2025年,各種會推理的AI模型如雨后春筍般涌現,比如ChatGPT o1/o3/o4、DeepSeek r1、Gemini 2 Flash Thinking、Claude 3.7 Sonnet (Extended Thinking)。
對于工程上一些問題比如復雜的自然語言轉sql,我們可能忍受模型的得到正確答案需要更多時間,但是準確度一定要高。那么我們就可以考慮用文中的方法(模型推理能力)得到更高精確度。
什么是推理能力
簡單說,就是模型在回答問題時會先輸出一大段推理過程,然后才給出最終答案。
下圖我們分別在deepseek的官網使用不帶深度思考的與帶深度思考(DeepSeek-R1)的模型對北京是中國的首都嗎?
可以看到當我們使用深度思考模型AI不會直接回答,而是會先來一段內心獨白再去回答,這中間的內心獨白就叫做推理。
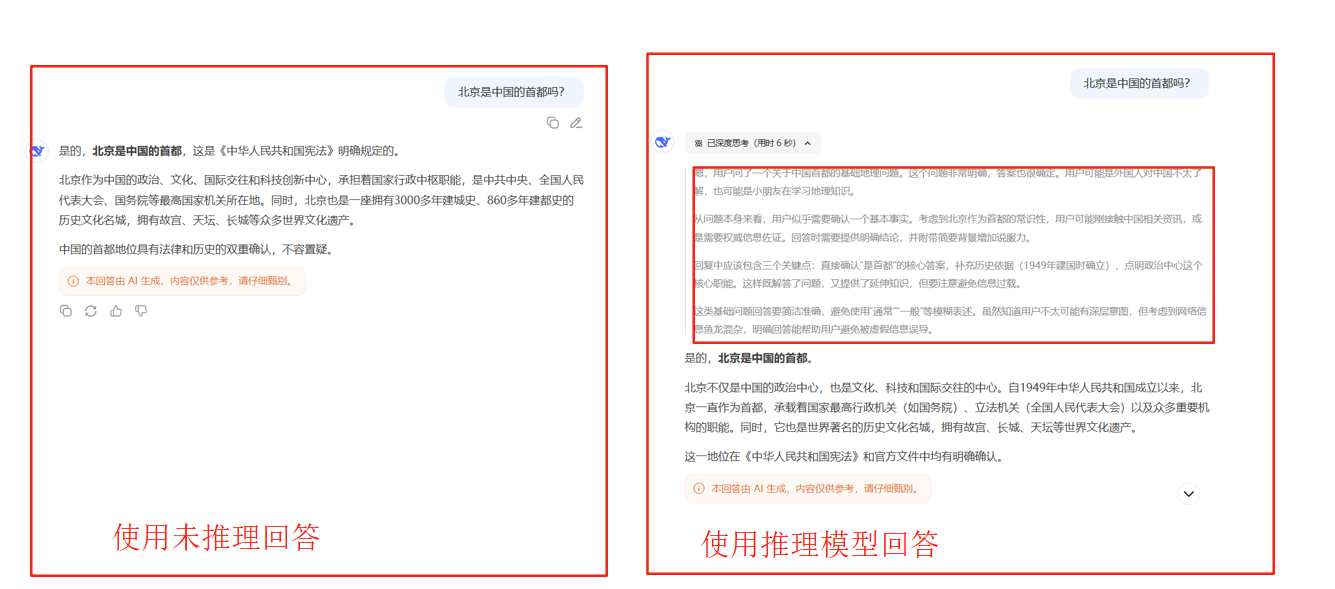
推理能力類似早先年間計算機視覺領域的可視化模型輸出的過程。推理能力是某些大模型本身就存在的能力,我們能達到的推理效果是因為我們通過訓練或提示詞解碼了這一過程。

讓LLM實現推理能力的四個方法
Chain-of-Thought 提示詞并不是對所有LLM都通用,比如LLama3不適用。
我們在平臺上使用的DeepSeek-R1就是結合了本文提到的四種方法實現的
1. Chain-of-Thought
CoT方法是一種提示詞引導,分為Short CoT和Long CoT代表性的Supervised CoT,Short CoT又可分為few-shot CoT和 zero-shot CoT。
| 類別 | 方法名稱 | 實現方式 | 示例 |
|---|---|---|---|
| Short CoT | Few-shot CoT | 提供示例引導 | 給出2-3個完整的問題-思考-答案示例,然后提問 |
| Short CoT | Zero-shot CoT | 簡單提示引導 | 在問題后加上"讓我們一步步思考" |
| Long CoT | Supervised CoT | 詳細流程指導 | 編寫復雜提示詞,明確指定思考流程、驗證步驟、輸出格式等 |
few-shot CoT是給一些范例引導模型思考,下圖展示了few-shot CoT的過程。zero-shot CoT是在問題后面加上一步步來思考。
zero-shot CoT是在問題后面加上讓我們一步步思考,下圖展示了zero-shot CoT的過程。

Supervised CoT通過編寫詳細的提示詞來指導模型的思考流程,下圖展示了Supervised CoT的過程:


2. 多次采樣
該方法核心是既然一次做不對,那就多試幾次。由此引出了兩類工程問題:
- 如何讓模型嘗試多次?(通常嘗試16+次)
- 如何在多次生成的答案篩選正確答案
產生多個答案
- 問題難度決定策略:
- 簡單問題:純串行效果最好
- 困難問題:需要并行+串行的平衡
- 中等問題:理想比例介于兩者之間
- 計算預算影響:
- 小預算:串行采樣更高效
- 大預算:需要平衡分配避免過度優化
- 互補性:
- 并行采樣提供全局搜索能力
- 串行采樣提供局部優化能力
- 兩者結合能夠充分利用測試時計算資源
1. 并行采樣(Parallel Sampling)
核心思想:同時生成多個完全獨立的解答
具體做法:
- 給定同一個問題,讓模型獨立生成N個不同的回答
- 每次生成都是從頭開始,互不依賴
- 通過設置temperature > 0來引入隨機性,確保每次生成的答案都不完全相同
2. 串行采樣(Sequential Sampling)/ 迭代修正
核心思想:基于前一次的嘗試來改進下一次的回答
具體做法:
- 先生成一個初始答案
- 將這個答案作為上下文,讓模型基于此生成改進版本
- 重復這個過程,每次都在前面答案的基礎上進行優化
3. 混合策略:并行+串行
最佳策略往往是兩種方法的結合
具體做法:
- 將計算預算分配給并行和串行兩種采樣
- 比如用一部分預算生成幾個獨立的起始點
- 然后從每個起始點進行串行改進
適應性分配:
- 簡單問題:更多串行采樣(因為初始答案通常在正確軌道上)
- 困難問題:更多并行采樣(需要探索不同的解題策略)
- 中等難度:平衡分配
篩選正確答案
1. Majority Vote:群眾的智慧
最直觀的方法是投票機制:看哪個答案出現次數最多就選哪個。
實驗數據顯示了一個很有趣的現象:Majority Vote的效果提升并不是線性的。
- 前期快速上升:從1次嘗試到16次,準確率提升很明顯
- 中期平緩增長:從16次到64次,提升變得溫和
- 后期趨于飽和:超過128次后,基本不再提升
這個曲線形狀很符合直覺。想象一下,如果正確答案出現的概率是30%,那么:
- 試1次:30%概率對
- 試5次:如果正確答案出現2次以上就贏,概率大大提升
- 試50次:如果正確答案真的占30%,那肯定會勝出
但如果模型本身對某類問題就是"系統性地理解錯誤",那試再多次也沒用——每次都會用錯誤的方法,只是錯得稍有不同而已。
實際操作中,你需要在提示詞里告訴模型把最終答案放在特定標簽中(比如<answer></answer>),這樣才能方便地統計各個答案的出現頻率。
2. Best of N:專業裁判來評分
你可以直接再加一個模型,用提示詞讓模型判斷它做得對不對。
更高級的做法是訓練一個專門的驗證器來給答案打分,然后從N個候選中選出得分最高的。這類似于建立一個機器學習模型,我們需要準備數據集,然后得到這樣的模型
訓練驗證器的方法很巧妙:
- 準備一批有標準答案的題目
- 讓語言模型生成大量不同的解答
- 根據最終答案的對錯來標注:正確答案標記為1,錯誤答案標記為0
- 用這些數據訓練驗證器
這樣就得到了一個"專業裁判",能夠識別哪些答案更可能正確。
3. Beam Search:智能路徑探索
如果說Best of N是"海選后評判",那么Beam Search就是"邊走邊篩選"的智能策略。它不等到最后才評判,而是在解題的每一步都進行篩選,只保留最有希望的路徑繼續探索。
核心思想:把解題過程看作一棵樹,每一步都是樹的一個分支,我們只保留最promising的幾條路徑繼續往下走。
具體流程:
- 生成多個起始步驟:比如生成8個不同的第一步解法
- 過程驗證器評分:用訓練好的驗證器給每個步驟打分
- 保留最優路徑:只保留得分最高的4個步驟(這個4就是beam width)
- 繼續擴展:從這4個步驟分別生成下一步,又得到新的候選
- 重復篩選:再次用驗證器評分,保留最好的4個
- 直到完成:重復這個過程直到得到最終答案
關鍵組件 - 過程驗證器:
與普通驗證器不同,過程驗證器不需要看到完整答案就能判斷當前步驟的質量。它就像一個經驗豐富的老師,看到學生解題的前幾步就能判斷這個思路靠不靠譜。
訓練過程驗證器的巧妙方法:
- 從某個中間步驟開始,讓原模型繼續解題多次(比如20次)
- 統計從這個步驟開始最終得到正確答案的比例
- 這個比例就是該步驟的"質量分數"
- 訓練驗證器學會預測這個分數
比如從某個step1開始,20次嘗試中有14次得到正確答案,那這個step1的質量分數就是0.7。
實際操作技巧:
請逐步解決這個數學問題
每個步驟用<step>和</step>標簽包圍
示例:
<step>分析:這是一個幾何問題...</step>
<step>計算:根據勾股定理...</step>
讓模型生成到</step>就停止,這樣可以精確控制每次只生成一步,然后用驗證器評估這一步的質量。
3. 模仿學習(Imitation Learning)
傳統的訓練數據只包含問題和答案,但在這種方法中,我們的訓練數據還包含了完整的推理步驟。
比如說,原來的訓練數據是:
- 問題:小明有3個蘋果,小紅給了他2個,他現在有幾個蘋果?
- 答案:5個
現在的訓練數據變成:
- 問題:小明有3個蘋果,小紅給了他2個,他現在有幾個蘋果?
- 推理過程:小明原本有3個蘋果,小紅又給了他2個蘋果,所以總共是3+2=5個蘋果
- 答案:5個
這里遇到的最大問題是:推理過程的數據從哪里來?讓人工去標注這些推理步驟實在太耗時耗力了。
聰明的解決方案是:讓語言模型自己生成推理過程。市面上已經有很多強大的推理模型,比如GPT-o1、Claude等。最簡單的方法就是知識蒸餾:
- 用一個強大的"老師"模型生成推理過程和答案
- 讓你的"學生"模型直接學習這些數據
- 完成訓練
4. 強化學習
DeepSeek團隊首先創造了一個叫R1-0的模型,這是一個完全用強化學習訓練出來的版本。他們以DeepSeek-V3-Base作為基礎模型,用兩個主要的獎勵信號進行訓練:
- 正確率獎勵:答對問題得到正向反饋
- 格式獎勵:要求模型生成特定的思考標記(think token)
實驗結果表明,這種純粹的強化學習方法確實有效。
真正的DeepSeek-R1:復雜的混合訓練流程
R1-0效果單次嘗試的正確率可以接近GPT-o1,但是它有一個致命問題:生成的推理過程幾乎無法閱讀。
官方發布的DeepSeek-R1對R0有了更進一步提升,從而使得其推理過程能正確被閱讀,且效果超過o1。
R1使用的方法其實就是融合了前面提到的四種方法。
第一步:推理數據人工標注
首先,研究團隊用R1-0來生成帶有推理過程的訓練數據。但由于R1-0的輸出質量堪憂,他們投入了大量人力去修改和改寫這些推理過程。
人工標注員需要將模型生成的那些難以理解的推理過程,改寫成人類可以閱讀的版本。
除了改寫R1-0的輸出,他們還使用了CoT:
- 用少樣本提示(Few-shot CoT)讓其他模型生成推理數據
- 使用提示工程讓模型生成更詳細、包含反思和驗證的答案
這一步做完后,就可以訓練一個模型了。我們把這個訓練好的模型稱為模型A
第二步:改進的強化學習
接下來,他們對模型A進行強化學習,但這次的強化學習有所改進。除了要求高正確率,還增加了一個重要約束:語言一致性獎勵。
如果模型在推理過程中始終使用同一種語言(比如全程英文或全程中文),就會獲得額外獎勵。這樣可以避免模型在推理中頻繁切換語言,提高可讀性。
雖然這個約束會輕微降低模型的正確率,但研究團隊認為這是值得的權衡。
第三步:擴展任務范圍
有了模型B之后,訓練的重點從數學和編程擴展到各種不同類型的任務。他們讓模型B對各種問題生成推理過程和答案。
由于很多任務沒有標準答案,他們使用DeepSeek-V3作為驗證器來判斷答案質量。同時,他們還設置了一些過濾規則,去除那些質量較差的推理過程,比如:
- 使用多種語言混雜的過程
- 過于冗長的推理
- 包含不必要代碼的過程
第四步:大規模模仿學習(模型C)
這一步是自動化的,因此可以生成更多數據。他們收集了60萬條推理數據,同時為了防止模型遺忘之前學到的知識,還加入了20萬條自我輸出數據(讓模型學習自己之前的優質輸出)。
用這80萬條數據對DeepSeek-V3-Base進行模仿學習,得到模型C。
第五步:最終的強化學習
最后,對模型C進行一輪強化學習,重點提升模型的安全性和有用性,最終得到我們使用的DeepSeek-R1。









中正確安裝 Rust)


)





——dlib臉部輪廓繪制)
