
- 作者: Shijin Zhao, Fuhui Zhou, Qihui Wu
- 單位:南京航空航天大學電子信息工程學院
- 論文標題: UAV Visual Navigation in the Large-Scale Outdoor Environment: A Semantic Map-Based Cognitive Escape Reinforcement Learning Method
- 論文鏈接:https://ieeexplore.ieee.org/abstract/document/10847926
- 出版信息:IEEE Internet of Things Journal (IOT) 20 January 2025
主要貢獻
- 提出SM-CERL框架:針對無人機視覺導航中的部分可觀察性和局部最優陷阱問題,提出了語義地圖基礎的認知逃逸強化學習(SM-CERL)框架。
- 知識驅動的導航性能提升:在SM-CERL框架中引入導航先驗知識和規則知識,幫助無人機更高效地推斷目標位置并逃逸局部最優,顯著提升導航性能。
- 卓越的實驗性能:通過大量實驗驗證,SM-CERL在導航準確性和效率方面均優于經典和現有的先進方法,展現出高效的導航能力和對新場景的良好泛化能力。
研究背景
- 無人機技術的快速發展:
- 無人機技術在物聯網(IoT)生態系統中的應用日益廣泛,如應急救援、農作物保護和交通監控等。
- 無人機視覺導航技術作為關鍵支撐,能夠利用機載相機獲取的第一人稱視覺輸入(實時視頻或圖像)精準導航至用戶指定目標,助力無人機在復雜IoT生態系統中成為智能自主節點,推動智慧城市建設。
- 傳統導航方法的局限性:
- 傳統的無人機導航方法主要依賴于同時定位與建圖(SLAM)技術,通過構建環境地圖實現路徑規劃導航。
- 然而,在大規模戶外環境中,SLAM技術因主動構建地圖計算效率低,且目標驅動視覺導航更關注達到視覺定義的目標而非構建詳細環境地圖,導致SLAM難以直接應用。
- 深度強化學習(DRL)的挑戰:
- DRL作為一種新興的導航方法,將導航決策問題建模為馬爾可夫決策過程(MDP),利用深度神經網絡直接基于輸入圖像做出導航決策,無需詳細環境地圖。
- 但DRL在復雜環境中學習有效導航策略面臨兩大挑戰,即部分可觀察性和局部最優陷阱。部分可觀察性導致無人機難以全面理解環境,局部最優陷阱則使無人機在訓練過程中因稀疏或欺騙性獎勵而陷入局部最優解,難以找到全局最優策略。
問題描述與馬爾可夫決策過程
問題表述
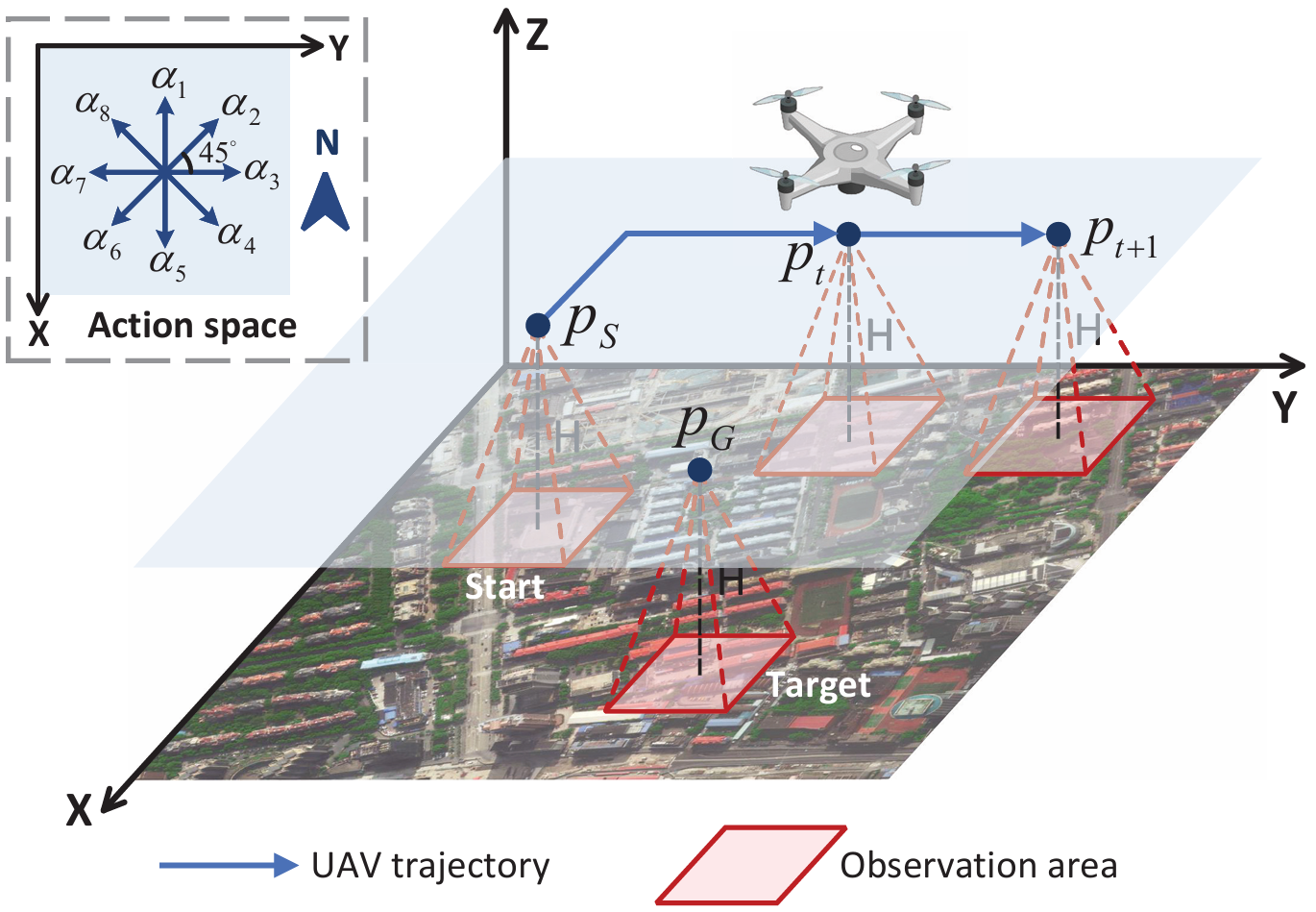
- 任務描述:研究目標驅動的無人機視覺導航任務,無人機在指定空域內導航至未知目標位置。導航過程中,無人機利用機載相機獲取的實時觀測圖像和目標圖像(均來自衛星地圖)進行導航。
- 飛行環境:假設無人機在高度為 H H H 的水平面上飛行,飛行區域為 [ 0 , D ] × [ 0 , D ] [0, D] \times [0, D] [0,D]×[0,D]。導航任務包含 T T T 個時間步,無人機從隨機起點 p S = ( x S , y S ) p_S = (x_S, y_S) pS?=(xS?,yS?) 飛往目標點 p G = ( x G , y G ) p_G = (x_G, y_G) pG?=(xG?,yG?)。
- 動作空間:無人機的飛行方向被離散化為八個選項,分別以北方向為基準,按順時針方向每隔45°劃分。
- 目標函數:最小化飛行時間 T T T,即
min ? { p t , ? t ∈ [ 0 , T ] } T , \min_{\{p_t, \forall t \in [0, T]\}} T, {pt?,?t∈[0,T]}min?T,
約束條件為:- p 0 = p S p_0 = p_S p0?=pS?, p T = p G p_T = p_G pT?=pG?;
- x L ≤ x t ≤ x U x_L \leq x_t \leq x_U xL?≤xt?≤xU?, y L ≤ y t ≤ y U y_L \leq y_t \leq y_U yL?≤yt?≤yU?,確保無人機在指定區域內飛行。
基于MDP的無人機導航建模
- MDP定義:將無人機視覺導航問題建模為馬爾可夫決策過程(MDP),其中無人機作為智能體(agent)與環境進行交互。
- 狀態(State):定義為基于觀測的語義地圖 M t ∈ R 2 × N g × N g M_t \in \mathbb{R}^{2 \times N_g \times N_g} Mt?∈R2×Ng?×Ng?,包含兩個通道:
- 探索地圖通道 M e t ∈ R 1 × N g × N g M_e^t \in \mathbb{R}^{1 \times N_g \times N_g} Met?∈R1×Ng?×Ng?,存儲已探索、未探索和當前位置的信息(分別用0、-1和1表示)。
- 相似度地圖通道 M s t ∈ R 1 × N g × N g M_s^t \in \mathbb{R}^{1 \times N_g \times N_g} Mst?∈R1×Ng?×Ng?,存儲與目標圖像相似度值(已探索區域的相似度值為 v s t ∈ { 0 , 1 } v_s^t \in \{0, 1\} vst?∈{0,1},未探索區域為-1)。
- 動作(Action):無人機的飛行方向,動作空間為 A = { α 1 , α 2 , … , α 8 } A = \{\alpha_1, \alpha_2, \dots, \alpha_8\} A={α1?,α2?,…,α8?}。
- 獎勵函數(Reward Function):
r t = { r g , if? p t = p G , r b , if? x t ? [ 0 , D ] or? y t ? [ 0 , D ] , r p , else . r_t = \begin{cases} r_g, & \text{if } p_t = p_G, \\ r_b, & \text{if } x_t \notin [0, D] \text{ or } y_t \notin [0, D], \\ r_p, & \text{else}. \end{cases} rt?=? ? ??rg?,rb?,rp?,?if?pt?=pG?,if?xt?∈/[0,D]?or?yt?∈/[0,D],else.?
其中, r g r_g rg? 為目標獎勵, r b r_b rb? 為越界懲罰, r p r_p rp? 為時間懲罰,激勵無人機快速到達目標。
- 狀態(State):定義為基于觀測的語義地圖 M t ∈ R 2 × N g × N g M_t \in \mathbb{R}^{2 \times N_g \times N_g} Mt?∈R2×Ng?×Ng?,包含兩個通道:
SM-CERL框架
框架概述
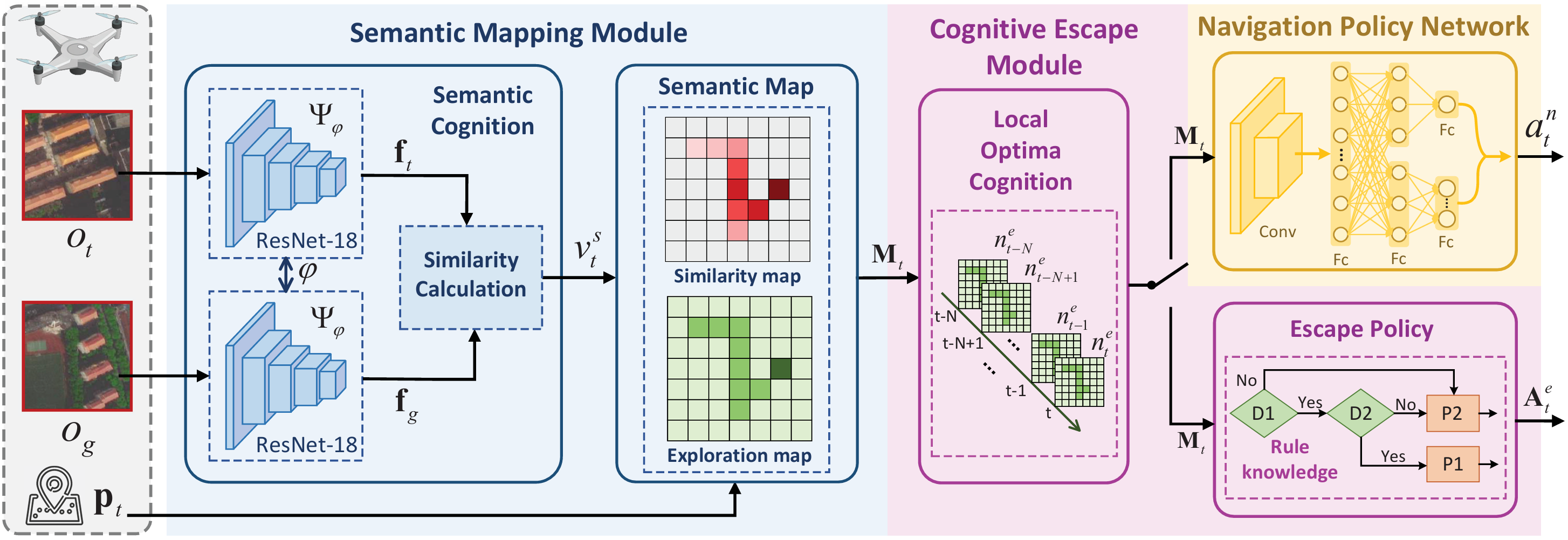
- 框架組成:SM-CERL框架包含三個模塊:
- 語義映射模塊(SMM):替代傳統DRL模型中的感知層,從原始圖像中提取語義信息并構建語義地圖。
- 認知逃逸模塊(CEM):主動識別局部最優并制定逃逸策略。
- 導航策略網絡(NPN):基于語義地圖生成導航動作,相當于傳統DRL模型中的決策層。
語義映射模塊(SMM)
- 語義認知子模塊:
- 使用預訓練的孿生網絡(每個分支為ResNet-18)提取當前觀測圖像 o t o_t ot? 和目標圖像 o G o_G oG? 的特征向量 f t f_t ft? 和 f G f_G fG?。
- 通過相似性計算組件(SCC)計算特征距離 d f t = ∥ f t ? f G ∥ 2 d_f^t = \|f_t - f_G\|_2 dft?=∥ft??fG?∥2?,進而得到相似度 v s t = max ? ( 0 , 1 ? d f t d f max ) v_s^t = \max(0, 1 - \frac{d_f^t}{d_f^{\text{max}}}) vst?=max(0,1?dfmax?dft??),其中 d f max d_f^{\text{max}} dfmax? 為最大閾值。
- 語義地圖子模塊:
- 根據相似度 v s t v_s^t vst? 和當前位置 p t p_t pt? 更新探索地圖和相似度地圖,構建語義地圖 M t M_t Mt?,為無人機提供環境語義信息和導航先驗知識。
認知逃逸模塊(CEM)
- 局部最優認知(LOC):
- 通過跟蹤語義地圖中已探索位置的數量,判斷無人機是否陷入局部最優。若連續多個時間步中探索位置數量未增加,則認定無人機陷入局部最優。
- 逃逸策略(EP):
- 將語義地圖劃分為多個子區域,計算各子區域的最大相似度值和探索網格數量。
- 根據規則選擇目標子區域(優先選擇相似度高且未充分探索的區域),并在其中隨機選取未訪問位置作為子目標,生成逃逸動作序列,直至到達子目標完成逃逸。
導航策略網絡(NPN)
- 網絡結構:采用Dueling Double Deep Q Network(D3QN)算法作為基礎算法。
- 輸入語義地圖 M t M_t Mt?,通過兩個卷積層提取特征(第一個卷積層有16個4×4濾波器,步長為2;第二個卷積層有32個2×2濾波器,步長為2),每個卷積層后接ReLU激活函數。
- 提取的特征輸入到Dueling網絡中,分別估計價值函數和優勢函數,最終輸出8維Q值向量,依據貪婪策略選擇動作。
SM-CERL的訓練
訓練過程概述
- 獨立訓練:SM-CERL的訓練分為兩個獨立階段,即語義認知網絡的訓練和導航策略網絡的訓練,兩個網絡可以獨立訓練。
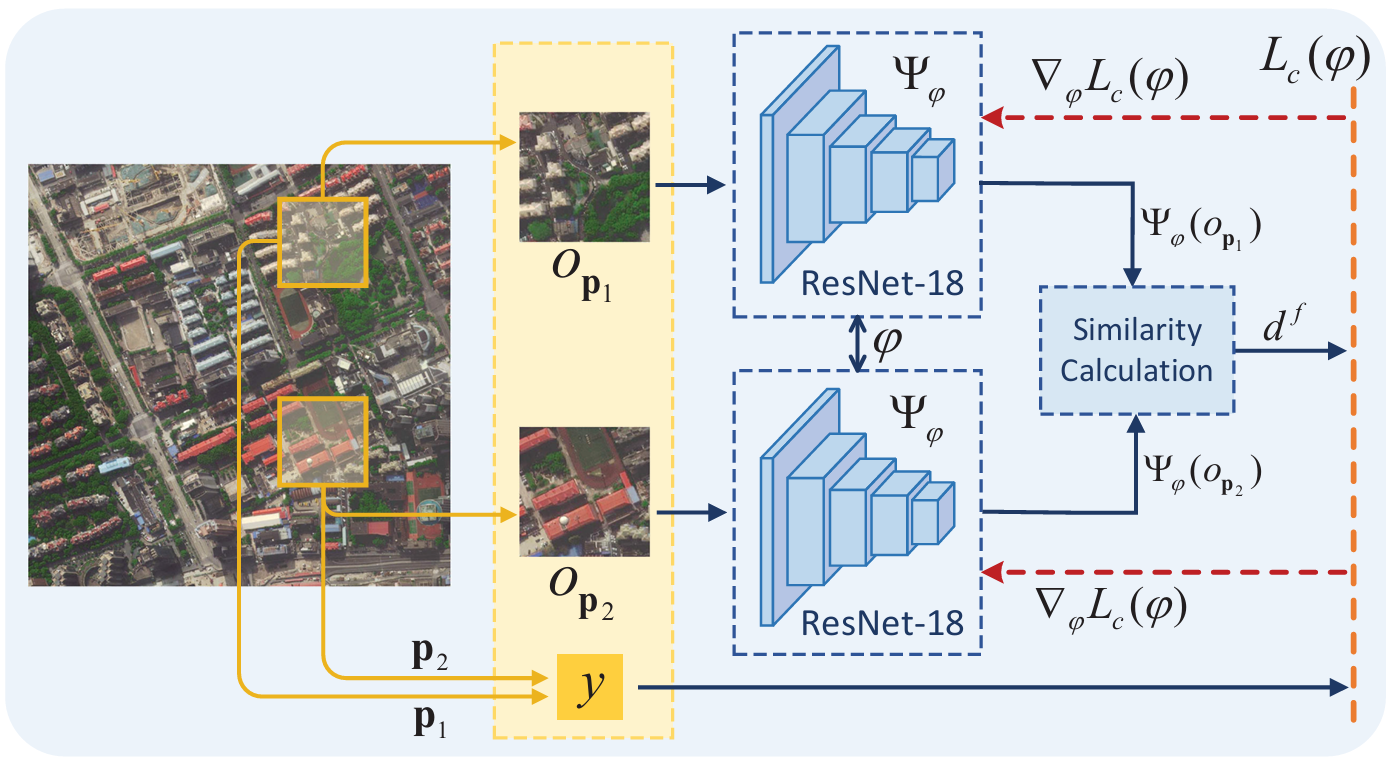
語義認知網絡訓練
- 孿生網絡訓練目標:學習參數 ? \phi ?,使網絡能夠將高維圖像空間轉換為低維特征空間,特征向量的歐幾里得距離與原始圖像空間中的相似度呈負相關。
- 訓練數據:從不同城市的衛星地圖中創建數據對 ( o p 1 , o p 2 , y ) (o_{p1}, o_{p2}, y) (op1?,op2?,y),根據圖像中心點距離判斷相似性(距離小于 k k k 為正樣本,大于 λ k \lambda k λk 為負樣本)。
- 對比損失函數:
L c ( ? ) = 1 2 y ( d f ) 2 + 1 2 ( 1 ? y ) max ? ( d m ? d f , 0 ) 2 , L_c(\phi) = \frac{1}{2} y (d_f)^2 + \frac{1}{2} (1 - y) \max(d_m - d_f, 0)^2, Lc?(?)=21?y(df?)2+21?(1?y)max(dm??df?,0)2,
其中 d m d_m dm? 為安全閾值,通過梯度優化方法最小化損失函數,使網絡能夠有效捕捉圖像的相似性結構。
導航策略網絡訓練
- 訓練算法:基于SM-CERL的導航策略網絡訓練過程如算法1所示。
- 初始化地圖、起點和目標點,構建語義地圖 M t M_t Mt? 作為狀態 s t s_t st?。
- 若無人機未陷入局部最優,則利用NPN選擇動作并執行,存儲訓練經驗 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st?,at?,rt?,st+1?) 到回放緩沖區 D D D,隨機采樣進行網絡訓練。
- 若無人機陷入局部最優,則利用CEM生成逃逸策略并執行逃逸動作,直至逃逸完成,隨后繼續利用NPN進行導航和訓練。
- 目標Q值計算:
y i = { r i , if?done r i + γ ? Q ( s i + 1 , arg ? max ? a Q ( s i + 1 , a ; θ ) ; θ ? ) , otherwise y_i = \begin{cases} r_i, & \text{if done} \\ r_i + \gamma \cdot Q(s_{i+1}, \arg\max_a Q(s_{i+1}, a; \theta); \theta^-), & \text{otherwise} \end{cases} yi?={ri?,ri?+γ?Q(si+1?,argmaxa?Q(si+1?,a;θ);θ?),?if?doneotherwise?
其中 θ ? \theta^- θ? 為目標網絡參數,每 N u N_u Nu? 步更新一次。 - 損失函數:
L Q ( θ ) = E ( s i , a i , r i , s i + 1 ) [ ( y i ? Q ( s i , a i ; θ ) ) 2 ] , L_Q(\theta) = \mathbb{E}_{(s_i, a_i, r_i, s_{i+1})} \left[ (y_i - Q(s_i, a_i; \theta))^2 \right], LQ?(θ)=E(si?,ai?,ri?,si+1?)?[(yi??Q(si?,ai?;θ))2],
通過梯度下降法更新網絡參數 θ \theta θ。
實驗
- 實驗設置:選擇六個不同區域的衛星地圖,大小為3km×3km,均勻劃分為30×30網格作為導航地圖,每個網格單元對應100m×100m的物理區域。在訓練過程中,為D3QN的訓練策略添加隨機性,使無人機有一定概率選擇隨機動作,而在評估時,無人機始終使用測試策略貪婪地選擇最優行為。
- 對比方法:
- 隨機動作(RA):無人機在每個時間步從動作空間中隨機選擇動作。
- CRL:與SM-CERL相比,CRL去除了SMM和CEM組件,僅使用語義認知網絡生成的相似性信息作為狀態,其策略網絡訓練過程如算法2所示,作為基線方法比較記憶增強和局部最優逃逸機制的效果。
- SM-CRL:保留SM-CERL的狀態,但去除了CEM,在訓練中不包含識別和逃逸局部最優的步驟,用于評估CEM對導航性能的貢獻。
- LSTM-CRL:在CRL基礎上引入LSTM網絡,增強無人機的記憶能力,其訓練過程與算法2相同,作為對比基線評估不同記憶增強機制(LSTM與SMM)對導航性能的影響。
- CERL-old:采用早期的CERL框架,基于已探索區域的信息隨機逃逸至未訪問區域,未利用探索相似性信息,用于評估增強型認知逃逸機制在逃逸局部最優方面的優勢。
- CERL:與SM-CERL相比,CERL去除了SMM,使用與CRL相同的狀態,在訓練中不包含語義映射過程,用于評估語義地圖對導航性能的影響。
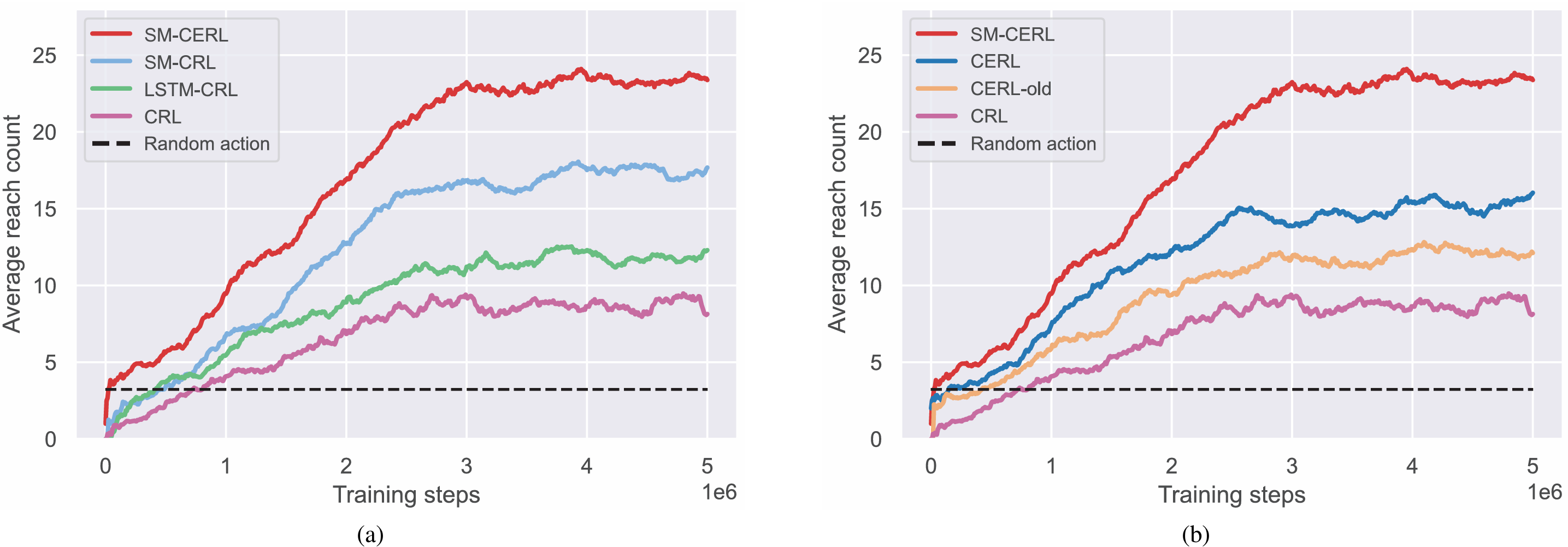
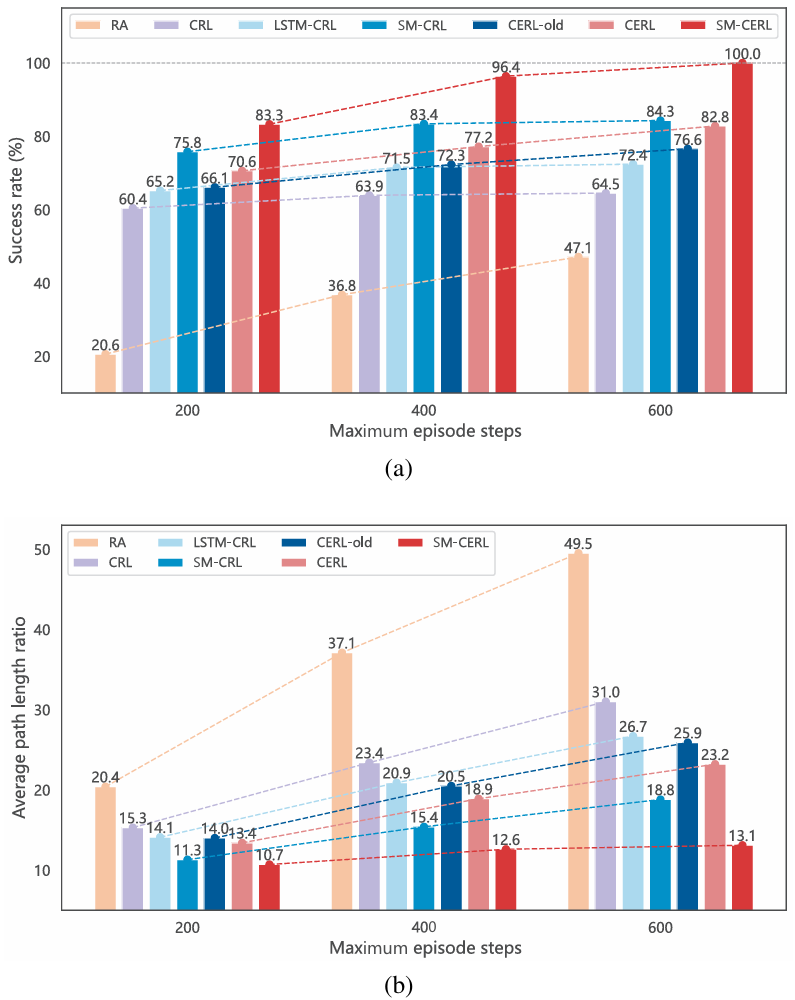
- 訓練性能評估:
- 通過在訓練過程中定期評估測試策略來衡量不同方法的訓練性能,以平均到達次數作為評估指標。
- SM-CERL方法在訓練過程中平均到達次數最高,表明其學習到了更有效的導航策略,能夠更頻繁地在規定時間步內到達目標。
- 導航性能比較:
- 在訓練五百萬步后,對各模型進行1000次導航測試,以成功率(SR)和平均路徑長度比(APLR)衡量導航性能。
- SM-CERL方法在所有測試方法中均實現了最高的成功率和最短的平均路徑長度比,證明了其在導航準確性和效率方面的優越性。
- 此外,通過對比CRL、LSTM-CRL和SM-CRL方法,驗證了SMM在記憶增強方面的優勢;通過對比CRL、CERL-old和CERL方法,證明了增強型CEM在逃逸局部最優方面的有效性。
-
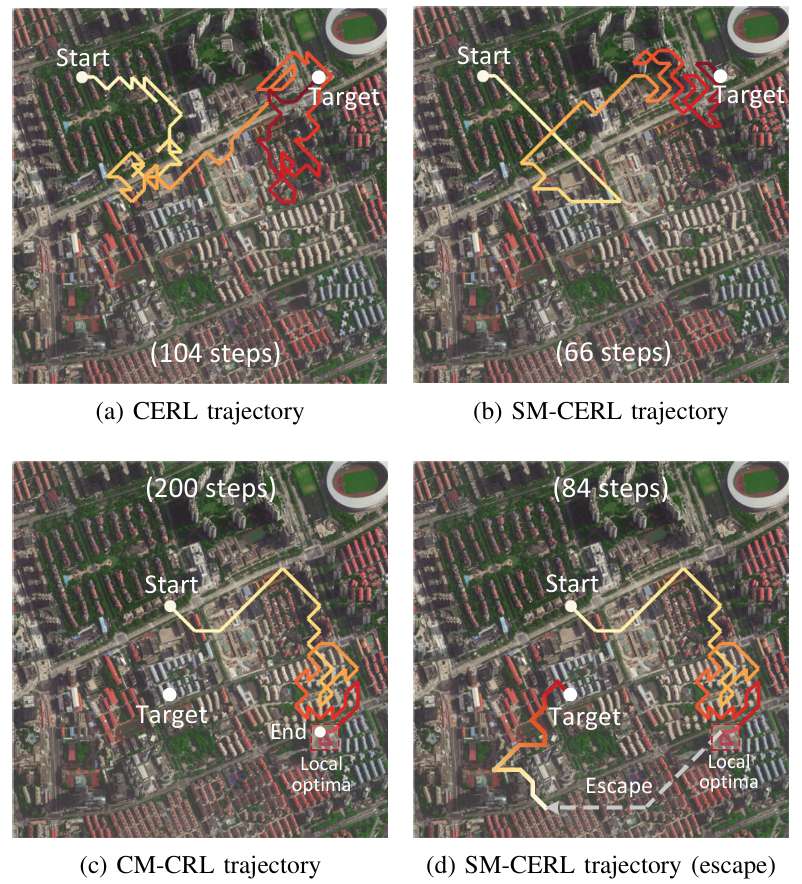
導航行為分析:
- SM-CERL方法的軌跡更高效,避免了重復探索,并能有效逃逸局部最優。
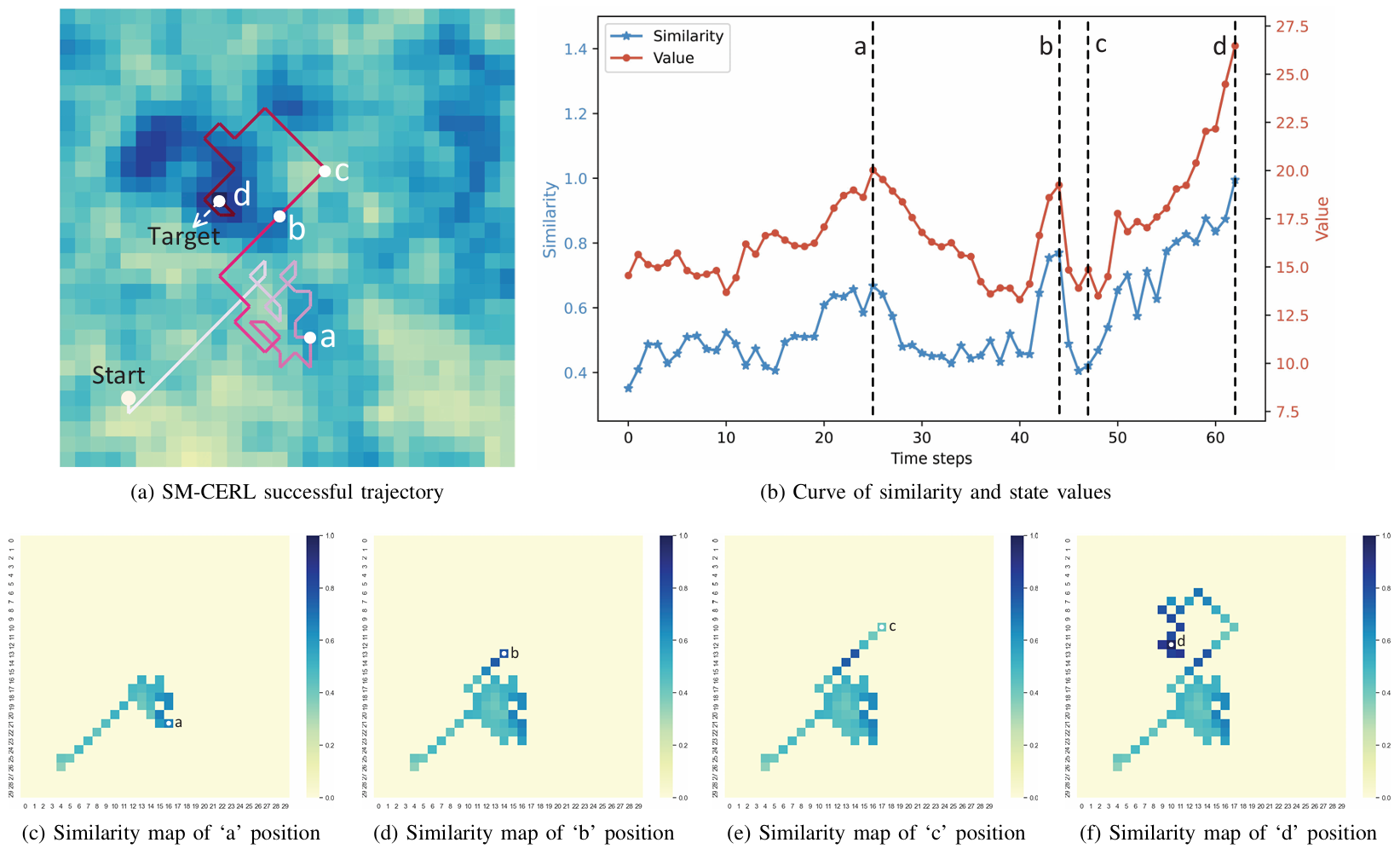
- 下圖進一步展示了SM-CERL方法在無局部最優陷阱時的導航軌跡以及相似度和狀態值的變化,表明無人機學習到了基于相似度的導航策略,傾向于向相似度更高的區域移動。
- 泛化能力分析:
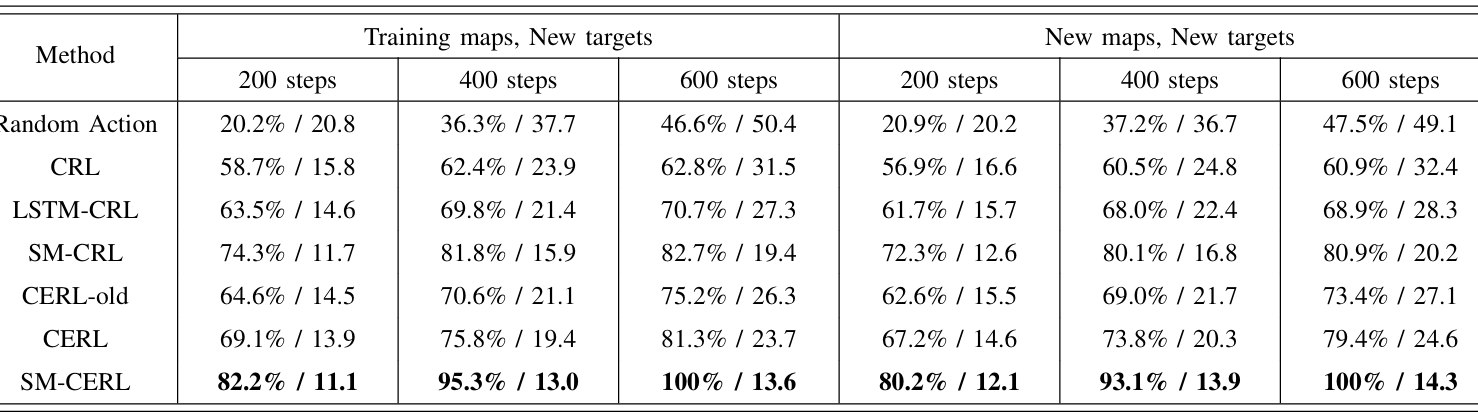
- 在訓練地圖上設置新目標以及在未見過的地圖上設置新目標兩種測試場景下,評估不同方法的泛化性能。
- 下表顯示,SM-CERL方法在兩種場景下均實現了最高的成功率和最短的平均路徑長度比,證明了其在新場景下的良好泛化能力。
結論與未來工作
- 結論:
- 本文提出的SM-CERL導航框架通過構建語義地圖作為無人機的記憶,并開發針對性的逃逸策略,有效解決了DRL在大規模戶外環境中無人機視覺導航所面臨的部分可觀察性和局部最優陷阱兩大挑戰。
- 實驗結果表明,SM-CERL方法在導航成功率和效率方面優于現有的經典和先進方法,能夠使無人機學習到令人滿意的導航能力,朝著尚未探索但相似度高的區域飛行,并有效逃逸局部最優,在新場景下也展現出良好的泛化能力,為無人機在各種實際應用中的大規模戶外導航提供了有力支持。
- 未來工作:
- 未來的發展可以聚焦于兩個主要方面,即跨平臺適應性和任務場景多樣化。對于跨平臺適應性,可以將框架擴展以支持不同類型的無人機(如旋翼和固定翼平臺)、實現多無人機協作以及整合額外的傳感器(如雷達、激光雷達和熱像儀)。
- 對于任務場景多樣化,可以將框架擴展以支持各種任務,包括搜索與救援、環境監測和基礎設施檢查等。此外,還可以通過充分利用集成環境傳感器的全面數據、為動態環境開發自適應導航策略以及為各種天氣和光照條件建立穩健解決方案來增強框架性能。


:最小可行化產品(MVP)的設計、驗證與數據驅動迭代)











》閱讀筆記:p86-p90)



: 線性代數(矩陣運算、特征值分解等))
)
