目錄
認識URL
urlencode 和 urldecode
HTTP 協議請求與響應格式
HTTP 的請求方法
GET 方法
POST 方法
HTTP 的狀態碼
HTTP 常見 Header
Location
關于 connection 報頭
HTTP版本
遠程連接服務器工具
setsockopt
我們來學習應用層協議http。
雖然我們說, 應用層協議是我們程序猿自己定的,但實際上, 已經有大佬們定義了一些現 成的, 又非常好用的應用層協議, 供我們直接參考使用. HTTP(超文本傳輸協議)就是其 中之一。 在互聯網世界中,HTTP(HyperText Transfer Protocol,超文本傳輸協議)是一個至 關重要的協議。它定義了客戶端(如瀏覽器)與服務器之間如何通信,以交換或傳輸 超文本(如 HTML 文檔)。 HTTP 協議是客戶端與服務器之間通信的基礎。客戶端通過 HTTP 協議向服務器發送 請求,服務器收到請求后處理并返回響應。HTTP 協議是一個無連接、無狀態的協 議,即每次請求都需要建立新的連接,且服務器不會保存客戶端的狀態信息。
認識URL

這里說下,http或者https的區別就是https是支持加密的,更安全,最前面的叫做協議名稱。
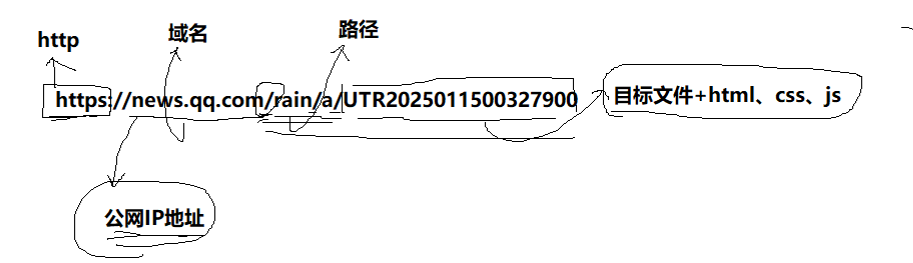
//后面就是訪問路徑+請求報頭,請求報頭的格式是kv的格式就是什么:什么,這些都是瀏覽器自動填寫的,在url中/不一定是根目錄,其實叫web根目錄,二者不一定相同,就是這個/是根據當前請求位置而定的,像你要請求的網址如果在本地,那本地就是根目錄,接著你可以接著往后輸入根目錄的其他內置的功能頁,這些頁比如/login/會直接被瀏覽器拼接在web根目錄的后面,完善請求路徑,然后路徑所指向的內容就是請求正文(目標文件),這個正文可以是html,css,js等的頁面,記住,瀏覽器會根據這個路徑直接運行這個文件,也就是說直接上傳一個html所在的路徑就相當于用瀏覽器直接訪問然后運行它,當然你也可以直接傳一堆的html代碼,瀏覽器直接可以做解析。所以我要通過url訪問某個服務器的網頁,就相當于請求某個資源,這些資源路徑本質就是文件路徑,這和Linux下是一樣的。為什么沒有體現端口號呢?成熟的應用層協議,往往和端口號是強關聯的,這個port已經提前內置到瀏覽器里面了,人家本來就認識。我們把在服務器和客戶端之間的瀏覽器這種東西叫做代理服務器。
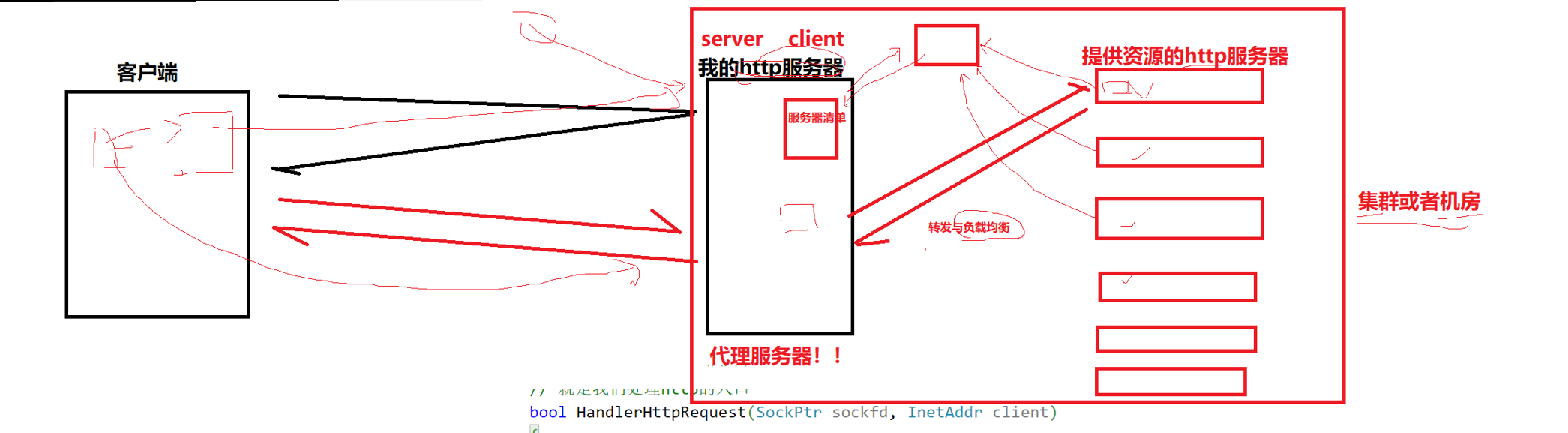
相當于轉接端,它會將用戶的請求轉接給其后面的多個客戶端,多個客戶端進行處理后將響應返回給代理服務器然后呈現給用戶。這很多個服務器就相當于多線程。所以我們平時用的百度等的各種app就是代理服務器不是真的位于最后的服務器。
代理服務器主要起到
我的數據給別人,別人的數據發送給我的本質是在做I/O,我們網上所有的行為都是在做I/O,我們通過url以及端口號進行通信,所以我們要獲取資源首先要確定我們要的資源在哪臺服務器上(網絡,ip),在什么路徑下(系統,路徑)。
urlencode 和 urldecode
像 / ? : 等這樣的字符, 已經被 url 當做特殊意義理解了. 因此這些字符不能隨意出現. 比如, 某個參數中需要帶有這些特殊字符, 就必須先對特殊字符進行轉義. 轉義的規則如下: 將需要轉碼的字符轉為 16 進制,然后從右到左,取 4 位(不足 4 位直接處理),每 2 位 做一位,前面加上%,編碼成%XY 格式。urldecode 就是 urlencode 的逆過程。
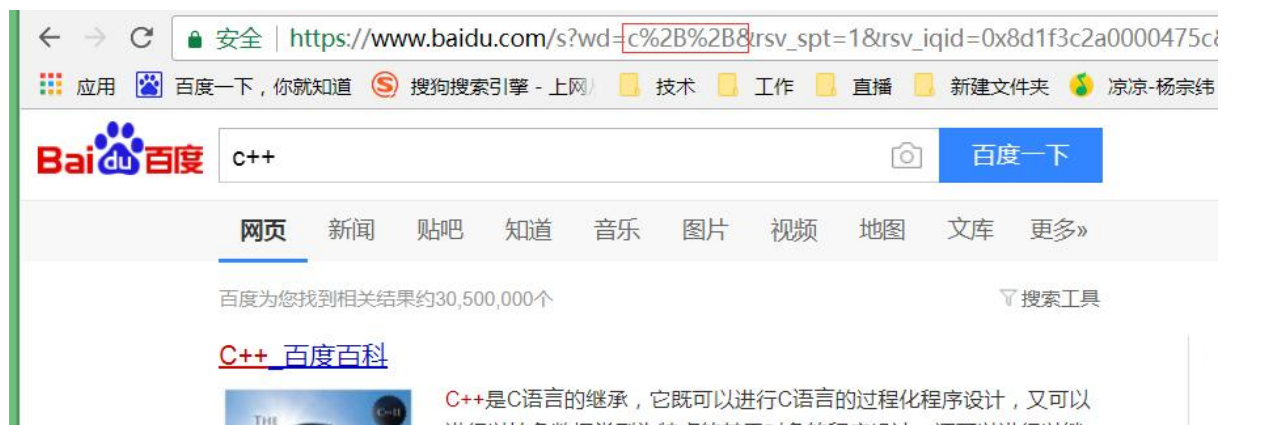
對于特殊字符進行搜索時用的這種函數進行類似于序列化/反序列化的操作,這種處理方法是相當于在定協議了。這種函數的設計網上自己搜索一下就有了。
HTTP 協議請求與響應格式
http是應用層協議,是基于tcp協議的,所以http也是面向連接的,并且面向字節流的。

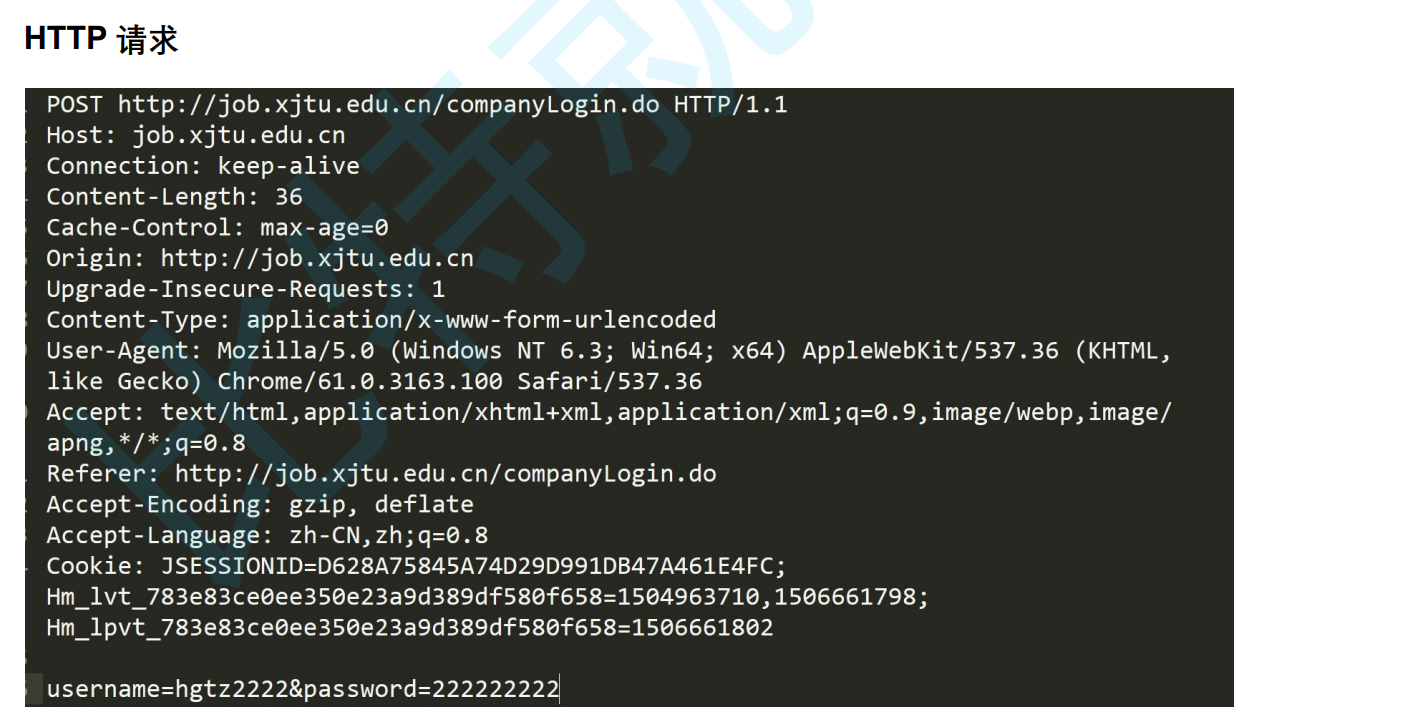
可以看到http的請求/響應都是結構化數據,一條url就是一條已經序列化的請求或者響應。對于http請求,首行: [方法] + [url] + [版本]中間用空格隔開,然后接上換行符/r/n,接著是請求報頭,HTTP 的請求報頭(HTTP Request Headers)在瀏覽器或客戶端與服務器通信時,起著非常重要的作用。它們提供了關于客戶端、請求內容、服務器期望的響應等關鍵信息,就是哈希表的結構,接著是空行,這個空行其實就是換行符,最后是請求正文,我們一個標準的http的request是需要有以上4個部分的,這個請求報頭其實是可以沒有的。正文(body)也可以是圖片,文本,html等。像圖片是二進制的格式是否能發送/讀取圖片完全取決于格式。
一下展示請求格式展示:
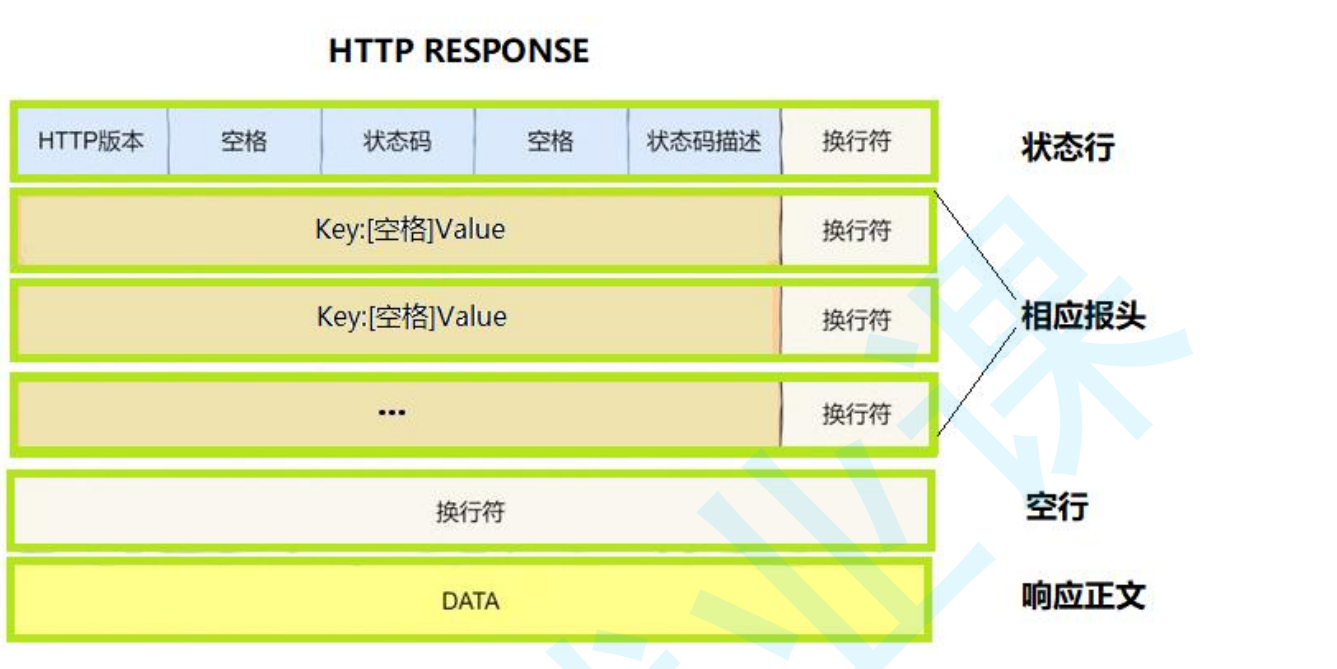
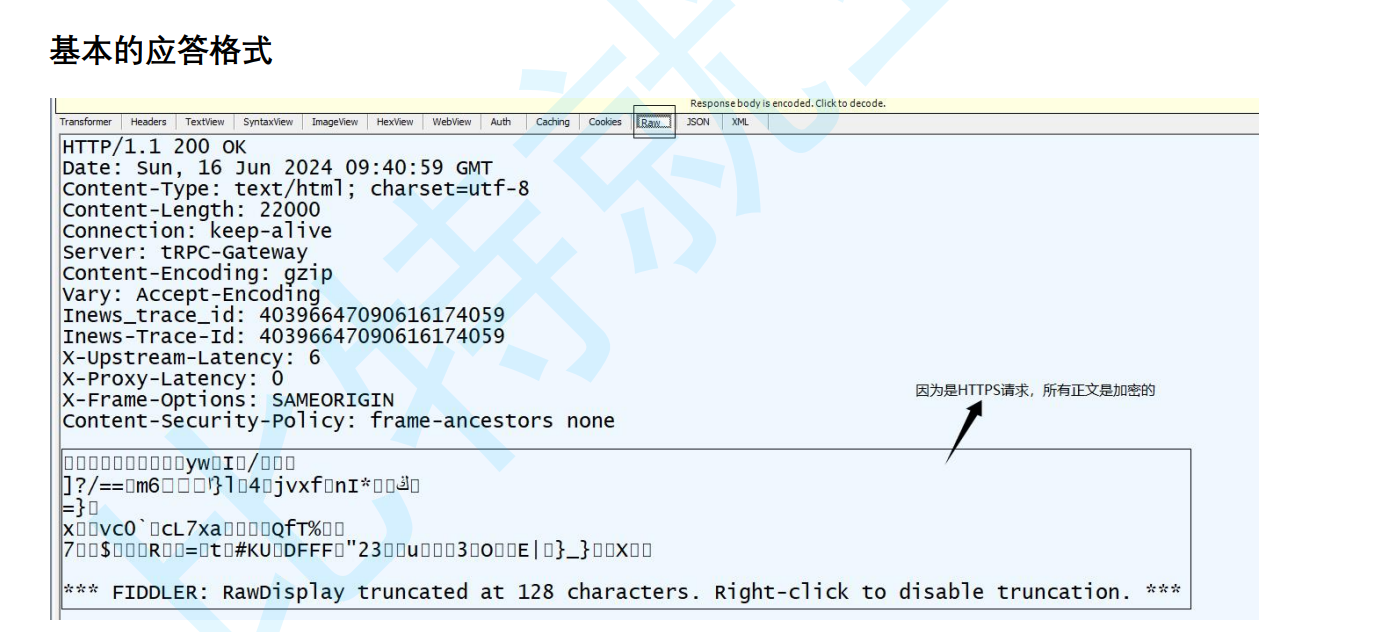
我們接著看應答格式,首行: [版本號] + [狀態碼] + [狀態碼解釋],接著是響應報頭Header: 請求的屬性, 冒號分割的鍵值對;每組屬性之間使用\r\n 分隔;遇到空行表示 Header 部分結束,空行,接著是響應正文Body: 空行后面的內容都是 Body. Body 允許為空字符串. 如果 Body 存在, 則在 Header 中會有一個 Content-Length 屬性來標識 Body 的長度; 如果服務器返回了一 個 html 頁面, 那么 html 頁面內容就是在 body 。
這個狀態碼和狀態描述符都是人為規定的。
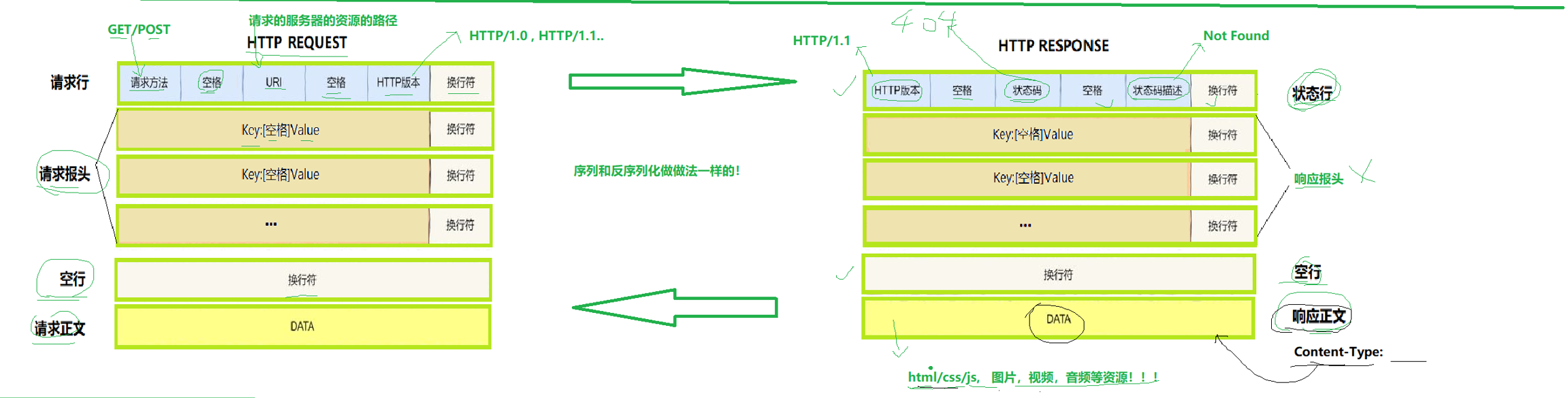
那怎么通信呢?首先用戶向瀏覽器發送一個請求,內部發送的是一個請求結構體,然后經過序列化成一行字符串(請求行+請求報頭+空行+請求正文),然后經由瀏覽器發送給服務端,服務端經過反序列化提取有效信息,然后返回資源,生成應答組件應答結構體,然后用相同的方式序列化,瀏覽器反序列化,通過瀏覽器讀取呈現出來。只不過我們的服務端一般都是瀏覽器,由于請求/響應都是互相看得懂的,所以序列化/反序列化方式一致。這里響應報文的反序列化和讀取是瀏覽器自己做的。點擊客戶端的連接也算發起一次請求不一定要輸入url
瀏覽器并不是一個傳統意義上的“代理服務器”,但它確實在客戶端角色之外,承擔了一些“代理服務器”類似的職責。
HTTP 的請求方法
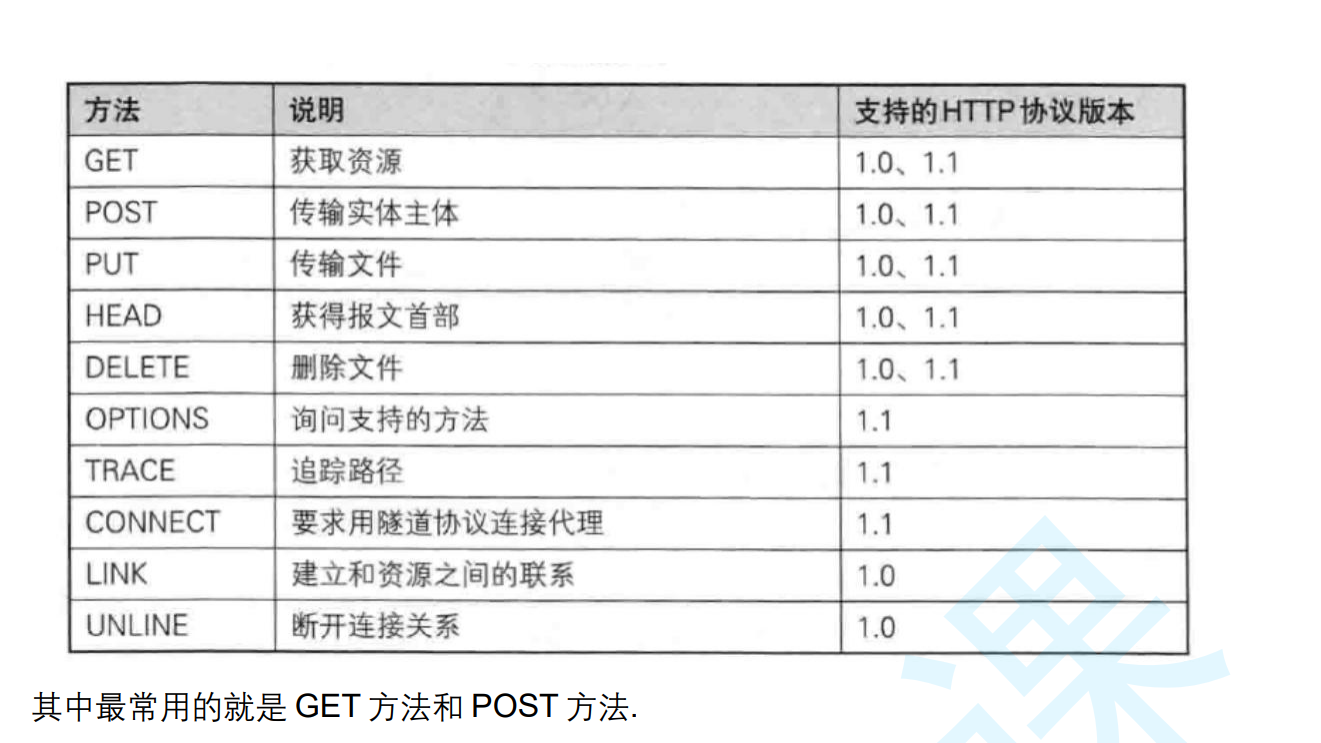
正常來說,服務器不可能暴露出很多方法的,這個對服務器本身不好,一般只會暴露GET/POST方法。如果只是訪問靜態網頁,那我們是不需要設置get/post方法的,請求正文正是我們要向服務器發送的東西,我們希望得到服務器相關的應答,就比如我們輸入密碼賬號就希望服務器可以做出判斷,這種就屬于交互式的http。這種網站叫交互式網站。
GET 方法
用途:用于請求 URL 指定的資源。
示例:GET /index.html HTTP/1.1
特性:指定資源經服務器端解析后返回響應內容。
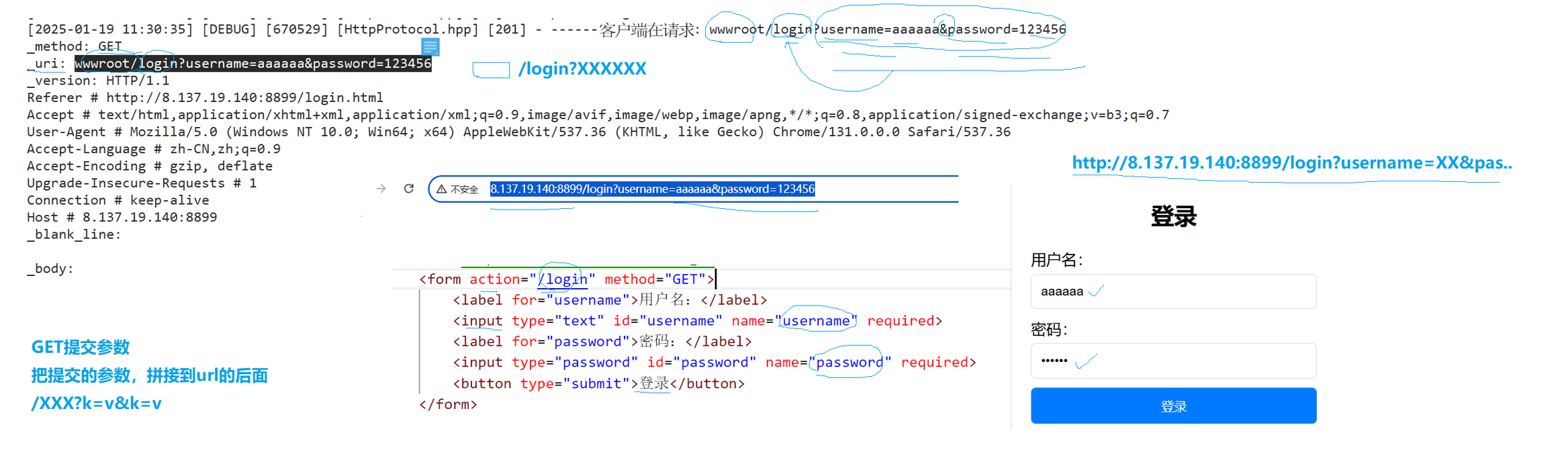
GET方式提交參數時,瀏覽器會自動將提交的參數作為請求報頭kv形式的添加到url的后面 /xxx?k=v,請求報頭和路徑之間是用?隔開的。
POST 方法
用途:用于傳輸實體的主體,通常用于提交表單數據。
示例:POST /submit.cgi HTTP/1.1
特性:可以發送大量的數據給服務器,并且數據包含在請求體中。
POST提交參數時,瀏覽器會自動將其提交到請求正文中。由于GET是之間添加在url里面的,所以對信息沒有起到保護作用,所以GET通常用來獲取網頁,POST通常用來上傳數據。這兩個本質都是用戶向服務器發信息,GET傳參通過url,POST通過body。

更多的請求方法都不是很重要了。如果沒有指定請求方法默認是GET。
HTTP 的狀態碼
我們可以對不同的請求情況進行分析從而設置此次請求是否合法合理的狀態碼,然后設置狀態碼通過響應結構體返回。
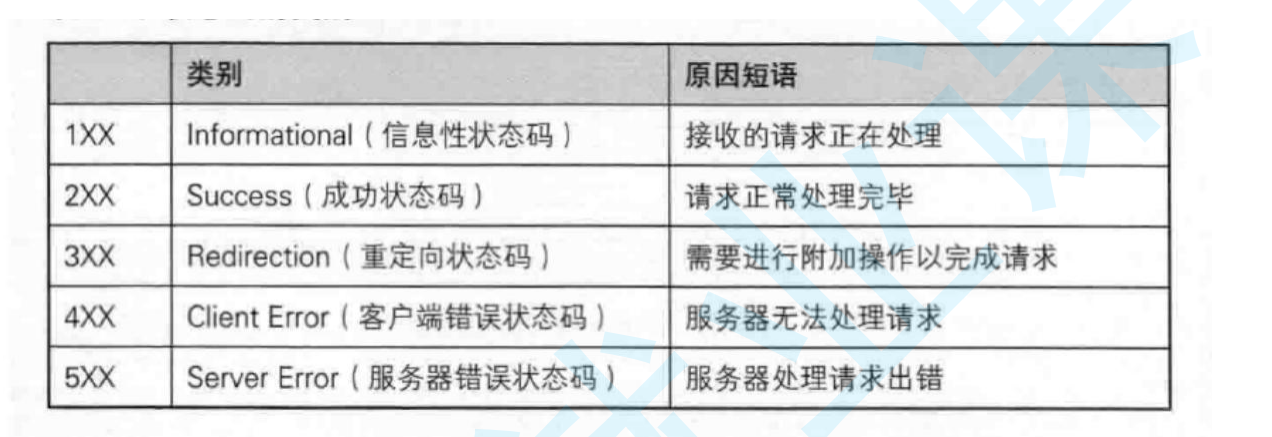
最常見的狀態碼, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定 向), 504(Bad Gateway)
一下是常見的狀態碼和狀態碼描述


這種狀態碼描述以及碼都是可以找到對應關系的,這種技術kv的關系,可以在網上找找看,不需要記。
HTTP 常見 Header
header就是請求/回響報頭。

這些都可以在請求時填寫,回應時自動根據請求的添加,所以請求報頭和回應報頭是基本一致的,都是可以設置的。
Content-Type指示請求體的內容類型,常用于 POST 或 PUT 請求。服務器返回的內容類型(如 HTML、JSON、XML 等)。主要是告訴服務器客戶端發送的內容格式,幫助服務器正確解析請求體。像帶了這個字段就不拍發送的正文被瀏覽器誤解了,雖然瀏覽器有時候也可以自動識別正文內容。
Host用于填充主機地址,端口號對于瀏覽器來說不需要,必須包含在每個 HTTP/1.1 請求中,那搜索引擎是怎么知道域名(主機地址)的呢,因為每個服務器的地址域名都是保存在瀏覽器里面的,所以即使域名(地址)變更了搜索引擎也會內置這個變化。然后為了防止用戶不知道新的域名是什么,瀏覽器會進行URL重定向,從舊的域名定向到新的域名,相當于訪問舊的域名時直接指向跳轉到了新的。
referer則相當于保留上此的訪問記錄。
User-Agent一般選擇瀏覽器默認生成的。
Location
通常用于 重定向 響應,指示客戶端應訪問的 URL。如果在 HTTP 響應頭中同時設置了 Location 和 Host,瀏覽器會根據 Location 頭部的內容進行重定向,而不直接處理 Host 頭部的變化。
HTTP 狀態碼 301(永久重定向)和 302(臨時重定向)都依賴 Location 選項。以下 是關于兩者依賴 Location 選項的詳細說明: HTTP 狀態碼 301(永久重定向): ? 當服務器返回 HTTP 301 狀態碼時,表示請求的資源已經被永久移動到新的位 置。 ? 在這種情況下,服務器會在響應中添加一個 Location 頭部,用于指定資源的新位 置。這個 Location 頭部包含了新的 URL 地址,瀏覽器會自動重定向到該地址。

HTTP 狀態碼 302(臨時重定向): ? 當服務器返回 HTTP 302 狀態碼時,表示請求的資源臨時被移動到新的位置。 ? 同樣地,服務器也會在響應中添加一個 Location 頭部來指定資源的新位置。瀏覽 器會暫時使用新的 URL 進行后續的請求,但不會緩存這個重定向。

就是301是永久修改指向,302是臨時的響應。
無論是 HTTP 301 還是 HTTP 302 重定向,都需要依賴 Location 選項來指定資 源的新位置。這個 Location 選項是一個標準的 HTTP 響應頭部,用于告訴瀏覽器應該 將請求重定向到哪個新的 URL 地址。
關于 connection 報頭
HTTP 中的 Connection 字段是 HTTP 報文頭的一部分,它主要用于控制和管理客戶 端與服務器之間的連接狀態,也可以設置的。
? Connection: keep-alive:表示希望保持連接以復用 TCP 連接。(長鏈接)
? Connection: close:表示請求/響應完成后,應該關閉 TCP 連接。(短鏈接)
Connection 字段還用于管理持久連接(也稱為長連接)。持久 連接允許客戶端和服務器在請求/響應完成后不立即關閉 TCP 連接,以便在同一個連接 上發送多個請求和接收多個響應。?如果connect設置是keep-alive那就是長鏈接,位于長鏈接時TCP交互不會自動關閉,會一直保持開啟狀態,允許我們不斷的發送請求,如果設置成close,就是短鏈接,在短鏈接下,我們只能交互一次,傳輸完后socket就自動關閉了,下次要傳輸時就得再次啟動tcp服務。這個根一次訪問量是沒有關系的,重點差別是次數。

HTTP版本
填寫格式,HTTP/x(x為版本號),這個x一般填寫1.0,1.1,2.0
遠程連接服務器工具
1。postman
Postman 是一個非常流行的 API 開發與測試工具,廣泛用于 開發者 和 測試人員 在開發 RESTful API 和其他 Web 服務時進行接口測試、調試和文檔生成。Postman 提供了圖形化界面,方便用戶構造、發送 HTTP 請求,查看響應數據,以及對接口進行自動化測試。記得選免費版的
2。telnet
Telnet 是一種用于遠程連接到另一臺計算機的協議和工具,通常用于命令行界面(CLI)下的網絡管理和故障排查。通過 Telnet,用戶可以通過網絡連接到遠程計算機,執行命令,管理設備或訪問服務。不過,Telnet 已經有些過時,很多現代網絡中更推薦使用 SSH(Secure Shell)來代替,因為 SSH 更安全,使用加密技術保護數據傳輸。而 Telnet 的數據是以明文形式傳輸的,容易受到竊聽。我覺得不是很好用,還是用上面那個吧,這個是屬于Linux指令,直接我用過了。
setsockopt
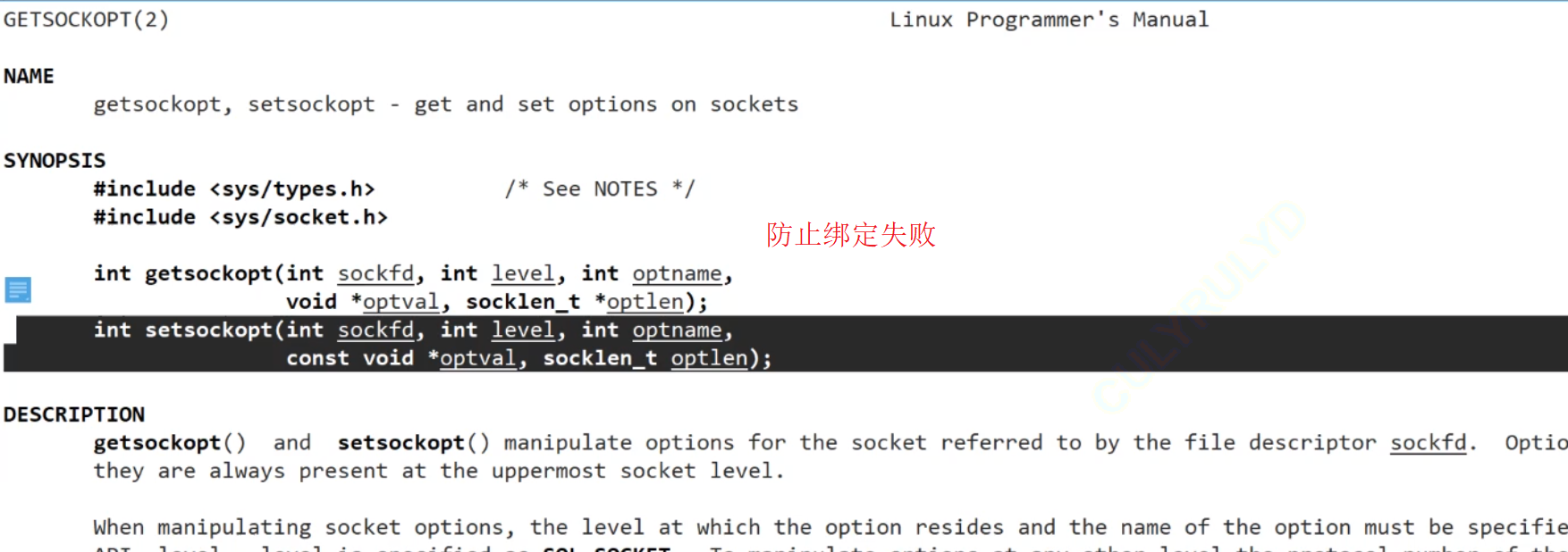
setsockopt 函數是一個用于在套接字(socket)上設置選項的函數,它允許程序控制套接字的行為。這在網絡編程中非常重要,尤其是在 TCP/IP 協議的套接字編程中。它通常用于設置一些影響套接字行為的參數,如緩沖區大小、超時、重試次數等。
如果服務器比客戶端先退出了,就會出現短時間綁定同一個端口綁定不上的問題,當服務器退出時,TCP 連接會處于一個 TIME_WAIT 狀態,等待足夠的時間確保客戶端收到確認消息。這段時間內,端口無法立即重新綁定給新的服務器實例,因為操作系統正在保護這個端口,以防止出現舊數據包的重傳或延遲到達的情況。就是揮手的過程,我們后面再說。它的作用是配置套接字的行為,通過修改底層協議棧或操作系統對套接字的處理方式,來滿足特定的需求。這個函數可以允許服務器快速重啟,告別TIME_WAIT狀態從而使同一個端口號被快速使用。
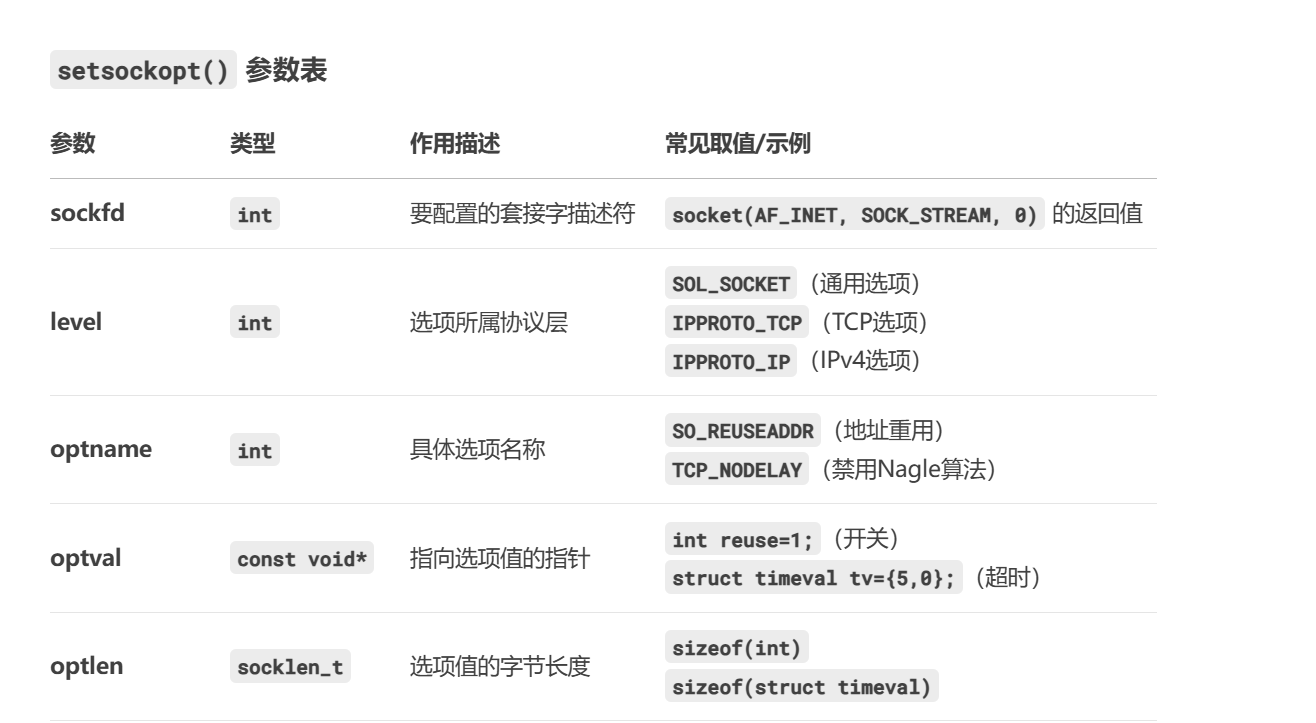
由于我們要處理的是端口的允許重用的問題所以選擇SO_REUSEADDR(允許多個套接字綁定相同 IP + 端口(Linux 3.9+,用于多進程服務器),默認是開啟的所以optval是1,就得到以下實現了:當然level也可以用IPPROTO_TCP,
int optval = 1; setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval));??











)
)







