性可以通過詞向量來體現。
- 自帶平滑功能。
11. 第十二章 詞嵌入和文檔嵌入
? ? ? ? 文字在經過預處理的五個階段,然后利用比較合適的方法進行文本表示。之后想要使用這些文本進行應用,因此設計語言模型。當然,在語言模型中延申出更好的文字表示(詞向量)。語言模型分為:統計語言模型(n-gram語言模型)、指數語言模型、神經網絡語言模型(nnlm,word2vec)。
? ? ? ? 其實文本表示章節就是在研究怎么把文本這個非結構數據表示為向量。但是無論我們用什么辦法,都無法很準確的描述(向量表達能力不夠,例如無法表達相似關系)。直到深度學習的出現,其在應用的過程中,首先就會將事物映射為相當復雜的向量,然后再做處理(特征提取)。可以這么說:
- 深度學習 = 特征提取+特征使用
- 深度學習模型 = 特征提取+特征使用
- 特征提取就是轉化為合適的向量
- 特征使用就是利用這些特征完成具體的任務(分類、目標檢測、自然語言生成等)
對預測任務的理解:
- 材料罐 = 特征(鐵礦石/木炭/石英)
- 煉金爐 = 模型(不同配方函數)
- 每個材料提煉后的精華 = 模型特征提取
- 精華的融合 = 模型特征使用
- 改進煉丹爐 = 反向傳播訓練模型
- 從初級升到高級煉丹爐 = 換模型
- 溫度控制 = 學習率
- 目標產物 = 預測值(黃金)
人類說話本質上:
- 輸入是前面說過的話
- 輸出是要說的下一個字
- 例如”我要去“,通過前面這三個字大腦這個模型就會輸出我心中最想去的地方作為輸出,”拉薩“!那如果我去過”拉薩“了,我的大腦模型就變了,我會輸出”云南“!
NNLM存在的問題:需要對詞典中所有word都算一遍概率,訓練、推理速度都太慢。
- 前半部分訓練詞語的特征向量。
- 后半部分通過詞向量訓練神經網絡語言模型。
word2vec:
- CBOW模型:利用周圍詞來計算中心詞概率,特征融合方法采用點對點加法。
- Skip-Gram模型:根據某個詞來計算周圍詞的概率。用成對單詞進行訓練(input word,output word)輸出是概率分布。引入層次和負采樣來解決NNLM計算詞典所有word的問題。

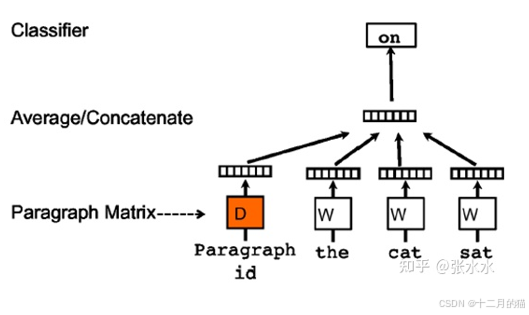
Doc2Vec:
????????不僅能學習單詞得向量,還能學習文本的向量表示。用于聚類、分類。訓練過程時,同時訓練詞向量和段落向量。詞向量隨滑動窗口的改變而改變,而段落向量只要在本段就不會改變。?
Glove:
? ? ? ? 改進了word2vec只能利用窗口中的局部信息的缺陷,成功利用全語料庫的信息。詞共現矩陣,表示了兩詞不同文檔出共現次數。
詞嵌入:使用深度學習來進行文本表示(將文本轉化為詞向量,同時盡可能減少信息損失)

不同方法本質都在想辦法盡可能保留下文本信息。
12. 第十三章 文本分類
12.1 文本分類
定義:用計算機對文本(或其他實體)按照一定的分類體系或標準進行自動分類標記。
應用:
- 情感分析:積極、消極、中性
- 主題分析:金融、體育、軍事
- 意圖識別:天氣查詢、歌曲搜索
- 問答任務:是、否
- 自然語言推理:導出、矛盾、中立
基本結構:
- 特征表示:詞袋模型、TF-IDF、統計語言模型(n-gram模型)、神經網絡語言模型(nnlm等詞嵌入)。
- 分類模型:淺層深度學習(參數較少,在小規模上效果好)、深度學習模型(結構復雜,對數據依賴性強)
Doc2Vec文本分類:
- 數據預處理
- 訓練Doc2Vec模型,得到文檔嵌入向量
- 創建文檔向量并劃分數據集
- 訓練分類器
Word2Vec文本分類:
- 方法流程同Doc2Vec類似,區別在于是對文檔中所有單詞的嵌入向量加權平均得到文檔向量。
12.2 fastText
Word2Vec的局限性:
- Word2Vec需要為每一個單詞創建嵌入,它不能處理任何在訓練中沒有遇到過的單詞。
- 對于詞根相同的單詞如eating、eat和eaten,這些單詞應該彼此有聯系,存在參數共享。
fastCNN(改進的是特征提取這一塊):

- 找特征向量的時候以字符級去確定特征向量,而不是整個單詞。
- 在訓練中,由于利用n-gram提取單詞中子部分特征,因此存在許多共享的部分(eat和eating存在共享)。因此訓練速度更快。
- 存儲空間更大了,因為需要存儲更多詞向量。

12.3 TextCNN
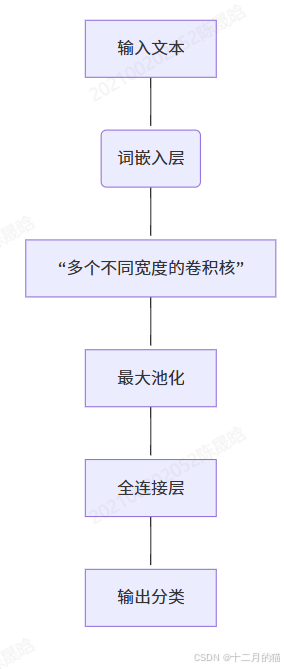
- 將計算機視覺中用于圖像識別的CNN遷移到自然語言領域。(改進的是特征使用這一塊)。
- 準備不同大小的卷積核,提取不同的信息,然后利用池化層和全連接層來使用這些信息。
- TextCNN的卷積核只能在序列方向移動。
12.4 大語言模型中的Token化
前面我們對文字這個非結構數據的處理流程是:文本預處理、文本表示、文本應用。
文本預處理里面提到分詞,從基于詞典模型? 到? 基于統計模型(HMM模型)
但是這一類的模型仍然存在問題:
- 詞典依賴性。
- 形態處理能力不足。
- 歧義處理能力弱。
- 跨語言適配差。
于是 分詞中的全新流派——Token出現了!!!
從此以后我們是按照Token去分詞,而不是按照詞去分詞~~
Token的優點:
- 自由把詞組合或拆分作為Token單位
- 開放詞匯表
- 形態處理能力強
- 跨語言適配性強
BPE:
- 初始化詞匯表
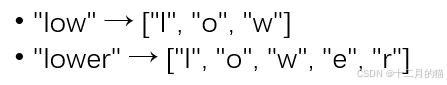
- 統計所有單詞及其字符的出現頻率

- 迭代合并高頻字符對

- 終止條件
本質就是在 考慮字符 和 考慮詞符 之間去找了一個平衡點。
核心思想:
- 出現頻率高+相鄰則合并有兩個目的:1.參考哈夫曼樹的思想;2.相鄰意味著是一個詞本身就要合并。
- 需要Token細粒化到什么程度由預設詞匯量決定。
優點:
- 從字符層級去考慮分詞。變為開放詞匯表同時提高了形態處理能力。
- 進行了有效壓縮,減少了全局分詞的弊端。
13. 第十四章 Web圖片數據
? ? ? ? 前面好多章,我們一直在講非結構數據中的文本部分。本章開始,我們就來講講圖片這個非結構數據。
13.1 web圖像
圖片分類:
- 矢量圖形
- SVG圖片:基于XML;可以用代碼來畫圖;隨時插入到HTML中;文字保留可編輯可搜尋狀態
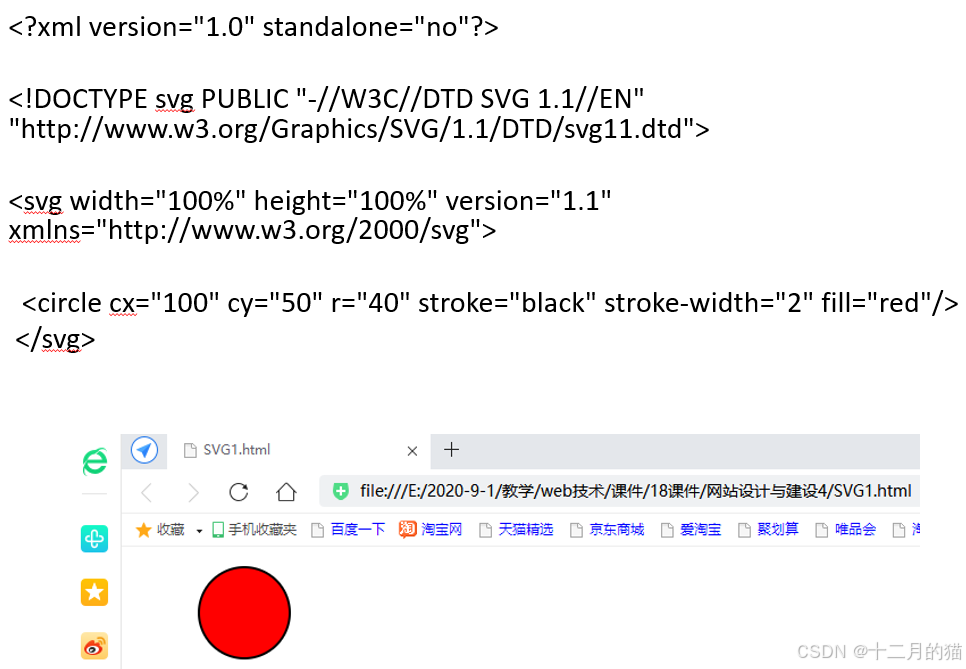
- 位圖圖像(Bitmap):使用顏色網格(像素,bit)來表現圖像。JPEG和GIF格式都是位圖。

13.2 圖像特征
從特征抽象程度來分:
- 低層特征
- 語義特征
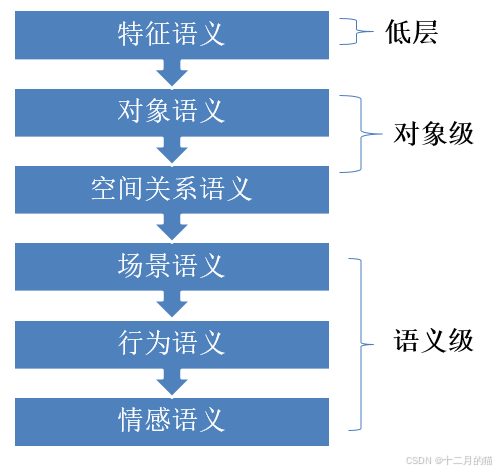
從特征來源來分:
- 局部特征
- 全局特征?
圖像常見特征有:
- 顏色特征
- 紋理特征
- 形狀特征
- CNN特征
13.3 顏色特征
- 顏色是彩色圖像最底層、最直觀的物理特征
- 通常對噪聲,圖像質量的退化、尺寸、分辨率等變化有很強的魯棒性。
- 全局特征
顏色空間:用數字表現顏色的抽象數學模型
- RGB空間:三種原色光描述自然界所有顏色,用相互垂直的坐標軸來表示,是一個加光模式。并不是完全符合人類對顏色相似性的視覺感知。

- HSV空間:人類視覺對亮度的敏感度大于色相的敏感度,因此分為三種分量:色相、飽和度、亮度。
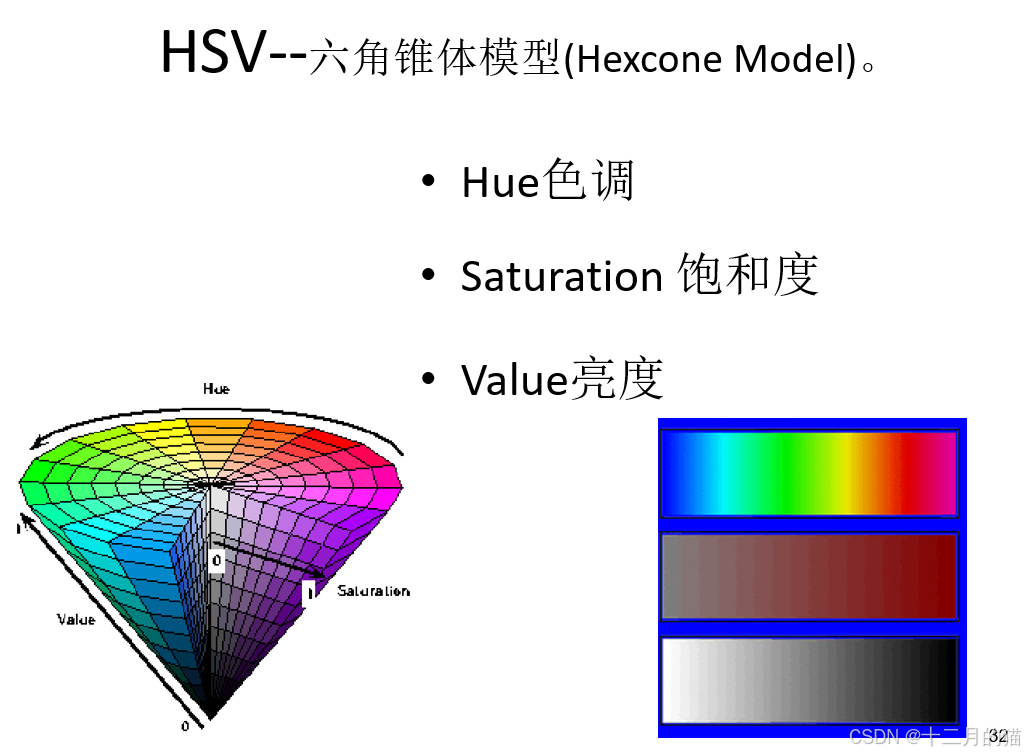
- 轉化公式:RGB向HSV的轉化公式

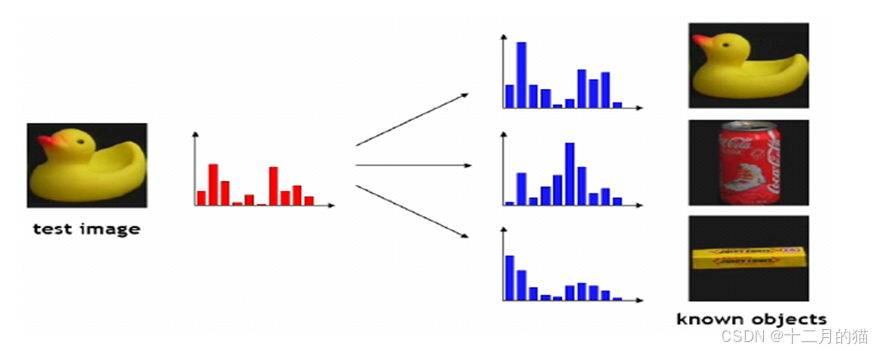
顏色直方圖:在顏色空間中采用一定的量化方法對顏色進行量化,然后統計每一個量化通道在整個圖像中所占的比重。
- 描述的是不同色彩在整幅圖像中所占比例。
- 描述分布特性。
- 具有平移、尺度、旋轉不變性。
- 適合描述那些難以自動分割的圖像。
- 任何圖像都有唯一一個直方圖,但是可能不同圖像有相同的顏色分布直方圖(可以分割承子圖像,建立索引來區分)。
顏色矩:在顏色直方圖的基礎上計算出每個顏色的矩估計。 直方圖是各個像素顏色的統計數據,顏色矩是各個像素顏色的統計摘要(用特征來表示)。前者是全部說出來,后者是把顏色統計信息轉為數學特征去表示。
- 一階矩(均值):
- 二階矩(方差):
- 三階矩(斜度):
- 四階矩(峰態):
使用這些特征量,代替顏色的統計值從而代表一張圖片。可以減少特征量(三個顏色分量,每一個使用三個低階矩3*3=9就可以表示),減少存儲空間。?
13.4 紋理特征
紋理特征:指在圖像中反復出現的局部模式和它們的排列規則,描述了圖像或者圖像區域所對應的景物的表面性質。并不反映本質屬性,隨分辨率變化有較大偏差,受光照反射等影響,造成誤導。
- 不是基于像素點的特征,而是基于像素區域的特征。
- 是一種統計特征,具有旋轉不變性,但是平移會發生改變。
基于信號處理方法描述紋理特征:
- 對圖像信號的頻率和方向進行選擇性濾波。
- 基于信號處理的方法也稱為濾波方法。
- 常見的圖像濾波方法有傅里葉變換和Gabor濾波器。
LBP特征:局部二值模式。結合了紋理圖像結構和像素統計關系的紋理特征描述方法。
- 一種有效的紋理描述算子
- 對光照具有不變性
- 具有旋轉不變性
- 灰度不變性

- 一般不用LBP圖譜作為特征向量用于分類識別,而是采用它的統計直方圖作為特征向量。
- 圖譜和位置有很大關系,會因為位置沒有對準產生很大誤差,可以將圖片劃分為若干個子區域,為每一個子區域建立LBP統計直方圖。
13.5 形狀特征
- 低級圖像特征主要有顏色、紋理和形狀。
- 低級圖像特征包括局部特征和全局特征:全局特征是基于整幅圖像提取的;局部特征是基于圖像的某個區域提取的。
- 局部形狀特征:LBP、HOG、SIFT
HOG特征(方向梯度直方圖):計算和統計圖像局部區域的梯度方向直方圖來構成特征
- 梯度概念就是像素值變換最快的方向。
- 在一幅圖像中,局部目標的表象和形狀能夠被梯度或邊緣的方向密度分布很好的描述
HOG步驟:
- 灰度化:將圖像看作(灰度)三維圖像。
- 采用Gamma矯正法對輸入圖像進行顏色空間標準化:減少噪音、局部陰影等干擾。
- 計算圖像每個像素的梯度
- 將圖像劃分為小Cell
- 統計每個cell的梯度直方圖:為每一個局部區域保留一個編碼,充分考慮局部信息。
- 將每幾個cell組成一個block,得到該block的HOG特征表述:從局部信息中提煉稍大一點的全局信息(非完全全局)。
- 將圖像內所有block的HOG特征描述串聯起來得到該圖像的HOG特征。

HOG優點:
- 由于HOG是在圖像的局部方格單元上操作,所以它對圖像幾何的和光學的形變都能保持比較好的不變性,因為這兩種形變只會出現在更大的空間領域上。
- 在粗的空域抽樣、精細的方向抽樣以及較強的局部光學歸一化等條件下,只要行人大體上能夠保持直立的姿 勢,可以容許行人有一些細微的肢體動作,這些細微的動作可以被忽略而不影響檢測效果。特別適合人體圖像檢測。
SIFT特征:
- 尺度不變特征轉換。
- 在空間尺度中尋找極值點,提取出其位置、尺度、旋轉不變量。
- 應用:機器人地圖感知導航。
- 尺度是客觀存在的,尺度空間的獲取要用高斯模糊來實現。高斯卷積是表現尺度空間的一種形式。
SIFT算法步驟:
- 建立尺度空間(高斯差分金字塔)。
- 在不同尺度空間中檢測極值點,進行精準定位和篩選。
- 特征點方向賦值(位置、尺度、方向等)
- 計算特征描述子
14. 總結
終于更新完了,不得不說Web數據管理的知識體量還是大的,比數據可視化大多了。希望這篇博客能夠給未來的學弟學妹們一點幫助。
?如果想持續關注系列文章,可以訂閱:
- 山東大學期末速通專用_十二月的貓的博客-CSDN博客













)


)


