作者:來自 Elastic?Bahubali Shetti

Elastic Observability 不僅提供日志聚合、指標分析、APM 和分布式追蹤,Elastic 的機器學習能力還能幫助分析問題的根因,讓你將時間專注于最重要的任務。
隨著越來越多的應用程序遷移到云端,收集的遙測數據(日志、指標、追蹤)也越來越多,這些數據有助于提升應用性能、運營效率和業務 KPI。然而,面對如此海量的數據,分析變得極其繁瑣且耗時。傳統的告警和簡單模式匹配方法(如可視化或關鍵詞搜索等)已無法滿足 IT 運維團隊和 SRE 的需求,就像在大海撈針一樣困難。
在本文中,我們將介紹 Elastic 在 IT 運維人工智能(AIOps)和機器學習(ML)方面的一些能力,幫助進行根因分析。
Elastic 的機器學習功能將通過提供異常檢測來幫助您調查性能問題,并通過時間序列分析和日志異常值檢測來精準定位潛在的根本原因。這些功能將幫助您縮短在大海撈針的時間。
Elastic 平臺讓你能快速開始使用機器學習,無需數據科學團隊或自行設計系統架構,也無需將數據遷移到第三方框架中進行模型訓練。
Elastic 預置了適用于可觀測性和安全場景的機器學習模型。如果這些模型無法很好地適應你的數據,Elastic 工具內的向導可以引導你通過幾個簡單步驟配置自定義異常檢測并用監督學習訓練模型。
為了幫助你快速上手,Elastic Observability 內置了多項關鍵功能來輔助分析,無需手動運行 ML 模型,從而減少日志分析所需的時間和精力。
以下是一些內置機器學習功能的簡介:
異常檢測:Elastic Observability 啟用后(參考文檔),會實時建模你的時間序列數據的正常行為,學習趨勢、周期性等,從而自動檢測異常,簡化根因分析并減少誤報。異常檢測在 Elasticsearch 中運行并可隨之擴展,并配有直觀的用戶界面。
日志分類:借助異常檢測,Elastic 能快速識別日志事件中的模式。日志分類視圖會基于日志消息和格式對其進行分組,避免你手動分析,讓你能更快采取行動。
高延遲或出錯的事務:Elastic Observability 的 APM 功能可以幫助你發現導致事務延遲的關鍵屬性,并識別哪些屬性最能區分成功和失敗的事務。相關功能概覽見:Elastic Observability 中的 APM 相關性分析:自動識別慢速或失敗事務的可能原因。
AIOps Labs:AIOps Labs 使用高級統計方法提供兩個主要功能:
-
日志突增檢測器:幫助識別日志速率上升的原因。通過分析流程視圖,你可以輕松發現和調查異常突增的根本原因。它會展示指定數據視圖的日志速率直方圖,并找出日志中跨字段、值的突變背后可能的原因。
-
日志模式分析:幫助你在非結構化日志中發現模式,便于更高效地分析數據。它會對選定字段執行分類分析,基于數據創建類別,并展示各類別的分布圖和匹配該類別的示例文檔。
在本文中,我們將基于 Google 開發并由 OpenTelemetry 改進的流行應用 “Hipster Shop” 演示異常檢測和日志分類。
有關高延遲分析功能的概覽請參閱此處,AIOps Labs 的概覽請見此處。
本文將通過一個實際場景展示如何使用異常檢測和日志分類功能,在 Hipster Shop 應用中幫助識別問題的根因。
前提條件與配置
如果你打算跟隨本文操作,以下是我們用于演示的一些組件和配置詳情:
-
確保你已在 Elastic Cloud 上擁有賬戶,并在 AWS 上部署了一個 Stack(部署說明見此)。由于 Elastic Serverless Forwarder 的要求,必須部署在 AWS 上。
-
使用廣受歡迎的 Hipster Shop 演示應用的某個版本。該應用最初由 Google 編寫,用于展示 Kubernetes,在多個變種中都很常見,例如 OpenTelemetry Demo App。Elastic 版本可以在此處找到。
-
確保你已為應用配置 Elastic APM Agent 或 OpenTelemetry Agent。更多詳情請參考以下兩篇博客:在 Elastic 中使用 OTel 實現獨立性 和 在 Elastic 中實現可觀測性與安全性。另外,也可以參考 Elastic 中的 OTel 文檔。
-
查看 Elastic Observability 的 APM 功能概覽。
-
閱讀 Elastic 的日志異常檢測文檔和日志分類文檔。
一旦你使用 APM(Elastic 或 OTel)Agent 對應用進行探針接入,并將指標和日志采集進 Elastic Observability 中,你應該可以看到如下的應用服務拓撲圖:
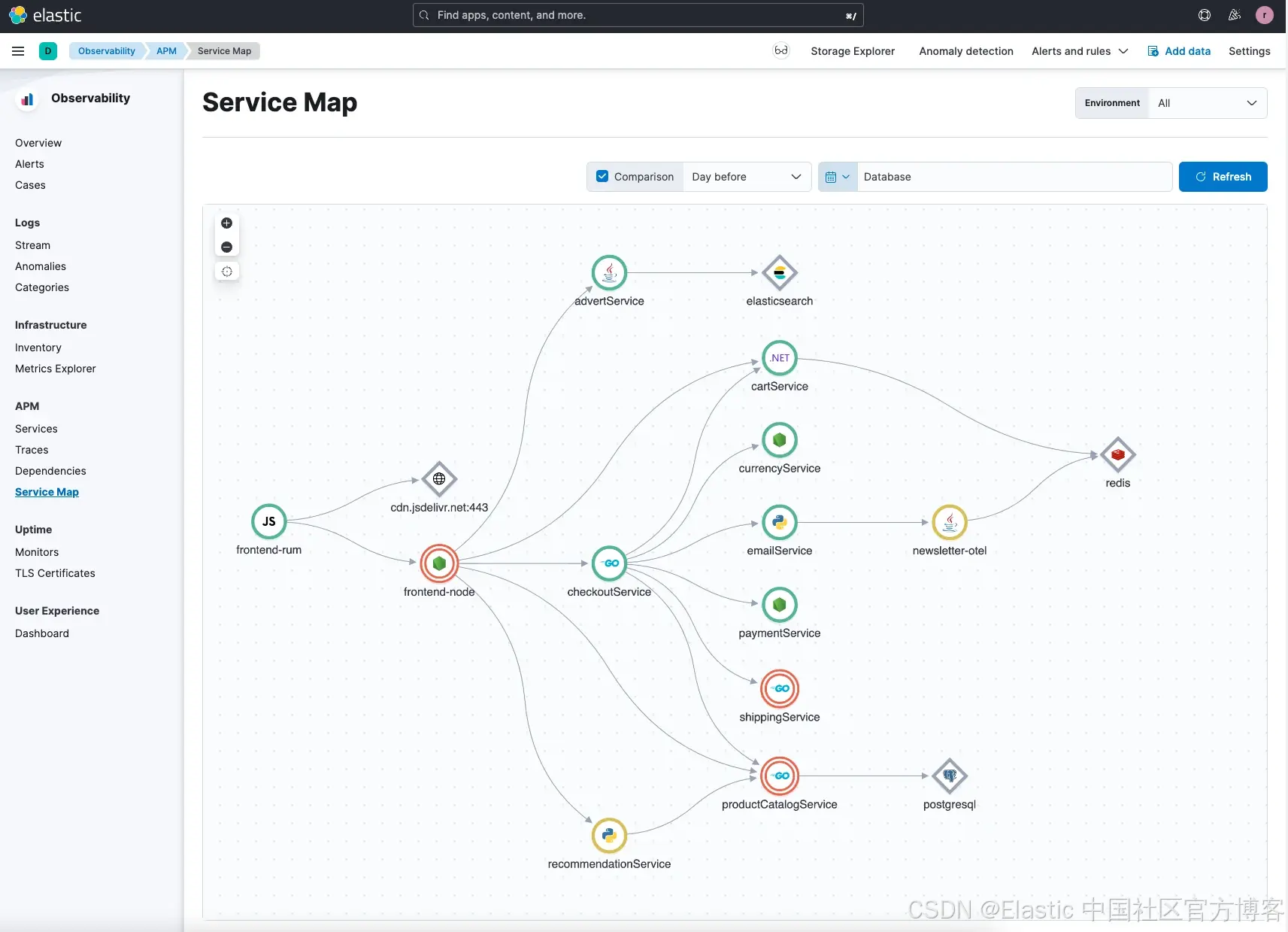
在我們的示例中,我們故意引入了一些問題,以便演示根因分析功能:異常檢測和日志分類。根據你加載應用的方式以及引入問題的不同,所產生的異常和日志分類結果可能會有所差異。
在本次演示中,我們將以 DevOps 或 SRE 的角色來管理生產環境中的這套應用。
根因分析
當應用已正常運行一段時間后,你突然收到通知,提示某些服務狀態異常。這種通知可能來自你在 Elastic 中配置的告警規則,也可能來自外部通知平臺,或是用戶反饋的問題。在這個場景中,我們假設客服接到多位客戶投訴,稱網站存在問題。
那么,作為 DevOps 或 SRE,你該如何展開調查呢?我們將通過 Elastic 的兩種方法來排查問題:
-
異常檢測
-
日志分類
雖然我們將這兩個功能分別展示,但它們是可以 結合使用 的,也是 Elastic Observability 提供的互補工具,旨在幫助你更高效地定位問題根因。
異常檢測中的機器學習
Elastic 會根據歷史模式檢測異常,并識別這些問題發生的概率。
從 服務拓撲圖(Service Map) 開始,你可以看到帶有紅色圓圈標記的異常。當你選擇其中一個異常時,Elastic 會為該異常提供一個評分(score),用于衡量其異常程度。
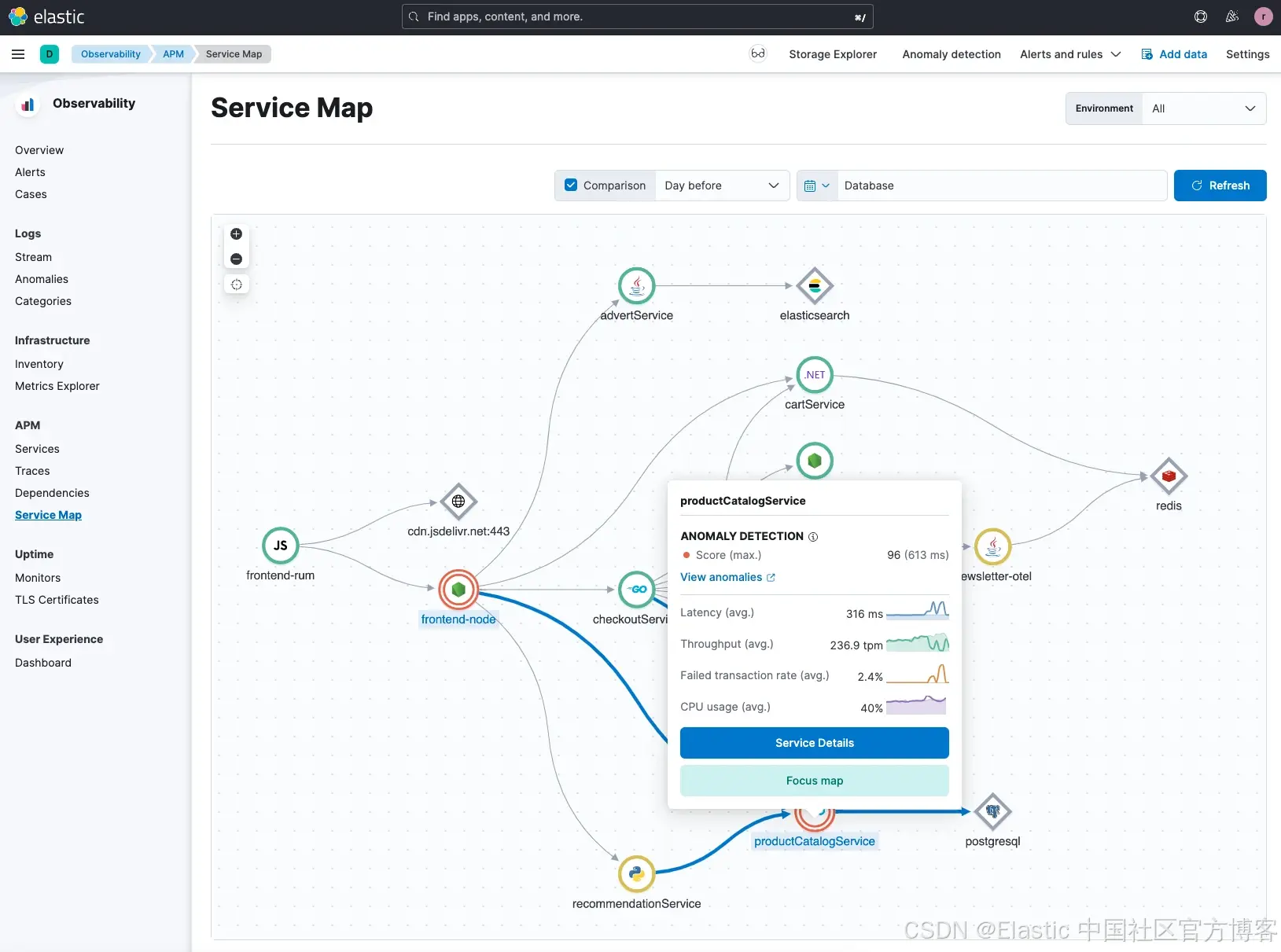
在這個示例中,我們可以看到 Hipster Shop 應用中的 productCatalogService 服務 出現了一個異常,異常評分為 96。異常評分表示該異常相較于歷史上檢測到的異常的重要程度,分數越高,異常越顯著。關于異常檢測結果的更多信息可以參考這里。
我們還可以進一步深入查看這個異常,分析其具體細節。
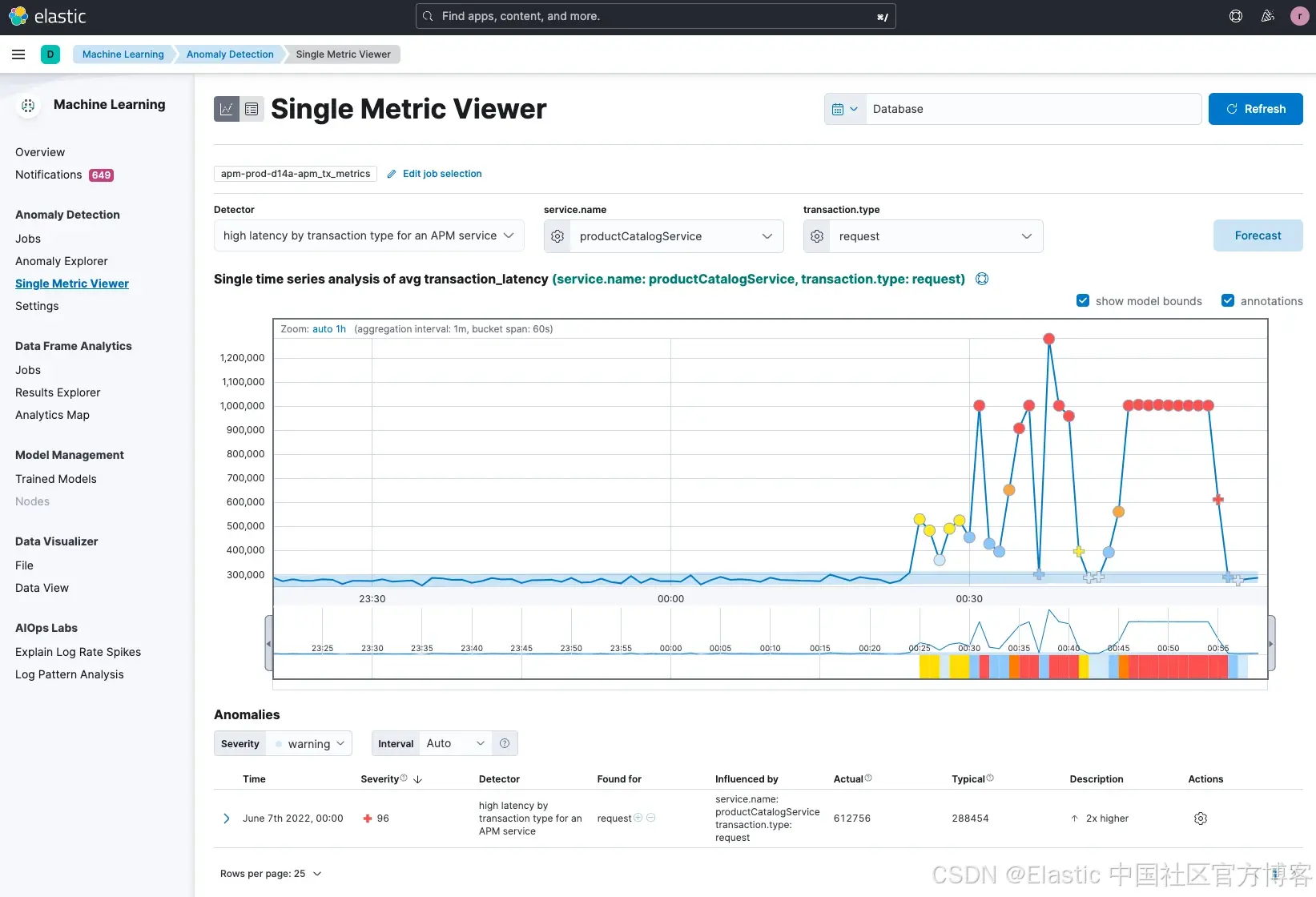
你會看到,productCatalogService 出現了 平均事務延遲時間的嚴重飆升,這正是服務拓撲圖中檢測到的異常。Elastic 的機器學習識別出了這個具體的 指標異常(可在 單指標視圖 中看到)。很可能客戶已經感受到網站變慢,導致公司正在流失潛在交易。
接下來的一個步驟是,從更宏觀的角度審查服務拓撲圖中其他潛在的異常。你可以使用 Anomaly Explorer(異常瀏覽器) 來查看所有已被識別出的異常。
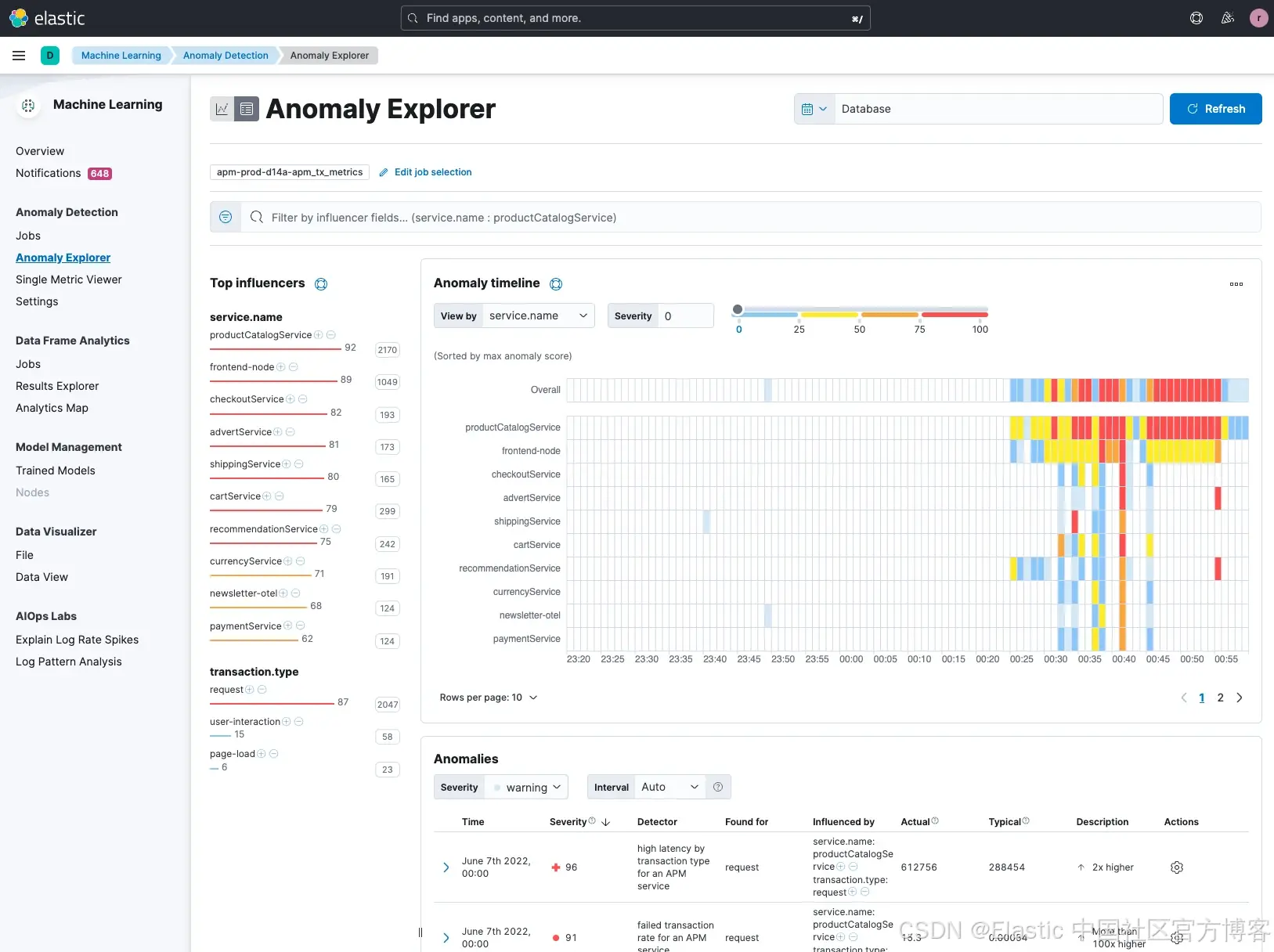
Elastic 檢測到多個服務存在異常,其中 productCatalogService 的異常評分最高,此外還有 frontend、checkoutService、advertService 等多個服務也具有較高評分。不過,目前的分析僅基于 單一指標。
Elastic 的機器學習不僅可以檢測單一指標,還可以對 各種類型的數據(如 Kubernetes 數據、指標、追蹤信息等)進行異常檢測。如果我們在 Elastic 中為這些不同數據類型分別創建了 獨立的機器學習任務(job),就能對整個系統的運行狀態進行更全面的分析,從而更準確地識別導致延遲問題的根本原因。
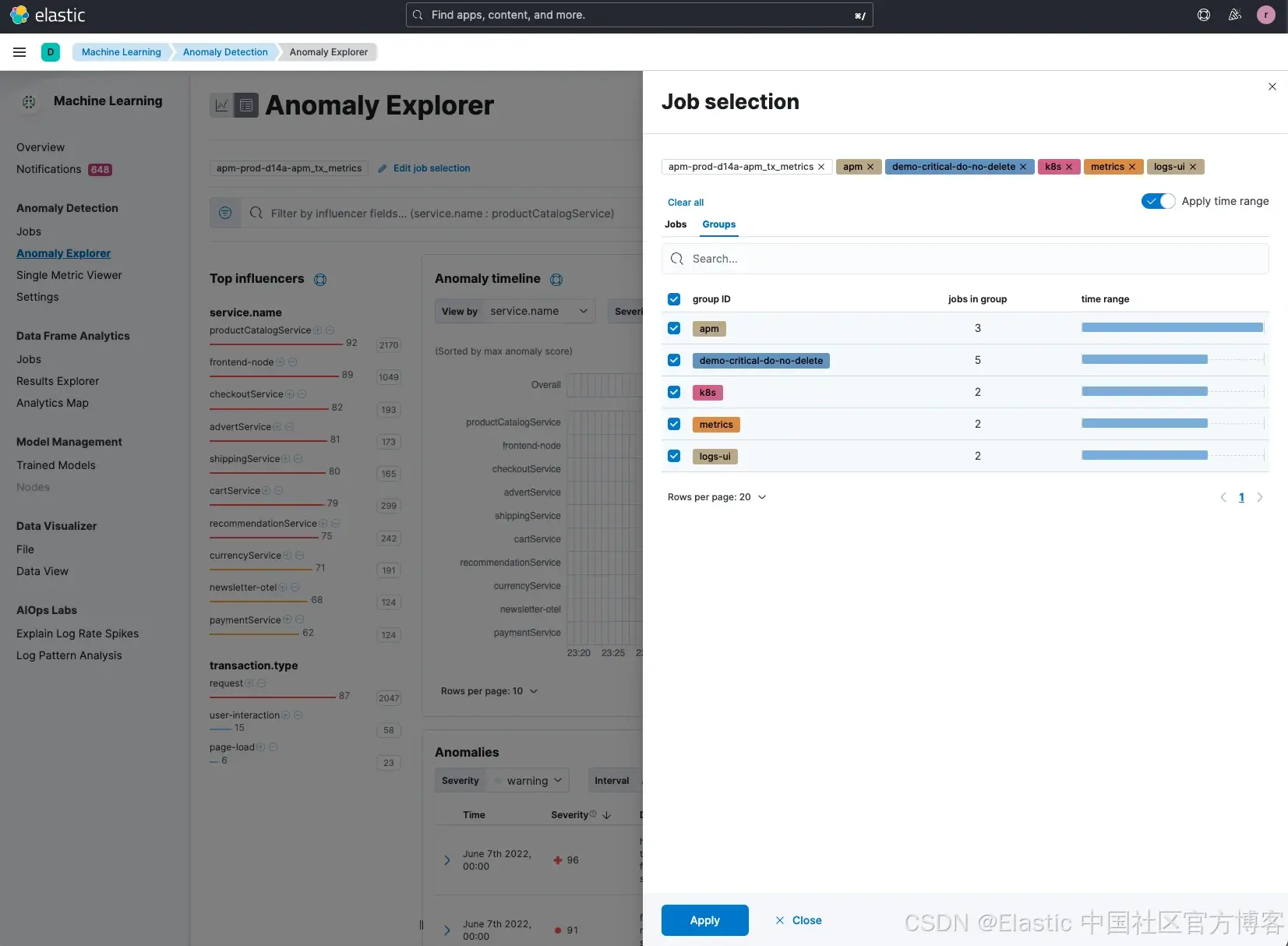
一旦選中了所有潛在的任務,并按 service.name 排序,我們可以看到 productCatalogService 仍然顯示出較高的異常影響因子評分。
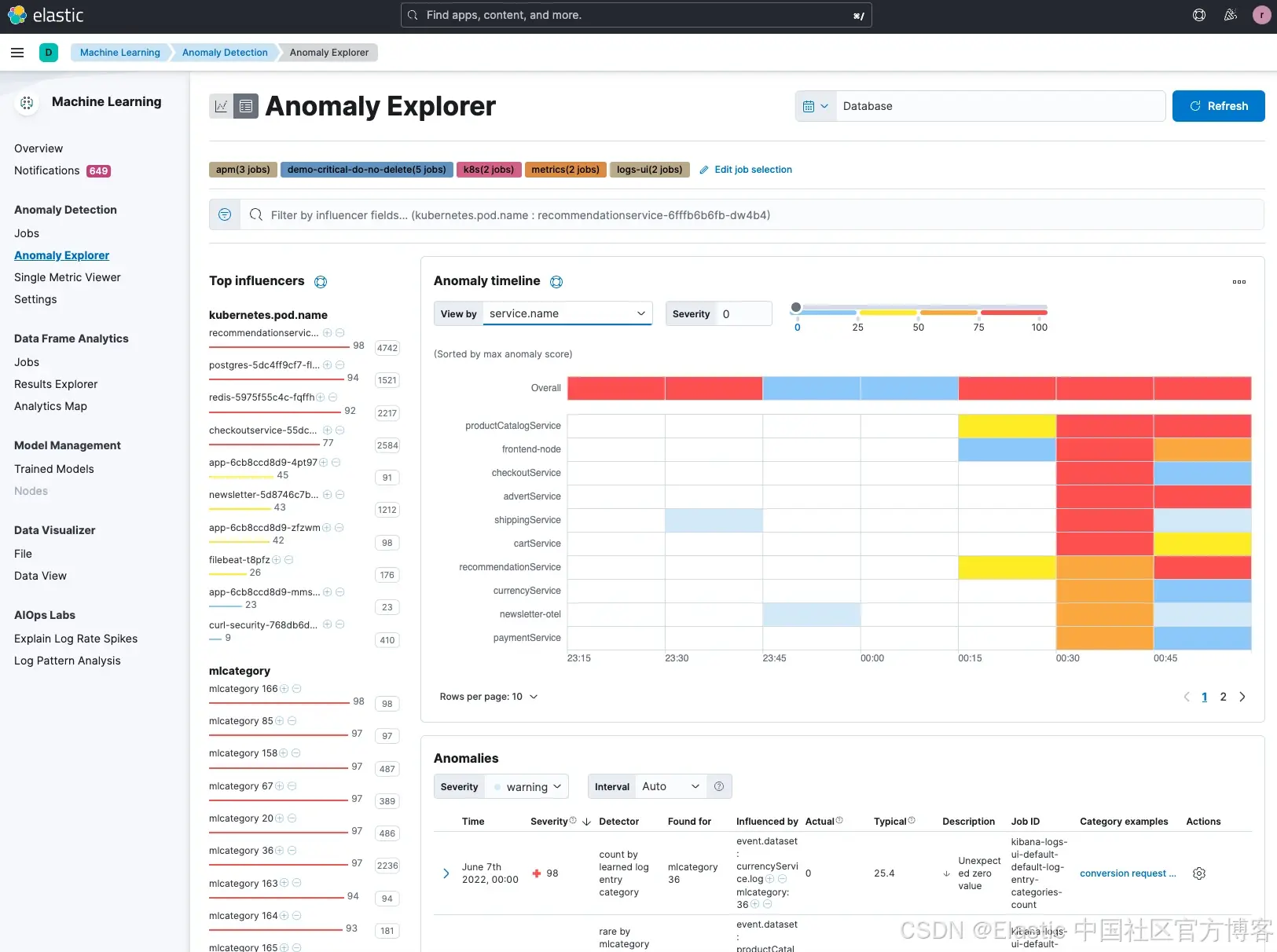
除了圖表為我們提供了異常的可視化信息外,我們還可以查看所有潛在的異常。你會注意到,Elastic 還對這些異常進行了分類(參見 category examples 列)。當我們瀏覽結果時,會注意到其中一個由分類識別出的潛在問題是 postgreSQL,其評分也高達 94。機器學習識別出了一個 “rare mlcategory”,這表示它是極少出現的類型,因此可能是客戶所遇問題的潛在原因。
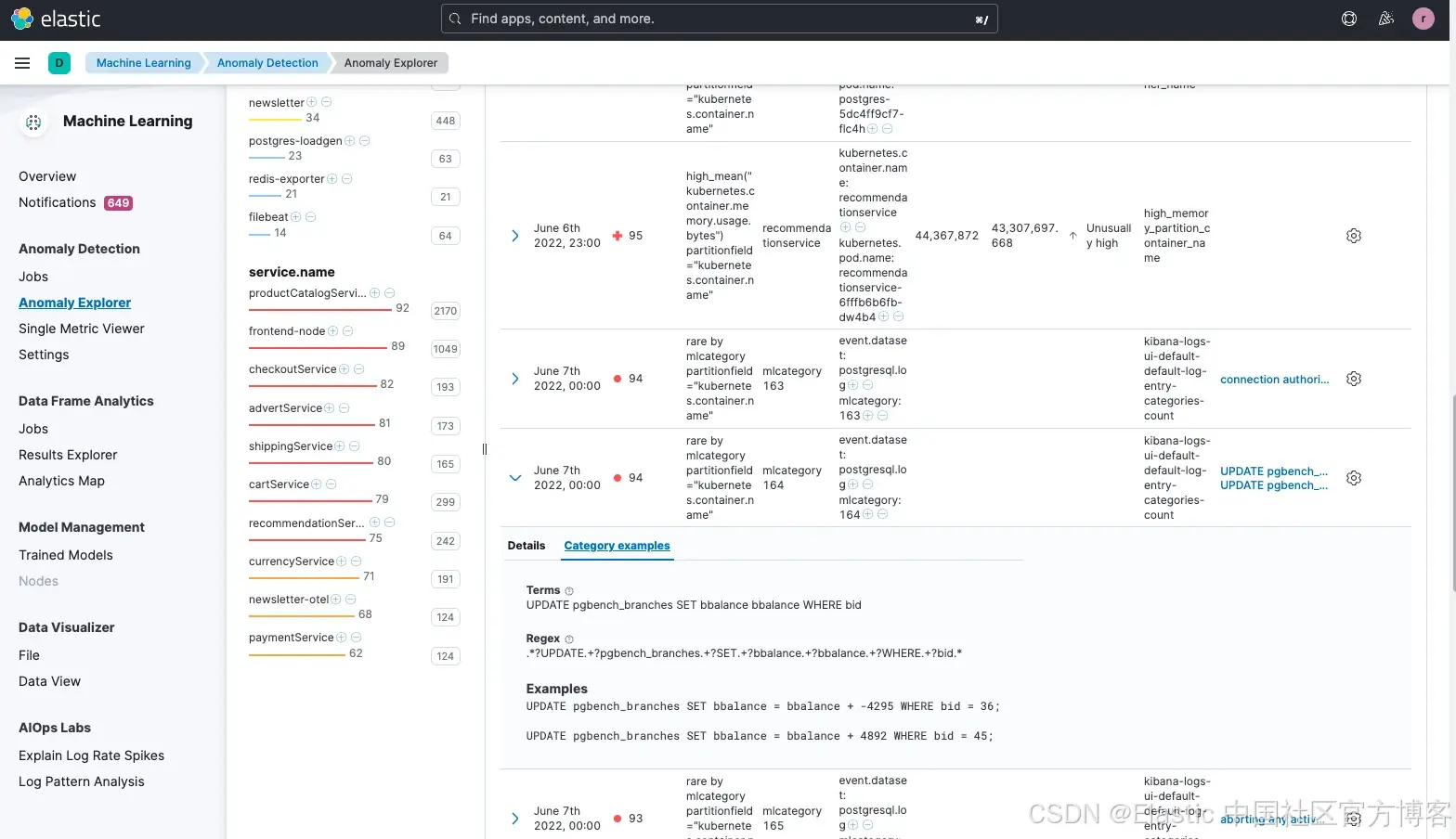
我們還注意到,這個問題可能是由 pgbench 引起的,pgbench 是一個流行的 postgreSQL 工具,用于對數據庫進行基準測試。pgbench 會反復執行相同的 SQL 命令序列,可能會在多個并發的數據庫會話中運行。雖然 pgbench 確實是個有用的工具,但它不應在生產環境中使用,因為它會對數據庫主機造成較大負載,很可能導致網站出現更高的延遲問題。
雖然這可能不是最終的根因,但我們已經較快地識別出了一個高概率的潛在問題。工程師可能本打算在測試環境的數據庫上運行 pgbench 來評估性能,而不是在生產環境中運行。
日志分類的機器學習
Elastic Observability 的服務拓撲圖檢測到了異常,在本次演示中,我們換一種方法,從服務拓撲圖中查看服務詳情,而不是一開始就直接探索異常。當我們查看 productCatalogService 的服務詳情時,看到以下內容:
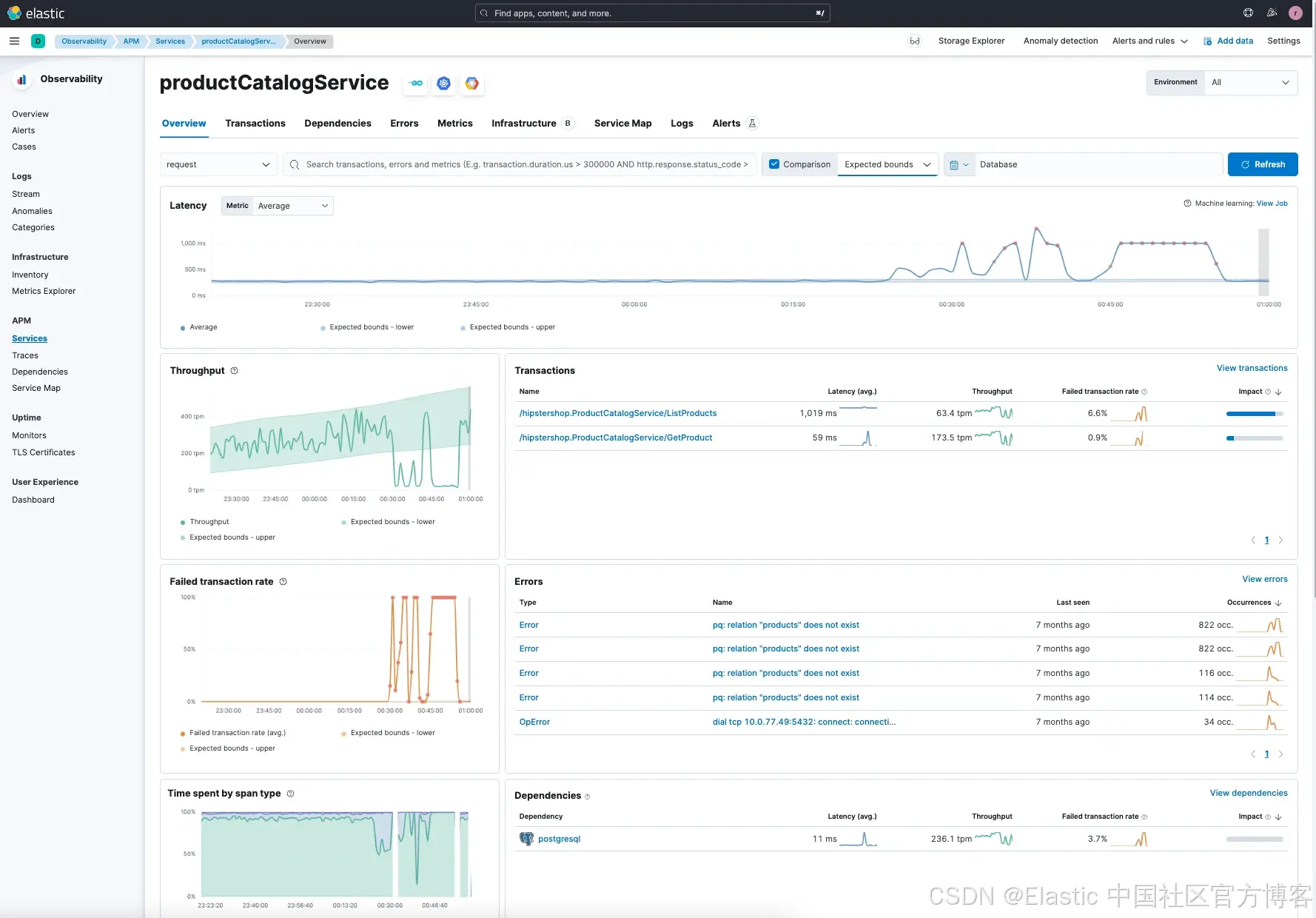
服務詳情顯示了幾個方面:
-
與服務預期范圍相比,延遲異常高。我們看到最近延遲明顯高于平均值,平均約為 275ms,但有時會超過 1 秒。
-
在高延遲的同一時間段內,失敗率也很高(左下角圖表 “Failed transaction rate”)。
-
事務中,特別是
/ListProduct請求延遲異常高,且失敗率也高。 -
productCatalogService依賴于 postgreSQL。 -
錯誤全部與 postgreSQL 相關。
-
我們可以選擇在 Elastic 中深入日志分析,或者使用一種更便捷的功能快速定位日志。
如果我們在 Elastic Observability 的日志分類(Categories)中搜索 postgresql.log 來幫助識別可能導致錯誤的 postgresql 日志,會發現 Elastic 的機器學習已自動對 postgresql 日志進行了分類。
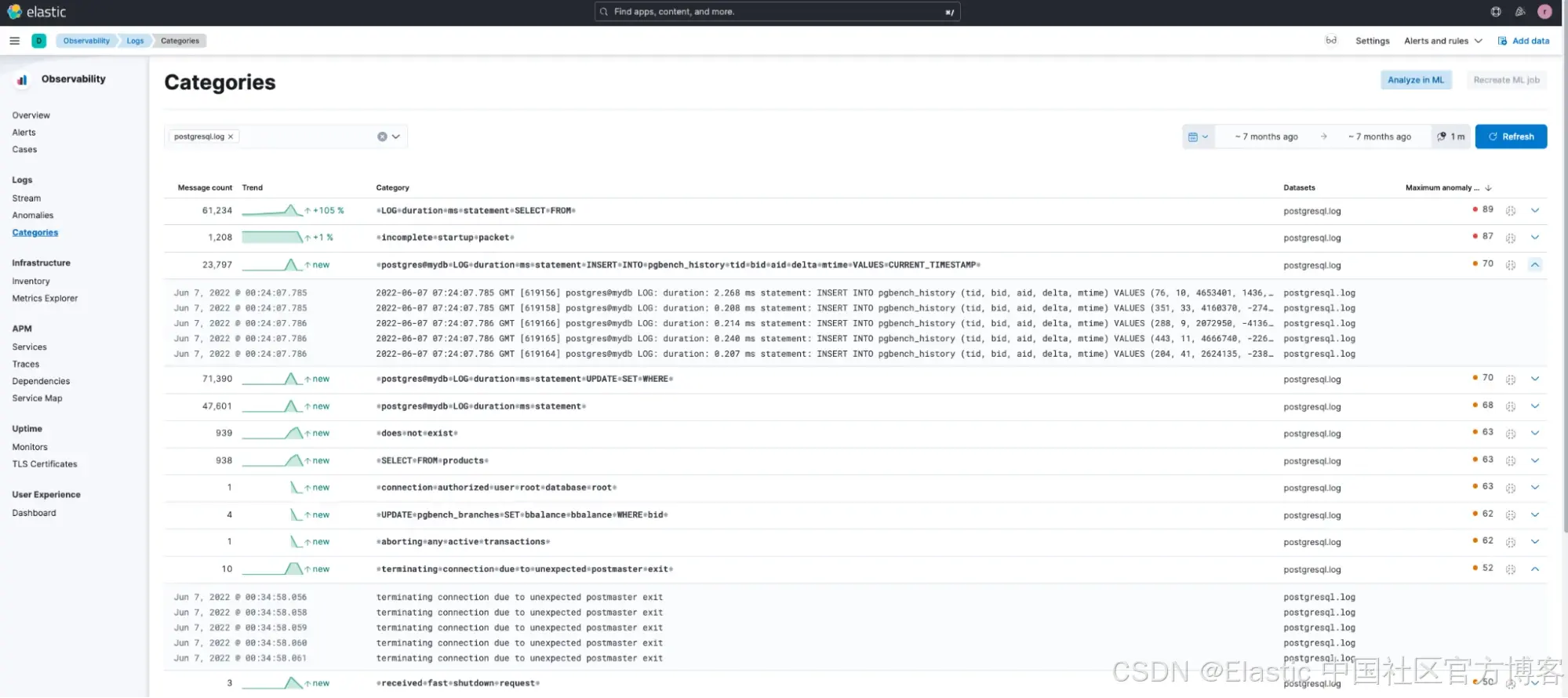
我們注意到另外兩點:
-
有一個高頻分類(消息數為 23,797,異常評分高達 70)與 pgbench 相關(這在生產環境中很少見)。因此,我們在分類中進一步搜索所有與 pgbench 相關的日志。
-
發現一個關于連接終止的異常問題(消息數較少)。
-
在調查第二個嚴重錯誤時,我們可以在分類中看到該錯誤發生前后的日志。
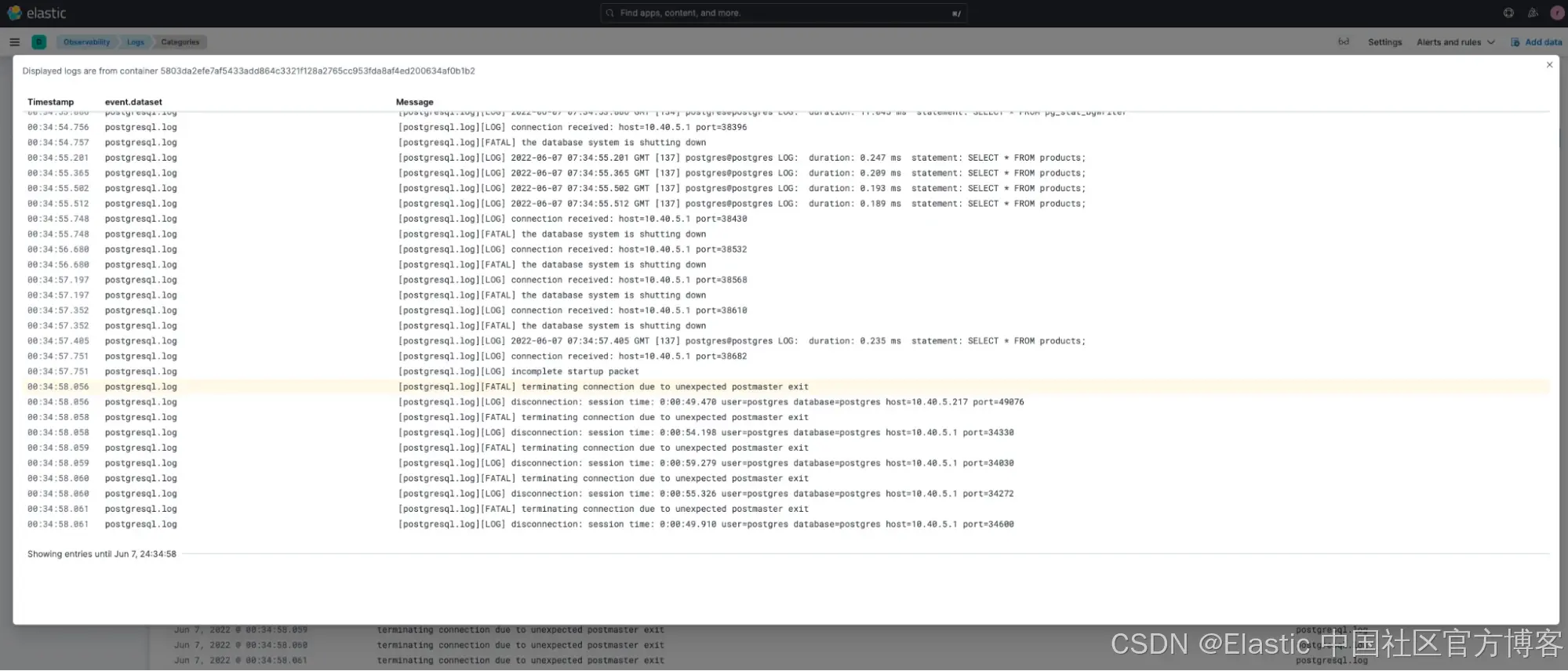
這個故障排查顯示 postgreSQL 出現了致命錯誤(FATAL error),數據庫在錯誤發生前已關閉,所有連接被終止。鑒于我們發現的這兩個直接問題,可以判斷有人運行了 pgbench,可能導致數據庫過載,進而引發客戶看到的延遲問題。
接下來的步驟可以是調查異常檢測結果,或者與開發人員合作,檢查代碼,確認 pgbench 是否被包含在部署配置中。
結論
希望你已經了解 Elastic Observability 如何幫助你更快地識別并接近問題的根本原因,而無需費力地尋找“干草堆中的針”。下面是本篇博客的快速總結和你所學內容:
-
Elastic Observability 提供了多種能力,幫助你減少定位根因的時間,提升平均修復時間(MTTR)甚至平均檢測時間(MTTD)。
-
本文重點介紹了以下兩項主要能力:
-
異常檢測:開啟后(參見文檔),Elastic Observability 會持續建模你的時間序列數據的正常行為 —— 學習趨勢、周期性等 —— 實時識別異常,簡化根因分析,減少誤報。異常檢測在 Elasticsearch 中運行并可擴展,且配備直觀的用戶界面。
-
日志分類:結合異常檢測,Elastic 快速識別日志事件中的模式。日志分類視圖會根據日志消息和格式自動分組,無需手動識別相似日志,方便你更快采取行動。
-
-
你已經了解如何輕松使用 Elastic Observability 的日志分類和異常檢測功能,無需理解底層機器學習原理,也無需復雜設置。
準備好開始了嗎?注冊 Elastic Cloud,試用上述介紹的功能和能力吧。
原文:Root cause analysis with logs: Elastic Observability's anomaly detection and log categorization — Elastic Observability Labs




】)

)









)


