1.分布式事務
分布式事務,就是指不是在單個服務或單個數據庫架構下,產生的事務,例如:
- 跨數據源的分布式事務
- 跨服務的分布式事務
- 綜合情況
我們之前解決分布式事務問題是直接使用Seata框架的AT模式,但是解決分布式事務問題的方案遠不止這一種。
1.1.CAP定理
解決分布式事務問題,需要一些分布式系統的基礎知識作為理論指導,首先就是CAP定理。
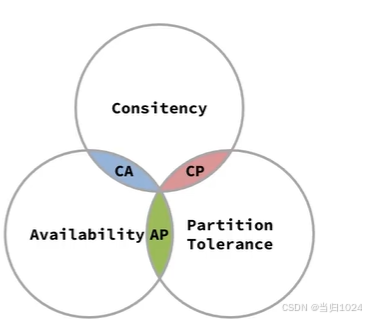
1998年,加州大學的計算機科學家 Eric Brewer 提出,分布式系統有三個指標:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分區容錯性)
它們的第一個字母分別是 C、A、P。Eric Brewer認為任何分布式系統架構方案都不可能同時滿足這3個目標,這個結論就叫做 CAP 定理。
為什么呢?
1.1.1.一致性
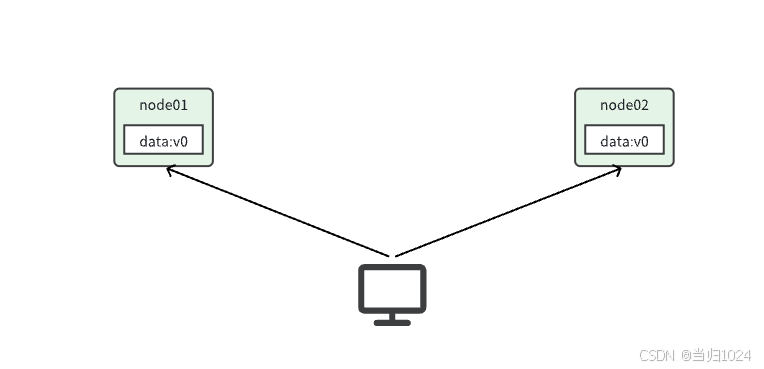
Consistency(一致性):用戶訪問分布式系統中的任意節點,得到的數據必須一致。
比如現在包含兩個節點,其中的初始數據是一致的:
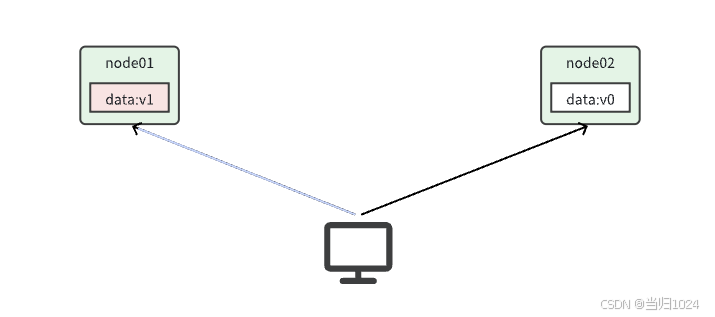
當我們修改其中一個節點的數據時,兩者的數據產生了差異:
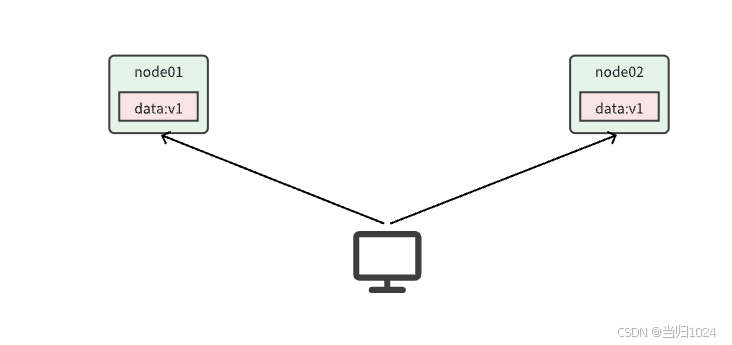
要想保住一致性,就必須實現node01 到 node02的數據 同步:
1.1.2.可用性
Availability (可用性):用戶訪問分布式系統時,讀或寫操作總能成功。
只能讀不能寫,或者只能寫不能讀,或者兩者都不能執行,就說明系統弱可用或不可用。
1.1.3.分區容錯
Partition,就是分區,就是當分布式系統節點之間出現網絡故障導致節點之間無法通信的情況:
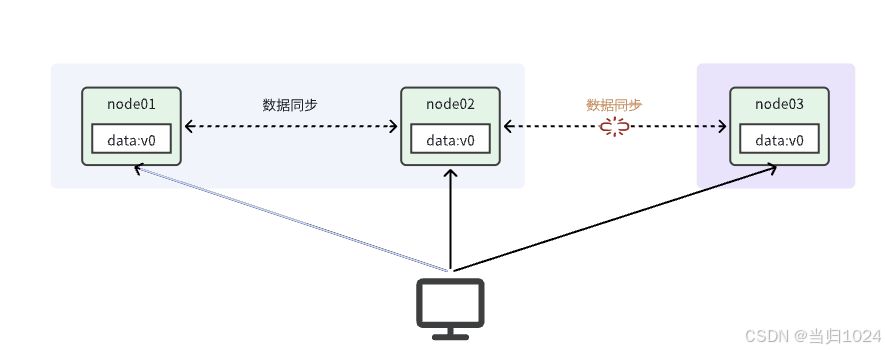
如上圖,node01和node02之間網關暢通,但是與node03之間網絡斷開。于是node03成為一個獨立的網絡分區;node01和node02在一個網絡分區。
Tolerance,就是容錯,即便是系統出現網絡分區,整個系統也要持續對外提供服務。
1.1.4.矛盾
在分布式系統中,網絡不能100%保證暢通,也就是說網絡分區的情況一定會存在。而我們的系統必須要持續運行,對外提供服務。所以分區容錯性(P)是硬性指標,所有分布式系統都要滿足。而在設計分布式系統時要取舍的就是一致性(C)和可用性(A)了。
假如現在出現了網絡分區,如圖:
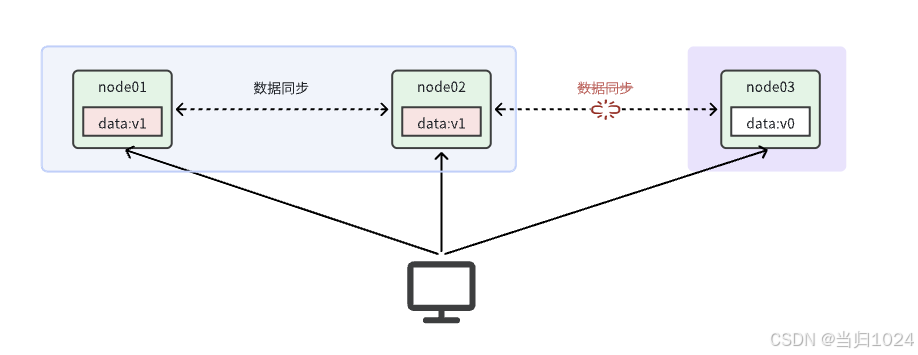
由于網絡故障,當我們把數據寫入node01時,可以與node02完成數據同步,但是無法同步給node03。現在有兩種選擇:
- 允許用戶任意讀寫,
保證可用性。但由于node03無法完成同步,就會出現數據不一致的情況。滿足AP - 不允許用戶寫,可以讀,直到網絡恢復,分區消失。這樣就
確保了一致性,但犧牲了可用性。滿足CP
可見,在分布式系統中,A和C之間只能滿足一個。
1.2.BASE理論
既然分布式系統要遵循CAP定理,那么問題來了,我到底是該犧牲一致性還是可用性呢?如果犧牲了一致性,出現數據不一致該怎么處理?
人們在總結系統設計經驗時,最終得到了一些心得:
Basically Available (基本可用):分布式系統在出現故障時,允許損失部分可用性,即保證核心可用。Soft State(軟狀態):在一定時間內,允許出現中間狀態,比如臨時的不一致狀態。Eventually Consistent(最終一致性):雖然無法保證強一致性,但是在軟狀態結束后,最終達到數據一致。
以上就是BASE理論。
簡單來說,BASE理論就是一種取舍的方案,不再追求完美,而是最終達成目標。因此解決分布式事務的思想也是這樣,有兩個方向:
AP思想:各個子事務分別執行和提交,無需鎖定數據。允許出現結果不一致,然后采用彌補措施恢復,實現最終一致即可。例如AT模式就是如此CP思想:各個子事務執行后不要提交,而是等待彼此結果,然后同時提交或回滾。在這個過程中鎖定資源,不允許其它人訪問,數據處于不可用狀態,但能保證一致性。例如XA模式
1.3.AT模式的臟寫問題
我們先回顧一下AT模式的流程,AT模式也分為兩個階段:
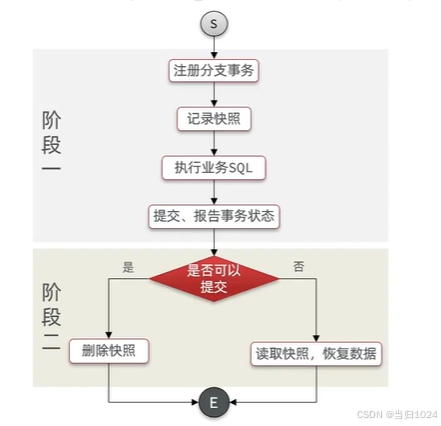
第一階段是記錄數據快照,執行并提交事務:
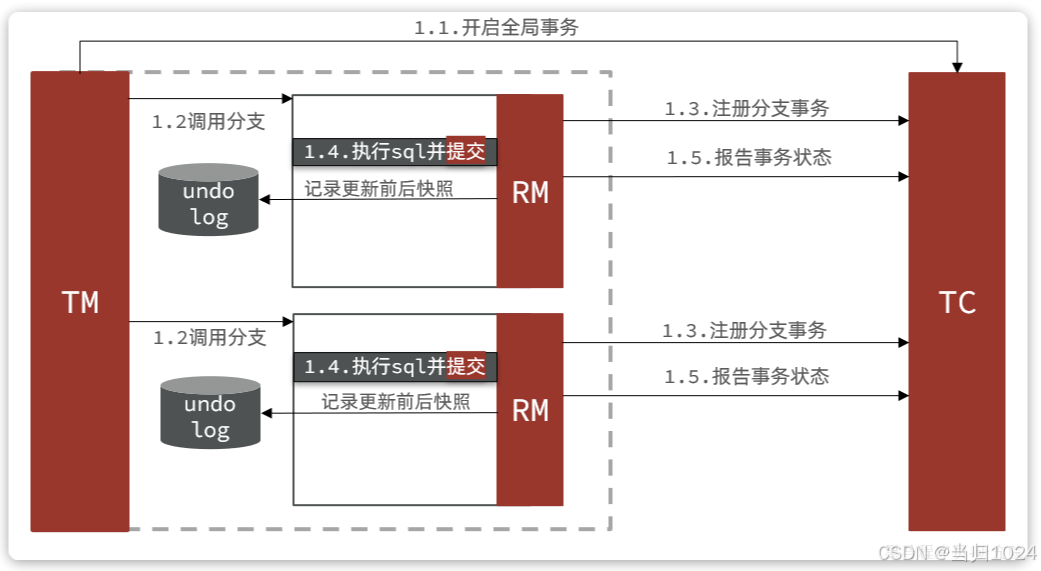
第二階段根據階段一的結果來判斷:
- 如果每一個分支事務都
成功,則事務已經結束(因為階段一已經提交),因此刪除階段一的快照即可 - 如果有
任意分支事務失敗,則需要根據快照恢復到更新前數據。然后刪除快照
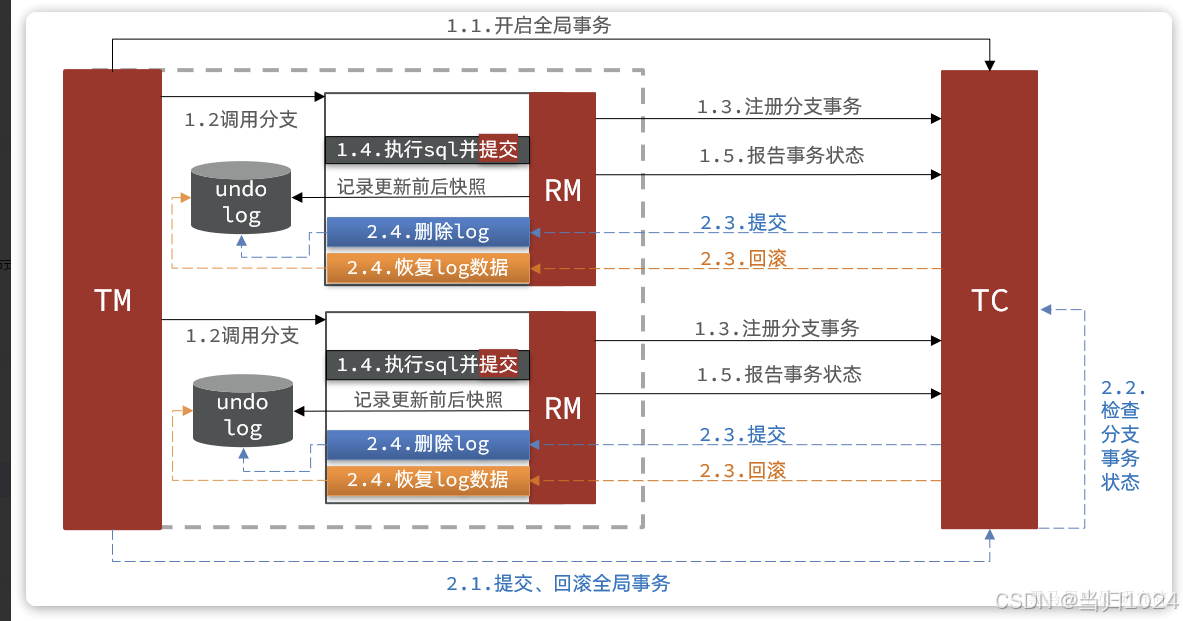
這種模式在大多數情況下(99%)并不會有什么問題,不過在極端情況下,特別是多線程并發訪問AT模式的分布式事務時,有可能出現臟寫問題,如圖:
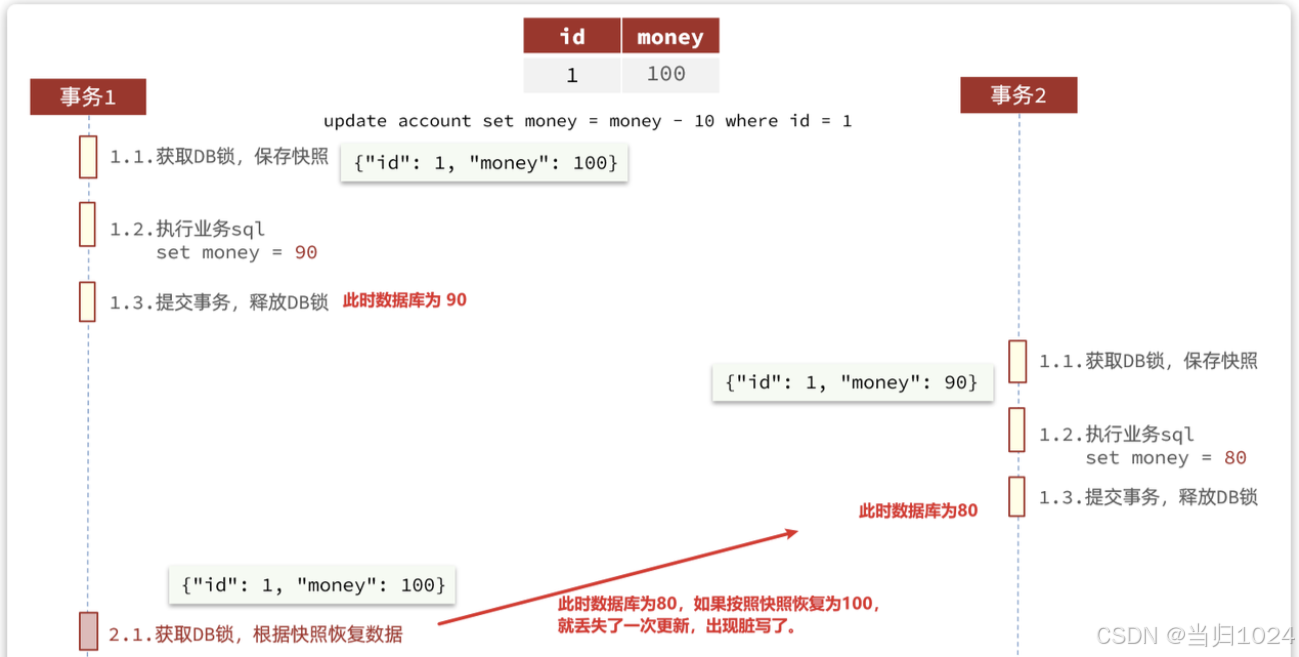
解決思路就是引入了全局鎖的概念。在釋放DB鎖之前,先拿到全局鎖。避免同一時刻有另外一個事務來操作當前數據。(db鎖的等待時長非常長,而事務2的全局鎖的等待時長只有300毫秒,所以一般最后事務1一定會拿到全局鎖和db鎖,不會想回等待進入死鎖)

具體可以參考官方文檔:
https://seata.apache.org/zh-cn/docs/dev/mode/at-mode/
全局鎖能夠限制的是都被seata統一管理的,如果有一個操作不是seata提哦難過一管理的,是其他操作的,那么全局鎖就會失效,需要人工介入

1.4.TCC模式
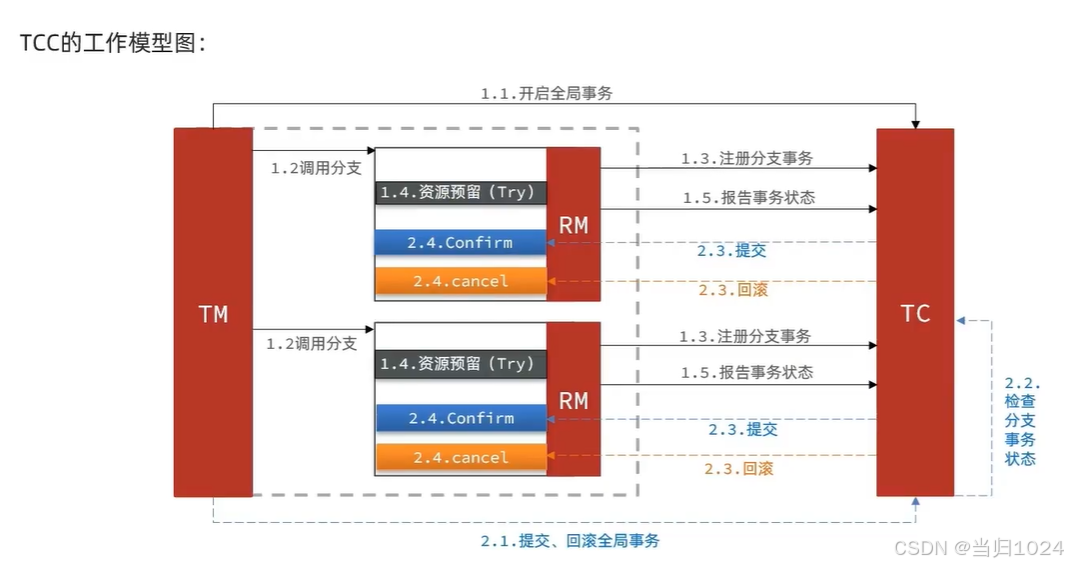
TCC模式與AT模式非常相似,每階段都是獨立事務,不同的是TCC通過人工編碼來實現數據恢復。需要實現三個方法:
try:資源的檢測和預留;confirm:完成資源操作業務;要求 try成功 confirm一定要能成功。cancel:預留資源釋放,可以理解為try的反向操作。
1.4.1.流程分析
舉例,一個扣減用戶余額的業務。假設賬戶A原來余額是100,需要余額扣減30元。
階段一( Try ):檢查余額是否充足,如果充足則凍結金額增加30元,可用余額扣除30
初始余額:

余額充足,可以凍結:

此時,總金額 = 凍結金額 + 可用金額,數量依然是100不變。事務直接提交無需等待其它事務。
階段二(Confirm):假如要提交(Confirm),之前可用金額已經扣減,并轉移到凍結金額。因此可用金額不變,直接凍結金額扣減30即可:

此時,總金額 = 凍結金額 + 可用金額 = 0 + 70 = 70元
階段二(Canncel):如果要回滾(Cancel),則釋放之前凍結的金額,也就是凍結金額扣減30,可用余額增加30

1.4.2.事務懸掛和空回滾
假如一個分布式事務中包含兩個分支事務,try階段,一個分支成功執行,另一個分支事務阻塞:
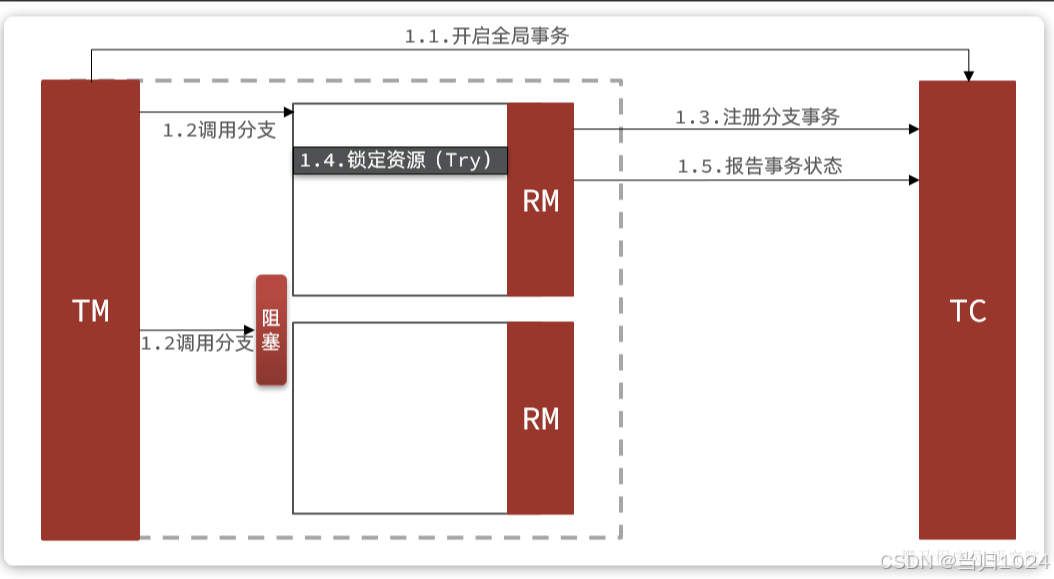
如果阻塞時間太長,可能導致全局事務超時而觸發二階段的cancel操作。兩個分支事務都會執行cancel操作:
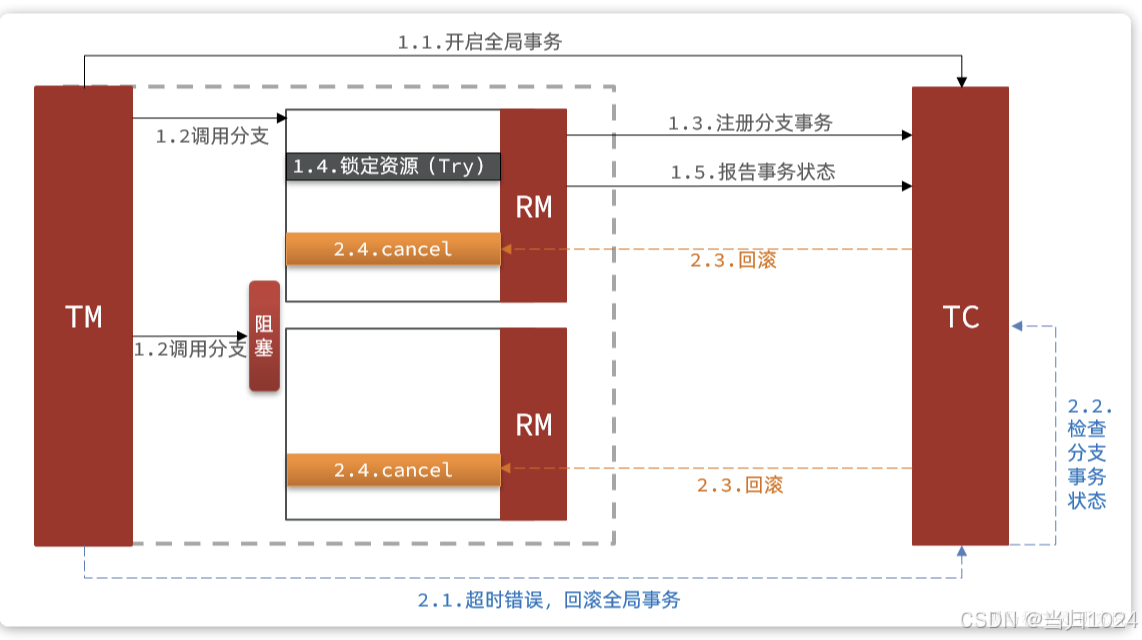
要知道,其中一個分支是未執行try操作的,直接執行了cancel操作,反而會導致數據錯誤。因此,這種情況下,盡管cancel方法要執行,但其中不能做任何回滾操作,這就是空回滾。
對于整個空回滾的分支事務,將來try方法阻塞結束依然會執行。但是整個全局事務其實已經結束了,因此永遠不會再有confirm或cancel,也就是說這個事務執行了一半,處于懸掛狀態,這就是業務懸掛問題。
以上問題都需要我們在編寫try、cancel方法時處理。
1.4.3.總結
TCC模式的每個階段是做什么的?
Try:資源檢查和預留Confirm:業務執行和提交Cancel:預留資源的釋放
TCC的優點是什么?
- 一階段完成直接提交事務,釋放數據庫資源,
性能好 - 相比AT模型,無需生成快照,
無需使用全局鎖,性能最強 - 不依賴數據庫事務,而是依賴補償操作,
可以用于非事務型數據庫
TCC的缺點是什么?
有代碼侵入,需要人為編寫try、Confirm和Cancel接口,太麻煩- 軟狀態,事務是最終一致
- 需要考慮
Confirm和Cancel的失敗情況,做好冪等處理、事務懸掛和空回滾處理
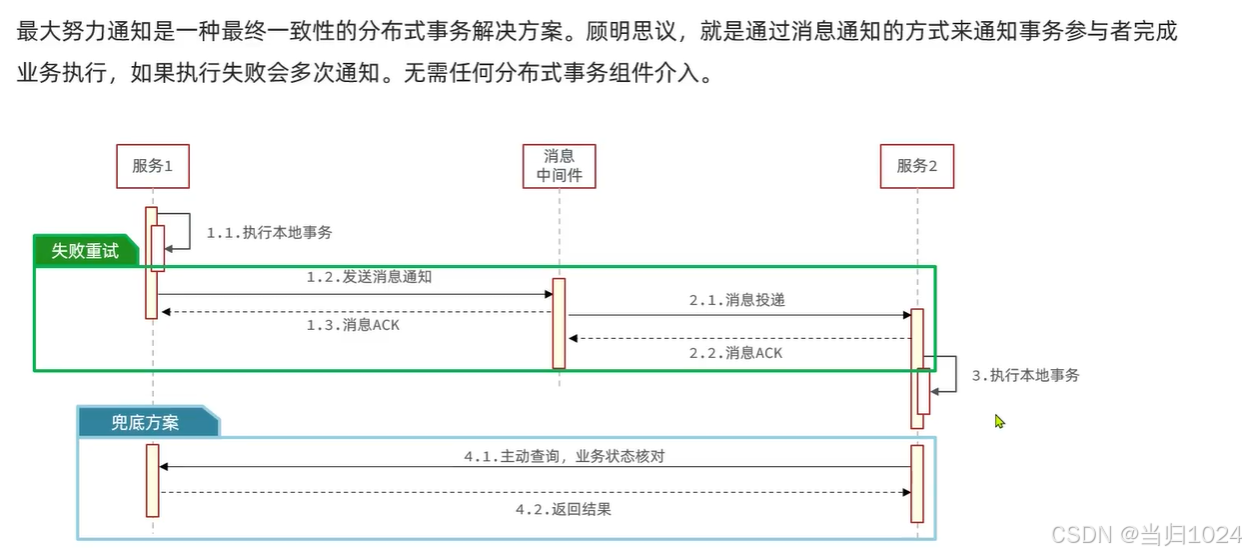
1.5. 最大努力通知
除了上述的兩種方式,有些企業嫌棄上述的方案,實現起來過于麻煩,所以可能會使用最大努力通知。
2.注冊中心
2.1.環境隔離
企業實際開發中,往往會搭建多個運行環境,例如:
- 開發環境
- 測試環境
- 預發布環境
- 生產環境
這些不同環境之間的服務和數據之間需要隔離。
還有的企業中,會開發多個項目,共享nacos集群。此時,這些項目之間也需要把服務和數據隔離。
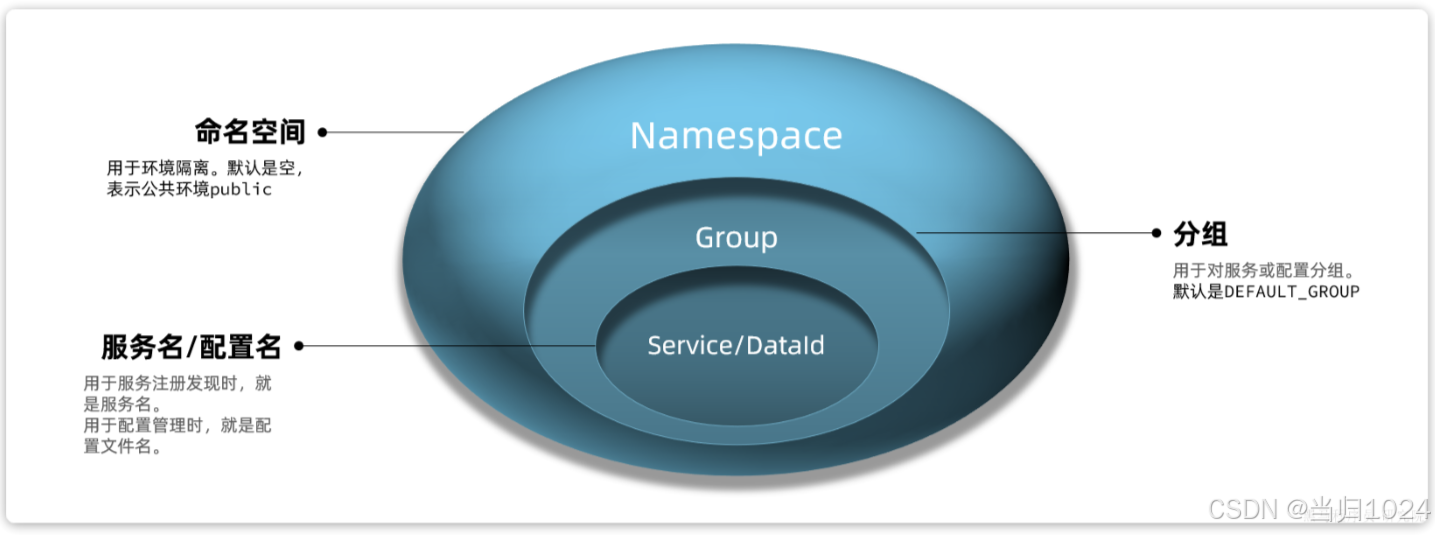
因此,Nacos提供了基于namespace的環境隔離功能。具體的隔離層次如圖所示:
說明:
- Nacos中可以配置多個
namespace,相互之間完全隔離。默認的namespace名為public - namespace下還可以
繼續分組,也就是group,相互隔離。默認的group是DEFAULT_GROUP - group之下就是
服務和配置了
2.1.1.創建namespace
nacos提供了一個默認的namespace,叫做public:
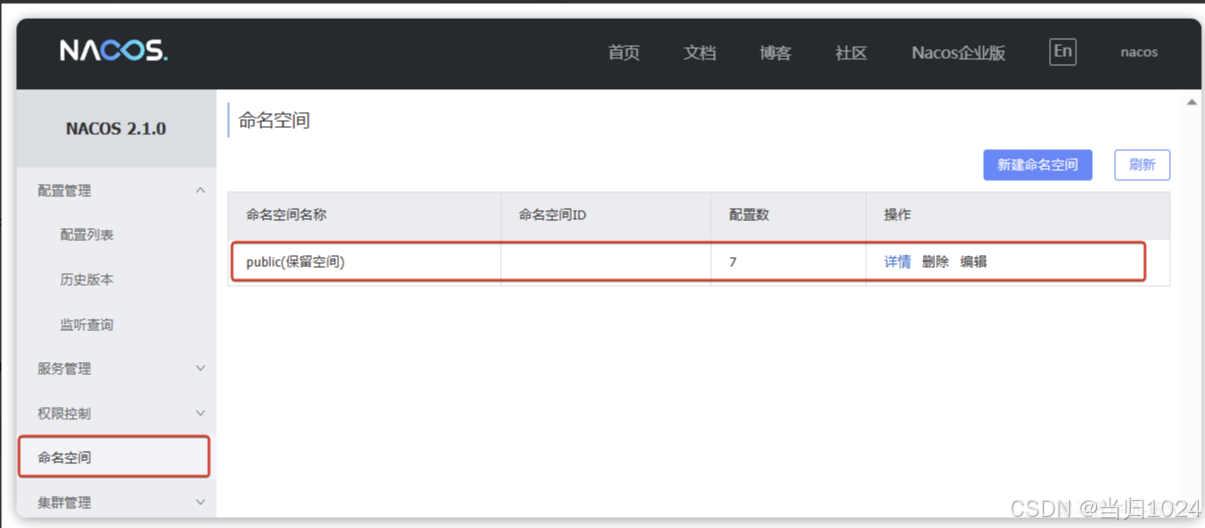
默認所有的服務和配置都屬于這個namespace,當然我們也可以自己創建新的namespace:
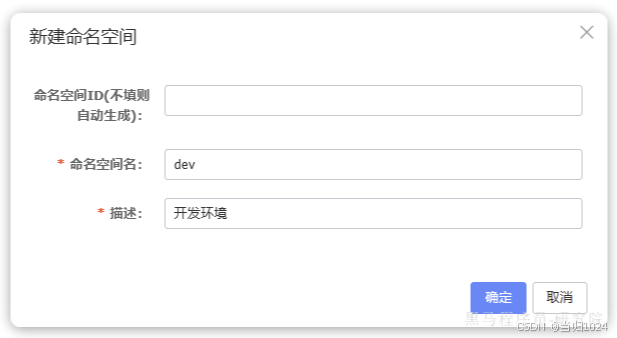
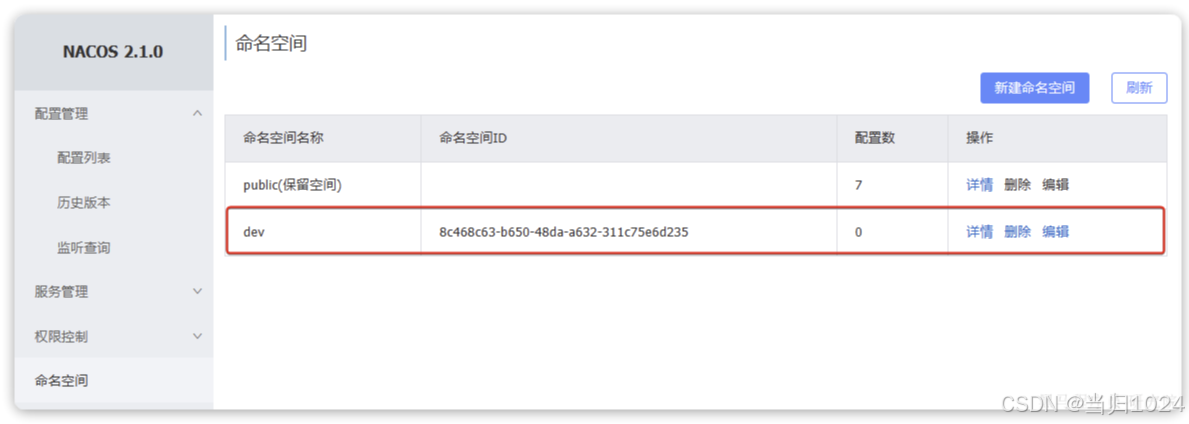
添加完成后,可以在頁面看到我們新建的namespace,并且Nacos為我們自動生成了一個命名空間id:
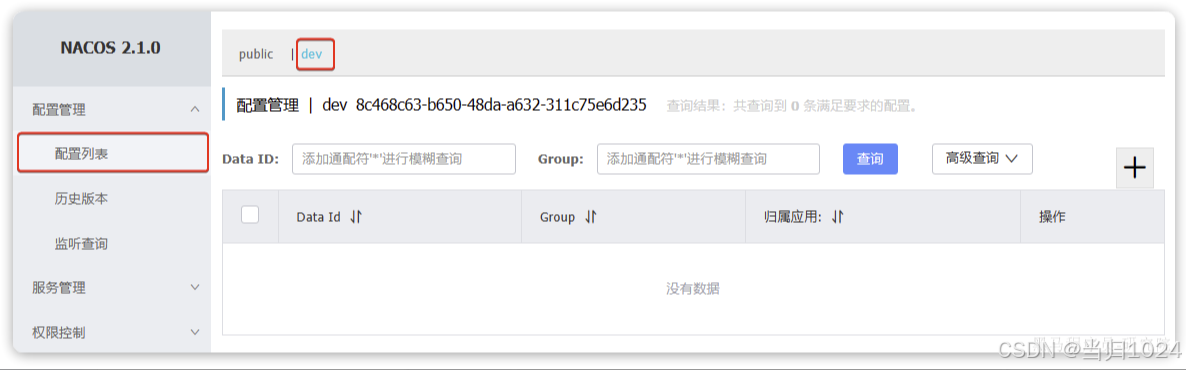
我們切換到配置列表頁,你會發現dev這個命名空間下沒有任何配置
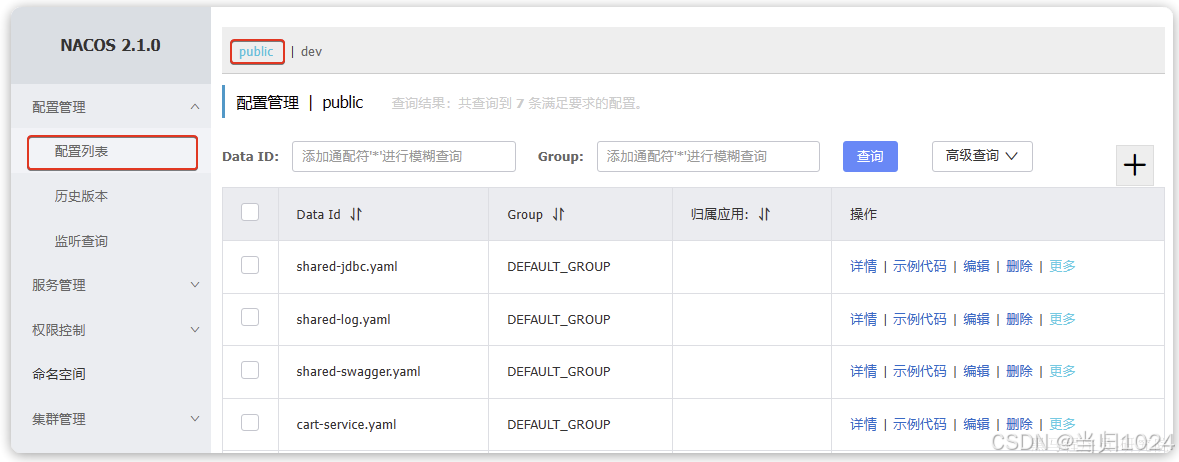
因為之前我們添加的所有配置都在public下:
2.1.2.微服務配置namespace
默認情況下,所有的微服務注冊發現、配置管理都是走public這個命名空間。如果要指定命名空間則需要修改application.yml文件。
比如,我們修改item-service服務的bootstrap.yml文件,添加服務發現配置,指定其namespace:
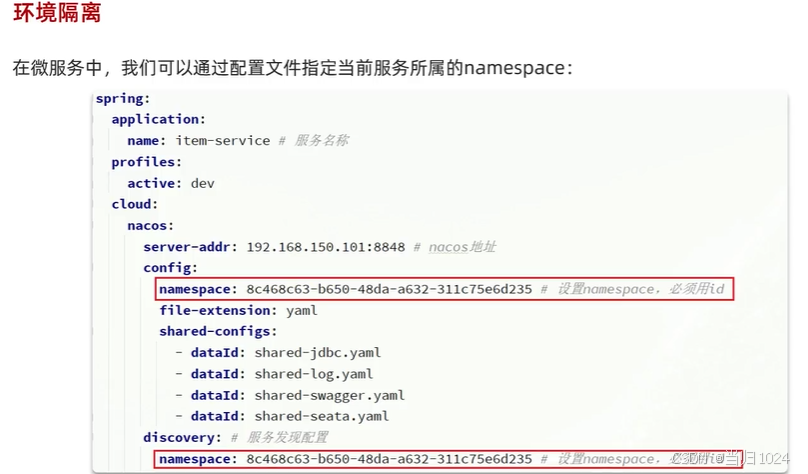
spring:application:name: item-service # 服務名稱profiles:active: devcloud:nacos:server-addr: 192.168.150.101 # nacos地址discovery: # 服務發現配置namespace: 8c468c63-b650-48da-a632-311c75e6d235 # 設置namespace,必須用id# 。。。略
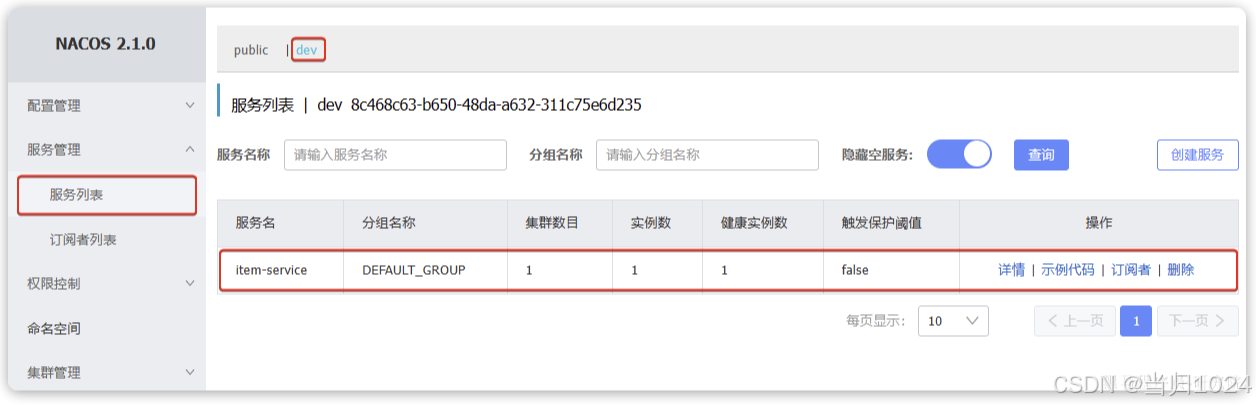
啟動item-service,查看服務列表,會發現item-service出現在dev下:
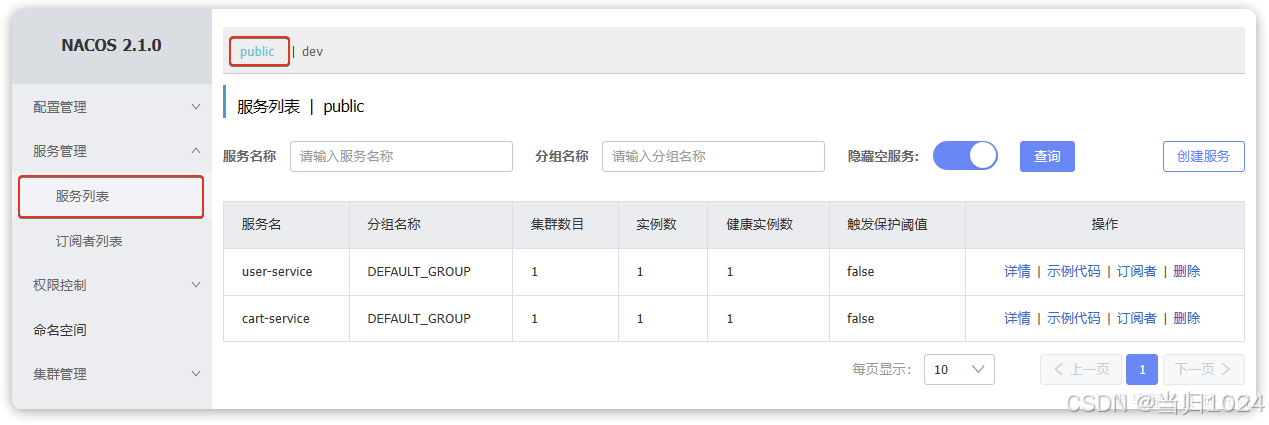
而其它服務則出現在public下:
此時訪問http://localhost:8082/doc.html,基于swagger做測試:
切換前是能夠查看item的最新價格的
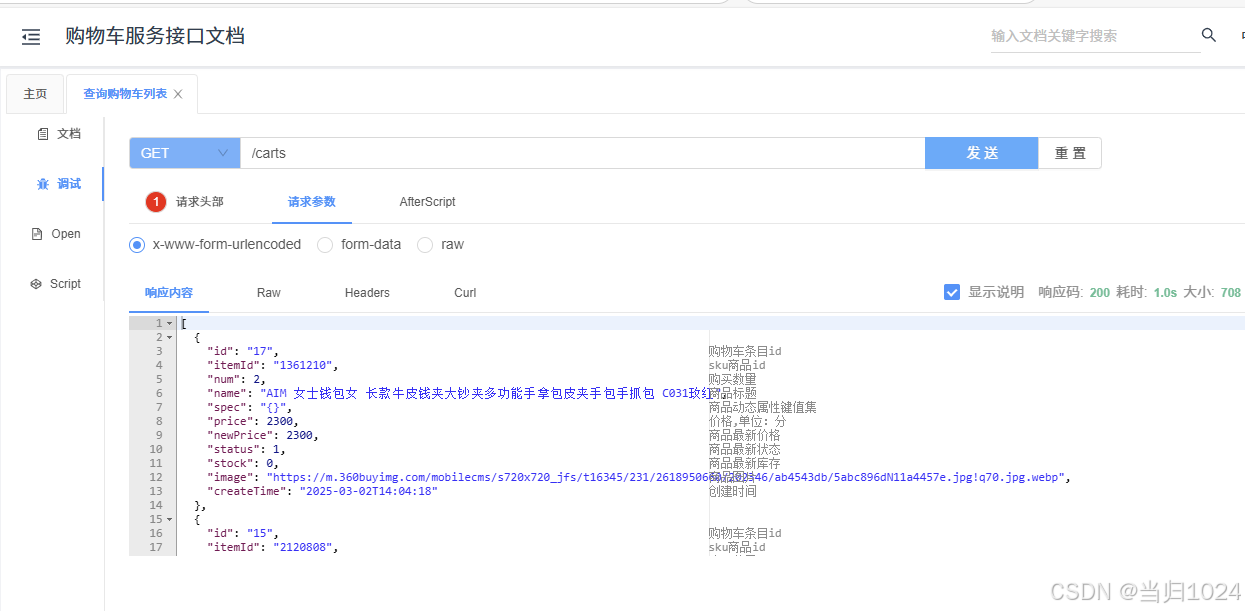
item的微服務使用了新的命名空間,
但是cart的微服務使用的是default的命名空間,就會查詢不到,所以查詢的newPrice就會為空
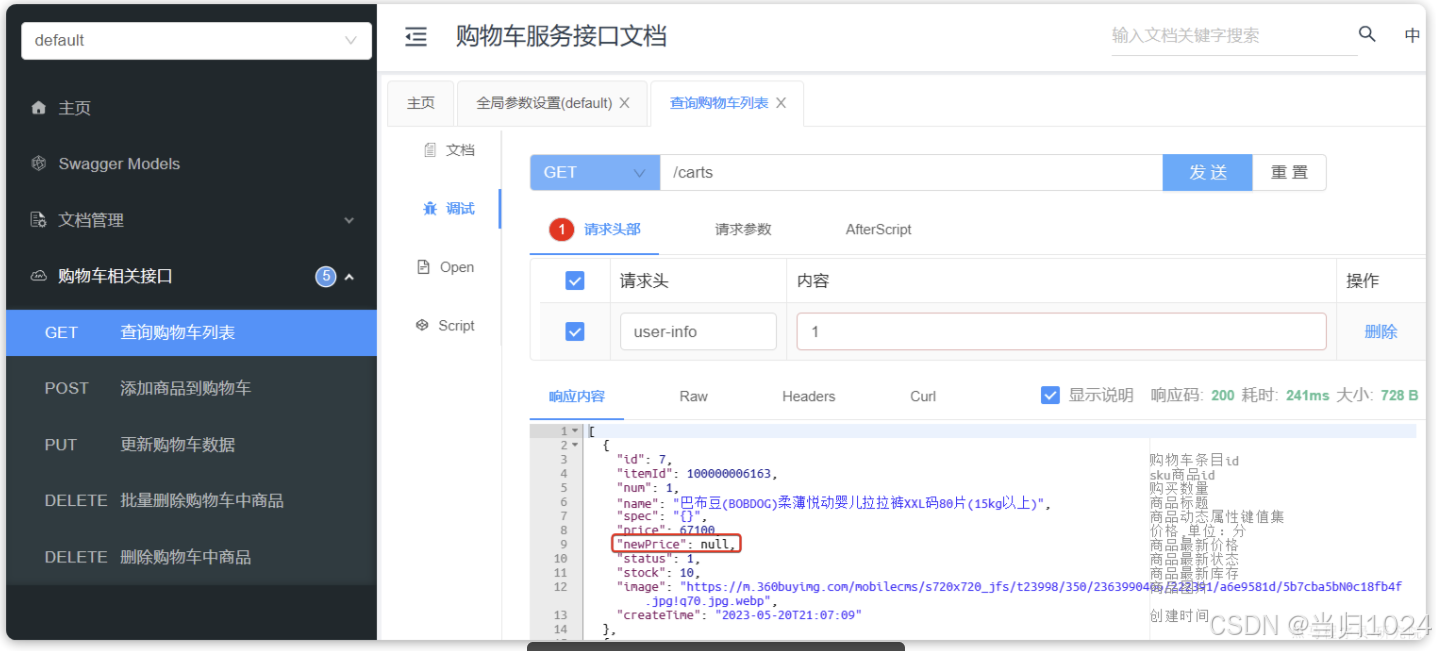
會發現查詢結果中缺少商品的最新價格信息。
我們查看服務運行日志:
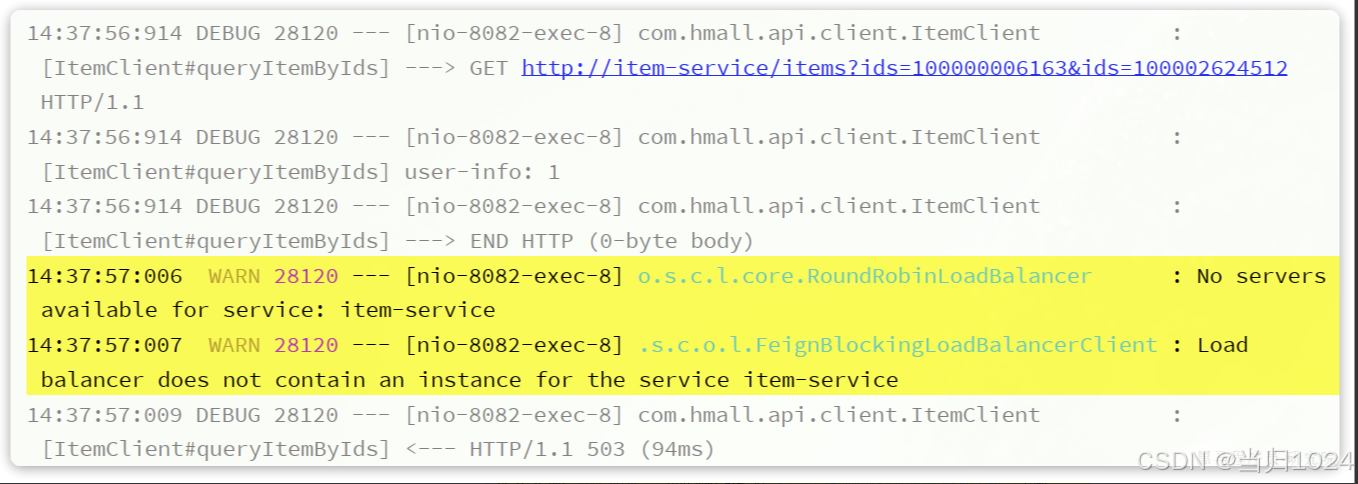
會發現cart-service服務在遠程調用item-service時,并沒有找到可用的實例。這證明不同namespace之間確實是相互隔離的,不可訪問。
當我們把namespace切換回public,或者統一都是以dev時訪問恢復正常。
2.2.分級模型
在一些大型應用中,同一個服務可以部署很多實例。而這些實例可能分布在全國各地的不同機房。由于存在地域差異,網絡傳輸的速度會有很大不同,因此在做服務治理時需要區分不同機房的實例。
例如item-service,我們可以部署3個實例:
- 127.0.0.1:8081
- 127.0.0.1:8082
- 127.0.0.1:8083
假如這些實例分布在不同機房,例如:
- 127.0.0.1:8081,在上海機房
- 127.0.0.1:8082,在上海機房
- 127.0.0.1:8083,在杭州機房
Nacos中提供了集群(cluster)的概念,來對應不同機房。也就是說,一個服務(service)下可以有很多集群(cluster),而一個集群(cluster)中下又可以包含很多實例(instance)。
如圖:
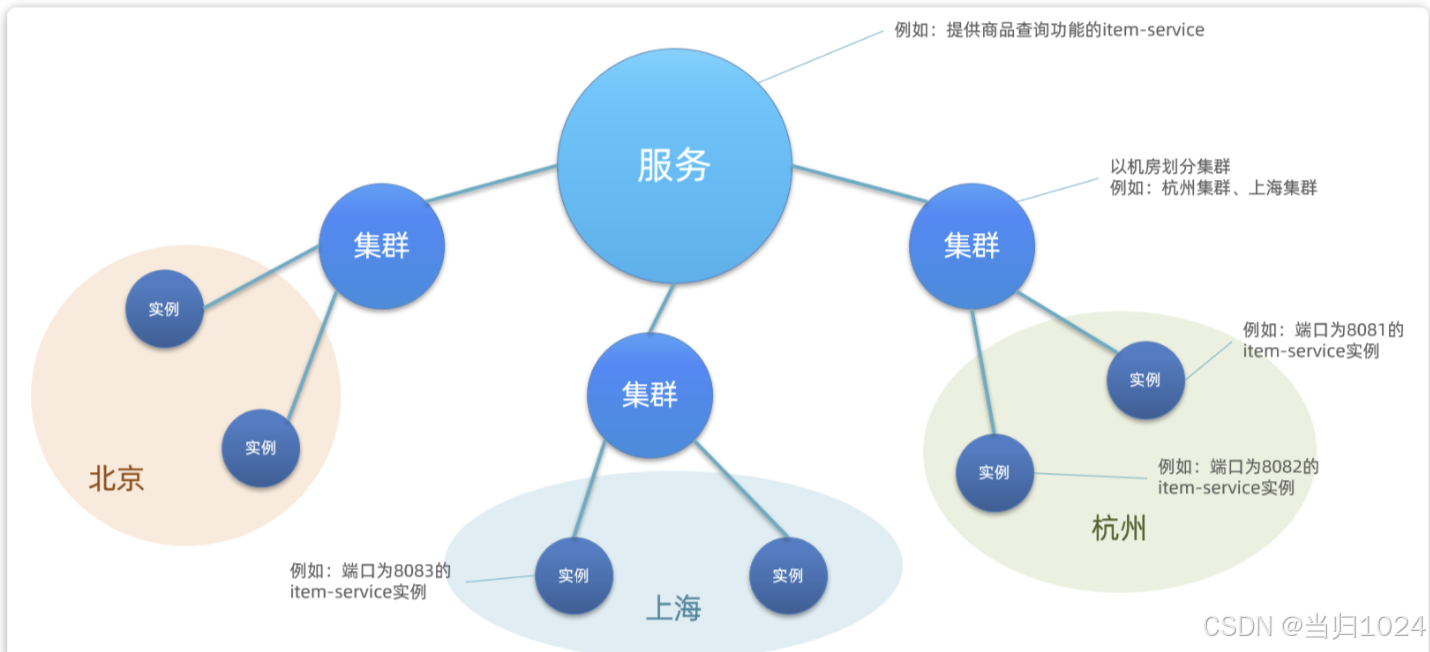
因此,結合我們上一節學習的namespace命名空間的知識,任何一個微服務的實例在注冊到Nacos時,都會生成以下幾個信息,用來確認當前實例的身份,從外到內依次是:
- namespace:命名空間
- group:分組
- service:服務名
- cluster:集群
- instance:實例,包含ip和端口
這就是nacos中的服務分級模型。
在Nacos內部會有一個服務實例的注冊表,是基于Map實現的,其結構與分級模型的對應關系如下:
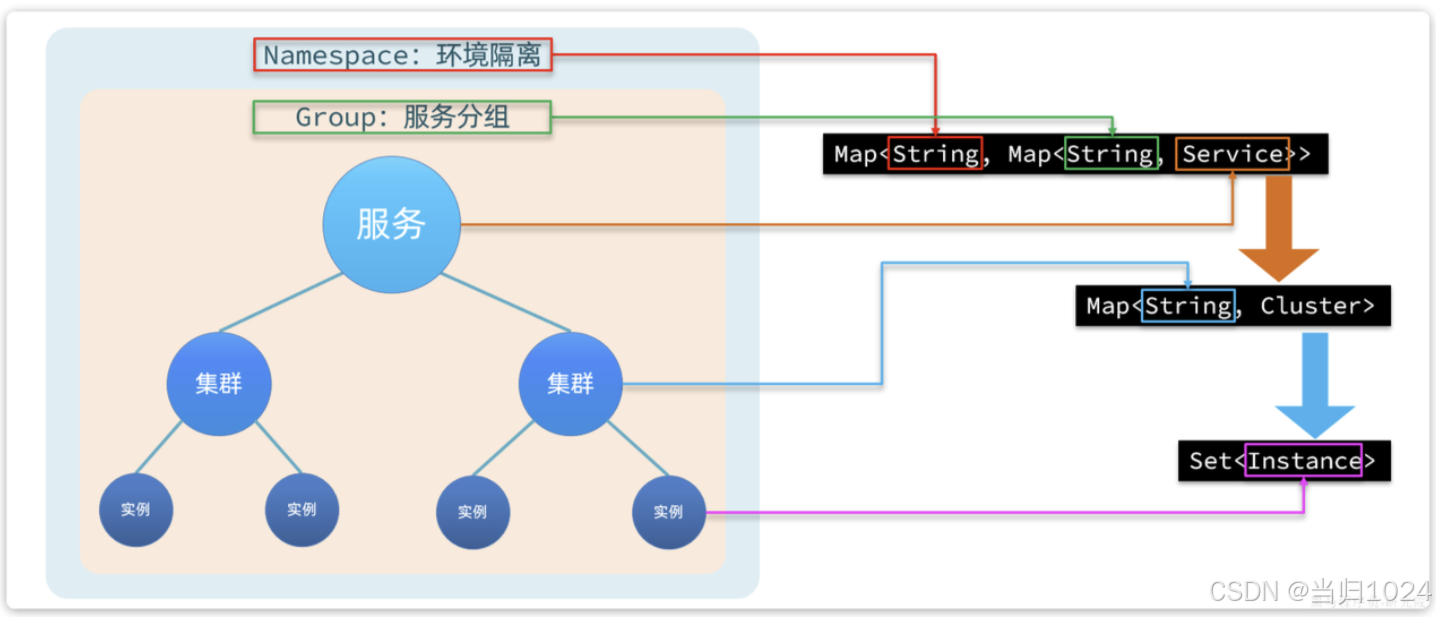
查看nacos控制臺,會發現默認情況下所有服務的集群都是default:
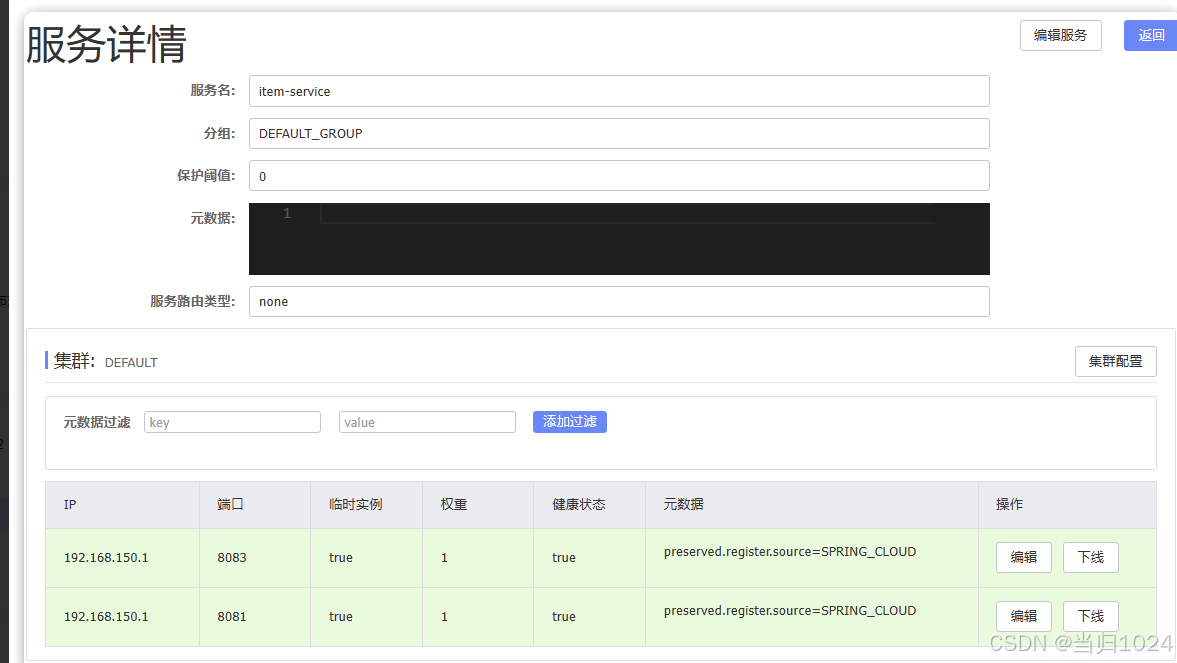
如果我們要修改服務所在集群,只需要修改bootstrap.yml即可:
spring:cloud:nacos:discovery:cluster-name: BJ # 集群名稱,自定義
我們修改item-service的bootstrap.yml,然后重新創建一個實例:

再次查看nacos:
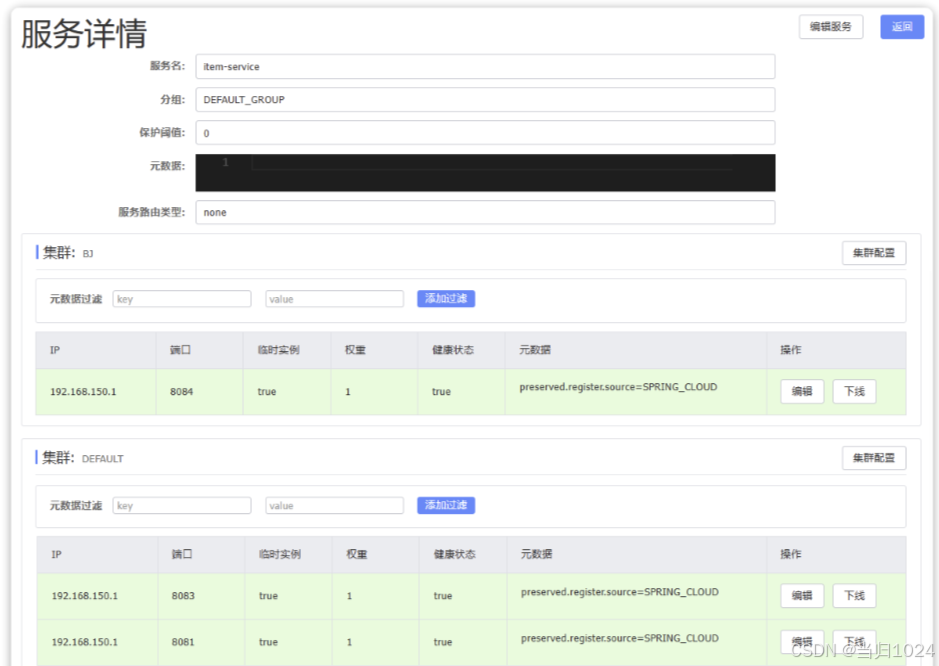
發現8084這個新的實例確實屬于BJ這個集群了。
2.3 Eureka和Nacos對比
Eureka是Netflix公司開源的一個注冊中心組件,目前被集成在SpringCloudNetflix這個模塊下。它的工作原理與Nacos類似:
- nacos時間更短,響應更加快,能夠更快發現異常
- eureka 更慢,但是變相保護了服務,因為網絡出現波動很正常,不能一出現波動就斷開
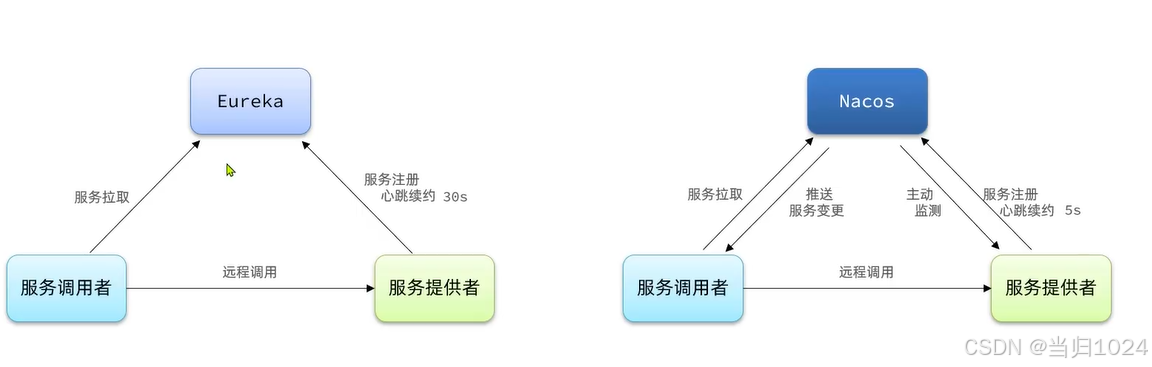
綜上,Eureka和Nacos的相似點有:
- 都支持服務注冊發現功能
- 都有基于心跳的健康監測功能
- 都支持集群,集群間數據同步默認是AP模式,即最全高可用性
Eureka和Nacos的區別有:
- Eureka的心跳是30秒一次,Nacos則是5秒一次
- Eureka如果90秒未收到心跳,則認為服務疑似故障,可能被剔除。Nacos中則是15秒超時,30秒剔除。
- Eureka每隔60秒執行一次服務檢測和清理任務;Nacos是每隔5秒執行一次。
- Eureka只能等微服務自己每隔30秒更新一次服務列表;Nacos即有定時更新,也有在服務變更時的廣播推送
- Eureka僅有注冊中心功能,而
Nacos同時支持注冊中心、配置管理 - Eureka和Nacos都支持集群,而且默認都是AP模式
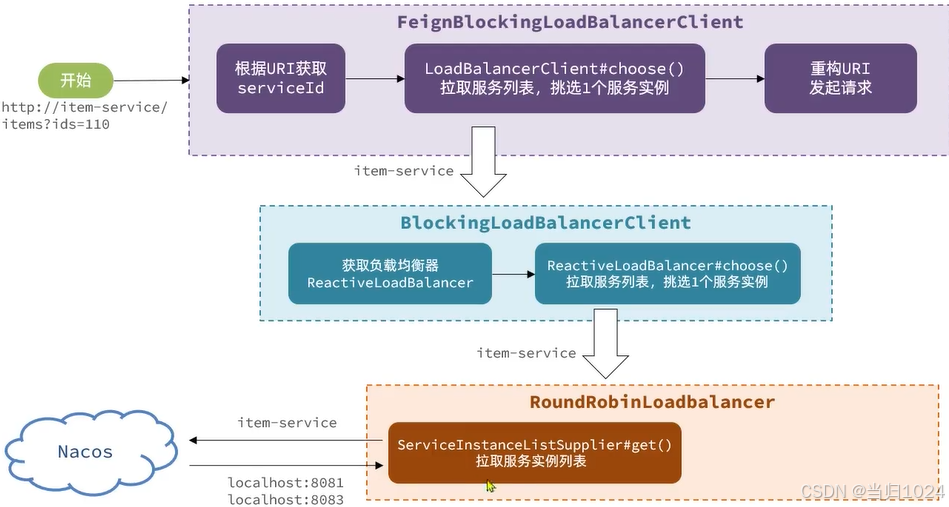
3 遠程調用
3.1 負載均衡




4.服務保護
4.1 線程隔離
首先我們來看下線程隔離功能,無論是Hystix還是Sentinel都支持線程隔離。不過其實現方式不同。
線程隔離有兩種方式實現:
線程池隔離:給每個服務調用業務分配一個線程池,利用線程池本身實現隔離效果信號量隔離:不創建線程池,而是計數器模式,記錄業務使用的線程數量,達到信號量上限時,禁止新的請求
如圖:
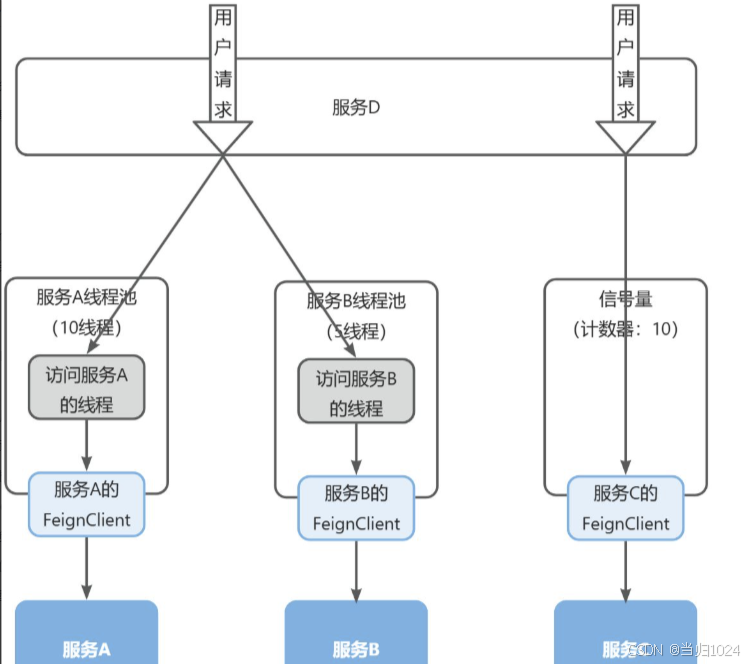
兩者的優缺點如下:

Sentinel的線程隔離就是基于信號量隔離實現的,而Hystix兩種都支持,但默認是基于線程池隔離。

4.2.滑動窗口算法
在熔斷功能中,需要統計異常請求或慢請求比例,也就是計數。在限流的時候,要統計每秒鐘的QPS,同樣是計數。可見計數算法在熔斷限流中的應用非常多。sentinel中采用的計數器算法就是滑動窗口計數算法。
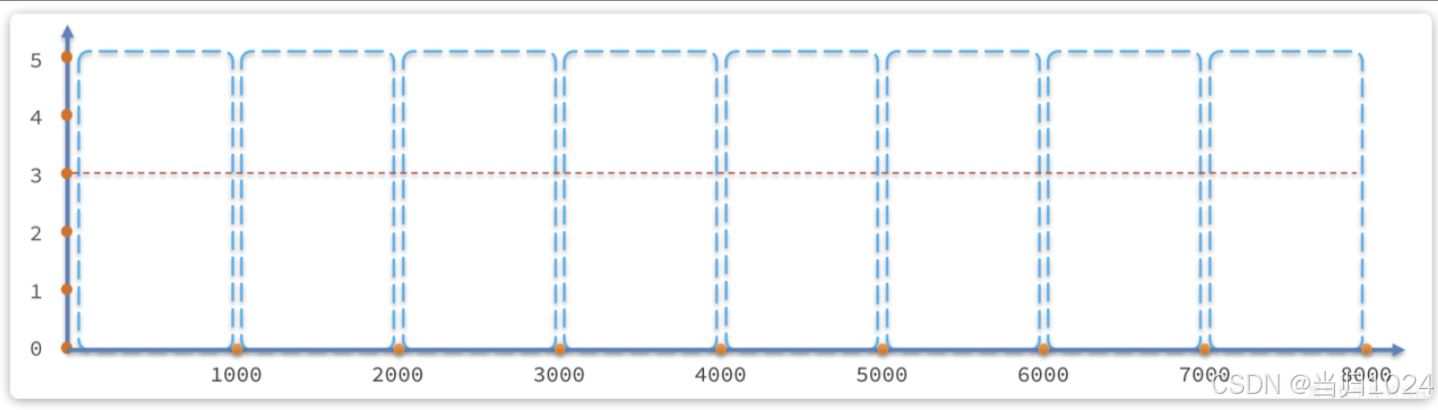
4.2.1.固定窗口計數
要了解滑動窗口計數算法,我們必須先知道固定窗口計數算法,其基本原理如圖:
說明:
- 將時間劃分為多個窗口,
窗口時間跨度稱為Interval,本例中為1000ms; 每個窗口維護1個計數器,每有1次請求就將計數器+1。限流就是設置計數器閾值,本例為3,圖中紅線標記- 如果計數器超過了限流閾值,則
超出閾值的請求都被丟棄。
示例:
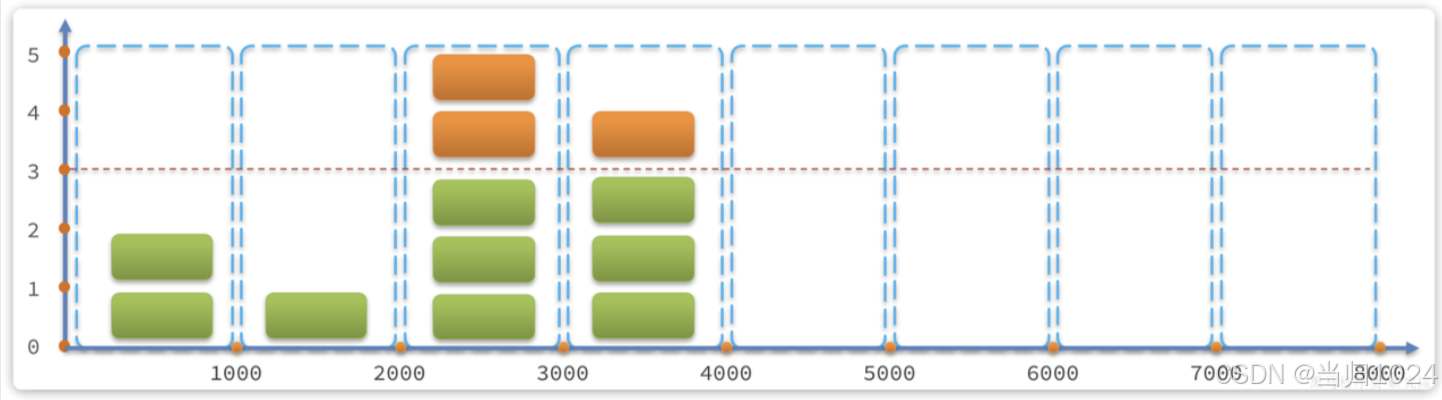
說明:
- 第1、2秒,請求數量都小于3,沒問題
- 第3秒,
請求數量為5,超過閾值,超出的請求被拒絕
但是我們考慮一種特殊場景,如圖:
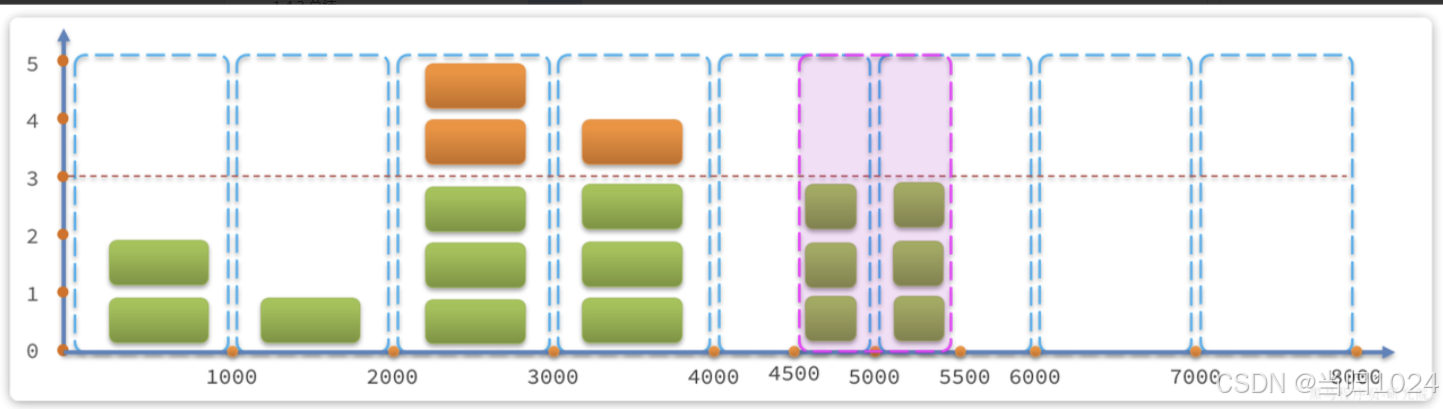
說明:
- 假如在第5、6秒,請求數量都為3,沒有超過閾值,全部放行
- 但是,如果第5秒的三次請求都是在4.5-5秒之間進來;第6秒的請求是在5-5.5之間進來。那么
從第4.5-5.5之間就有6次請求!也就是說每秒的QPS達到了6,遠超閾值。
這就是固定窗口計數算法的問題,它只能統計當前某1個時間窗的請求數量是否到達閾值,無法結合前后的時間窗的數據做綜合統計。
因此,我們就需要滑動時間窗口算法來解決。
4.2.2.滑動窗口計數
固定時間窗口算法中窗口有很多,其跨度和位置是與時間區間綁定,因此是很多固定不動的窗口。而滑動時間窗口算法中只包含1個固定跨度的窗口,但窗口是可移動動的,與時間區間無關。
具體規則如下:
- 窗口時間跨度
Interval大小固定,例如1秒 時間區間跨度為Interval / n ,例如n=2,則時間區間跨度為500ms- 窗口會隨著當前請求所在時間currentTime移動,窗口范圍從
(currentTime-Interval)時刻之后的第一個時區開始,到currentTime所在時區結束。
如圖所示:
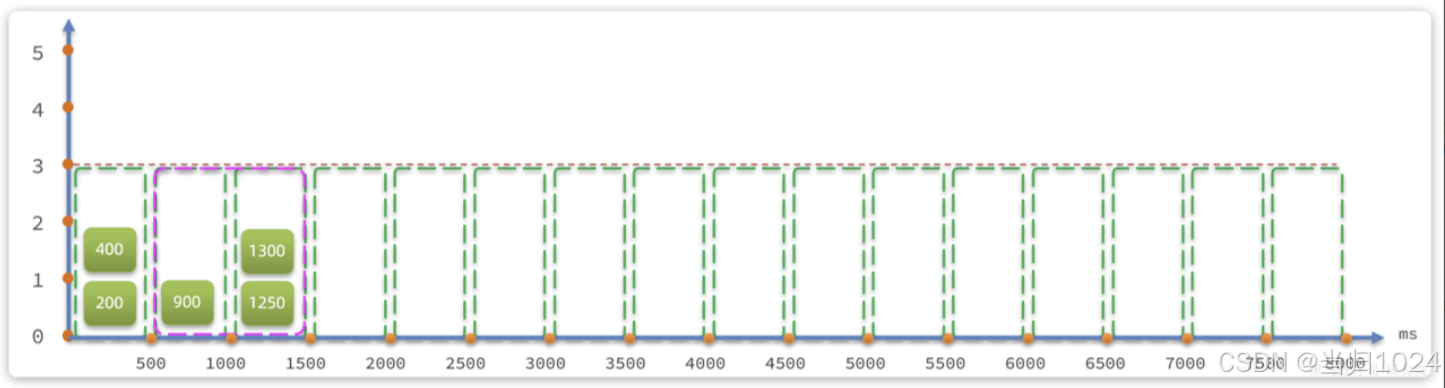
限流閾值依然為3,綠色小塊就是請求,上面的數字是其currentTime值。
- 在第1300ms時接收到一個請求,其所在時區就是1000~1500
- 按照規則,
currentTime-Interval值為300ms,300ms之后的第一個時區是500-1000,因此窗口范圍包含兩個時區:500-1000、1000-1500,也就是粉紅色方框部分 - 統計窗口內的請求總數,發現是3,未達到上限。
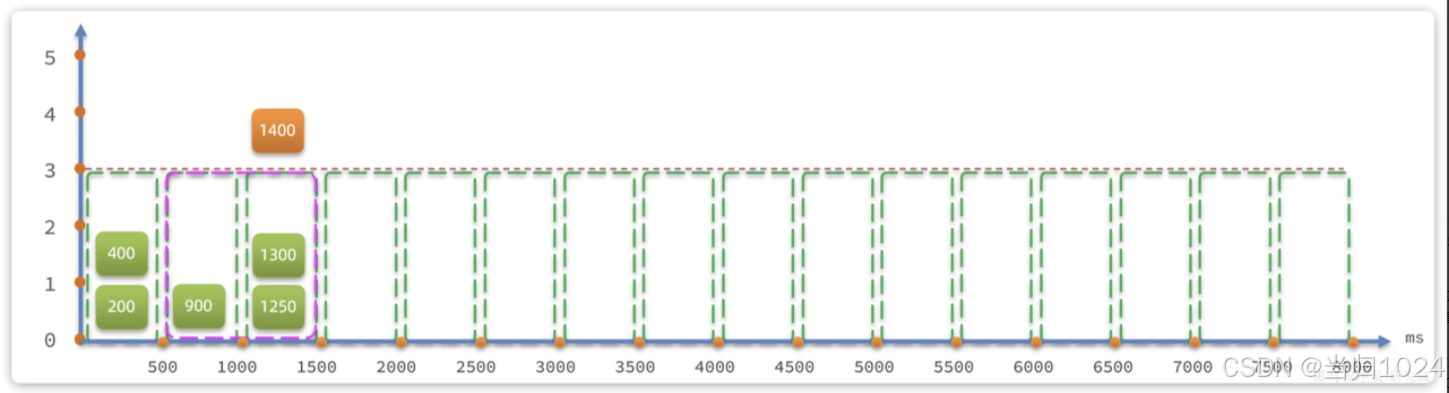
若第1400ms又來一個請求,會落在1000~1500時區,雖然該時區請求總數是3,但滑動窗口內總數已經達到4,因此該請求會被拒絕:
假如第1600ms又來的一個請求,處于1500-2000時區,根據算法,滑動窗口位置應該是1000-1500和1500~2000這兩個時區,也就是向后移動:
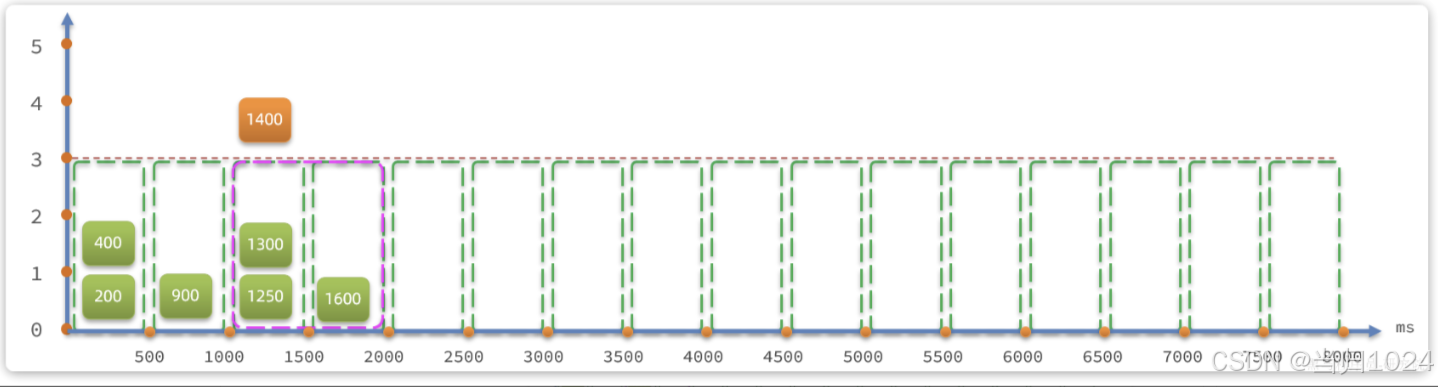
這就是滑動窗口計數的原理,解決了我們之前所說的問題。而且滑動窗口內劃分的時區越多,這種統計就越準確。
4.3.令牌桶算法
限流的另一種常見算法是令牌桶算法。Sentinel中的熱點參數限流正是基于令牌桶算法實現的。其基本思路如圖:


)










Fiddler抓包-Fiddler如何設置捕獲Firefox瀏覽器的Https會話)





