正則表達式是一種強大的文本模式匹配工具,它使用一種特殊的語法來描述要搜索或操作的字符串模式。在 Java 中,我們可以使用 java.util.regex包提供的類來處理正則表達式。
:::color3
正則表達式不止 Java 語言提供了相應的功能,很多其他語言都提供了對其的支撐,比如:Python、Javascript
:::
正則表達式
簡單來說,正則表達式就是一個由特殊字符(稱為元字符)和普通字符組成的字符串,用來定義一個搜索模式。這個模式可以用來匹配、查找、替換符合特定規則的文本。
例如,模式 \d+ 可以匹配一個或多個數字,模式 [a-z]+ 可以匹配一個或多個小寫字母。
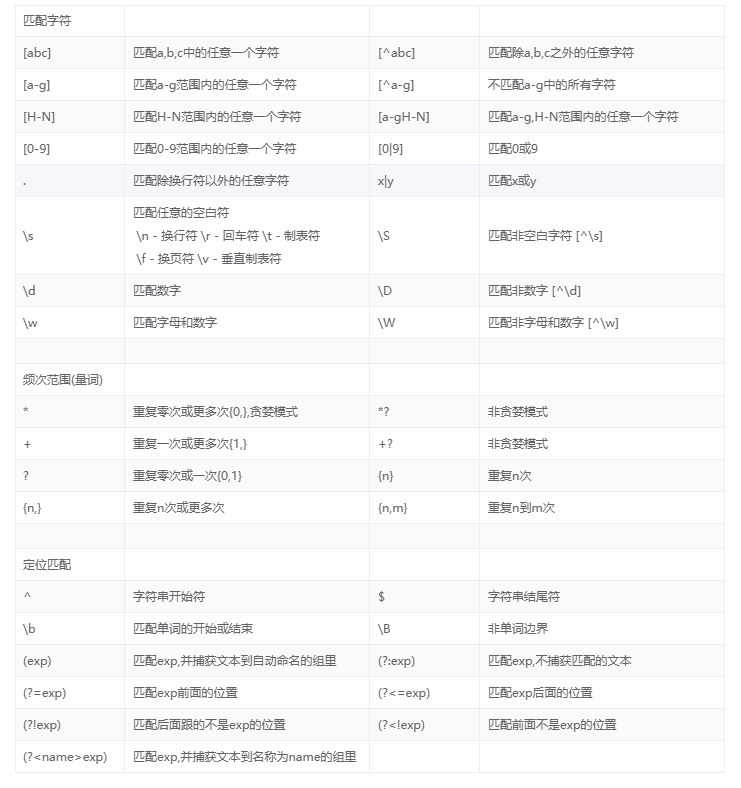
常用的元字符:
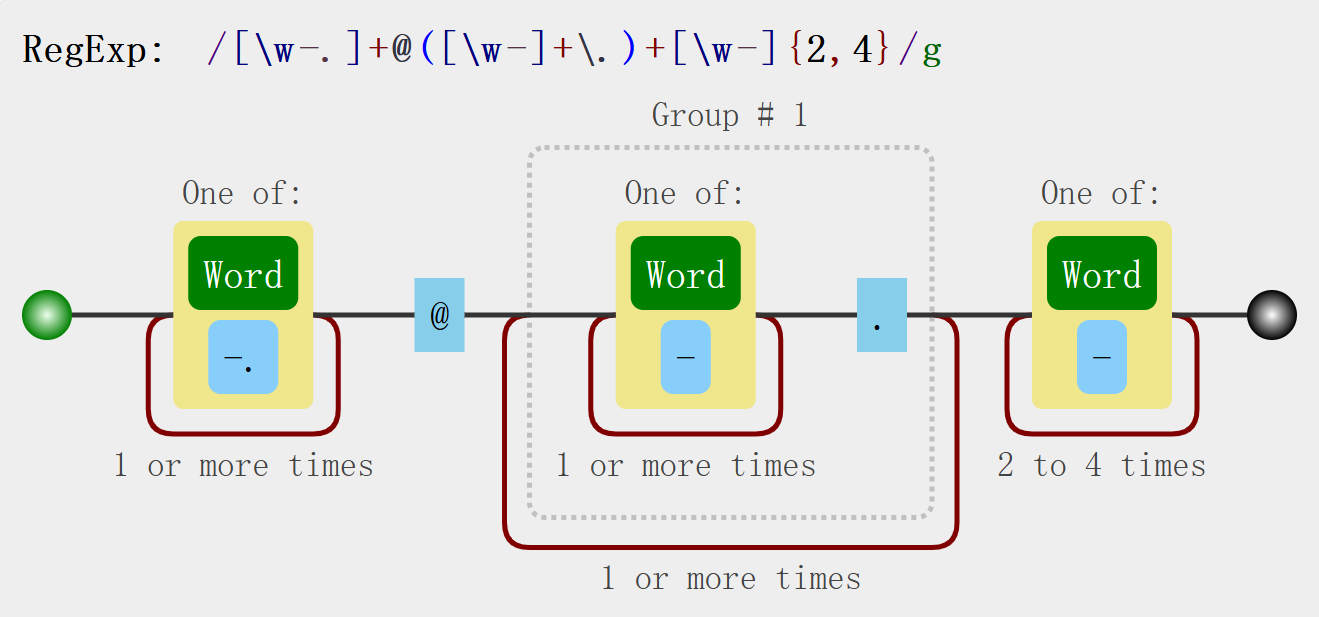
比如,這是一個匹配大多數郵箱地址的正則表達式:
^[\w\-\.]+@([\w\-]+\.)+[\w\-]{2,4}$
^
- 匹配輸入的 開始位置。
[\w\-\.]+
- 匹配郵箱的 用戶名部分(@ 前面)。
[\w\-\.]表示可以是以下任意一個字符:\w:等價于[a-zA-Z0-9_](字母、數字或下劃線)\-:減號(-)\.:點號(.)
+表示上面的字符可以重復出現 1 次或多次。
@
- 郵箱地址中的 @ 符號,用作用戶名和域名的分隔。
([\w\-]+\.)+
- 匹配域名部分中前面的部分(例如:
mail.google.)。 [\w\-]+:一個或多個字母、數字、下劃線或減號。\.:一個點號。(...) +:這個結構可以出現一次或多次,表示可以匹配像abc.、mail.google.等。
[\w\-]{2,4}
- 匹配最后的頂級域名(如
com、net、org)。 - 范圍
{2,4}表示:2 到 4 個字符之間。 - 允許的字符:字母、數字、下劃線、減號。
$
- 匹配輸入的 結束位置。
可以在這個網站方便的看到正則表達式的匹配情況:
https://www.mklab.cn/utils/regex
Java 中使用正則表達式
Java 中使用正則表達式的步驟
- 創建
**Pattern**對象: 使用Pattern.compile(String regex)編譯正則表達式。 - 創建
**Matcher**對象: 使用pattern.matcher(CharSequence input)將Pattern對象應用于輸入字符串。 - 進行匹配操作: 使用
Matcher對象的方法進行查找、匹配和替換等操作。
比如,我們使用上面的郵箱的正則表達式判斷字符串是不是一個郵箱地址:
Pattern pattern = Pattern.compile("[\\w\\-\\.]+@([\\w\\-]+\\.)+[\\w\\-]{2,4}");
Matcher matcher1 = pattern.matcher("111111111@qq.com");
System.out.println(matcher1.matches()); // trueMatcher matcher2 = pattern.matcher("123ab");
System.out.println(matcher2.matches()); // false
:::color3
在 Java 字符串中,反斜杠 \ 是一個特殊字符,用于轉義。因此,在正則表達式中要表示字面意義的反斜杠,需要使用雙反斜杠 \\。例如,要匹配一個點號 .,正則表達式應該是 \.,但在 Java 字符串中需要寫成 "\\."。
:::
Matcher 類的常用方法:
| 方法名 | 作用 |
|---|---|
| matches() | 嘗試將整個輸入序列與該模式匹配。只有當整個輸入序列完全匹配模式時才返回 true |
| find() | 嘗試查找與該模式匹配的輸入序列的下一個子序列。如果找到匹配項,則返回 true。可以多次調用 find() 來查找所有匹配項 |
| group() | 返回由上一次匹配操作所匹配的子序列。如果匹配成功,group(0) 返回整個匹配的子串。如果正則表達式中包含分組(用括號 () 包圍),可以使用 group(n) 來獲取第 n 個分組匹配的子串(索引從 1 開始) |
| start() | 返回上一次匹配的起始索引 |
| end() | 返回上一次匹配的結束索引(不包含) |
| replaceAll(String replacement) | 將輸入序列中所有匹配該模式的子序列替換為指定的 replacement 字符串。返回一個新的字符串 |
| replaceFirst(String replacement) | 將輸入序列中第一個匹配該模式的子序列替換為指定的 replacement 字符串。返回一個新的字符串 |
下面是一個使用正則表達式從字符串中統計 Hello 出現次數的例子,每次還打印了找到的 Hello 在字符串中的開始下標(包含)和結束下標(不包含):
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexMatches {public static void main( String[] args ){final String REGEX = "\\bHello\\b";final String INPUT = "Hello world,Hello Tomcat,Hello Java";Pattern p = Pattern.compile(REGEX);Matcher m = p.matcher(INPUT); // 獲取 matcher 對象int count = 0;while (m.find()) {count++;System.out.println("Match number " + count);System.out.println("start(): " + m.start());System.out.println("end(): " + m.end());}}
}
String 類提供了一些方便的方法,入參可以使用正則表達式:
| 方法名 | 作用 |
|---|---|
| matches(String regex) | 判斷字符串是否完全匹配給定的正則表達式 |
| split(String regex) | 根據給定的正則表達式將字符串分割成字符串數組 |
| replaceAll(String regex, String replacement) | 將字符串中所有匹配給定的正則表達式的子字符串替換為指定的 replacement 字符串 |
| replaceFirst(String regex, String replacement) | 將字符串中第一個匹配給定的正則表達式的子字符串替換為指定的 replacement 字符串 |
下面是使用 String 類的 replaceAll 方法將所有的數字替換為 * 的例子:
String text = "Hello 123 World 456";
String result = text.replaceAll("\\d+", "***"); // Hello *** World ***













)





