ElasticSearch
DSL查詢文檔

分類

| 查詢類型 | 功能描述 | 典型應用場景 | 示例語法 |
|---|---|---|---|
| 查詢所有 | 匹配所有文檔,無過濾條件 | 數據預覽/測試 | json { "query": { "match_all": {} } } |
| 全文檢索查詢 | 對文本字段分詞后匹配,基于倒排索引 | 搜索框模糊匹配、多字段搜索 | json { "query": { "match": { "title": "Elasticsearch指南" } } } |
| 精確查詢 | 直接匹配未經分詞的字段值(keyword/數值/日期等) | 狀態過濾、范圍篩選、精確ID查詢 | json { "query": { "term": { "status": "published" } } } |
| 地理查詢 | 基于經緯度的空間位置計算 | 附近地點搜索、地理圍欄 | json { "query": { "geo_distance": { "distance": "10km", "location": "40,-70" } } } |
| 復合查詢 | 組合多個查詢條件,支持邏輯運算和自定義評分 | 復雜業務場景(權重排序、多條件過濾) | json { "query": { "bool": { "must": [ { "term": { "category": "tech" } } ] } } } |

match_all---匹配所有文檔
match_all查詢是一個特殊的查詢類型,它用于匹配索引中的所有文檔,而不考慮任何特定的查詢條件。
基本語法:
GET /<your-index-name>/_search
{
"query": {
?? "match_all": {}
}
}
高級用法
您可以在matchall查詢中添加額外的參數來控制搜索結果的顯示,例如設置返回的文檔數量(size)、開始返回的文檔位置(from)、排序規則(sort)以及選擇返回哪些字段(source)。
-
size返回指定條數
size 關鍵字: 指定查詢結果中返回指定條數。 默認返回值10條
GET /employee/_search
{
? "query": {
?? "match_all": {}
? },
? "size": 3 ?
}
-
from&size分頁查詢
size:顯示應該返回的結果數量,默認是 10 from:顯示應該跳過的初始結果數量,默認是 0 from 關鍵字用來指定起始返回位置,和size關鍵字連用可實現分頁效果
GET /employee/_search
{
? "query": {
?? "match_all": {}
? },
? "from": 0,
? "size": 5 ?
}
-
sort指定字段排序
指定查詢結果的排序方式,是根據什么進行排序的
# 根據age排序
GET /employee/_search
{"query": {"match_all": {}},"sort": [{"age": "desc"}]
}
?
# 排序的同時進行分頁
GET /employee/_search
{"query": {"match_all": {}},"sort": [{"age": "desc"}],"from": 2,"size": 5
}-
_source返回源數據
指定查詢之后返回的字段,定向顯示需要的字段與屏蔽不需要的字段
GET /employee/_search
{
? "query": {
?? "match_all": {}
? },
? "_source": ["name","address"]
}
精確匹配
精確匹配是指的是搜索內容不經過文本分析直接用于文本匹配,這個過程類似于數據庫的SQL查詢,搜索的對象大多是索引的非text類型字段。此類檢索主要應用于結構化數據,如ID、狀態和標簽等。主要介紹一下term與terms、range的查詢方式,因為使用的頻率比較高。還有一些其它的精確匹配的類型在這里就不詳細展開說明,在前面文章里面的腦圖鏈接中有說明可以進行了解。
基本語法
①term查詢
在Elasticsearch 8.x中,term查詢用于執行精確匹配查詢,它適用于未經過分詞處理的keyword字段類型。
GET /{index_name}/_search
{
"query": {
?? "term": {
? ?? "{field.keyword}": {
? ? ?? "value": "your_exact_value"
? ?? }
?? }
}
}
這里的{index_name}是你要查詢的索引名稱,{field.keyword}是你要匹配的字段名稱,.keyword后綴表示該字段是一個keyword類型,用于存儲精確匹配的數據。"value"是你要精確匹配的值
②terms查詢
在Elasticsearch 8.x中,進行多值精確匹配時,可以使用terms查詢。terms查詢允許你指定一個字段,并匹配該字段中的多個精確值
GET /<index_name>/_search
{
"query": {
?? "terms": {
? ?? "<field_name>": [
? ? ?? "value1",
? ? ?? "value2",
? ? ?? "value3",
? ? ?? ...
? ?? ]
?? }
}
}
-
<index_name> 是你想要查詢的索引名稱。
-
<field_name> 是你想要對其執行terms查詢的字段名。
-
方括號內的值列表是你希望在查詢中匹配的字段值
③range查詢
在Elasticsearch 8.x中,進行精確范圍查詢時,可以使用range查詢。
GET /<index_name>/_search
{
"query": {
?? "range": {
? ?? "<field_name>": {
? ? ?? "gte": <lower_bound>,
? ? ?? "lte": <upper_bound>,
? ? ?? "gt": <greater_than_bound>,
? ? ?? "lt": <less_than_bound>
? ?? }
?? }
}
}
-
<index_name> 是你想要查詢的索引名稱。
-
<field_name> 是你想要對其執行range查詢的字段名。
-
gte 表示大于或等于(Greater Than or Equal)。
-
lte 表示小于或等于(Less Than or Equal)。
-
gt 表示嚴格大于(Greater Than)。
-
lt 表示嚴格小于(Less Than)。
-
<lower_bound>, <upper_bound>, <greater_than_bound>, <less_than_bound> 是指定的數值邊界。
全文檢索
全文檢索查詢旨在基于相關性搜索和匹配文本數據。這些查詢會對輸入的文本進行分析,將其拆分為詞項(單個單詞),并執行諸如分詞、詞干處理和標準化等操作。此類檢索主要應用于非結構化文本數據,如文章和評論等。主要介紹一下match與multi_match的查詢方式,因為使用的頻率比較高。還有一些其它的全文檢索類型在這里就不詳細展開說明,在前面文章里面的腦圖鏈接中有說明可以進行了解。
全文檢索的關鍵特點:
-
對輸入的文本進行分析,并根據分析后的詞項進行搜索和匹配。全文檢索查詢會對輸入的文本進行分析,將其拆分為詞項,并基于這些詞項進行搜索和匹配操作。
-
以相關性為基礎進行搜索和匹配。全文檢索查詢使用相關性算法來確定文檔與查詢的匹配程度,并按照相關性進行排序。相關性可以基于詞項的頻率、權重和其他因素來計算。
-
全文檢索查詢適用于包含自由文本數據的字段,例如文檔的內容、文章的正文或產品描述等。
基本語法
①match查詢
//match查詢(跟據一個字段查詢)
GET /<index_name>/_search
{
"query": {
??? "match": {
????? "<field_name>": "<query_string>"
??? }
}
}
<index_name> 是你要搜索的索引名稱。 <query_string> 是你要在多個字段中搜索的字符串。 <field1>, <field2>, ... 是你要搜索的字段列表。
②multi_match查詢
//multi_match查詢(跟據多個字段查詢,字段越多查詢效率越差)
GET /<index_name>/_search
{
"query": {
??? "multi_match": {
????? "query": "<query_string>",
????? "fields": ["<field1>", "<field2>", ...]
??? }
}
}
<index_name> 是你要搜索的索引名稱。 <query_string> 是你要在多個字段中搜索的字符串。 <field1>, <field2>, ... 是你要搜索的字段列表
Boolean查詢
-
搜索上下文(Query Context):使用搜索上下文時,ElasticSearch需要計算每個文檔與搜索條件的相關度得分,這個得分的計算需要使用一套復雜的計算公式,有一定的性能開銷,帶文本分析的全文檢索的查詢語句很適合放在搜索上下文中
-
過濾上下文(Filter Context):使用過濾上下文時,ElasticSearch只需要判斷搜索條件根文檔數據是否匹配。過濾上下文的查詢不需要進行相關度得分計算,還可以使用緩存加快響應的速度,很多術語級查詢語句都適合放在過濾上下文中
| 特性 | 搜索上下文(Query Context) | 過濾上下文(Filter Context) |
|---|---|---|
| 作用 | 計算文檔相關性得分,影響排序結果 | 判斷文檔是否匹配條件,不計算得分 |
| 性能 | 計算成本較高(需計算相關性) | 高效(結果可緩存,無需計算得分) |
| 典型使用場景 | 全文檢索、模糊匹配、需要結果排序的場景 | 精確篩選(狀態過濾、范圍查詢)、高頻重復條件過濾 |
| 語法位置 | query 參數內(如 bool.must、bool.should) | filter 參數內(如 bool.filter、bool.must_not) |
| 緩存機制 | 不緩存結果 | 自動緩存結果(提升重復查詢性能) |

//must關鍵詞
GET /books/_search
{"query": {"bool": {"must": [{"match": {"title": "java編程"}},{"match": {"description": "性能優化"}}]}}
}//should關鍵詞
GET /books/_search
{"query": {"bool": {"should": [{"match": {"title": "java編程"}},{"match": {"description": "性能優化"}}],"minimum_should_match": 1}}
}//filter關鍵詞
GET /books/_search
{"query": {"bool": {"filter": [{"term": {"language": "java"}},{"range": {"publish_time": {"gte": "2010-08-01"}}}]}}
}地理查詢
地理查詢旨在跟據用戶給出的地理位置信息來查詢附近的目標資源的信息以及數量
基本語法
-
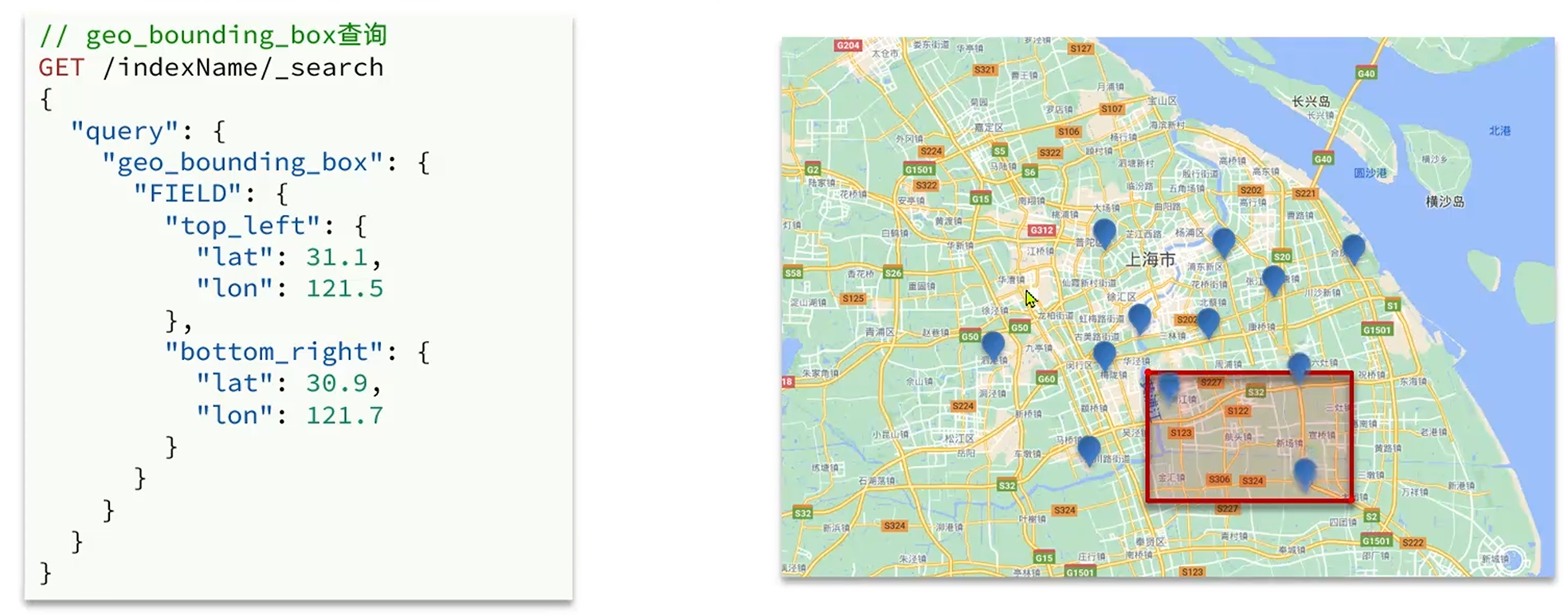
geo_bounding_box查詢
查詢地理坐標在框定的正方形區域內的目標資源,跟據左上經緯度(top_left)和右下經緯度(bottom_right)來構建區域方型,進而確定資源
-
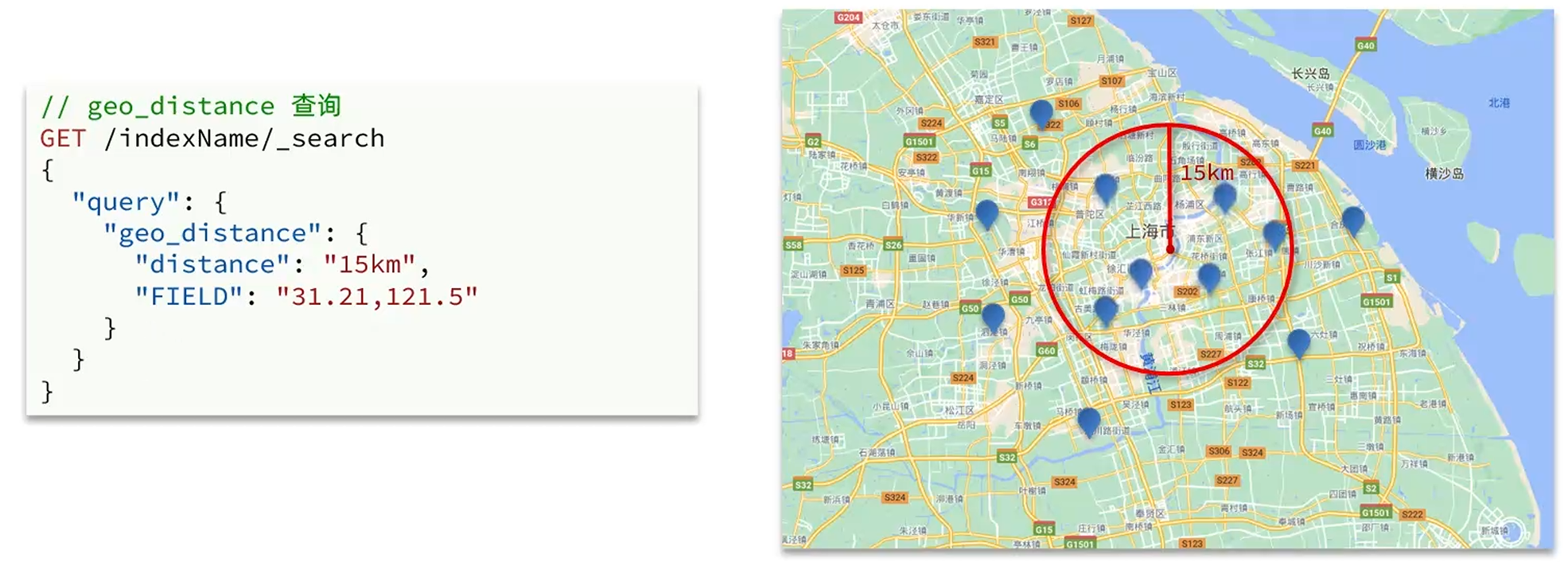
geo_distance查詢
查詢以目標位置為圓心,指定路徑為半徑的圓形區域內的目標資源的信息
高亮顯示
Elasticsearch 的高亮顯示功能允許在搜索結果中突出顯示匹配的關鍵詞或短語,幫助用戶快速定位相關信息。
GET /hotel/_search
{
? "query":{
??? "搜索方式":{
????? "字段名":"搜索內容"
??? }
? },
? "highlight":{
??? "fields":{
????? "字段名":{
??????? "pre_tags":"<em>",? //用來標記高亮字段的前置標簽
??????? "post_tags":"</em>" //用來標記高亮字段的后置標簽
????? },
????? "字段名2":{
??????? "pre_tags":"<em>",?? //用來標記高亮字段的前置標簽
??????? "post_tags":"</em>", //用來標記高亮字段的后置標簽
??????? "require_field_match":"false"
????? }
??? }
? }
}
示例演示
//使用自定義高亮顯示來標識(可以)
GET /products/_search
{"query": {"multi_match": {"fields": ["name","desc"],"query": "牛仔"}},"highlight": {"post_tags": ["</span>"], "pre_tags": ["<span style='color:red'>"],"fields": {"*":{}}}
}//多字段高亮配置
GET /products/_search
{"query": {"term": {"name": {"value": "牛仔"}}},"highlight": {"pre_tags": ["<font color='red'>"],"post_tags": ["<font/>"],"require_field_match": "false","fields": {"name": {},"desc": {}}}
}相關參數說明:
-
highlight 關鍵字: 可以讓符合條件的文檔中的關鍵詞高亮。
-
highlight相關屬性:
-
pre_tags 前綴標簽
-
post_tags 后綴標簽
-
tags_schema 設置為styled可以使用內置高亮樣式
-
require_field_match 多字段高亮需要設置為false
ES向量檢索

核心特性
-
向量數據類型
-
dense_vector:支持浮點數密集向量(如BERT、ResNet生成的向量)。 -
sparse_vector(實驗性):支持稀疏向量(如TF-IDF高維稀疏表示)。
-
-
近似最近鄰搜索(ANN)
-
基于 HNSW(Hierarchical Navigable Small World) 算法,平衡精度與性能。
-
支持 歐氏距離(l2)、余弦相似度(cosine)、點積(dot_product) 等相似度計算方式。
-
-
性能優化
-
支持 量化(Quantization) 減少存儲占用(如int8量化)。
-
通過 段合并優化(Force Merge) 提升檢索速度。
-
-
混合檢索
-
結合傳統全文檢索(BM25)與向量檢索,實現多模態搜索。
-

搜索相關性
概念:在搜索引擎中描述一個文檔與查詢語句匹配程度的度量標準。
ElasticSearch 5之前的版本評分機制,或者打分模型是基于TF_IDF實現的。從ElasticSearch 5之后默認的打分機制改成了Okapi BM25。
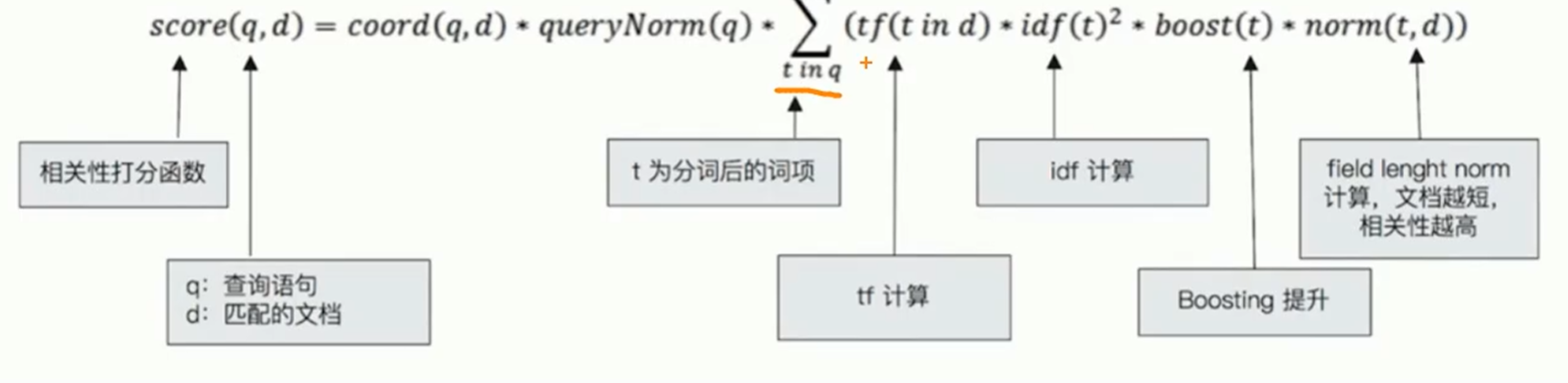
TF_IDF算法:
-
TF是詞頻:檢索詞在文檔中出現的頻率越高,相關性也就越高
-
IDF是逆向文本頻率:每個檢索詞在索引中出現的頻率,頻率越高,相關性就越低。
-
字段長度歸一值:檢索詞出現在一個內容短的title要比同樣的詞出現在一個內容長的content字段權重更大
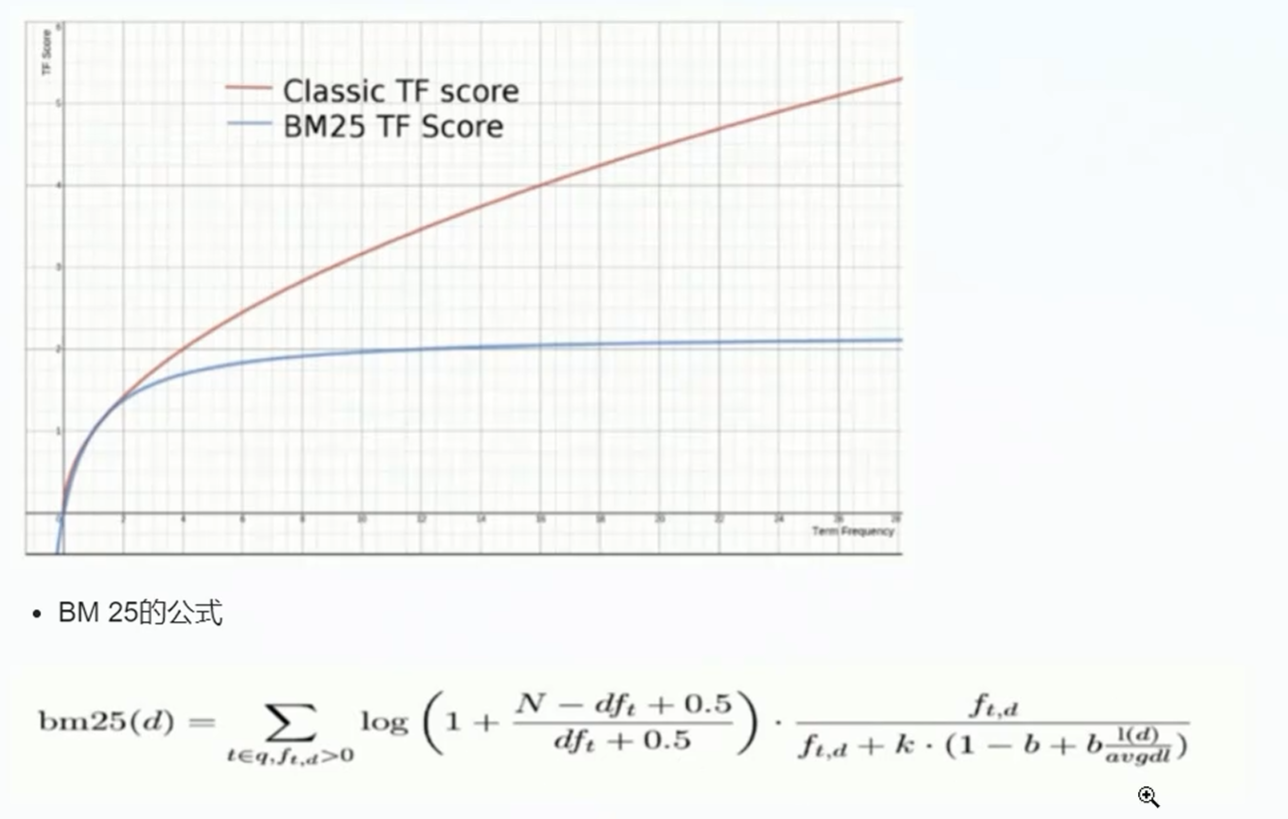
BM 25算法:
和經典的TF_IDF的算法比較起來,當TF無限增加時,BM 25算分會趨近于一個數值
自定義評分策略

Index Boost(索引級權重)
作用:提升指定索引的文檔相關性,適用于跨索引搜索。
GET /index1,index2/_search
{
? "indices_boost": [
??? { "index1": 1.5 },? // index1的文檔相關性提升50%
??? { "index2": 0.8 }?? // index2的文檔相關性降低20%
? ],
? "query": { "match_all": {} }
}
Boosting Query(條件權重)
作用:提升或降低匹配特定條件的文檔評分。
GET /products/_search
{
? "query": {
??? "boosting": {
????? "positive": { "match": { "title": "手機" } },? // 匹配的文檔基礎評分
????? "negative": { "term": { "brand": "A" } },????? // 匹配此條件的文檔降權
????? "negative_boost": 0.2? // 負向權重系數(原評分 × 0.2)
??? }
? }
}
Function Score(自定義評分)
作用:通過函數動態計算文檔評分,支持多種評分函數組合。
GET /articles/_search
{
? "query": {
??? "function_score": {
????? "query": { "match": { "content": "AI" } },? // 基礎查詢
????? "functions": [
??????? {
????????? "filter": { "term": { "category": "tech" } }, // 過濾條件
????????? "weight": 2? // 符合條件文檔評分 ×2
??????? },
??????? {
????????? "field_value_factor": {? // 字段值影響評分
??????????? "field": "views",
??????????? "modifier": "log1p",
??????????? "factor": 0.1
????????? }
??????? }
????? ],
????? "boost_mode": "multiply"? // 評分計算方式(默認sum)
??? }
? }
}
Rescore Query(二次評分)
作用:對初始查詢結果進行二次評分,優化性能。
GET /logs/_search
{
? "query": { "match": { "message": "error" } },
? "rescore": {
??? "window_size": 50,? // 對前50個結果二次評分
??? "query": {
????? "rescore_query": {
??????? "function_score": {
????????? "query": { "match_all": {} },
????????? "script_score": {
??????????? "script": "_score * doc['severity'].value"? // 根據嚴重程度調整評分
????????? }
??????? }
????? }
??? }
? }
}
總結:
| 方法 | 適用場景 | 性能影響 | 靈活性 |
|---|---|---|---|
| Index Boost | 多索引搜索時優先級控制 | 低 | 低 |
| Boosting Query | 簡單條件降權(如排除低質量內容) | 中 | 中 |
| Function Score | 復雜評分邏輯(如熱度、點擊率加權) | 高 | 高 |
| Rescore Query | 分頁后優化Top N結果(如精細化排序) | 可控 | 中 |
多字段查詢優化
最佳字段搜索
-
最佳字段(Best Fields):在多個字段中返回評分最高的
-
多數字段(Most Fields):匹配多個字段,返回各個字段評分之和
-
混合字段(Cross Fields):跨字段匹配,待查詢內容在多個字段中都顯示
最佳字段(Best Fields)
核心邏輯
-
評分機制:從所有匹配字段中取 最高評分 作為文檔最終評分。
-
適用場景:關鍵詞集中在單一字段(如商品標題優先于描述)。
-
默認類型:
multi_match的默認策略即為best_fields。
//語法示例
GET /products/_search
{
? "query": {
??? "multi_match": {
????? "query": "無線藍牙耳機",
????? "fields": ["title^3", "description"],? // title權重提升3倍
????? "type": "best_fields",
????? "tie_breaker": 0.3? // 其他字段評分的30%加入總分。平衡因子
??? }
? }
}
多數字段(Most Fields)
核心邏輯
-
評分機制:將 所有匹配字段的評分累加 作為文檔最終評分。
-
適用場景:關鍵詞分散在多個字段(如標題和描述均含部分關鍵詞)。
GET /articles/_search
{
? "query": {
??? "multi_match": {
????? "query": "機器學習框架",
????? "fields": ["title", "content", "tags"],
????? "type": "most_fields",? // 合并所有字段評分
????? "minimum_should_match": "50%"? // 至少匹配50%詞項
??? }
? }
}
混合字段(Cross Fields)
核心邏輯
-
評分機制:將多個字段視為 一個整體字段,要求所有詞項在 任意字段組合 中匹配。
-
適用場景:跨字段嚴格匹配(如地址:省+市+街道需完整匹配)。
GET /users/_search
{
? "query": {
??? "multi_match": {
????? "query": "張三 杭州 西湖區",
????? "fields": ["province", "city", "district"],
????? "type": "cross_fields",? // 所有詞項需在任意字段中覆蓋
????? "operator": "AND"??????? // 必須匹配所有詞項
??? }
? }
}
| 維度 | Best Fields | Most Fields | Cross Fields |
|---|---|---|---|
| 評分重點 | 單字段最佳匹配 | 多字段累計貢獻 | 跨字段聯合覆蓋 |
| 適用場景 | 核心字段優先級高(如標題) | 多字段互補(如標題+描述) | 嚴格跨字段匹配(如姓名+地址) |
| 性能開銷 | 低 | 中 | 高(需跨字段驗證) |
| 典型參數 | tie_breaker | minimum_should_match | operator(需設為AND) |
聚合
簡介:聚合(Aggregation) 是數據處理中的一種核心操作,指將多行數據合并為單個統計值的過程。它常用于對數據集進行匯總分析。
-
桶(Bucket)聚合:用來對文檔做分組
-
TermAggregation:按照文檔字段值進行分組
-
Date Histogram:按照日期階梯進行分組。如一周為一組,一月為一組
-
-
度量(Metric)聚合:用于計算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同時求max、min、avg、sum等
-
-
管道(Pipeline)聚合:其它聚合的結果為基礎做聚合,類比于嵌套聚合
-
Derivative(導數聚合):計算相鄰分桶的差值。
-
Moving Average(移動平均):計算滑動窗口內的平均值。
-
Bucket Script(自定義腳本):用腳本處理多個聚合結果。
-
桶(Bucket)聚合

//按照文檔字段進行分組檢索
{
? "aggs": {
??? "group_by_field": {
????? "terms": { "field": "字段名" }
??? }
? }
}//按照日期進行分組檢索
{
? "aggs": {
??? "group_by_date": {
????? "date_histogram": {
??????? "field": "日期字段",
??????? "calendar_interval": "1d"? // 間隔:1天、1M、1y 等
????? }
??? }
? }
}
度量(Metric)聚合

{
? "aggs": {
??? "metric_name": { "avg": { "field": "數值字段" } }
? }
}
管道(Pipeline)聚合
// 先按日期分桶,再計算每月銷售額的月環比增長率
GET /sales/_search
{
? "size": 0,
? "aggs": {
??? "sales_per_month": {
????? "date_histogram": { "field": "date", "calendar_interval": "1M" },
????? "aggs": {
??????? "total_sales": { "sum": { "field": "amount" } },
??????? "monthly_growth": {
????????? "derivative": { "buckets_path": "total_sales" } // 導數聚合
??????? }
????? }
??? }
? }
}



















 瞬態仿真)