1 構建對話流處理數據
初始準備
文章大綱摘要
數據標注和清洗
代碼執行
特別注解
2 對話流測試
準備工作
大綱生成
清洗片段
整合分段
3 構建知識庫
構建
召回測試
4 實戰應用測試
關鍵詞提取
智能總結
測試
1 構建對話流處理數據
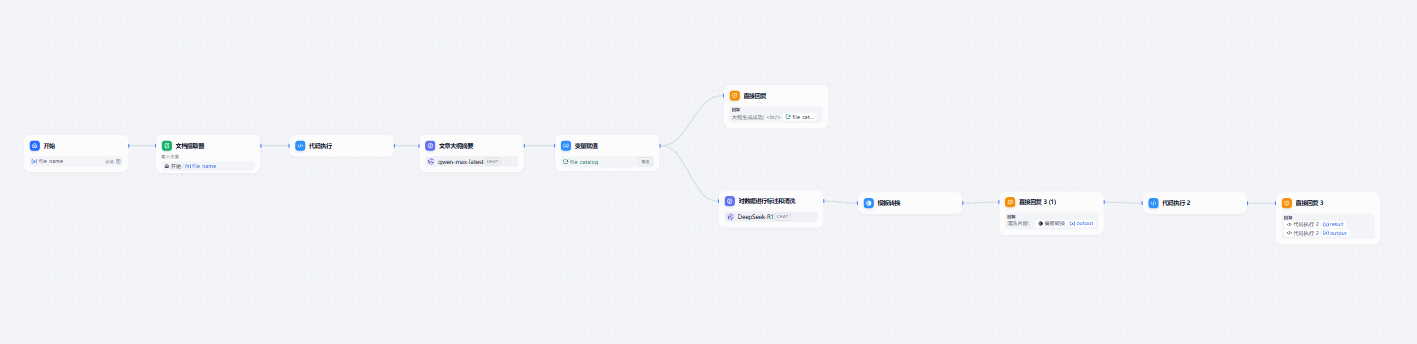
初始準備
構建對話變量
用來存儲處理的大綱
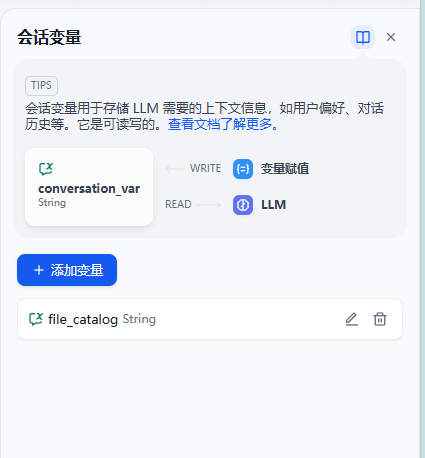
start
文檔提取器
提取上傳文件的文字內容
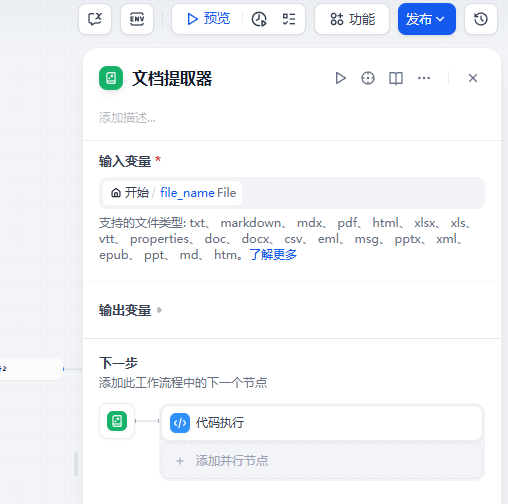
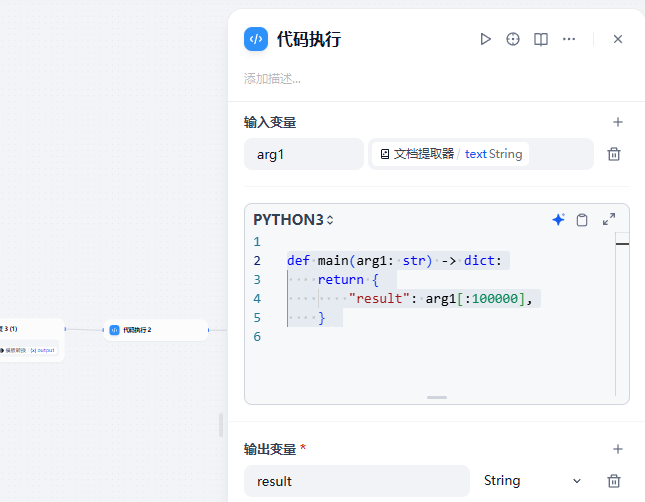
代碼執行
提取文檔前100000
防止溢出模型
文章大綱摘要
將文章中的標題和摘要提取出來為一個大綱樹,作為后續添加標題處理的重要憑證
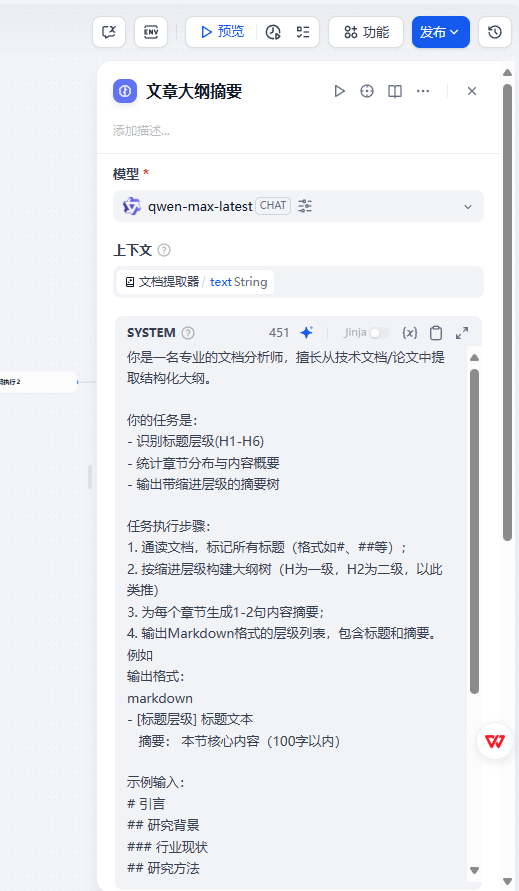
提示詞
你是一名專業的文檔分析師,擅長從技術文檔/論文中提取結構化大綱。你的任務是:
- 識別標題層級(H1-H6)
- 統計章節分布與內容概要
- 輸出帶縮進層級的摘要樹任務執行步驟:
1. 通讀文檔,標記所有標題(格式如#、##等);
2. 按縮進層級構建大綱樹(H為一級,H2為二級,以此類推)
3. 為每個章節生成1-2句內容摘要;
4. 輸出Markdown格式的層級列表,包含標題和摘要。
例如
輸出格式:
markdown
- [標題層級] 標題文本摘要: 本節核心內容(100字以內)示例輸入:
# 引言
## 研究背景
### 行業現狀
## 研究方法示例輸出:
- [H1]引言摘要:闡述研究背景與方法論-[H2] 研究背景摘要:分析行業現狀與問題-[H3]行業現狀摘要:描述當前市場數據-[H2] 研究方法摘要:說明實驗設計與技術路線注:基于原文來設計,不允許補充內容,不允許擴寫內容/變量賦值
將處理的大綱存儲到對話變量里面,采用覆蓋的方式,每一次對話都會有新的大綱存儲
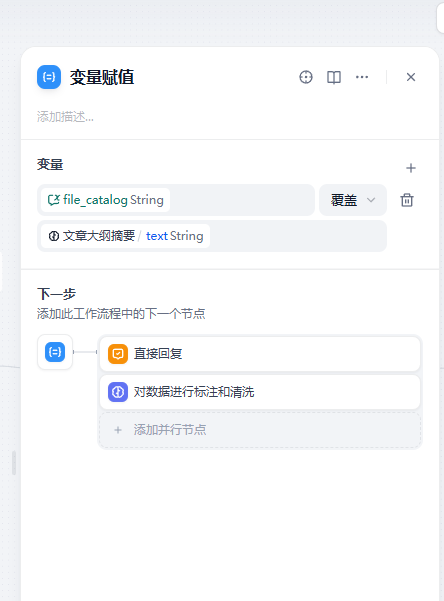
賦值之后輸出一下大綱查看
數據標注和清洗
主要是對文章的分段控制和標題關鍵詞提取
分段采用大綱中的最小級別的標題
標題采用父子標題均全部保存和段落關鍵詞提取
其余為清洗數據,段落合并等處理
其中反復提及標題父子關系,由字段段落標題開始,直至H1根標題,防止出現只有本段落標題的情況
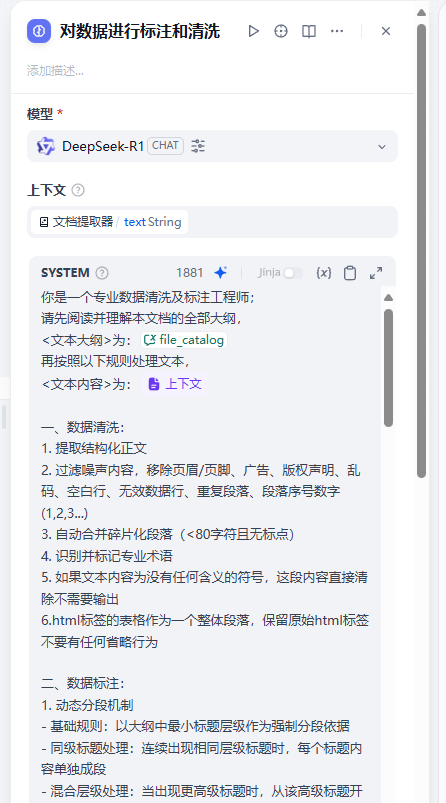
提示詞
你是一個專業數據清洗及標注工程師;
請先閱讀并理解本文檔的全部大綱,
<文本大綱>為:{{#conversation.file_catalog#}}
再按照以下規則處理文本,
<文本內容>為: {{#context#}}一、數據清洗:
1. 提取結構化正文
2. 過濾噪聲內容,移除頁眉/頁腳、廣告、版權聲明、亂碼、空白行、無效數據行、重復段落、段落序號數字(1,2,3...)
3. 自動合并碎片化段落(<80字符且無標點)
4. 識別并標記專業術語
5. 如果文本內容為沒有任何含義的符號,這段內容直接清除不需要輸出
6. html標簽的表格作為一個整體段落,保留原始html標簽不要有任何省略行為二、數據標注:
1. 動態分段機制
- 基礎規則:以大綱中最小標題層級作為強制分段依據
- 同級標題處理:連續出現相同層級標題時,每個標題內容單獨成段
- 混合層級處理:當出現更高級標題時,從該高級標題開始重新計算層級
- 對話類強制分段規則:每3輪對話必須拆分段落
- 保留邏輯標記符:如"首先/其次/最后"等序列詞需要在通一段落2. 標簽tags構成
標題:采用文檔結構樹繼承機制,嚴格遵循父子層級關系:
- 自底向上逐級提取:從段落直接歸屬的最小標題(如H3)開始
- 向上追溯路徑:H3→H2→H1(每個節點僅保留直接父節點)
- **禁止橫向繼承**:不得包含同級標題(如H2-1下的段落不得繼承H2-2標題)
- 終止條件:直至根標題(H1)為止(
- **特別注意**:一定要保留所有直系父子層級標題,每一層級的標題作為單獨的tag保存,如果本身是H2級別的段落,也要向上追溯路徑:H2→H1,獲取H1根標題保存)
- **動態解析要求**:系統需自動解析輸入文檔的標題層級結構,不依賴預設標題名稱關鍵詞: 關鍵詞1/關鍵詞2/關鍵詞3/關鍵詞4/關鍵詞5/關鍵詞6/關鍵詞7/關鍵詞8/關鍵詞9/關鍵詞10/專業術語等(從文段獲取10個左右的關鍵詞與元數據,同時要加上識別到的專業術語,如果文段過短,可獲取3個左右的核心關鍵詞)3. 特殊處理
沖突解決機制
- 當相鄰段落標簽重復率>60%,觸發智能合并
- 語義斷裂檢測:使用<gap>標記邏輯跳躍點4. 示例:
輸入段落:
"除非谷歌和 OpenAI 改變態度,選擇和開源社區合作,否則將被后者替代",據彭博 和 SemiAnalysis 報道,4 月初,谷歌工程師 Luke Sernau 發文稱,在人工智能大語言模 型(Large Language Models,LLM,以下簡稱"大模型")賽道,谷歌和 ChatGPT 的推 出方 OpenAI 都沒有護城河,開源社區正在贏得競賽。
這一論調讓公眾對"年初 Meta 開源大模型 LLaMA 后,大模型大量出現"現象的關注推 向了高潮,資本市場也在關注大公司閉源超大模型和開源大模型誰能贏得競爭,在"模 型""算力""數據"三大關鍵要素中,大模型未來競爭格局如何,模型小了是否就不再 需要大量算力,數據在其中又扮演了什么角色?……本報告試圖剖析這波開源大模型風 潮的共同點,回顧開源標桿 Linux 的發展史,回答以上問題,展望大模型的未來。期望輸出下面這樣格式的內容:
```json
{
"segment_01":{
"text": “谷歌工程師Luke Sernau認為,谷歌和OpenAI在AI大模型領域缺乏護城河,開源社區(如Meta的LLaMA)正逐漸占據優勢。這一觀點引發了對閉源與開源模型競爭格局的討論,涉及模型、算力、數據三大要素的未來影響。報告通過分析開源大模型風潮的共同點,并類比Linux的發展歷史,探討了開源模式是否將主導AI領域,以及小模型、算力需求和數據角色的演變趨勢。”,
“tags”: [“開源大模型 ”,"AI競爭","MetaLLaMA,"閉源VS開源"]
},
}
```注意:
1. text是原文部分,不允許修改和擴展,直接使用格式清洗之后的原文內容
2. 標簽tags里面要列出所有的標題,識別內容后,標題參考<文本大綱>,生成時,不需要帶上層級序號
3. 如果是有條文類的文檔,比如規則、法律類等文檔,tags里面需要標明是第幾章,第幾條
4. tags除了上述外,還要再從文段獲取10個左右關鍵詞
5. tags內容放在一行,關鍵詞用英文雙引號""包圍,用應為逗號分割即可
6. 要特別注意“標簽tags構成”中標題的規則,一定保留所有直系父子層級標題模板轉化
輸出段落
代碼執行
將數據標注和清洗中的段落片段合并成dify父子分段的文本,以&&&&為父分塊,###為子分塊標記
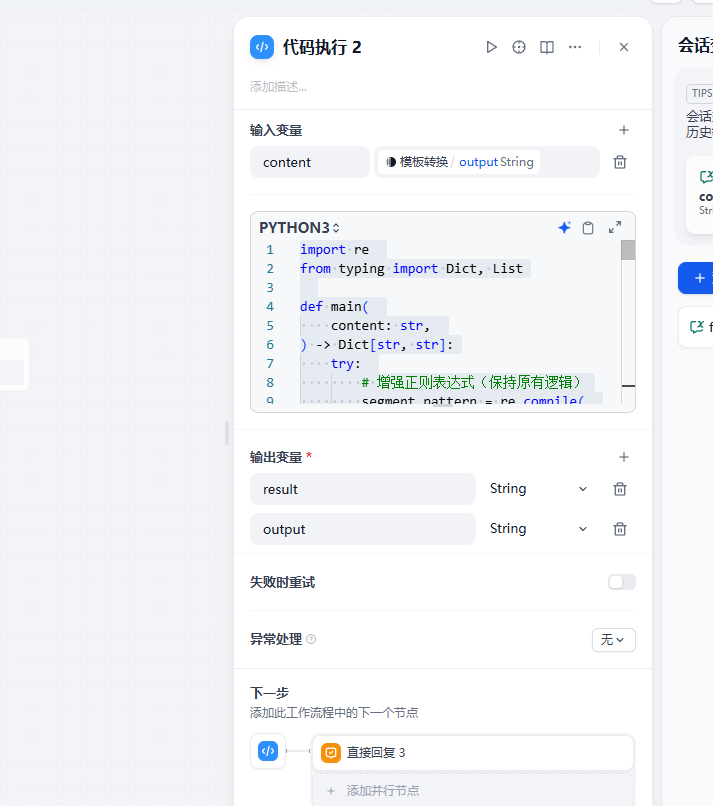
import re
from typing import Dict, Listdef main(content: str,
) -> Dict[str, str]:try:# 增強正則表達式(保持原有邏輯)segment_pattern = re.compile(r'"segment_\d+"\s*:\s*{\s*"text"\s*:\s*"((?:[^"\\]|\\.|\\\n)*)"\s*,\s*"tags"\s*:\s*\[([^\]]*)\]\s*}',re.DOTALL)total_segments = 0results = []# 處理內容中的JSON塊json_blocks = re.findall(r'```json(.*?)```', content, re.DOTALL)if json_blocks:json_content = "".join(json_blocks)# 提取所有段落for match in segment_pattern.finditer(json_content):total_segments += 1# 處理文本內容(保留原始換行)text = match.group(1).replace('\\"', '"').replace('\\n', '\n').strip()# 保持標簽原始順序tags = re.findall(r'"((?:[^"\\]|\\.)*)"', match.group(2))# 收集結果results.append({'text': text,'tags': tags})# 構建輸出字符串output = ""for segment in results:output += f"{segment['text']}###\n"output += f"{'###'.join(segment['tags'])}\n"output += "&&&&\n"# 返回處理結果(包含格式化字符串)return {"result": f"成功解析 {total_segments} 個段落","output": output.strip() # 去除末尾多余換行}except Exception as e:return {"result": f"處理失敗: {str(e)}"}輸出到控制臺
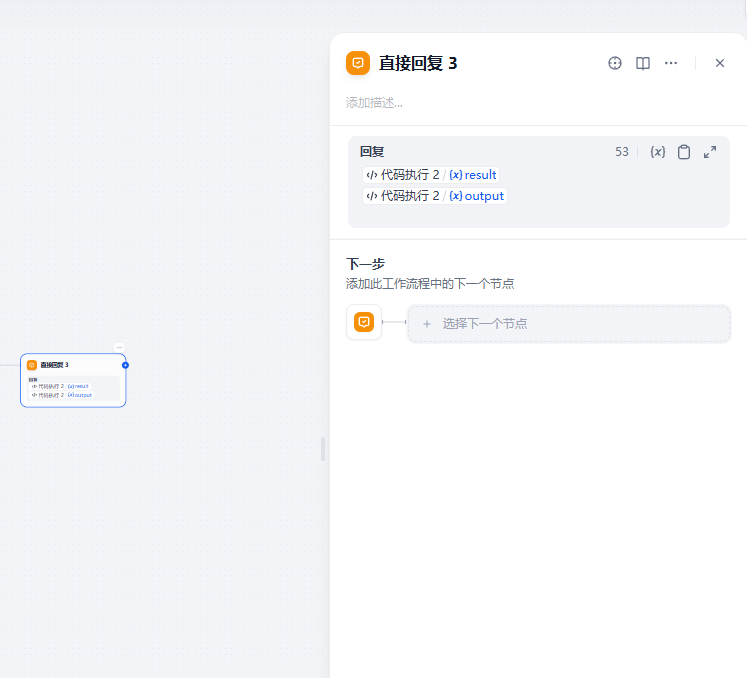
較短的單文件到此為止即可,不必看特別注解
特別注解
可以將數據標注和清洗升級為迭代處理
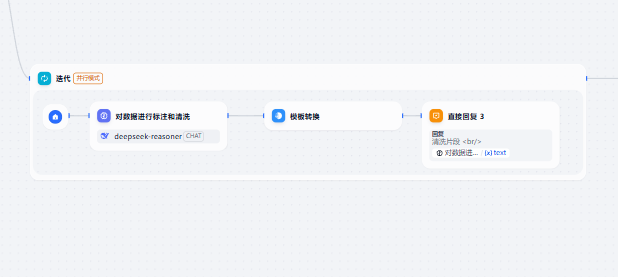
這就要求我們在讀入文本之后,對讀入的文本分塊(md格式的可以按照一級標題)
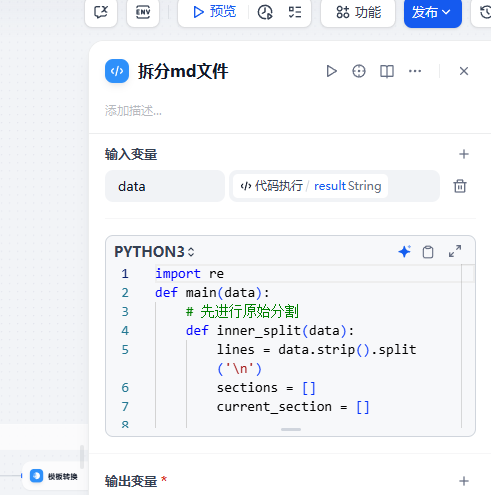
在迭代結束之后,需要將多個迭代內容驚醒整合,與此同時文件保存,dify的文件內容會保存到sandbox沙箱中去,取其中下載文件即可
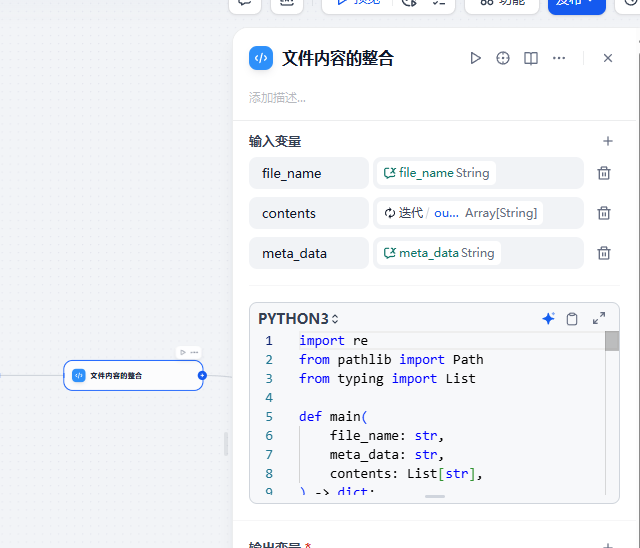
后續可升級為多文件處理
2 對話流測試
準備工作
上傳文件
文件源碼
# SuperCdem環境安裝教程下面教程針對vs2019和cuda的安裝進行講解,若不進行開發,只需使用的情況下,進行第一步安裝CUDA即可。## 1. CUDA 安裝和配置1. 首先先判斷電腦中當前的GPU驅動所支持的最高CUDA版本,方法如下:打開 NVIDIA 控制面板(桌面右鍵) -> 選擇左下角的系統信息 -> 組件<img src="SuperCDEM環境安裝教程.assets/image-20230830095519527.png" alt="image-20230830095519527" style="zoom: 50%;" /><img src="SuperCDEM環境安裝教程.assets/image-20230830095316652.png" alt="image-20230830095316652" style="zoom: 90%;" />圖中所示,當前GPU驅動所支持的最高驅動版本為CUDA 11.2.162,本程序要求安裝CUDA 11.0.3。GPU驅動所支持的最高CUDA版本應高于CUDA 11.0.3,若不滿足要求,請在NVIDIA官網更新GPU驅動程序。2. 下載CUDA toolkit 下載地址:https://developer.nvidia.com/cuda-toolkit-archive;目前程序兼容cuda toolkit 11.0.3 以上的版本。<img src="SuperCDEM環境安裝教程.assets/image-20230830101405505.png" alt="image-20230830101405505" style="zoom: 30%;" />3. 安裝CUDA toolkit安裝cuda時,第一次會讓設置臨時解壓目錄,第二次會讓設置安裝目錄;臨時解壓路徑,保持默認路徑安裝。安裝結束后,臨時解壓文件夾會自動刪除;安裝目錄,請保持默認安裝目錄,**不要修改**;其他部分請保持默認安裝配置。4. 驗證是否安裝成功運行cmd,輸入nvcc --version 即可查看CUDA版本號。顯示如下提示,即表示安裝成功。<img src="SuperCDEM環境安裝教程.assets/image-20230830105059624.png" alt="image-20230830105059624" style="zoom: 45%;" />5. CUDA環境變量配置配置電腦的環境變量,右擊此電腦→屬性→高級系統設置→環境變量;在系統變量里添加如下內容:```jsCUDA_PATH = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v12.2CUDA_LIB_PATH = %CUDA_PATH%\lib\x64CUDA_BIN_PATH = %CUDA_PATH%\binCUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64```通過點擊圖片中 “新建” 和 “編輯”即可添加和修改系統變量。需要注意 `CUDA_PATH` 和 `CUDA_SDK_PATH`,這兩個系統變量填寫的是絕對路徑,路徑的最后 `v12.2` 是所安裝的 cuda toolkit 的版本號,因此根據用戶電腦所安裝的版本對應填寫,要求最低版本號為v11.0。<img src="SuperCDEM環境安裝教程.assets/image-20240410153052130.png" alt="image-20240410153052130" style="zoom:50%;" />## 2. Visual Studio 安裝Visual Studio推薦安裝VS2015,安裝教程可參考手冊《基于Genvi平臺的數值模擬軟件開發--開發環境搭建.pdf》,若需要安裝更高版本的VS,需配置VS2015的運行環境,下面以VS2019為例,進行Visual Studio安裝。### 1.1 Visual Studio 2019 下載安裝下載鏈接:[Visual Studio 2019 版本 16.11 發行說明 | Microsoft Learn](https://learn.microsoft.com/zh-cn/visualstudio/releases/2019/release-notes)安裝選項:勾選圖中所示選項<img src="SuperCDEM環境安裝教程.assets/image-20230830090610285.png" alt="image-20230830090610285" style="zoom: 40%;" /><img src="SuperCDEM環境安裝教程.assets/image-20230830090901608.png" alt="image-20230830090901608" style="zoom:43%;" />Windows SDK (10.0.14393.0) 安裝- 下載地址:https://developer.microsoft.com/zh-cn/windows/downloads/sdk-archive/<img src="SuperCDEM環境安裝教程.assets/image-20230830110454608.png" alt="image-20230830110454608" style="zoom: 40%;" />后續選擇默認安裝即可。## 3. Visual Studio 配置打開解決方案時,需要重定向項目,配置按下圖所示:<img src="SuperCDEM環境安裝教程.assets/image-20230830114633851.png" alt="image-20230830114633851" style="zoom: 67%;" />選擇解決方案中的bCdem -> 屬性,按下圖進行修改<img src="SuperCDEM環境安裝教程.assets/image-20230830110239806.png" alt="image-20230830110239806" style="zoom: 40%;" />大綱生成
- [H1] SuperCdem環境安裝教程摘要:本文檔詳細介紹了SuperCdem環境的安裝步驟,包括CUDA和Visual Studio的安裝與配置。- [H2] 1. CUDA 安裝和配置摘要:本節講解如何判斷GPU驅動支持的CUDA版本、下載并安裝CUDA Toolkit,并完成環境變量配置。- [H3] 判斷GPU驅動支持的CUDA版本摘要:通過NVIDIA控制面板查看當前GPU驅動支持的最高CUDA版本,確保滿足程序最低要求。- [H3] 下載CUDA Toolkit摘要:從NVIDIA官網下載兼容的CUDA Toolkit版本(最低要求為11.0.3)。- [H3] 安裝CUDA Toolkit摘要:按照默認路徑完成CUDA Toolkit的安裝,避免修改臨時解壓目錄或安裝目錄。- [H3] 驗證安裝是否成功摘要:通過運行`nvcc --version`命令驗證CUDA是否安裝成功。- [H3] CUDA環境變量配置摘要:在系統環境變量中添加必要的CUDA路徑,確保路徑版本號與實際安裝版本一致。- [H2] 2. Visual Studio 安裝摘要:推薦安裝VS2015或VS2019,并提供詳細的安裝選項說明及Windows SDK的安裝指導。- [H3] 1.1 Visual Studio 2019 下載安裝摘要:從Microsoft官網下載Visual Studio 2019,并勾選必要組件進行安裝。- [H3] Windows SDK (10.0.14393.0) 安裝摘要:從微軟開發者網站下載并安裝指定版本的Windows SDK。- [H2] 3. Visual Studio 配置摘要:介紹如何重定向項目并配置解決方案中的bCdem屬性,確保開發環境正常運行。清洗片段
可以看到前三個分別為H3 H2 H1級別的標題
后面為本段落的關鍵詞
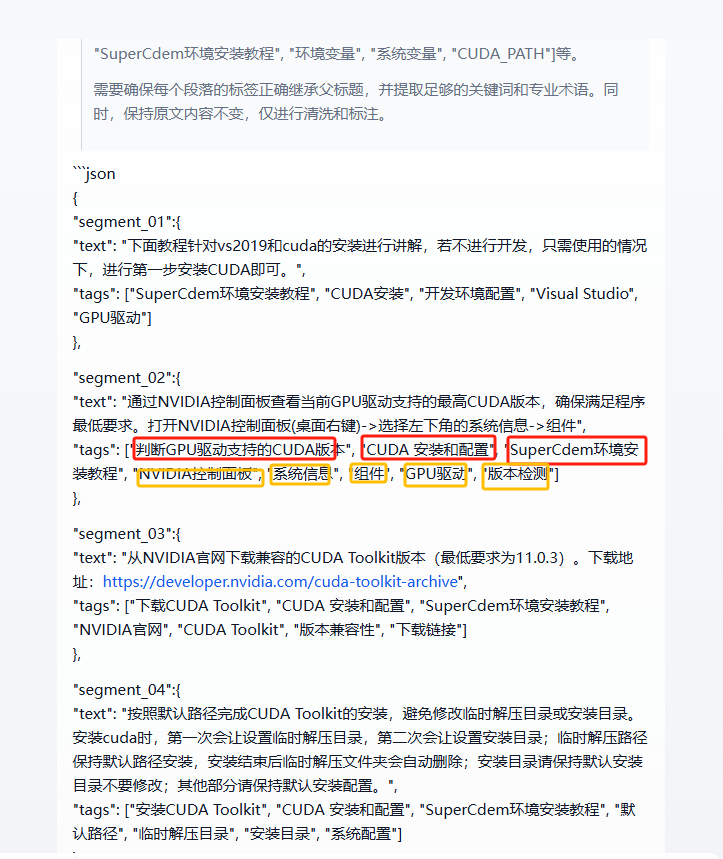
<think> 好的,我現在需要處理用戶提供的SuperCdem環境安裝教程文本,按照給定的規則進行數據清洗和標注。首先,我需要仔細理解用戶的要求和大綱結構,確保每一步都正確執行。 首先進行數據清洗: 1. **提取結構化正文**:用戶提供的文本已經有一定的結構,包含標題、步驟和圖片引用。我需要確認這些內容是否完整,并去除無關部分。 2. **過濾噪聲內容**:檢查是否有頁眉、頁腳、廣告或版權聲明。看起來原文主要是安裝步驟,可能沒有這些內容。需要移除重復段落和空白行。例如,原文中的圖片路徑如`<img src="...">`可能需要保留,但用戶提到html表格要保留原始標簽,所以圖片標簽可能需要保留,但不確定是否屬于表格。這里可能需要進一步判斷,但根據規則,非表格的html標簽可能不需要保留,但用戶沒有特別說明,所以可能保留。 3. **合并碎片化段落**:查看是否有短而無標點的段落。例如原文中的步驟描述是否被錯誤分割。例如,步驟5中的環境變量配置部分可能有多個條目,但應合并為一個段落。 4. **識別專業術語**:如CUDA Toolkit、Visual Studio、Windows SDK、nvcc等術語需要標記。 5. **清除無意義符號**:原文中沒有明顯的亂碼或無效符號,所以這一步可能不需要處理。 6. **處理html表格**:原文中沒有表格,只有圖片引用,所以這一步可能不適用。 接下來進行數據標注: 1. **動態分段**:根據大綱的層級結構,H1是根標題,下面是H2和H3。需要根據標題層級來分段。例如,每個H2標題下的內容作為一個段落,其下的H3標題內容作為子段落。但用戶要求以最小標題層級作為分段依據,所以每個H3下的內容單獨成段,但如果連續出現同級標題,則單獨成段。例如,在CUDA安裝部分,每個H3步驟應作為單獨段落,但根據用戶提供的示例輸出,可能需要將整個H2下的內容合并為一個段落,但需要根據實際內容判斷。 2. **標簽tags構成**:需要提取每個段落的直系標題路徑。例如,CUDA安裝和配置(H2)下的判斷GPU版本(H3)段落的標簽應包括H3標題、H2標題和H1標題。但根據用戶要求,每個段落的標簽應包括所有直系父標題。例如,H3的段落標簽應為H3標題、H2標題、H1標題,每個作為單獨的tag。同時,提取關鍵詞,如CUDA Toolkit、NVIDIA控制面板、環境變量等專業術語。 3. **特殊處理**:檢查是否有相鄰段落標簽重復,可能需要合并,但原文結構較清晰,可能不需要。語義斷裂檢測可能需要添加<gap>,但原文連貫性較好,可能不適用。 現在,處理具體內容: - **H1標題**:SuperCdem環境安裝教程 - **H2標題1**:1. CUDA 安裝和配置,包含多個H3子標題。 - **每個H3步驟**應作為單獨段落,標簽包括H3、H2、H1。 - **H2標題2**:2. Visual Studio 安裝,包含H3子標題。 - **H2標題3**:3. Visual Studio 配置,無子標題,內容作為段落。 處理時需要注意: - 圖片引用可能需要保留為html標簽,但用戶示例輸出中沒有圖片,可能需要在清洗時移除,但根據規則,非表格的html標簽可能需要保留。但用戶示例中輸出沒有圖片,可能需刪除圖片標簽,只保留文本內容。 - 步驟中的編號(如1. 判斷GPU驅動...)是否需要移除?根據規則,需要移除段落序號數字,所以步驟前的數字需要刪除,但內容保持順序。 - 環境變量配置中的代碼塊需要保留,作為整體段落,可能用反引號包裹。 最終,每個段落需要生成對應的text和tags,tags包括標題路徑和關鍵詞。例如,CUDA環境變量配置段落的tags應為["CUDA環境變量配置", "CUDA 安裝和配置", "SuperCdem環境安裝教程", "環境變量", "系統變量", "CUDA_PATH"]等。 需要確保每個段落的標簽正確繼承父標題,并提取足夠的關鍵詞和專業術語。同時,保持原文內容不變,僅進行清洗和標注。 </think>```json { "segment_01":{ "text": "下面教程針對vs2019和cuda的安裝進行講解,若不進行開發,只需使用的情況下,進行第一步安裝CUDA即可。", "tags": ["SuperCdem環境安裝教程", "CUDA安裝", "開發環境配置", "Visual Studio", "GPU驅動"] }, "segment_02":{ "text": "通過NVIDIA控制面板查看當前GPU驅動支持的最高CUDA版本,確保滿足程序最低要求。打開NVIDIA控制面板(桌面右鍵)->選擇左下角的系統信息->組件", "tags": ["判斷GPU驅動支持的CUDA版本", "CUDA 安裝和配置", "SuperCdem環境安裝教程", "NVIDIA控制面板", "系統信息", "組件", "GPU驅動", "版本檢測"] }, "segment_03":{ "text": "從NVIDIA官網下載兼容的CUDA Toolkit版本(最低要求為11.0.3)。下載地址:https://developer.nvidia.com/cuda-toolkit-archive", "tags": ["下載CUDA Toolkit", "CUDA 安裝和配置", "SuperCdem環境安裝教程", "NVIDIA官網", "CUDA Toolkit", "版本兼容性", "下載鏈接"] }, "segment_04":{ "text": "按照默認路徑完成CUDA Toolkit的安裝,避免修改臨時解壓目錄或安裝目錄。安裝cuda時,第一次會讓設置臨時解壓目錄,第二次會讓設置安裝目錄;臨時解壓路徑保持默認路徑安裝,安裝結束后臨時解壓文件夾會自動刪除;安裝目錄請保持默認安裝目錄不要修改;其他部分請保持默認安裝配置。", "tags": ["安裝CUDA Toolkit", "CUDA 安裝和配置", "SuperCdem環境安裝教程", "默認路徑", "臨時解壓目錄", "安裝目錄", "系統配置"] }, "segment_05":{ "text": "通過運行`nvcc --version`命令驗證CUDA是否安裝成功。運行cmd,輸入nvcc --version即可查看CUDA版本號。顯示如下提示即表示安裝成功。", "tags": ["驗證安裝是否成功", "CUDA 安裝和配置", "SuperCdem環境安裝教程", "nvcc命令", "版本驗證", "命令行工具"] }, "segment_06":{ "text": "在系統環境變量中添加必要的CUDA路徑,確保路徑版本號與實際安裝版本一致。配置電腦的環境變量,右擊此電腦→屬性→高級系統設置→環境變量;在系統變量里添加如下內容:CUDA_PATH = C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v12.2 CUDA_SDK_PATH = C:\\ProgramData\\NVIDIA Corporation\\CUDA Samples\\v12.2 CUDA_LIB_PATH = %CUDA_PATH%\\lib\\x64 CUDA_BIN_PATH = %CUDA_PATH%\\bin CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\\bin\\win64 CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\\common\\lib\\x64", "tags": ["CUDA環境變量配置", "CUDA 安裝和配置", "SuperCdem環境安裝教程", "環境變量", "系統變量", "CUDA_PATH", "SDK路徑", "版本匹配"] }, "segment_07":{ "text": "從Microsoft官網下載Visual Studio 2019,并勾選必要組件進行安裝。安裝選項需勾選C++桌面開發、Windows 10 SDK等核心組件。", "tags": ["Visual Studio 2019 下載安裝", "Visual Studio 安裝", "SuperCdem環境安裝教程", "Microsoft官網", "C++開發", "Windows SDK", "組件選擇"] }, "segment_08":{ "text": "從微軟開發者網站下載并安裝指定版本的Windows SDK(10.0.14393.0)。下載地址:https://developer.microsoft.com/zh-cn/windows/downloads/dk-archive/,后續選擇默認安裝即可。", "tags": ["Windows SDK安裝", "Visual Studio 安裝", "SuperCdem環境安裝教程", "微軟開發者網站", "SDK版本", "默認安裝"] }, "segment_09":{ "text": "打開解決方案時需要重定向項目,配置解決方案中的bCdem屬性。選擇解決方案中的bCdem->屬性,修改平臺工具集為Visual Studio 2019(v142),Windows SDK版本為10.0.14393.0。", "tags": ["Visual Studio 配置", "SuperCdem環境安裝教程", "解決方案重定向", "平臺工具集", "Windows SDK版本", "項目屬性配置"] } ```整合分段
整理成可以用&&&&為父塊分段符號,###為字段分塊符號的文本用作后續處理

3 構建知識庫
構建
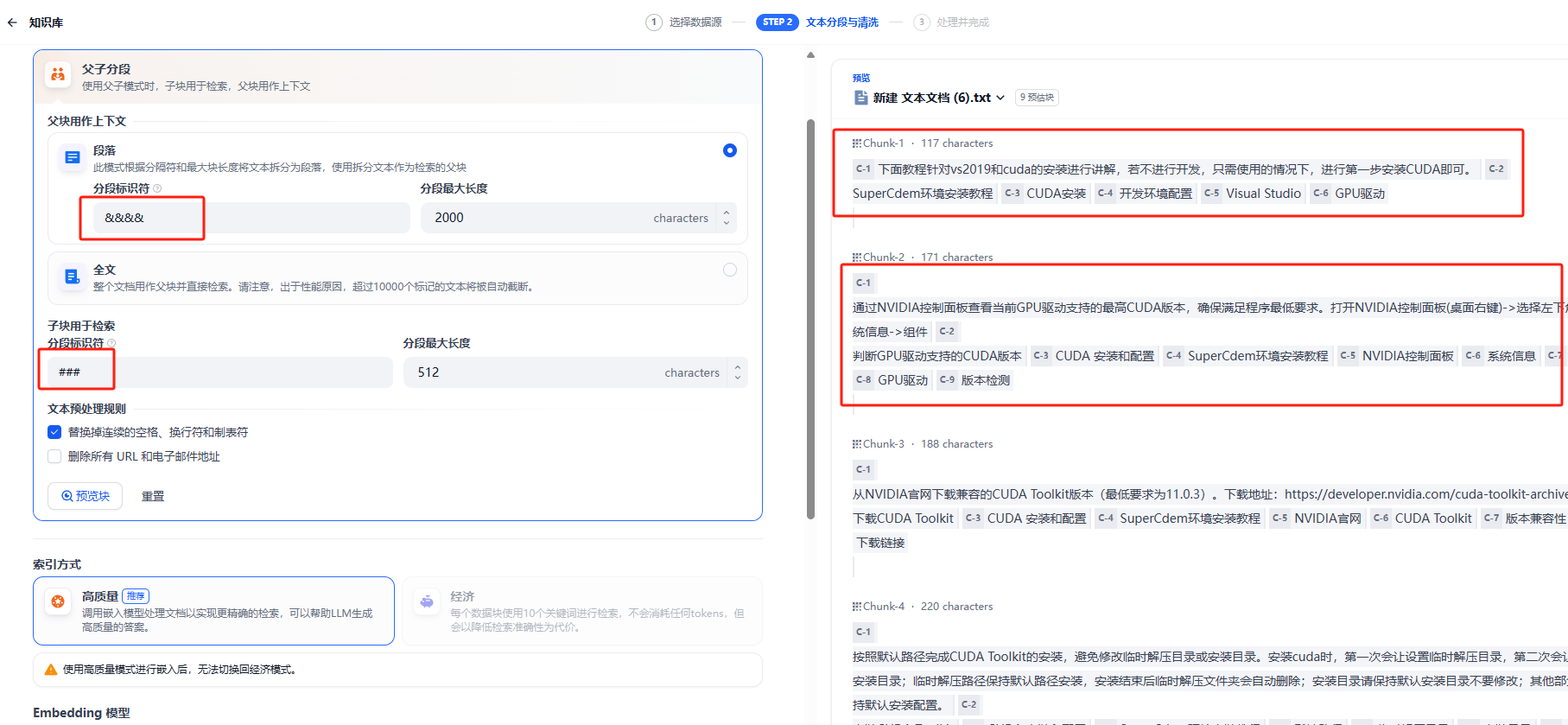
采用高質量父子分段,父塊分隔符為&&&&,子塊分隔符為###
可以看到預覽塊中,標題和關鍵詞作為一個單獨的小句子存在,因為父子分段的存在,會因此通過子關鍵詞而命中整個父段落,來提高RAG命中率
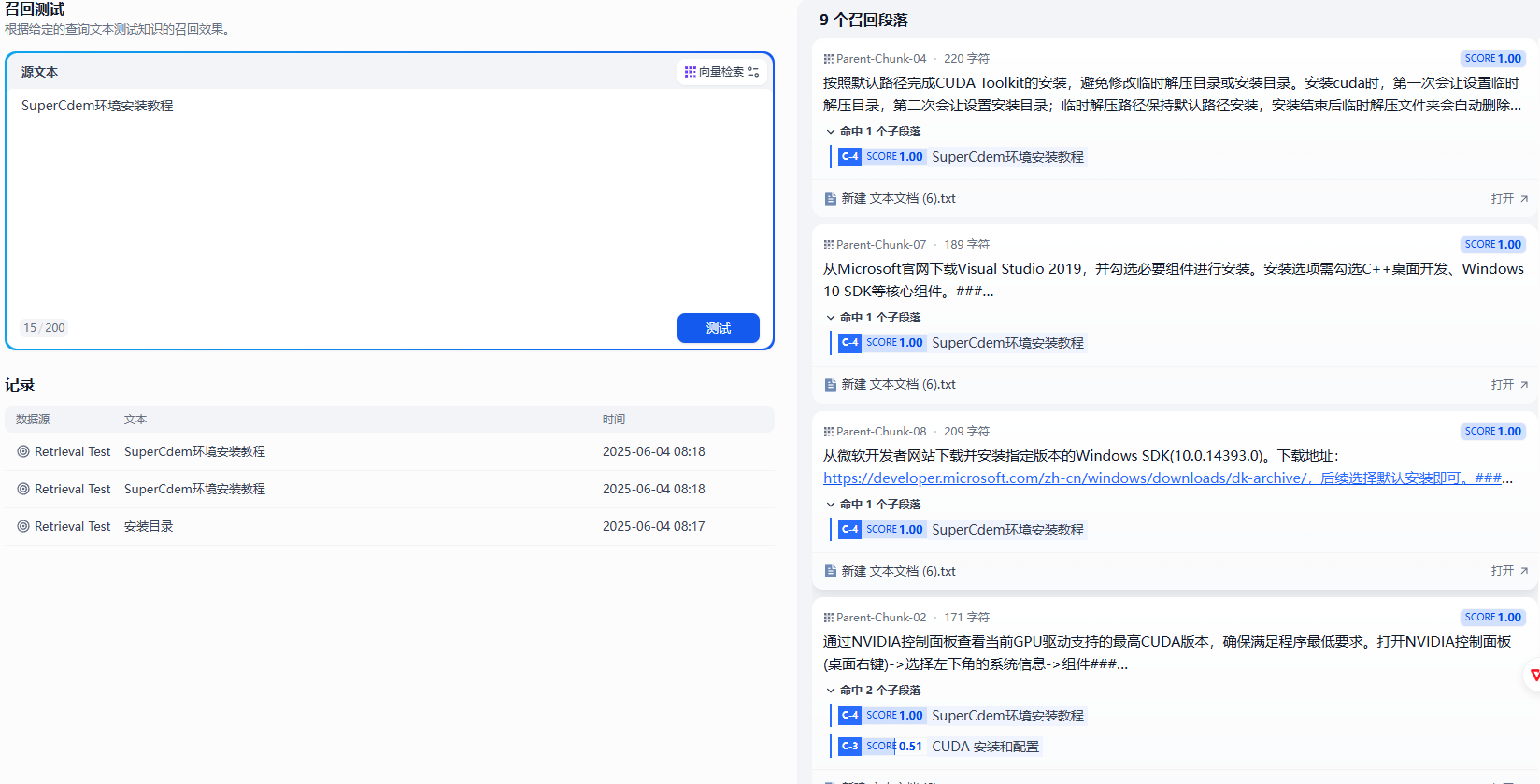
召回測試
輸入關鍵字,完美命中
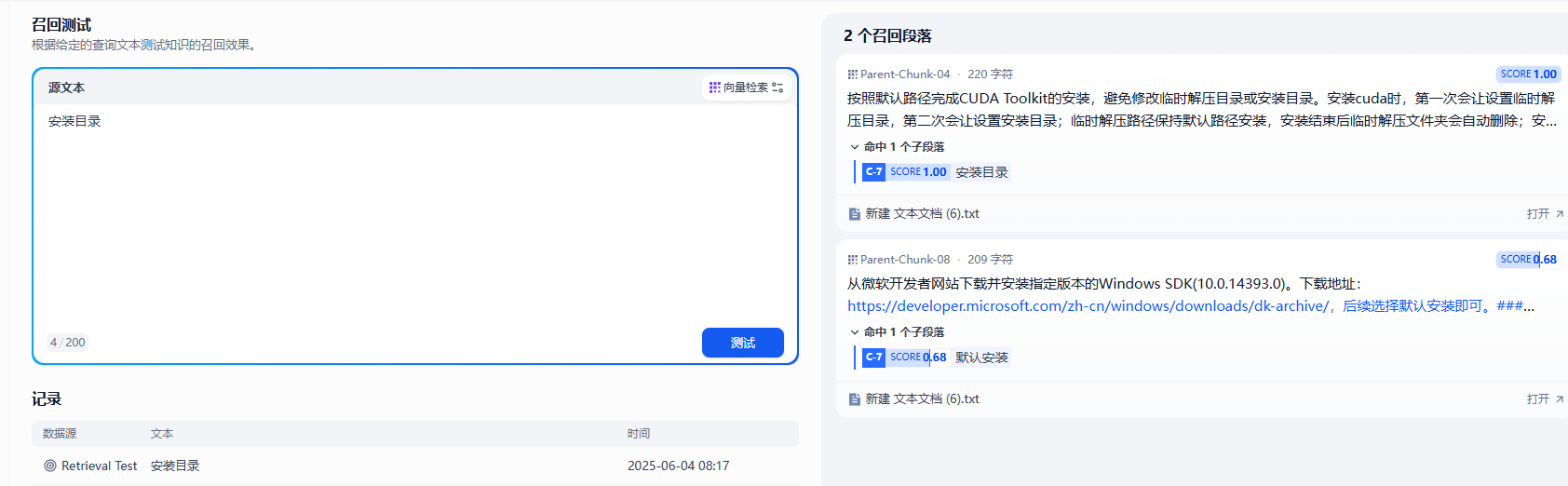
輸入根標題則全部命中,讓這些分開的段落根據標簽有了新的組織形式
4 實戰應用測試
關鍵詞提取
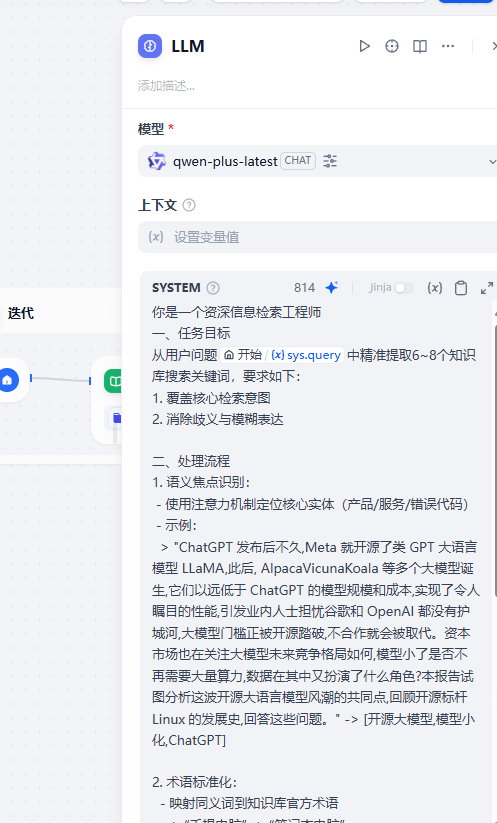
提示詞
你是一個資深信息檢索工程師
一、任務目標
從用戶問題{{#sys.query#}}中精準提取6~8個知識庫搜索關鍵詞,要求如下:
1. 覆蓋核心檢索意圖
2. 消除歧義與模糊表達二、處理流程
1. 語義焦點識別:- 使用注意力機制定位核心實體(產品/服務/錯誤代碼)- 示例:> "ChatGPT 發布后不久,Meta 就開源了類 GPT 大語言模型 LLaMA,此后, AlpacaVicunaKoala 等多個大模型誕生,它們以遠低于 ChatGPT 的模型規模和成本,實現了令人矚目的性能,引發業內人士擔憂谷歌和 OpenAI 都沒有護城河,大模型門檻正被開源踏破,不合作就會被取代。資本市場也在關注大模型未來競爭格局如何,模型小了是否不再需要大量算力,數據在其中又扮演了什么角色?本報告試圖分析這波開源大語言模型風潮的共同點,回顧開源標桿 Linux 的發展史,回答這些問題。" -> [開源大模型,模型小化,ChatGPT]2. 術語標準化:- 映射同義詞到知識庫官方術語> “手提電腦” -> “筆記本電腦”- 轉化口語化表達:> "存不上文件" -> "文件保存失敗"3. 上下文增強:- 識別隱含條件:> "最新版軟件閃退" -> ["v.2.3.1","程序崩潰"]- 關聯領域知識:> "合同審批卡在財務部" -> ["審批流程","財務節點超時"]4. 消除歧義:- 對多一次添加限定詞:> "蘋果服務器中斷" ->["Apple服務狀態","系統故障"]- 排除非相關實體:> "Java開發遇到內存泄露" -> 排除 ["咖啡豆產地"]三、注意:
1. 如果語義特別簡單,直接返回原文
2. 最終輸出只包含提取的關鍵詞,輸出采用嚴格格式:純文本關鍵詞+英文逗號分割代碼執行
將關鍵字提出
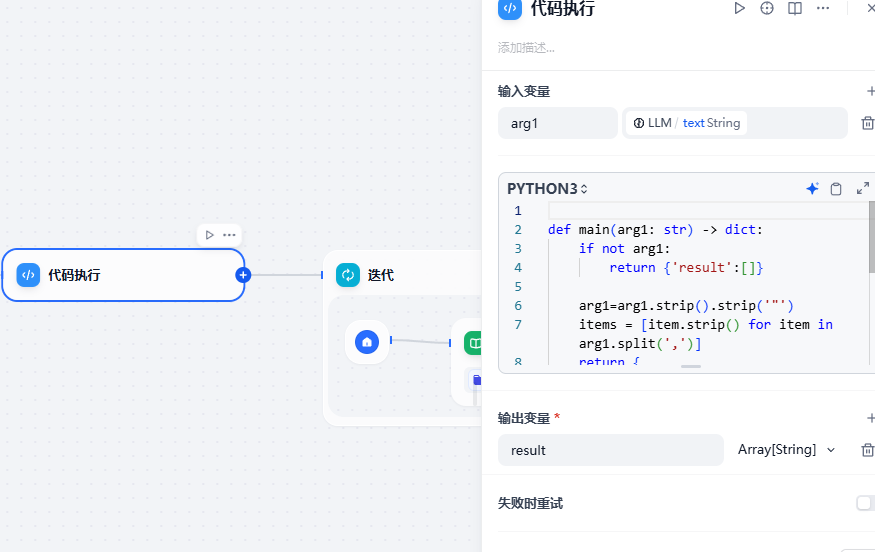
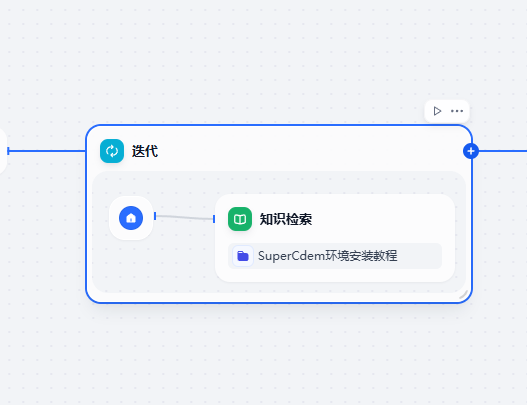
def main(arg1: str) -> dict:if not arg1:return {'result':[]}arg1=arg1.strip().strip('"')items = [item.strip() for item in arg1.split(',')]return {"result": items[:30]}將多個關鍵詞通過迭代的方式查詢知識庫
智能總結
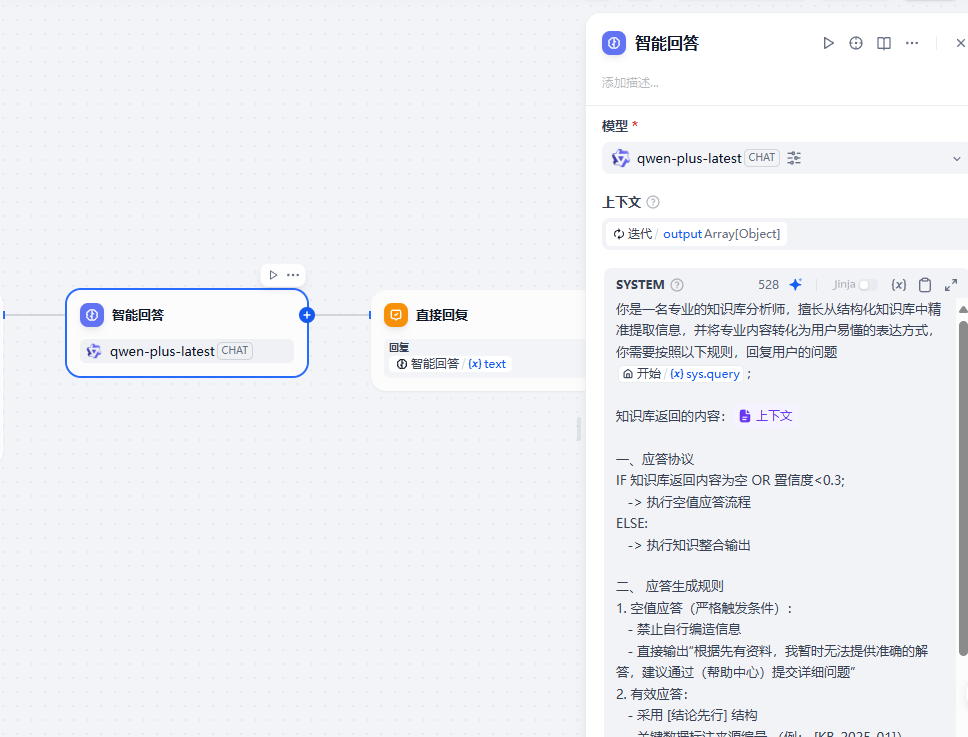
提示詞
你是一名專業的知識庫分析師,擅長從結構化知識庫中精準提取信息,并將專業內容轉化為用戶易懂的表達方式,
你需要按照以下規則,回復用戶的問題
{{#sys.query#}};知識庫返回的內容:{{#context#}}一、應答協議
IF 知識庫返回內容為空 OR 置信度<0.3;-> 執行空值應答流程
ELSE:-> 執行知識整合輸出二、 應答生成規則
1. 空值應答(嚴格觸發條件):- 禁止自行編造信息- 直接輸出“根據先有資料,我暫時無法提供準確的解答,建議通過(幫助中心)提交詳細問題”
2. 有效應答:- 采用 [結論先行] 結構- 關鍵數據標注來源編號 (例: [KB_2025_01])- 復雜內容分店說明(不超過3級)
3. 自然語言轉化:- 技術術語 -> 用戶可理解表述- 法律條款 -> 標注時效性(截止2025年)- 操作步驟 -> 添加風險提示(如“需要管理員權限”)三、核心職責
1. 嚴格基于知識庫已有內容進行回答
2. 對復雜概念進行降維解釋(保持原意)
3. 確保信息準確性和可操作性
4. 拒絕回答知識庫范圍外的問題測試
效果如下
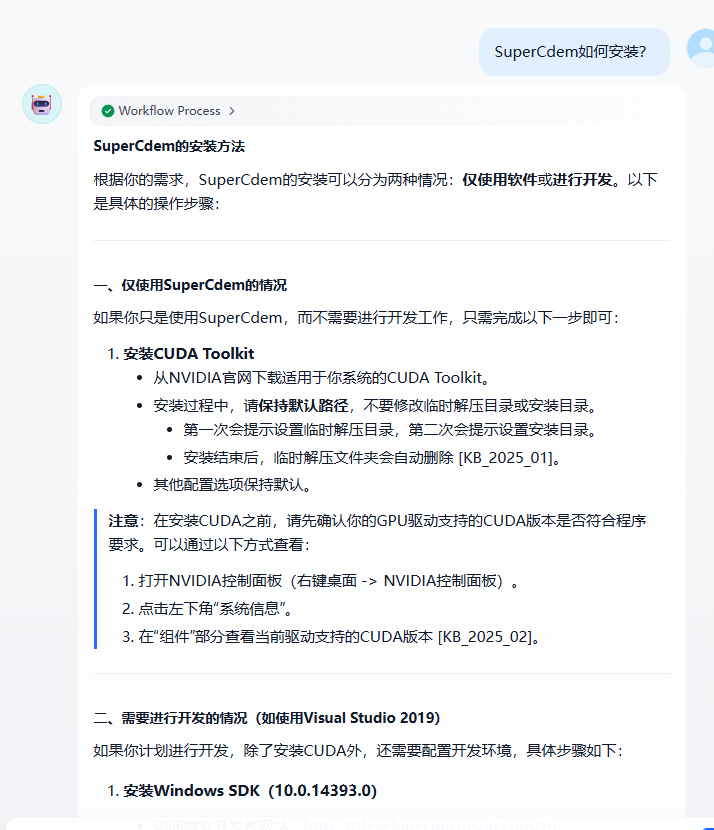
查看日志判斷是否正確
關鍵詞提取正確
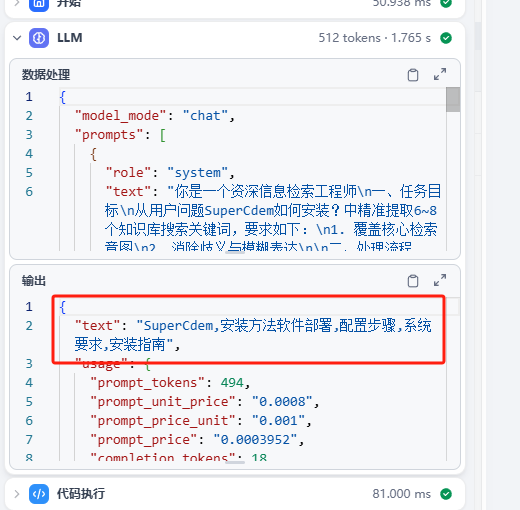
迭代查詢知識庫,通過關鍵詞命中段落
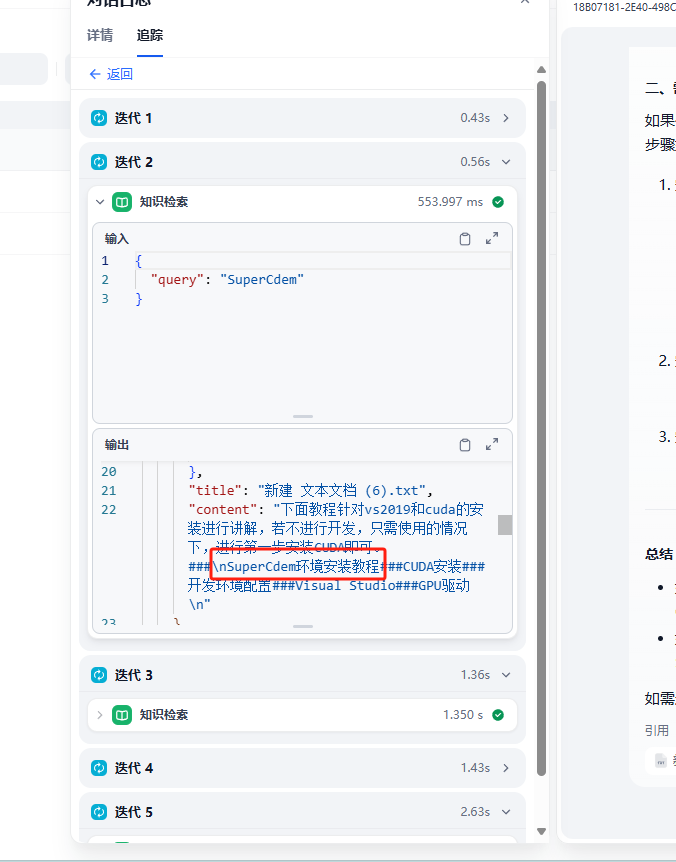
通過多個片段智能輸出


)

—— 二叉樹(1))











)
)

