在自然語言處理領域,預訓練語言模型(如BERT、GPT、T5)已成為基礎設施。但如何讓這些“通才”模型蛻變為特定任務的“專家”?微調策略正是關鍵所在。本文將深入剖析七種核心微調技術及其演進邏輯。
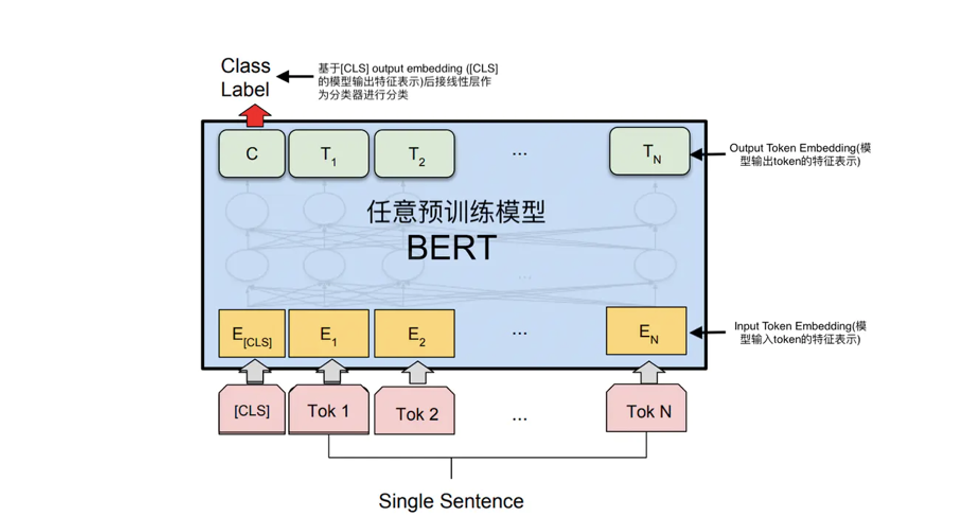
一、基礎概念:為什么需要微調?
預訓練模型在海量語料上學習了通用語言表征(詞義、語法、淺層語義),但其知識是領域無關的。例如:
-
醫學文本中的“陽性”與日常用語含義不同
-
金融領域的“多頭”非指動物頭部
-
法律文本的特殊句式結構
微調的本質:在預訓練知識基礎上,通過特定領域數據調整模型參數,使其適應下游任務,如文本分類、實體識別、問答系統等。
二、經典策略:全參數微調(Full Fine-tuning)
工作原理:解凍整個模型,在任務數據上更新所有權重
# PyTorch典型實現
model = B

)


函數解析)


)


)
:Docker與K8S部署的區別)






- 適用于算法競賽(如 CCF CSP、藍橋杯、NOI))