大語言模型預備數學知識
復習一下在大語言模型中用到的矩陣和向量的運算,及概率統計和神經網絡中常用概念。
矩陣的運算
矩陣

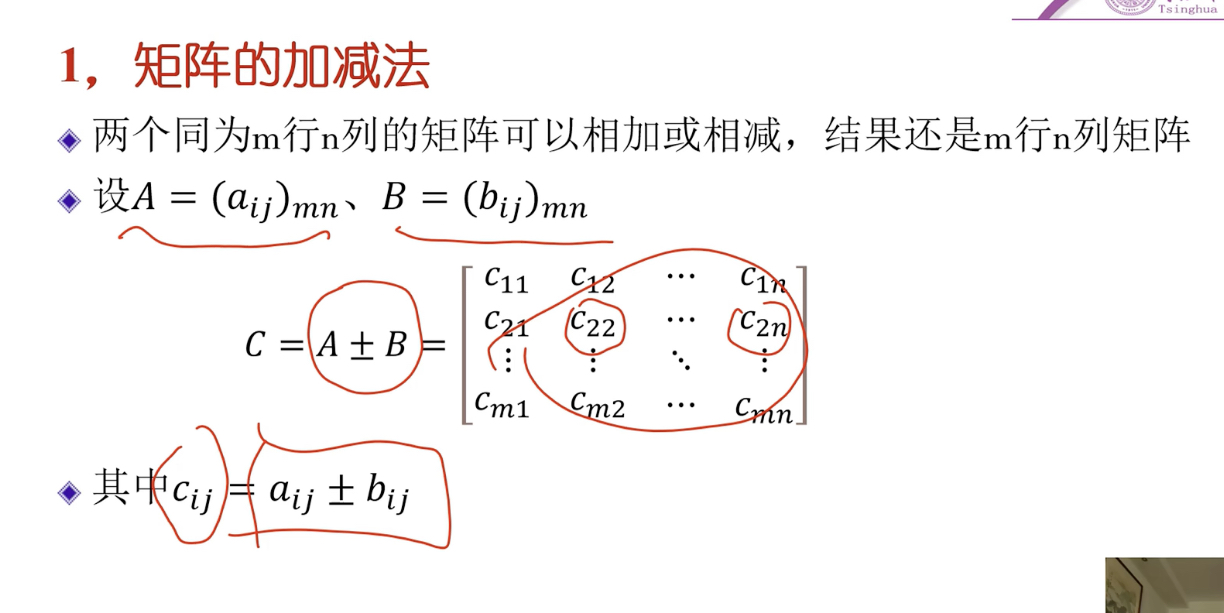
矩陣加減法
條件:行數列數相同的矩陣才能做矩陣加減法
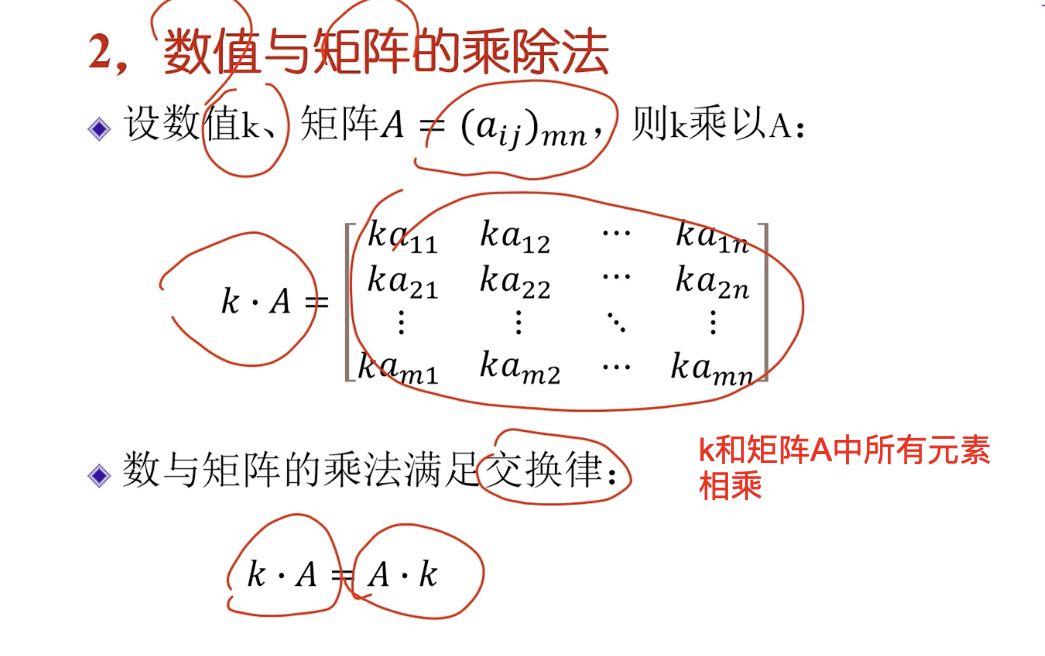
數值與矩陣的乘除法

矩陣乘法
條件:矩陣A的列數 = 矩陣B的行數時, A才能乘B
因為矩陣乘法是前一個矩陣各行中各個元素乘后一個矩陣各列中對于元素,所以要求矩陣A的列數 = 矩陣B的行數。

矩陣乘法性質

矩陣的轉置
轉置:矩陣所有的行按順序變成列

轉置的性質

向量的運算
向量
本博客后續,默認用行向量來表示默認向量

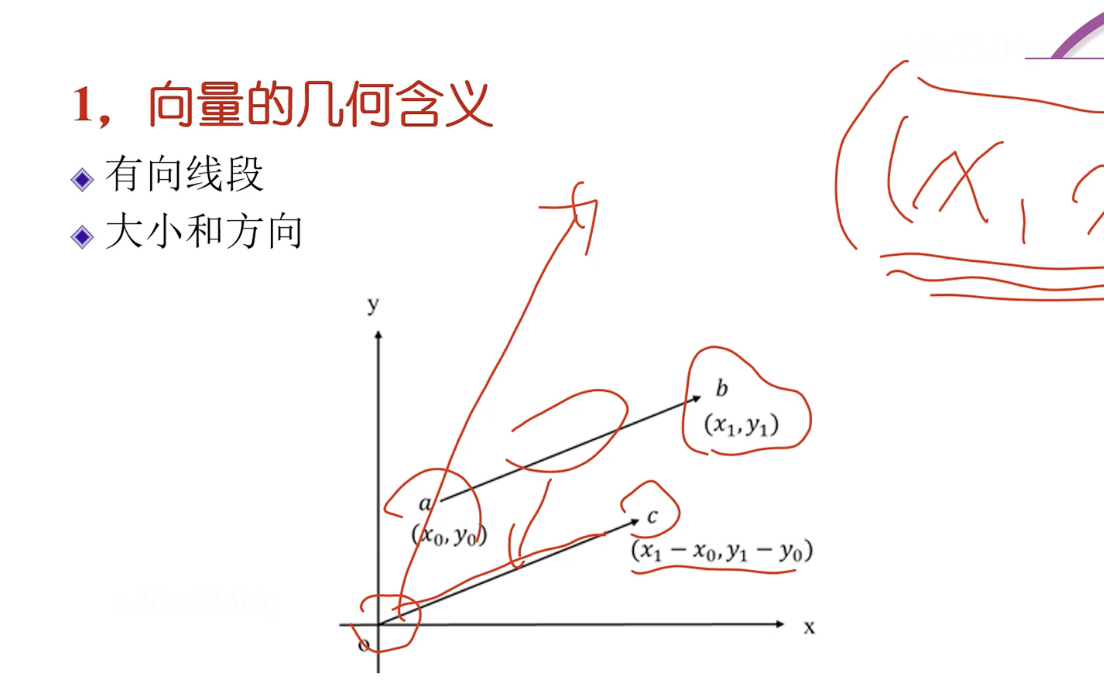
向量的幾何意義
起點在坐標原點,終點在坐標數值的向量
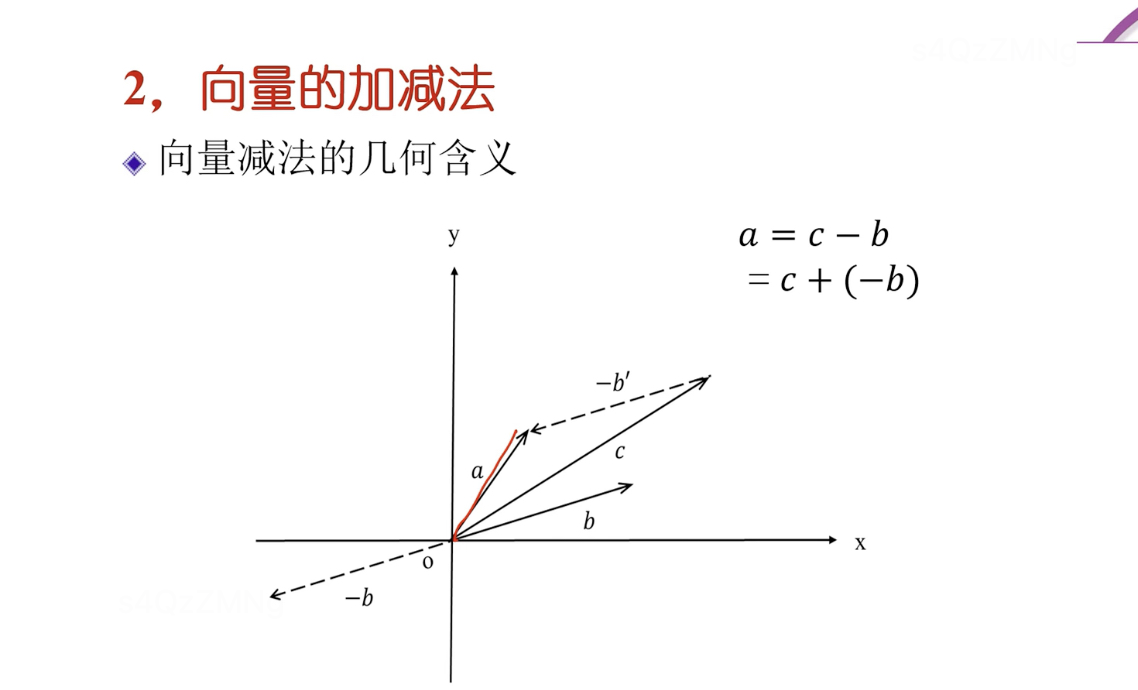
向量的加減法
條件:向量a,b的元素的個數相同

向量加法,以零點為起點,以b’終點為終點的向量(b’的起點為a的終點)。減法就相當于 加 負向量
數值與向量的乘除法
a向量乘2,表示對a向量伸長了兩倍。

向量的乘法
向量乘法是向量的點積運算,又稱內積
點積:行向量乘列向量,結果為標量

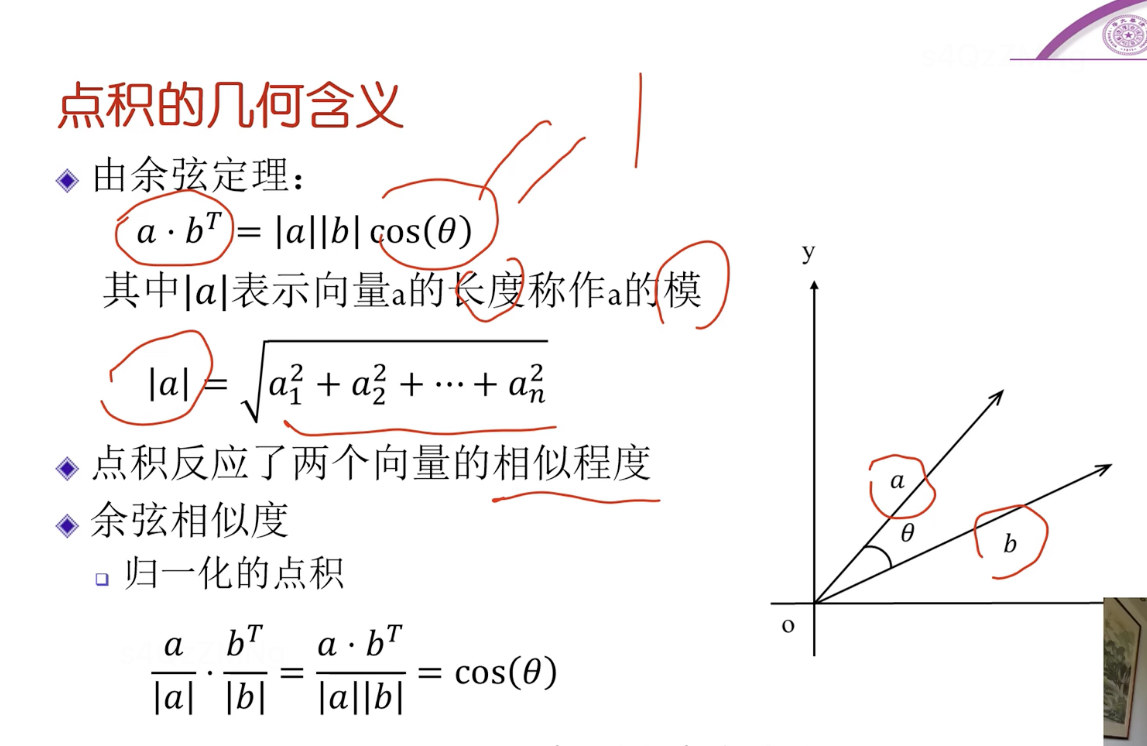
點積點幾何含義(常用)
反映了兩個向量相似程度,當兩個向量方向一致時,夾角為0,cos夾角 = 1,兩向量長度不變則此時兩向量的點積最大,表示兩向量此時最相似。
但點積的大小也跟向量a,b的長度有關,所以可以進行歸一化,即分別對每個向量除各自的長度(模),稱為余弦相似度。(歸一化了,就跟具體的向量長度沒關系了,其值完全反映兩個向量的相似性)
矩陣和向量的乘法
向量(指行向量)右乘矩陣(矩陣在右邊),條件:矩陣行數與向量元素個數相等。相乘結果為一個行向量,其元素個數為矩陣的列數。

向量(指列向量)左乘矩陣(矩陣在左邊),條件:矩陣列數與向量元素個數相等。相乘結果為一個列向量,其元素個數為矩陣的行數。

矩陣和向量的乘法的幾何意義
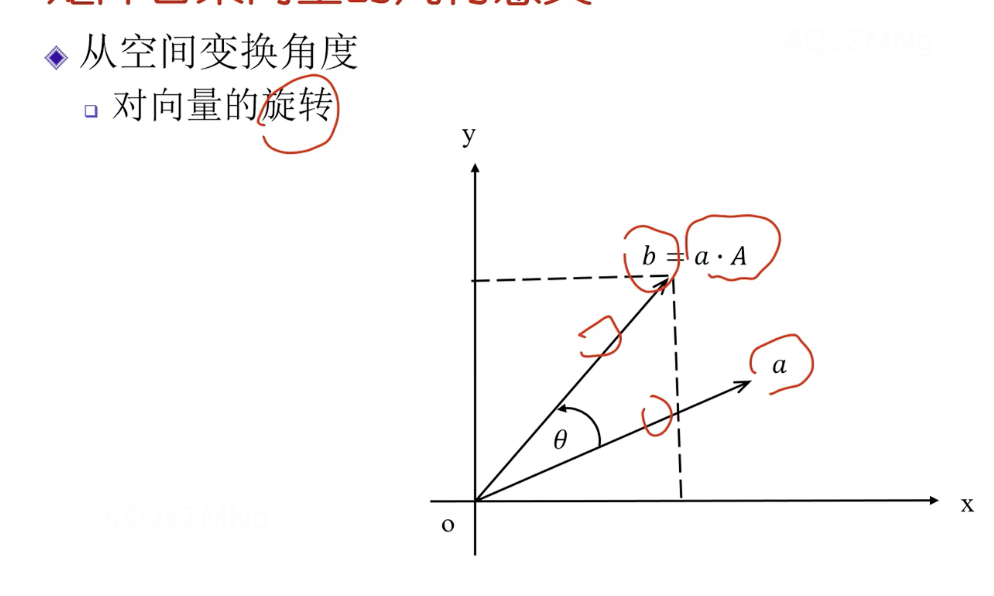
向量右乘矩陣的幾何意義
- 相似性角度

- 空間變換角度,表示對向量的旋轉操作
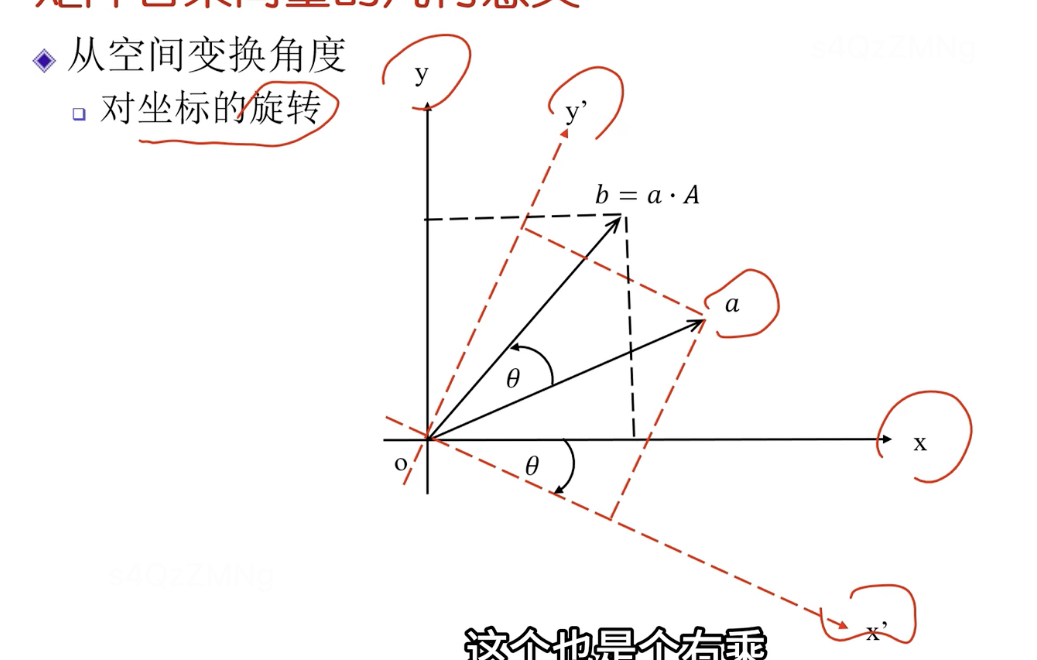
a在新坐標系中的坐標
概率
數學期望與方差

數學期望:離散型隨機變量每個可能的取值,與該取值對應的概率相乘,統一相加的結果,反映取值的平均值


蒙特卡洛方法(通過采樣的方法)
即計算數學期望值的時候,通過采樣計算平均值的方式去近似(蒙特卡洛方法)。
為什么?因為我們不知道每種概率是多少,就通過采樣的辦法去近似,當采樣數量足夠多時,采樣平均值就可被認為數學期望。


數學期望的性質


最后一條性質指,隨機變量x,任何可能都>=0,則數學期望>=0
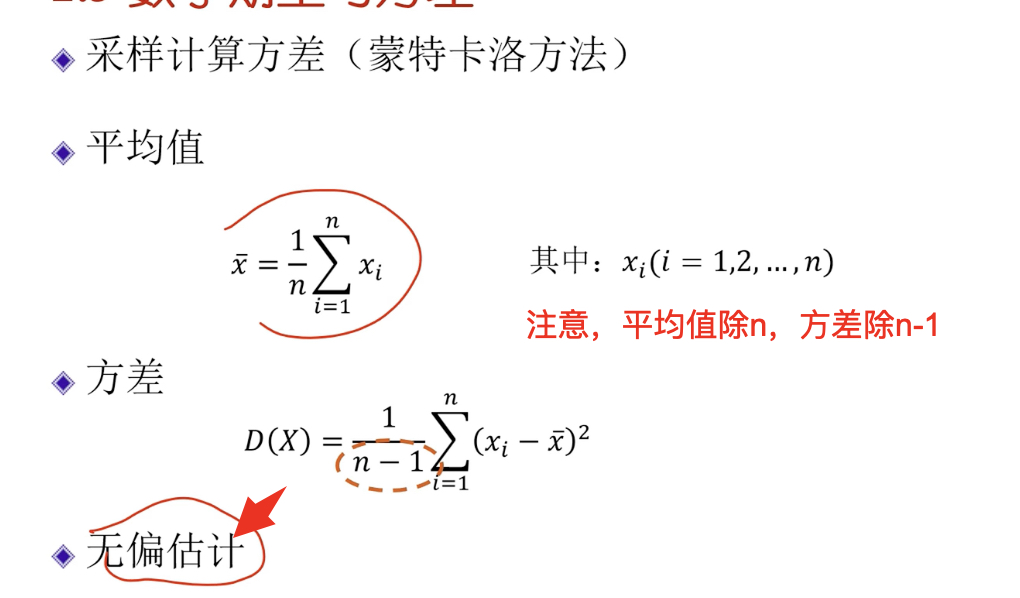
方差


計算方差的過程
如何理解評價值除n,方差除n-1。因為前面求平均值時除n,知道了n個數中n-1個就可以把第n個算出來,它們之間有一定相關性。除n-1得到的才是無偏估計。
舉例

方差的性質

馬爾可夫過程
馬爾可夫過程是一個隨機過程,且未來的發展只與當前狀態有關,而跟之前的狀態無關。一般來說都是一種近似的結果,通過近似來簡化計算。
一般的隨機過程
X(t)的取值稱為隨機過程在時間t的狀態

馬爾可夫過程

神經網絡與深度學習
梯度下降
方向:如果斜率(導數)>0,則x減;如果斜率(導數)<0,則x加(即修改的方向跟導數的方向相反)
大小:離最低點(最優值)遠時,比較陡(導數絕對值越大越陡)—導數絕對值越大,修改量越大。
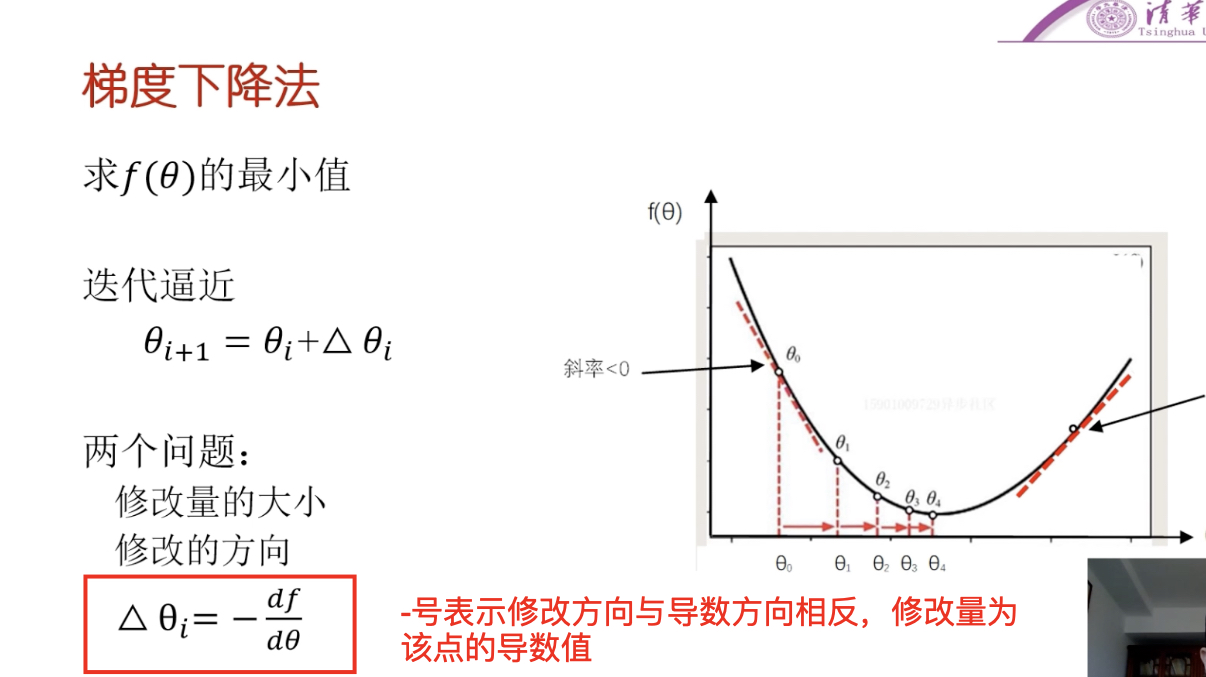
震蕩問題,因為導數趨于∞時,會導致震蕩, 引入一個大于0的常量步長,防止震蕩很大,使其一步步過來。
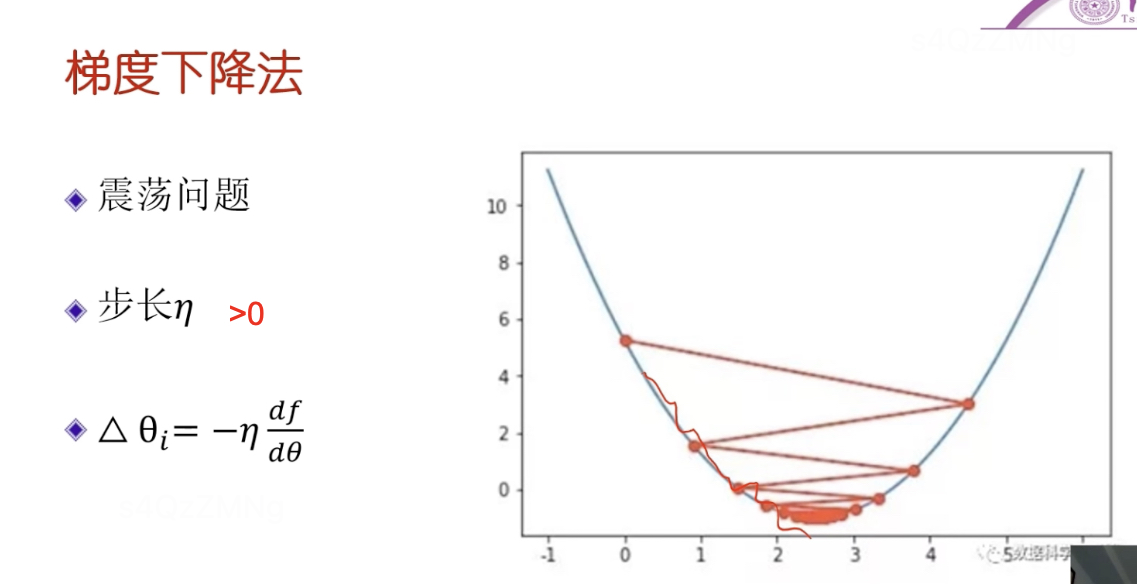
在神經網絡中因為參數量很大所以用偏導數

導數反映某一處切線斜率,梯度表示在曲線中的某個切平面的斜率。梯度下降核心思想:沿著梯度的反方向,看那個地方下降最快,沿最陡峭地方往下走,一點點找到最優值。
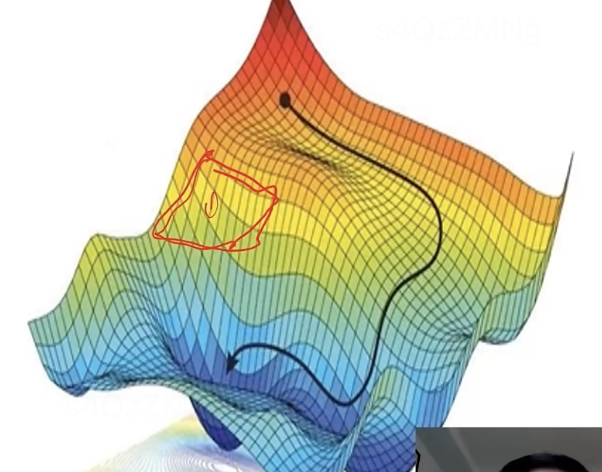
常見梯度下降算法

歡迎各位讀者點贊評論收藏,本人后續也會對這塊基礎數學知識進行進一步更新




)
)










和 BLE)
(編譯器為支持運行時多態(動態綁定)而自動生成的一種內部數據結構)虛函數指針vptr)
