引子
前文寫到RagFlow的環境搭建&推理測試,感興趣的童鞋可以移步(RagFlow環境搭建&推理測試-CSDN博客)。前文也寫過RagFLow參數配置&測試的文檔,詳見(RagFlow環境搭建&推理測試-CSDN博客)。很少寫關于具體代碼的blog,這個不涉密,OK,那我們開始吧。
一、RagFlow檢索優化--ES替換為Infitity
在上一篇文章中,我嘗試新建了兩個知識庫,一個知識庫中有兩個文檔,其中一個比較大,另外一個知識庫上傳的時QA對的excel表格。我在聊天設置中選擇了兩個知識庫,我提出文檔,到得到答案差不多要3mins,這個。。。呃,需要排查下。那我們就采用控制變量法來找到問題原因吧,既然時兩個知識庫,那我們先刪除一個QA對知識庫。。。好家伙,提出一個問題,依然需要3mins才出答案。那我們繼續,剩下的一個知識庫中兩個文檔,那我們先禁用一個長的文檔,來看看效果。呃。。時間略快一點,還是要2mins。
根據上一篇博客里所講,我這里選擇了reranker模型,那么在混合查詢中的向量相似度部分將被rerank打分代替。那就去掉rerank,我們再測試下,emm 。。。時間略有縮短,可以看到顯示搜索中這個過程十分耗時。當然有可能是我的機器配置比較差的緣故,但進一步分析,目前設置是使用關鍵詞相似度與向量余弦相似度相結合的混合查詢方式。采用的是ES數據庫的查詢結果計算的。
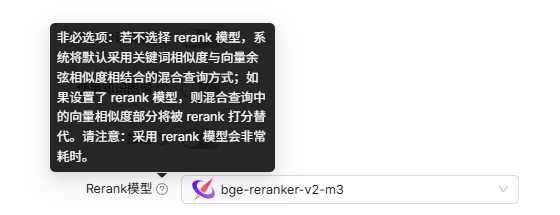
剛好看到RagFlow中配置文檔中有替換Infinity的部分,那就先來了解下Infinity到底是什么。
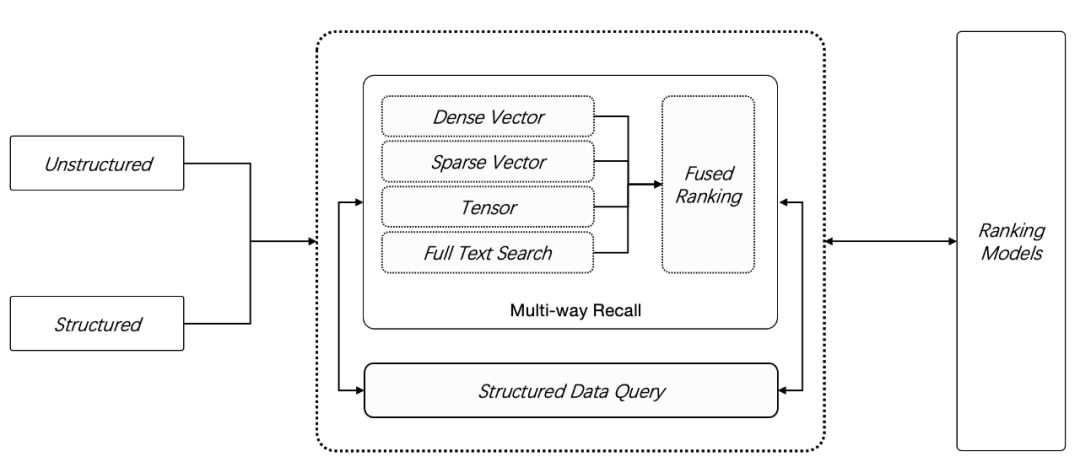
開源 AI 原生數據庫 Infinity,23年12月 正式開源發布,提供了 2 種新數據類型:稀疏向量 Sparse Vector 和 張量 Tensor,在此前的全文搜索和向量搜索之外, Infinity 提供了更多的召回手段,如下圖所示,用戶可以采用任意 N 路召回(N ≥ 2)進行混合搜索,這是目前功能最強大的 RAG 專用數據庫。
我們知道,僅僅依靠向量搜索(默認情況下,它用來特指稠密向量)并不總能提供令人滿意的結果。當用戶問題中的特定關鍵詞與存儲的數據不準確匹配時,這種問題尤為明顯。這是因為向量本身不具備精確語義表征能力:一個詞,一句話,乃至一篇文章,都可以只用一個向量來表示,這時向量本質上表達的是這段文字的“語義”,也就是這段文字跟其他文字在一個上下文窗口內共同出現概率的壓縮表示 ,因此向量天然無法表示精確的查詢。例如如果用戶詢問“2024 年 3 月我們公司財務計劃包含哪些組合”,那么很可能得到的結果是其他時間段的數據,或者得到運營計劃,營銷管理等其他類型的數據。
因此,在一種好的解決方案是,利用基于關鍵詞的全文搜索提供精確查詢,它跟向量搜索共同工作,這就是全文搜索 + 向量搜索 的 2 路召回,又被稱為混合搜索(hybrid search)。
多了 那么多我們來看下ES和Infinity執行效率上的對比吧。如下圖:

我們可以看到infinity的執行效率是Especially的40倍左右,那我們就替換下試試。
關閉docker容器
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml down -v
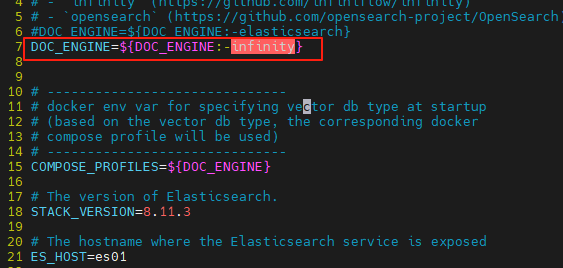
修改參數
vi .env
重啟容器
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml up -d

會去拉取infinity的docker鏡像,更新之后,速度果然大幅度提升,幾秒內響應。
二、代碼解析
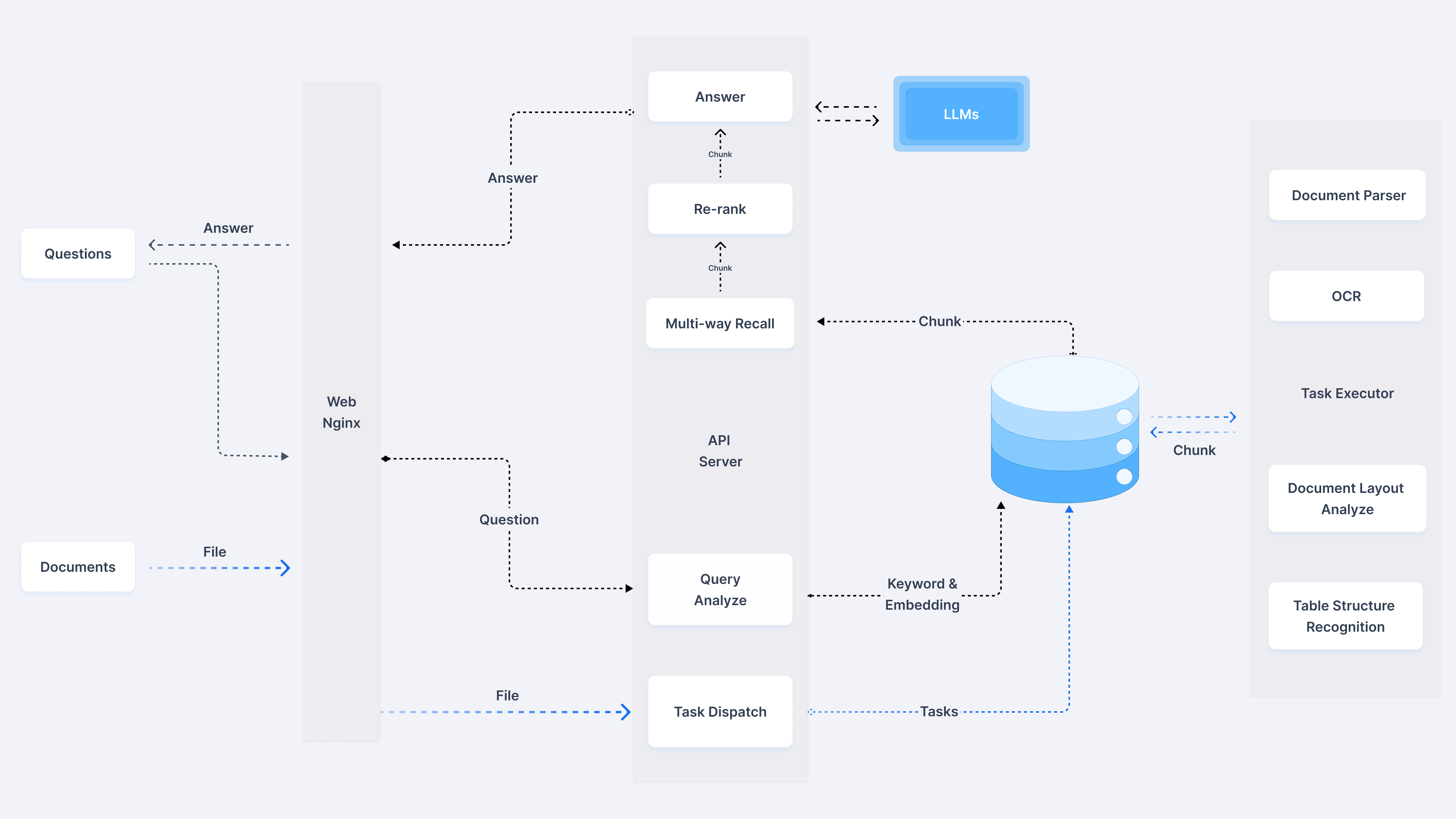
1、整體架構
我們從官方的架構圖入手,我們可以看到從左往右,是我們在實際在線應用的時候的流程架構,從右到左,是知識庫離線生成的流程架構。很明顯,這張圖中把知識庫部分畫的很大,彰顯它在整個RagFlow項目中的核心地位。于此同時,最右側詳細介紹了文件解析的各種手段,比如?OCR,?Document Layout Analyze?等,這些在常規的 RAG 中可能會作為一個不起眼的?Unstructured Loader?包含進去,可以猜到 RagFlow 的一個核心能力在于文件的解析環節。在官方文檔中也反復強調?Quality in, quality out, 反映出 RAGFlow 的獨到之處在于細粒度文檔解析。另外文檔中提到其沒有使用任何 RAG 中間件,而是完全重新研發了一套智能文檔理解系統,并以此為依托構建 RAG 任務編排體系,也可以理解文檔的解析是其 RagFlow 的核心亮點。
2、代碼結構
我們來看看代碼結構(版本:v0.18.0)
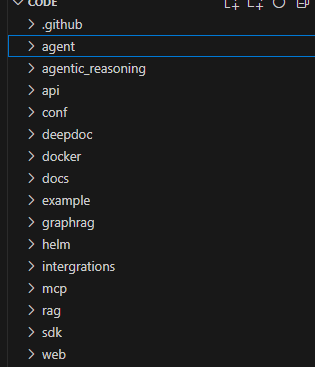
agent:RagFlow新增的一個模塊,即工作流(注:實際上工作流和agent不是一個概念,agent可以作為workflow的一部分),通過“Graph"是一個由節點和邊組成的數學概念。它被用來構建復雜的工作流或代理。
agentic_reasoning:代理推理
api:后端的 API
conf :配置信息
deepdoc: 文件解析模塊
docker:docker配置安裝啟動部署文件
docs:文檔
example:案例
graphrag:圖rag
helm:打包管理工具
intergreations:集成插件工具
mcp:模型上下文協議
web:對應的是前端頁面,TypeScript?開發
其他的一些技術中間件
Web 服務:Flask
業務數據庫:Mysql
向量數據庫:?ElasticSearch?(常規關鍵詞搜索用的也是它),前文已經替換?infinity?
文件存儲:?MinIO,支持分布式存儲
緩存中間件:valkey/valkey:8?是從 Redis 7.2.4 fork 而來,旨在作為 Redis 的開源替代品,特別是在 Redis Labs 更改了 Redis 的源碼使用協議之后。它保持了與 Redis 的兼容性,同時引入了許多性能和功能上的改進。在網絡應用中,Valkey 可以用作緩存、消息隊列、會話存儲等多種用途,適用于需要快速數據訪問和低延遲的場景。
3、源碼解析
(1)加載文件
常規的 RAG 服務都是在上傳時進行文件的加載和解析,但是 RAGFlow 的上傳僅僅包含上傳至 MinIO,需要手工點擊觸發文件的解析。根據實際體驗,RAGFlow 的解析相當慢,資源開銷也比較大,所以這就是采取二次手工確認的產品方案的原因吧。

實際的文件解析通過接口?/v1/document/run?進行觸發的,實際的處理是在?api/db/services/task_service.py?中的?queue_tasks()?中完成的,此方法會根據文件創建一個或多個異步任務,方便異步執行。實現如下所示:
def queue_tasks(doc: dict, bucket: str, name: str, priority: int):def new_task():return {"id": get_uuid(), "doc_id": doc["id"], "progress": 0.0, "from_page": 0, "to_page": 100000000}parse_task_array = []# pdf 文件的解析,根據不同的類型設置單個任務最多處理的頁數# 默認單個任務處理 12 頁 pdf,paper 類型的 pdf 一個任務處理 22 頁,其他 pdf 不分頁if doc["type"] == FileType.PDF.value:file_bin = STORAGE_IMPL.get(bucket, name)do_layout = doc["parser_config"].get("layout_recognize", "DeepDOC")pages = PdfParser.total_page_number(doc["name"], file_bin)page_size = doc["parser_config"].get("task_page_size", 12)if doc["parser_id"] == "paper":page_size = doc["parser_config"].get("task_page_size", 22)if doc["parser_id"] in ["one", "knowledge_graph"] or do_layout != "DeepDOC":page_size = 10 ** 9page_ranges = doc["parser_config"].get("pages") or [(1, 10 ** 5)]for s, e in page_ranges:s -= 1s = max(0, s)e = min(e - 1, pages)for p in range(s, e, page_size):task = new_task()task["from_page"] = ptask["to_page"] = min(p + page_size, e)parse_task_array.append(task)# 表格數據單個任務處理 3000 行elif doc["parser_id"] == "table":file_bin = STORAGE_IMPL.get(bucket, name)rn = RAGFlowExcelParser.row_number(doc["name"], file_bin)for i in range(0, rn, 3000):task = new_task()task["from_page"] = itask["to_page"] = min(i + 3000, rn)parse_task_array.append(task)else:parse_task_array.append(new_task())chunking_config = DocumentService.get_chunking_config(doc["id"])# 任務插入 Redis 消息隊列,方便異步處理for task in parse_task_array:hasher = xxhash.xxh64()for field in sorted(chunking_config.keys()):if field == "parser_config":for k in ["raptor", "graphrag"]:if k in chunking_config[field]:del chunking_config[field][k]hasher.update(str(chunking_config[field]).encode("utf-8"))for field in ["doc_id", "from_page", "to_page"]:hasher.update(str(task.get(field, "")).encode("utf-8"))task_digest = hasher.hexdigest()task["digest"] = task_digesttask["progress"] = 0.0task["priority"] = priorityprev_tasks = TaskService.get_tasks(doc["id"])ck_num = 0if prev_tasks:for task in parse_task_array:ck_num += reuse_prev_task_chunks(task, prev_tasks, chunking_config)TaskService.filter_delete([Task.doc_id == doc["id"]])chunk_ids = []for task in prev_tasks:if task["chunk_ids"]:chunk_ids.extend(task["chunk_ids"].split())if chunk_ids:settings.docStoreConn.delete({"id": chunk_ids}, search.index_name(chunking_config["tenant_id"]),chunking_config["kb_id"])DocumentService.update_by_id(doc["id"], {"chunk_num": ck_num})bulk_insert_into_db(Task, parse_task_array, True)DocumentService.begin2parse(doc["id"])unfinished_task_array = [task for task in parse_task_array if task["progress"] < 1.0]for unfinished_task in unfinished_task_array:assert REDIS_CONN.queue_product(get_svr_queue_name(priority), message=unfinished_task), "Can't access Redis. Please check the Redis' status."從上面的實現來看,文件的解析是根據內容拆分為多個任務,通過 Redis 消息隊列進行暫存(生產者),之后就可以離線異步處理。直接查看對應的消息隊列的消費模塊(消費者),對應在?rag/svr/task_executor.py?中的?main()?方法中。實現如下所示:
async def main():logging.info(r"""______ __ ______ __/_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____/ / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___// / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /
/_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/""")logging.info(f'TaskExecutor: RAGFlow version: {get_ragflow_version()}')settings.init_settings()print_rag_settings()if sys.platform != "win32":signal.signal(signal.SIGUSR1, start_tracemalloc_and_snapshot)signal.signal(signal.SIGUSR2, stop_tracemalloc)TRACE_MALLOC_ENABLED = int(os.environ.get('TRACE_MALLOC_ENABLED', "0"))if TRACE_MALLOC_ENABLED:start_tracemalloc_and_snapshot(None, None)signal.signal(signal.SIGINT, signal_handler)signal.signal(signal.SIGTERM, signal_handler)threading.Thread(name="RecoverPendingTask", target=recover_pending_tasks).start()async with trio.open_nursery() as nursery:nursery.start_soon(report_status)while not stop_event.is_set():async with task_limiter:nursery.start_soon(handle_task)logging.error("BUG!!! You should not reach here!!!")
)











)





