MySQL篇
- 一、總體結構
- 二、優化
- (一)定位慢查詢
- 1.1 開源工具
- 1.2Mysql自帶的慢日志查詢
- 1.3 總結
- (二)定位后優化
- 2.1 優化
- 2.2 總結
- (三)索引
- 3.1 索引
- 3.2 索引底層數據結構——B+樹
- 3.3 總結
- (四)聚簇索引、非聚簇索引
- 4.1 聚簇索引、非聚簇索引
- 4.2 回表查詢
- 4.3 總結
- (五)覆蓋索引
- 5.1 覆蓋索引
- 5.3 MYSQL超大分頁
- 5.3 總結
- (六)索引創建原則
- 6.1 原則
- 6.2 總結
- (七)索引失效
- 7.1 索引失效的情況
- 7.2 總結
- (八)優化經驗
- 8.1 表的設計優化
- 8.2 SQL語句優化
- 8.3 主從復制、讀寫分離
- 8.4 總結
- 三、其他面試
- (一)事務
- 1.1 事務特性
- 1.2 并發事務
- 1.3 解決并發事務問題——隔離
- 1.4 undo Log 和redo log
- 1.4.1 重做日志
- 1.4.2 回滾日志 undo log
- 1.5 MVCC
- 1.5.1 記錄中的隱藏字段
- 1.5.2 undo log
- 1.5.3 readView
- (二)主從同步原理
- (三)分庫分表
- 1、垂直拆分
- 1.1 垂直分庫
- 1.2 垂直分表
- 2、 水平拆分
- 2.1 水平分庫
- 2.2 水平分表
- 3、分庫分表新問題及其解決方案
- 4、總結
一、總體結構


二、優化
(一)定位慢查詢
問:在mysql如何進行慢查詢?
出現的情況:
- 聚合查詢
- 多表查詢
- 表數據量過大查詢深度分頁查詢
具體現象:頁面加載過慢、接口壓測響應時間過長(超過1s)
1.1 開源工具
調試工具: Arthas
運維工具: Prometheus .Skywalking
1.2Mysql自帶的慢日志查詢
慢查詢日志記錄了所有執行時間超過指定參數(long _query_time,單位:秒,默認10秒)的所有SQL語句的日志如果要開啟慢查詢日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:

配置完畢之后,通過以下指令重新啟動MySQL服務器進行測試,查看慢日志文件中記錄的信息/var/lib/mysgql/localhost-slow.log。

1.3 總結


(二)定位后優化
2.1 優化
問:這個SQL語句執行很慢,你是如何分析(優化)的呢?

可以采用EXPLAIN或者DESC命令獲取 MySQL如何執行SELECT語句的信息。





2.2 總結


(三)索引
3.1 索引
問:了解過索引嗎(什么是索引)?
索引 (index)是幫助MysQL高效獲取數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構(B+樹),這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法,這種數據結構就是索引。
以二分查找為例:

3.2 索引底層數據結構——B+樹
索引的底層結構是什么?
B+樹
①二叉樹:時間復雜度不太穩定

②紅黑樹:雖然保持了平衡,但是本質上也是二叉樹,每個結點只有兩個分支,查找效率不高

③B樹:B-Tree,B樹是一種多叉路衡查找樹,相對于二叉樹,B樹每個節點可以有多個分支,即多叉。以一顆最大度數(max-degree)為5(5階)的b-tree為例,那這個B樹每個節點最多存儲4個key。變成了矮胖樹,解決了層級過高查找效率過低的問題,但是B樹效率仍沒有B+樹優秀
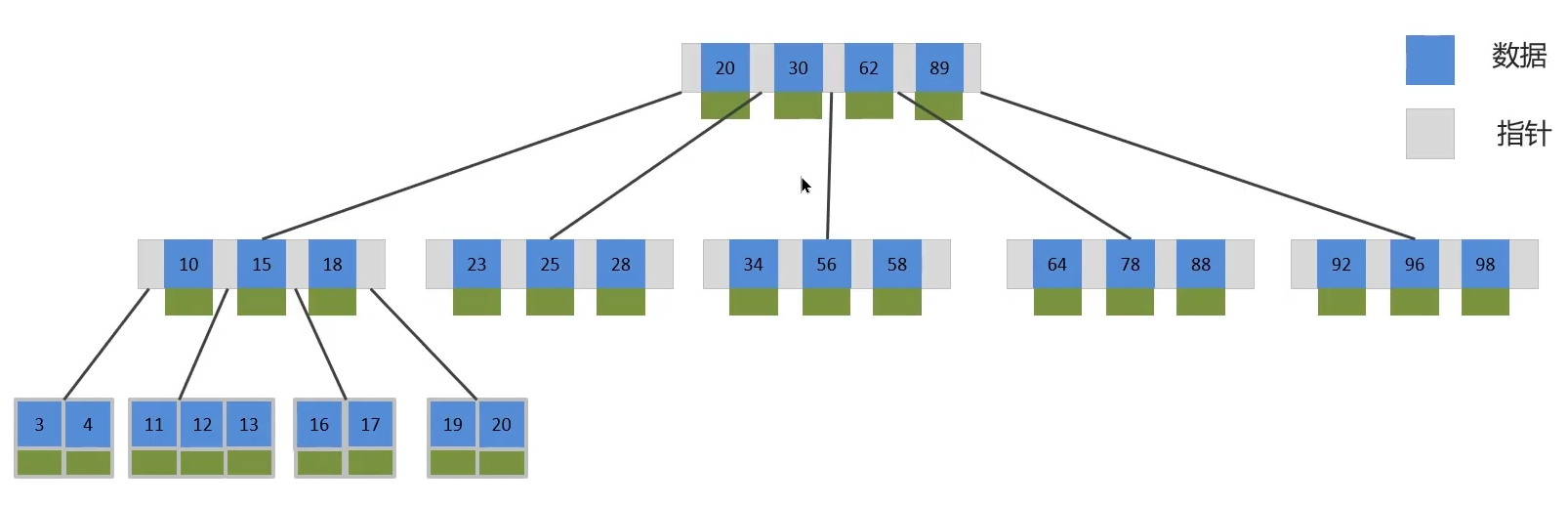
④B+樹:B+ Tree是在BTree基礎上的一種優化,使其更適合實現外存儲索引結構,InnoDB存儲引擎就是用B+Tree實現其索引結構。非葉子結點只存儲指針不存儲數據,只有最底層葉子結點才會存儲數據,非葉子節點的作用是導航找到數據。

- 磁盤讀寫代價B+樹更低;
- 查詢效率B+樹更加穩定;
- B+樹便于掃庫和區間查詢
3.3 總結


(四)聚簇索引、非聚簇索引
問:什么是聚簇索引?什么是非聚簇索引(二級索引)?(什么是回表查詢?)
4.1 聚簇索引、非聚簇索引
講解視頻:聚簇索引和非聚簇索引的 區別



4.2 回表查詢
以上面為姓名列添加索引的二級索引為例,查詢“name = “Arm””,由于給name字段添加了索引,那么現在會走二級索引,找到10,但我們需要查找的是全部信息select * ,通過查詢到的主鍵ID10到聚簇索引中區查找,最終找到所有信息。

4.3 總結


(五)覆蓋索引
5.1 覆蓋索引
覆蓋索引是指查詢使用了索引,并且需要返回的列,在該索引中已經全部能夠找到。
例如:在以下第二個例子中,通過“name = “Arm””可以直接查詢 到id,并直接返回id,name。在第三個例子中gender不可以一次查詢直接找到,而是需要回表查詢。

5.3 MYSQL超大分頁
在數據量比較大時,如果進行limit分頁查詢,在查詢時,越往后,分頁查詢效率越低。
分頁查詢耗時對比:

因為,當在進行分頁查詢時,如果執行limit 9000000,10,此時需要MySQL排序前9000010記錄,僅僅返回9000000 - 9000010的記錄,其他記錄丟棄,查詢排序的代價非常大。
優化思路:一般分頁查詢時,通過創建
覆蓋索引能夠比較好地提高性能,可以通過覆蓋索引加子查詢形式進行優化


視頻講解:MYSQL深度分頁如何優化?
①先根據Id排序(只查詢id,減少回表),返回10條索引——>覆蓋索引
②在和之前的表做關聯,做一個等價查詢(通過id走主鍵索引,只查需要的10條)
通過該過程辦法,極大的優化了查詢效率。
5.3 總結



(六)索引創建原則
6.1 原則
- 針對于數據量較大,且查詢比較頻繁的表建立索引。單表超過10萬數據(增加用戶體驗)
- 針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索引。
- 盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高。
- 如果是字符串類型的字段,字段的長度較長,可以針對于字段的特點,建立前綴索引。
- 盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省存儲空間,避免回表,提高查詢效率。
- 要控制索引的數量,索引并不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率。
- 如果索引列不能存儲NULL值,請在創建表時使用NOT NULL約束它。當優化器知道每列是否包含NULL值時,它可以更好地確定哪個索引最有效地用于查詢。
6.2 總結


(七)索引失效
7.1 索引失效的情況
-
違背最左前綴法則
如果索引了多列,要遵守最左前綴法則。指的是查詢從索引的最左前列開始,并且不跳過索引中的列。匹配最左前綴法則,走索引:(a,b,c的聯合索引包含:a,ab,abc這三種情況)
表的情況:

遵循最左前綴法則的查詢:
 失效的情況:
失效的情況:

符合最左法則,但是跳躍了中間某一列,那么只能查詢到符合的:

-
范圍查詢右邊的列,不能使用索引

-
索引列上進行運算操作,索引也會失效

-
字符串不加單引號,導致索引失效

由于,在查詢是,沒有對字符串加單引號,MySQL的查詢優化器,會自動的進行類型轉換造成索引失效。 -
模糊查詢,有可能導致索引失效:以
%開頭的Like模糊查詢,索引失效。如果僅僅是尾部模糊匹配,索引不會失效。如果是頭部模糊匹配,索引失效。

7.2 總結


(八)優化經驗
問: 談一談對sql優化的經驗

8.1 表的設計優化
表的設計優化 參考:阿里開發手冊《嵩山版》
- 比如設置合適的數值(tinyint int bigint),要根據實際情況選擇
- 比如設置合適的字符串類型(char和varchar) char定長效率高,varchar可變長度,效率稍低
8.2 SQL語句優化
- SELECT語句務必指明字段名稱(避免直接使用select * )
- SQL語句要避免造成索引失效的寫法
- 盡量用union all代替union union會多一次過濾,效率低

union all 會將兩次查詢的結果直接組合起來,不會刪除重復的部分,union過濾重復部分。 - 避免在where子句中對字段進行表達式操作
- Join優化能用innerjoin 就不用left join right join,如必須使用一定要以小表為驅動,內連接會對兩個表進行優化,
優先把小表放到外邊,把大表放到里邊。left join或right join,不會重新調整順序

以該循環為例子,只需要進行三次小循環(三次連接數據庫的操作)后再每次連接中執行其中操作即可。
8.3 主從復制、讀寫分離
如果數據庫的使用場景讀的操作比較多的時候,為了避免寫的操作所造成的性能影響可以采用讀寫分離的架構。讀寫分離解決的是,數據庫的寫入,影響了查詢的效率。

8.4 總結


三、其他面試
(一)事務
1.1 事務特性
事務特性:ACID
事務是一組操作的集合,它是一個不可分割的工作單位,事務會把所有的操作作為一個整體一起向系統提交或撤銷操作請求,即這些操作要么同時成功,要么同時失敗。
- 原子性(Atomicity):事務是不可分割的最小操作單元,要么全部成功,要么全部失敗。
- 一致性(Consistency):事務完成時,必須使所有的數據都保持一致狀態。
- 隔離性(Isolation):數據庫系統提供的隔離機制,保證事務在不受外部并發操作影響的獨立環境下運行。
- 持久性 (Durability):事務一旦提交或回滾,它對數據庫中的數據的改變就是永久的。


1.2 并發事務
問:并發事務帶來哪些問題?怎么解決這些問題呢?MySQL的默認隔離級別是?
并發事務問題: 臟讀、不可重復讀、幻讀
解決方案:隔離
隔離級別: 讀未提交、讀已提交、可重復讀、串行化

在解決了不可重復讀的基礎上(事務回滾了)

1.3 解決并發事務問題——隔離



1.4 undo Log 和redo log
緩沖池(buffer pool):主內存中的一個區域,里面可以緩存磁盤上經常操作的真實數據,在執行增刪改查操作時,先操作緩沖池中的數據(若緩沖池沒有數據,則從磁盤加載并緩存),以一定頻率刷新到磁盤,從而減少磁盤IO,加快處理速度
數據頁(page):是InnoDB存儲引擎磁盤管理的最小單元,每個頁的大小默認為16KB。頁中存儲的是行數據

操作時,為提高效率會首先操作內存結構中的緩沖池,操作結束后會將信息同步到磁盤中(還未同步的稱為臟頁),但是同步過程中會出現宕機的現象,導致無法同步,內存中數據無法保存太久,最后會消失,無法做到持久化。
1.4.1 重做日志
重做日志,記錄的是事務提交時數據頁的物理修改,是用來實現事務的持久性。
該日志文件由兩部分組成:重做日志緩沖(redo log buffer)以及重做日志文件(redo log file) ,前者是在內存中,后者在磁盤中。當事務提交之后會把所有修改信息都存到該日志文件中,用于在刷新臟頁到磁盤,發生錯誤時,進行數據恢復使用。

1.4.2 回滾日志 undo log
回滾日志,用于記錄數據被修改前的信息,作用包含兩個:提供回滾和MVCC(多版本并發控制)。undo log和redo log記錄物理日志不一樣,它是邏輯日志。
可以認為當delete一條記錄時,undo log中會記錄一條對應的insert記錄,反之亦然,
當update一條記錄時,它記錄一條對應相反的update記錄。當執行rollback時,就可以從undo log中的邏輯記錄讀取到相應的內容并進行回滾。
undo log 可以實現事務的一致性和原子性


1.5 MVCC
問:事務的隔離性是如何保證的?
鎖:排他鎖(如一個事務獲取了一個數據行的排他鎖,其他事務就不能再獲取該行的其他鎖)
mvcc:多版本并發控制
全稱Multi-Version Concurrency Control,多版本并發控制。指維護一個數據的多個版本,使得讀寫操作沒有沖突
MVCC的具體實現,主要依賴于數據庫記錄中的隱式字段、undo log日志、readView。

1.5.1 記錄中的隱藏字段


1.5.2 undo log
- 回滾日志,在insert、update、delete的時候產生的便于數據回滾的日志。
- 當insert的時候,產生的undo log日志只在回滾時需要,在事務提交后,可被立即冊除。
- 而update、delete的時候,產生的undo log日志不僅在回滾時需要,mvcc版本訪問也需要,不會立即被刪除。

不同事務或相同事務對同一條記錄進行修改,會導致該記錄的undolog生成一條記錄版本鏈表,鏈表的頭部是最新的舊記錄,鏈表尾部爆最早的舊記錄。
1.5.3 readView
ReadView(讀視圖)是快照讀SQL執行時MVCC提取數據的依據,記錄并維護系統當前活躍的事務(未提交的) id。當前讀
讀取的是記錄的最新版本,讀取時還要保證其他并發事務不能修改當前記錄,會對讀取的記錄進行加鎖。對于我們日常的操作,如:select … lock in share mode(共享鎖),select … for update、update、insert.
delete(排他鎖)都是一種當前讀。
快照讀
簡單的select (不加鎖)就是快照讀,快照讀,讀取的是記錄數據的可見版本,有可能是歷史數據,不加鎖,是非阻塞讀。
Read Committed:每次select,都生成一個快照讀。
Repeatable Read:開啟事務后第一個select語句才是快照讀的地方。
v




(二)主從同步原理

MySQL主從復制的核心就是二進制日志
二進制日志(BINLOG)記錄了所有的DDL(數據定義語言)語句和DML(數據操縱語言)語句
但不包括數據查詢(SELECT、SHQW)語句。



(三)分庫分表
只有一個從庫不夠用,分庫分表分擔了訪問壓力。
分庫分表的時機:
- 項目業務數據逐漸增多,或業務發展比較迅速單表的數據量達
1000W或20G以后 - 優化已解決不了性能問題(主從讀寫分離、查詢索引…)
- IO瓶頸(磁盤IO、網絡lO)、CP心瓶頸(聚合查詢、連接數太多)


1、垂直拆分
1.1 垂直分庫
以表為依據,根據業務將不同表拆分到不同庫中。

特點:
- 按業務對數據分級管理、維護、監控、擴展
- 在高并發下,提高磁盤IO和數據量連接數
1.2 垂直分表
以字段為依據,根據字段屬性將不同字段拆分到不同表中。
拆分規則:把不常用的字段單獨放在一張表,把text,blob等大字段拆分出來放在附表中

特點:
- 冷熱數據分離(經常訪問的就是熱數據,不常訪問的就是冷數據)
- 減少IO過渡爭搶,兩表互不影響
2、 水平拆分
2.1 水平分庫
將一個庫的數據拆分到多個庫中。表結構、字段屬性都是一模一樣的,但是把表分在了很多個不同的地方(庫)。
路由規則:
- 根據id節點取模
- 按id也就是范圍路由,節點1(1-100萬),節點2(100萬-200萬)

特點:
- 解決了單庫大數量,高并發的性能瓶頸問題
- 提高了系統的穩定性和可用性
2.2 水平分表
將一個表的數據拆分到多個表中,同樣的字段屬性一模一樣,但是數據存儲不同。

特點:
- 優化單一表數據量過大而產生的性能問題;
- 避免IO爭搶并減少鎖表的幾率;
3、分庫分表新問題及其解決方案

分庫之后的問題:
- 分布式事務一致性問題
- 跨節點關聯查詢
- 跨節點分頁、排序函數
- 主鍵避重
解決方案:采用中間件

4、總結







)
)


 - 動態規劃深度解析)

))

)
)



)