前言
過去一周,我司「七月在線」長沙分部的具身團隊在機械臂和人形上并行發力
- 關于機械臂
一方面,在IL和VLA的路線下,先后采集了抓杯子、桌面收納、插入耳機孔的數據,然后云端訓-本地5090推理
二方面,在RL的路線下,通過復現UC伯克利的HIL-SERL先后在仿真、真機上抓方塊 - 關于人形
一者,對于manipulation,本周暫先實現了通過VR遙操宇樹G1采集數據
二者,對于locomotion,我司長沙具身團隊的其中一個小組準備復現基于PBHC的KungfuBot
故為了和團隊更好的復現之,我在解讀完該論文之后,準備把其源碼也好好解析下
而根據此文《KungfuBot——基于物理約束和自適應運動追蹤的人形全身控制PBHC,用于學習打拳或跳舞(即RL下的動作模仿和運控)》可知,KungfuBot中的RL模塊是基于ASAP實現的
故為了更好的復現KungfuBot,本文先來解讀下ASAP目前已經對外開源的代碼
根據ASAP的GitHub代碼倉庫可知,ASAP專注于學習敏捷的人形機器人全身技能,構建在HumanoidVerse多模擬器框架之上,其
- 支持多種物理模擬器:IsaacGym、IsaacSim、Genesis
- 實現人形機器人的運動追蹤和全身控制
- 提供從仿真到現實的轉移能力
- 模塊化設計,支持算法、環境、模擬器的分離
┌─────────────────────────────────────────────────┐
│ 配置系統 (config/) │
│ base.yaml → algo/ → env/ → robot/ → rewards/ │
└─────────────┬───────────────────────────────────┘│ Hydra instantiate()▼
┌─────────────────────────────────────────────────┐
│ 環境層 (envs/) │
│ BaseTask ← locomotion/motion_tracking │
└─────────────┬───────────────────────────────────┘│ composition▼
┌─────────────────────────────────────────────────┐
│ 模擬器層 (simulator/) │
│ BaseSimulator ← IsaacGym/IsaacSim/Genesis │
└─────────────┬───────────────────────────────────┘│ used by▼
┌─────────────────────────────────────────────────┐
│ 算法層 (agents/) │
│ BaseAlgo ← PPO/DAGGER/DeltaA/ForceControl │
└─────────────────────────────────────────────────┘運行時調用順序如下
1. train_agent.py::main()
2. ├── config加載 (Hydra)
3. ├── 模擬器選擇 (IsaacGym/IsaacSim/Genesis)
4. ├── env實例化 (BaseTask子類)
5. │ ├── simulator實例化 (BaseSimulator子類)
6. │ ├── robot配置加載
7. │ └── terrain/obs/rewards設置
8. ├── algo實例化 (BaseAlgo子類)
9. │ ├── actor/critic網絡創建
10. │ └── 數據緩沖區初始化
11. └── algo.learn() 訓練循環第一部分?算法模塊 agents/
包含
- train_agent.py: 訓練智能體的主入口
train_agent.py: ├── hydra → 配置加載 ├── utils.config_utils → 配置預處理 ├── BaseTask → 環境創建 ├── BaseAlgo → 算法創建 └── wandb → 日志記錄 - eval_agent.py: 評估智能體的主入口
提供實時鍵盤控制接口
支持力控制調試功能
可視化評估結果
agents模塊的完整目錄如下
agents/
├── base_algo/ # 算法基類定義
│ └── base_algo.py # BaseAlgo抽象基類
├── modules/ # 神經網絡核心組件
│ ├── ppo_modules.py # PPO Actor/Critic網絡
│ ├── modules.py # 通用神經網絡模塊
│ ├── encoder_modules.py # 編碼器模塊
│ ├── world_models.py # 世界模型實現
│ └── data_utils.py # 數據存儲和GAE計算
├── callbacks/ # 實時分析和可視化系統
│ ├── base_callback.py # 回調基類
│ ├── analysis_plot_*.py # 各類分析繪圖回調
│ └── analysis_plot_template.html # 實時可視化模板
├── ppo/ # 標準PPO算法
├── dagger/ # 模仿學習算法
├── decouple/ # 解耦合控制算法
├── delta_a/ # ASAP核心創新:增量學習
├── delta_dynamics/ # Delta動力學模型
├── force_control/ # 力感知控制算法
├── mppi/ # 模型預測路徑積分控制
└── ppo_locomanip.py # 運動操作專用PPO1.1 模塊組件agents/modules/
1.1.1 ppo_modules.py: PPO算法的Actor-Critic網絡
1.1.2 modules.py: 通用神經網絡模塊
1.1.3 encoder_modules.py:?編碼器模塊
1.1.4 world_models.py: 世界模型實現
1.1.5 data_utils.py: 數據處理工具,包含經驗回放緩沖區
// 待更
1.2 回調系統 agents/callbacks/
**分析和可視化:**
- **analysis_plot_*.py**: 各種分析圖表生成
- **base_callback.py**: 回調基類
- 支持力估計、運動分析、開環跟蹤等多種分析
1.3 模仿學習:DAgger 算法實現(dagger.py)
本文件實現了 DAgger(Dataset Aggregation)模仿學習算法,是 ASAP 框架中用于“模仿學習/專家演示學習”的核心類。它讓智能體在自己的策略下探索環境,并在這些狀態下查詢專家動作,逐步聚合數據,提升策略泛化能力
整個算法的流程為
- 初始化:加載學生和專家網絡,準備數據存儲
- 訓練循環:
用學生策略探索環境,記錄每一步的狀態和專家動作
用專家動作作為標簽,訓練學生策略模仿專家
記錄和可視化訓練過程 - 評估:支持回調式評估和推理
DAgger(BaseAlgo)
- 繼承自 BaseAlgo,擁有統一的 setup、learn、evaluate_policy 等接口
- 關鍵成員變量包括:
? - self.actor:待訓練的策略網絡
? - self.gt_actor:專家(教師)策略網絡
? - self.optimizer:優化器
? - self.storage:數據存儲(經驗回放)
? - self.writer:Tensorboard 日志
? - self.eval_callbacks:評估回調
? - self.episode_env_tensors:環境統計
1.3.1 setup:模仿學習中"學生-教師"雙網絡架構的實現
該方法主要
- 網絡初始化:創建學生網絡(需要訓練的actor)和教師網絡(提供專家示范的gt_actor)
- 優化器設置:為學生網絡配置Adam優化器
- 存儲初始化:設置用于存儲軌跡數據的RolloutStorage,注冊各種數據類型的存儲鍵
- 統計跟蹤:初始化用于跟蹤訓練過程中各種統計信息的變量和緩沖區
即初始化 RolloutStorage,注冊觀測、動作、專家動作等數據字段
具體而言
- 方法開始時通過日志記錄初始化過程,然后創建兩個關鍵的神經網絡組件
第一個是學習者網絡 (`self.actor`),它是需要被訓練的策略網絡,使用當前配置中的網絡架構參數進行初始化
第二個是專家網絡 (`self.gt_actor`),它代表"ground truth"或教師策略,不僅使用專門的網絡配置,還通過 `teacher_actor_network_load_dict` 加載預訓練的權重def setup(self):logger.info("Setting up Dagger") # 記錄開始設置DAgger算法的日志信息# 從配置中提取演員網絡的配置字典actor_network_dict = dict(actor=self.config.network_dict['actor'])
最終,分別創建學生actor、教師gt_actor# 從配置中提取教師演員網絡的配置字典teacher_actor_network_dict = dict(actor=self.config.network_dict['teacher_actor'])# 從配置中提取教師演員網絡的加載配置字典teacher_actor_network_load_dict = dict(actor=self.config.network_load_dict['teacher_actor'])
這種設計使得專家網絡能夠在訓練過程中為學習者提供高質量的示范動作# 創建學生演員網絡(PPO演員,固定標準差)self.actor = PPOActorFixSigma(self.algo_obs_dim_dict, actor_network_dict, {}, self.num_act)# 創建教師演員網絡(ground truth演員,用于提供專家示范)self.gt_actor = PPOActorFixSigma(self.algo_obs_dim_dict, teacher_actor_network_dict, teacher_actor_network_load_dict, self.num_act) - 網絡初始化完成后,代碼將兩個網絡都移動到指定的計算設備上,確保訓練過程中的計算效率
# 將學生演員網絡移動到指定設備(CPU或GPU)self.actor.to(self.device)# 將教師演員網絡移動到指定設備(CPU或GPU)self.gt_actor.to(self.device) - 接下來,為學習者網絡創建 Adam 優化器,這是訓練過程中唯一需要更新參數的網絡,而專家網絡的參數保持固定
# 創建Adam優化器來訓練學生演員網絡self.optimizer = optim.Adam(self.actor.parameters(), lr=self.learning_rate)logger.info(f"Setting up Storage") # 記錄開始設置存儲的日志信息 - 然后,方法初始化了一個專門的存儲系統 `RolloutStorage`,用于管理訓練數據的收集和批處理
存儲系統的設計特別體現了 DAgger 算法的數據需求
首先,它為所有觀測變量分配存儲空間
然后注冊兩套完整的動作相關數據:# 創建回合存儲對象,用于存儲軌跡數據self.storage = RolloutStorage(self.env.num_envs, self.num_steps_per_env)## Register obs keys # 注冊觀測鍵# 遍歷算法觀測維度字典,為每個觀測類型注冊存儲鍵for obs_key, obs_dim in self.algo_obs_dim_dict.items():self.storage.register_key(obs_key, shape=(obs_dim,), dtype=torch.float)
? 一套用于學習者的動作、動作概率、動作均值和方差
# 注冊學生演員的動作存儲鍵self.storage.register_key('actions', shape=(self.num_act,), dtype=torch.float)# 注冊學生演員的動作對數概率存儲鍵self.storage.register_key('actions_log_prob', shape=(1,), dtype=torch.float)# 注冊學生演員的動作均值存儲鍵self.storage.register_key('action_mean', shape=(self.num_act,), dtype=torch.float)# 注冊學生演員的動作標準差存儲鍵self.storage.register_key('action_sigma', shape=(self.num_act,), dtype=torch.float)
這種并行存儲機制使得算法能夠在每個時間步同時記錄學習者的行為和專家在相同狀態下的示范行為,為后續的監督學習提供配對的訓練數據# 注冊教師演員的動作存儲鍵(ground truth actions)self.storage.register_key('gt_actions', shape=(self.num_act,), dtype=torch.float)# 注冊教師演員的動作對數概率存儲鍵self.storage.register_key('gt_actions_log_prob', shape=(1,), dtype=torch.float)# 注冊教師演員的動作均值存儲鍵self.storage.register_key('gt_action_mean', shape=(self.num_act,), dtype=torch.float)# 注冊教師演員的動作標準差存儲鍵self.storage.register_key('gt_action_sigma', shape=(self.num_act,), dtype=torch.float) - 最后,方法初始化了訓練過程中的統計和監控組件
這包括用于記錄回合信息的列表,以及使用雙端隊列實現的滑動窗口統計,可以跟蹤最近100個回合的獎勵和長度
同時,為每個并行環境分配了當前獎勵總和和回合長度的張量,支持多環境并行訓練的實時統計# 初始化回合信息列表,用于存儲每個回合的統計信息self.ep_infos = []# 創建獎勵緩沖區,最多存儲100個回合的獎勵(用于計算平均獎勵)self.rewbuffer = deque(maxlen=100)# 創建長度緩沖區,最多存儲100個回合的長度(用于計算平均長度)self.lenbuffer = deque(maxlen=100)# 初始化當前獎勵累計張量,為每個環境跟蹤當前回合的獎勵總和self.cur_reward_sum = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)# 初始化當前回合長度張量,為每個環境跟蹤當前回合的步數self.cur_episode_length = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)
1.3.2 learn:訓練主循環,分為數據采集和訓練兩個階段
每次迭代:
- _rollout_step:用當前策略與環境交互,收集狀態、動作、專家動作等數據
- _training_step:用行為克隆損失(BC Loss)訓練 actor,使其輸出盡量接近專家動作
- 日志記錄與模型保存
具體而言
- 首先,如果設置了 `init_at_random_ep_len`,會將環境的 episode 長度緩沖區隨機初始化,以增加訓練多樣性
接著,環境被重置,獲得初始觀測,并將所有觀測張量移動到指定設備(如 GPU),確保后續計算高效def learn(self):# 如果需要在隨機的episode長度初始化,則對環境的episode長度緩沖區進行隨機賦值if self.init_at_random_ep_len:self.env.episode_length_buf = torch.randint_like(self.env.episode_length_buf, high=int(self.env.max_episode_length))# 重置所有環境,獲取初始觀測obs_dict = self.env.reset_all()# 將所有觀測數據轉移到指定設備(如GPU或CPU)for obs_key in obs_dict.keys():obs_dict[obs_key] = obs_dict[obs_key].to(self.device) - 隨后,模型被切換到訓練模式
主循環根據 `num_learning_iterations` 控制迭代次數,每次迭代都記錄起始時間# 設置模型為訓練模式self._train_mode()
每一輪,首先通過 `_rollout_step` 與環境交互,采集一批新數據,并返回最新的觀測# 獲取本次學習的迭代次數num_learning_iterations = self.num_learning_iterations# 計算總的迭代次數tot_iter = self.current_learning_iteration + num_learning_iterations# 遍歷每一次學習迭代# for it in track(range(self.current_learning_iteration, tot_iter), description="Learning Iterations"):for it in range(self.current_learning_iteration, tot_iter):# 記錄本次迭代的起始時間self.start_time = time.time()
然后調用 `_training_step`,對采集到的數據進行行為克隆(BC)訓練,得到平均損失# 進行一次rollout,返回新的觀測(必須更新,否則一直用初始觀測)obs_dict = self._rollout_step(obs_dict)
完成訓練后,記錄本輪訓練所用時間# 執行一次訓練步驟,返回平均BC損失mean_bc_loss = self._training_step()# 記錄本次迭代的結束時間self.stop_time = time.time()# 計算本次學習所用時間self.learn_time = self.stop_time - self.start_time - 每輪結束后,會整理日志信息(如當前迭代數、采集和訓練時間、平均損失、獎勵等)
并調用 `_post_epoch_logging` 進行可視化和記錄
如果當前迭代數滿足保存間隔條件,還會保存模型檢查點
每輪結束后,episode 相關信息會被清空,為下次迭代做準備 - 循環結束后,更新當前的學習迭代計數,并再次保存最終模型
整體來看,該方法實現了 DAgger 算法的標準訓練流程,包括數據采集、模型訓練、日志記錄和模型保存等關鍵步驟
1.3.3 _rollout_step
- 用 actor 采樣動作與環境交互,同時用 gt_actor 計算同一狀態下的專家動作
- 將觀測、動作、專家動作等信息存入 storage
- 統計獎勵、episode 長度等信息
1.3.4 _training_step
- 從 storage 生成小批量數據
- 計算行為克隆損失(BC Loss):均方誤差,目標是讓 actor 輸出接近專家動作
- 反向傳播并優化 actor 網絡
1.3.5 日志與評估
- _post_epoch_logging:詳細記錄訓練過程中的損失、獎勵、性能等信息,支持 Tensorboard 和 Rich 控制臺美化
- evaluate_policy:支持評估模式,結合回調機制靈活擴展評估邏輯
1.4 PPO:標準實現與運動操作專用PPO的實現
1.4.1 PPO的標準實現
這段代碼實現了 PPO(Proximal Policy Optimization)強化學習算法的主類。它負責整個算法的生命周期管理,包括初始化、模型和優化器的構建、數據存儲、訓練循環、模型保存與加載、評估流程等
1.4.1.1 __init__
- 在 `__init__` 構造函數中,PPO 類會初始化環境、配置、日志記錄器(用于 TensorBoard)、以及一些用于統計和追蹤訓練過程的變量。它還會初始化獎勵和回合長度的緩沖區,用于后續的統計分析
- `_init_config` 方法會從配置對象中提取所有關鍵超參數,包括環境數量、觀測和動作維度、學習率、損失系數、折扣因子等,確保算法的靈活性和可配置性
1.4.1.2 setup方法:調用 `_setup_models_and_optimizer` 和 `_setup_storage`
`setup` 方法會調用 `_setup_models_and_optimizer` 和 `_setup_storage`,分別初始化 actor/critic 網絡及其優化器,以及 rollout 數據存儲結構
- 模型采用 PPOActor 和 PPOCritic 兩個神經網絡,優化器使用 Adam
- 數據存儲結構會注冊所有需要追蹤的張量,包括觀測、動作、獎勵、優勢等
1.4.1.3?訓練主循環在 `learn` 方法
簡言之,訓練主循環在 `learn` 方法中實現。每次迭代會先進行 rollout(與環境交互收集數據),然后進行訓練步驟(mini-batch SGD),并記錄訓練過程中的各種統計信息。訓練過程中會定期保存模型和優化器狀態,便于斷點恢復
具體而言
- 首先,如果配置了 `init_at_random_ep_len`,會將環境的 episode 長度緩沖區隨機初始化,這有助于增加訓練的多樣性
def learn(self):# 如果需要在隨機的episode長度初始化,則對環境的episode長度緩沖區進行隨機賦值if self.init_at_random_ep_len:self.env.episode_length_buf = torch.randint_like(self.env.episode_length_buf, high=int(self.env.max_episode_length)) - 接著,環境會被重置,獲得初始觀測
并將所有觀測張量移動到指定的設備(如 GPU 或 CPU),以確保后續計算的高效性# 重置所有環境,獲取初始觀測obs_dict = self.env.reset_all()# 將每個觀測都轉移到指定的設備上(如GPU或CPU)for obs_key in obs_dict.keys():obs_dict[obs_key] = obs_dict[obs_key].to(self.device) - 隨后,模型被切換到訓練模式(`self._train_mode()`),以啟用如 dropout、BN 等訓練相關的行為
主循環根據當前迭代次數和總訓練迭代數進行# 設置模型為訓練模式self._train_mode()
每次迭代包括以下步驟:# 獲取本次學習的迭代次數num_learning_iterations = self.num_learning_iterations# 計算總的迭代次數(當前迭代數 + 本次要迭代的次數)tot_iter = self.current_learning_iteration + num_learning_iterations
1. 記錄當前時間,便于后續統計訓練耗時
2. 調用 `_rollout_step` 與環境交互,收集一批數據(觀測、動作、獎勵等),并返回最新的觀測# 不使用track進度條,因為會和motion loading bar沖突# for it in track(range(self.current_learning_iteration, tot_iter), description="Learning Iterations"):for it in range(self.current_learning_iteration, tot_iter):# 記錄本次迭代的起始時間self.start_time = time.time()
3. 調用 `_training_step`,對采集到的數據進行策略和價值網絡的訓練# 進行一次rollout,返回新的觀測(必須更新,否則一直用初始觀測)obs_dict = self._rollout_step(obs_dict)
4. 記錄本次迭代的耗時,并將相關統計信息(如損失、采集時間、獎勵等)打包到 `log_dict`,用于日志記錄和可視化# 進行一次訓練步驟,返回損失字典loss_dict = self._training_step()
5. 每隔 `save_interval` 次迭代保存一次模型和優化器狀態,便于斷點恢復# 記錄本次迭代的結束時間self.stop_time = time.time()# 計算本次學習所用時間self.learn_time = self.stop_time - self.start_time# 日志信息字典,包含當前迭代、損失、采集和學習時間、獎勵等log_dict = {'it': it,'loss_dict': loss_dict,'collection_time': self.collection_time,'learn_time': self.learn_time,'ep_infos': self.ep_infos,'rewbuffer': self.rewbuffer,'lenbuffer': self.lenbuffer,'num_learning_iterations': num_learning_iterations}# 執行日志記錄self._post_epoch_logging(log_dict)
6. 清空本輪的 episode 信息緩存,為下輪訓練做準備# 每隔save_interval步保存一次模型if it % self.save_interval == 0:self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(it)))# 清空本輪收集的episode信息self.ep_infos.clear() - 循環結束后,更新當前的訓練迭代計數,并再次保存一次模型,確保所有訓練進度都被持久化
# 累加當前學習迭代次數self.current_learning_iteration += num_learning_iterations# 保存最終模型self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(self.current_learning_iteration)))
1.4.1.4?rollout (采樣和數據收集)的實現:_rollout_step與_actor_rollout_step
rollout 過程由 `_rollout_step` 實現——_rollout_step又會調用_actor_rollout_step,負責與環境交互、收集數據、處理獎勵和終止信息,并將數據寫入存儲
具體而言,
- 它首先在 `torch.inference_mode()` 上下文中運行,這樣可以避免梯度計算,提高推理效率。方法內部通過循環 `self.num_steps_per_env` 次,每次循環代表智能體在環境中的一步
def _rollout_step(self, obs_dict):# 在推理模式下,不計算梯度,提升效率with torch.inference_mode():# 遍歷每個環境步數for i in range(self.num_steps_per_env):# 初始化策略狀態字典policy_state_dict = {} - 在每一步中
首先通過 `_actor_rollout_step` 計算當前觀測下的動作及相關策略信息
并通過 `_critic_eval_step` 評估當前狀態的價值# 通過actor獲取動作及相關策略信息,存入policy_state_dictpolicy_state_dict = self._actor_rollout_step(obs_dict, policy_state_dict)
所有與觀測和策略相關的數據都會被存儲到 `self.storage`,以便后續訓練使用# 通過critic評估當前狀態的價值values = self._critic_eval_step(obs_dict).detach()# 將價值信息加入策略狀態字典policy_state_dict["values"] = values
隨后,智能體根據動作與環境交互,獲得新的觀測、獎勵、終止信號和額外信息# 將觀測信息存入rollout存儲for obs_key in obs_dict.keys():self.storage.update_key(obs_key, obs_dict[obs_key])# 將策略相關信息存入rollout存儲for obs_ in policy_state_dict.keys():self.storage.update_key(obs_, policy_state_dict[obs_])
并將這些數據轉移到設備上(如 GPU)# 獲取當前動作actions = policy_state_dict["actions"]# 構造actor_state字典actor_state = {}actor_state["actions"] = actions# 與環境交互,獲得新的觀測、獎勵、done標志和額外信息obs_dict, rewards, dones, infos = self.env.step(actor_state)# 將新的觀測轉移到指定設備for obs_key in obs_dict.keys():obs_dict[obs_key] = obs_dict[obs_key].to(self.device)# 獎勵和done也轉移到設備rewards, dones = rewards.to(self.device), dones.to(self.device) - 獎勵會根據是否有超時(`time_outs`)進行修正,確保獎勵的準確性
每一步的數據(獎勵、終止信號等)都會被存儲,并通過 `self._process_env_step` 處理智能體和價值網絡的重置
若啟用了日志記錄,還會統計每個 episode 的獎勵和長度,并在 episode 結束時重置相關統計量 - 循環結束后,方法會記錄采集數據所用的時間,并調用 `_compute_returns` 計算每一步的回報(returns)和優勢(advantages)
這些數據隨后批量存儲到 `self.storage`,為后續的策略優化做準備# 為訓練準備數據,計算returns和advantagesreturns, advantages = self._compute_returns(last_obs_dict=obs_dict,policy_state_dict=dict(values=self.storage.query_key('values'), dones=self.storage.query_key('dones'), rewards=self.storage.query_key('rewards'))) - 最終,方法返回最新的觀測字典
# 返回最新的觀測字典return obs_dict
1.4.1.5? GAE(廣義優勢估計):在 `_compute_returns` 方法中實現
優勢和回報的計算采用 GAE(廣義優勢估計),在 `_compute_returns` 方法中實現,能夠有效降低策略梯度的方差
- 首先,方法會用當前環境的最后一個觀測(`last_obs_dict`)通過價值網絡(critic)計算最后狀態的價值 `last_values`
并將所有相關張量(values、dones、rewards、last_values)移動到指定設備(如 GPU)def _compute_returns(self, last_obs_dict, policy_state_dict):"""計算每一步的回報(returns)和優勢(advantages),用于PPO訓練使用廣義優勢估計(GAE)來降低策略梯度的方差。"""# 用critic網絡評估最后一個觀測的狀態價值,并去除梯度last_values = self.critic.evaluate(last_obs_dict["critic_obs"]).detach()# 初始化優勢為0advantage = 0# 從策略狀態字典中獲取values、dones和rewardsvalues = policy_state_dict['values']dones = policy_state_dict['dones']rewards = policy_state_dict['rewards']# 將所有張量轉移到指定設備(如GPU)last_values = last_values.to(self.device)values = values.to(self.device)dones = dones.to(self.device)rewards = rewards.to(self.device) - 隨后,初始化一個與 values 形狀相同的 returns 張量,用于存儲每一步的回報
# 初始化returns張量,形狀與values相同returns = torch.zeros_like(values) - 為方便大家更好的理解,我直接引用此文《ChatGPT技術原理解析:從RL之PPO算法、RLHF到GPT4、instructGPT》的中的「3.3 針對「對話序列/獎勵值序列/values/DSC優勢函數/returns」的一個完整示例」內容 給大家解釋說明下
首先,GAE的計算公式為?
且如此文所說,考慮到有

故,實際計算的時候,為減少計算量,可以先計算A_7,再分別計算A_6、A_5、A_4、A_3、A_2、A_1
其次,再回顧一下TD誤差的含義:δ_1?=?r1?+ γV_old(2)?- V_old(1)
比如對于上式:實際獲得的即時獎勵 r1 加上折扣后的未來獎勵預測 γV_old(2),再減去我們原先預測的當前時間步的獎勵 V_old(1),這就是后者的預測與前者實際經驗之間的差距
SO,核心計算在一個反向循環中完成(從最后一步到第一步)。對于每一步,方法會判斷下一個狀態是否為終止狀態(`next_is_not_terminal`),并據此計算 TD 殘差(delta)
優勢(advantage)通過遞歸方式累加,結合了當前步的 TD 殘差和未來步的優勢,體現了 GAE 的思想# 獲取步數num_steps = returns.shape[0]# 反向遍歷每一步,計算GAE優勢和回報for step in reversed(range(num_steps)):# 最后一步的next_values用last_values,其余用下一步的valuesif step == num_steps - 1:next_values = last_valueselse:next_values = values[step + 1]# 判斷下一步是否為終止狀態next_is_not_terminal = 1.0 - dones[step].float()# 計算TD殘差delta = rewards[step] + next_is_not_terminal * self.gamma * next_values - values[step]
每一步的回報則等于當前優勢加上當前狀態的價值,即# 遞歸計算GAE優勢advantage = delta + next_is_not_terminal * self.gamma * self.lam * advantage ,故有
,故有 # 當前步的回報等于優勢加上當前價值returns[step] = advantage + values[step] - 最后,方法計算優勢(returns - values)
并進行標準化處理(減去均值,除以標準差),以便后續訓練時數值更穩定# 計算優勢(returns - values),并進行標準化advantages = returns - valuesadvantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)# 返回回報和標準化后的優勢 - 最終返回每一步的回報和標準化后的優勢。這個過程確保了 PPO 算法在更新策略時能夠利用高質量、低方差的優勢估計
return returns, advantages
1.4.1.6?_training_step
訓練步驟 `_training_step` 會從存儲中生成 mini-batch,依次進行策略和價值網絡的更新
1.4.1.7?_update_ppo
PPO 的核心損失計算在 `_update_ppo` 方法中實現,包括代理損失、價值損失和熵損失,并支持自適應 KL 散度調整學習率
1.4.1.8 其他
此外,類還實現了模型的保存與加載、評估流程(包括回調機制)、以及詳細的日志記錄和可視化
1.4.2?運動操作專用PPO
// 待更
1.5 ASAP的核心創新模塊:增量學習與Delta動力學模型
1.5.1 機器人運控train_delta_a.py:基于PPO的擴展(支持雙策略)
本文件定義了一個名為 `PPO DeltaA` 的類,是基于 PPO(Proximal Policy Optimization)算法的擴展,主要用于機器人運動控制任務,支持“雙策略”機制: ?
- 主策略:當前正在訓練的 PPO 策略 ?
- 參考策略:從 checkpoint 加載的、凍結參數的預訓練策略(可用于對比、輔助、模仿等)
其主要依賴包括
- `torch`、`torch.nn`、`torch.optim`:PyTorch 深度學習框架
- humanoidverse 相關模塊:自定義的環境、網絡結構、工具等
- `hydra`、`omegaconf`:配置管理
- `loguru`、`rich`:日志和美觀的終端輸出
- 其他:`os`、`time`、`deque`、`statistics` 等標準庫
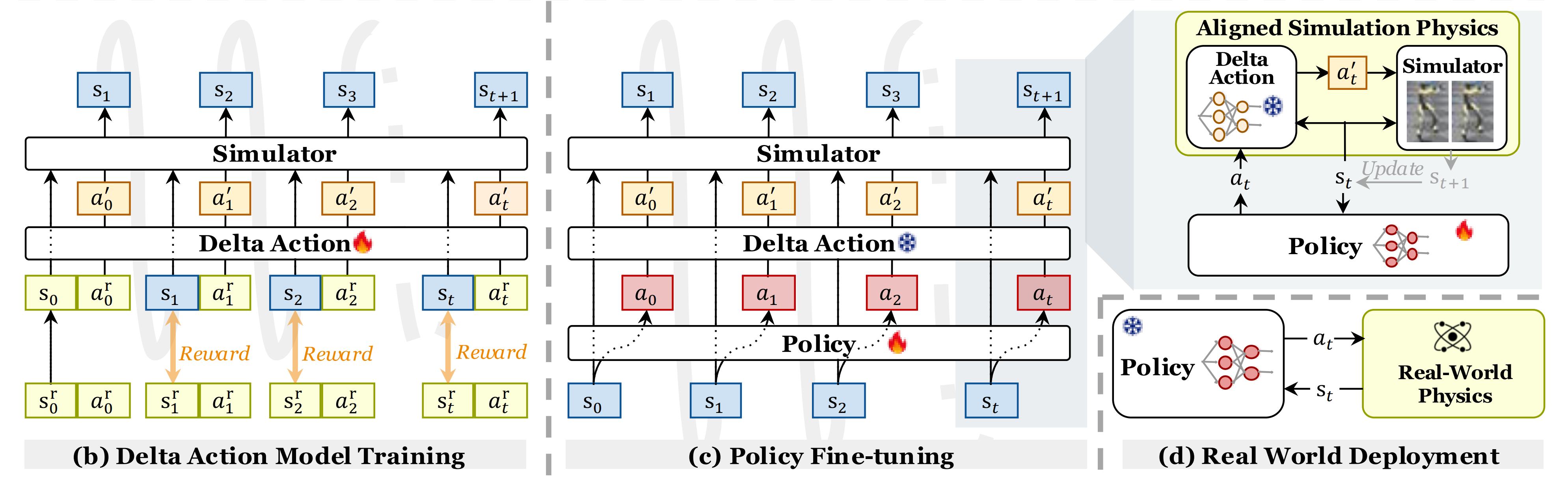
如此文《ASAP——讓宇樹G1后仰跳投且跳舞:仿真中重現現實軌跡,然后通過增量動作模型預測仿真與現實的差距,最終縮小差距以對齊》所說
- 工作流程如圖2(b)所示
- PPO 用于訓練增量動作策略
,學習修正后的
以匹配仿真與真實世界
1.5.1.1 初始化(`__init__`)
- -繼承自 PPO 基類,初始化環境、配置、日志目錄、設備等
如果配置中指定了 `policy_checkpoint`,則:
自動查找并加載 checkpoint 對應的 config.yaml 配置文件
合并 `eval_overrides` 配置(如果有) - 預處理配置
pre_process_config(policy_config) # 對配置進行預處理 - 使用 hydra 的 `instantiate` 動態實例化參考策略(`self.loaded_policy`),并調用其 `setup()` 方法
加載 checkpoint 權重到參考策略 - 設置參考策略為評估模式(凍結參數,不參與訓練)
禁用參考策略所有參數的梯度(`param.requires_grad = False`)
獲取參考策略的推理函數 `eval_policy`
1.5.1.2 rollout 步驟(`_rollout_step`):采集一段軌跡(rollout),供后續訓練使用
這段 `_rollout_step` 方法負責在強化學習訓練中收集一批(batch)環境交互數據。它的主要流程是在不計算梯度的情況下(`torch.inference_mode()`),循環執行 `num_steps_per_env` 次,每次代表環境中的一步
簡言之,每步流程:
- 主策略推理,得到動作(actions)和值(values)
- 參考策略推理,得到 `actions_closed_loop`
- 將主策略和參考策略的動作都傳入環境 `env.step(actor_state)`
- 收集環境返回的觀測、獎勵、done、info 等
- 更新存儲器(RolloutStorage),包括獎勵、done、values 等
- 統計回合獎勵、長度等信息
- 采集完一段后,計算 returns 和 advantages,供 PPO 算法訓練
具體而言,在每一步中
- 首先,主策略推理,得到動作(actions)和值(values)
通過 `_actor_rollout_step` 計算當前策略的動作,并通過 `_critic_eval_step` 計算當前狀態的價值(value),這些信息被存儲在 `policy_state_dict` 中def _rollout_step(self, obs_dict): # 采集一段rollout軌跡with torch.inference_mode(): # 關閉梯度計算,加速推理for i in range(self.num_steps_per_env): # 遍歷每個環境步# 計算動作和值# 策略狀態字典policy_state_dict = {} # 主策略推理policy_state_dict = self._actor_rollout_step(obs_dict, policy_state_dict) # 評估當前狀態的價值values = self._critic_eval_step(obs_dict).detach() # 存儲valuepolicy_state_dict["values"] = values - 隨后,所有觀測和策略相關的數據都會被存入 `self.storage`,用于后續訓練
## 存儲觀測for obs_key in obs_dict.keys():# 存儲每個觀測self.storage.update_key(obs_key, obs_dict[obs_key]) for obs_ in policy_state_dict.keys():# 存儲策略相關數據self.storage.update_key(obs_, policy_state_dict[obs_]) # 獲取主策略動作actions = policy_state_dict["actions"] # 構造actor狀態actor_state = {} # 主策略動作actor_state["actions"] = actions - 接下來,參考策略推理,得到 `actions_closed_loop`
方法還會用一個“參考策略”(`self.loaded_policy`,通常是預訓練或專家策略)對 `closed_loop_actor_obs` 進行推理,得到 `actions_closed_loop`
并將其與主策略的動作一起組成 `actor_state`,用于環境的下一步模擬# 參考策略推理policy_output = self.loaded_policy.eval_policy(obs_dict['closed_loop_actor_obs']).detach()# 存儲參考策略動作actor_state["actions_closed_loop"] = policy_output - 環境執行一步后,新的觀測、獎勵、終止標志和信息被返回。所有張量會被轉移到正確的設備(如 GPU),獎勵和終止信息也會被存儲
若出現超時(`time_outs`),獎勵會做相應調整# 與環境交互,獲得新觀測、獎勵、done等obs_dict, rewards, dones, infos = self.env.step(actor_state) for obs_key in obs_dict.keys():# 移動到指定設備obs_dict[obs_key] = obs_dict[obs_key].to(self.device) # 獎勵和done也移動到設備rewards, dones = rewards.to(self.device), dones.to(self.device) # 記錄環境統計信息self.episode_env_tensors.add(infos["to_log"]) # 獎勵擴展維度rewards_stored = rewards.clone().unsqueeze(1)
每一步還會調用 `_process_env_step` 進行額外處理# 如果有超時信息if 'time_outs' in infos: # 修正獎勵rewards_stored += self.gamma * policy_state_dict['values'] * infos['time_outs'].unsqueeze(1).to(self.device) # 檢查獎勵維度assert len(rewards_stored.shape) == 2 self.storage.update_key('rewards', rewards_stored) # 存儲獎勵self.storage.update_key('dones', dones.unsqueeze(1)) # 存儲doneself.storage.increment_step() # 存儲步數+1self._process_env_step(rewards, dones, infos) # 處理環境步 - 如果設置了日志目錄,還會記錄每個 episode 的獎勵和長度,便于后續統計和分析
- 循環結束后,方法會統計采集數據所用的時間,并調用 `_compute_returns` 計算每一步的回報(returns)和優勢(advantages)
這些數據會批量更新到存儲中,為后續的策略優化做準備# 計算回報和優勢returns, advantages = self._compute_returns(last_obs_dict=obs_dict,policy_state_dict=dict(values=self.storage.query_key('values'), dones=self.storage.query_key('dones'), rewards=self.storage.query_key('rewards')))self.storage.batch_update_data('returns', returns) # 存儲回報self.storage.batch_update_data('advantages', advantages) # 存儲優勢 - 最后返回最新的觀測字典
return obs_dict # 返回最新觀測
整個過程實現了數據采集、存儲和預處理的自動化,是 PPO 及其變體算法訓練流程的核心部分。
1.5.1.3 評估前處理(`_pre_eval_env_step`)
簡言之
- 用于評估階段,每步都讓主策略和參考策略分別推理動作
- 更新 `actor_state`,包含主策略動作和參考策略動作
- 支持回調機制(`eval_callbacks`),可擴展評估邏輯
1.5.2?Delta動力學模型
// 待更
1.6 控制算法:解耦合控制、力感知控制、模型預測路徑積分控制
// 待更
第二部分 環境模塊 envs/
BaseTask (envs/base_task/base_task.py):
├── BaseSimulator → 物理模擬器接口
├── terrain → 地形生成
├── robot配置 → 機器人參數
├── obs配置 → 觀察空間定義
└── rewards配置 → 獎勵函數設計具體任務繼承關系:
BaseTask
├── LocomotionTask (locomotion/)
├── MotionTrackingTask (motion_tracking/)
└── LeggedBaseTask (legged_base_task/)**基礎任務架構:**
- **BaseTask**: 所有RL任務的基類,處理模擬器初始化、環境設置、觀察空間定義
- **base_task/**: 包含基礎任務實現和配置
**專門任務類型:**
- **locomotion/**: 運動控制任務,實現機器人行走、跑步等基礎運動
- **motion_tracking/**: 運動追蹤任務,實現對人類動作的模仿和跟蹤
- **legged_base_task/**: 腿式機器人基礎任務
- **env_utils/**: 環境工具函數,包含地形生成、物理參數設置等
第三部分 模擬器模塊 simulator/
支持多種物理引擎:
- **IsaacGym**: NVIDIA的GPU加速物理模擬器
- **IsaacSim**: 基于Omniverse的仿真平臺
- **Genesis**: 新興的高性能物理模擬器
- **base_simulator/**: 模擬器基類,提供統一接口
第四部分 配置系統 config/
采用Hydra配置管理,結構化組織:
- **base.yaml/base_eval.yaml**: 基礎配置
- **algo/**: 算法特定配置
- **env/**: 環境配置
- **robot/**: 機器人配置 (如G1機器人的29自由度配置)
- **rewards/**: 獎勵函數配置
- **obs/**: 觀察空間配置
- **terrain/**: 地形配置
第五部分 工具模塊 utils/
**通用工具:**
- **common.py**: 通用函數
- **math.py**: 數學工具函數
- **torch_utils.py**: PyTorch相關工具
- **config_utils.py**: 配置處理工具
- **motion_lib/**: 動作庫,存儲和處理人類動作數據
第六部分 數據模塊data/
- **motions/**: 存儲人類動作數據
- **robots/**: 機器人模型文件和配置
第七部分 Isaac工具isaac_utils/
專門為Isaac模擬器提供的數學和旋轉工具:
- **maths.py**: 數學計算函數
- **rotations.py**: 旋轉變換工具
// 待更















)



