TensorFlow深度學習實戰(20)——自組織映射詳解
- 0. 前言
- 1. 自組織映射原理
- 2. 自組織映射的優缺點
- 3. 使用自組織映射實現顏色映射
- 小結
- 系列鏈接
0. 前言
自組織映射 (Self-Organizing Map, SOM) 是一種無監督學習算法,主要用于高維數據的降維、可視化和聚類分析,廣泛應用于數據挖掘、模式識別、圖像處理等領域。
1. 自組織映射原理
K-means 和主成分分析 (Principal Component Analysis, PCA) 都可以對輸入數據進行聚類,但它們不保持拓撲關系。在本節中,我們將介紹自組織映射 (Self-Organizing Map, SOM),也稱 Kohonen 網絡,或 WTU (Winner-Take-All Unit),由 Teuvo Kohonen 于 1982 年提出,這類方法能夠保持拓撲關系。SOM 是一種非常特殊的神經網絡,受到人腦一個獨特特征的啟發,在人類大腦中,不同的感官輸入以拓撲順序的方式表示。與其他神經網絡不同,神經元之間不是通過權重連接在一起,而是相互影響學習。SOM 最重要的是,神經元以拓撲方式表示學習到的輸入。
在 SOM 中,神經元通常放置在( 1D 或 2D )網格的節點上。雖然也可以使用更高維度,但在實踐中很少使用。網格中的每個神經元通過權重矩陣連接到所有輸入單元。下圖展示了一個具有 6 × 8 (48 個)神經元和 5 個輸入的 SOM。在這種情況下,每個神經元將有 5 個元素,從而形成一個大小為 48 × 5 的權重矩陣:

自組織映射 (Self-Organizing Map, SOM) 通過競爭學習來學習,可以視為 PCA 的非線性推廣,因此,像主成分分析 (Principal Component Analysis, PCA) 一樣,也可以用于降維。
為了實現 SOM,首先需要了解它的工作原理。第一步是將網絡的權重初始化為隨機值或從輸入中隨機抽樣。每個占據網格空間的神經元將被分配特定的位置,與輸入距離最小的神經元稱為獲勝神經元 (Best Matching Unit, BMU),通過測量所有神經元的權重向量 W W W 與輸入向量 X X X 之間的距離實現:
d j = ∑ i = 1 N ( W i j ? X i ) 2 d_j=\sqrt{\sum_{i=1}^N(W_{ij}-X_i)^2} dj?=i=1∑N?(Wij??Xi?)2?
其中, d j d_j dj? 是神經元 j j j 的權重與輸入 X X X 之間的距離,具有最低 d d d 值的神經元是獲勝神經元。
接下來,調整勝者神經元及其鄰近神經元的權重,以確保如果下一次輸入相同,同一神經元仍然是獲勝神經元。
為了決定哪些鄰近神經元需要修改,網絡使用鄰域函數 ∨ ) ( r ) \vee )(r) ∨)(r),通常使用以下鄰域函數:
∨ ( r ) = e ? d 2 2 σ 2 \vee (r)=e^{-\frac {d^2}{2\sigma^2}} ∨(r)=e?2σ2d2?
其中, σ \sigma σ 是神經元影響范圍的時間依賴半徑, d d d 是它與獲勝神經元的距離,函數圖像如下所示。

鄰域函數的另一個重要特性是其半徑會隨著時間減少。因此,在開始時,許多鄰近神經元的權重會修改,但隨著網絡的學習,最終只有少數神經元的權重(有時是一個或沒有)在學習過程中修改。
權重的變化根據以下方程:
d W = η ∧ ( X ? W ) dW=\eta \wedge(X-W) dW=η∧(X?W)
對所有輸入重復迭代以上過程。隨著迭代的進行,根據迭代次數逐漸降低學習率和半徑。
2. 自組織映射的優缺點
自組織映射 (Self-Organizing Map, SOM) 的計算成本較高,因此對于較大的數據集并不實用。但它們易于理解,并且能夠很好地發現輸入數據之間的相似性。因此,SOM 被廣泛應用于圖像分割和在自然語言處理中確定詞匯相似性映射。
具體而言,SOM 具有以下優勢
- 無監督學習:
SOM是一種無監督學習算法,可以在沒有標簽的情況下進行數據分析和模式識別 - 能夠處理高維數據:
SOM能夠將高維數據映射到低維空間,從而幫助我們更好地理解和可視化高維數據 - 數據聚類與模式識別:
SOM可以將相似的數據點映射到網格中相鄰的位置,從而實現數據的聚類。由于SOM保持了輸入數據的拓撲結構,相似的輸入數據會被映射到網格中相鄰的節點,這使得它在模式識別、異常檢測等任務中有著較好的表現 - 自適應性:
SOM在訓練過程中能夠根據輸入數據的分布情況自適應地調整模型結構,能夠有效地識別出數據中的重要模式
SOM 的缺點如下:
- 計算復雜度高:
SOM的訓練過程需要對每一個輸入數據點計算與所有神經元的距離,這使得它在大規模數據集上訓練時計算量較大,訓練時間較長,尤其是對于高維數據 - 對初始化敏感:
SOM的性能對初始化有一定的依賴,如果初始化的權重分布不合理,可能導致訓練結果不理想 - 容易陷入局部最優:
SOM的訓練算法具有局部更新的特性,容易陷入局部最優解,尤其是在數據特征復雜或者維度較高時,可能會導致學習過程無法收斂到最優解 - 對噪聲敏感:
SOM對數據中的噪聲較為敏感,噪聲數據可能會導致訓練結果失真,從而影響映射效果
3. 使用自組織映射實現顏色映射
自組織映射 (Self-Organizing Map, SOM) 生成的輸入空間特征圖具有一些有趣的屬性:
- 特征圖提供了輸入空間的良好表示,這一屬性可以用于向量量化,從而可以將一個連續的輸入空間用SOM表示為一個離散的輸出空間
- 特征圖是拓撲有序的,即輸出網格中神經元的空間位置對應于輸入的特定特征
- 特征圖還反映了輸入空間的統計分布;具有最多輸入樣本的區域在特征圖中占據較大的面積
SOM 的這些特性使其具有許多有趣的應用。在本節中,使用 SOM 將給定的紅 (Red, R)、綠 (Green, G) 和藍 (Blue, B) 像素值聚類到相應的顏色圖中。
(1) 首先導入所需的模塊:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import time
(2) 定義 WTU 類。__init__ 函數初始化了 SOM 的各種超參數,包括 2D 網格的維度 (m, n)、輸入特征的數量 dim、鄰域半徑 sigma、初始權重以及拓撲信息:
# Define the Winner Take All units
class WTU(object):def __init__(self, m, n, dim, num_iterations, eta = 0.5, sigma = None):self._m = mself._n = nself._neighbourhood = []self._topography = []self._num_iterations = int(num_iterations) self._learned = Falseself.dim = dimself.eta = float(eta)if sigma is None:sigma = max(m,n)/2.0 # Constant radiuselse:sigma = float(sigma)self.sigma = sigmaprint('Network created with dimensions',m,n)# Weight Matrix and the topography of neuronsself._W = tf.random.normal([m*n, dim], seed = 0)self._topography = np.array(list(self._neuron_location(m, n)))
WTU 類最重要的函數是 training() 函數,使用 Kohonen 算法找到獲勝神經元,并根據鄰域函數更新權重:
def training(self,x, i):m = self._mn= self._n # Finding the Winner and its locationd = tf.sqrt(tf.reduce_sum(tf.pow(self._W - tf.stack([x for i in range(m*n)]),2),1))self.WTU_idx = tf.argmin(d,0)slice_start = tf.pad(tf.reshape(self.WTU_idx, [1]),np.array([[0,1]]))self.WTU_loc = tf.reshape(tf.slice(self._topography, slice_start,[1,2]), [2])# Change learning rate and radius as a function of iterationslearning_rate = 1 - i/self._num_iterations_eta_new = self.eta * learning_rate_sigma_new = self.sigma * learning_rate# Calculating Neighbourhood functiondistance_square = tf.reduce_sum(tf.pow(tf.subtract(self._topography, tf.stack([self.WTU_loc for i in range(m * n)])), 2), 1)neighbourhood_func = tf.exp(tf.negative(tf.math.divide(tf.cast(distance_square, "float32"), tf.pow(_sigma_new, 2))))# multiply learning rate with neighbourhood funceta_into_Gamma = tf.multiply(_eta_new, neighbourhood_func)# Shape it so that it can be multiplied to calculate dWweight_multiplier = tf.stack([tf.tile(tf.slice(eta_into_Gamma, np.array([i]), np.array([1])), [self.dim])for i in range(m * n)])delta_W = tf.multiply(weight_multiplier,tf.subtract(tf.stack([x for i in range(m * n)]),self._W))new_W = self._W + delta_Wself._W = new_W
fit() 函數是一個輔助函數,調用 training() 函數并存儲質心網格以便于檢索:
def fit(self, X):for i in range(self._num_iterations):for x in X:self.training(x,i)# Store a centroid grid for easy retrievalcentroid_grid = [[] for i in range(self._m)]self._Wts = list(self._W)self._locations = list(self._topography)for i, loc in enumerate(self._locations):centroid_grid[loc[0]].append(self._Wts[i])self._centroid_grid = centroid_gridself._learned = True
然后,定義一些輔助函數用于找到獲勝神經元并生成 2D 神經元網格,以及一個將輸入向量映射到 2D 網格中相應神經元的函數:
def winner(self, x):idx = self.WTU_idx,self.WTU_locreturn idxdef _neuron_location(self,m,n):for i in range(m):for j in range(n):yield np.array([i,j])def get_centroids(self):if not self._learned:raise ValueError("SOM not trained yet")return self._centroid_griddef map_vects(self, X):if not self._learned:raise ValueError("SOM not trained yet")to_return = []for vect in X:min_index = min([i for i in range(len(self._Wts))],key=lambda x: np.linalg.norm(vect - self._Wts[x]))to_return.append(self._locations[min_index])return to_return
(3) 定義函數 normalize() 用于對輸入數據進行歸一化:
def normalize(df):result = df.copy()for feature_name in df.columns:max_value = df[feature_name].max()min_value = df[feature_name].min()result[feature_name] = (df[feature_name] - min_value) / (max_value - min_value)return result.astype(np.float32)
(4) 讀取數據 colors.csv,對其進行歸一化,數據包含不同顏色的紅、綠和藍通道值:
import pandas as pddf = pd.read_csv('colors.csv') # The last column of data file is a label
data = normalize(df[['R', 'G', 'B']]).values
name = df['Color-Name'].values
n_dim = len(df.columns) - 1# Data for Training
colors = data
color_names = name
(5) 接下來,創建 SOM 并進行訓練:
t = time.time()
som = WTU(30, 30, n_dim, 400, sigma=10.0)
som.fit(colors)
s = time.time() - t
print(s)
# 3820.9206821918488
(6) fit() 函數運行時間稍長,訓練完成后,查看模型訓練結果:
# Get output grid
image_grid = som.get_centroids()# Map colours to their closest neurons
mapped = som.map_vects(colors)# Plot
plt.imshow(image_grid)
plt.title('Color Grid SOM')
for i, m in enumerate(mapped):plt.text(m[1], m[0], color_names[i], ha='center', va='center',bbox=dict(facecolor='white', alpha=0.5, lw=0))
plt.show()idx, loc = som.winner([0.5, 0.5, 0.5])
print(idx, loc)
可以在 2D 神經元網格中看到顏色映射:
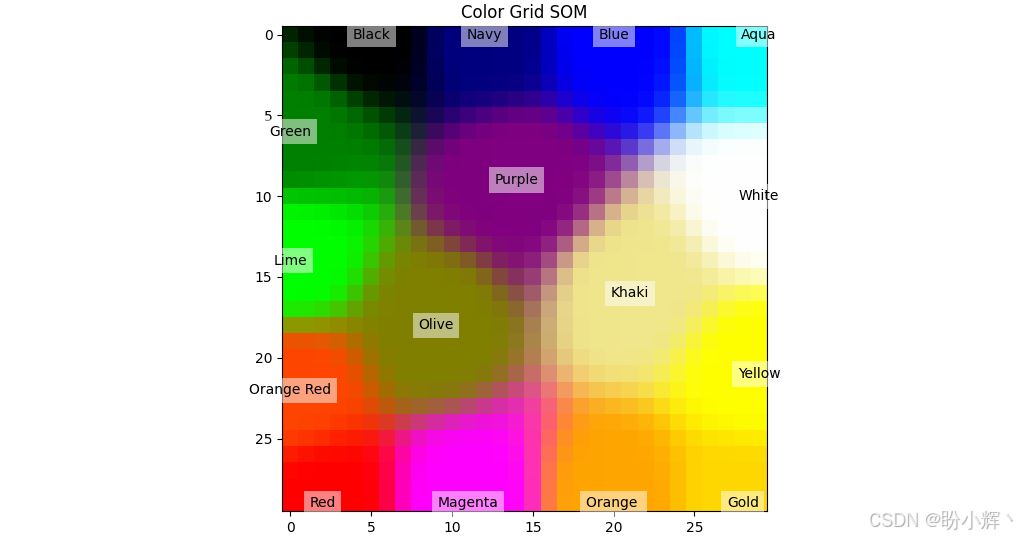
可以看到,類似顏色的獲勝神經元彼此靠近。
小結
自組織映射 (Self-Organizing Map, SOM) 是一種無監督學習算法,廣泛用于數據的降維、聚類、模式識別等任務。它通過將高維數據映射到低維的網格上,使得相似的樣本數據在網格中相鄰。
系列鏈接
TensorFlow深度學習實戰(1)——神經網絡與模型訓練過程詳解
TensorFlow深度學習實戰(2)——使用TensorFlow構建神經網絡
TensorFlow深度學習實戰(3)——深度學習中常用激活函數詳解
TensorFlow深度學習實戰(4)——正則化技術詳解
TensorFlow深度學習實戰(5)——神經網絡性能優化技術詳解
TensorFlow深度學習實戰(6)——回歸分析詳解
TensorFlow深度學習實戰(7)——分類任務詳解
TensorFlow深度學習實戰(8)——卷積神經網絡
TensorFlow深度學習實戰(9)——構建VGG模型實現圖像分類
TensorFlow深度學習實戰(10)——遷移學習詳解
TensorFlow深度學習實戰(11)——風格遷移詳解
TensorFlow深度學習實戰(12)——詞嵌入技術詳解
TensorFlow深度學習實戰(13)——神經嵌入詳解
TensorFlow深度學習實戰(14)——循環神經網絡詳解
TensorFlow深度學習實戰(15)——編碼器-解碼器架構
TensorFlow深度學習實戰(16)——注意力機制詳解
TensorFlow深度學習實戰(17)——主成分分析詳解
TensorFlow深度學習實戰(18)——K-means 聚類詳解
TensorFlow深度學習實戰(19)——受限玻爾茲曼機






企業級安全方案設計 - 多因素認證(MFA)實現)




Monitor/自旋/輕量級/鎖膨脹/wait/notify/鎖消除)

進行兩臺電腦的串口通訊)





