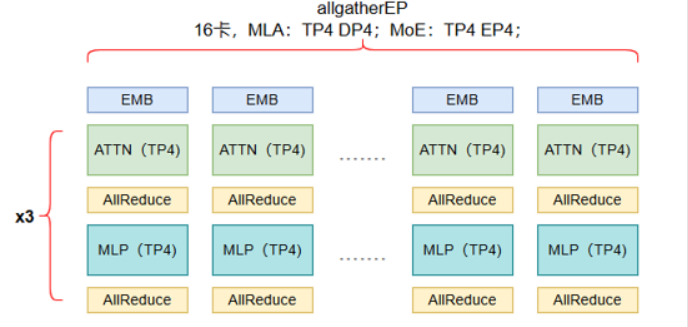

我們考慮一個典型的Transformer模型結構,在多層堆疊中,其中包含Attention層和MoE層(FeedForward層被替換為MoE層)。在模型最后是LM Head(語言模型頭),通常是一個全連接層,將隱層向量映射到詞表大小的輸出。
在您描述的配置中,MoE層采用allgatherEP模式,其輸出通過Reduce-Scatter操作得到分片輸出(每個TP組內,每張卡持有部分隱層維度)。而下一步的LM Head需要完整的隱層向量作為輸入。因此,在LM Head之前需要將分片的數據通過All-Gather操作聚合為完整向量。
具體流程如下:
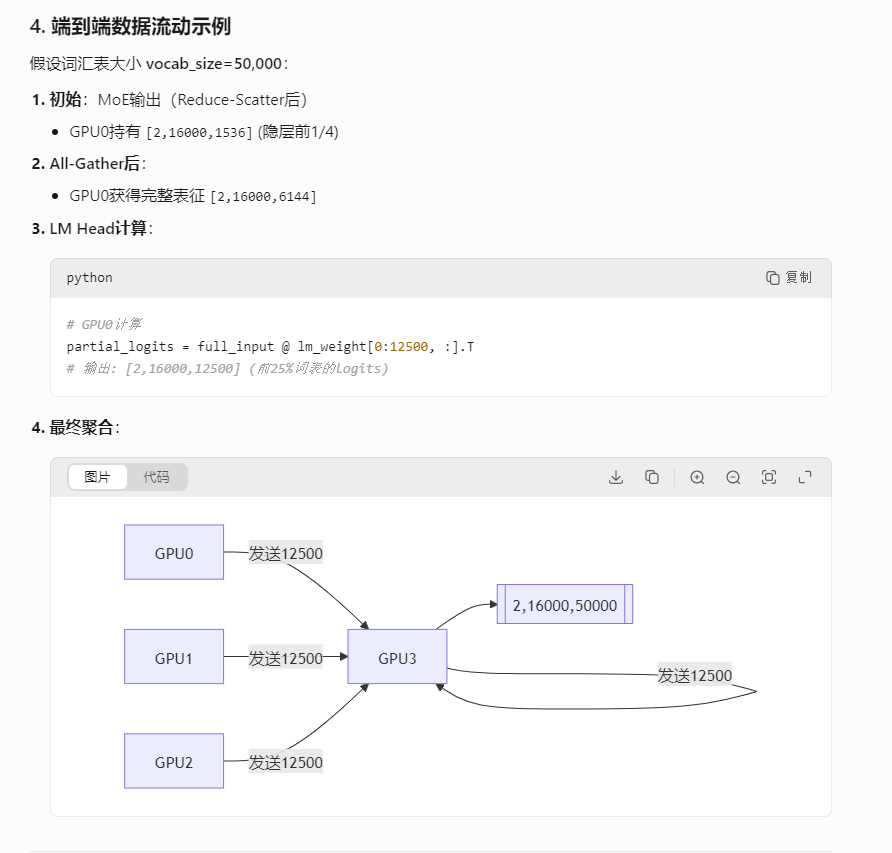
MoE層輸出(Reduce-Scatter之后):每張卡持有分片數據,形狀為 [batch_size, seq_len, hidden_size/TP_size]
例如:TP=4,hidden_size=6144,則每張卡持有 [batch_size, 16000, 1536]
為了進行LM Head計算(需要完整的隱層向量),在TP組內執行All-Gather操作:
將其他3張卡上的分片數據收集過來,每張卡都得到完整的隱層向量 [batch_size, 16000, 6144]
LM Head計算:
此時每張卡都擁有完整的輸出向量,可以獨立計算LM Head(一個線性層,權重形狀為 [vocab_size, hidden_size])。
但是,由于LM Head的計算量可能很大(特別是詞表很大時),通常也會采用張量并行(TP)來切分這個線性層。
LM Head的TP切分:
將LM Head的權重矩陣按列切分(即hidden維度切分),每張卡持有一部分權重:[vocab_size, hidden_size/TP_size]。
這樣,每張卡只需要計算自己的部分:logits_local = input_full @ weight_local.T,輸出形狀為 [batch_size, seq_len, vocab_size/TP_size]
然后,通過All-Gather(在vocab維度)將logits聚合為完整的詞表大小(也可以使用Reduce-Scatter,但一般為了后續的損失計算,需要每張卡都有完整的logits,所以用All-Gather):
每張卡收集其他卡計算的logits分片,得到完整的logits:[batch_size, seq_len, vocab_size]
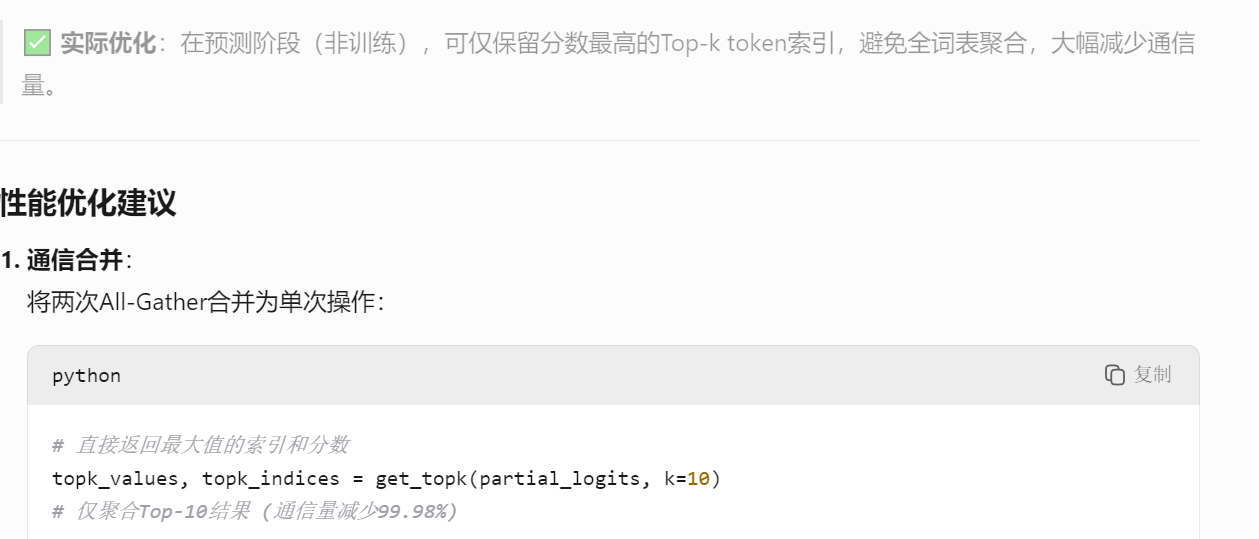
但是,這里有一個效率問題:在LM Head之前做了All-Gather得到完整隱層,而后面又進行了兩次通信(第一次是矩陣乘后的All-Gather,第二次是為了得到完整logits)。實際上,我們可以通過Gather操作合并來優化。
另一種常見的做法(如Megatron-LM的做法)是:避免在LM Head之前做All-Gather,而是直接利用分片的隱層和分片的權重計算,然后再進行All-Gather(在詞表維度聚合)。這樣就只需要一次All-Gather通信。
步驟:
MoE層輸出:分片隱層 [batch_size, seq_len, hidden_size/TP_size]
LM Head權重:每張卡持有 [vocab_size, hidden_size] 的列切分(每個分片大小為 [vocab_size, hidden_size/TP_size])
每張卡計算:logits_local = input_local @ weight_local.T 得到 [batch_size, seq_len, vocab_size] 的一部分(實際上是 [batch_size, seq_len, vocab_size] 在vocab維度上的一個分片?注意:矩陣乘法說明:input_local的隱層維度是hidden_size/TP,而weight_local.T的維度是 [hidden_size/TP_size, vocab_size],但這樣乘出來的結果是 [batch_size, seq_len, vocab_size],但是注意,這個結果是不完整的,因為輸入只是部分隱層。因此需要將各個卡的結果相加(Reduce-Sum)才能得到完整的logits。
因此,正確的做法是:
在計算完本地矩陣乘之后,需要進行一次All-Reduce(Sum)操作,將各個卡上的部分logits相加,得到完整的logits。但這里因為輸入本身就是分片的,所以需要All-Reduce。但是,這種做法在Megatron中只適用于無并行的線性層。在LM Head中,如果權重按列切分(即每張卡持有部分權重),那么每個分片權重與輸入分片相乘只能得到部分結果,而完整的結果需要將各個部分加起來(即沿著hidden維度拆分,然后結果相加)。
因此,LM Head的計算應該是:
輸入:X (每張卡上 [batch_size, seq_len, hidden_size/TP_size])
權重:W (每張卡上 [vocab_size, hidden_size/TP_size])
計算:local_logits = X @ W.T 得到 [batch_size, seq_len, vocab_size],但這個結果只是部分結果(因為是隱層分片和權重分片相乘)
然后,需要All-Reduce(Sum)操作:將各個卡上的local_logits相加,得到完整的logits。
然而,在MoE之后,如果我們不進行All-Gather(還原完整隱層),那么LM Head就要在分片隱層的基礎上計算,然后通過All-Reduce來聚合。這樣通信量是多少呢?
通信量 = batch_size * seq_len * vocab_size * sizeof(float)
這通常很大,因為vocab_size很大(幾萬到幾十萬)。例如,batch_size=1, seq_len=16000, vocab_size=50000, 則通信量=1 * 16000 * 50000 * 4字節=3.2GB,這比之前All-Gather的通信量(1 * 16000 * 6144 * 2字節≈196MB)大得多。
因此,更高效的做法是:
在MoE輸出后,使用All-Gather恢復完整隱層(每張卡得到 [batch, seq, hidden],通信量是 (TP_size-1)/TP_size * hidden_size * …,也就是上面提到的377MB左右,對于TP=4,每個分片1536,All-Gather需要發送3個1536的分片,所以輸入數據量是 3 * (batch_size * seq_len * 1536),以batch=2, seq=16000為例:3 * 2 * 16000 * 1536 * 2字節(fp16)≈ 2.25GB(注意這是總發送數據量,在NCCL中,All-Gather會將這些數據分發到其他卡,所以每卡接收3塊數據,共約2.25GB,但現代GPU卡間帶寬高,如NVLink 600GB/s,實際時間很短)
然后,使用TP切分權重計算LM Head(不需要立即做All-Gather)。但注意,由于我們已經All-Gather得到了完整隱層,那么我們可以將LM Head的權重按行切分(即切分vocab維度)。這樣每張卡計算一部分詞表的logits。
然后,再使用All-Gather將各個卡上分詞的logits收集起來,得到完整的logits。
第二步的通信量:All-Gather聚合logits,通信量為:batch_size * seq_len * vocab_size * (TP_size-1)/TP_size * sizeof(float)
例如:batch=2, seq=16000, vocab=50000, TP=4,則通信量 = 2 * 16000 * 50000 * 3/4 * 4字節≈4.8GB(按float32計算,如果用float16則減半)。這依然很大。
所以,為了減少通信量,另一種策略是將LM Head的權重切分到不同的數據并行組(DP)中,只在一個設備上計算整個LM Head(不并行),但這樣會引入計算瓶頸。
或者,我們可以不進行第二次All-Gather,而是在后續的損失計算中進行優化。但是,損失計算(交叉熵)通常需要完整的logits。
實際上,我們觀察到,在Megatron-LM中,對于LM Head,他們采用了以下兩種方式之一:
A. 不切分LM Head(權重復制),在計算之前通過All-Gather得到完整隱層(這樣每張卡有完整隱層),然后每張卡獨立計算整個LM Head(權重復制,所以輸出也是完整的logits)。這樣避免了第二步的All-Gather,但每張卡都存儲了整個詞表(可能很大)且計算了完整的矩陣乘法(計算量大,但并行度高)。
B. 將LM Head用張量并行切分(按hidden維度切分權重),然后通過All-Reduce得到完整的logits(如上所述)。但這種方法在詞表大時通信量很大。
由于詞表很大(如50k),All-Reduce的通信量甚至比All-Gather隱層還要大,因此實際中更常見的是使用All-Gather隱層的方式(即先將隱層收集完整),然后每張卡獨立計算整個LM Head(需要每張卡都存儲完整的LM Head權重)。
但是,這需要每張卡都有足夠的顯存放得下整個LM Head(詞表大小×隱層大小×2字節(fp16))。例如50k×6144×2≈600MB,這可以接受。
因此,推薦做法:
MoE層輸出后,在TP組內通過All-Gather得到完整隱層(每張卡都有 [batch, seq, hidden])。
然后,LM Head(一個線性層)的權重在每張卡上都是完整的(通過DP組廣播,每個DP組內的卡都有相同的權重副本)。
每張卡獨立計算:logits = hidden_full @ lm_head_weight.T,得到 [batch, seq, vocab]。
這樣避免了LM Head的并行通信,但增加了顯存占用(存儲完整LM Head權重)和計算量(每張卡都計算整個矩陣乘法)。然而,計算方面實際上通過數據并行分攤了(因為batch切分在數據并行組內,但實際上在TP組內也是完整batch?注意,TP組內的batch是完整的,因為前面All-Gather已經得到完整隱層,而每個TP組計算的是整個batch?)
澄清:我們的并行方式包括DP(數據并行)和TP(張量并行)。在TP組內,每個TP組處理一個數據并行分片(batch的一部分)。所以,在TP組內,All-Gather之后的隱層是該TP組負責的那部分batch(batch_size/DP_size)的完整隱層。然后,在TP組內每張卡計算完整的LM Head(對這部分batch)。
因此,總計算量:每個TP組獨立計算batch_size/DP_size個樣本的整個LM Head。
這樣,LM Head的計算在多個TP組之間是數據并行的(每個組算一部分batch)。
所以,這個方案是可行的,并且沒有額外的通信。
總結流程:
在注意力層:使用TP=4(和DP=4)計算。
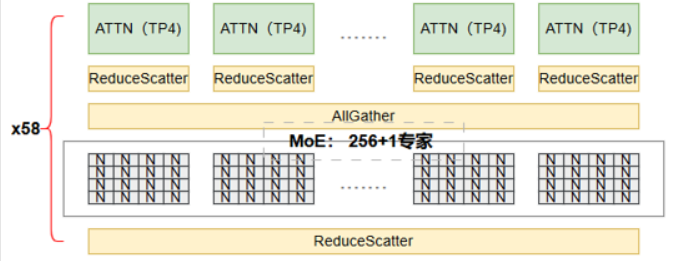
MoE層:使用TP=4和EP=4(allgatherEP模式),輸出通過Reduce-Scatter得到分片隱層(每個卡持有部分隱層)。
為了進入后續層(比如下一層可能是Attention層)需要完整隱層?但這里是進入LM Head。
但是,在模型結構上,通常MoE層后面可能還有層(如另一個Attention層),但最后才是LM Head。在您的配置中,可能MoE層是最后一層專家層,然后輸出到LM Head。
因此,如果后面是LM Head,那么:
Step1: MoE層輸出(Reduce-Scatter后) -> 每張卡有 [batch, seq, hidden/TP]
Step2: 執行All-Gather(在TP組內)得到完整的隱層 [batch, seq, hidden](注意,這個batch是當前DP分片,即batch/DP_size)
Step3: 將完整隱層輸入到LM Head(每張卡都有完整的LM Head權重,獨立計算)
Step4: 得到logits [batch, seq, vocab],然后計算損失(在數據并行組內需要聚合損失?或者直接在每個設備上計算自己部分batch的損失,然后梯度聚合時自然合并)
注意:損失計算不需要跨設備通信,因為每個設備只計算自己部分batch的損失(標簽也是分片的),最后梯度聚合在數據并行組內進行(只對模型參數梯度,損失值本身不需要聚合)。
所以,在MoE層后到LM Head之間,需要一次All-Gather(在TP組內)來恢復完整隱層,然后直接計算LM Head。
這個All-Gather操作是必要的。
如果您不想做這次All-Gather,另一種方法是:將LM Head的TP計算與前面的MoE層的TP輸出分片對齊(按隱層維度切分),然后通過All-Reduce(Sum)來聚合logits。但是,如上所述,All-Reduce的通信量很大(因為詞表大),所以通常不采用。
結論:在您的配置下,MoE層后進入LM Head之前,需要一次All-Gather(在TP組內)來恢復完整隱層。
這也就是為什么您的問題描述中說“然后進入下一步采用all gather”的原因。




)
---gateway api)
)








)




vue3中的pinia狀態管理、組件通信方式及總結、插槽)


)