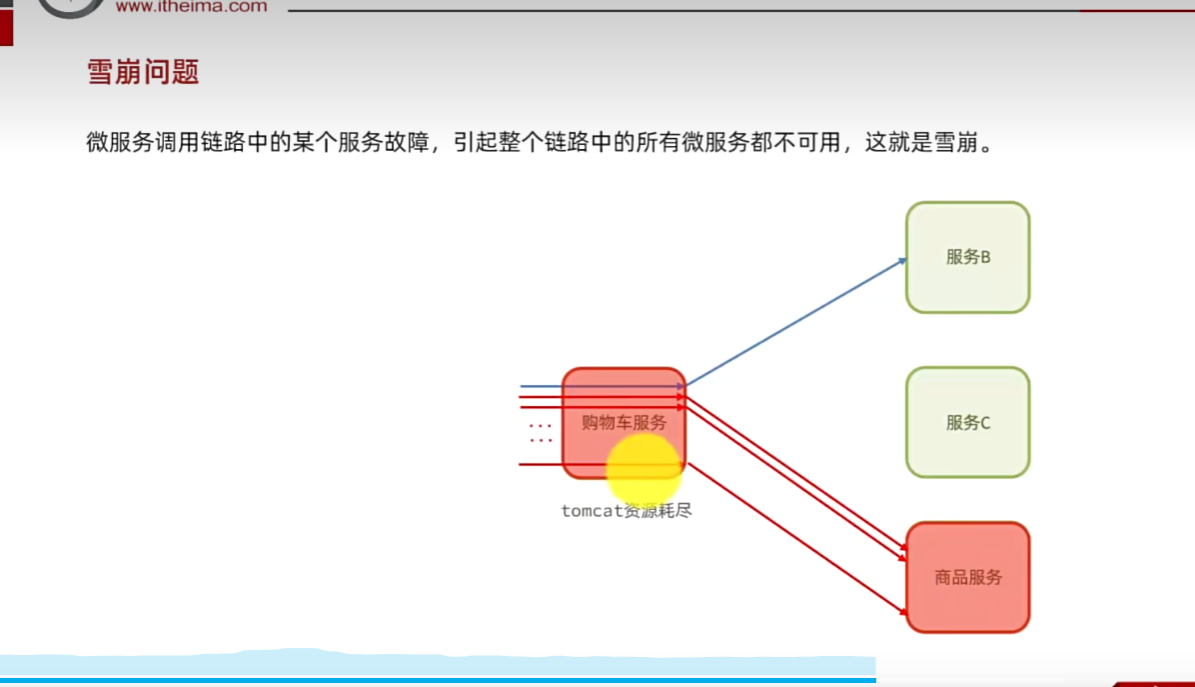
雪崩問題:
小問題引發大問題,小服務出現故障,處理不當,可能導致整個微服務宕機。
假如商品服務出故障,購物車調用該服務,則可能出現處理時間過長,如果一秒幾十個請求,那么處理時間過長,那么卡的人越來越多,那么就會導致資源耗盡。原本服務B可以使用,此時此刻也宕機了,然后其他服務去調用服務B那么也會出現該情況,然后出現連鎖反應。因為資源耗盡導致宕機等可能
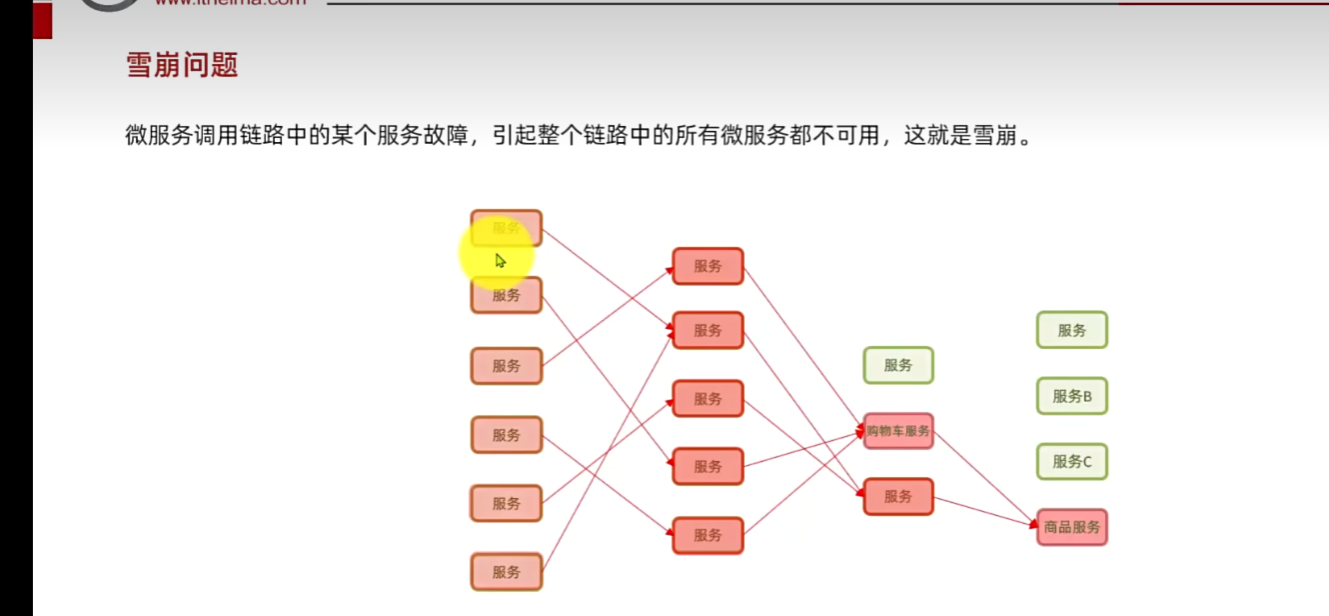
最后導致:出現級聯反應,小問題不解決,越滾越大,原本就一個小問題,某一微服務提供者出現故障,負責調用它的人等待時間多長,就是滾雪球,沒有進行異常處理。


解決方案:
一、不管請求多少,服務承受的都是固定的,從狂暴的到柔和的,限制到每秒中只有幾個,避免崩掉

但是也無法保證百分百沒有問題(避免卡死,等待導致雪崩)引入線程隔離。
我們去限定每個業務線程的數量,那么當有請求,就必須去線程池去取 然后去調用服務B,
業務二:那么即使四個線程去取的時候全故障了,那么也不會耗盡服務A的資源,關進黑屋里面,起到故障隔離,服務B影響不到
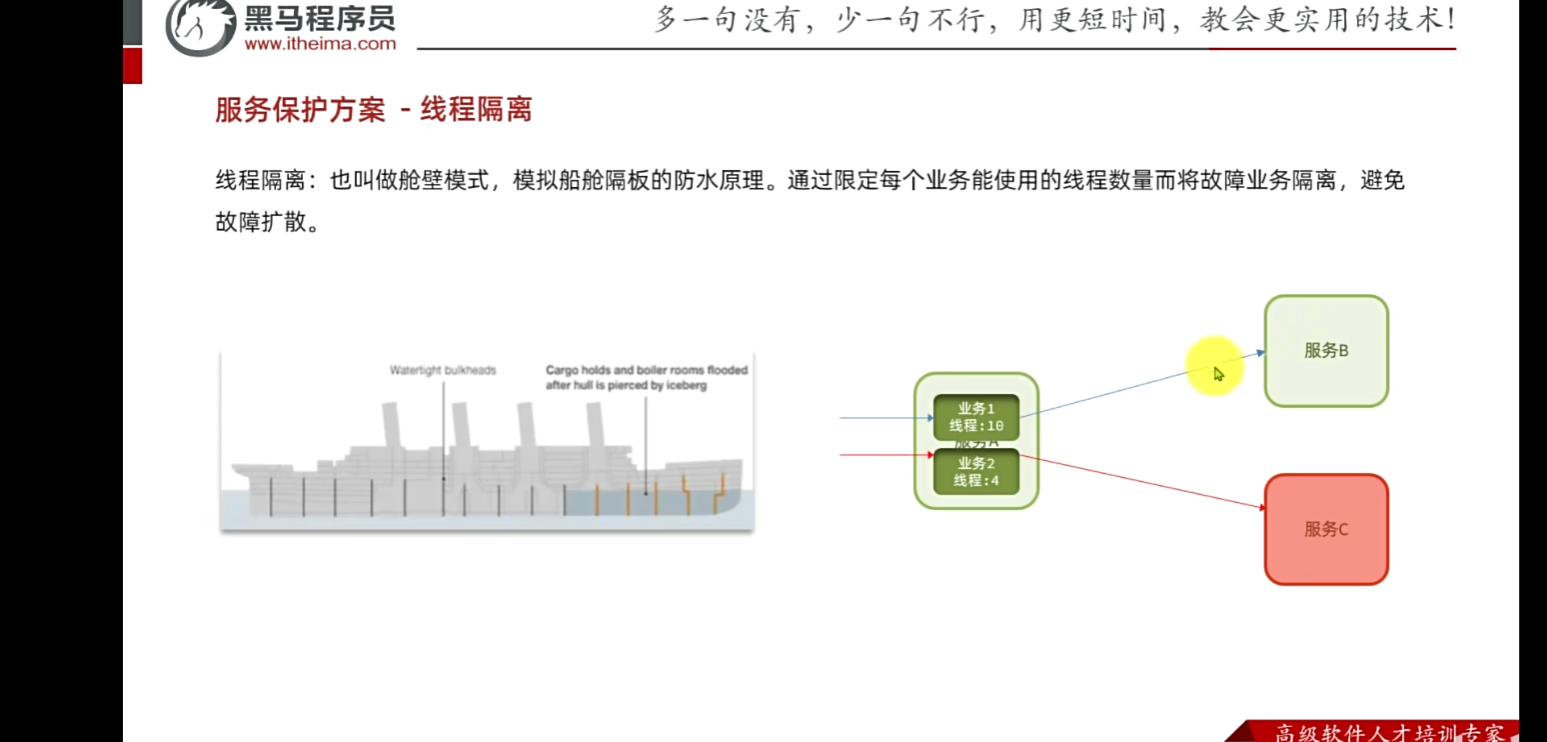
那么也不能百分百解決問題:假如一直來請求,那么雖然說已經隔離了四個,那么也一直不斷有新的請求資源,雖然不會導致服務A宕機,但是也會消耗CPU資源等。
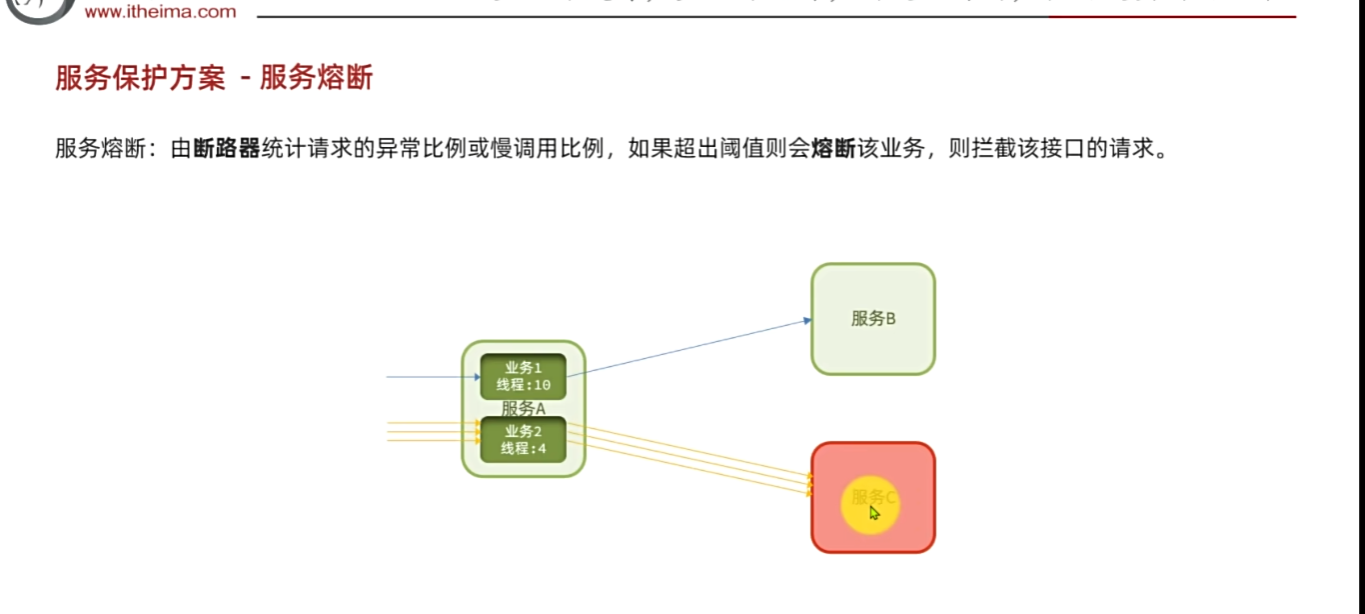
所以應該拒絕它訪問,這個叫服務壟斷,攔截請求,就像是電路的保險開關。“斷路器”,自動斷開,防止進一步請求
例如:假如訪問時間過長,那么發現請求的異常比例 比如五次四次掛的或者慢調用太高,那么直接熔斷該業務
fallback:提前寫好邏輯,后備處理方案,對于服務C的一個補充。
當有再次新的請求那么直接拒絕走fallback,少了等待卡死
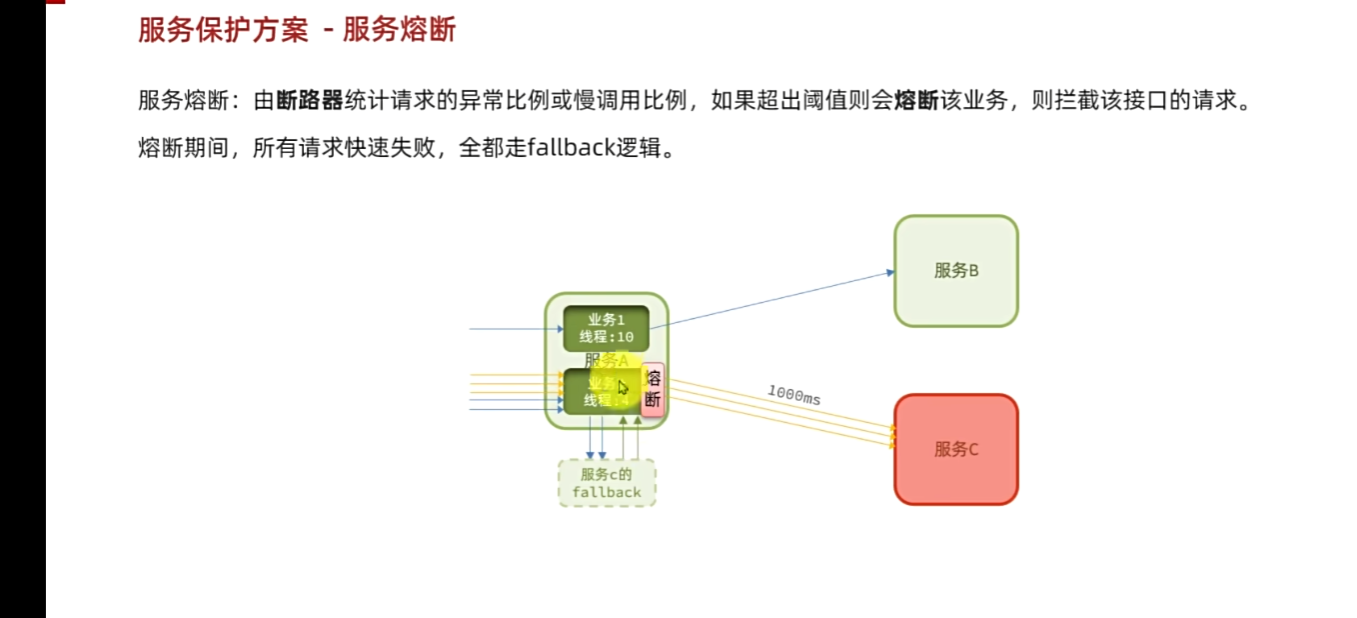
不僅上面故障隔離,避免了服務A被拖死。還在這個熔斷策略,避免無效資源浪費,提高了前端的響應速度
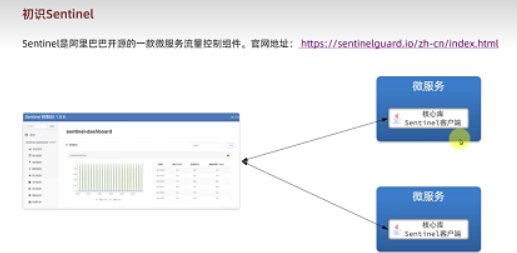
sentinel配置:導入相關依賴和配置,與控制臺相連接,方便管理
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
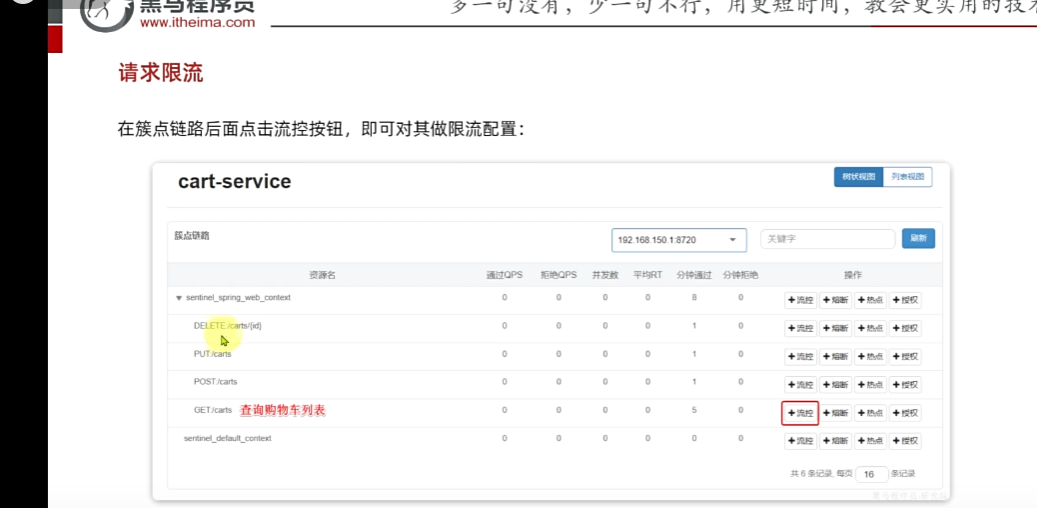
以上多調用幾次該微服務就可以顯示,例如調用購物車列表
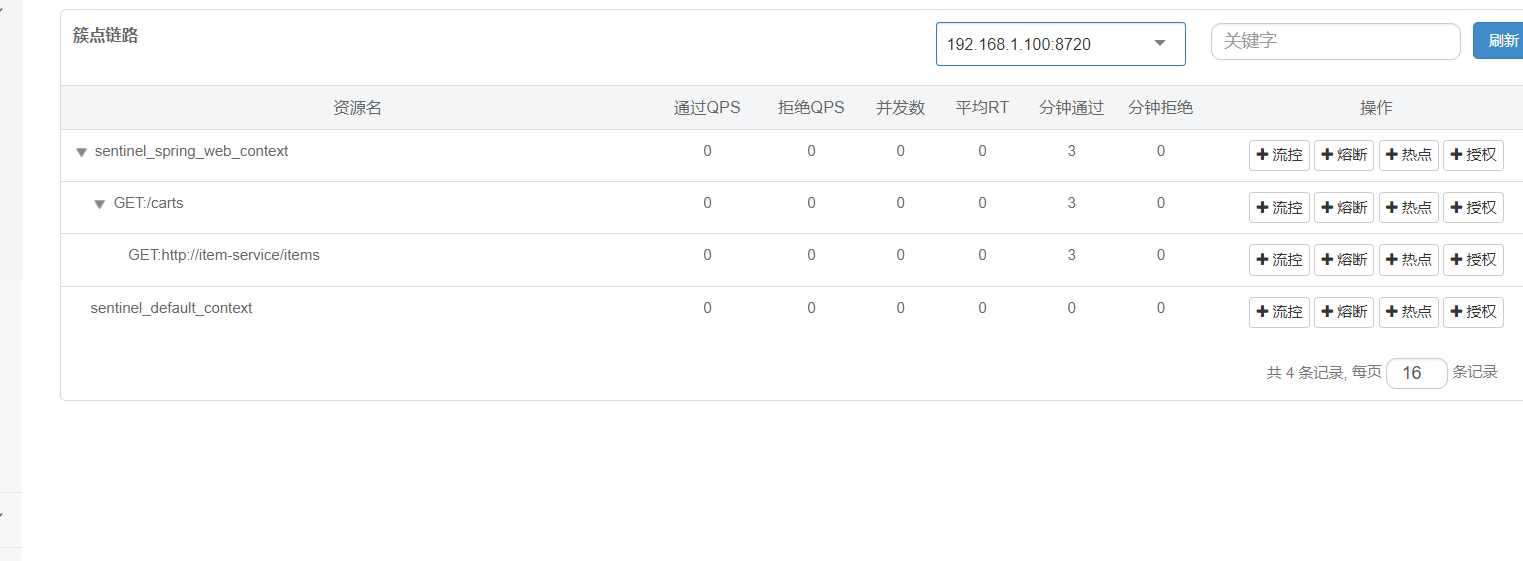
簇點鏈路:意思就是那些Controller接口(監控http接口)
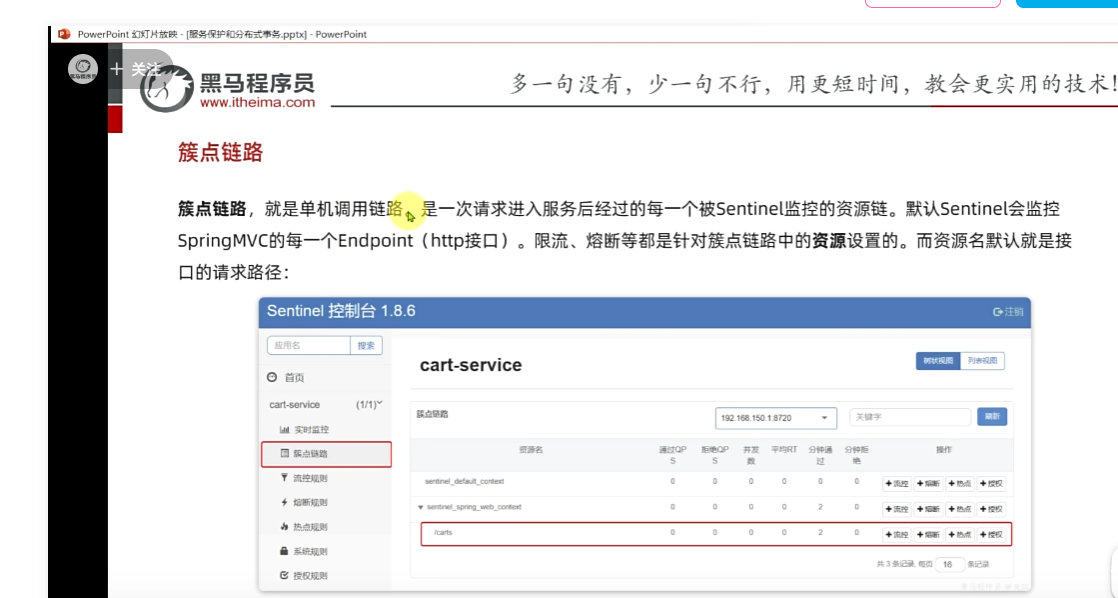
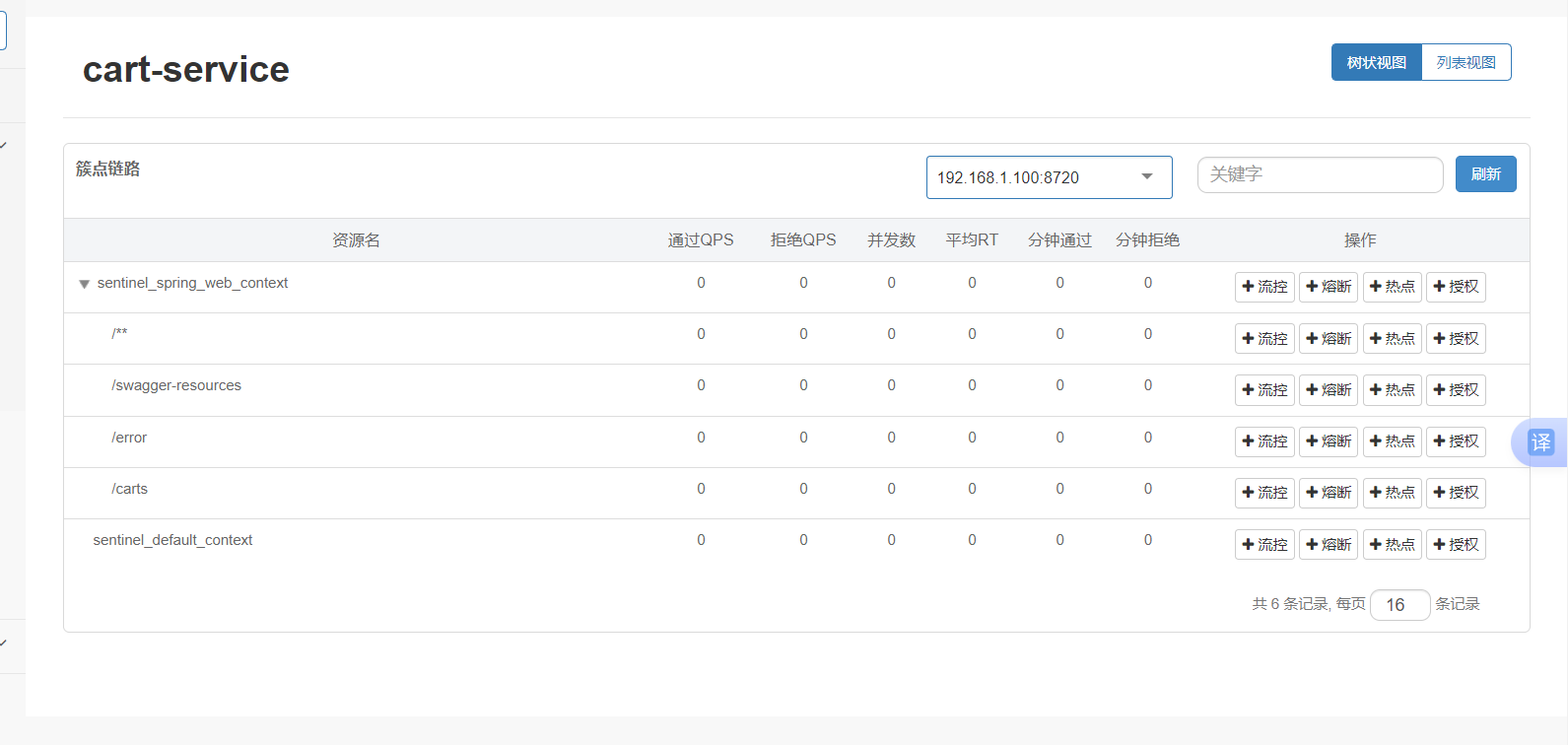
這里把carts作為簇點名稱,以這個為唯一標識,但是我們發現我們這個都是restful風格的,路徑都是相同,但是請求方式不同
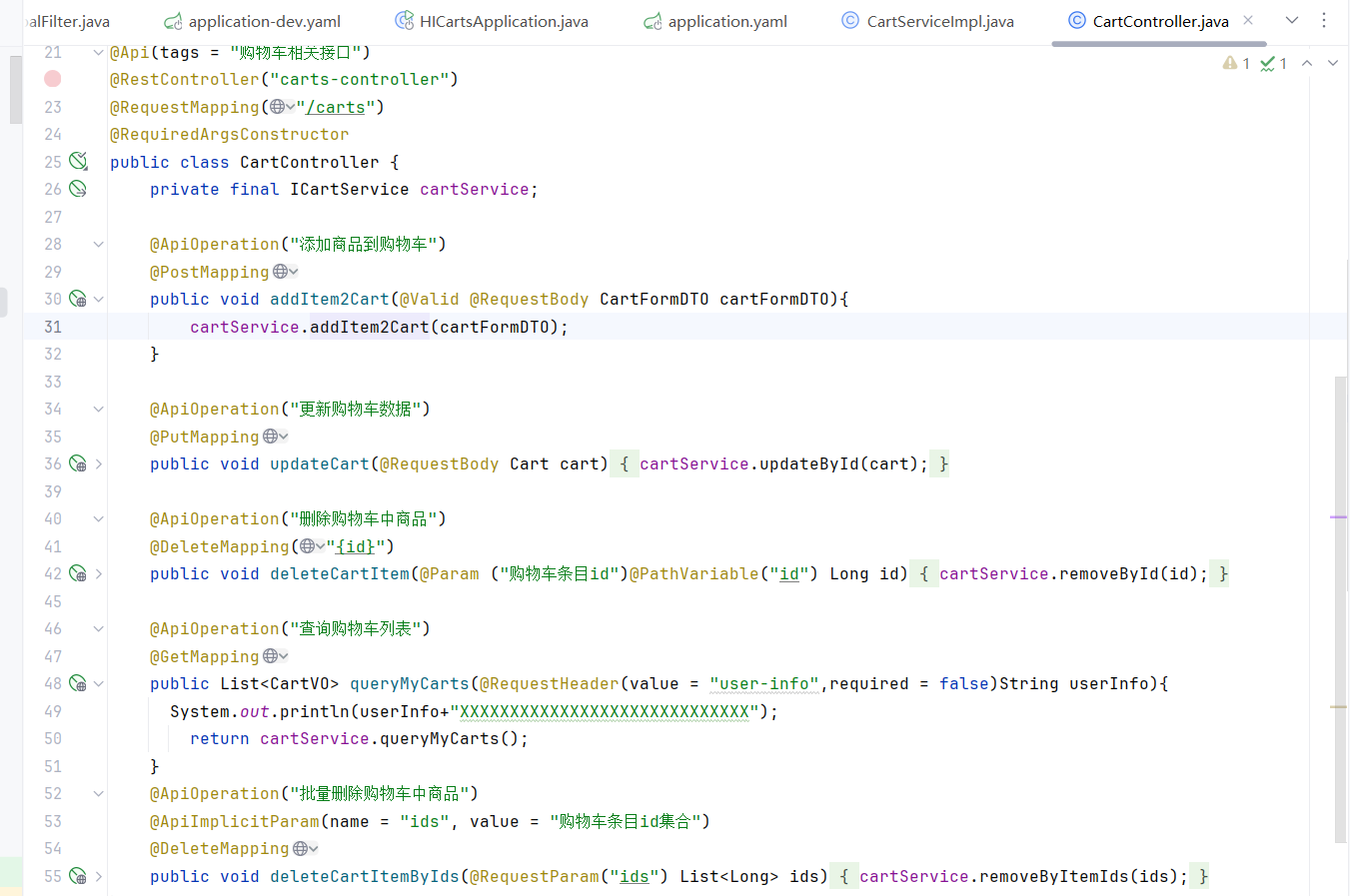
如何解決呢 加上這行
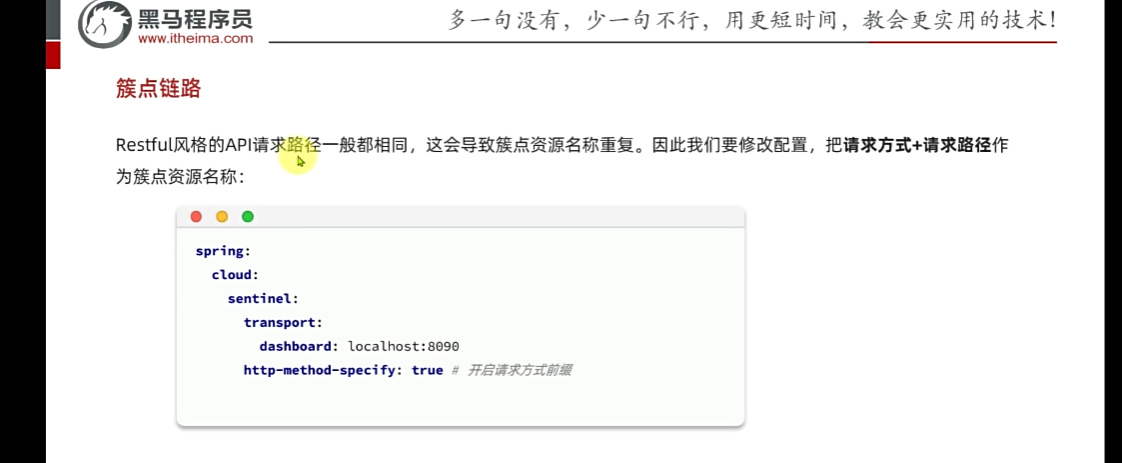
訪問該微服務的各個接口,每個接口都分別地去做監控
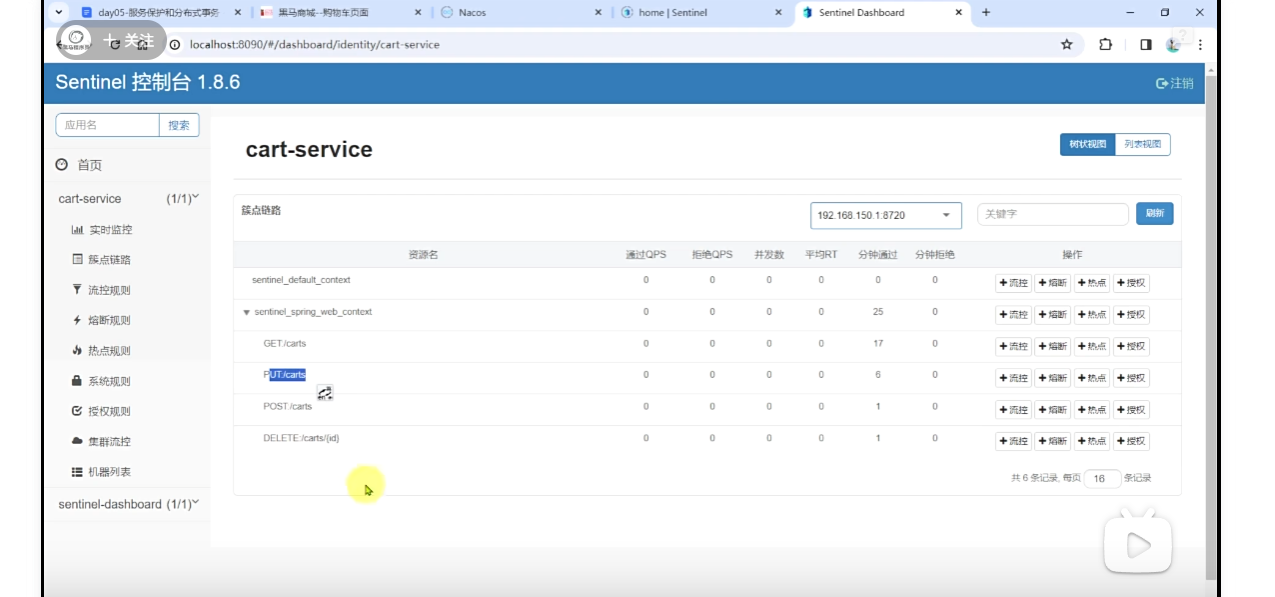
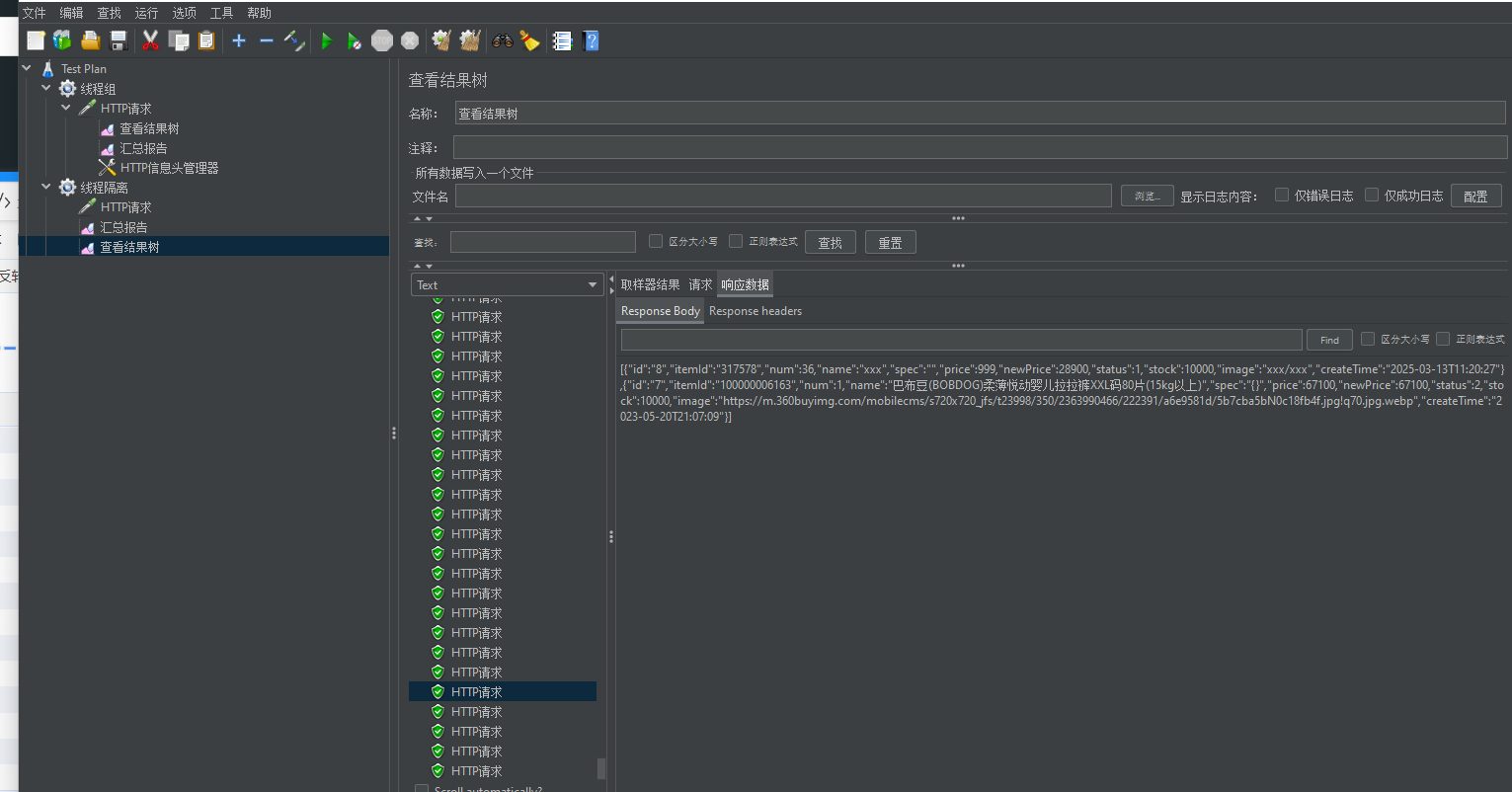
詳細分析:過程使用Jmeter
請求限流:
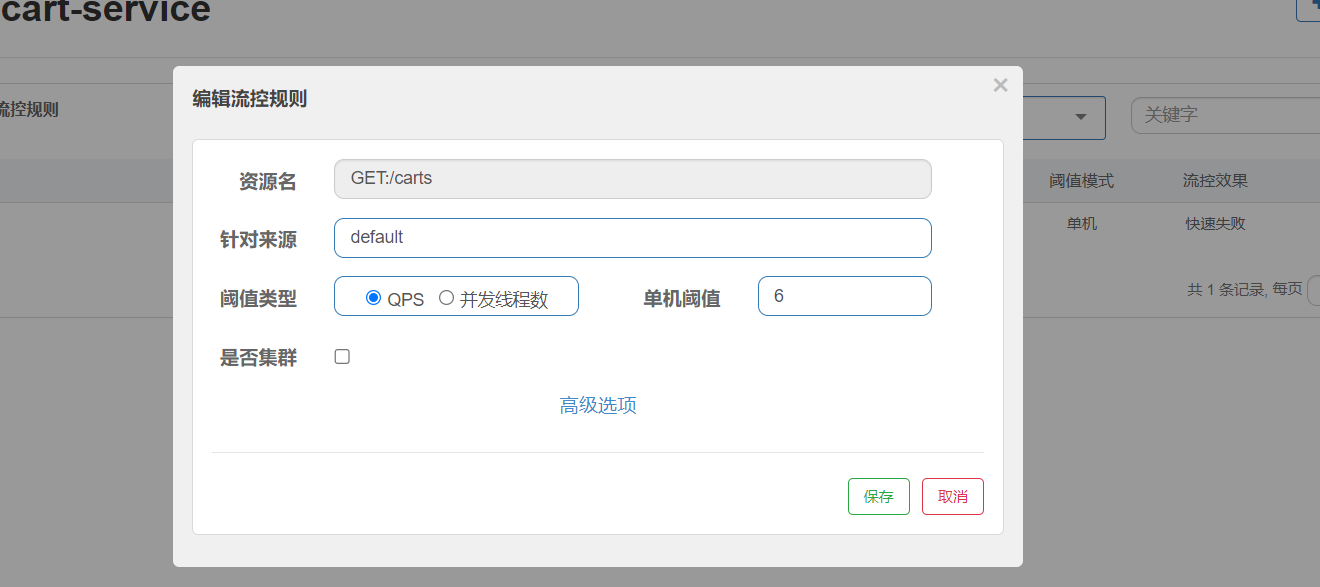
1.以購物車為例,QPS: 每秒鐘請求的數量,單機閾值:每秒鐘多少個
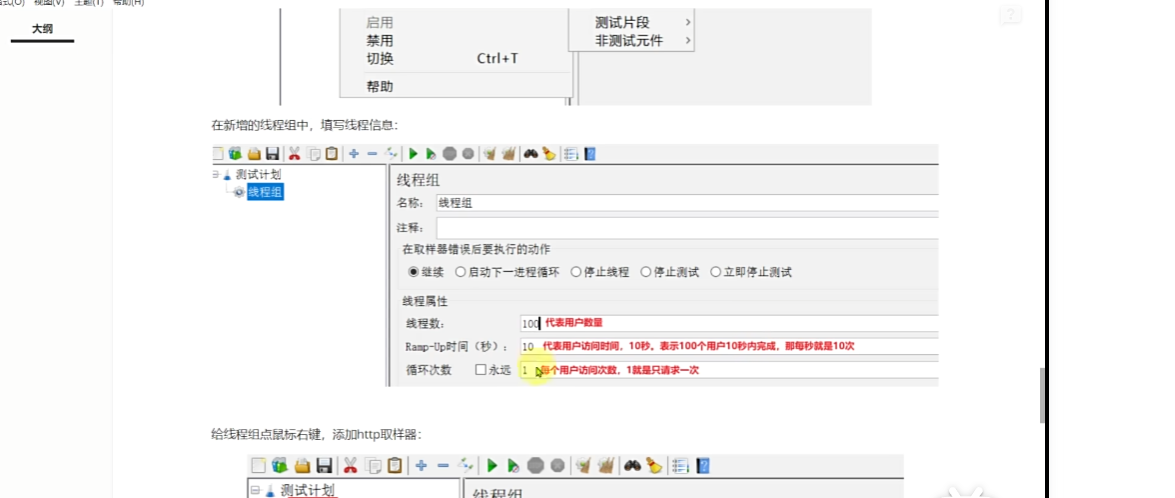
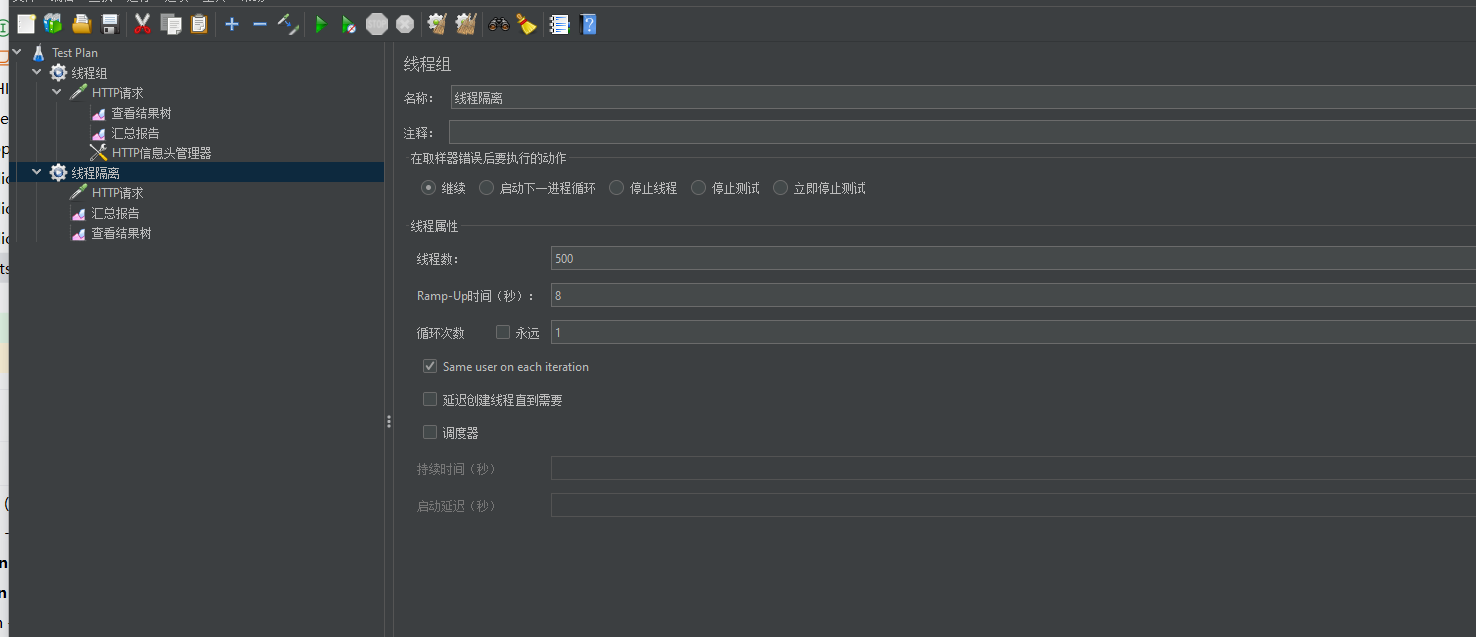
Jmeter:在TestPlan->線程(用戶)->然后線程組(模擬多個用戶)
用戶100個,發起請求總共耗時多久,多久把請求發完 100%10=10,就是每秒鐘10個
每個用戶發起一個請求
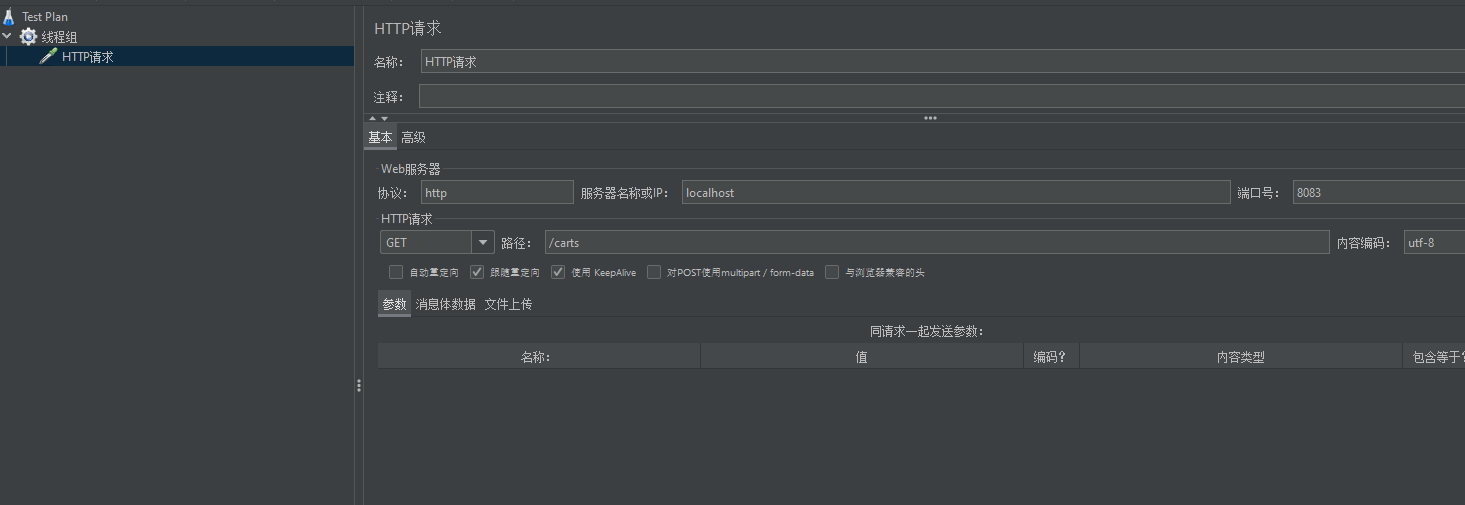
然后添加HTTP請求
那么啟動之后
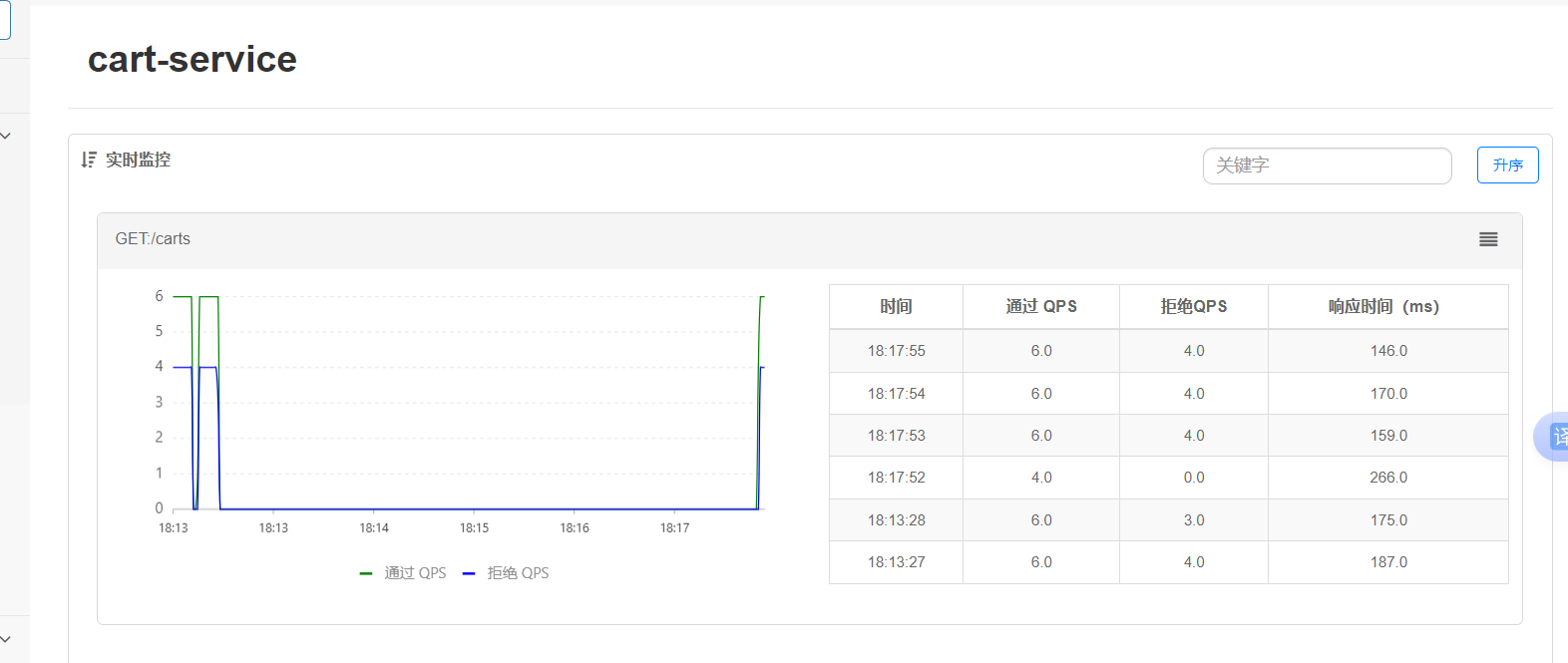
我們可以查看報告十個里面有4個就是說被拒絕了,并且異常為百分之40
報告如下:(如果訪問的是429的狀態碼),比如秒殺,有可能你被限流了
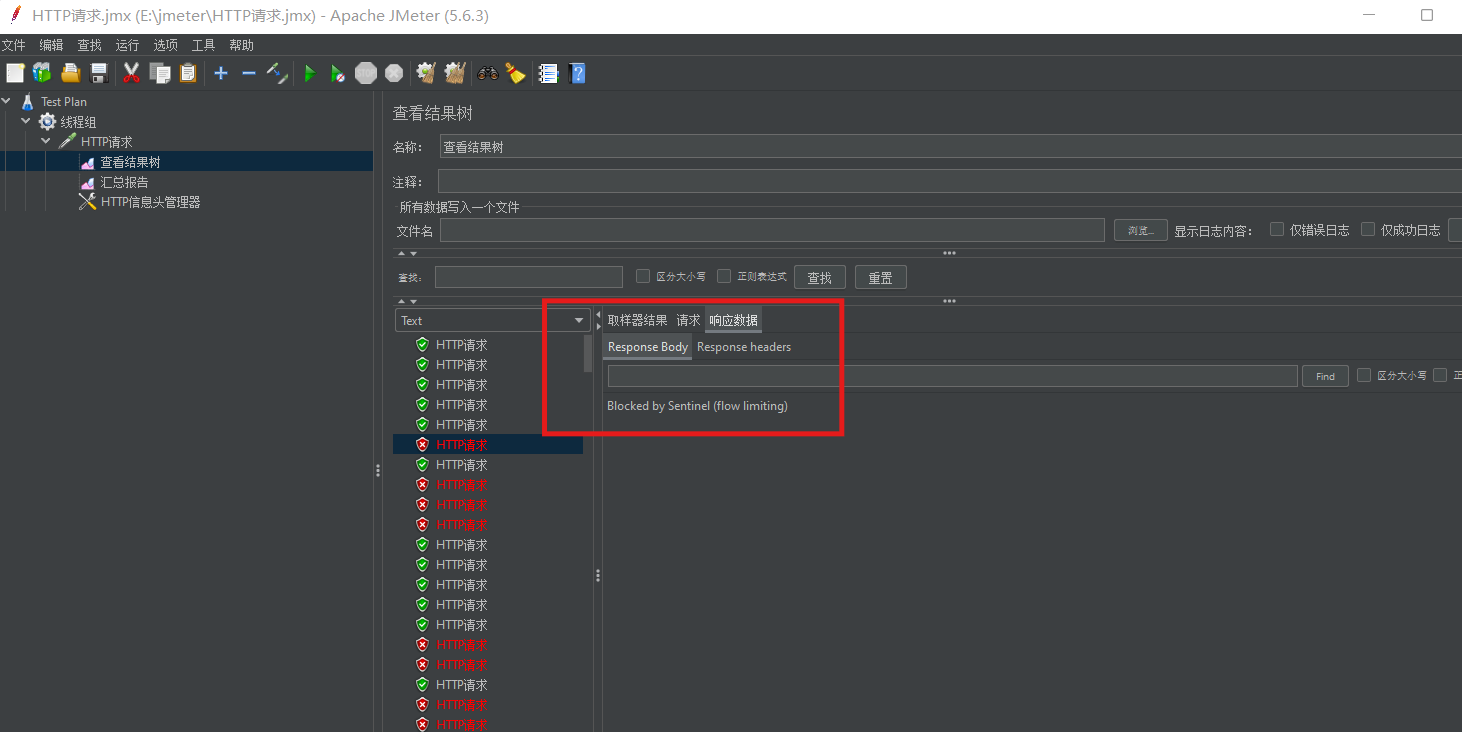
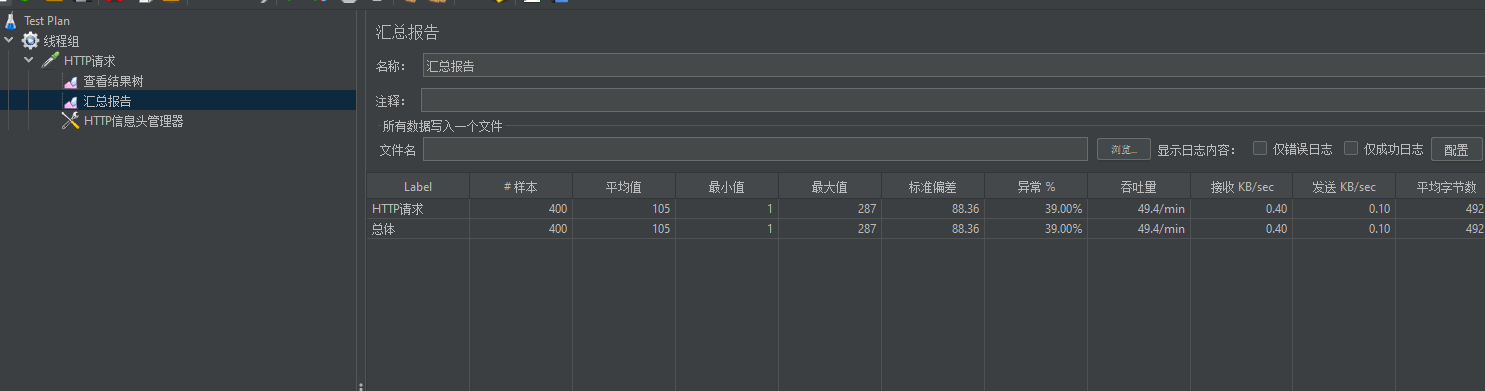
成功的案例:
線程隔離:
1.舉例:查詢購物車列表。模擬商品服務需要加載兩秒到三秒然后才能返回給服務A,
把服務A的各個業務各自分配相應的線程數
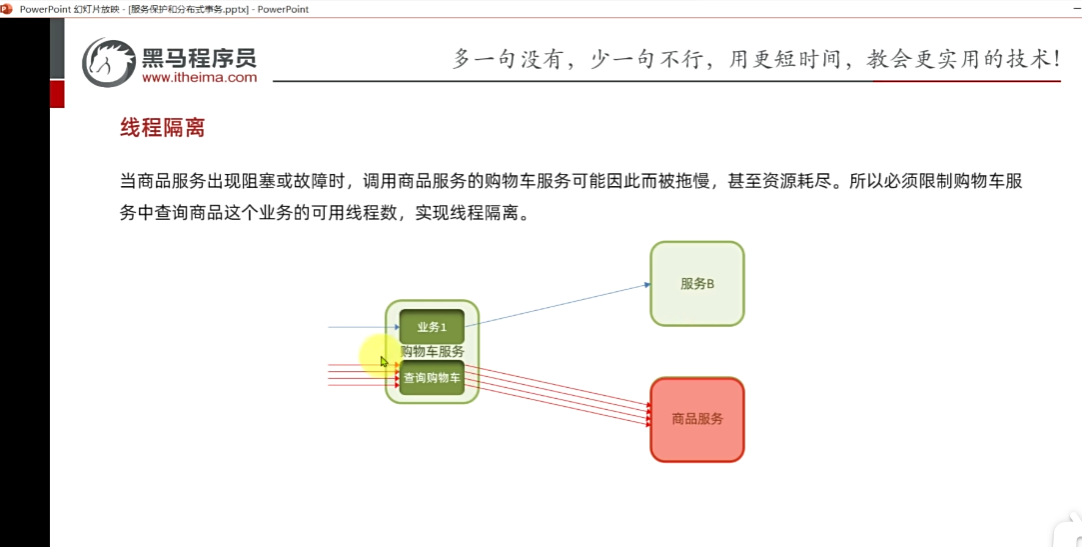
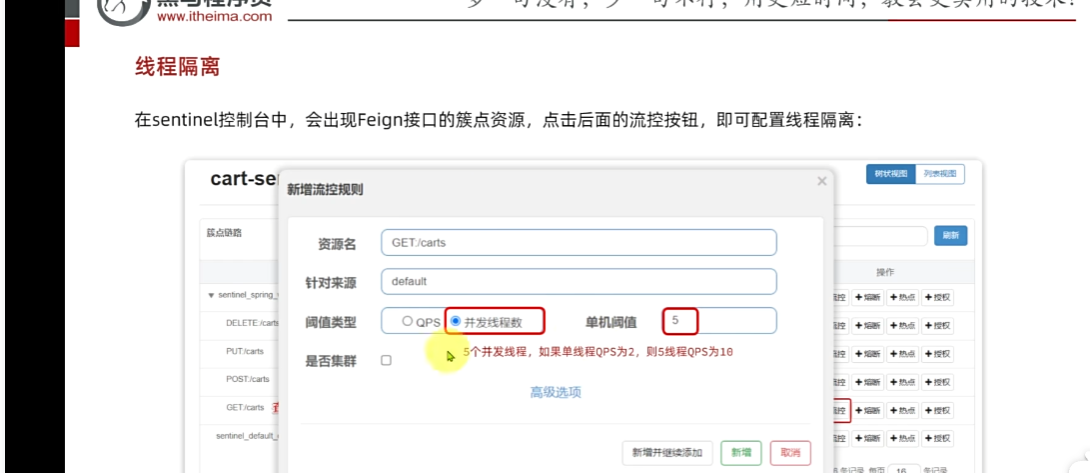
2.找到查詢購物車的業務,?這個也是線程隔離也是流控的一部分,因為你要去隔離。
并發線程數:線程可用資源數量。單機閾值,表示你可以用五個線程數;假設接口比較慢 返回一次需要500ms,那么一秒可以處理兩次請求,一個線程每秒鐘可以處理兩個,五個就是每秒鐘可以處理十個請求,也就是該接口允許每秒鐘處理十個請求
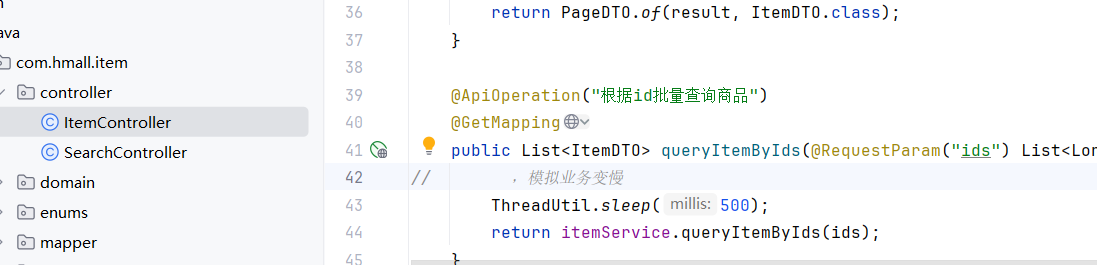
我們現在就是模擬說并發比較高,把資源耗盡導致,添加購物車商品受影響
原本添加只需要22ms,查詢:500ms
Jmeter模擬:
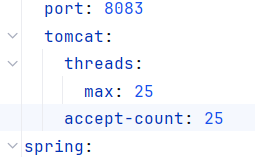
以上就是模擬了每秒鐘最大的連接數,我們在tomcat已經設置好50
tomcat:? max-connections: 50
剛剛只需要22ms,現在添加的接口資源被耗盡了。
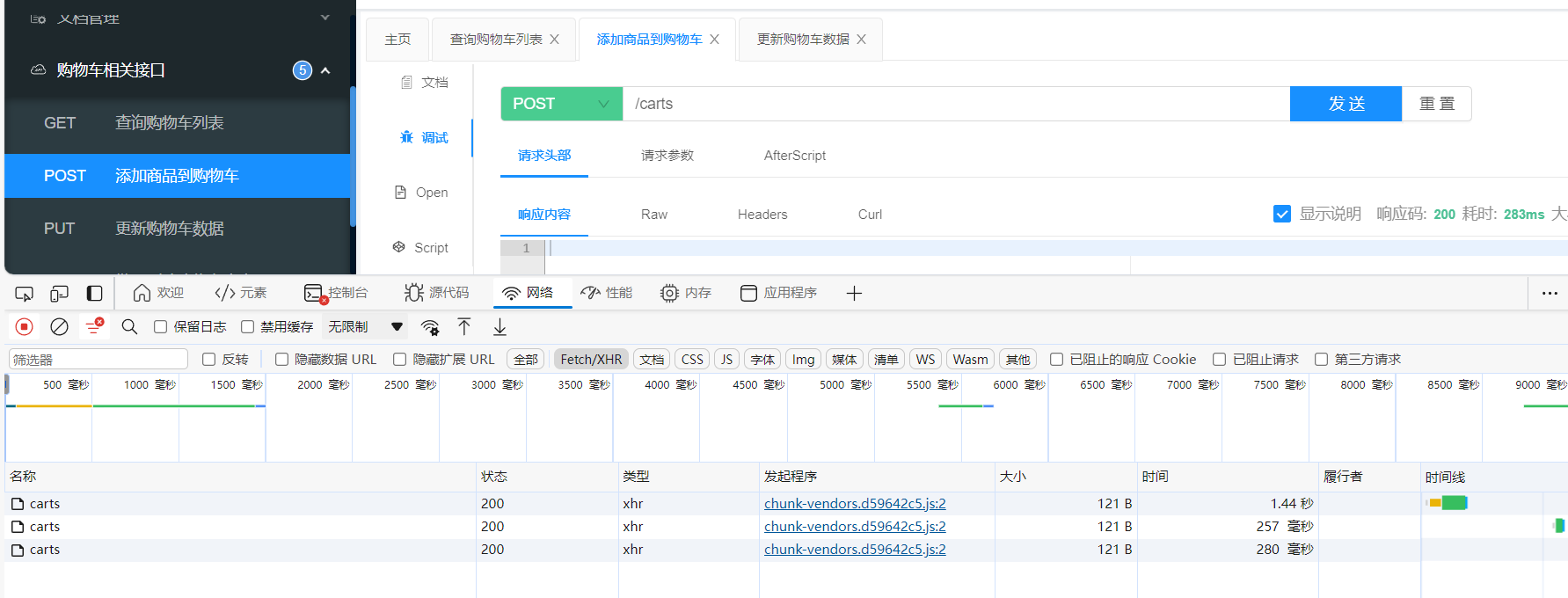
以及極大可能導致查詢失敗。很慢很慢,查詢連進都進不去,
商品服務變慢,導致了 購物車服務也被連累拖慢。如果并發進一步提高,那么可能掛了

如何解決?
我們設置好線程隔離
 、
、
畫紅色部分為添加購物車訪問時長,絲毫沒有受到影響,而查詢直接訪問失敗

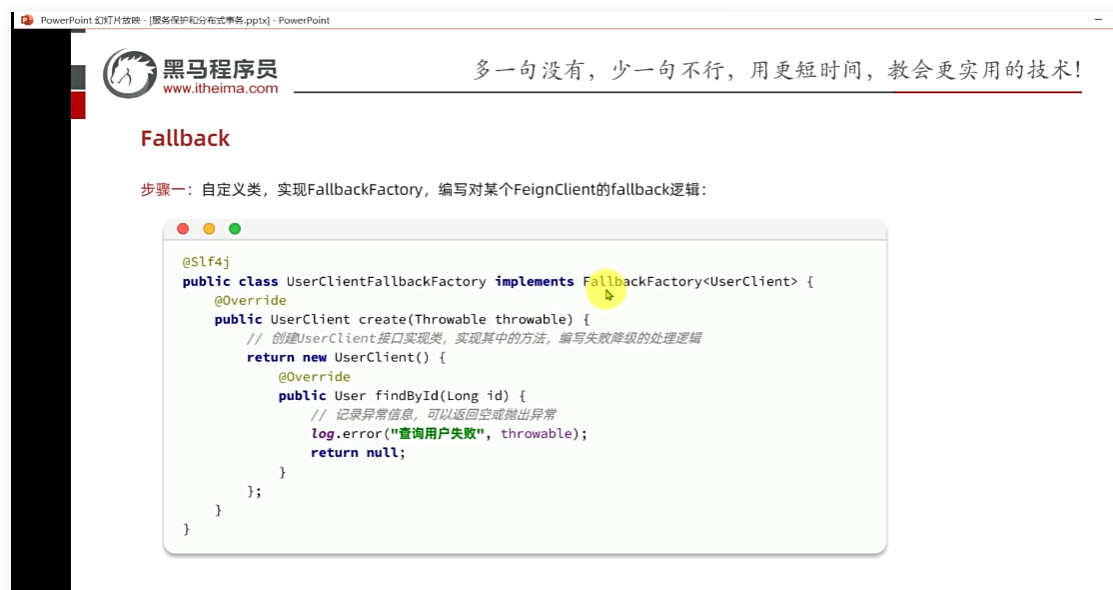
fallback:
我們在測試的時候,把線程數打滿的情況下,添加和修改的訪問時長沒有受到任何影響,查詢這個接口,響應時長很慢很慢,甚至出現報錯,前端得不到響應,資源被耗盡,這個時候我們應該如何去解決?
通過fallback去緩解
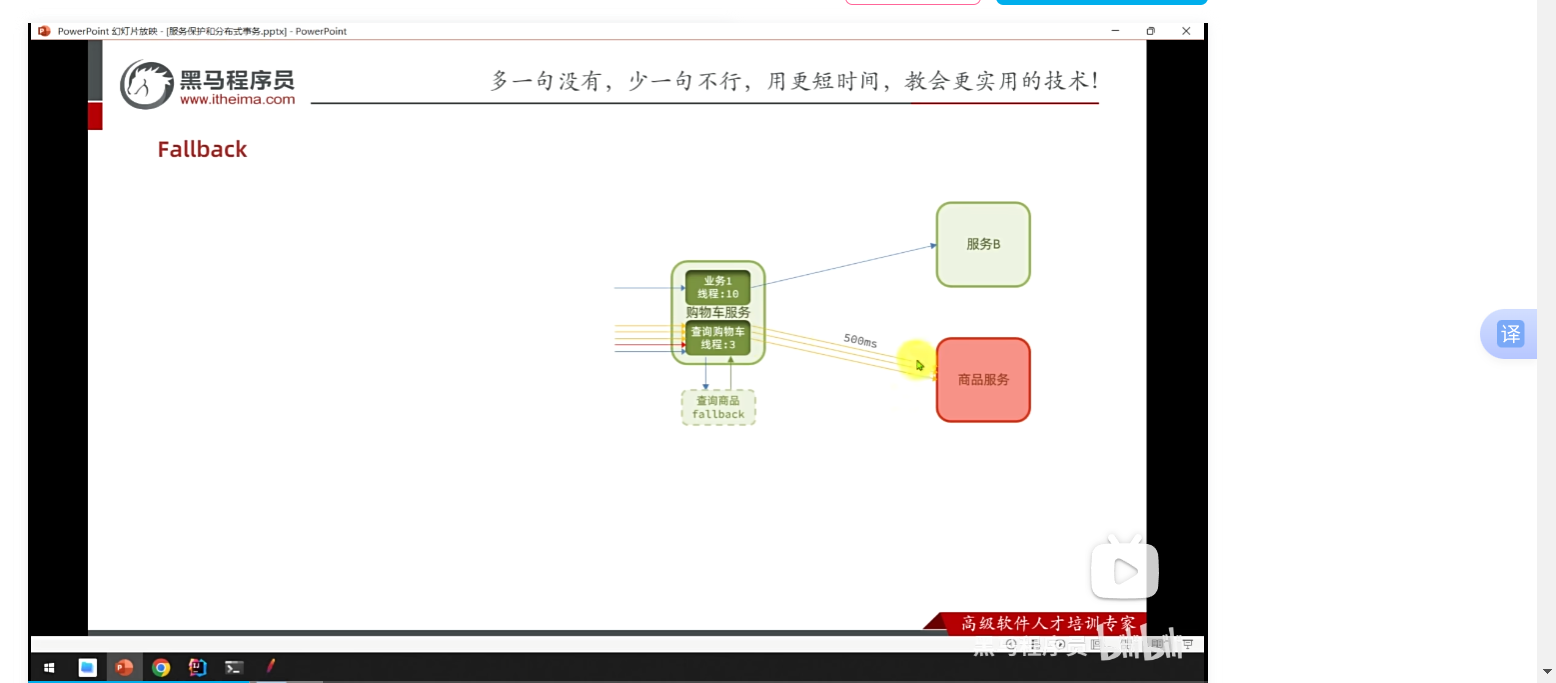
一瞬間來了很多請求,不會影響其他業務。但是,自身不可用,自身的資源被耗盡拒絕不再報錯,而是給用戶一個友好的提示。我們只對查詢商品,我們對商品服務feign線程隔離,對購物車查詢商品做fallback
所以
第一:讓http遠程調用也能被sentinel識別成為簇點。
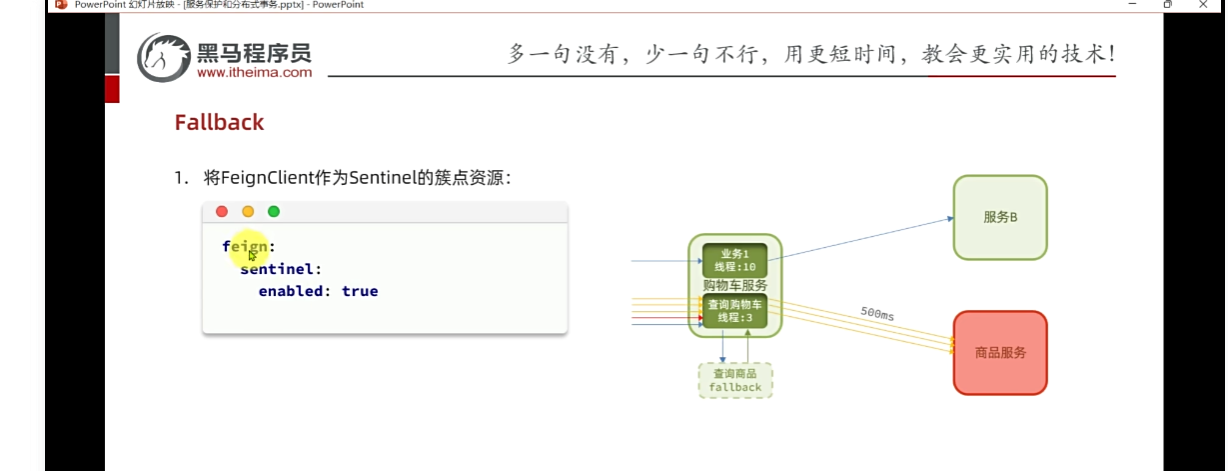
2.代表feign監控開啟,開啟流控,線程隔離,當線程打滿的時候,拒絕新的請求,不想報錯,添加fallback返回友好提示
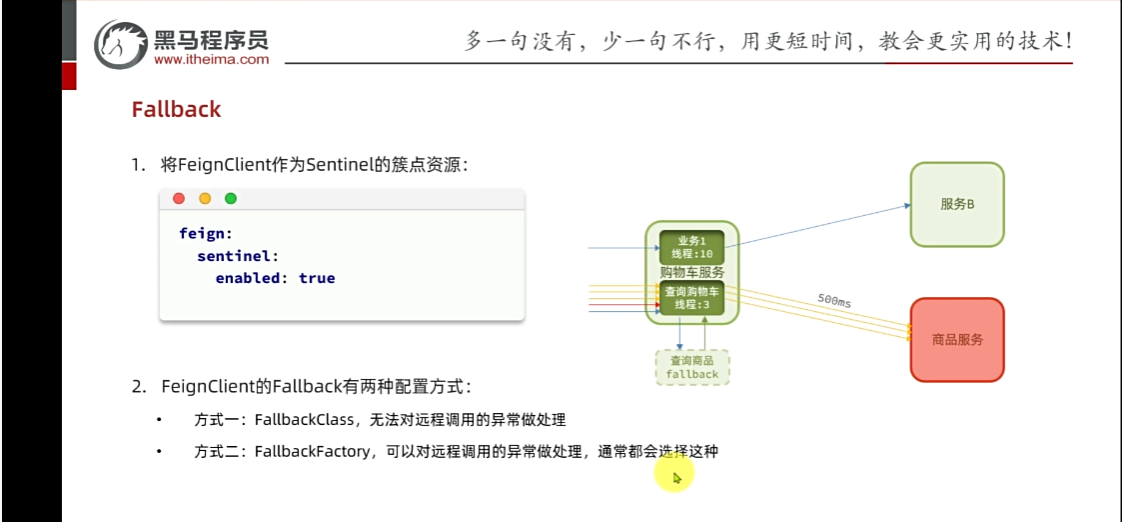
又多了一個鏈路,內部通過feign發起請求,開啟feign監控后,那么就出現了
那么我現在不用對整個購物車中的查詢商品進行線程隔離和流量控制,我僅僅對查這個feign的商品服務做線程隔離和流量控制,當我們的商品微服務出現故障的時候,我們只對商品微服務進行隔離,這樣就沒有問題,盡管你并發很高也不會把整個微服務資源耗盡
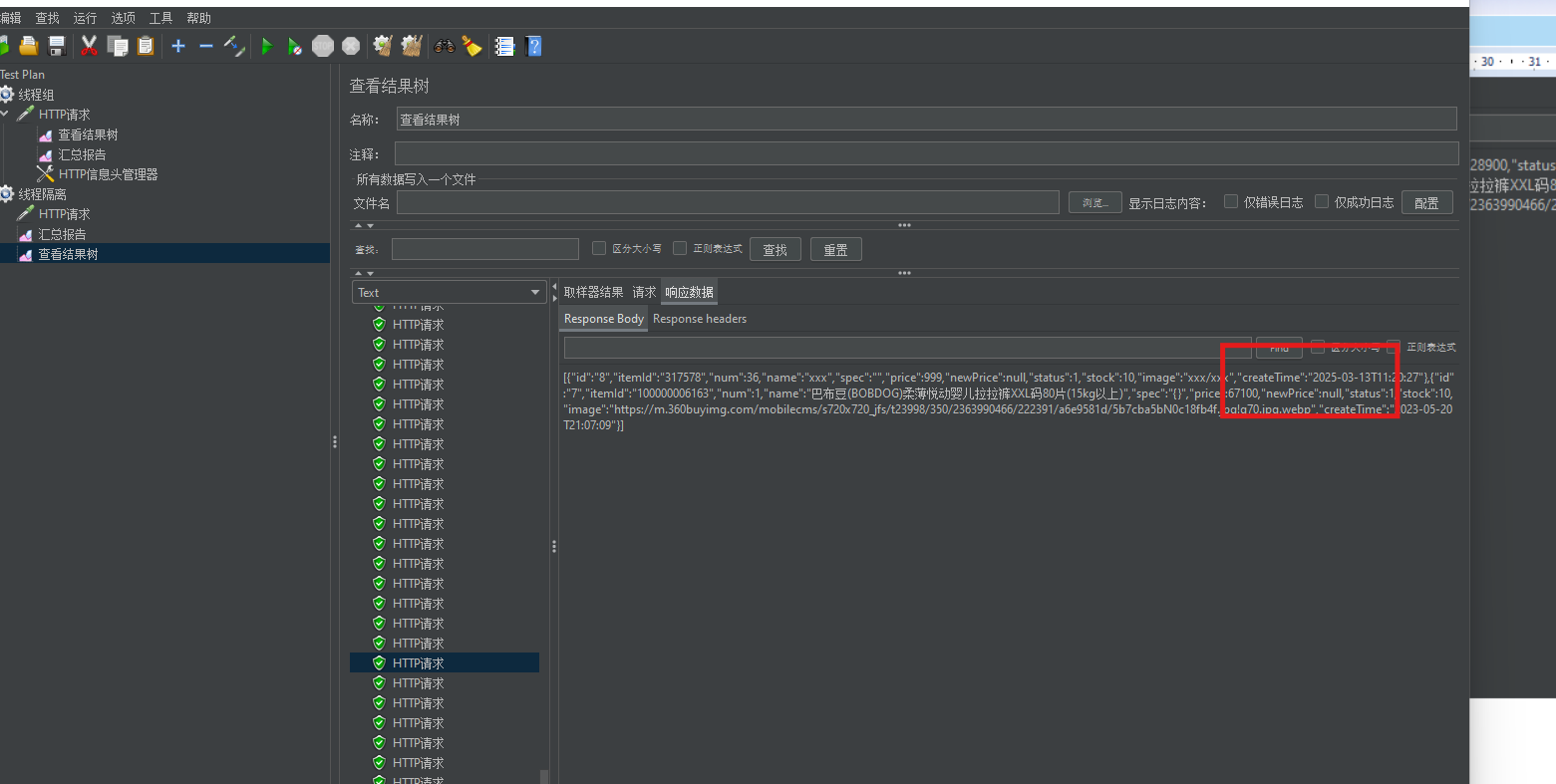
這里我配置的參數
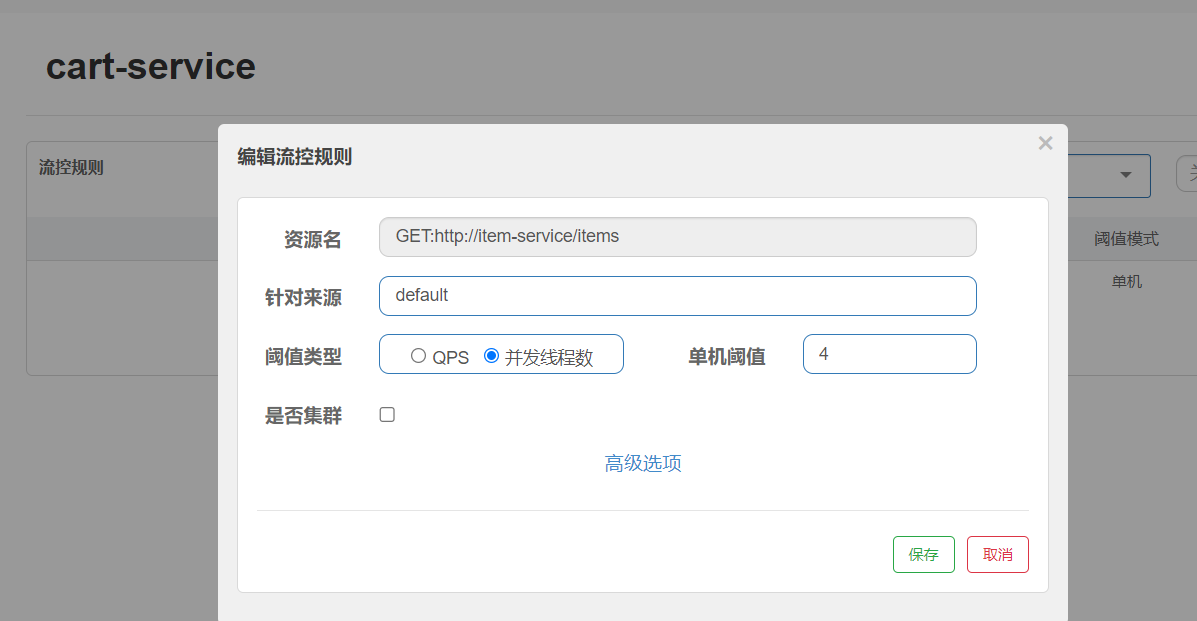
不建議對整個查詢購物車業務進行流量控制,一旦失敗就都失敗了,所以只針對feign
服務熔斷:
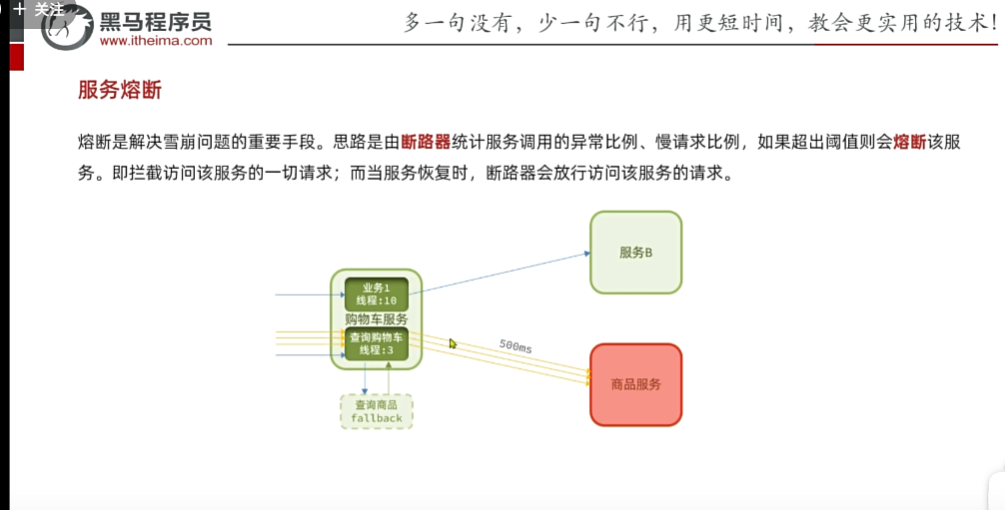
但是我們盡管做了線程隔離,但是我們卡的不會太多線程數,但是每一次請求來了都要做遠程調用,又很耗時,浪費,這還是超時,如果掛了沒必要再發起請求,
如果異常比例比較高,直接熔斷,拒絕發起請求,然后再走fallback這是優化后的最優解。
熔斷也不能一直斷開,如果恢復正常還要取消熔斷。
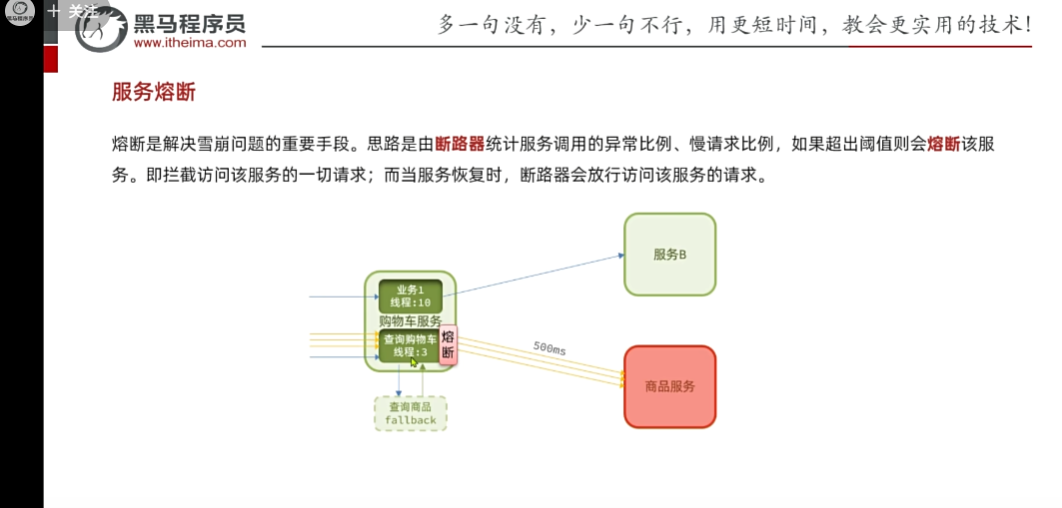
現在還有一個問題就是,什么時候熔斷,什么時候斷開?
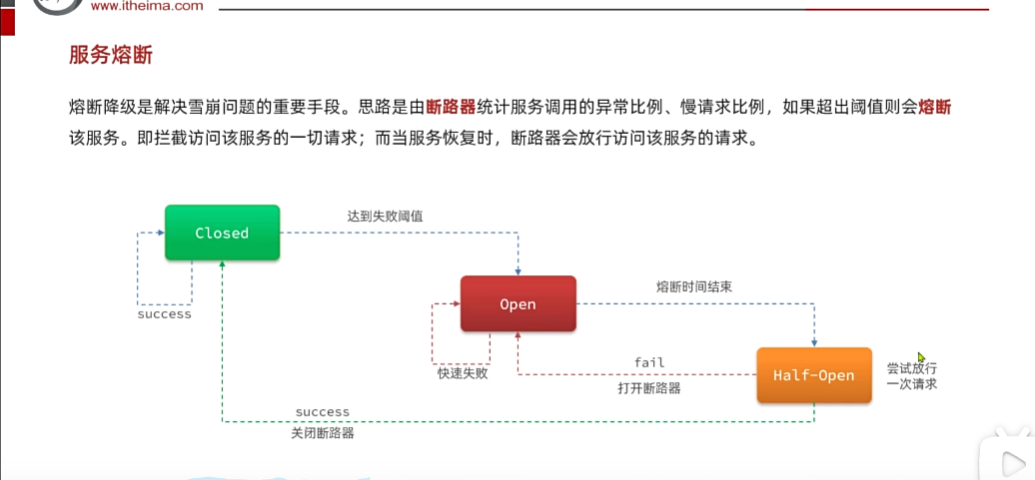
斷路器可以幫助我們
默認是綠色狀態,表示可以正常訪問,同時會去監控經過斷路器的請求,如果發現比例過高達到閾值,直接open(持續時間可配置),熔斷時間到期后,會去走到測試half,那么
檢查一下服務有沒有恢復,沒有恢復就回到open,到期后,再次進行檢查,如果成功了,就關閉
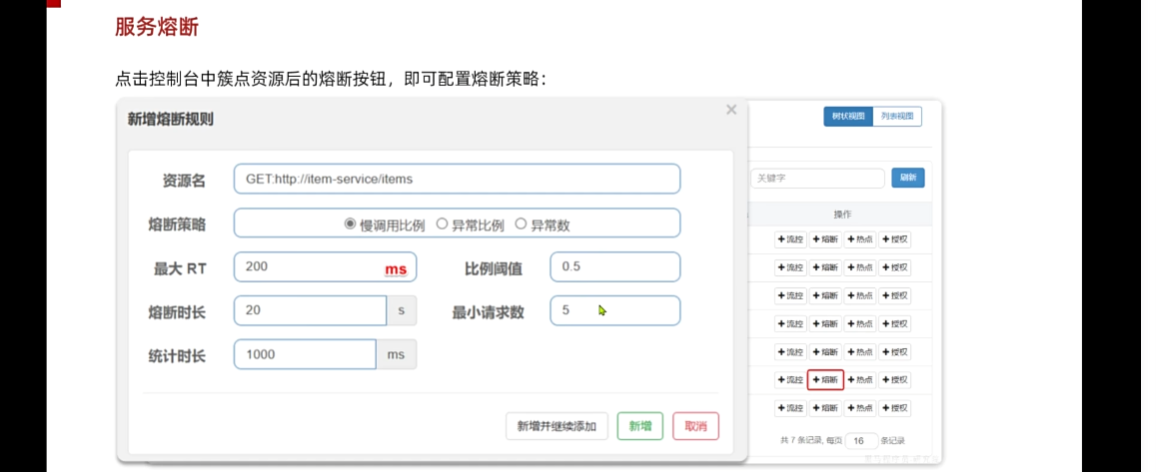
我們僅僅要做的就是在sentinel中做好配置 點擊熔斷查看規則
慢調用比例:十次請求多少次請求很慢
RT:最大響應時間 代表如果我發出這個請求超出200ms,那么就算是慢的,低于兩百不統計
比例閾值:那么就是慢多少達到閾值,超過百分之50,那么就達到閾值我就需要給你熔斷,比如十次有五次
熔斷時長:就是觸發熔斷,open的臨時狀態,拒絕所有的請求,不發起遠程調用,減少資源浪費
最小請求次數:就是統計的次數,最少發起幾次 然后查看是否達到0.5
統計時長:多少作為周期進行統計,1s只要請求數量為幾次,失敗多少次然后就觸發
測試:
熔斷后你會發現查詢購物車速度變快很多,因為它不會再去遠程調用,不會再去查商品
之前:

改進后:

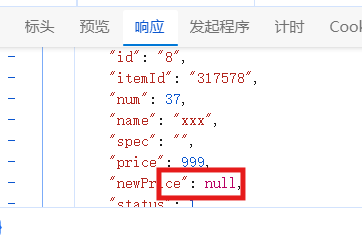
熔斷結束了,我們發行一次檢測都是七百多那么沒事了,如果有超過繼續熔斷




整合提示詞(Prompt))





)






)
2.3搭建仿真模型模塊操作運行仿真)

