隨著汽車成為人們日常生活中不可或缺的一部分,而駕駛艙中傳統的觸摸交互方式容易分散駕駛員的注意力,存在安全風險,因此,車內基于語音的交互方式得到重視。與通常家庭或會議場景中的語音識別系統不同,駕駛場景中的系統面臨更加獨特的挑戰,缺乏大規模的公共真實車內數據一直是該領域發展的主要障礙。AISHELL-5是首個開源的真實車載多通道、多說話人中文自動語音識別(ASR)高質量數據集。AISHELL-5的開源加速了智能駕艙內語音交互的相關技術研究,并且希爾貝殼聯合西工大音頻語音與語言處理研究組(ASLP@NPU)、理想汽車發布的AISHELL-5論文成功入選INTERSPEECH2025國際會議,以下是AISHELL-5數據集的相關介紹。

數據地址:https://www.aishelltech.com/AISHELL_5


-
論文地址:https://arxiv.org/pdf/2505.23036
-
GitHub:https://github.com/DaiYvhang/AISHELL-5
數據說明
AISHELL-5?共計893.7小時,單通道145.25小時。邀請165名錄音人,在真實車內,涉及60+車載場景下錄制。錄音內容包含對話(706.59H)和噪聲(187.11H)兩類。拾音點位共計5個:近講為頭戴麥克風(采樣率:16kHz,16bit,數據量:215.63H),遠講為駕艙內麥克風(采樣率:16kHz,16bit,數據量:490.96H,拾音位:4個音位)。噪聲采集由駕艙內麥克風(采樣率:16kHz,16bit,數據量:187.11H,拾音位:4個音位)錄制。
錄制場景示意圖:
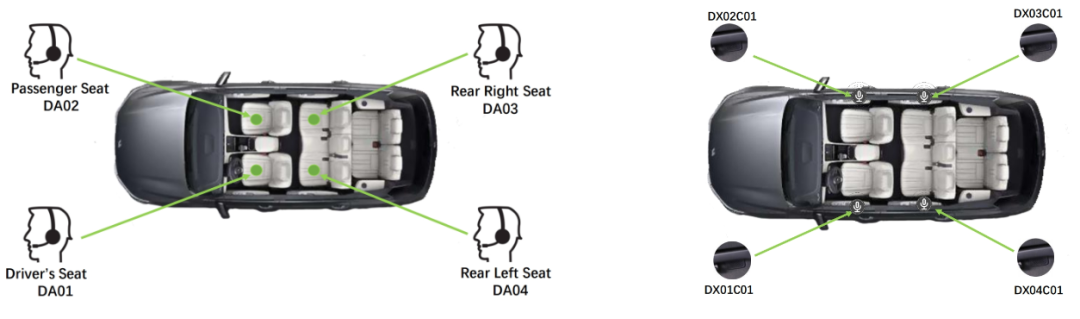
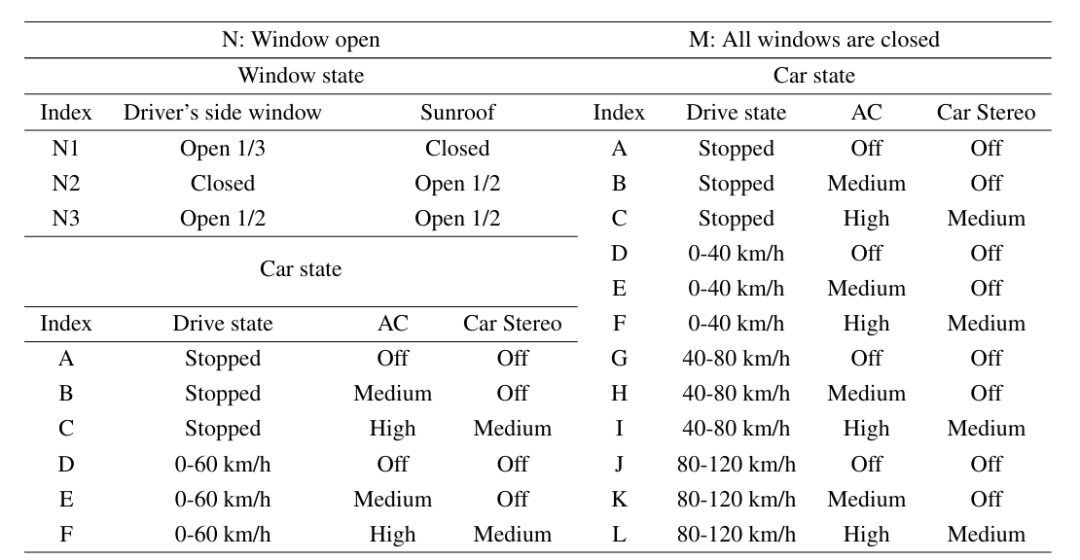
錄制環境設計信息:
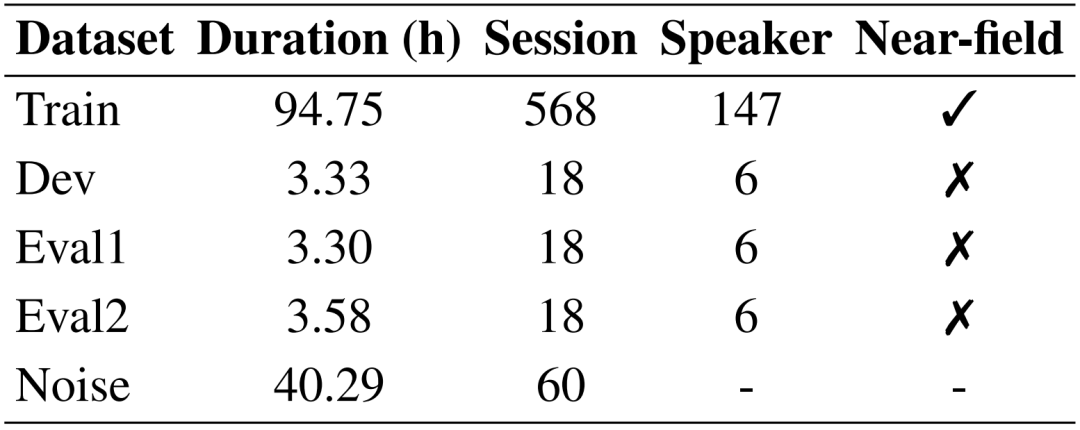
實驗數據分配如下:
? ??
試驗說明
我們提供了基于該數據集構建的一套開源基線系統。該系統包括一個語音前端模型,利用語音源分離技術從遠場信號中提取出每位說話人的清晰語音,以及一個語音識別模塊,用于準確轉寫每位說話人的語音內容。
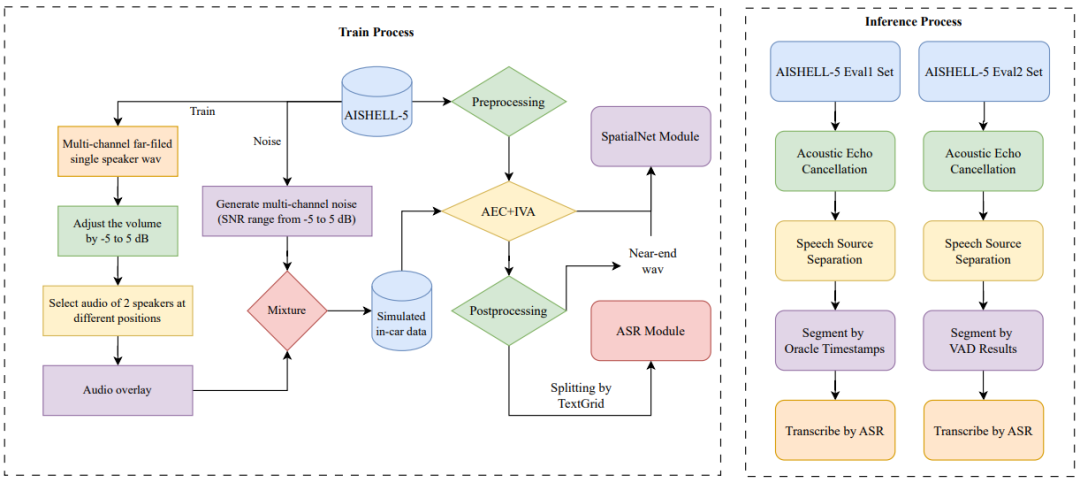
系統實驗結果:
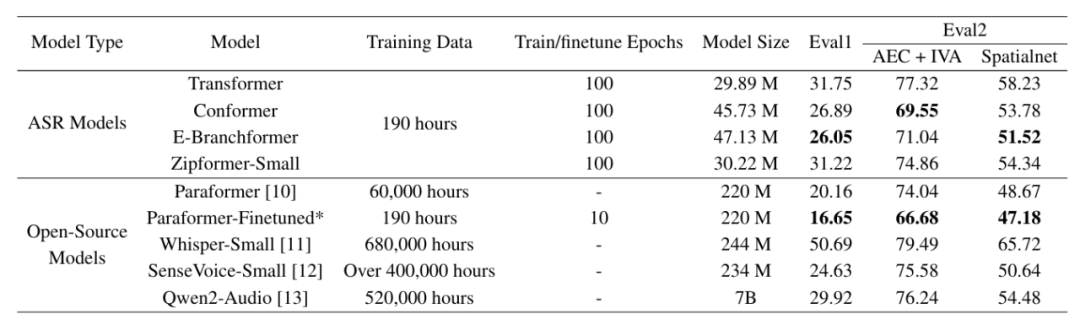
實驗結果展示了多種主流ASR 模型在 AISHELL-5 數據集上面臨的挑戰。AISHELL-5 數據的開源能夠推動智駕領域復雜駕艙場景下的語音技術研究。
)





 工具)

)
)
---gateway api)
)







