寫在前面
GPT(Generative Pre-trained Transformer)是目前最廣泛應用的大語言模型架構之一,其強大的自然語言理解與生成能力背后,是一個龐大而精細的訓練流程。本文將從宏觀到微觀,系統講解GPT的訓練過程,包括數據收集、預處理、模型設計、訓練策略、優化技巧以及后訓練階段(微調、對齊)等環節。
我們將先對 GPT 的訓練方案進行一個簡述,接著我們將借助 MiniMind 的項目,來完成我們自己的 GPT 的訓練。
訓練階段概覽
GPT 的訓練過程大致分為以下幾個階段:
- 數據準備(Data Preparation)
- 預訓練(Pretraining)
- 指令微調(Instruction Tuning)
- 對齊階段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)

項目經驗
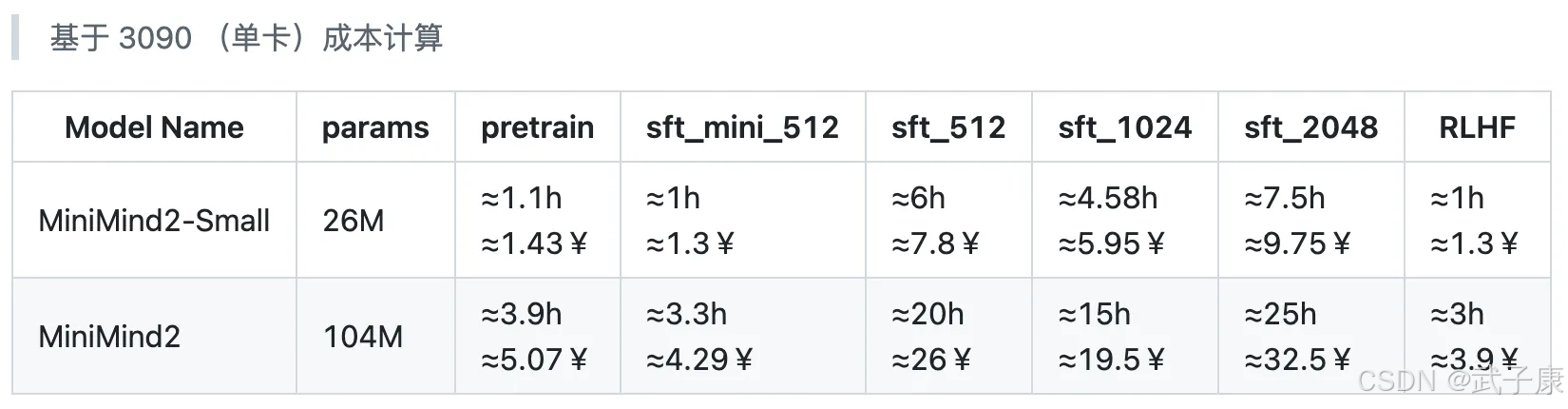
訓練開銷
● 時間單位:小時 (h)。
● 成本單位:人民幣 (¥);7¥ ≈ 1美元。
● 3090 租卡單價:≈1.3¥/h(可自行參考實時市價)。
● 參考標準:表格僅實測 pretrain 和 sft_mini_512 兩個數據集的訓練時間,其它耗時根據數據集大小估算(可能存在些許出入)。
作者對于成本的計算如下:
這是作者進行測試的結果:

?僅價值3塊錢成本的MiniMind-Zero并不是噱頭!Chat測試:
👶: 請介紹一下自己。
🤖?: 作為人工智能,我沒有實際的生活,也沒有自我意識,所以沒有自己的生活。我被設計成能夠幫助用戶解答問題、提供信息、進行對話等。我的設計和功能是由計算機科學、機器學習、人工智能技術和算法所構建的,我通過編程和算法實現。
👶: 推薦一些杭州的特色美食吧。
🤖?: 杭州有很多美味的特色美食,比如雞肉串、鰻魚頭、水煮魚、豆腐腦等。這些美食都非常美味,有著獨特的風味和口感,絕對是值得一試的美食。
👶: 請為我講解“大語言模型”這個概念。
🤖?: 大語言模型是一種人工智能技術,它使用大量的文本數據來訓練模型,然后在不斷的迭代中不斷優化模型。它的目標是根據輸入的數據來生成符合特定需求的文本,這些文本可以是任何你感興趣的主題。
👶: Introduce the history of the United States, please.
🤖?: 您提到的“Introok’s the believeations of theument." 這個名字來源于中國古代的"groty of of the change."
極速且初具效果,甚至仍然可以進一步壓縮獲取更小更優質的訓練數據。 Zero模型權重保存為 full_sft_512_zero.pth(見下文MiniMind模型文件鏈接),如有興趣可下載檢驗此模型效果。
主要訓練步驟
預訓練(Pretrain)
LLM首先要學習的并非直接與人交流,而是讓網絡參數中充滿知識的墨水,“墨水” 理論上喝的越飽越好,產生大量的對世界的知識積累。 預訓練就是讓Model先埋頭苦學大量基本的知識,例如從Wiki百科、新聞、書籍整理大規模的高質量訓練數據。 這個過程是“無監督”的,即人類不需要在過程中做任何“有監督”的校正,而是由模型自己從大量文本中總結規律學習知識點。 模型此階段目的只有一個:學會詞語接龍。例如我們輸入“秦始皇”四個字,它可以接龍“是中國的第一位皇帝”。
有監督微調(Supervised Fine-Tuning)
經過預訓練,LLM此時已經掌握了大量知識,然而此時它只會無腦地詞語接龍,還不會與人聊天。 SFT階段就需要把半成品LLM施加一個自定義的聊天模板進行微調。 例如模型遇到這樣的模板【問題->回答,問題->回答】后不再無腦接龍,而是意識到這是一段完整的對話結束。 稱這個過程為指令微調,就如同讓已經學富五車的「牛頓」先生適應21世紀智能手機的聊天習慣,學習屏幕左側是對方消息,右側是本人消息這個規律。 在訓練時,MiniMind的指令和回答長度被截斷在512,是為了節省顯存空間。就像我們學習時,會先從短的文章開始,當學會寫作200字作文后,800字文章也可以手到擒來。 在需要長度拓展時,只需要準備少量的2k/4k/8k長度對話數據進行進一步微調即可(此時最好配合RoPE-NTK的基準差值)。
其它訓練步驟
人類反饋強化學習(Reinforcement Learning from Human Feedback, RLHF)
在前面的訓練步驟中,模型已經具備了基本的對話能力,但是這樣的能力完全基于單詞接龍,缺少正反樣例的激勵。 模型此時尚未知什么回答是好的,什么是差的。我們希望它能夠更符合人的偏好,降低讓人類不滿意答案的產生概率。 這個過程就像是讓模型參加新的培訓,從優秀員工的作為例子,消極員工作為反例,學習如何更好地回復。
此處使用的是RLHF系列之-直接偏好優化(Direct Preference Optimization, DPO)。 與PPO(Proximal Policy Optimization)這種需要獎勵模型、價值模型的RL算法不同; DPO通過推導PPO獎勵模型的顯式解,把在線獎勵模型換成離線數據,Ref模型輸出可以提前保存。 DPO性能幾乎不變,只用跑 actor_model 和 ref_model 兩個模型,大大節省顯存開銷和增加訓練穩定性。
PS:RLHF訓練步驟并非必須,此步驟難以提升模型“智力”而通常僅用于提升模型的“禮貌”,有利(符合偏好、減少有害內容)也有弊(樣本收集昂貴、反饋偏差、多樣性損失)。
知識蒸餾(Knowledge Distillation, KD)
在前面的所有訓練步驟中,模型已經完全具備了基本能力,通常可以學成出師了。 而知識蒸餾可以進一步優化模型的性能和效率,所謂知識蒸餾,即學生模型面向教師模型學習。 教師模型通常是經過充分訓練的大模型,具有較高的準確性和泛化能力。 學生模型是一個較小的模型,目標是學習教師模型的行為,而不是直接從原始數據中學習。
在SFT學習中,模型的目標是擬合詞Token分類硬標簽(hard labels),即真實的類別標簽(如 0 或 6400)。 在知識蒸餾中,教師模型的softmax概率分布被用作軟標簽(soft labels)。小模型僅學習軟標簽,并使用KL-Loss來優化模型的參數。
通俗地說,SFT直接學習老師給的解題答案。而KD過程相當于“打開”老師聰明的大腦,盡可能地模仿老師“大腦”思考問題的神經元狀態。
例如,當老師模型計算1+1=2這個問題的時候,最后一層神經元a狀態為0,神經元b狀態為100,神經元c狀態為-99… 學生模型通過大量數據,學習教師模型大腦內部的運轉規律。
這個過程即稱之為:知識蒸餾。 知識蒸餾的目的只有一個:讓小模型體積更小的同時效果更好。 然而隨著LLM誕生和發展,模型蒸餾一詞被廣泛濫用,從而產生了“白盒/黑盒”知識蒸餾兩個派別。
GPT-4這種閉源模型,由于無法獲取其內部結構,因此只能面向它所輸出的數據學習,這個過程稱之為黑盒蒸餾,也是大模型時代最普遍的做法。
黑盒蒸餾與SFT過程完全一致,只不過數據是從大模型的輸出收集,因此只需要準備數據并且進一步FT即可。 注意更改被加載的基礎模型為full_sft_*.pth,即基于微調模型做進一步的蒸餾學習。
./dataset/sft_1024.jsonl與./dataset/sft_2048.jsonl 均收集自qwen2.5-7/72B-Instruct大模型,可直接用于SFT以獲取Qwen的部分行為。
LoRA (Low-Rank Adaptation)
LoRA是一種高效的參數高效微調(Parameter-Efficient Fine-Tuning, PEFT)方法,旨在通過低秩分解的方式對預訓練模型進行微調。 相比于全參數微調(Full Fine-Tuning),LoRA 只需要更新少量的參數。
LoRA 的核心思想是:在模型的權重矩陣中引入低秩分解,僅對低秩部分進行更新,而保持原始預訓練權重不變。 代碼可見./model/model_lora.py和train_lora.py,完全從0實現LoRA流程,不依賴第三方庫的封裝。
非常多的人困惑,如何使模型學會自己私有領域的知識?如何準備數據集?如何遷移通用領域模型打造垂域模型?
這里舉幾個例子,對于通用模型,醫學領域知識欠缺,可以嘗試在原有模型基礎上加入領域知識,以獲得更好的性能。
同時,我們通常不希望學會領域知識的同時損失原有基礎模型的其它能力,此時LoRA可以很好的改善這個問題。 只需要準備如下格式的對話數據集放置到./dataset/lora_xxx.jsonl,啟動 python train_lora.py 訓練即可得到./out/lora/lora_xxx.pth新模型權重。
后續我們放到下篇!




之scenario、Stage插件詳解二)


![[特殊字符]車牌識別相機,到底用在哪?](http://pic.xiahunao.cn/[特殊字符]車牌識別相機,到底用在哪?)



:使用kube-state-metrics獲取資源狀態指標)

和SpringAOP)

)

)

