簡述
試驗參考了mini_qwen 的開源實現
GitHub - qiufengqijun/mini_qwen: 這是一個從頭訓練大語言模型的項目,包括預訓練、微調和直接偏好優化,模型擁有1B參數,支持中英文。這是一個從頭訓練大語言模型的項目,包括預訓練、微調和直接偏好優化,模型擁有1B參數,支持中英文。. Contribute to qiufengqijun/mini_qwen development by creating an account on GitHub.![]() https://github.com/qiufengqijun/mini_qwen
https://github.com/qiufengqijun/mini_qwen
分詞器使用Qwen/Qwen2.5-0.5B-Instruct,通過擴充模型隱藏狀態層數、嵌入層維度和注意力頭數,增加參數量到1B,使用flash_attention_2進行加速
主要特點:
-
低資源需求:預訓練和微調僅需 12GB 顯存,DPO 訓練需要 14GB 顯存
-
訓練數據:使用來自 BAAI(北京智源人工智能研究院)的數據集,包括用于預訓練的 160 億 tokens、用于微調的 900 萬條樣本,以及用于偏好優化的 6 萬條樣本。
數據集
魔塔社區?BAAI/IndustryCorpus2 數據集,根據需要下載
# 下載預訓練數據集
modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'film_entertainment/*/high*' --local_dir 'data/pt' # 數據量較大,英文文件選擇前3個文件modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'computer_programming_code/*/high*' --local_dir 'data/pt'
modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'computer_communication/*/high*' --local_dir 'data/pt' # 數據量較大,英文文件選擇前3個文件modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'tourism_geography/*/high*' --local_dir 'data/pt'
modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'artificial_intelligence_machine_learning/*/high*' --local_dir 'data/pt'
modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'news_media/*/high*' --local_dir 'data/pt'
modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'literature_emotion/*/high*' --local_dir 'data/pt' # 數據量較大,英文文件選擇前3個文件modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'accommodation_catering_hotel/*/high*' --local_dir 'data/pt'
modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'current_affairs_government_administration/*/high*' --local_dir 'data/pt' # 數據量較大,英文文件選擇前3個文件modelscope download --dataset 'BAAI/IndustryCorpus2' --include 'mathematics_statistics/*/high*' --local_dir 'data/pt'查看下數據
dataset = load_dataset("parquet", data_files="mini_data/pt/accommodation_catering_hotel/chinese/high/rank_00000.parquet", split="train")
print(dataset[0])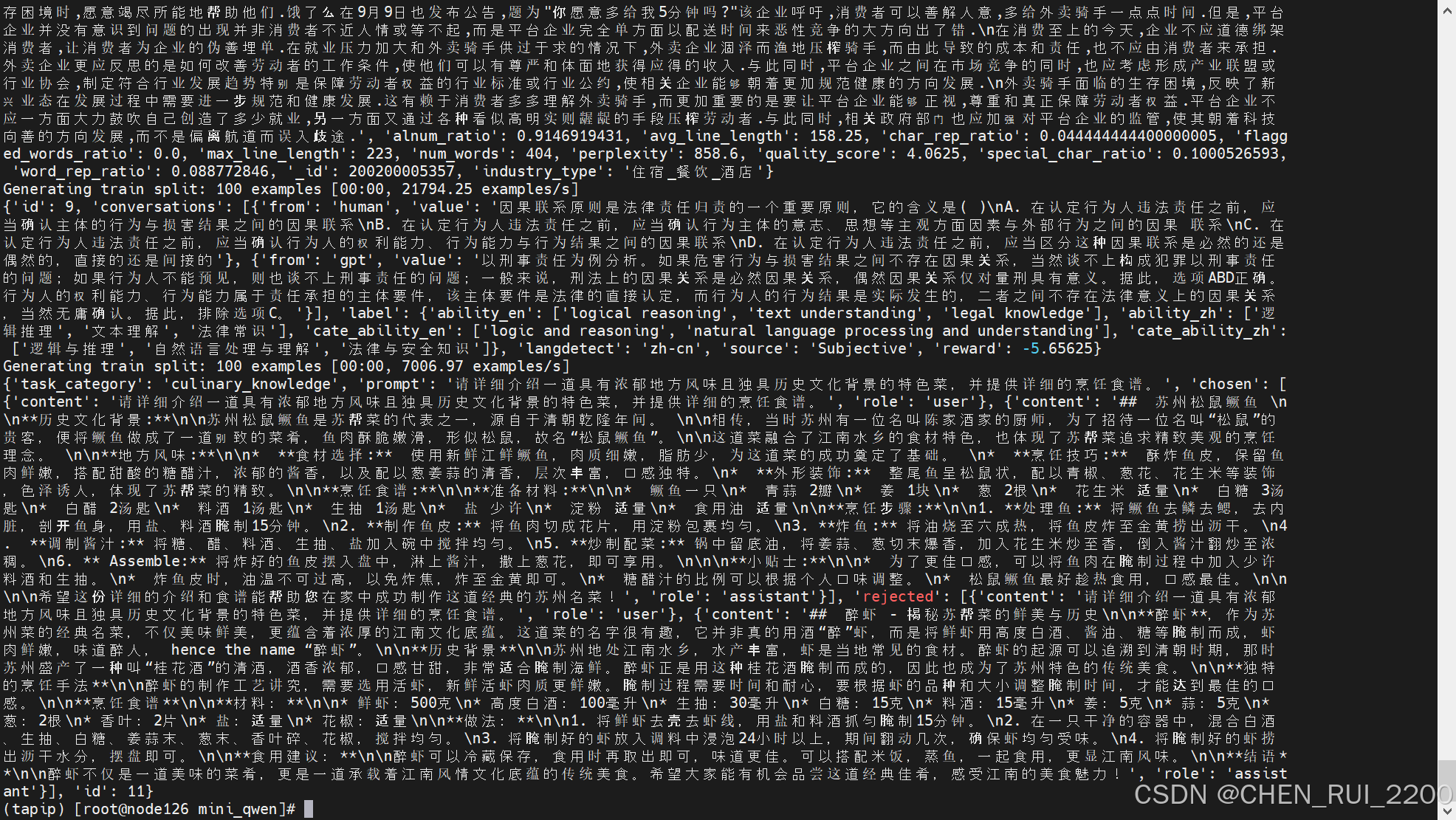
# 大概這么個結構
{"text": "馬亮:如何破解外賣騎手的\"生死劫\"\n在消費至上的今天,企業不應道德綁架消費者,讓消費者為企業的偽善埋單。。。。。。","alnum_ratio": 0.9146919431,"avg_line_length": 158.25,"char_rep_ratio": 0.044444444400000005,"flagged_words_ratio": 0.0,"max_line_length": 223,"num_words": 404,"perplexity": 858.6,"quality_score": 4.0625,"special_char_ratio": 0.1000526593,"word_rep_ratio": 0.088772846,"_id": 200200005357,"industry_type": "住宿_餐飲_酒店"
}
這個結構是一個經過質量分析或過濾的訓練樣本的 JSON 表示,用于語言模型訓練前的數據評估或篩選階段。它除了包含原始文本(text)外還包含了一系列用來衡量數據質量的統計特征指標,用于判斷該樣本是否值得保留用于訓練。
🔹 質量指標字段說明:
| 字段名 | 說明 |
|---|---|
alnum_ratio | 字母數字字符所占比例。用于判斷文本是否主要為自然語言(而非亂碼或表格類數據) |
avg_line_length | 平均每行字符數。可能反映文本結構是否合理(過長/過短) |
char_rep_ratio | 字符重復率。例如“哈哈哈哈哈哈”這種重復率就很高 |
flagged_words_ratio | 敏感詞或不良詞匯占比(0 表示未檢測到敏感詞) |
max_line_length | 最長一行的字符數。可用于過濾極端異常格式文本 |
num_words | 詞數總計。用于衡量樣本長度 |
perplexity | 使用某個語言模型評估的困惑度(perplexity)。數值越低,表示文本越“正常”或模型越容易預測它 |
quality_score | 綜合質量評分。可能是上述特征加權后的結果,衡量樣本是否值得用于訓練 |
special_char_ratio | 特殊字符(如 #¥%&* 等)在文本中的占比 |
word_rep_ratio | 單詞重復率(如“外賣外賣外賣平臺”) |
訓練邏輯
加載數據集
# 加載數據集并進行預處理
directories = ["accommodation_catering_hotel","artificial_intelligence_machine_learning","computer_communication","computer_programming_code","film_entertainment","literature_emotion","news_media","tourism_geography","current_affairs_government_administration","mathematics_statistics",
]
data_files = find_files(directories)
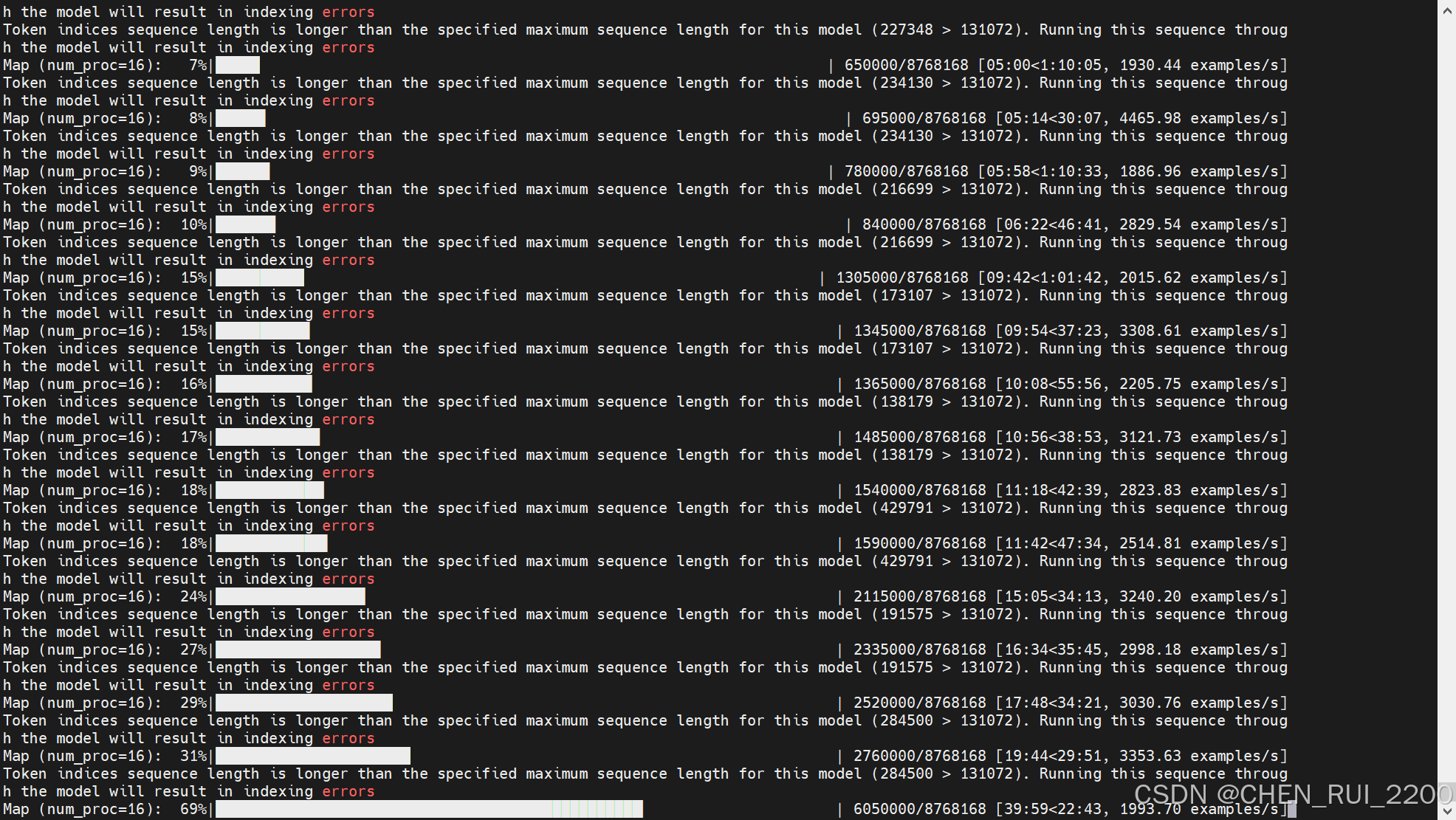
dataset = load_dataset("parquet", data_files=data_files, split="train", columns=["text"]) # 只保留text字段
dataset = dataset.shuffle(seed=42)數據清洗,將原始文本 → 添加結束符 → 分詞 → 拼接成一長串 → 按 block_size 切成多個訓練用的樣本塊(每塊長度一致),給每條文本加上自定義的“結束符” <|im_end|>,把所有樣本的 token 串接在一起(例如把多個 [101,102] 合并為 [101,102,103,104,...]),這是因為 GPT 模型的預訓練目標是連續預測序列,所以訓練輸入是一個“連續的 token 流”。
計算總長度并對齊
-
得到拼接后 token 總長度(例如 10,356)
-
只保留整除
block_size(1024)的部分,截斷掉尾部多余部分,例如:10356 → 10240(保留完整的 10 塊)切成 1024 個 token 一塊的樣本,每隔 1024 個 token 分一塊,生成多個訓練樣本,輸出結構:
{"input_ids": [[token1...token1024], [token1025...token2048], ...],"attention_mask": 同理
}
參考預訓練代碼
def preprocess_dataset(examples):"""預處理預訓練數據集,將文本分詞并分塊"""eos_token = "<|im_end|>"text_examples = [text + eos_token for text in examples["text"]] # 添加結束符tokenized_examples = tokenizer(text_examples, add_special_tokens=False)# 將分詞結果拼接并分塊concatenated_examples = {k: list(chain(*tokenized_examples[k])) for k in tokenized_examples.keys()}total_length = len(concatenated_examples[list(concatenated_examples.keys())[0]])block_size = 1024 # 分塊大小total_length = (total_length // block_size) * block_size # 對齊塊大小result = {k: [t[i : i + block_size] for i in range(0, total_length, block_size)]for k, t in concatenated_examples.items()}return result# 應用預處理函數
train_dataset = dataset.map(preprocess_dataset,batched=True,batch_size=5000,remove_columns=dataset.column_names,num_proc=16,
),原來有很多條文本,現在經過這段預處理函數:
-
文本 → 拼接 → 分詞 → 連續 token 序列 → 按塊切分
-
輸出的每個樣本都是
1024個 token 的一段,可直接送入語言模型進行訓練(如 GPT)
數據預處理
訓練配置
預訓練
accelerate_config.yaml 文件包含了用于配置訓練環境的參數。以下是各個配置項的含義:
- compute_environment: 指定計算環境,這里為本地機器 (
LOCAL_MACHINE)。- debug: 調試模式,設置為
false表示不啟用調試。- deepspeed_config: 包含與 DeepSpeed 相關的配置:
- gradient_accumulation_steps: 梯度累積步數,這里設置為 16。
- gradient_clipping: 梯度裁剪值,防止梯度過大,這里為 1.0。
- offload_optimizer_device: 優化器的卸載設備,這里為
none表示不卸載。- offload_param_device: 參數的卸載設備,這里為
none。- zero3_init_flag: 是否啟用 ZeRO-3 初始化,這里為
false。- zero_stage: ZeRO 優化的階段,這里設置為 2。
- distributed_type: 分布式訓練類型,這里為
DEEPSPEED。- downcast_bf16: 是否降低 bf16 精度,這里設置為 'no'。
- enable_cpu_affinity: 是否啟用 CPU 親和性,設置為
false。- machine_rank: 當前機器在分布式訓練中的排名,這里為 0。
- main_training_function: 主訓練函數的名稱,這里為
main。- mixed_precision: 混合精度訓練,這里使用 bf16。
- num_machines: 參與訓練的機器數量,這里為 1。
- num_processes: 每臺機器上的進程數量,這里為 2。
- rdzv_backend: rendezvous 后端,這里為
static。- same_network: 是否在同一網絡中,設置為
true。- tpu_env: TPU 環境配置,這里為空。
- tpu_use_cluster: 是否使用 TPU 集群,設置為
false。- tpu_use_sudo: 是否使用 sudo 權限,設置為
false。- use_cpu: 是否使用 CPU 進行訓練,設置為
false。
這些配置項幫助用戶設置和優化模型訓練過程,尤其是在使用 DeepSpeed 進行分布式訓練時, 配置參考
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:gradient_accumulation_steps: 16gradient_clipping: 1.0offload_optimizer_device: noneoffload_param_device: nonezero3_init_flag: falsezero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
訓練邏輯
# 已經下載了Qwen2.5-0.5B-Instruct地址
model_path = "./models/Qwen2.5-0.5B-Instruct"
config = AutoConfig.from_pretrained(model_path)# 調整模型配置
config.num_attention_heads = 16
config.num_key_value_heads = 4
config.hidden_size = 1024
config.num_hidden_layers = 48# 加載模型
model = AutoModelForCausalLM.from_config(config, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2")# 加載分詞器
tokenizer = AutoTokenizer.from_pretrained(model_path)# 訓練參數配置
training_args = TrainingArguments(output_dir=output_path,overwrite_output_dir=True,learning_rate=1e-4,warmup_ratio=0.1,lr_scheduler_type="cosine",num_train_epochs=1,per_device_train_batch_size=12,gradient_accumulation_steps=16,save_steps=100_000,save_total_limit=3,bf16=True,# save_only_model=True,logging_steps=20,
)# 初始化Trainer
trainer = Trainer(model=model,args=training_args,data_collator=collator,train_dataset=train_dataset,
)使用accelerate 加速訓練
模型參數量: 576851712
表示模型總共有 576,851,712 個參數,也就是約 5.77 億參數(≈ 577M)。
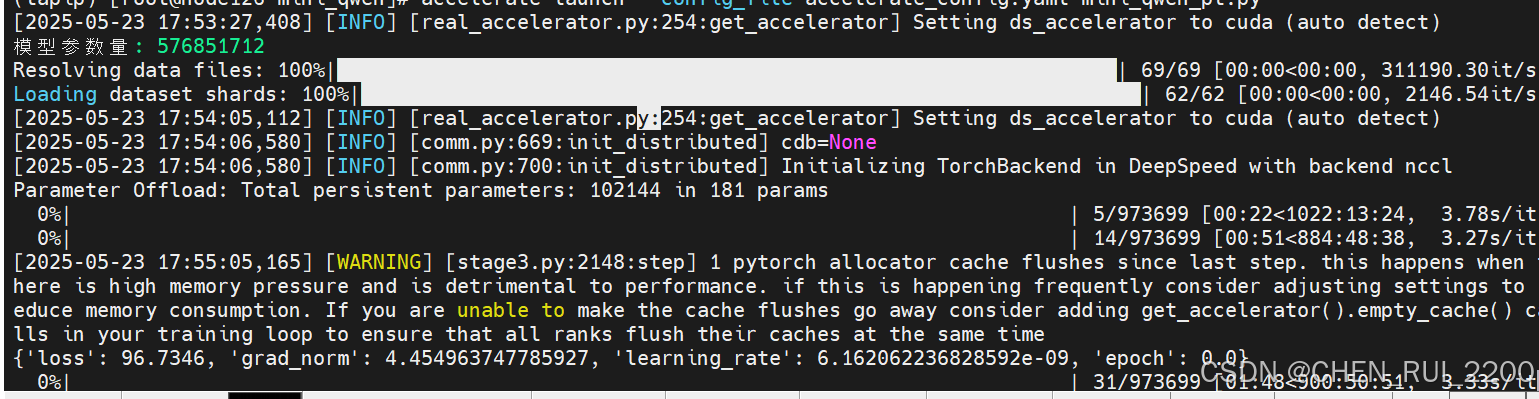
和之前用的MiniMind架構的模型比訓練速度要慢很多,所以直接跳過預訓練使用基座進行微調
SFT微調
?trl 配置
# 訓練參數配置
training_args = SFTConfig(output_dir=output_path, # 訓練完成后模型保存的目錄overwrite_output_dir=True, # 如果目錄已存在則覆蓋原模型learning_rate=1e-5, # 學習率,SFT階段建議小一點warmup_ratio=0.1, # 熱身步數比例,用于逐漸增加學習率lr_scheduler_type="cosine", # 學習率調度策略:余弦退火num_train_epochs=3, # 訓練輪數per_device_train_batch_size=12, # 每張顯卡的batch大小(顯存不夠就調小)gradient_accumulation_steps=16, # 梯度累計步數,總batch大小 = 12 × 16 = 192save_strategy="epoch", # 每輪結束保存一次模型save_total_limit=3, # 最多保存3個checkpoint,舊的自動刪掉bf16=True, # 使用 bfloat16 進行訓練(比 fp16 更穩定,NVIDIA A100/H100 支持)logging_steps=20, # 每20步打印一次日志
)# 初始化Trainer
trainer = SFTTrainer(model=model, # 使用的模型(已初始化)args=training_args, # 上面定義的訓練參數train_dataset=dataset, # 訓練數據集tokenizer=tokenizer, # 分詞器formatting_func=formatting_prompts_func, # 格式化數據的函數,把樣本轉換成 prompt + completiondata_collator=collator, # 數據整理器(例如自動填充、構建input_ids等)
)

![前端[插件化]設計思想_Vue、React、Webpack、Vite、Element Plus、Ant Design](http://pic.xiahunao.cn/前端[插件化]設計思想_Vue、React、Webpack、Vite、Element Plus、Ant Design)






】)

)








