指令重排序
指令重排序是指在程序執行過程中,為了提高性能,編譯器或處理器會對指令的執行順序進行重新排列。
指令重排序導致可見性消失
在多線程環境下,每個線程都有自己的工作內存,線程對變量的操作是在工作內存中進行的,而不是直接操作主內存中的變量。當線程將主內存中的變量讀取到工作內存后,如果發生指令重排序,可能會導致該線程對變量的修改在其他線程看來不可見。這是因為指令重排序可能會使變量的修改在時間上被推遲,而其他線程在這段時間內讀取的仍然是舊值,從而出現可見性問題
示例
public class VisibilityProblem {private static boolean flag = false;private static int data = 0;public static void main(String[] args) throws InterruptedException {// 線程1負責修改flag和data的值Thread thread1 = new Thread(() -> {data = 10;flag = true;});// 線程2在flag為true時,打印data的值Thread thread2 = new Thread(() -> {while (!flag) {// 線程2在此處自旋等待flag變為true}System.out.println("data = " + data);});thread1.start();thread2.start();thread1.join();thread2.join();}
}按照正常的邏輯,線程 1 先將data賦值為 10,然后將flag設置為true,線程 2 在flag變為true后,應該打印出data的值為 10。然而,由于指令重排序,線程 1 中對data和flag的賦值操作可能會被重排序,導致線程 2 可能先看到flag變為true,而此時data的值可能還沒有被更新為 10,從而打印出錯誤的結果(可能是 0)。
解決方案
- 使用 volatile 關鍵字:對共享變量使用
volatile關鍵字修飾,它可以保證變量的內存可見性,即當一個線程修改了volatile變量的值,其他線程能夠立即看到這個修改,同時禁止指令重排序,確保volatile變量的讀寫操作按照程序中的順序執行。如將上述代碼中的flag聲明改為private static volatile boolean flag = false;,就可以解決可見性問題。 - 使用鎖機制:通過
synchronized關鍵字或者ReentrantLock等鎖機制來保證同一時刻只有一個線程能夠訪問共享資源,這樣可以避免指令重排序帶來的可見性問題。因為在獲取鎖和釋放鎖的過程中,會有相應的內存屏障來保證內存的可見性和禁止指令重排序。例如,將線程 1 中修改data和flag的代碼放在synchronized塊中,也能解決可見性問題。
指令重排序解決翻案
雖然因為流水線技術導致了指令重排序產生可能的錯誤,但它提高了性能。所有我們可以禁止一定數量的指令重排序。比如說有200行代碼,我們需要這兩行不要指令重排序,按順序執行,那么我們只設計局部。防止指令重排序就行了。
-
使用內存屏障(Memory Barrier)
- 原理:內存屏障是一種指令,它可以阻止處理器在內存屏障之前的指令和之后的指令之間進行重排序,并且確保在執行到內存屏障時,之前所有的寫操作都已經完成并對其他處理器可見,之后的讀操作將獲取到最新的值。
- 作用:通過在適當的位置插入內存屏障,可以保證多線程環境下內存操作的順序性和可見性,從而避免因指令重排序導致的問題。例如,在 Java 中,
volatile關鍵字的實現就利用了內存屏障,當對volatile變量進行寫操作時,會在寫操作之后插入一個寫內存屏障,確保寫操作對其他線程可見;當對volatile變量進行讀操作時,會在讀操作之前插入一個讀內存屏障,確保讀到的是最新的值。
-
利用原子操作和同步機制
- 原理:原子操作是指在執行過程中不會被中斷的操作,它要么完全執行,要么完全不執行。在多線程環境下,使用原子操作可以保證對共享資源的訪問是原子性的,避免了指令重排序和數據競爭問題。同時,同步機制如鎖(
synchronized關鍵字、ReentrantLock等)可以保證在同一時刻只有一個線程能夠訪問被保護的代碼塊或資源。 - 作用:在獲取鎖和釋放鎖的過程中,會有相應的內存屏障來保證內存的可見性和禁止指令重排序。例如,當一個線程獲取鎖時,會清空自己的工作內存,從主內存中重新讀取共享變量的值;當釋放鎖時,會將工作內存中的修改刷新到主內存中,確保其他線程能夠看到最新的值。
- 原理:原子操作是指在執行過程中不會被中斷的操作,它要么完全執行,要么完全不執行。在多線程環境下,使用原子操作可以保證對共享資源的訪問是原子性的,避免了指令重排序和數據競爭問題。同時,同步機制如鎖(
-
采用線程局部存儲(Thread - Local Storage,TLS)
- 原理:線程局部存儲是一種為每個線程提供獨立存儲空間的機制,每個線程可以在自己的局部存儲中存儲和訪問數據,而不會影響其他線程。
- 作用:通過將共享變量復制到線程局部存儲中,每個線程只操作自己的副本,避免了多線程對共享變量的并發訪問,從而消除了指令重排序和數據競爭的可能性。不過,使用線程局部存儲需要注意數據的生命周期管理,確保在使用完畢后及時清理,避免內存泄漏。
內存屏障
- 類型:
storeFence():禁止寫操作重排序(寫屏障)。loadFence():禁止讀操作重排序(讀屏障)。fullFence():禁止所有內存操作重排序(全屏障)。
- 適用場景:在需要保證順序的兩行代碼前后插入屏障,確保它們不會被重排序。
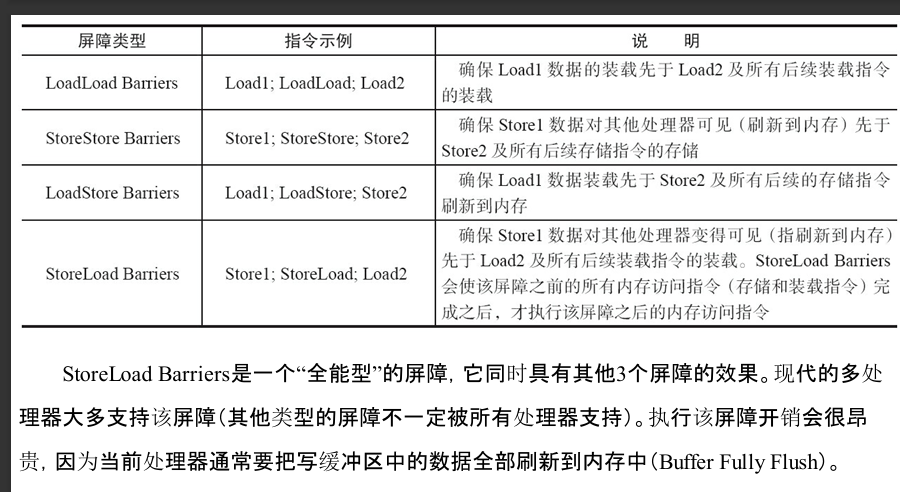
指令重排序規則
規則(Load-Load/Load-Store....)上一行代碼和下一行代碼相鄰的兩行代碼。第一行是XX操作,第二行是XX操作。
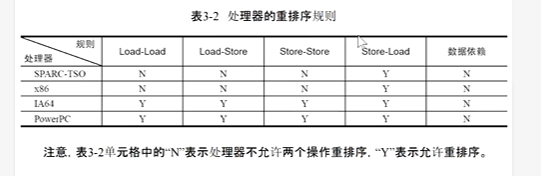
常見的處理器都允許Store-Load重排序;常見的處理器都不允許對存在數據依賴的操作做重排序。sparc-TSO和X86擁有相對較強的處理器內存模型,它們僅允許對寫-讀操作做重排序(因為它們都使用了寫緩沖區)。
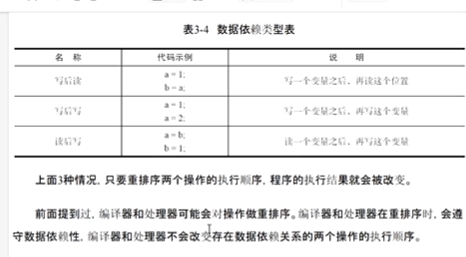
數據依賴
數據依賴是指兩條指令之間存在對同一數據的操作,且后一條指令的執行結果依賴于前一條指令的執行結果。它是指令重排序的核心約束條件之一,決定了指令能否被重新排列。
a = 10; // 指令1:寫入a
b = a + 5; // 指令2:讀取a的值,依賴指令1的結果 禁止重排序。若交換指令 1 和指令 2 的順序,指令 2 將讀取到未初始化的 a(或舊值),導致結果錯誤。
happens-before

是一個核心概念,用于定義多線程環境下操作之間的順序關系,確保前一個操作的結果對后續操作可見,并禁止不合理的指令重排序。它是判斷多線程程序是否正確的重要依據,而非實際執行順序的 “時間先后”,而是一種?邏輯上的因果關系。注意兩個操作之間具有 happen before 關系,并不意味著前一個操作必須在后一個操作前執行,它僅僅要求前一個操作執行的結果。對后可見。且前一個操作按照順序排在第二個操作后面
?
happens-before 的核心規則
JMM 定義了以下?6 條基本規則(另有傳遞性規則),滿足這些規則的操作對,前者的結果對后者可見,且兩者之間不會發生指令重排序:
1.?程序順序規則(Program Order Rule)
- 同一線程內,按照代碼順序,前面的操作?happens-before?后面的操作。
單線程內,后續操作必然能看到前面操作的結果(編譯器 / 處理器不會重排序破壞真依賴)。int a = 1; // 操作1 happens-before 操作2 int b = a; // 操作2
2.?監視器鎖規則(Monitor Lock Rule)
- 解鎖操作(
unlock)happens-before?后續對同一鎖的?加鎖操作(lock)。
鎖的釋放會將工作內存的數據刷新到主內存,加鎖會清空工作內存并重新讀取主內存數據。synchronized (lock) {x = 10; // 寫操作,unlock happens-before 后續的 lock } // 解鎖 // 其他線程獲取鎖后: synchronized (lock) {int y = x; // 能看到 x=10(因 unlock happens-before 此次 lock) }
3.?volatile 變量規則(Volatile Variable Rule)
- 對?volatile 變量的寫操作 happens-before?后續對該變量的?讀操作。
volatile int flag = 0; // 線程A: flag = 1; // 寫volatile,happens-before 線程B的讀操作 // 線程B: int i = flag; // 能看到 flag=1(禁止讀寫操作重排序,且保證內存可見性)
volatile 通過內存屏障禁止重排序,并強制讀寫時刷新主內存。
4.?線程啟動規則(Thread Start Rule)
- 主線程中調用?
thread.start()?happens-before?該線程內的?第一個操作。
啟動線程后,線程內的操作必然能看到啟動前的可見狀態。Thread thread = new Thread(() -> {x = 10; // 線程內第一個操作,保證在 thread.start() 之后可見 }); thread.start(); // happens-before 線程內的所有操作
5.?線程終止規則(Thread Termination Rule)
- 線程內的?最后一個操作 happens-before?其他線程通過?
thread.join()?返回?或檢測到線程終止(如?isAlive()?為 false)。Thread thread = new Thread(() -> {x = 10; // 線程內最后一個操作 }); thread.start(); thread.join(); // join() 返回時,保證能看到線程內 x=10 System.out.println(x); // 輸出 10
join () 會等待線程執行完畢,確保線程內所有操作的結果對主線程可見。
6.?線程中斷規則(Thread Interruption Rule)
- 對線程的?
interrupt()?調用 happens-before?被中斷線程檢測到中斷事件(如?interrupted()?或?isInterrupted()?返回 true)。Thread thread = new Thread(); // 線程A: thread.interrupt(); // happens-before 線程B檢測到中斷 // 線程B: boolean isInterrupted = thread.isInterrupted(); // 能正確檢測到中斷
7.?對象終結規則(Finalizer Rule)
- 對象的?構造函數執行完畢 happens-before?其?
finalize()?方法的開始。
傳遞性規則(Transitivity)
如果操作 A happens-before 操作 B,且操作 B happens-before 操作 C,則?操作 A happens-before 操作 C。
// 規則組合示例:
// 1. 線程1解鎖鎖 L(A happens-before B)
// 2. 線程2獲取鎖 L(B happens-before C)
// 3. 線程2讀取變量 x(C happens-before D)
// 傳遞后:線程1對x的修改(在解鎖前)happens-before 線程2對x的讀取(D)
happens-before 與指令重排序的關系
- 保證可見性:滿足 happens-before 的操作對,前者的結果對后者可見(無需擔心緩存未刷新或重排序導致的舊值)。
- 限制重排序范圍:JVM 允許編譯器 / 處理器對不違反 happens-before 規則的操作進行重排序,以優化性能。
- 例如:無 happens-before 關系的操作(如不同線程的無依賴操作),可能被重排序;
- 有 happens-before 關系的操作,其順序在內存語義上不可被打破。
happen before 傳遞性
如果?操作 A happens-before 操作 B,且?操作 B happens-before 操作 C,則?操作 A happens-before 操作 C。
傳遞性的本質是將多個獨立的 happens-before 關系 “串聯” 起來,形成更長的因果鏈,確保最終的操作結果可見性。
public class TransitivityExample {static int x = 0;static final Object lock = new Object();// 線程1:修改x并釋放鎖static class Thread1 extends Thread {public void run() {synchronized (lock) { // 加鎖1(操作A)x = 10; // 寫x(操作B)} // 釋放鎖(操作C)}}// 線程2:獲取鎖并讀取xstatic class Thread2 extends Thread {public void run() {synchronized (lock) { // 加鎖2(操作D)int y = x; // 讀x(操作E)System.out.println(y); // 輸出10}}}public static void main(String[] args) throws InterruptedException {Thread1 t1 = new Thread1();Thread2 t2 = new Thread2();t1.start();t2.start();t1.join();t2.join();}
}- 基本規則應用:
- 線程 1 內:操作 B(寫 x)happens-before 操作 C(釋放鎖)(程序順序規則)。
- 鎖規則:操作 C(釋放鎖)happens-before 操作 D(獲取鎖)(監視器鎖規則)。
- 線程 2 內:操作 D(獲取鎖)happens-before 操作 E(讀 x)(程序順序規則)。
- 傳遞性推導:
操作 B → 操作 C → 操作 D → 操作 E,通過傳遞性,操作 B happens-before 操作 E,確保線程 2 讀取到 x=10。
重排序
如果兩個操作訪問同一個變量,且這兩個操作中有一個為寫操作,此時這兩個操作之間 就存在數據依賴性。這里所說的數據依賴性僅針對單個處理器中執行的指令序列和單個線程中執行的操作,不同處理器之間和不同線程之間的數據依賴性不被編譯器和處理器考慮。
數據依賴性的定義與條件
當兩個操作訪問同一個變量,且至少有一個操作是寫操作時,這兩個操作之間存在數據依賴性。具體包括以下三種場景(均滿足 “至少一個寫操作”):
- 真依賴(寫→讀):前一個操作寫變量,后一個操作讀該變量(如?
a=1; b=a;)。 - 反依賴(讀→寫):前一個操作讀變量,后一個操作寫該變量(如?
b=a; a=1;)。 - 輸出依賴(寫→寫):兩個操作都寫同一個變量(如?
a=1; a=2;)。
關鍵約束:
- 數據依賴性僅針對?單個線程內的操作序列?或?單個處理器中執行的指令序列。
- 編譯器和處理器只考慮單線程內的數據依賴,跨線程、跨處理器的數據依賴被忽略(即不保證多線程間的操作順序和可見性)。
數據依賴性對指令重排序的影響(單線程 vs 多線程)
1.?單線程場景
- 編譯器和處理器?必須遵守數據依賴性,不會對存在數據依賴的操作進行重排序(尤其是真依賴)。
- 例如:
a=1; b=a+1;?中,真依賴存在,重排序會改變結果,因此禁止重排序。 - 反依賴和輸出依賴允許重排序,但通過寄存器重命名等技術保證單線程結果正確性(如?
a=1; a=2;?重排序為?a=2; a=1;?無意義,但最終結果以最后一次寫入為準)。
- 例如:
2.?多線程場景
- 跨線程的數據依賴性不被編譯器和處理器考慮!即使兩個線程操作同一變量(且至少一個是寫操作),編譯器 / 處理器可能對跨線程的操作進行重排序,導致以下問題:
- 可見性問題:線程 A 寫入變量后,線程 B 可能讀取到舊值(因未刷新主內存或指令重排序)。
- 偽數據依賴問題:跨線程的操作看似無依賴(如線程 A 寫?
x?和線程 B 寫?y),但實際可能通過共享變量隱含依賴(如依賴?x?和?y?的寫入順序)。
順序一致性
順序一致性內存模型是一個理論參考模型,在設計的時候,處理器的內存模型和編程語 言的內存模型都會以順序一致性內存模型作為參照。就是同步操作。
Java 中 64 位變量(long/double)寫操作的原子性問題及多線程風險
核心問題
-
Java 內存模型(JVM)的規定:
- 對?64 位的
long和double類型變量的寫操作,不保證原子性(讀操作同理,除非使用volatile)。 - 即:寫一個
long變量(64 位)可能被拆分為?兩次 32 位的寫操作(高 32 位和低 32 位)。
- 對?64 位的
-
多線程場景下的風險:
- 若兩個線程同時修改同一個
long變量,可能出現?“半更新” 現象:- 線程 A 寫入前 32 位,尚未寫入后 32 位時,線程 B 被調度,寫入后 32 位,最終變量值為線程 A 的前 32 位 + 線程 B 的后 32 位(數據錯位)。
- 或線程 A 的寫操作未完成時,線程 B 讀取變量,得到前 32 位是新值、后 32 位是舊值的 “拼湊結果”。
- 若兩個線程同時修改同一個
-
底層硬件原因:
- CPU 內存總線寬度不足(如 32 位總線):傳輸 64 位數據需分兩次完成,無法保證一次性寫入。
- 即使在 64 位處理器上,Java 規范也未強制要求原子性(允許平臺優化),導致跨平臺不一致性。
問題本質
- 原子性缺失:64 位數據的寫操作被拆分為兩次獨立的 32 位操作,兩次操作之間可能發生線程切換,導致數據不一致。
- 可見性與順序性問題:即使不考慮線程切換,非原子寫操作也可能因指令重排序或緩存延遲,讓其他線程看到中間狀態。
解決方案
-
使用
volatile關鍵字:- 對
volatile long或volatile double的寫操作,JVM 強制保證原子性(底層通過內存屏障實現)。 - 示例:
private volatile long value; // 寫操作原子性有保障
- 對
-
使用原子類
AtomicLong(或AtomicReference<Long>):AtomicLong提供get()、set()、compareAndSet()等原子操作方法,確保 64 位數據的讀寫原子性。- 示例:
private AtomicLong value = new AtomicLong(0); value.set(100L); // 原子寫 long v = value.get(); // 原子讀
-
使用同步機制(
synchronized或顯式鎖):- 通過加鎖保證同一時刻只有一個線程執行寫操作,避免線程切換導致的半更新問題。
- 示例:
private long value; private final Object lock = new Object();public void setValue(long v) {synchronized (lock) {value = v; // 加鎖后寫操作具有原子性} }
總結建議
- 優先使用
AtomicLong:比volatile更靈活(支持原子更新操作),比synchronized性能更好(無鎖或輕量級鎖實現)。 - 避免依賴平臺特性:即使某些 64 位處理器保證
long寫原子性,Java 規范未強制要求,必須通過顯式機制(volatile/ 原子類 / 鎖)保證跨平臺一致性。 - 理解原子性邊界:原子性僅保證單次操作的完整性,復合操作(如 “先讀再寫”)仍需額外同步(如 CAS 或鎖)。
事務?
事務是一個批次的操作,要么都成功,要么都失敗的意思。一個事務可能會有很多步驟,這里關鍵是總線會同步,總線會同步試圖并發使用總線的事務。競爭總線的這些事物會排隊在一個處理器的執行總線事務時間,總線會禁止其他的處理器和 IO 設備執行內存的讀寫,也就說呢,其中一個使用總線的時候,其他就得等著。是物理信號不允許。
總線事務。總線所有的步驟沒處理完,我不會釋放總線我們最怕的什么呢?我們最怕的,比如說我們對內層操作有兩步,執行完一步的時候中斷了其他的線程來執行了。我沒處理完。我一直站著走路線,其他的用不了。
volatile特性
volatile阻止指定重排序,它能夠阻止重排序,它保障線程可見性就是它能保證了你此時此刻能讀到最準確的。
它修飾的變量在后邊被操作的過程中讀或者寫的前后受到影響(上下兩行)。離得遠的行數不受影響。

單例模式
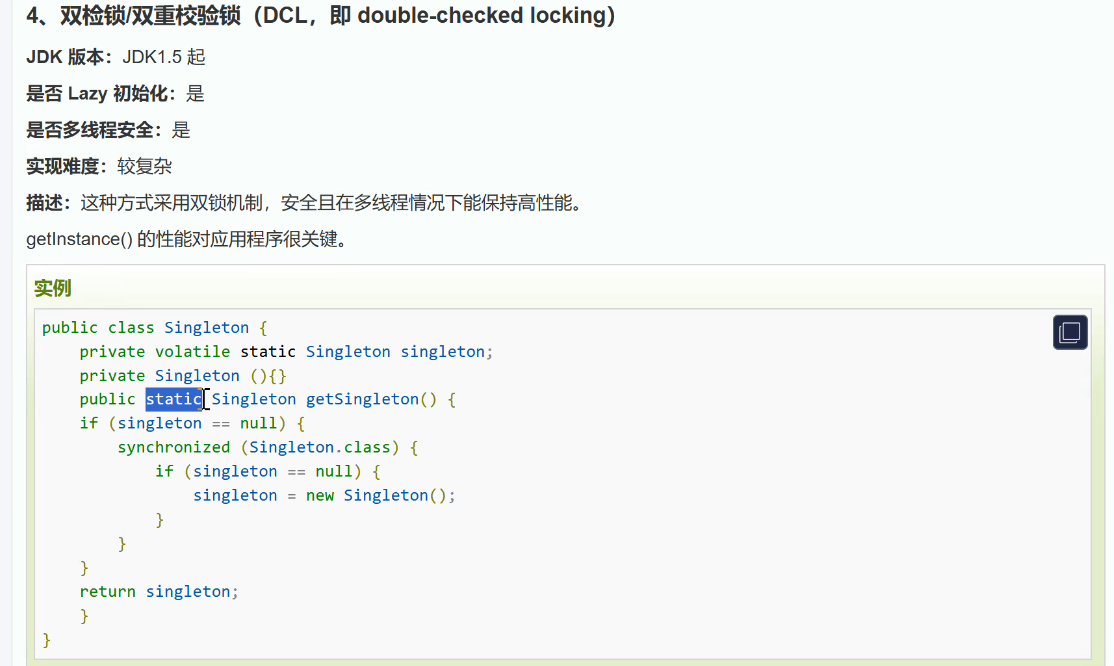
關鍵設計點
-
私有構造函數:防止外部通過
new創建實例,確保單例性。 -
靜態 volatile 變量:
volatile關鍵字確保變量的寫操作先行發生于后續的讀操作(禁止指令重排序),避免其他線程看到 "半初始化" 狀態的對象。- 在 JDK 5 及以后版本,
volatile提供了內存屏障功能,保證初始化對象的過程不會被重排序。
-
雙重檢查機制:
- 第一次檢查(無鎖):多數情況下實例已經創建,直接返回,避免進入同步塊,提高性能。
- 同步塊:僅當第一次檢查發現實例為 null 時才進入,確保只有一個線程創建實例。
- 第二次檢查(同步塊內):防止多個線程同時通過第一次檢查后,重復創建實例。
為什么需要 volatile?
volatile關鍵字的作用是禁止指令重排序,確保初始化對象的過程按順序完成:
- 分配內存空間
- 初始化對象
- 將引用指向內存空間
如果沒有volatile,可能發生指令重排序,順序變為:1→3→2。當線程 A 執行了 1 和 3 但還未執行 2 時,線程 B 檢查singleton不為 null,直接返回未完全初始化的對象,導致錯誤。
優點
- 線程安全:通過雙重檢查和同步機制,確保只有一個實例被創建。
- 高效性:大多數情況下無需進入同步塊,性能開銷小。
- 延遲加載:實例在第一次使用時才被創建,避免資源浪費。
構造方法,私有無法通過它 new1個對象出來?。構造方法私有無法通過,無法new出對象。沒有對象怎么調方法,沒有對象能調靜態方法,所以方法必須是靜態。
方法為什么也是靜態的,因為靜態方法只能對靜態變量進行操作,靜態方法無法對非靜態變量進行操作。
這加上鎖的意思呢?就是說。創建對象的時候,只能有一個對它進行操作。多線程操作的時候,只能有一個線程競爭所對它進行操作。
所以我們用volatile它的時候才加鎖,用完之后這個鎖就不存在了,因為代碼就進不來了,其他線程對吧,調這個方法直接 return 了,只能同時拷貝一個方法的。
Volatile 內存語義實現:
概念含義?:內存語義的實現即探討 volatile 如何設計、需遵循的規則及具備的功能。
重排序規則?:不同代碼行的普通變量與 volatile 變量的讀寫操作組合有不同重排序規則,如普通變量讀寫與 volatile 寫、volatile 讀與其他代碼行、volatile 寫與普通變量寫或 volatile 寫操作等搭配,9 種組合中阻止 6 種指令重排序,影響范圍為前后兩行。
屏障類型?:有寫讀、讀寫等屏障,分別表示不允許特定兩個操作指令重排序,最終優化只需一個寫讀屏障。
對變量操作定義?:根據變量在等號兩側及是否被 volatile 修飾確定是讀操作還是寫操作,若一行中有 volatile 則以其為主,兩側都是則讀寫都在。
與普通變量重排序限制?:舊內存模型允許 long 變量與普通變量重排序,新規則為提供輕量級線程間通信機制,禁止 volatile 變量與普通變量重排序,因重排序可能破壞語義。
功能性能特點?:保證單個變量讀寫原子性,功能不如鎖強大,如 cyclic 鎖更霸道,volatile 允許同時讀,鎖不允許;但 volatile 在可伸縮和執行性能上有優勢,相對輕量級。
鎖的內存語義?:
synchronize 相關?:鎖的釋放獲取存在 happens-before 關系,即加鎖前上一個鎖需已釋放;線程獲取鎖時將本地內存設置無效,從主內存讀取共享變量,釋放鎖時將本地內存共享變量刷新到主內存。
底層通知機制?:線程競爭鎖,獲取成功的線程釋放鎖時通知阻塞隊列所有線程競爭進入就緒隊列,并非單獨通知某一線程。
公平鎖(Fair Lock)和非公平鎖(Nonfair Lock)
| 特性 | 公平鎖 | 非公平鎖 |
|---|---|---|
| 獲取鎖順序 | 嚴格按照等待隊列順序(先到先得) | 不保證順序,允許搶占(可能插隊) |
| 等待隊列 | 必須檢查隊列頭部是否有前驅節點 | 直接嘗試搶占,不檢查隊列 |
| 線程饑餓 | 較少發生(按順序獲取) | 可能發生(新線程頻繁搶占導致舊線程等待) |
| 上下文切換 | 更多(每次喚醒隊列頭部線程) | 更少(可能直接由剛釋放鎖的線程重新獲取) |
| 吞吐量 | 較低(頻繁線程掛起 / 恢復) | 較高(減少上下文切換開銷) |
| 適用場景 | 需嚴格公平(如資源分配、避免饑餓) | 追求性能(大多數并發場景) |
?
AQS
state 是指加鎖次數?,非公屏鎖性能更好,注意非公平性能更好,公屏鎖性能不好,公平鎖和非公平鎖,哪個是主流呢?非公平所是主流性能更好,性能更好。,任務時間短的先執行,你很快執行完了,你執行完之后我下次不用選你了,我性能更好了
我釋放鎖之后呢,我會輪流去通知這里邊隊列,比如說這里邊有十個線程,我十個線程的話呢,我并不是只通知第一個線程。
我是都同志,我都通知你第一個如果競爭成功了,你去加鎖,如果你不是第一個競爭成功的,你不加鎖。
這樣浪費 CPU 了,就是你通知的時候屬于全都通知的,通知的都是屬于全都通知,但是呢,你只有第一個競爭成功的時候才加鎖其他的優先競爭成功了,屬于白競爭。
會判定你是不是第一個不是第一個的話?你就再歇回去。白白浪費 CPU 性能。而非公平的話呢,就是說。我在隊列一邊有先后順序我會按照先后順序
![]() 獲取當前線程
獲取當前線程





:微服務的劃分原則)









)

)

