概念
? 什么是進程優先級,為什么需要進程優先級,怎么做到進程優先級這是本文需要解釋清楚的。
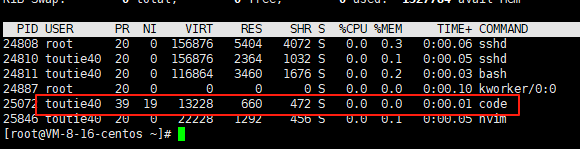
? 優先級的本質其實就是排隊,為了去爭奪有限的資源,比如cpu的調度。cpu資源分配的先后性就是指進程的優先級。優先級高的進程有優先執行的,配置進程優先級對多任務環境的Linux很有用,可以改善系統的性能。在Linux中進程的PCB也就是task_struct中優先級屬性是有幾個int類型的數字來表示的,數字越小優先級越高。這里我們可以查看一個進程的優先級和修改。我們用ps -l指令可以看到以下幾個數據
![]()
 ??
??
? 這里可以看到,PRI為39 NI值為19,這是我修改以后的數值,原本是PRI 20 NI 0,即使我輸入修改100但是最后值修改了19,說明修改NI值是有范圍的?,這是為了進程調度盡量公平,不會出現個別極端進程,為什么是在這40的范圍內后續我們會講到。
進程切換
? 有了優先級就是為了在進程切換的時候進行排序,那么什么是進程切換?進程切換的核心其實就是保存上下文數據恢復上下文數據,那么什么是上下文數據,容我慢慢敘說。一個進程被被cpu調度的時候,此時它的PCB就是現在調度隊列的當前節點,在CPU內部有一套寄存器來儲存代碼和數據,其中的eip來儲存當前執行指令的下一地址,ir存儲的是當前需要執行的指令,控制器先ir讀指令執行,執行完畢又會反饋給eip寄存器。此時儲存在寄存器中的代碼和數據就是上下文數據。當前進程的時間片到了即將被切換的時候,它會將上下文數據儲存到PCB中的一個tss_struct結構體中,方便下次切換回來的時候能夠知道上一次運行到了哪里,恢復寄存器中的數據,每個程序在進程切換的時候都需要做這個事情,因為寄存器只有一套,這種行為是對進程代碼數據運行的一種保護,如果不做保護就無法進行調度與切換。
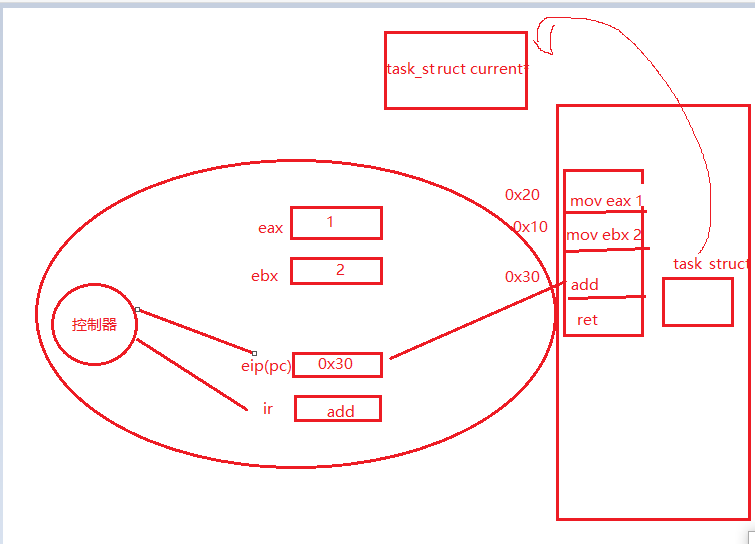
? 這里可以參考Linux0.11的內核代碼發現上下文數據確實是保存在tss之中,但是在現在的內核中由于保護算法已經過于復雜了,沒有十章八章難以敘述,所以而且不方便觀察

Linux真實調度算法
? 說了這么多優先級的本質還是為了更好的了解Lniux調度算法。這個算法并不是簡單的FIFO調度,cpu在調度進程時會在一個runqueue結構體中選擇需要調度的進程,這個runqueue主要由一個有兩個元素queue結構體數組,兩個指向queue結構體數組的指針,*active和*expored即活躍的和過期的,以下用示意圖說明。
??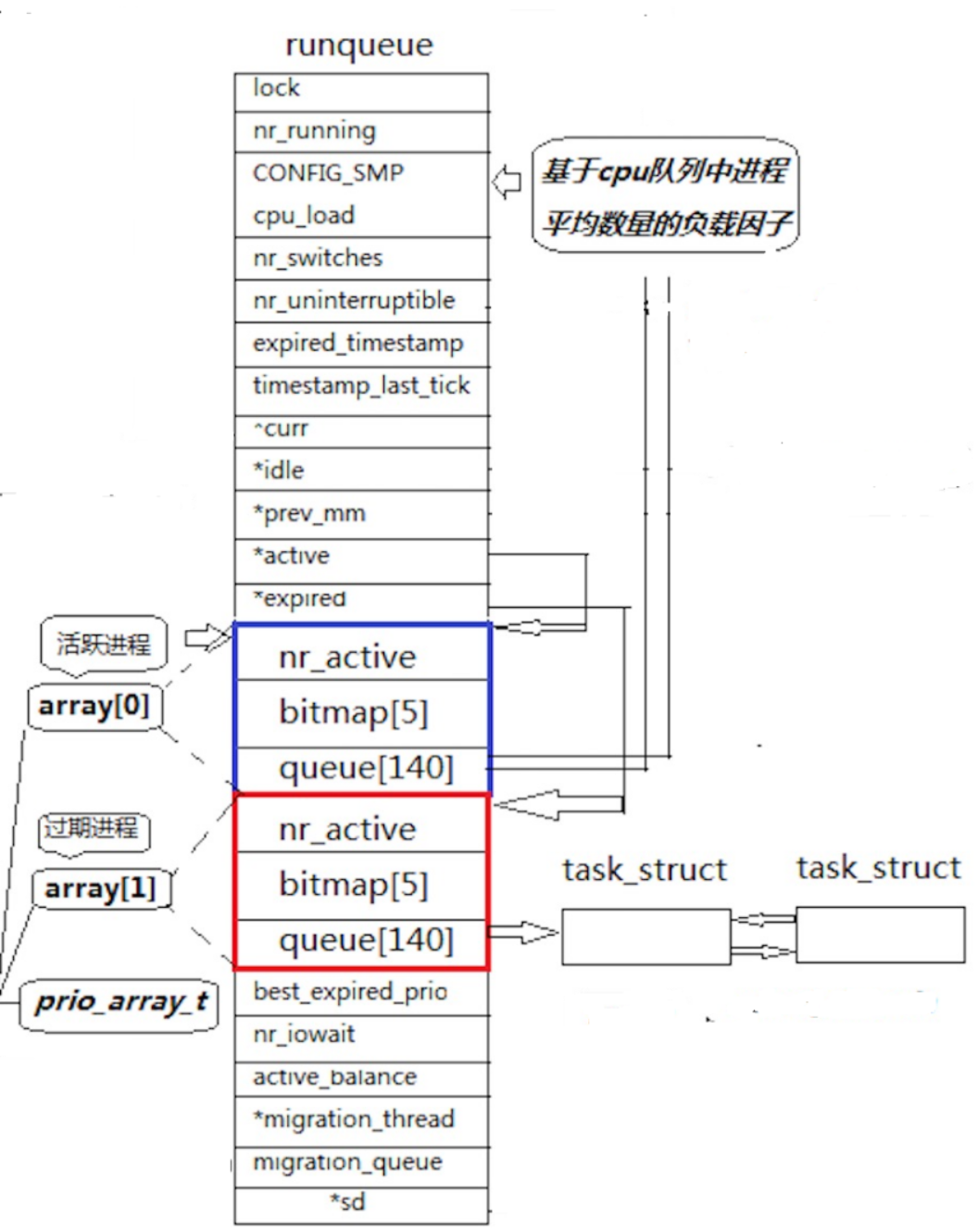
? 我們可以看到這這兩個數組的元素的結構體時由一個int 類型的nr_active,和一個有五個元素int類型的bitmap數組組成的。*active和*expored指針分別指向這兩個數組元素,cpu調度時只會從活躍指針這個結構體中的queue隊列來調度進程,這個隊列通常前一百位是不用的,而后四十位就是對應我們上面所提到的優先級范圍,40這個范圍就是因為隊列中只有四十個位置是儲存進程的。這個隊列每個元素下又掛著一個哈希桶,所以每個相同優先級的進程都會被掛在同一個桶中,調度的時候按照隊列先進先出的規則被調度,當這個優先級桶的元素空了cpu才會調度下一個優先級的進程。其中這里的nr_active是一個計數器,記錄當前隊列中還有多少個進程,bitmap是為了提高cpu調度效率而存在的,它用5*32個比特位來表示當前調度queue隊列中哪個優先級有進程再去這個地方調度進程,而不是進行遍歷隊列查找再調度。過期隊列上放置的進程,都是時間?耗盡的進程和新插入的進程,當活動隊列上的進程都被處理完畢之后,對過期隊列的進程進?時間?重新計算。active指針永遠指向活動隊列,?expired指針永遠指向過期隊列, 可是活動隊列上的進程會越來越少,過期隊列上的進程會越來越多,因為進程時間?到期時?直都存在的,所以在合適的時候交換active指針和expired指針的內容,就相當于有具有了?批新的活動進程。這個合適的時候就是當活躍進程nr_active計數器為0的時候,此時兩個兩個隊列就會被調換開始新一輪的調度。注意結束的進程是不會進入過期隊列的,而是會被父進程接管并釋放。
? ?在系統當中查找?個最合適調度的進程的時間復雜度是?個常數,不隨著進程增多?導致時間成 本增加,我們稱之為進程調度O(1)算法!Linux中的內核調度算法就是進程調度O(1)算法。
? 順便提到一點Linux中的task_struct中的鏈式結構并不是和普通雙鏈表那樣將節點和屬性放在一起,它的鏈表節點中只有next節點和prev節點,然后在task_struct中和其他屬性一起儲存。這樣做的好處是能夠讓一個task_struct在多個隊列(調度和阻塞)中存在,而不需要將相同的進程屬性放在不同的鏈表之中再鏈接。如圖所示
 ?
?
補充?
? 那么有的同學會問了只有鏈表節點如何訪問數據,每個數據類型的偏移量相對于結構體指針是固定的,我們可以通過鏈表節點的地址和偏移量來找到當前結構體指針再訪問其他的數據。我們可以通過offseto這個宏來獲得該成員相對于0地址的偏移。
#define offsetof(type, member) ((size_t)&(((type *)0)->member))這里有一個代碼可以方便大家理解具體過程
#include <iostream>#define offsetof(type, member) ((size_t)&(((type *)0)->member))
using namespace std;int main()
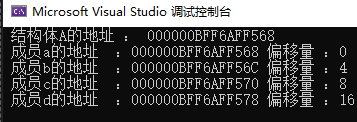
{struct A{int a;int b;float c;double d;};A instanceA; // Renamed variable to avoid conflict with struct namecout << " 結構體A的地址 : " << &instanceA << endl;cout << " 成員a的地址 :" << &instanceA.a << " 偏移量 :" << offsetof(A, a) << endl;cout << " 成員b的地址 :" << &instanceA.b << " 偏移量 :" << offsetof(A, b) << endl;cout << " 成員c的地址 :" << &instanceA.c << " 偏移量 :" << offsetof(A, c) << endl;cout << " 成員d的地址 :" << &instanceA.d << " 偏移量 :" << offsetof(A, d) << endl;return 0;
}? 我們可以看到兩次運行的各個成員地址都不一樣,但是偏移量都是相同的?
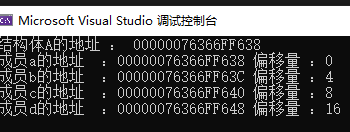
? 然后我們就可以通過這樣的方法來找到對象本身從而訪問其他的數據
int main() {A instanceA;int* pB = &instanceA.b;A* pStruct = (A*)((char*)pB - offsetof(A, b));cout << "instanceA 地址: " << &instanceA << endl;cout << "通過成員b地址和偏移量得到的結構體地址: " << pStruct << endl;return 0;
}![]()

)










Fiddler抓包-Fiddler如何設置捕獲Firefox瀏覽器的Https會話)






