參考博客:https://blog.csdn.net/sjsjnsjnn/article/details/128345976
一、五種IO模型
- 阻塞式I/O
- 非阻塞式I/O
- I/O復用(多路轉接)
- 信號驅動式I/O
- 異步I/O
I/O我們并不陌生,簡單的說就是輸入輸出;對于一個輸入操作通常包括兩個不同的階段:
- 等待數據準備好
- 從內核向進程復制數據
對于一個套接字上的輸入操作,第一步通常涉及等待數據從網絡中到達,然后被復制到內核的某個緩沖區;第二步就是把數據從內核緩沖區復制到應用進程的緩沖區。
二、阻塞式I/O
2.1 概念
最流行的I/O模型是阻塞式I/O模型,我們之前的博客中基本都采用的是阻塞式I/O(因為默認情況下所有的套接字都是阻塞的)。
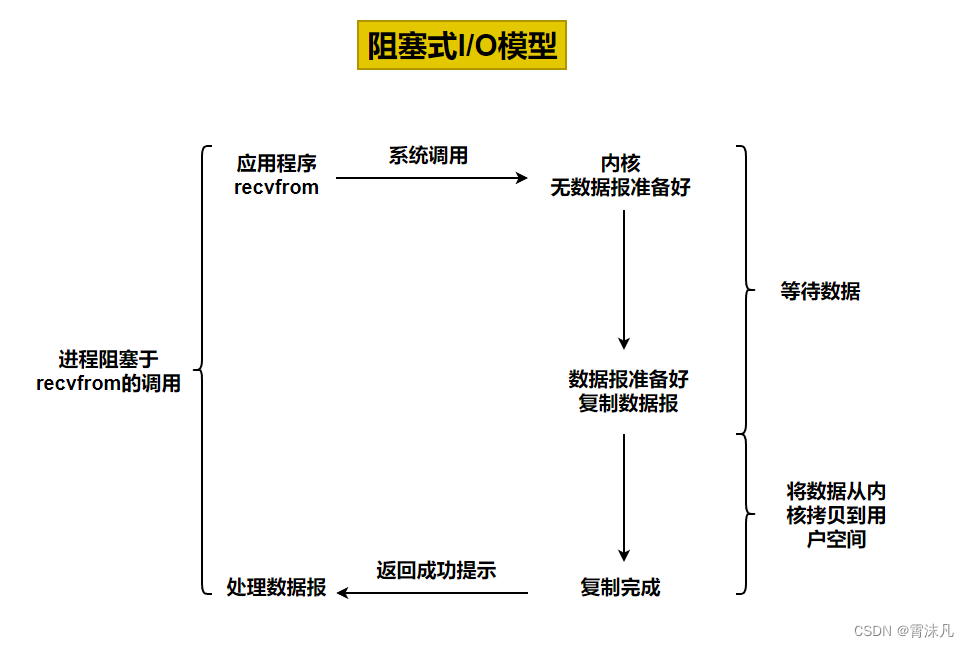
-
阻塞式 IO 是一種 同步 IO 模型,當進程 / 線程發起 IO 操作(如
read/write系統調用)時,若數據未準備好(或無法立即完成操作),發起操作的進程 / 線程會被操作系統 “掛起”(阻塞),無法執行其他任務,直到 IO 操作完成(數據就緒、讀寫完畢等)才會解除阻塞,繼續執行后續邏輯。 -
簡單說:“IO 沒完成,進程 / 線程就干等,啥也做不了”。
2.2 典型流程(以網絡 read 為例)
以從套接字讀取數據(recv/read 系統調用)為例,阻塞式 IO 的完整過程:
- 發起 IO 請求:進程調用
read嘗試讀取數據。 - 內核等待數據:若內核緩沖區中沒有可用數據(比如網絡數據還沒收到),內核會進入 “等待數據就緒” 狀態。
- 進程阻塞:此時,發起
read的進程會被操作系統標記為 “阻塞態”,從 CPU 調度隊列中移除,無法執行任何代碼。 - 數據就緒 & 拷貝:當內核拿到數據(如網絡包到達),會將數據從 內核空間拷貝到用戶空間。
- 解除阻塞,返回結果:數據拷貝完成后,操作系統喚醒進程,
read系統調用返回,進程繼續執行后續邏輯。
整個過程中,“等待數據就緒” 和 “數據拷貝” 兩個階段,進程都會處于阻塞狀態(無法干其他事)。
2.3 特點與優缺點
優點
- 實現簡單:無需復雜的輪詢、事件監聽邏輯,代碼直觀易寫(比如簡單的服務器 / 客戶端模型,直接用
accept/recv/send即可)。 - 邏輯清晰:適合對實時性要求不高、連接數少的場景,開發調試成本低。
缺點
- 資源浪費:進程 / 線程阻塞期間,會占用系統資源(如線程棧內存),且無法處理其他任務。高并發場景下,大量阻塞線程會導致系統資源被占滿,性能急劇下降。
- 響應不及時:若 IO 操作耗時久(如磁盤讀寫慢、網絡延遲高),阻塞會導致整個進程 / 線程 “卡殼”,無法響應其他請求。
2.4. 適用 & 不適用場景
適用場景
- 連接數少、數據量大:比如數據庫備份程序(少連接、但需傳輸大量數據),用阻塞 IO 可簡化代碼,無需處理復雜的并發邏輯。
- 對實時性要求低:如后臺腳本(日志歸檔、文件同步),阻塞等待的代價可接受。
- 開發調試階段:快速實現功能原型時,阻塞 IO 代碼簡潔,便于驗證邏輯。
不適用場景
- 高并發場景:如 Web 服務器需同時處理 thousands 連接,阻塞 IO 會導致線程爆炸,資源耗盡。
- 低延遲要求場景:如實時通信(IM、音視頻),阻塞等待會導致消息延遲、卡頓。
三、非阻塞式I/O
3.1 概念
對于非阻塞式I/O模型,就是進程把一個套接字設置成非阻塞,本質上就是在通知內核:當所有請求的I/O操作非得把本進程投入睡眠才能完成時,請不要把本進程投入睡眠,而是返回一個錯誤。
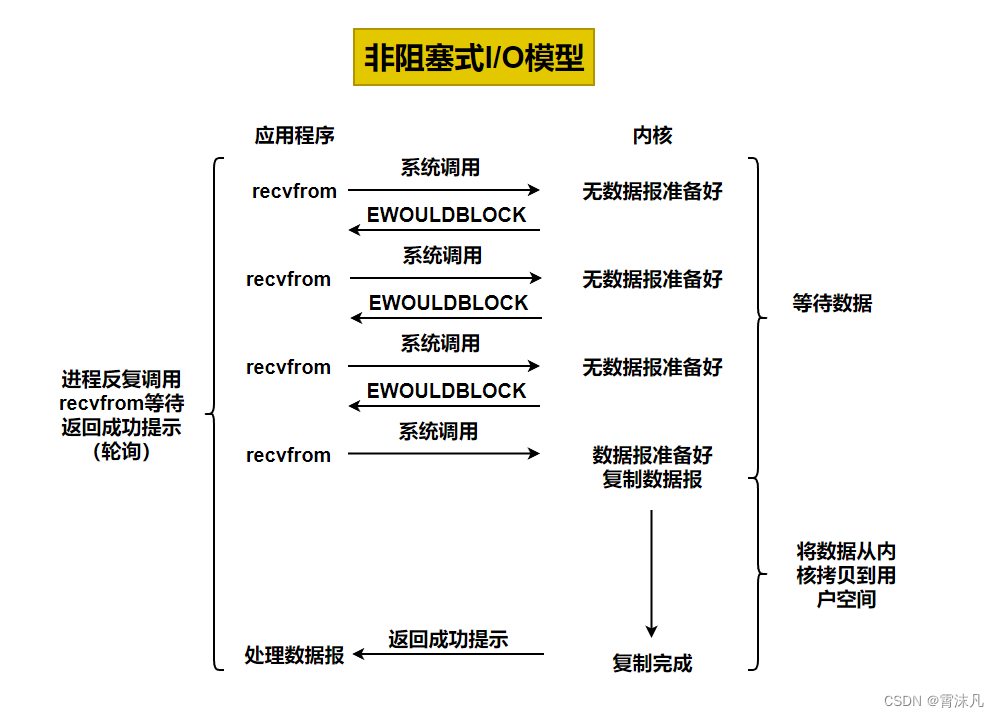
-
非阻塞 IO 是 同步 IO 模型(注意和 “異步 IO” 區分),當進程 / 線程發起 IO 操作(如
read/write)時,若數據未準備好(或無法立即完成),系統調用會立即返回特定狀態(如錯誤碼EAGAIN/EWOULDBLOCK),不會阻塞進程 / 線程。進程可繼續執行其他邏輯,或通過 “輪詢”“事件通知” 等方式,后續再嘗試 IO 操作。 -
簡單說:“IO 沒就緒,操作立即返回;進程不阻塞,自己決定后續咋處理”。
3.2 典型流程(以網絡 read 為例)
以從套接字讀取數據(recv/read 系統調用)為例,非阻塞 IO 的完整過程:
- 設置非阻塞模式:通過
fcntl或ioctl等函數,將文件描述符(如套接字)標記為 “非阻塞”。 - 發起 IO 請求:進程調用
read嘗試讀取數據。 - 判斷數據是否就緒:
- 若內核緩沖區有數據,則正常讀取,
read返回實際讀取的字節數,進程繼續處理數據。 - 若內核緩沖區無數據(IO 未就緒),
read立即返回 -1,并設置errno為EAGAIN或EWOULDBLOCK,表示 “操作暫時無法完成,建議稍后重試”。
- 若內核緩沖區有數據,則正常讀取,
- 進程執行其他任務:因
read未阻塞,進程可去處理其他邏輯(如響應其他請求、執行計算任務等)。 - 輪詢 / 事件驅動重試:進程可通過 “定時輪詢”(主動再次調用
read)或 “事件通知”(如結合select/poll/epoll),在數據就緒后重新發起read操作。
3.3 特點與優缺點
優點
- 高并發支持:單進程 / 線程可同時處理多個 IO 操作(通過輪詢或事件驅動),無需為每個 IO 單獨開線程,減少線程切換開銷,提升資源利用率。
- 實時響應:進程不會因某一個 IO 未就緒而 “卡殼”,可及時處理其他任務(如高并發服務器中,同時響應多個客戶端請求)。
- 靈活性強:進程可自主控制重試時機(比如結合業務邏輯,決定多久后再次嘗試 IO 操作)。
缺點
- 輪詢開銷:若單純用 “忙輪詢”(頻繁調用
read檢查數據),會持續占用 CPU,導致資源浪費。需結合select/poll/epoll等 “IO 多路復用” 機制優化。 - 編程復雜度高:需手動處理 “IO 未就緒” 的返回狀態,編寫重試邏輯、錯誤處理,代碼比阻塞 IO 復雜。
- 部分場景效率低:若 IO 操作頻繁且大部分時間未就緒,“輪詢 + 重試” 可能比阻塞 IO 更耗時(需平衡重試間隔、事件通知機制)。
3.4 適用 & 不適用場景
適用場景
- 高并發網絡編程:如 Web 服務器(Nginx 就大量用非阻塞 IO + 多路復用)、即時通訊(IM)、實時音視頻,需同時處理成千上萬個連接。
- 事件驅動架構:搭配
epoll/kqueue等機制,實現高效的 “事件循環”(如 Redis 單線程模型,靠非阻塞 IO + 事件驅動支撐高并發)。 - 需要 “邊等 IO 邊干活”:進程在等待數據時,還想處理其他任務(如后臺任務調度、定時任務)。
不適用場景
- 簡單低并發任務:如普通命令行工具、簡單文件讀寫,用阻塞 IO 更簡單,沒必要引入非阻塞的復雜度。
- 無法有效減少輪詢:若業務邏輯中,IO 就緒頻率極低,但又必須頻繁重試,非阻塞 IO 會因 “空轉輪詢” 浪費 CPU。
四、I/O復用(多路轉接)
4.1 概念
有了I/O復用(多路轉接),我們就可以調用select或poll或epoll,阻塞在這三個系統調用的某一個之上,而不是阻塞在真正的I/O系統調用上。
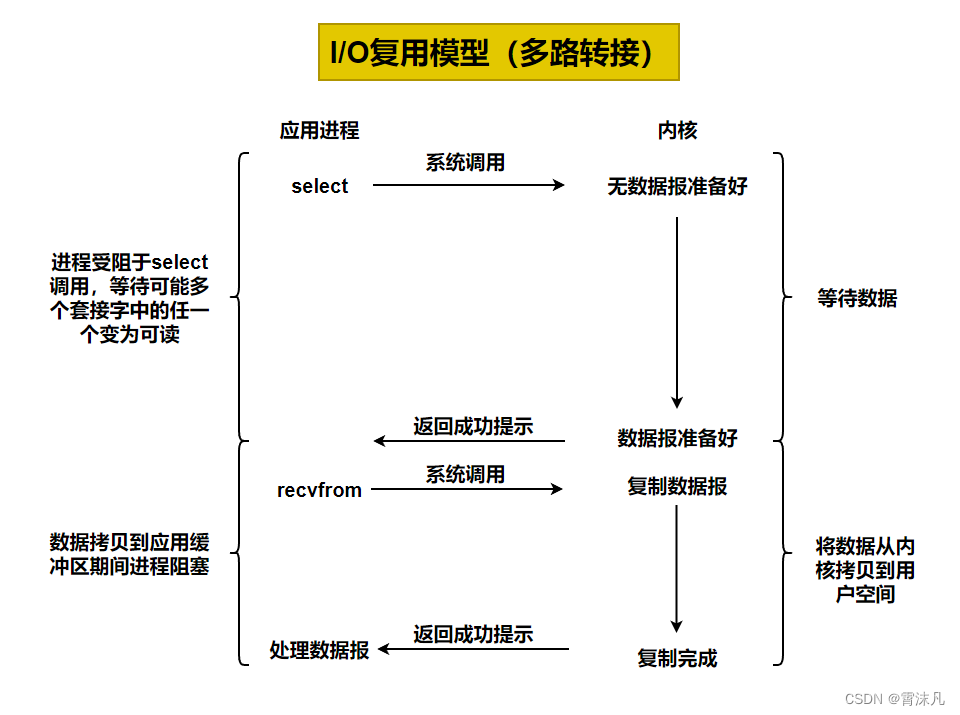
-
I/O 復用(I/O Multiplexing)是 Linux 中一種高效處理多連接的技術,也被稱為 “多路轉接”。它允許單個線程同時監控多個 I/O 事件源,當某個事件源就緒時,再進行相應處理。這種模型特別適合高并發場景,是現代高性能服務器(如 Nginx、Redis)的核心技術之一。
-
I/O 復用的本質是:使用一個線程 / 進程,通過系統調用(如select、poll、epoll)同時監聽多個文件描述符(如套接字、管道)的 I/O 事件,當有事件就緒時,再執行對應的處理邏輯。
常見的 I/O 事件包括:
- 可讀事件:文件描述符有數據可讀(如 TCP 連接收到數據)。
- 可寫事件:文件描述符可以寫入數據(如 TCP 緩沖區可寫入)。
- 異常事件:文件描述符發生錯誤(如連接斷開)。
4.2 工作流程
以網絡服務器為例,I/O 復用的典型流程:
- 創建監聽套接字:綁定端口并監聽連接請求。
- 注冊監聽事件:將監聽套接字和所有客戶端連接的套接字添加到復用器(如
select/poll/epoll)。 - 等待事件就緒:線程調用復用器的系統調用(如
select()),進入阻塞狀態,等待任意文件描述符就緒。 - 處理就緒事件:
- 若監聽套接字就緒 → 接受新連接并注冊到復用器。
- 若客戶端套接字就緒 → 讀取 / 寫入數據。
- 循環監聽:繼續等待下一批事件。
4.3 適用場景
- 高并發連接:如 Web 服務器(Nginx)、即時通訊(IM)、游戲服務器。
- 連接多但活躍少:例如 10 萬連接,但同時活躍的只有 1000 個,epoll優勢明顯。
- 單線程 / 進程處理多連接:避免創建大量線程導致的上下文切換開銷。
- 低延遲要求:通過事件驅動方式快速響應 IO 就緒事件。
五、信號驅動式I/O
5.1 概念
我們也可以用信號,讓內核在描述符就緒時發送SIGIO信號通知我們。我們稱這種模型為信號驅動式I/O模型。
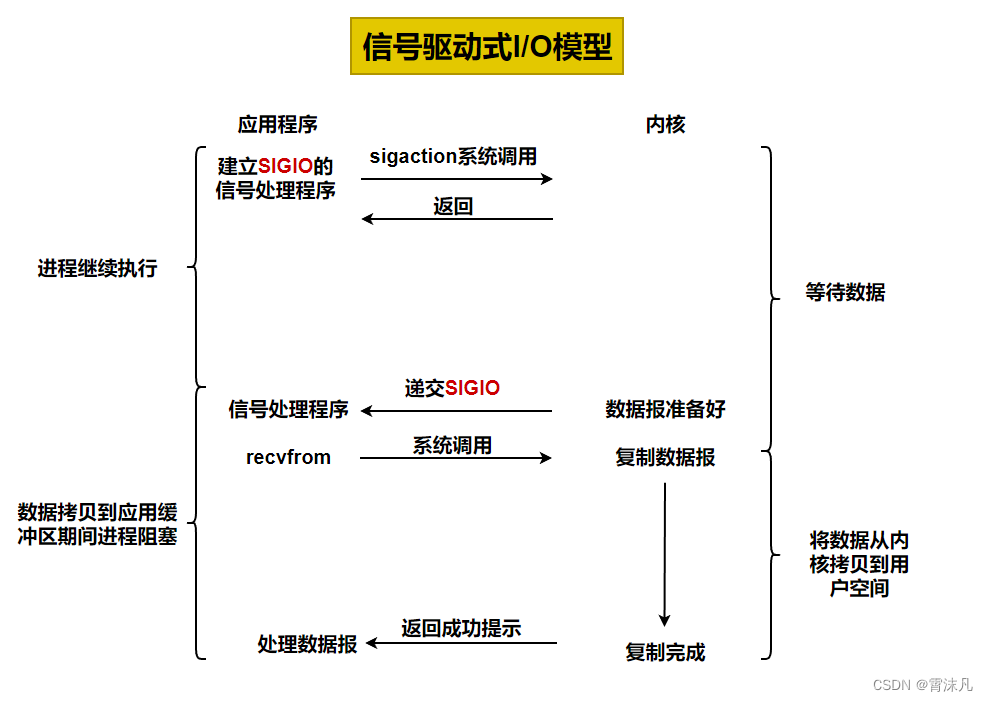
-
信號驅動式 I/O(Signal-Driven I/O)是 Linux 中一種異步通知機制,允許進程在 I/O 操作就緒時通過信號接收通知,而不必主動輪詢或阻塞等待。這種模型特別適合需要及時響應 I/O 事件但又不想阻塞主線程的場景。
-
信號驅動式 I/O 的本質是:進程預先向內核注冊一個信號處理函數,當特定的 I/O 事件發生時,內核通過發送信號(通常是SIGIO)通知進程,進程在信號處理函數中執行相應的 I/O 操作。
5.2 工作流程
以網絡套接字為例,信號驅動 I/O 的典型流程:
- 創建套接字并設置:創建套接字后,設置為非阻塞模式(通常配合使用)。
- 注冊信號處理函數:使用
signal()或sigaction()注冊SIGIO信號的處理函數。 - 設置進程為 I/O 的屬主:通過
fcntl()設置文件描述符的屬主進程,確保信號能正確發送到該進程。 - 啟用異步通知:通過
fcntl()設置FASYNC標志,開啟信號驅動模式。 - 繼續執行其他任務:進程可以繼續執行其他邏輯,無需阻塞等待 I/O。
- 接收信號并處理:當 I/O 事件就緒(如數據可讀)時,內核發送
SIGIO信號,進程在信號處理函數中執行 I/O 操作。
5.3 適用場景
- 需要及時響應 I/O 事件:如實時監控系統、網絡設備驅動程序。
- 不希望阻塞主線程:主程序需要繼續執行其他任務,I/O 事件通過信號異步通知。
- 連接數較少但需要異步處理:相比 I/O 復用,信號驅動 I/O 更適合連接數較少的場景。
- 硬件交互:與硬件設備(如串口、網卡)進行交互時,可通過信號驅動模式及時獲取數據。
5.4 優缺點
優點
- 異步通知:無需主動輪詢或阻塞等待,提高 CPU 利用率。
- 及時響應:I/O 事件發生時立即通過信號通知,延遲較低。
- 編程簡單:相比 I/O 復用,信號驅動 I/O 的實現更直觀,無需維護復雜的事件循環。
缺點
- 信號丟失風險:如果信號處理函數執行時間過長,可能會丟失后續信號。
- 信號處理限制:信號處理函數只能調用異步信號安全的函數,功能受限。
- 連接數限制:每個文件描述符都需要獨立的信號處理,不適合大量連接的場景。
- 平臺兼容性:在不同操作系統上實現可能有差異,Linux 和 BSD 系統支持較好。
六、異步I/O
6.1 概念
異步I/O的工作機制:告知內核啟動某個操作,并讓內核在整個操作(包括將數據從內核復制到我們自己的緩沖區)完成后通知我們。這種模型與信號驅動I/O模型的主要區別在于:信號驅動式I/O是有內核通知我們何時可以啟動一個I/O操作,而異步I/O模型是由內核通知我們I/O操作何時完成。
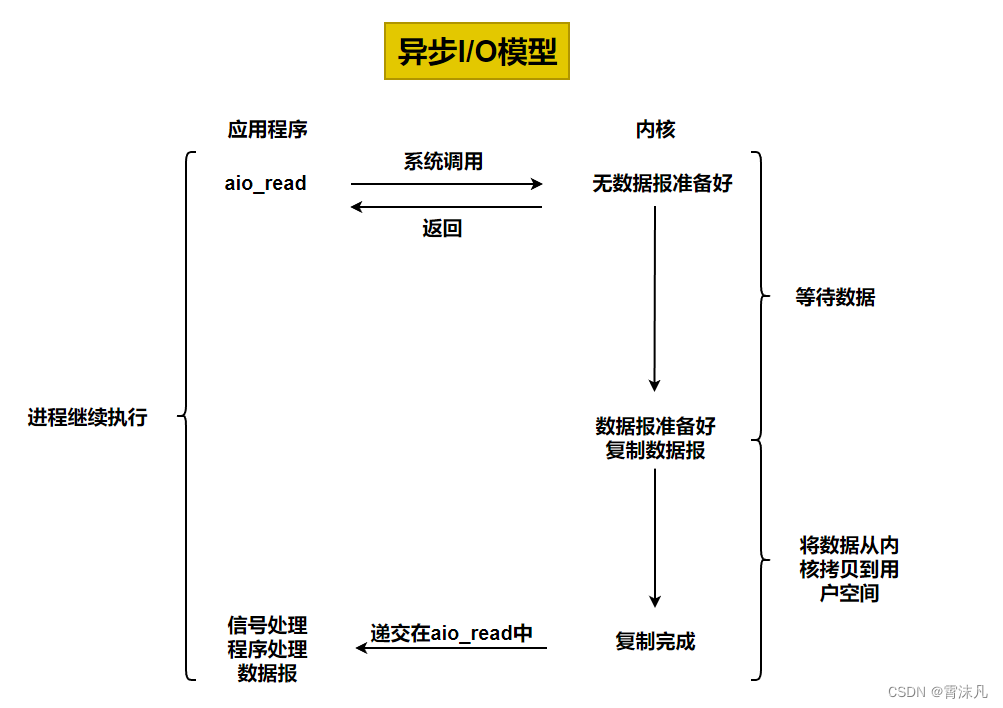
-
異步 I/O(Asynchronous I/O)是 Linux 中最高效的 I/O 模型,它允許進程在發起 I/O 操作后無需等待完成,繼續執行其他任務,內核會在 I/O 操作全部完成后通過回調或信號通知進程。這種模型特別適合需要處理大量并發 I/O 但對延遲要求極高的場景。
-
異步 I/O 的本質是:進程發起 I/O 操作后立即返回,內核在后臺完成數據讀寫,操作完成后通過回調函數或信號通知進程。整個過程中,進程無需阻塞或主動檢查 I/O 狀態。
6.2 工作流程
以文件讀取為例,異步 I/O 的典型流程:
- 準備 I/O 請求:進程創建異步 I/O 控制塊(如
struct aiocb),設置文件描述符、緩沖區、偏移量等參數。 - 提交請求:調用
aio_read()或aio_write()提交異步 I/O 請求,立即返回。 - 繼續執行其他任務:進程無需等待,可繼續執行其他邏輯。
- 內核處理 I/O:內核在后臺將數據從磁盤讀入用戶緩沖區(或從用戶緩沖區寫入磁盤)。
- 完成通知:I/O 操作完成后,內核通過以下方式通知進程:
- 發送信號(如
SIGIO或自定義信號)。 - 調用預先注冊的回調函數(通過
aio_suspend()等待)。
- 發送信號(如
- 處理結果:進程在信號處理函數或回調中檢查 I/O 結果。
6.3 優缺點
優點
- 最高性能:I/O 操作完全由內核異步處理,進程無需等待,CPU 利用率最大化。
- 低延遲:I/O 完成后立即通知進程,延遲最小。
- 資源高效:無需為每個 I/O 操作創建線程 / 進程,減少內存和 CPU 開銷。
- 真正的并行:計算任務和 I/O 操作可完全并行執行。
缺點
- 編程復雜:API 使用難度大,需要處理回調或信號,調試困難。
- 平臺兼容性差:不同操作系統實現差異大,POSIX AIO 在某些系統上性能不佳。
- 文件系統限制:Linux Native AIO 只支持特定文件系統(如 XFS)和直接 I/O(O_DIRECT)。
- 緩沖區對齊要求:使用直接 I/O 時,緩沖區必須按頁對齊,增加編程復雜度。
- 錯誤處理復雜:異步操作的錯誤處理和恢復機制更復雜。
適用場景
- 高性能存儲系統:如數據庫、文件系統,需要處理大量并發 I/O 請求。
- 實時數據處理:如流媒體服務器、金融交易系統,對延遲要求極高。
- 網絡代理 / 轉發:如高性能代理服務器、CDN 節點,需快速轉發數據。
- 多任務并行處理:應用程序需要同時執行計算任務和 I/O 操作。
- 對資源利用率要求高:避免創建大量線程 / 進程處理 I/O,減少上下文切換開銷。
七、五種I/O模型的比較
如下圖所示,前4種模型主要區別在于第一階段,因為他們第二階段都是一樣的:在數據從內核復制到調用者的緩沖區期間,進程阻塞于recvfrom調用。相反,異步I/O模型在這兩個階段都要處理,從而不同于其他4種模型。
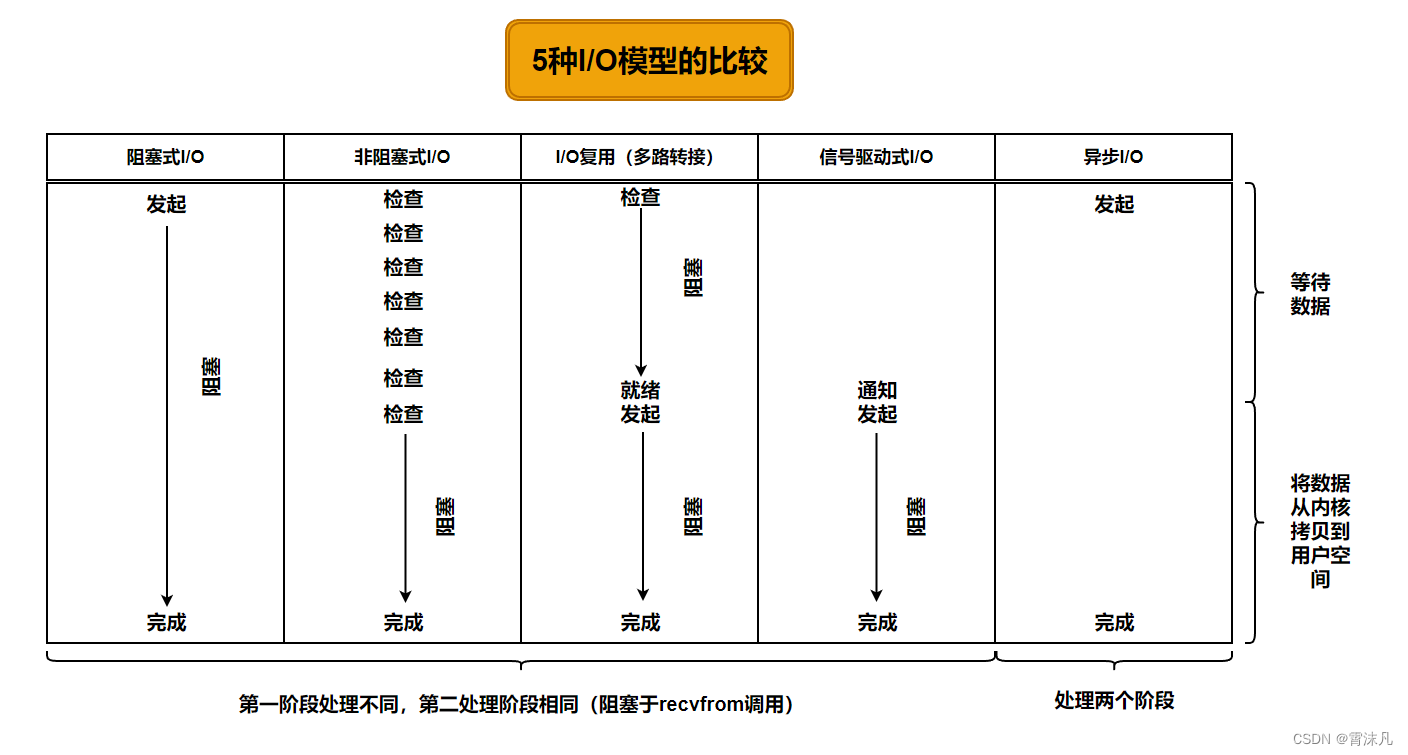
I/O和異步I/O的比較:
- 同步I/O: 導致請求進程阻塞,直到I/O操作完成;
- 異步I/O: 不導致請求進程阻塞;
簡單的講:就是是否參與了I/O操作
- 前四種I/O模型——阻塞式I/O模型、非阻塞式I/O模型、I/O復用(多路轉接)和信號驅動式I/O模型都是同步I/O,因為其中真正的I/O操作(recvfrom)將進程阻塞。只有異步I/O模型是異步I/O。
八、I/O復用典型使用在下列網絡應用場合
- 當客戶處理多個描述符時,必須使用I/O復用;
- 如果一個TCP服務器既要處理監聽套接字,又要處理已連接的套接字,一般就要使用I/O復用;
- 如果一個服務器既要處理TCP,又要處理UDP,一般就要使用I/O復用。
- 如果一個服務器要處理多個協議或多個服務,一般就需要使用I/O復用。
更多資料:https://github.com/0voice

入門與基礎使用)

框架)

)





 工具)

)
)
---gateway api)
)


